Elasticsearch的集群部署
- 1. Elasticsearch集群架构
- 主节点
- 数据节点
- 客户端节点
- 分片
- 节点间通信
- 集群状态
- 2. Elasticsearch集群部署
- 2.1 系统配置修改
- 2.1.1 修改文件句柄数和线程数
- 2.1.2 修改虚拟内存
- 2.1.3 关闭交换空间(Swap)
- 2.2 下载es数据库并上传到服务器
- 2.3 修改集群配置文件
- 2.3.1 elasticsearch.yml配置项说明
- 2.3.2 修改node1节点配置信息
- 2.3.2 修改node2节点配置信息
- 2.3.3 修改node3节点配置信息
- 2.4 创建 Elasticsearch 用户和组
- 2.5 设置目录权限
- 2.6. 启动 Elasticsearch 服务
- 2.6.1 配置启动内存(可选)
- 2.6.2 创建启动和停止服务的脚本
- 2.7 开放防火墙端口
- CentOS
- Ubuntu
- 2.8 查看es启动状态
1. Elasticsearch集群架构
Elasticsearch集群是一个强大的搜索和分析引擎,由多个节点组成,每个节点都是一个独立的Elasticsearch实例。这些节点协同工作,共同构建一个高度可用和可扩展的搜索引擎。本文将深入探讨Elasticsearch集群的架构和部署,包括主节点、数据节点、客户端节点、分片以及节点间的通信方式。
主节点
在Elasticsearch集群中,有一个节点被指定为主节点。主节点的主要任务是集群管理和协调工作。以下是主节点的一些关键职责:
-
维护集群状态: 主节点负责维护整个集群的状态,包括
节点列表、索引元数据和分片状态等。 -
负责集群重平衡: 当新的节点加入或旧的节点退出集群时,主节点会负责
重新平衡集群,确保分片被适当地重新分配给节点,以保持负载均衡。 -
执行集群级别操作: 主节点可以执行集群级别的操作,例如创建或删除索引、设置索引级别的设置等。
-
监控节点状态: 主节点监控集群中的各个节点的状态,及时检测节点是否正常工作。
在一个集群中,只能有一个主节点。如果主节点出现故障,Elasticsearch会自动选举一个新的主节点来接管工作,确保集群的稳定运行。
数据节点
数据节点的主要责任是存储和处理数据。当客户端向集群发起搜索请求时,数据节点会根据请求查询本地数据并返回结果。每个数据节点都负责存储集群中的一部分数据。当新的数据被索引时,数据节点会将数据分配给相应的分片,并将分片存储在本地磁盘上。如果数据节点发生故障,集群中的其他节点会接管该节点的工作,确保数据的可用性和冗余备份。
客户端节点
客户端节点不存储数据,它们的主要作用是向集群发送查询请求,并将查询结果返回给客户端应用程序。
客户端节点具有以下两个关键作用:
-
负载均衡: 客户端节点可以将查询请求分配给不同的数据节点,实现负载均衡,提高查询性能。
-
故障切换: 如果某个数据节点出现故障,客户端节点可以自动将查询请求切换到其他健康的节点,确保服务的可用性。
分片
在Elasticsearch集群中,数据被分成多个分片进行存储和管理。每个分片是一个独立的Lucene索引,包含了一部分数据和索引信息。分片可以在集群中的不同节点之间进行分配和复制,以实现高可用性和数据冗余。
每个索引都可以被分成多个主分片和多个副本分片。主分片是索引的基本单元,包含数据的一部分和索引信息。每个主分片都是独立的Lucene索引,可以在集群中的任何节点上存储。副本分片是主分片的拷贝,用于提高查询效率和可用性。
