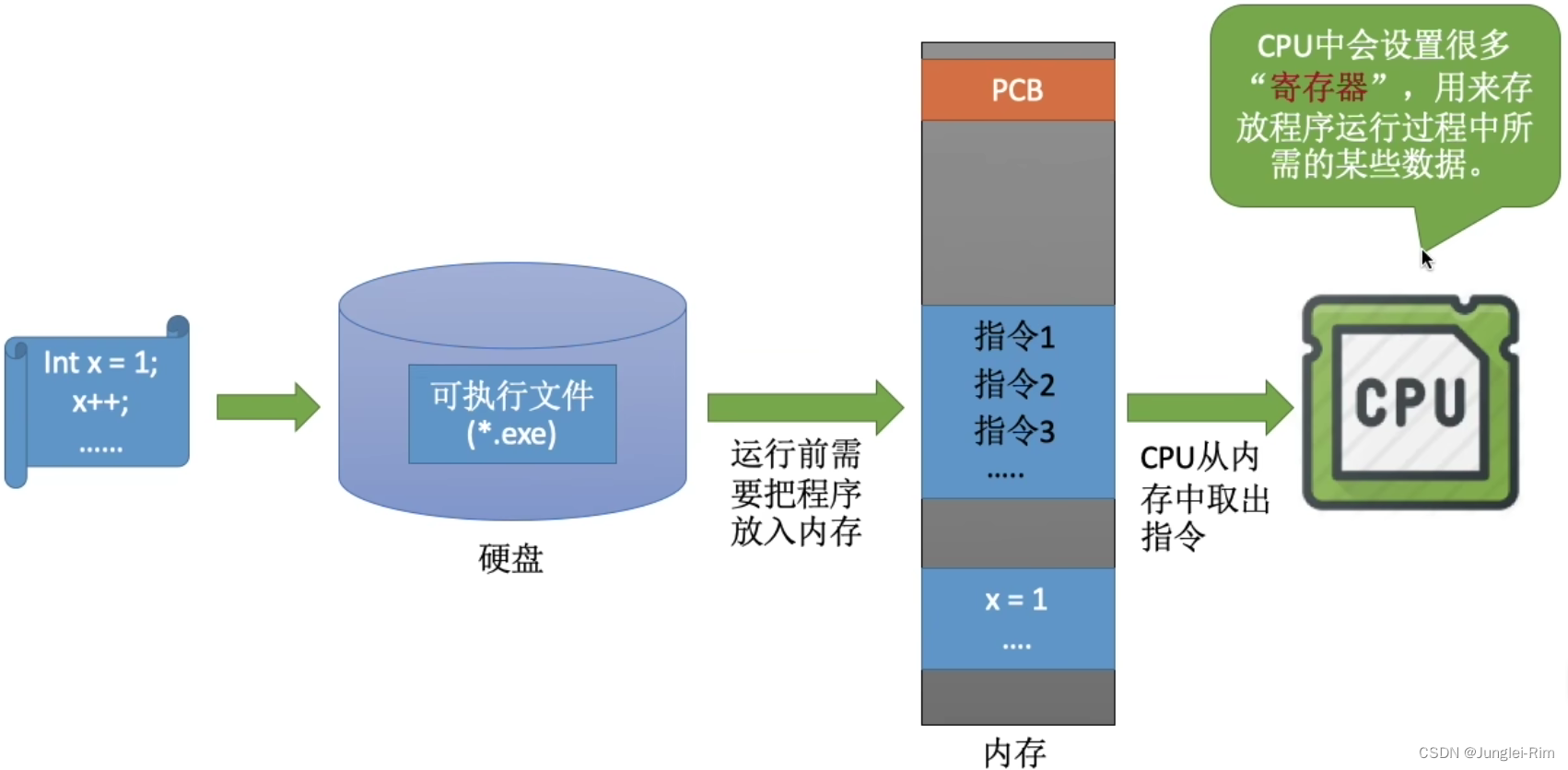
文章目录
- 根据截图,识别菜品
- 根据截图,识别数学公式
- 根据截图生成前端UI代码
- 可视化图像复现
- 案例一
- 案例二
- 更多可以使用的方向
制作人:川川
辛苦测评,如果对你有帮助支持一下书籍:https://item.jd.com/14049708.html
根据截图,识别菜品
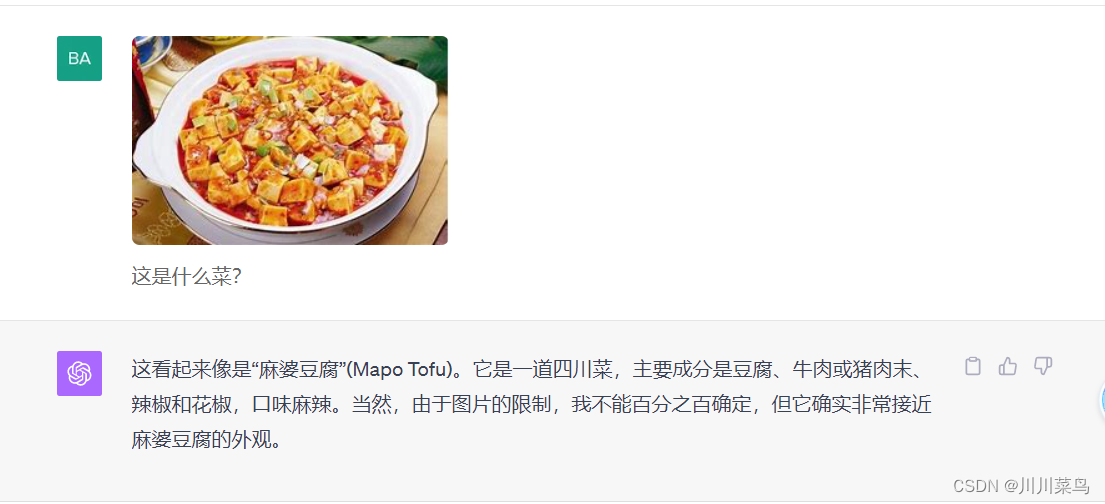
问一个麻婆豆腐看看?回复如下:
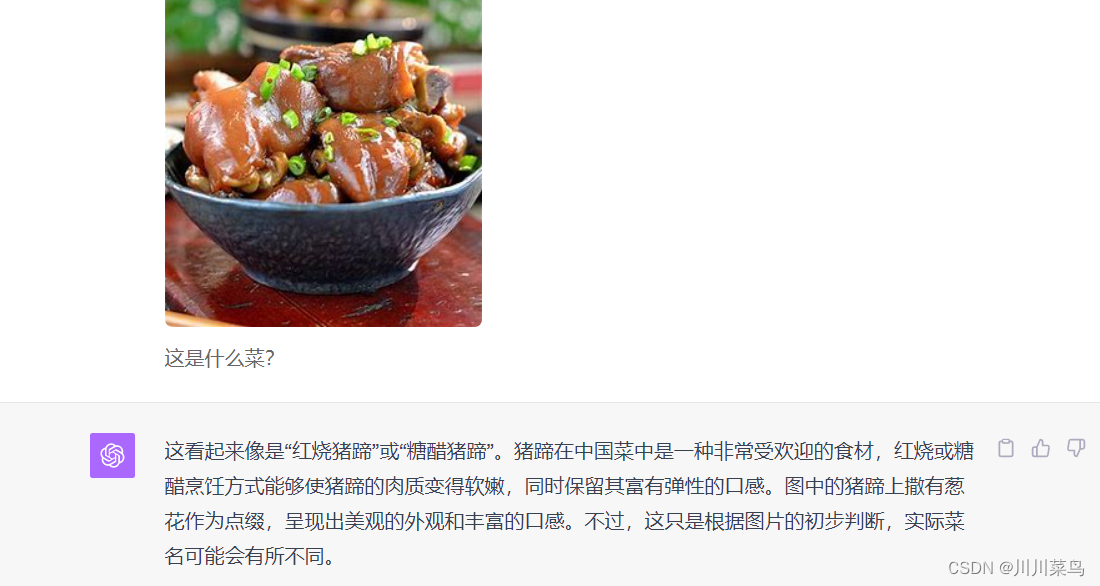
问一个红烧猪蹄看看?回复如下:
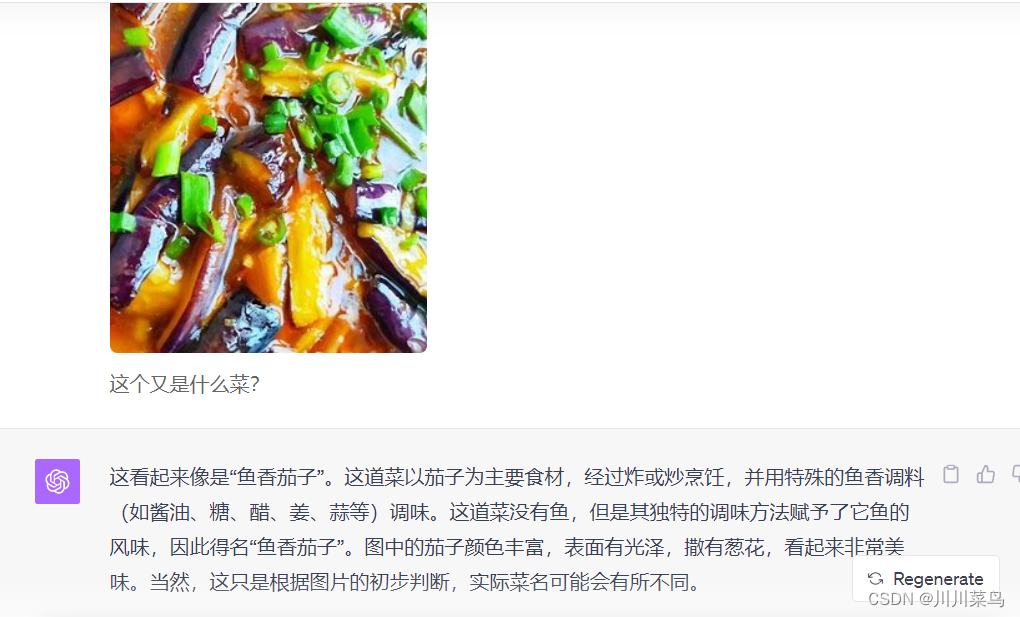
再来问一个红烧茄子,回复如下:
根据截图,识别数学公式
这里我选一个考研高数的选择题测试:

再选一个选择题:

既然都识别完全正确,给出答案更是我想要的,可以看到答案完全正确!

根据截图生成前端UI代码
提问:
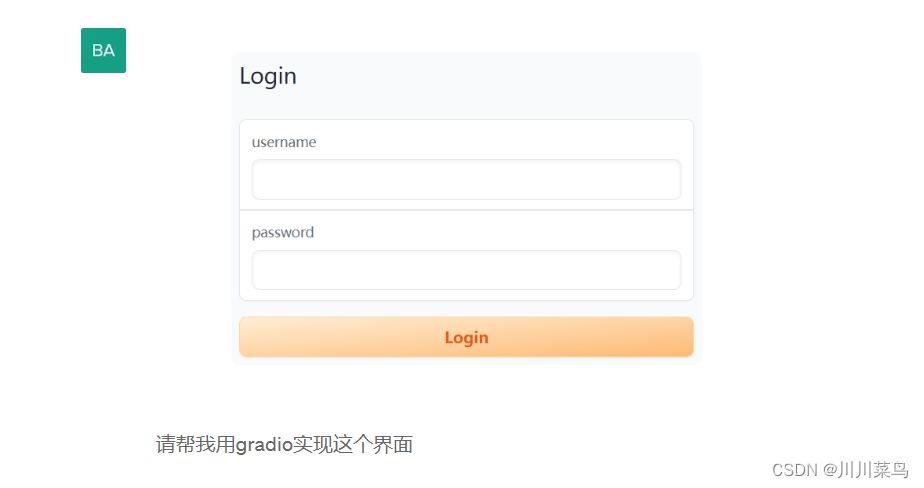
给我生成代码:
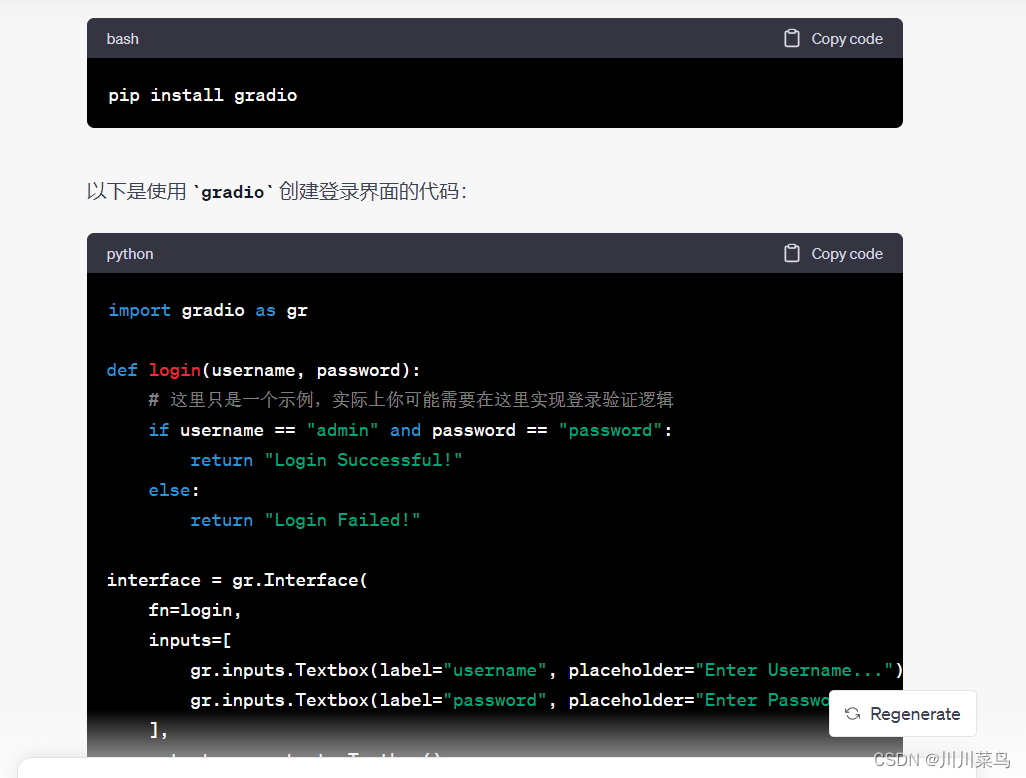
运行效果如下,基本已经实现:
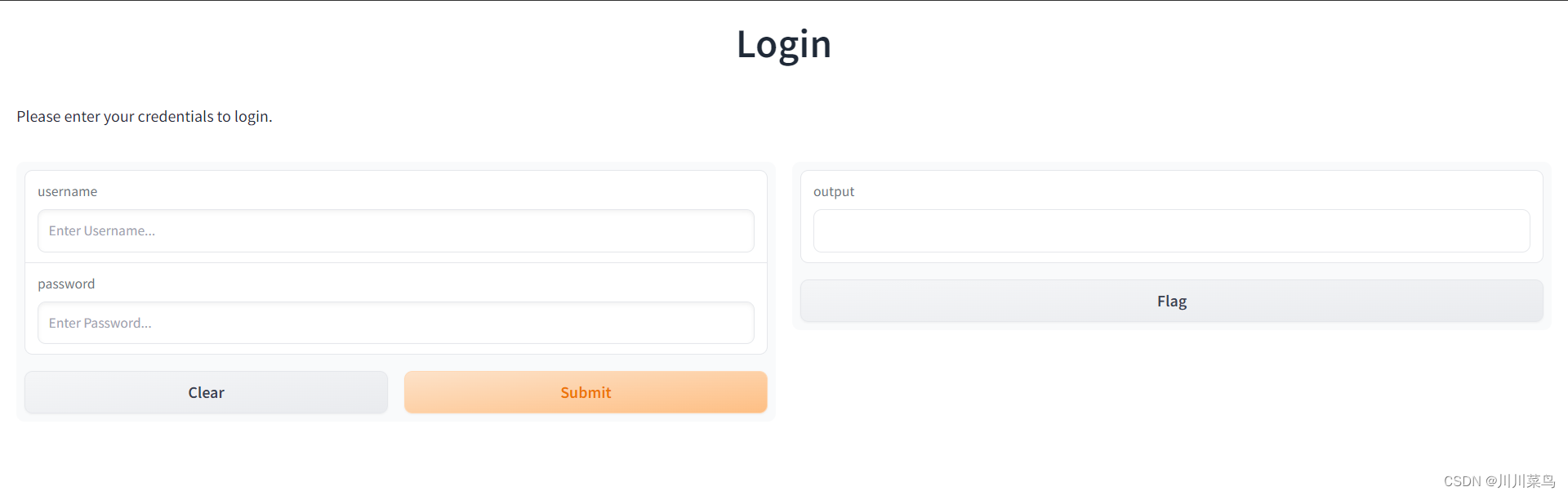
继续让他帮我复现一个UI:
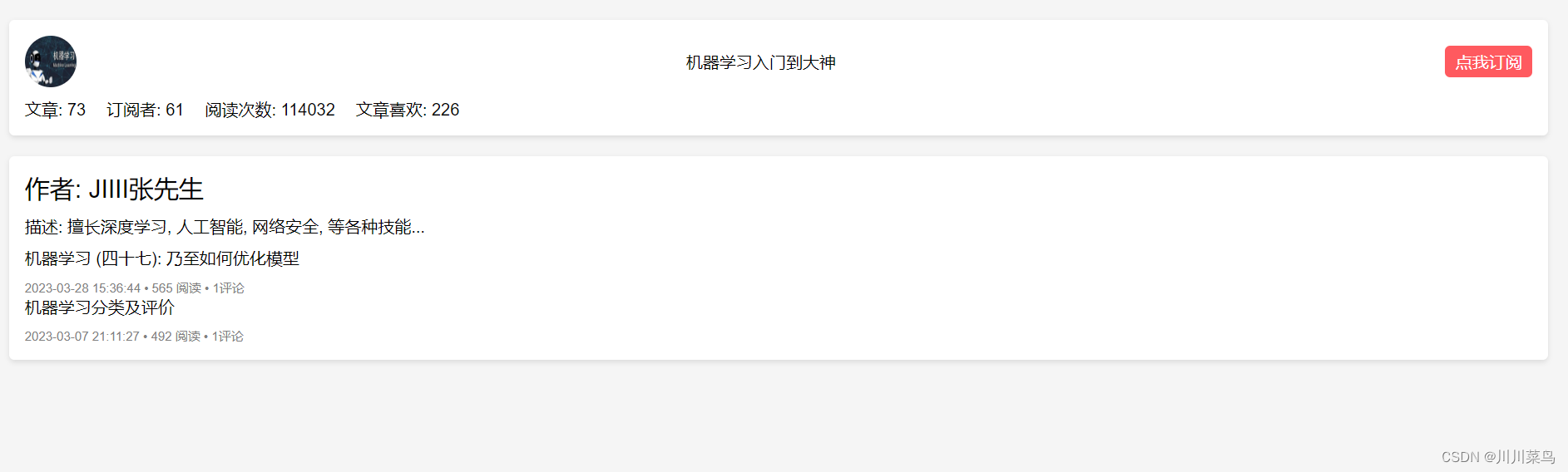
根据代码,我得到结果如下UI结果:
可视化图像复现
案例一
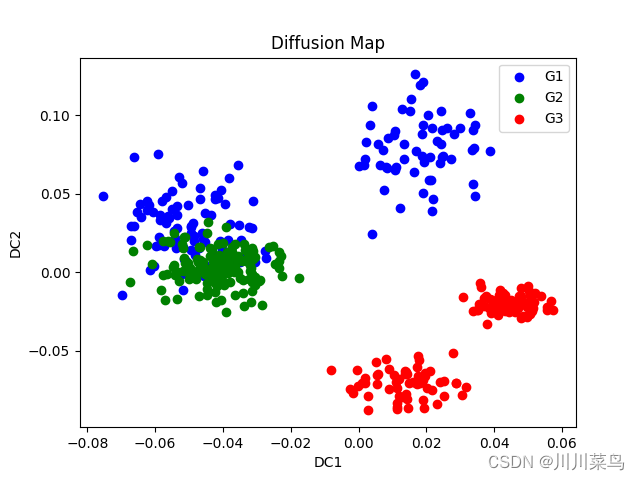
例如这个图:
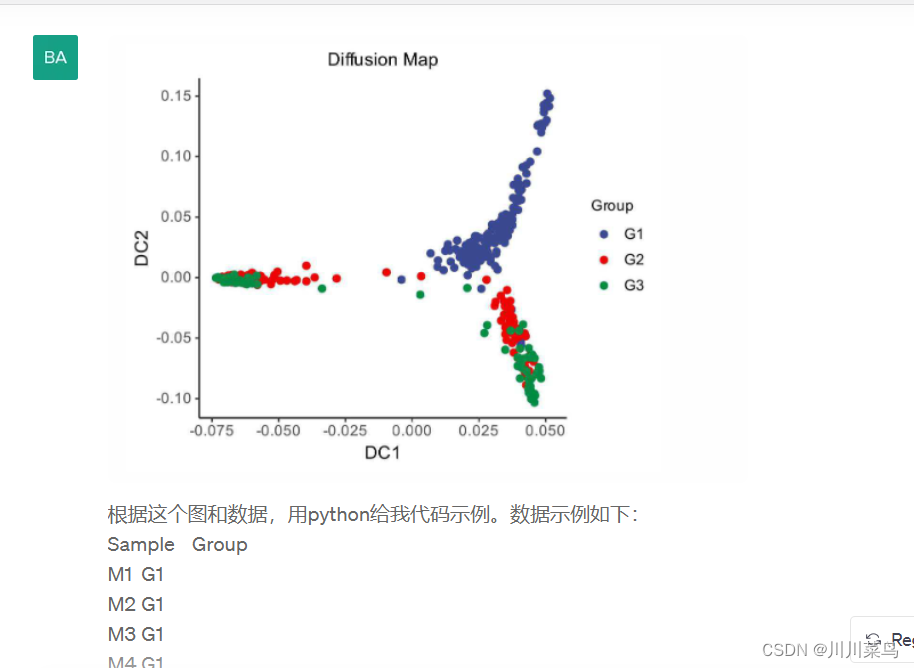
返回代码如下:
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟数据
np.random.seed(0)
num_samples_per_group = 150
# 为G1生成数据
g1_dc1 = np.concatenate([np.random.normal(-0.05, 0.01, 90), np.random.normal(0.015, 0.01, 60)])
g1_dc2 = np.concatenate([np.random.normal(0.03, 0.02, 90), np.random.normal(0.08, 0.02, 60)])
# 为G2生成数据
g2_dc1 = np.random.normal(-0.04, 0.01, num_samples_per_group)
g2_dc2 = np.random.normal(0.005, 0.01, num_samples_per_group)
# 为G3生成数据
g3_dc1 = np.concatenate([np.random.normal(0.015, 0.01, 60), np.random.normal(0.045, 0.005, 90)])
g3_dc2 = np.concatenate([np.random.normal(-0.07, 0.01, 60), np.random.normal(-0.02, 0.005, 90)])
# 绘制图像
plt.scatter(g1_dc1, g1_dc2, color='blue', label='G1')
plt.scatter(g2_dc1, g2_dc2, color='green', label='G2')
plt.scatter(g3_dc1, g3_dc2, color='red', label='G3')
# 设置标题和轴标签
plt.title('Diffusion Map')
plt.xlabel('DC1')
plt.ylabel('DC2')
plt.legend()
# 显示图像
plt.show()
结果如下,可以看到基本实现,具体只不过就是数据的调整:
案例二
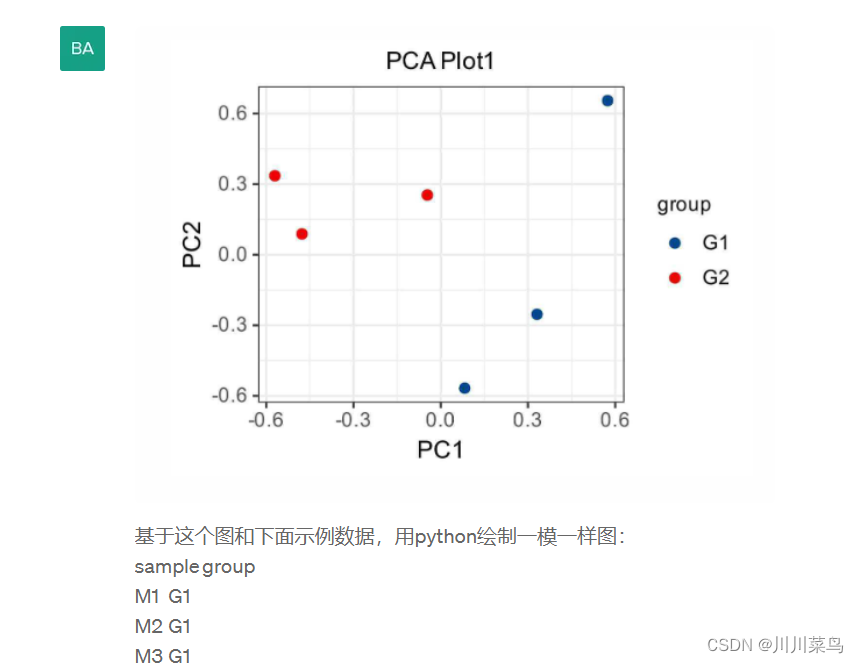
复现这个图:
返回代码如下:
import matplotlib.pyplot as plt
import pandas as pd
# 创建数据
data = {
'sample': ['M1', 'M2', 'M3', 'M8', 'M9', 'M10'],
'group': ['G1', 'G1', 'G1', 'G2', 'G2', 'G2'],
'PC1': [0.5, -0.4, 0.2, -0.5, 0, 0.5],
'PC2': [0.5, -0.4, 0.2, 0.3, 0, -0.2]
}
df = pd.DataFrame(data)
color_map = {'G1': 'blue', 'G2': 'red'}
# 绘制散点图
for group, color in color_map.items():
mask = df['group'] == group
plt.scatter(df[mask]['PC1'], df[mask]['PC2'], color=color, s=100, label=group)
plt.title('PCA Plot1')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.grid(True)
plt.axhline(0, color='black',linewidth=0.5)
plt.axvline(0, color='black',linewidth=0.5)
plt.legend()
plt.show()
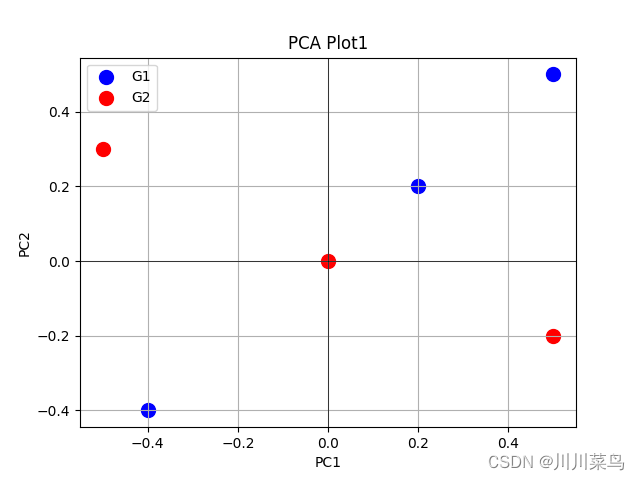
运行如下,可以看到基本复现,完全OK:
更多可以使用的方向
- 文本识别:从截图中提取文本信息,这在处理图像中的文本时非常有用,尤其是当原始文档不可用时。
- 对象识别:识别截图中的特定对象,如人脸、动植物、产品或其他项目。
- 数据提取:从截图中的图表或图形中提取数据。
- 翻译:提取截图中的文本,并将其翻译成其他语言。
- 辅助视觉障碍人士:通过截图识别,帮助视觉障碍人士理解图像内容。
- 图像搜索:通过截图识别,可以进行图像搜索,找到相似或相关的图片。
- 图像编辑和增强:识别截图中的元素,以便进行图像编辑和增强。
- 教育与学习:通过截图识别,可以帮助用户学习和理解图像中的信息,例如,识别数学公式或科学图表。
- 解决问题:例如,在技术支持领域,用户可以通过截图分享他们的问题,而支持人员可以通过识别截图来提供帮助。
10.比较和分析:比较不同截图中的内容,进行图像分析或者内容比较。