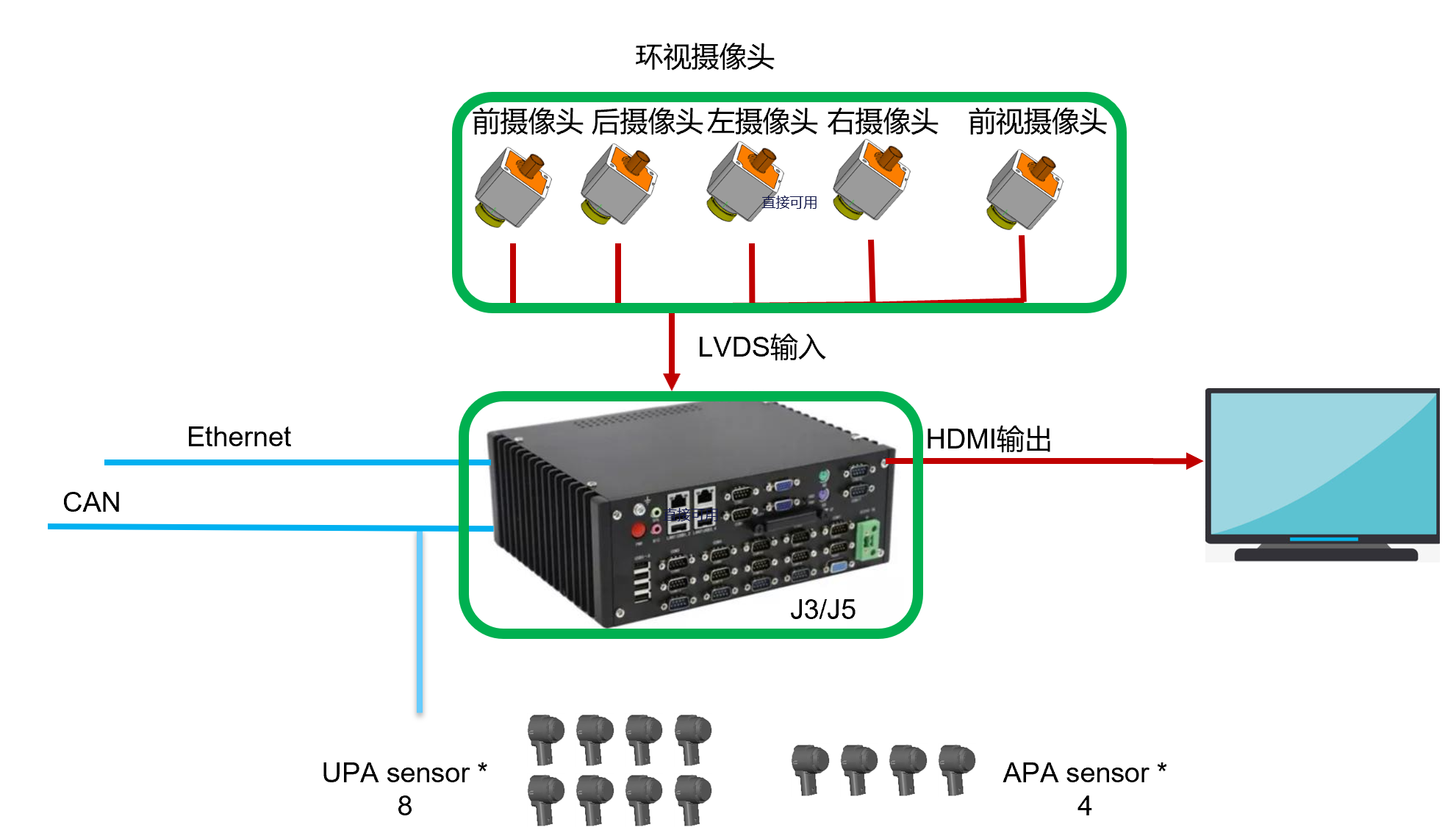
使用Transformers来使用模型
如希望使用Qwen-chat进行推理,所需要写的只是如下所示的数行代码。请确保你使用的是最新代码,并指定正确的模型名称和路径,如Qwen/Qwen-7B-Chat和Qwen/Qwen-14B-Chat
这里给出了一段代码
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# 可选的模型包括: "Qwen/Qwen-7B-Chat", "Qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认使用自动模式,根据设备自动选择精度
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 第一轮对话
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二轮对话
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》这段代码怎么用呢?
我们来分析一下吧\
从transformers库中导入类
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig这两行是从Hugging Face的Transformers库中导入了三个类:
【AutoModelForCausalLM】:这是一个用于加载预训练的因果语言模型(Causal Language Model)的类。因果语言模型是一种可以生成连续文本的模型,例如在对话生成或故事生成等任务中。
【AutoTokenizer】:这是一个用于加载预训练的分词器(Tokenizer)的类。分词器是用于将输入文本切分成模型可以理解的单元(如单词、子词或字符)的工具。
【GenerationConfig】:这是一个用于配置生成任务的类。它可以用于设置生成任务的各种参数,例如生成文本的最大长

![2023年中国肠胃炎用药行业现状分析:随着老龄化进程明显加速,市场规模同比增长7%[图]](https://img-blog.csdnimg.cn/img_convert/3d983f53934f6399eefdab45a3a52af7.png)