分片的数量在索引创建时指定,并且一旦创建后就不能更改。通常情况下,主分片的数量应该与集群中的数据节点数量相匹配,以确保每个节点都能存储一定数量的分片。
节点间通信
在Elasticsearch集群中,节点之间通过网络进行通信。每个节点都有一个唯一的节点名称,节点名称由Elasticsearch自动生成。节点名称通常采用以下格式:
<host>-<uuid>
其中,host是节点所在的主机名,uuid是一个唯一的标识符,用于确保节点名称的唯一性。
节点之间的通信可以通过两种方式进行:HTTP协议和Transport协议。HTTP协议是Elasticsearch的默认协议,用于处理RESTful API请求。Transport协议是Elasticsearch集群内部使用的协议,用于节点之间的直接通信。
集群状态
Elasticsearch集群的状态可以分为以下三种:
-
Green: 集群正常,所有主分片和副本分片都可用。
-
Yellow: 集群部分可用,所有主分片都可用,但一些副本分片不可用。
-
Red: 集群不可用,至少有一个主分片不可用。
当Elasticsearch集群中的节点发生故障时,主节点会自动将故障节点从集群中移除,并将分配给该节点的分片重新分配给其他节点。一旦故障节点恢复正常
,它会重新加入集群,并重新分配分片,确保数据的完整性和可用性。
Elasticsearch的集群架构为大规模数据存储和搜索提供了高度可扩展性和可用性,使其成为处理复杂搜索和分析需求的理想选择。通过理解集群架构的不同组件和角色,可以更好地规划和管理Elasticsearch集群,以满足业务需求。
2. Elasticsearch集群部署
2.1 系统配置修改
2.1.1 修改文件句柄数和线程数
为了防止 Elasticsearch 用户拥有的可创建文件描述符权限过低而导致错误,需要修改文件句柄数和线程数。编辑 /etc/security/limits.conf 文件并添加以下内容:
# 文件句柄
es soft nofile 65536
es hard nofile 65536
# 线程
es soft nproc 4096
es hard nproc 4096
保存退出后,需要重新启动系统
以上配置是为了解决:
报错问题:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
问题描述:elasticsearch用户拥有的可创建文件描述的权限太低,至少需要65536;
2.1.2 修改虚拟内存
编辑 /etc/sysctl.conf 文件并添加以下内容:
vm.max_map_count=262144
保存退出后,刷新配置文件:
sysctl -p
验证是否修改成功:
sysctl vm.max_map_count
以上配置是为了解决:
报错问题:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
2.1.3 关闭交换空间(Swap)
官方建议:把内存的一半给Lucene+不要超过32G+关闭swap
ES建议要关闭 swap 内存交换空间,禁用swapping。因为当内存交换到磁盘上,一个100微秒的操作可能变成 10毫秒,然后100 微秒的操作时延累加起来,可以看出 swapping 对于性能的影响是致命的
vim /etc/fstab
注释含有swap一行
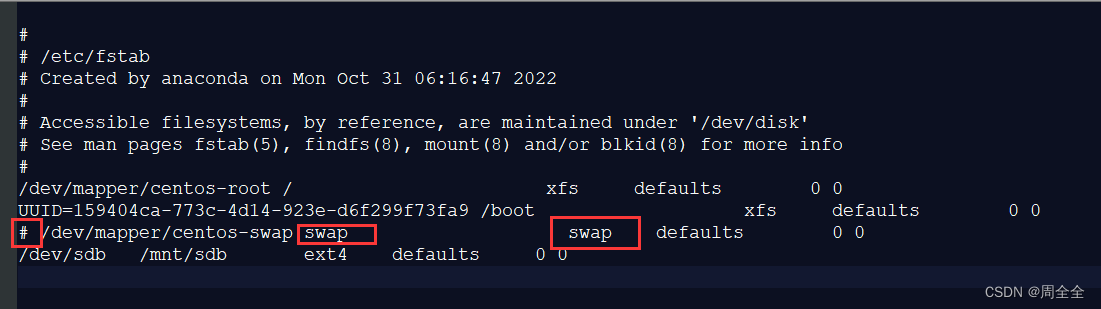
注释前:

保存退出后需要系统重启!
注释后:

2.2 下载es数据库并上传到服务器
下载 Elasticsearch 7.17.11,上传到服务器,并使用以下命令解压 Elasticsearch:
cd /mnt/data/es-cluster
tar -zxvf elasticsearch-7.17.11-linux-x86_64.tar.gz
复制3份,分别命名如下:

2.3 修改集群配置文件
2.3.1 elasticsearch.yml配置项说明
| 配置项 | 配置说明 | 配置示例 |
|---|---|---|
| cluster.name | 集群名称 | es-cluster |
| node.name | 节点名称 | node1 |
| path.data | 数据目录 | /home/es/path/node/data |
| path.logs | 日志目录 | /home/es/path/node/logs |
| node.name | 节点名称 | node1 |
| network.host | 绑定IP地址 | 127.0.0.1 |
| http.port | 指定服务访问端口 | 9201 |
| transport.tcp.port | 指定API端户端调用端口 | 9301 |
| discovery.seed_hosts | 集群通讯地址 | [“127.0.0.1:9301”, “127.0.0.1:9301:9302”, “127.0.0.1:9301:9303”] |
| cluster.initial_master_nodes | 集群初始化能够参选的节点信息 | [“127.0.0.1:9301”, “127.0.0.1:9301:9302”, “127.0.0.1:9301:9303”] |
| http.cors.enabled | 开启跨域访问支持 | true |
| http.cors.allow-origin | 跨域访问允许的域名 | “*” |
端口分配如下:
| 主机 | 节点名称 | HTTP端口 | Transport端口 |
|---|---|---|---|
| 192.168.0.119 | node1 | 9201 | 9301 |
| 192.168.0.119 | node2 | 9202 | 9302 |
| 192.168.0.119 | node3 | 9203 | 9303 |
2.3.2 修改node1节点配置信息
vim /mnt/data/es-cluster/elasticsearch-7.17.11-node1/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node1
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node1/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node1/logs
# 指定服务访问端口
http.port: 9201
# 指定API端户端调用端口
transport.tcp.port: 9301
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.3.2 修改node2节点配置信息
vim /mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node2
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node2/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node2/logs
# 指定服务访问端口
http.port: 9202
# 指定API端户端调用端口
transport.tcp.port: 9302
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.3.3 修改node3节点配置信息
vim /mnt/sdb/es-cluster/elasticsearch-7.17.11-node3/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node3
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node3/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node3/logs
# 指定服务访问端口
http.port: 9203
# 指定API端户端调用端口
transport.tcp.port: 9303
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.4 创建 Elasticsearch 用户和组
创建一个名为 “es” 的用户和一个名为 “es” 的群组,然后将用户添加到该群组中:
# 新建群组es
groupadd es
# 新建用户es并指定群组为es
useradd -g es es
# 设置用户密码
passwd es
# usermod 将用户添加到某个组group
usermod -aG root es
2.5 设置目录权限
设置 Elasticsearch 集群目录所属的用户和组:
chown -R es:es /mnt/data/es-cluster
2.6. 启动 Elasticsearch 服务
2.6.1 配置启动内存(可选)
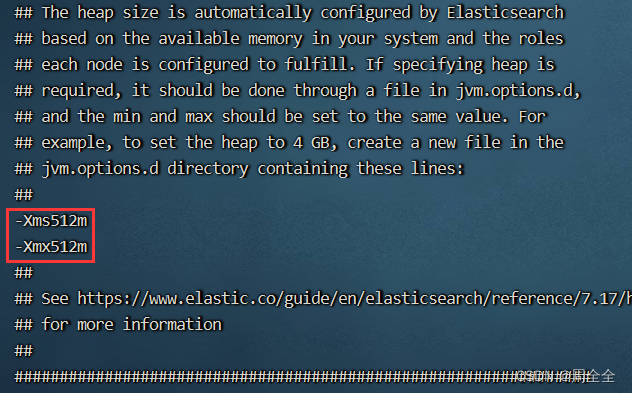
如果单机的内存大小有限,可以设置es的启动内存大小。分别进入三个节点的/config目录,执行 vim jvm.options,修改配置
-Xms512m
-Xmx512m
2.6.2 创建启动和停止服务的脚本
给三个es节点创建启动和停止 Elasticsearch 服务的脚本
(注意当前目录是在 ../elasticsearch-7.17.11-node1)
-
startes-single.sh
#!/bin/bash cd "$(dirname "$0")" # -d:后台(daemon)方式运行 Elasticsearch ./bin/elasticsearch -d -p pid -
stopes-single.sh
#!/bin/bash cd "$(dirname "$0")" if [ -f "pid" ]; then pkill -F pid fi -
赋予执行权限:
chmod 755 startes-single.sh stopes-single.sh chown es:es startes-single.sh stopes-single.sh -
以 Elasticsearch 用户身份启动 Elasticsearch 服务:
su es cd /mnt/sdb/es-cluster/elasticsearch-7.17.11-node1 ./startes-single.sh
可能的报错:
- failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing
][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [node2] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:173) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:160) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112) ~[elasticsearch-cli-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.Command.main(Command.java:77) ~[elasticsearch-cli-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:125) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80) ~[elasticsearch-7.17.11.jar:7.17.11]
Caused by: java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:328) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.node.Node.<init>(Node.java:429) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.node.Node.<init>(Node.java:309) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:169) ~[elasticsearch-7.17.11.jar:7.17.11]
... 6 more
uncaught exception in thread [main]
java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:328)
at org.elasticsearch.node.Node.<init>(Node.java:429)
at org.elasticsearch.node.Node.<init>(Node.java:309)
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:169)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:160)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112)
at org.elasticsearch.cli.Command.main(Command.java:77)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:125)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80)
解决: 配置文件中增加:node.max_local_storage_nodes: 3
这个配置限制了单节点上可以开启的ES存储实例的个数。单机需要启动多个实例就需要把这个配置写到配置文件中,并为这个配置赋值为2或者更高
2.7 开放防火墙端口
CentOS
# 查看防火墙状态
systemctl status firewalld
# 查看开放的端口
firewall-cmd --query-port=9200/tcp
# 添加端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 重载防火墙
firewall-cmd --reload
# 再次查看端口是否已经开放
firewall-cmd --query-port=9200/tcp
Ubuntu
# 查看防火墙状态
sudo ufw status
# 开放端口 9200
sudo ufw allow 9200/tcp
# 查看已添加的规则
sudo ufw status numbered
# 查看防火墙状态
sudo ufw status
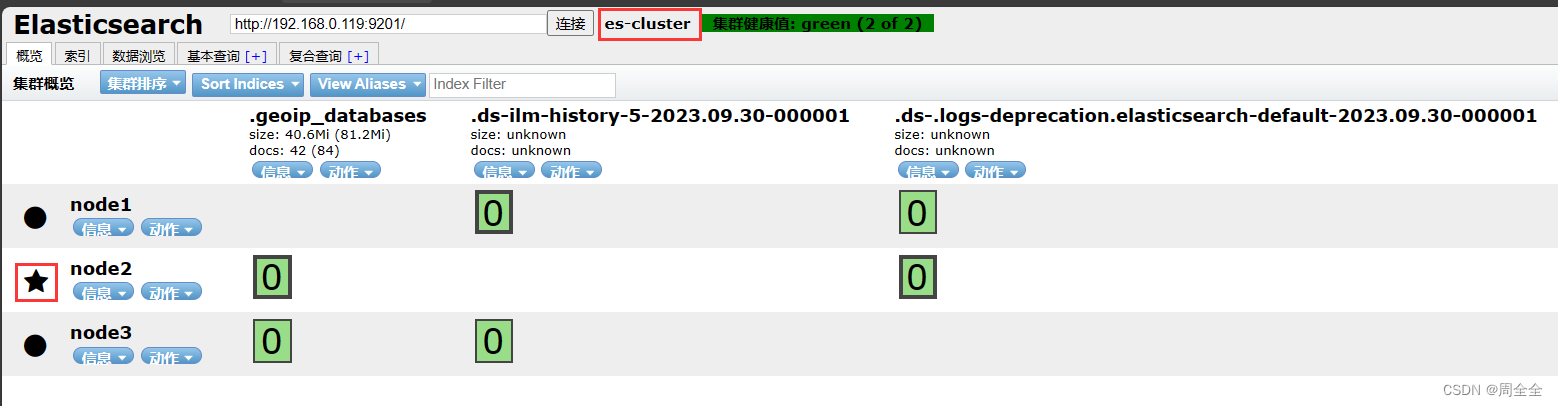
2.8 查看es启动状态
- 分别访问三个节点的http端口
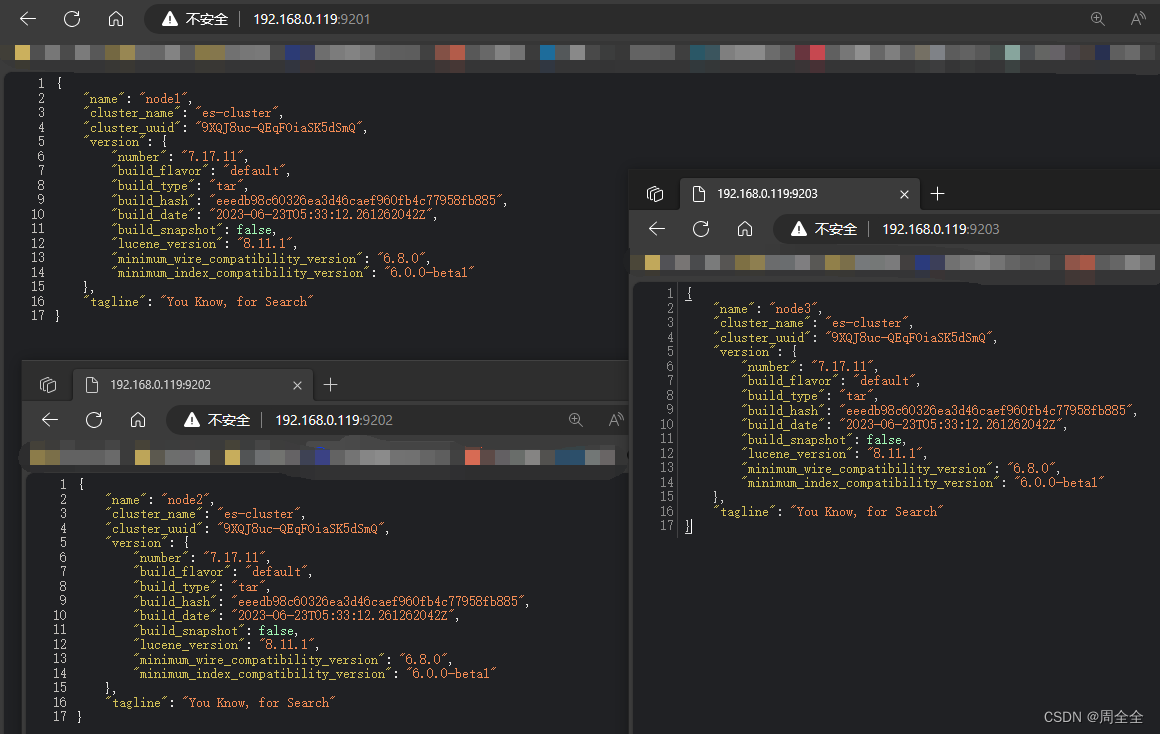
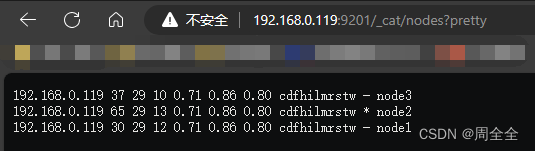
- 查看节点状态
http://192.168.0.119:9201/_cat/nodes?pretty
可以看到三个节点信息,三个节点会自行选举出主节点(ES的是基于Bully选举算法做的改进实现)
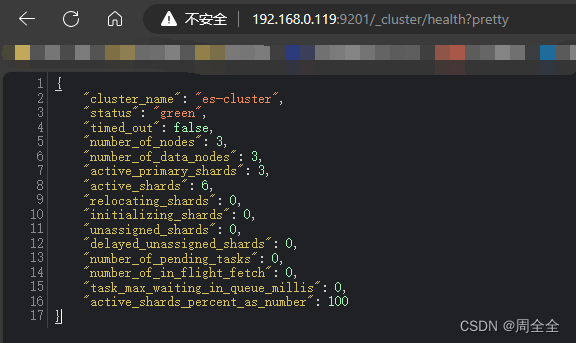
- 查看集群健康状态
http://192.168.0.119:9201/_cluster/health?pretty
4.elasticsearch header查看