摘要
原文标题:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
链接:https://arxiv.org/pdf/1908.10084.pdf
尽管Bert和RoBERTa在句子对回归任务上,例如语义文本相似度(Semantic Text Similarity),取得了新的sota结果。但是,需要将两个句子都输入到模型中,造成较大的计算延时:在10,000个句子中需要相似的句子对,需要BERT计算50,000,000次,需要大概65个小时。因此,BERT的模型结构决定了,不适合用来做相似文本检索或者是无监督文本聚类。
因此,本文提出了基于孪生网络或者三元网络结构的BERT模型,可以用来计算具有语义的句子向量,该向量可以使用余弦相似度进行比较。这种方法可以在保留BERT的准确度水平的基础上,将65小时缩减到5s。
文本评估了SBERT(Sentence BERT的简称)和SRoBERTa在STS任务和迁移学习任务上的表现。
模型
SBERT通过在BERT和RoBERTa的输出之上加入池化层,获得固定长的句子向量表示。本文实验了三种池化策略:
- 直接使用CLS的向量;
- 使用所有输出向量的均值MEAN
- 使用所有输出向量的最大值MAX
模型结构
使用孪生网络训练BERT。具体结构如下:
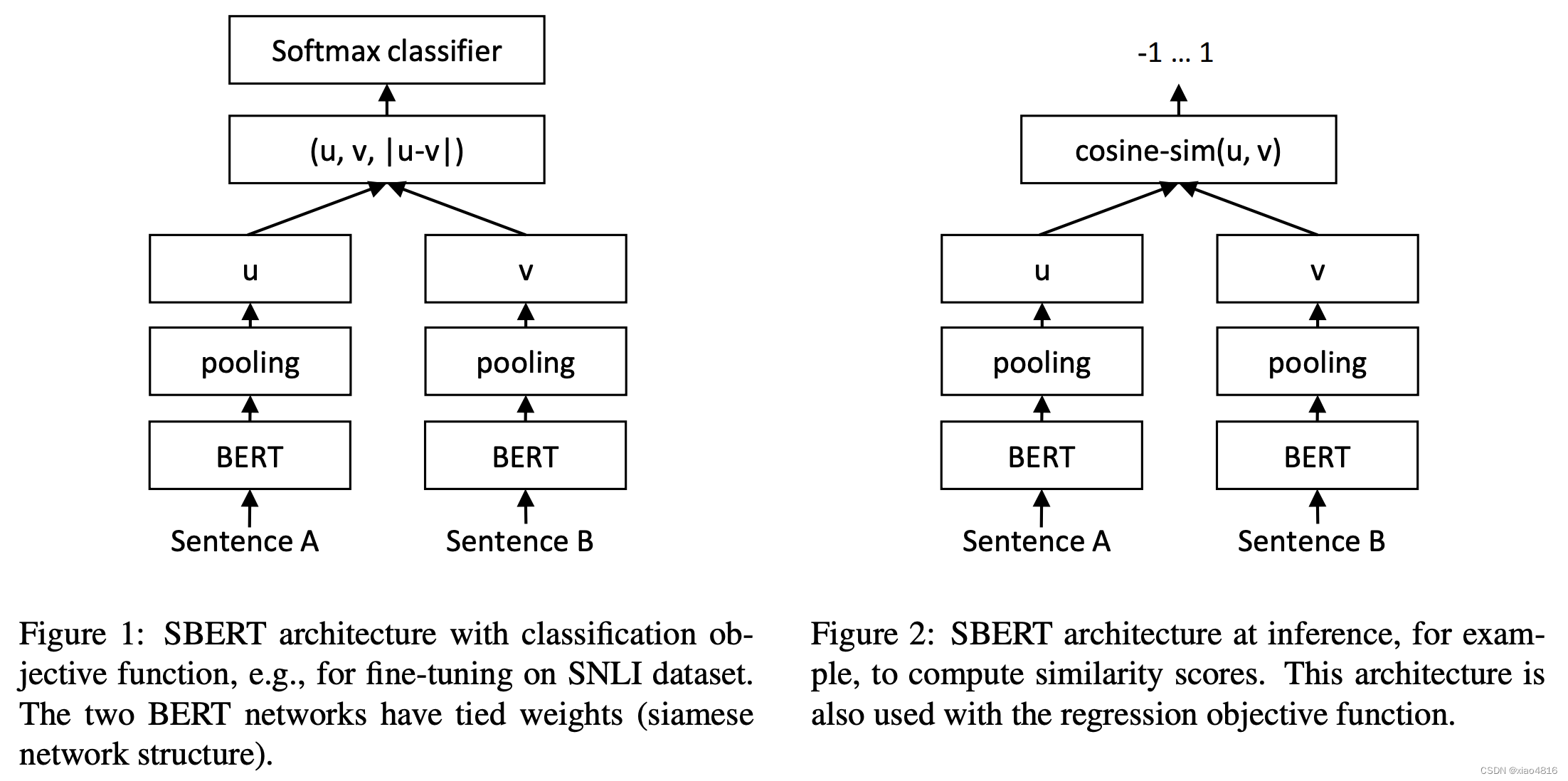
注意:孪生网络通过共享两个主模型的权重,从而得到一致的向量表示。
模型的网络结构取决于可用的训练数据。本文实验了如下的网络结构和损失函数。
分类目标函数
首先将三个向量拼起来,分别是u,v,元素差|u-v|。然后乘权重矩阵后,计算softmax得到最终的预测概率向量。
o
=
s
o
f
t
m
a
x
(
W
3
n
∗
k
∗
c
o
n
c
a
t
(
u
,
v
,
∣
u
−
v
∣
)
)
o=softmax(W^{3n*k}*concat(u,v,|u-v|))
o=softmax(W3n∗k∗concat(u,v,∣u−v∣))
其中,n为句子向量的长度,k为类别标签的个数。然后使用交叉熵损失函数对模型进行权重的计算。
c
r
o
s
s
_
e
n
t
r
o
p
y
_
l
o
s
s
=
−
∑
y
i
∗
(
l
o
g
p
i
)
cross\_entropy\_loss=-\sum{y_i*(logp_i)}
cross_entropy_loss=−∑yi∗(logpi)
回归目标函数
计算两个句子向量的余弦相似度作为输出。
o
=
c
o
s
_
s
i
m
(
u
,
v
)
=
u
∗
v
∣
∣
u
∣
∣
∗
∣
∣
v
∣
∣
o=cos\_sim(u,v)=\frac{u*v}{||u||*||v||}
o=cos_sim(u,v)=∣∣u∣∣∗∣∣v∣∣u∗v
使用均方误差作为损失函数。
m
e
a
n
_
s
q
u
a
r
e
_
e
r
r
o
r
=
−
∑
i
n
(
y
^
i
−
y
i
)
2
mean\_square\_error=-\sum_i^n{(\hat{y}_i-y_i)^2}
mean_square_error=−i∑n(y^i−yi)2
三元目标函数
给定一个锚定句子a,一个正例句子p,一个负例句子n。三元损失函数使a和p之间的距离小于a和n之间的距离。具体的损失函数如下:
t
r
i
p
l
e
_
l
o
s
s
=
m
a
x
(
∣
s
a
,
s
p
∣
−
∣
s
a
,
s
n
∣
+
ϵ
,
0
)
triple\_loss=max(|s_a,s_p|-|s_a,s_n|+\epsilon,0)
triple_loss=max(∣sa,sp∣−∣sa,sn∣+ϵ,0)
其中,
s
x
s_x
sx表示句子a/p/n的句子向量。
∣
.
∣
|.|
∣.∣表示距离函数。
ϵ
\epsilon
ϵ表示间隔。
ϵ
\epsilon
ϵ的作用为,ap之间的距离和an之间的距离只差至少在该间隔之上。本文中,距离使用欧氏距离,间隔设置为1.
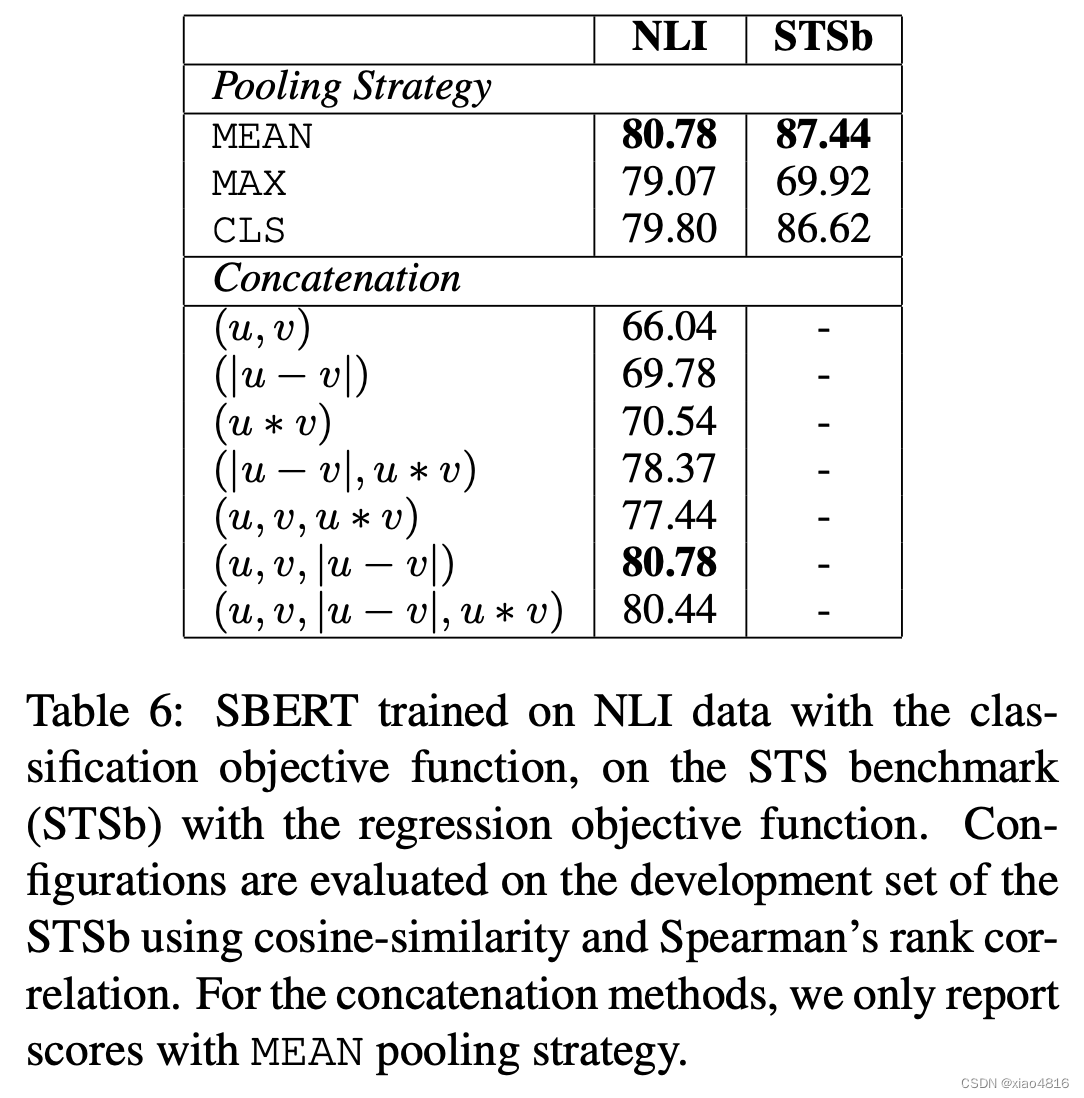
消融实验
消融实验的目的是,通过去掉模型中的某个模块,观察结果的变化,从而判断该模块的作用。目的是发现其中的因果关系。
本文验证了不同的池化策略和向量拼接策略之间的差异。





![[Java·算法·困难]LeetCode124.二叉树中的最大路径和](https://img-blog.csdnimg.cn/2e7b2b30fb1a4b41a0a28a7e6e55fe1e.png)