在进行去雨去雪去雾算法的学习过程中,需要构建去雨去雪去雾数据集,本文参考Learning Multiple Adverse Weather Removal via Two-stage Knowledge Learning and Multi-contrastive Regularization: Toward a Unified Model论文中的数据集设定,分别从Rain1400,CSD,OTS三个数据集的训练集中挑选5000张作为训练集,使用原始的测试集作为验证集。

首先是去雪数据集CSD中挑选5000张,该数据集的挑选最为简单,只需要随机从8000张中挑选5000张即可。其中首先生成要挑选的图片的文本信息,创建csd.txt,随后直接读取csd.txt中的路径即可。
import os, random, shutil
def moveFile(fileDir, tarDir):
datas=[]
with open("csd.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
datas.append(line)
for name in datas:
print(fileDir + name,tarDir + name)
shutil.move(fileDir + name, tarDir + name)
#生成要随机抽取的图像地址
def create_img_txt(dir):
pathDir = os.listdir(dir) # 取图片的原始路径
picknumber = 5000 # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
for name in sample:
with open("csd.txt", "a") as file:
file.write(name + "\n")
print(name)
file.close()
if __name__ == '__main__':
fileDir = "F:/datasets\去噪\去雪数据集\CSD\Train\Snow/" # 源图片文件夹路径
tarDir = "F:\datasets\去噪\挑选出的数据集\Snow\Train/Snow/" # 移动到新的文件夹路径
moveFile(fileDir, tarDir)
#moveFile(fileDir,tarDir)
csd.txt文件内容:
随后是去雨数据集的构建,由于该数据集中每一张真值图像对应14张噪声图像,因此本文采用与去雪数据集相同的构造方式,首先在去雾噪声图像中挑选5000张,由于训练集中的真值图像只有900张,因此这5000张噪声图像中包含了所有真值图像的噪声,但为了以防万一,还是通过读取前面的真值图像编号来确定真值图像。
import os, random, shutil
def moveFile(fileDir, tarDir):
datas=[]
with open("rain_1.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
datas.append(line)
for name in datas:
print(fileDir + name,tarDir + name)
shutil.copy(fileDir + name, tarDir + name)
def editrain():
datas=[]
with open("rain_1.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
line=line.split("_")
datas.append(line[0]+".jpg")
for name in datas:
with open("rain_2.txt", "a") as file:
file.write(name + "\n")
print(name)
#生成要随机抽取的图像地址
def create_img_txt(dir):
pathDir = os.listdir(dir) # 取图片的原始路径
picknumber = 5000 # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
for name in sample:
with open("rain_1.txt", "a") as file:
file.write(name + "\n")
print(name)
file.close()
if __name__ == '__main__':
fileDir = "F:\datasets\去噪\去雨数据集\下雨检测图像数据集/rainy_image_dataset/training/rainy_image/" # 源图片文件夹路径
tarDir = "F:\datasets\去噪\挑选出的数据集\Rain\Train\Rain/" # 移动到新的文件夹路径
moveFile(fileDir, tarDir)
#moveFile(fileDir,tarDir)
rain1.txt文件为噪声图像
rain2.txt为真值图像
随后是去雾数据集的构建,去雾数据集包含2601张真实图像,每张图像对应35张噪声图像,且其分为了4个文件,分别包含520x35,520x35,520x35,501x35
考虑挑选的图像总量为5000张,因此分别从每个文件中挑选1300,1300,1300,1100张加噪图像
import os, random, shutil
def moveFile(fileDir, tarDir):
datas=[]
with open("fog_2.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
datas.append(line)
for name in datas:
print(fileDir + name,tarDir + name)
shutil.copy(fileDir + name, tarDir + name)
def editrain():
datas=[]
with open("fog_1.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
line=line.split("_")
datas.append(line[0]+".jpg")
for name in datas:
with open("fog_2.txt", "a") as file:
file.write(name + "\n")
print(name)
def create_img_txt(dir):
pathDir = os.listdir(dir) # 取图片的原始路径
picknumber = 1100 # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
for name in sample:
with open("fog_1.txt", "a") as file:
file.write(name + "\n")
print(name)
file.close()
if __name__ == '__main__':
fileDir = "F:/datasets/去噪/室外去雾数据集OTS/OTS_beta/clear/clear/clear/" # 源图片文件夹路径
tarDir = "F:/datasets/去噪/挑选出的数据集/Fog/Train/GT/" # 移动到新的文件夹路径
#create_img_txt(fileDir)
#editrain()
moveFile(fileDir, tarDir)
为了方便提取,需要生成四个单独的数据集地址文件,最后再汇总在一起。
最后便是JSON文件的构建了,使用先前生成的地址文件,可以很方便的构建出对应的JSON格式文件。
csd_json文件构建:
gt_path="F:/datasets/CSD/Train/GT/"
input_path="F:/datasets/CSD/Train/Snow/"
def editrain():
data=[]
with open("csd.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
data.append(line)
with open('csd.json', 'a') as f:
for name in data:
path='"'+gt_path+name+'",\n'+'"'+input_path+name+'"'
f.write("["+path+"],\n")
editrain()
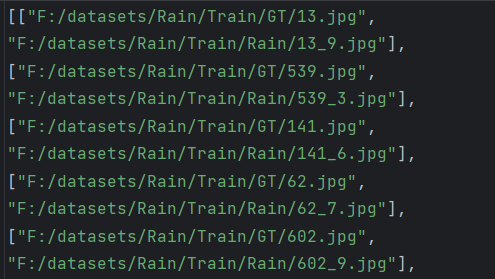
去雨去雾json文件构建
gt_path="F:/datasets/Rain/Train/GT/"
input_path="F:/datasets/Rain/Train/Rain/"
def editrain():
data1=[]
data2=[]
with open("rain_1.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
data1.append(line)
line=line.split("_")
data2.append(line[0]+".jpg")
with open('rain1400.json', 'a') as f:
for name1,name2 in zip(data1,data2):
path='"'+gt_path+name2+'",\n'+'"'+input_path+name1+'"'
f.write("["+path+"],\n")
editrain()
生成的json文件: