消息存储
在 【RocketMQ】消息的存储一文中提到,Broker收到消息后会调用CommitLog的asyncPutMessage方法写入消息,在DLedger模式下使用的是DLedgerCommitLog,进入asyncPutMessages方法,主要处理逻辑如下:
- 调用
serialize方法将消息数据序列化; - 构建批量消息追加请求
BatchAppendEntryRequest,并设置上一步序列化的消息数据; - 调用
handleAppend方法提交消息追加请求,进行消息写入;
public class DLedgerCommitLog extends CommitLog {
@Override
public CompletableFuture<PutMessageResult> asyncPutMessages(MessageExtBatch messageExtBatch) {
// ...
AppendMessageResult appendResult;
BatchAppendFuture<AppendEntryResponse> dledgerFuture;
EncodeResult encodeResult;
// 将消息数据序列化
encodeResult = this.messageSerializer.serialize(messageExtBatch);
if (encodeResult.status != AppendMessageStatus.PUT_OK) {
return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, new AppendMessageResult(encodeResult
.status)));
}
putMessageLock.lock();
msgIdBuilder.setLength(0);
long elapsedTimeInLock;
long queueOffset;
int msgNum = 0;
try {
beginTimeInDledgerLock = this.defaultMessageStore.getSystemClock().now();
queueOffset = getQueueOffsetByKey(encodeResult.queueOffsetKey, tranType);
encodeResult.setQueueOffsetKey(queueOffset, true);
// 创建批量追加消息请求
BatchAppendEntryRequest request = new BatchAppendEntryRequest();
request.setGroup(dLedgerConfig.getGroup()); // 设置group
request.setRemoteId(dLedgerServer.getMemberState().getSelfId());
// 从EncodeResult中获取序列化的消息数据
request.setBatchMsgs(encodeResult.batchData);
// 调用handleAppend将数据写入
AppendFuture<AppendEntryResponse> appendFuture = (AppendFuture<AppendEntryResponse>) dLedgerServer.handleAppend(request);
if (appendFuture.getPos() == -1) {
log.warn("HandleAppend return false due to error code {}", appendFuture.get().getCode());
return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.OS_PAGECACHE_BUSY, new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR)));
}
// ...
} catch (Exception e) {
log.error("Put message error", e);
return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR)));
} finally {
beginTimeInDledgerLock = 0;
putMessageLock.unlock();
}
// ...
});
}
}
序列化
在serialize方法中,主要是将消息数据序列化到内存buffer,由于消息可能有多条,所以开启循环读取每一条数据进行序列化:
- 读取总数据大小、魔数和CRC校验和,这三步是为了让buffer的读取指针向后移动;
- 读取FLAG,记在flag变量;
- 读取消息长度,记在bodyLen变量;
- 接下来是消息内容开始位置,将开始位置记录在bodyPos变量;
- 从消息内容开始位置,读取消息内容计算CRC校验和;
- 更改buffer读取指针位置,将指针从bodyPos开始移动bodyLen个位置,也就是跳过消息内容,继续读取下一个数据;
- 读取消息属性长度,记录消息属性开始位置;
- 获取主题信息并计算数据的长度;
- 计算消息长度,并根据消息长度分配内存;
- 校验消息长度是否超过限制;
- 初始化内存空间,将消息的相关内容依次写入;
- 返回序列化结果
EncodeResult;
class MessageSerializer {
public EncodeResult serialize(final MessageExtBatch messageExtBatch) {
// 设置Key:top+queueId
String key = messageExtBatch.getTopic() + "-" + messageExtBatch.getQueueId();
int totalMsgLen = 0;
// 获取消息数据
ByteBuffer messagesByteBuff = messageExtBatch.wrap();
List<byte[]> batchBody = new LinkedList<>();
// 获取系统标识
int sysFlag = messageExtBatch.getSysFlag();
int bornHostLength = (sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 4 + 4 : 16 + 4;
int storeHostLength = (sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 4 + 4 : 16 + 4;
// 分配内存
ByteBuffer bornHostHolder = ByteBuffer.allocate(bornHostLength);
ByteBuffer storeHostHolder = ByteBuffer.allocate(storeHostLength);
// 是否有剩余数据未读取
while (messagesByteBuff.hasRemaining()) {
// 读取总大小
messagesByteBuff.getInt();
// 读取魔数
messagesByteBuff.getInt();
// 读取CRC校验和
messagesByteBuff.getInt();
// 读取FLAG
int flag = messagesByteBuff.getInt();
// 读取消息长度
int bodyLen = messagesByteBuff.getInt();
// 记录消息内容开始位置
int bodyPos = messagesByteBuff.position();
// 从消息内容开始位置,读取消息内容计算CRC校验和
int bodyCrc = UtilAll.crc32(messagesByteBuff.array(), bodyPos, bodyLen);
// 更改位置,将指针从bodyPos开始移动bodyLen个位置,也就是跳过消息内容,继续读取下一个数据
messagesByteBuff.position(bodyPos + bodyLen);
// 读取消息属性长度
short propertiesLen = messagesByteBuff.getShort();
// 记录消息属性位置
int propertiesPos = messagesByteBuff.position();
// 更改位置,跳过消息属性
messagesByteBuff.position(propertiesPos + propertiesLen);
// 获取主题信息
final byte[] topicData = messageExtBatch.getTopic().getBytes(MessageDecoder.CHARSET_UTF8);
// 主题字节数组长度
final int topicLength = topicData.length;
// 计算消息长度
final int msgLen = calMsgLength(messageExtBatch.getSysFlag(), bodyLen, topicLength, propertiesLen);
// 根据消息长度分配内存
ByteBuffer msgStoreItemMemory = ByteBuffer.allocate(msgLen);
// 如果超过了最大消息大小
if (msgLen > this.maxMessageSize) {
CommitLog.log.warn("message size exceeded, msg total size: " + msgLen + ", msg body size: " +
bodyLen
+ ", maxMessageSize: " + this.maxMessageSize);
throw new RuntimeException("message size exceeded");
}
// 更新总长度
totalMsgLen += msgLen;
// 如果超过了最大消息大小
if (totalMsgLen > maxMessageSize) {
throw new RuntimeException("message size exceeded");
}
// 初始化内存空间
this.resetByteBuffer(msgStoreItemMemory, msgLen);
// 1 写入长度
msgStoreItemMemory.putInt(msgLen);
// 2 写入魔数
msgStoreItemMemory.putInt(DLedgerCommitLog.MESSAGE_MAGIC_CODE);
// 3 写入CRC校验和
msgStoreItemMemory.putInt(bodyCrc);
// 4 写入QUEUEID
msgStoreItemMemory.putInt(messageExtBatch.getQueueId());
// 5 写入FLAG
msgStoreItemMemory.putInt(flag);
// 6 写入队列偏移量QUEUEOFFSET
msgStoreItemMemory.putLong(0L);
// 7 写入物理偏移量
msgStoreItemMemory.putLong(0);
// 8 写入系统标识SYSFLAG
msgStoreItemMemory.putInt(messageExtBatch.getSysFlag());
// 9 写入消息产生的时间戳
msgStoreItemMemory.putLong(messageExtBatch.getBornTimestamp());
// 10 BORNHOST
resetByteBuffer(bornHostHolder, bornHostLength);
msgStoreItemMemory.put(messageExtBatch.getBornHostBytes(bornHostHolder));
// 11 写入消息存储时间戳
msgStoreItemMemory.putLong(messageExtBatch.getStoreTimestamp());
// 12 STOREHOSTADDRESS
resetByteBuffer(storeHostHolder, storeHostLength);
msgStoreItemMemory.put(messageExtBatch.getStoreHostBytes(storeHostHolder));
// 13 RECONSUMETIMES
msgStoreItemMemory.putInt(messageExtBatch.getReconsumeTimes());
// 14 Prepared Transaction Offset
msgStoreItemMemory.putLong(0);
// 15 写入消息内容长度
msgStoreItemMemory.putInt(bodyLen);
if (bodyLen > 0) {
// 写入消息内容
msgStoreItemMemory.put(messagesByteBuff.array(), bodyPos, bodyLen);
}
// 16 写入主题
msgStoreItemMemory.put((byte) topicLength);
msgStoreItemMemory.put(topicData);
// 17 写入属性长度
msgStoreItemMemory.putShort(propertiesLen);
if (propertiesLen > 0) {
msgStoreItemMemory.put(messagesByteBuff.array(), propertiesPos, propertiesLen);
}
// 创建字节数组
byte[] data = new byte[msgLen];
msgStoreItemMemory.clear();
msgStoreItemMemory.get(data);
// 加入到消息集合
batchBody.add(data);
}
// 返回结果
return new EncodeResult(AppendMessageStatus.PUT_OK, key, batchBody, totalMsgLen);
}
}
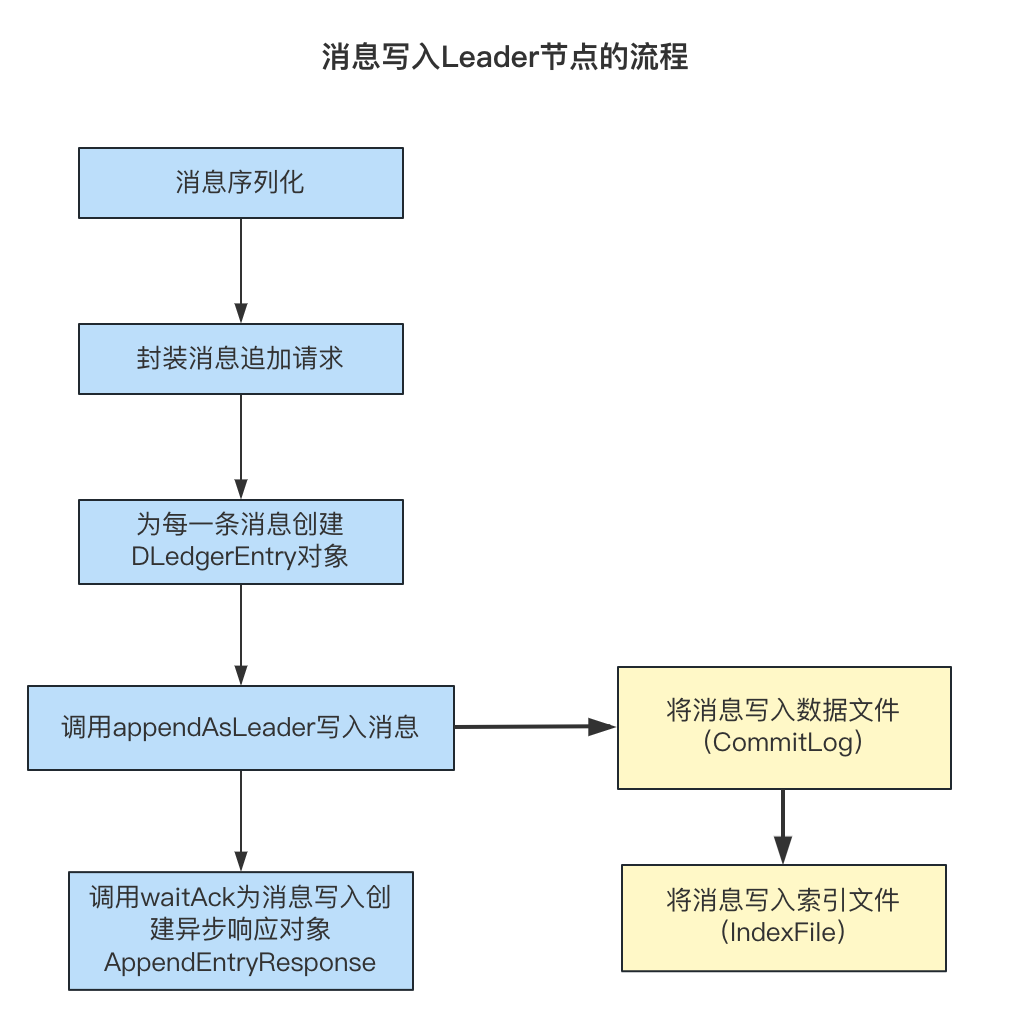
写入消息
将消息数据序列化之后,封装了消息追加请求,调用handleAppend方法写入消息,处理逻辑如下:
- 获取当前的Term,判断当前Term对应的写入请求数量是否超过了最大值,如果未超过进入下一步,如果超过,设置响应状态为
LEADER_PENDING_FULL表示处理的消息追加请求数量过多,拒绝处理当前请求; - 校验是否是批量请求:
- 如果是:遍历每一个消息,为消息创建
DLedgerEntry对象,调用appendAsLeader将消息写入到Leader节点, 并调用waitAck为最后最后一条消息创建异步响应对象; - 如果不是:直接为消息创建
DLedgerEntry对象,调用appendAsLeader将消息写入到Leader节点并调用waitAck创建异步响应对象;
- 如果是:遍历每一个消息,为消息创建
public class DLedgerServer implements DLedgerProtocolHander {
@Override
public CompletableFuture<AppendEntryResponse> handleAppend(AppendEntryRequest request) throws IOException {
try {
PreConditions.check(memberState.getSelfId().equals(request.getRemoteId()), DLedgerResponseCode.UNKNOWN_MEMBER, "%s != %s", request.getRemoteId(), memberState.getSelfId());
PreConditions.check(memberState.getGroup().equals(request.getGroup()), DLedgerResponseCode.UNKNOWN_GROUP, "%s != %s", request.getGroup(), memberState.getGroup());
// 校验是否是Leader节点,如果不是Leader抛出NOT_LEADER异常
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
PreConditions.check(memberState.getTransferee() == null, DLedgerResponseCode.LEADER_TRANSFERRING);
// 获取当前的Term
long currTerm = memberState.currTerm();
// 判断Pengding请求的数量
if (dLedgerEntryPusher.isPendingFull(currTerm)) {
AppendEntryResponse appendEntryResponse = new AppendEntryResponse();
appendEntryResponse.setGroup(memberState.getGroup());
// 设置响应结果LEADER_PENDING_FULL
appendEntryResponse.setCode(DLedgerResponseCode.LEADER_PENDING_FULL.getCode());
// 设置Term
appendEntryResponse.setTerm(currTerm);
appendEntryResponse.setLeaderId(memberState.getSelfId()); // 设置LeaderID
return AppendFuture.newCompletedFuture(-1, appendEntryResponse);
} else {
if (request instanceof BatchAppendEntryRequest) { // 批量
BatchAppendEntryRequest batchRequest = (BatchAppendEntryRequest) request;
if (batchRequest.getBatchMsgs() != null && batchRequest.getBatchMsgs().size() != 0) {
long[] positions = new long[batchRequest.getBatchMsgs().size()];
DLedgerEntry resEntry = null;
int index = 0;
// 遍历每一个消息
Iterator<byte[]> iterator = batchRequest.getBatchMsgs().iterator();
while (iterator.hasNext()) {
// 创建DLedgerEntry
DLedgerEntry dLedgerEntry = new DLedgerEntry();
// 设置消息内容
dLedgerEntry.setBody(iterator.next());
// 写入消息
resEntry = dLedgerStore.appendAsLeader(dLedgerEntry);
positions[index++] = resEntry.getPos();
}
// 为最后一个dLedgerEntry创建异步响应对象
BatchAppendFuture<AppendEntryResponse> batchAppendFuture =
(BatchAppendFuture<AppendEntryResponse>) dLedgerEntryPusher.waitAck(resEntry, true);
batchAppendFuture.setPositions(positions);
return batchAppendFuture;
}
throw new DLedgerException(DLedgerResponseCode.REQUEST_WITH_EMPTY_BODYS, "BatchAppendEntryRequest" +
" with empty bodys");
} else { // 普通消息
DLedgerEntry dLedgerEntry = new DLedgerEntry();
// 设置消息内容
dLedgerEntry.setBody(request.getBody());
// 写入消息
DLedgerEntry resEntry = dLedgerStore.appendAsLeader(dLedgerEntry);
// 等待响应,创建异步响应对象
return dLedgerEntryPusher.waitAck(resEntry, false);
}
}
} catch (DLedgerException e) {
// ...
}
}
}
pendingAppendResponsesByTerm
DLedgerEntryPusher中有一个pendingAppendResponsesByTerm成员变量,KEY为Term的值,VALUE是一个ConcurrentHashMap,ConcurrentHashMap中的KEY为消息的index(每条消息的编号,从0开始,后面会提到),value为此条消息写入请求的异步响应对象AppendEntryResponse:

调用isPendingFull方法的时候,会先校验当前Term是否在pendingAppendResponsesByTerm中有对应的值,如果没有,创建一个ConcurrentHashMap进行初始化,否则获取对应的ConcurrentHashMap里面数据的个数,与MaxPendingRequestsNum做对比,校验是否超过了最大值:
public class DLedgerEntryPusher {
// 外层的KEY为Term的值,value是一个ConcurrentMap
// ConcurrentMap的KEY为消息的index,value为此条消息写入请求的异步响应对象AppendEntryResponse
private Map<Long, ConcurrentMap<Long, TimeoutFuture<AppendEntryResponse>>> pendingAppendResponsesByTerm = new ConcurrentHashMap<>();
public boolean isPendingFull(long currTerm) {
// 校验currTerm是否在pendingAppendResponsesByTerm中
checkTermForPendingMap(currTerm, "isPendingFull");
// 判断当前Term对应的写入请求数量是否超过了最大值
return pendingAppendResponsesByTerm.get(currTerm).size() > dLedgerConfig.getMaxPendingRequestsNum();
}
private void checkTermForPendingMap(long term, String env) {
// 如果pendingAppendResponsesByTerm不包含
if (!pendingAppendResponsesByTerm.containsKey(term)) {
logger.info("Initialize the pending append map in {} for term={}", env, term);
// 创建一个ConcurrentHashMap加入到pendingAppendResponsesByTerm
pendingAppendResponsesByTerm.putIfAbsent(term, new ConcurrentHashMap<>());
}
}
}
pendingAppendResponsesByTerm的值是在什么时候加入的?
在写入Leader节点之后,调用DLedgerEntryPusher的waitAck方法(后面会讲到)的时候,如果集群中有多个节点,会为当前的请求创建AppendFuture<AppendEntryResponse>响应对象加入到pendingAppendResponsesByTerm中,所以可以通过pendingAppendResponsesByTerm中存放的响应对象数量判断当前Term有多少个在等待的写入请求:
// 创建响应对象
AppendFuture<AppendEntryResponse> future;
// 创建AppendFuture
if (isBatchWait) {
// 批量
future = new BatchAppendFuture<>(dLedgerConfig.getMaxWaitAckTimeMs());
} else {
future = new AppendFuture<>(dLedgerConfig.getMaxWaitAckTimeMs());
}
future.setPos(entry.getPos());
// 将创建的AppendFuture对象加入到pendingAppendResponsesByTerm中
CompletableFuture<AppendEntryResponse> old = pendingAppendResponsesByTerm.get(entry.getTerm()).put(entry.getIndex(), future);
写入Leader
DLedgerStore有两个实现类,分别为DLedgerMemoryStore(基于内存存储)和DLedgerMmapFileStore(基于Mmap文件映射):
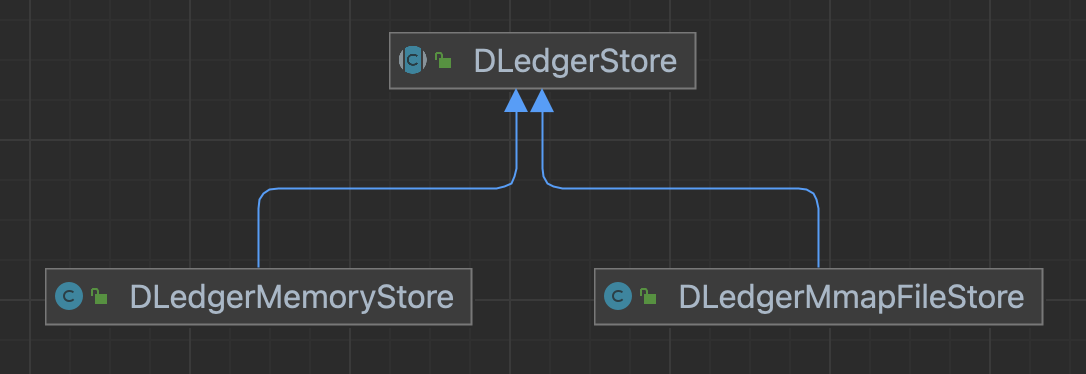
在createDLedgerStore方法中可以看到,是根据配置的存储类型进行选择的:
public class DLedgerServer implements DLedgerProtocolHander {
public DLedgerServer(DLedgerConfig dLedgerConfig) {
this.dLedgerConfig = dLedgerConfig;
this.memberState = new MemberState(dLedgerConfig);
// 根据配置中的StoreType创建DLedgerStore
this.dLedgerStore = createDLedgerStore(dLedgerConfig.getStoreType(), this.dLedgerConfig, this.memberState);
// ...
}
// 创建DLedgerStore
private DLedgerStore createDLedgerStore(String storeType, DLedgerConfig config, MemberState memberState) {
if (storeType.equals(DLedgerConfig.MEMORY)) {
return new DLedgerMemoryStore(config, memberState);
} else {
return new DLedgerMmapFileStore(config, memberState);
}
}
}
appendAsLeader
接下来以DLedgerMmapFileStore为例,看下appendAsLeader的处理逻辑:
-
进行Leader节点校验和磁盘已满校验;
-
获取日志数据buffer(dataBuffer)和索引数据buffer(indexBuffer),会先将内容写入buffer,再将buffer内容写入文件;
-
将entry消息内容写入dataBuffer;
-
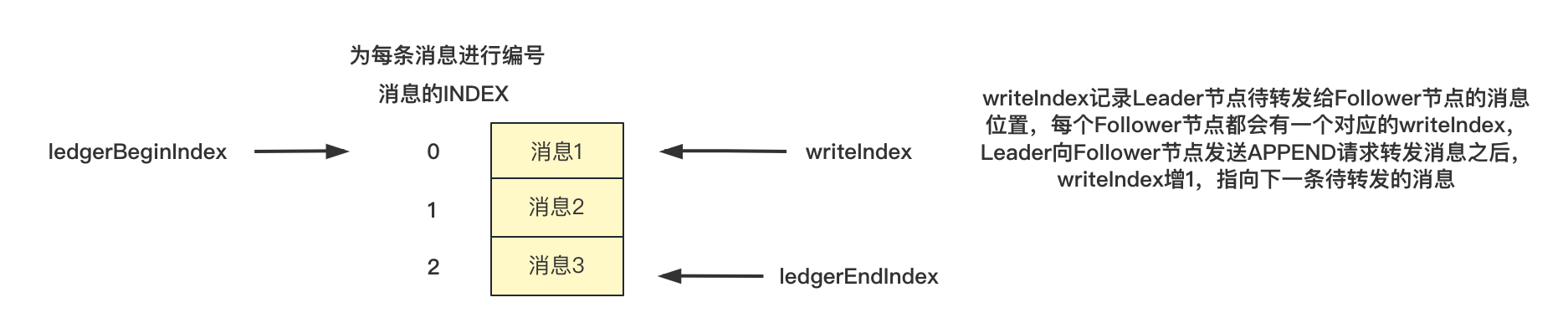
设置消息的index(为每条消息进行了编号),为ledgerEndIndex + 1,ledgerEndIndex初始值为-1,新增一条消息ledgerEndIndex的值也会增1,ledgerEndIndex是随着消息的增加而递增的,写入成功之后会更新ledgerEndIndex的值,ledgerEndIndex记录最后一条成功写入消息的index;
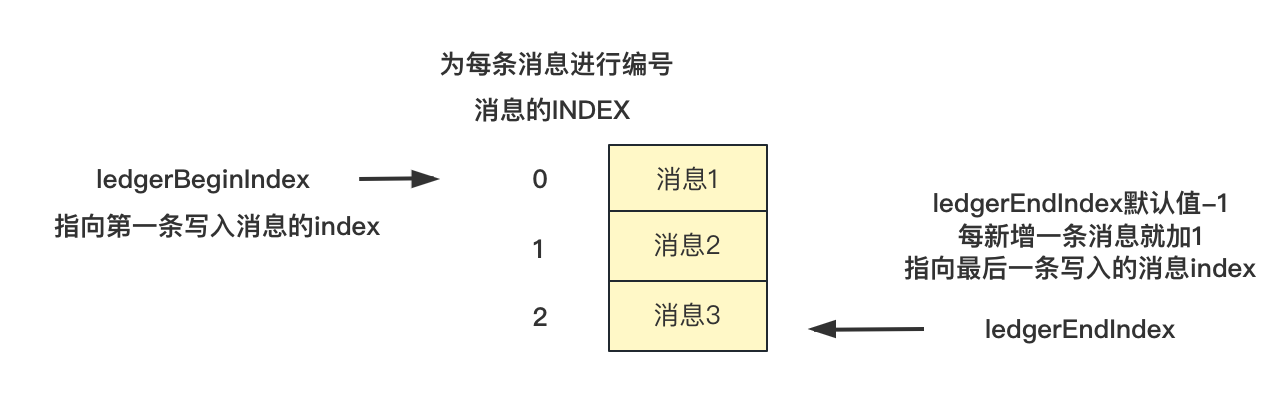
-
调用dataFileList的append方法将dataBuffer内容写入日志文件,返回数据在文件中的偏移量;
-
将索引信息写入indexBuffer;
-
调用indexFileList的append方法将indexBuffer内容写入索引文件;
-
ledgerEndIndex加1;
-
设置ledgerEndTerm的值为当前Term;
-
调用
updateLedgerEndIndexAndTerm方法更新MemberState中记录的LedgerEndIndex和LedgerEndTerm的值,LedgerEndIndex会在FLUSH的时候,将内容写入到文件进行持久化保存。
public class DLedgerMmapFileStore extends DLedgerStore {
// 日志数据buffer
private ThreadLocal<ByteBuffer> localEntryBuffer;
// 索引数据buffer
private ThreadLocal<ByteBuffer> localIndexBuffer;
@Override
public DLedgerEntry appendAsLeader(DLedgerEntry entry) {
// Leader校验判断当前节点是否是Leader
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
// 磁盘是否已满校验
PreConditions.check(!isDiskFull, DLedgerResponseCode.DISK_FULL);
// 获取日志数据buffer
ByteBuffer dataBuffer = localEntryBuffer.get();
// 获取索引数据buffer
ByteBuffer indexBuffer = localIndexBuffer.get();
// 将entry消息内容写入dataBuffer
DLedgerEntryCoder.encode(entry, dataBuffer);
int entrySize = dataBuffer.remaining();
synchronized (memberState) {
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER, null);
PreConditions.check(memberState.getTransferee() == null, DLedgerResponseCode.LEADER_TRANSFERRING, null);
// 设置消息的index,为ledgerEndIndex + 1
long nextIndex = ledgerEndIndex + 1;
// 设置消息的index
entry.setIndex(nextIndex);
// 设置Term
entry.setTerm(memberState.currTerm());
// 设置魔数
entry.setMagic(CURRENT_MAGIC);
// 设置Term的Index
DLedgerEntryCoder.setIndexTerm(dataBuffer, nextIndex, memberState.currTerm(), CURRENT_MAGIC);
long prePos = dataFileList.preAppend(dataBuffer.remaining());
entry.setPos(prePos);
PreConditions.check(prePos != -1, DLedgerResponseCode.DISK_ERROR, null);
DLedgerEntryCoder.setPos(dataBuffer, prePos);
for (AppendHook writeHook : appendHooks) {
writeHook.doHook(entry, dataBuffer.slice(), DLedgerEntry.BODY_OFFSET);
}
// 将dataBuffer内容写入日志文件,返回数据的位置
long dataPos = dataFileList.append(dataBuffer.array(), 0, dataBuffer.remaining());
PreConditions.check(dataPos != -1, DLedgerResponseCode.DISK_ERROR, null);
PreConditions.check(dataPos == prePos, DLedgerResponseCode.DISK_ERROR, null);
// 将索引信息写入indexBuffer
DLedgerEntryCoder.encodeIndex(dataPos, entrySize, CURRENT_MAGIC, nextIndex, memberState.currTerm(), indexBuffer);
// 将indexBuffer内容写入索引文件
long indexPos = indexFileList.append(indexBuffer.array(), 0, indexBuffer.remaining(), false);
PreConditions.check(indexPos == entry.getIndex() * INDEX_UNIT_SIZE, DLedgerResponseCode.DISK_ERROR, null);
if (logger.isDebugEnabled()) {
logger.info("[{}] Append as Leader {} {}", memberState.getSelfId(), entry.getIndex(), entry.getBody().length);
}
// ledgerEndIndex自增
ledgerEndIndex++;
// 设置ledgerEndTerm的值为当前Term
ledgerEndTerm = memberState.currTerm();
if (ledgerBeginIndex == -1) {
// 更新ledgerBeginIndex
ledgerBeginIndex = ledgerEndIndex;
}
// 更新LedgerEndIndex和LedgerEndTerm
updateLedgerEndIndexAndTerm();
return entry;
}
}
}
更新LedgerEndIndex和LedgerEndTerm
在消息写入Leader之后,会调用getLedgerEndIndex和getLedgerEndTerm法获取DLedgerMmapFileStore中记录的LedgerEndIndex和LedgerEndTerm的值,然后更新到MemberState中:
public abstract class DLedgerStore {
protected void updateLedgerEndIndexAndTerm() {
if (getMemberState() != null) {
// 调用MemberState的updateLedgerIndexAndTerm进行更新
getMemberState().updateLedgerIndexAndTerm(getLedgerEndIndex(), getLedgerEndTerm());
}
}
}
public class MemberState {
private volatile long ledgerEndIndex = -1;
private volatile long ledgerEndTerm = -1;
// 更新ledgerEndIndex和ledgerEndTerm
public void updateLedgerIndexAndTerm(long index, long term) {
this.ledgerEndIndex = index;
this.ledgerEndTerm = term;
}
}
waitAck
在消息写入Leader节点之后,由于Leader节点需要向Follwer节点转发日志,这个过程是异步处理的,所以会在waitAck方法中为消息的写入创建异步响应对象,主要处理逻辑如下:
- 调用
updatePeerWaterMark更新水位线,因为Leader节点需要将日志转发给各个Follower,这个水位线其实是记录每个节点消息的复制进度,也就是复制到哪条消息,将消息的index记录下来,这里更新的是Leader节点最新写入消息的index,后面会看到Follower节点的更新; - 如果集群中只有一个节点,创建
AppendEntryResponse返回响应; - 如果集群中有多个节点,由于日志转发是异步进行的,所以创建异步响应对象
AppendFuture<AppendEntryResponse>,并将创建的对象加入到pendingAppendResponsesByTerm中,pendingAppendResponsesByTerm的数据就是在这里加入的;
这里再区分一下pendingAppendResponsesByTerm和peerWaterMarksByTerm:
pendingAppendResponsesByTerm中记录的是每条消息写入请求的异步响应对象AppendEntryResponse,因为要等待集群中大多数节点的响应,所以使用了异步处理,之后获取处理结果。
peerWaterMarksByTerm中记录的是每个节点的消息复制进度,保存的是每个节点最后一条成功写入的消息的index。
public class DLedgerEntryPusher {
public CompletableFuture<AppendEntryResponse> waitAck(DLedgerEntry entry, boolean isBatchWait) {
// 更新当前节点最新写入消息的index
updatePeerWaterMark(entry.getTerm(), memberState.getSelfId(), entry.getIndex());
// 如果集群中只有一个节点
if (memberState.getPeerMap().size() == 1) {
// 创建响应
AppendEntryResponse response = new AppendEntryResponse();
response.setGroup(memberState.getGroup());
response.setLeaderId(memberState.getSelfId());
response.setIndex(entry.getIndex());
response.setTerm(entry.getTerm());
response.setPos(entry.getPos());
if (isBatchWait) {
return BatchAppendFuture.newCompletedFuture(entry.getPos(), response);
}
return AppendFuture.newCompletedFuture(entry.getPos(), response);
} else {
// pendingAppendResponsesByTerm
checkTermForPendingMap(entry.getTerm(), "waitAck");
// 响应对象
AppendFuture<AppendEntryResponse> future;
// 创建AppendFuture
if (isBatchWait) {
// 批量
future = new BatchAppendFuture<>(dLedgerConfig.getMaxWaitAckTimeMs());
} else {
future = new AppendFuture<>(dLedgerConfig.getMaxWaitAckTimeMs());
}
future.setPos(entry.getPos());
// 将创建的AppendFuture对象加入到pendingAppendResponsesByTerm中
CompletableFuture<AppendEntryResponse> old = pendingAppendResponsesByTerm.get(entry.getTerm()).put(entry.getIndex(), future);
if (old != null) {
logger.warn("[MONITOR] get old wait at index={}", entry.getIndex());
}
return future;
}
}
}
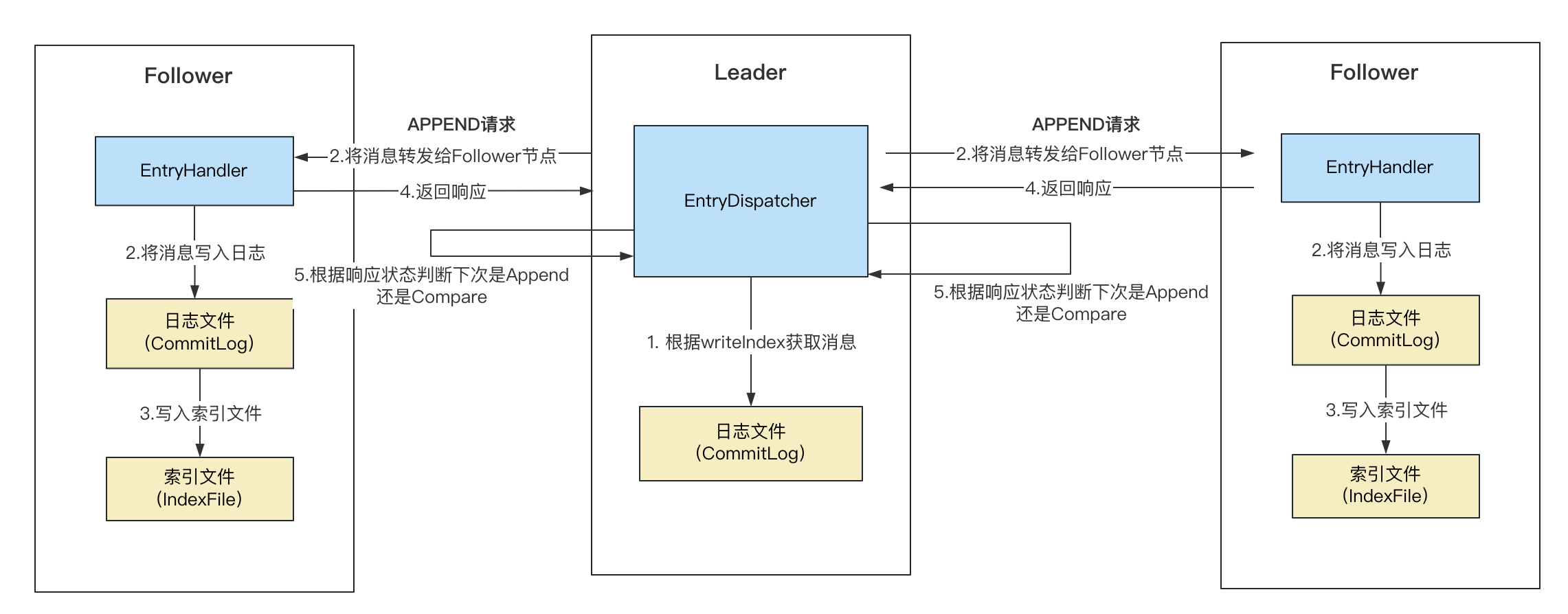
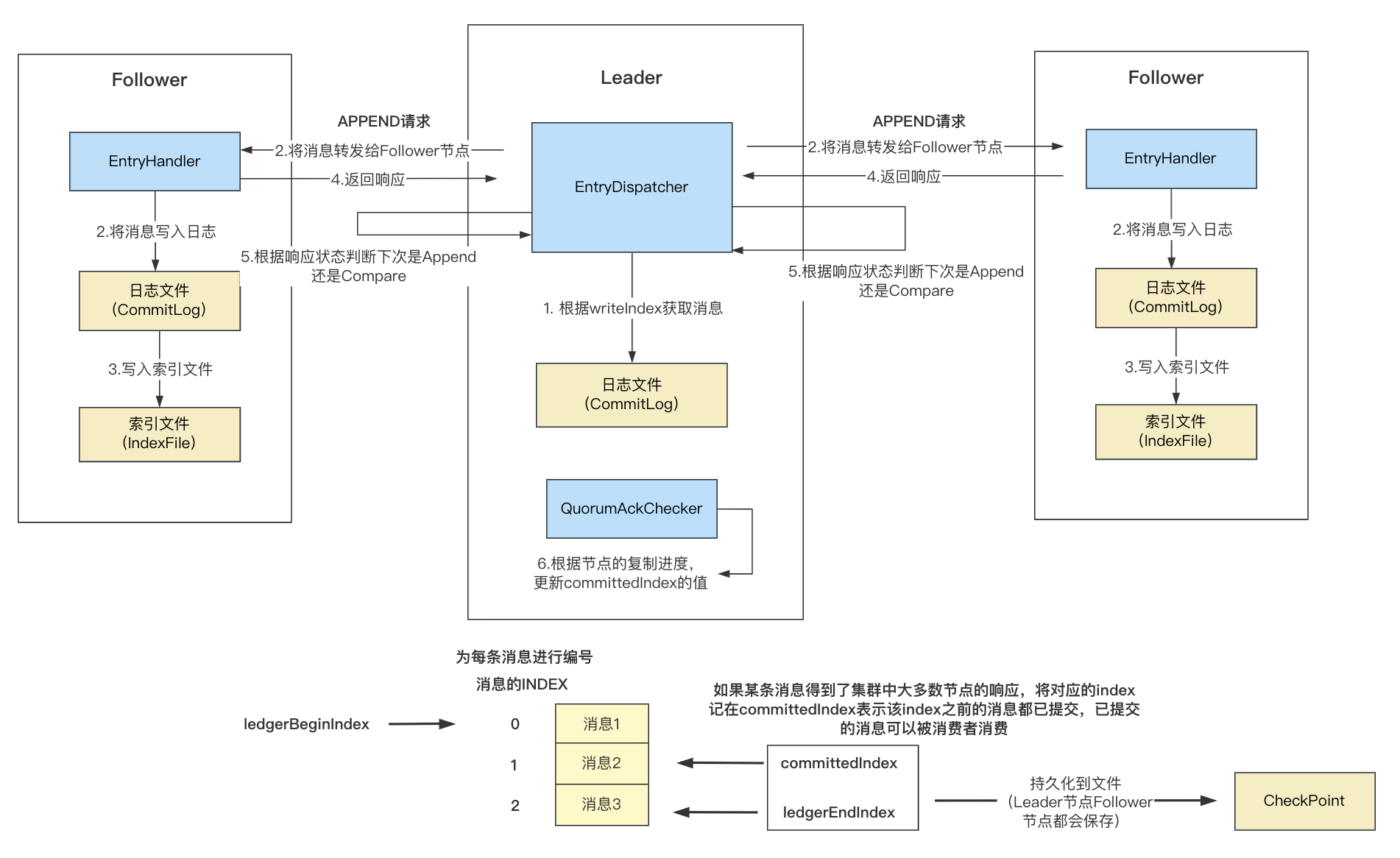
日志复制
消息写入Leader之后,Leader节点会将消息转发给其他Follower节点,这个过程是异步进行处理的,接下来看下消息的复制过程。
在DLedgerEntryPusher的startup方法中会启动以下线程:
EntryDispatcher:用于Leader节点向Follwer节点转发日志;EntryHandler:用于Follower节点处理Leader节点发送的日志;QuorumAckChecker:用于Leader节点等待Follower节点同步;
需要注意的是,Leader节点会为每个Follower节点创建EntryDispatcher转发器,每一个EntryDispatcher负责一个节点的日志转发,多个节点之间是并行处理的。
public class DLedgerEntryPusher {
public DLedgerEntryPusher(DLedgerConfig dLedgerConfig, MemberState memberState, DLedgerStore dLedgerStore,
DLedgerRpcService dLedgerRpcService) {
this.dLedgerConfig = dLedgerConfig;
this.memberState = memberState;
this.dLedgerStore = dLedgerStore;
this.dLedgerRpcService = dLedgerRpcService;
for (String peer : memberState.getPeerMap().keySet()) {
if (!peer.equals(memberState.getSelfId())) {
// 为集群中除当前节点以外的其他节点创建EntryDispatcher
dispatcherMap.put(peer, new EntryDispatcher(peer, logger));
}
}
// 创建EntryHandler
this.entryHandler = new EntryHandler(logger);
// 创建QuorumAckChecker
this.quorumAckChecker = new QuorumAckChecker(logger);
}
public void startup() {
// 启动EntryHandler
entryHandler.start();
// 启动QuorumAckChecker
quorumAckChecker.start();
// 启动EntryDispatcher
for (EntryDispatcher dispatcher : dispatcherMap.values()) {
dispatcher.start();
}
}
}
EntryDispatcher(日志转发)
EntryDispatcher用于Leader节点向Follower转发日志,它继承了ShutdownAbleThread,所以会启动线程处理日志转发,入口在doWork方法中。
在doWork方法中,首先调用checkAndFreshState校验节点的状态,这一步主要是校验当前节点是否是Leader节点以及更改消息的推送类型,如果不是Leader节点结束处理,如果是Leader节点,对消息的推送类型进行判断:
APPEND:消息追加,用于向Follower转发消息,批量消息调用doBatchAppend,否则调用doAppend处理;COMPARE:消息对比,一般出现在数据不一致的情况下,此时调用doCompare对比消息;
public class DLedgerEntryPusher {
// 日志转发线程
private class EntryDispatcher extends ShutdownAbleThread {
@Override
public void doWork() {
try {
// 检查状态
if (!checkAndFreshState()) {
waitForRunning(1);
return;
}
// 如果是APPEND类型
if (type.get() == PushEntryRequest.Type.APPEND) {
// 如果开启了批量追加
if (dLedgerConfig.isEnableBatchPush()) {
doBatchAppend();
} else {
doAppend();
}
} else {
// 比较
doCompare();
}
Thread.yield();
} catch (Throwable t) {
DLedgerEntryPusher.logger.error("[Push-{}]Error in {} writeIndex={} compareIndex={}", peerId, getName(), writeIndex, compareIndex, t);
// 出现异常转为COMPARE
changeState(-1, PushEntryRequest.Type.COMPARE);
DLedgerUtils.sleep(500);
}
}
}
}
状态检查(checkAndFreshState)
如果Term与memberState记录的不一致或者LeaderId为空或者LeaderId与memberState的不一致,会调用changeState方法,将消息的推送类型更改为COMPARE,并将compareIndex置为-1:
public class DLedgerEntryPusher {
private class EntryDispatcher extends ShutdownAbleThread {
private long term = -1;
private String leaderId = null;
private boolean checkAndFreshState() {
// 如果不是Leader节点
if (!memberState.isLeader()) {
return false;
}
// 如果Term与memberState记录的不一致或者LeaderId为空或者LeaderId与memberState的不一致
if (term != memberState.currTerm() || leaderId == null || !leaderId.equals(memberState.getLeaderId())) {
synchronized (memberState) { // 加锁
if (!memberState.isLeader()) {
return false;
}
PreConditions.check(memberState.getSelfId().equals(memberState.getLeaderId()), DLedgerResponseCode.UNKNOWN);
term = memberState.currTerm();
leaderId = memberState.getSelfId();
// 更改状态为COMPARE
changeState(-1, PushEntryRequest.Type.COMPARE);
}
}
return true;
}
private synchronized void changeState(long index, PushEntryRequest.Type target) {
logger.info("[Push-{}]Change state from {} to {} at {}", peerId, type.get(), target, index);
switch (target) {
case APPEND:
compareIndex = -1;
updatePeerWaterMark(term, peerId, index);
quorumAckChecker.wakeup();
writeIndex = index + 1;
if (dLedgerConfig.isEnableBatchPush()) {
resetBatchAppendEntryRequest();
}
break;
case COMPARE:
// 如果设置COMPARE状态成功
if (this.type.compareAndSet(PushEntryRequest.Type.APPEND, PushEntryRequest.Type.COMPARE)) {
compareIndex = -1; // compareIndex改为-1
if (dLedgerConfig.isEnableBatchPush()) {
batchPendingMap.clear();
} else {
pendingMap.clear();
}
}
break;
case TRUNCATE:
compareIndex = -1;
break;
default:
break;
}
type.set(target);
}
}
}
Leader节点消息转发
如果处于APPEND状态,Leader节点会向Follower节点发送Append请求,将消息转发给Follower节点,doAppend方法的处理逻辑如下:
-
调用
checkAndFreshState进行状态检查; -
判断推送类型是否是
APPEND,如果不是终止处理; -
writeIndex为待转发消息的Index,默认值为-1,判断是否大于LedgerEndIndex,如果大于调用doCommit向Follower节点发送COMMIT请求更新committedIndex(后面再说);
这里可以看出转发日志的时候也使用了一个计数器writeIndex来记录待转发消息的index,每次根据writeIndex的值从日志中取出消息进行转发,转发成后更新writeIndex的值(自增)指向下一条数据。
-
如果pendingMap中的大小超过了最大限制maxPendingSize的值,或者上次检查时间超过了1000ms(有较长的时间未进行清理),进行过期数据清理(这一步主要就是为了清理数据):
pendingMap是一个ConcurrentMap,KEY为消息的INDEX,value为该条消息向Follwer节点转发的时间(doAppendInner方法中会将数据加入到pendingMap);
- 前面知道peerWaterMark的数据记录了每个节点的消息复制进度,这里根据Term和节点ID获取对应的复制进度(最新复制成功的消息的index)记在peerWaterMark变量中;
- 遍历pendingMap,与peerWaterMark的值对比,peerWaterMark之前的消息表示都已成功的写入完毕,所以小于peerWaterMark说明已过期可以被清理掉,将数据从pendingMap移除达到清理空间的目的;
- 更新检查时间lastCheckLeakTimeMs的值为当前时间;
-
调用
doAppendInner方法转发消息; -
更新writeIndex的值,做自增操作指向下一条待转发的消息index;
public class DLedgerEntryPusher {
private class EntryDispatcher extends ShutdownAbleThread {
// 待转发消息的Index,默认值为-1
private long writeIndex = -1;
// KEY为消息的INDEX,value为该条消息向Follwer节点转发的时间
private ConcurrentMap<Long, Long> pendingMap = new ConcurrentHashMap<>();
private void doAppend() throws Exception {
while (true) {
// 校验状态
if (!checkAndFreshState()) {
break;
}
// 如果不是APPEND状态,终止
if (type.get() != PushEntryRequest.Type.APPEND) {
break;
}
// 判断待转发消息的Index是否大于LedgerEndIndex
if (writeIndex > dLedgerStore.getLedgerEndIndex()) {
doCommit(); // 向Follower节点发送COMMIT请求更新
doCheckAppendResponse();
break;
}
// 如果pendingMap中的大小超过了maxPendingSize,或者上次检查时间超过了1000ms
if (pendingMap.size() >= maxPendingSize || (DLedgerUtils.elapsed(lastCheckLeakTimeMs) > 1000)) {
// 根据节点peerId获取复制进度
long peerWaterMark = getPeerWaterMark(term, peerId);
// 遍历pendingMap
for (Long index : pendingMap.keySet()) {
// 如果index小于peerWaterMark
if (index < peerWaterMark) {
// 移除
pendingMap.remove(index);
}
}
// 更新检查时间
lastCheckLeakTimeMs = System.currentTimeMillis();
}
if (pendingMap.size() >= maxPendingSize) {
doCheckAppendResponse();
break;
}
// 同步消息
doAppendInner(writeIndex);
// 更新writeIndex的值
writeIndex++;
}
}
}
}
getPeerWaterMark
peerWaterMarksByTerm
peerWaterMarksByTerm中记录了日志转发的进度,KEY为Term,VALUE为ConcurrentMap,ConcurrentMap中的KEY为Follower节点的ID(peerId),VALUE为该节点已经同步完毕的最新的那条消息的index:
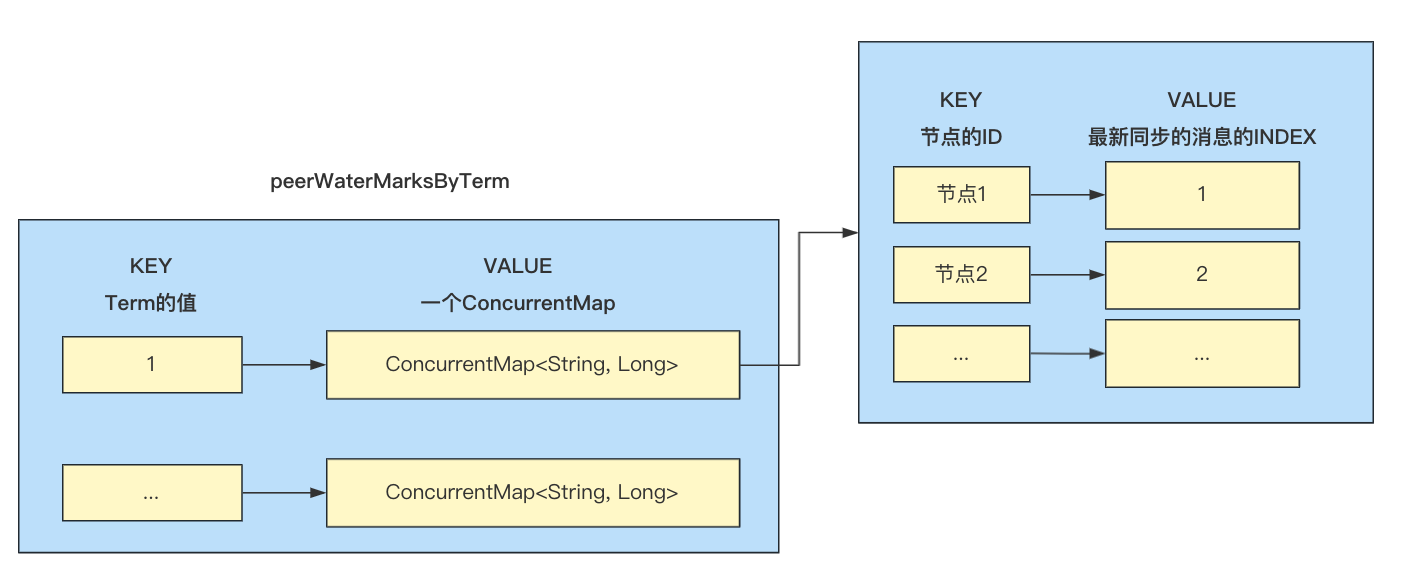
调用getPeerWaterMark方法的时候,首先会调用checkTermForWaterMark检查peerWaterMarksByTerm是否存在数据,如果不存在, 创建ConcurrentMap,并遍历集群中的节点,加入到ConcurrentMap,其中KEY为节点的ID,value为默认值-1,当消息成功写入Follower节点后,会调用updatePeerWaterMark更同步进度:
public class DLedgerEntryPusher {
// 记录Follower节点的同步进度,KEY为Term,VALUE为ConcurrentMap
// ConcurrentMap中的KEY为Follower节点的ID(peerId),VALUE为该节点已经同步完毕的最新的那条消息的index
private Map<Long, ConcurrentMap<String, Long>> peerWaterMarksByTerm = new ConcurrentHashMap<>();
// 获取节点的同步进度
public long getPeerWaterMark(long term, String peerId) {
synchronized (peerWaterMarksByTerm) {
checkTermForWaterMark(term, "getPeerWaterMark");
return peerWaterMarksByTerm.get(term).get(peerId);
}
}
private void checkTermForWaterMark(long term, String env) {
// 如果peerWaterMarksByTerm不存在
if (!peerWaterMarksByTerm.containsKey(term)) {
logger.info("Initialize the watermark in {} for term={}", env, term);
// 创建ConcurrentMap
ConcurrentMap<String, Long> waterMarks = new ConcurrentHashMap<>();
// 对集群中的节点进行遍历
for (String peer : memberState.getPeerMap().keySet()) {
// 初始化,KEY为节点的PEER,VALUE为-1
waterMarks.put(peer, -1L);
}
// 加入到peerWaterMarksByTerm
peerWaterMarksByTerm.putIfAbsent(term, waterMarks);
}
}
// 更新水位线
private void updatePeerWaterMark(long term, String peerId, long index) {
synchronized (peerWaterMarksByTerm) {
// 校验
checkTermForWaterMark(term, "updatePeerWaterMark");
// 如果之前的水位线小于当前的index进行更新
if (peerWaterMarksByTerm.get(term).get(peerId) < index) {
peerWaterMarksByTerm.get(term).put(peerId, index);
}
}
}
}
转发消息
doAppendInner的处理逻辑如下:
- 根据消息的index从日志获取消息Entry;
- 调用buildPushRequest方法构建日志转发请求PushEntryRequest,**在请求中设置了消息entry、当前Term、Leader节点的commitIndex(最后一条得到集群中大多数节点响应的消息index)**等信息;
- 调用dLedgerRpcService的push方法将请求发送给Follower节点;
- 将本条消息对应的index加入到pendingMap中记录消息的发送时间(key为消息的index,value为当前时间);
- 等待Follower节点返回响应:
(1)如果响应状态为SUCCESS, 表示节点写入成功:- 从pendingMap中移除本条消息index的信息;
- 更新当前节点的复制进度,也就是updatePeerWaterMark中的值;
- 调用quorumAckChecker的wakeup,唤醒QuorumAckChecker线程;
(2)如果响应状态为INCONSISTENT_STATE,表示Follower节点数据出现了不一致的情况,需要调用changeState更改状态为COMPARE;
private class EntryDispatcher extends ShutdownAbleThread {
private void doAppendInner(long index) throws Exception {
// 根据index从日志获取消息Entry
DLedgerEntry entry = getDLedgerEntryForAppend(index);
if (null == entry) {
return;
}
checkQuotaAndWait(entry);
// 构建日志转发请求PushEntryRequest
PushEntryRequest request = buildPushRequest(entry, PushEntryRequest.Type.APPEND);
// 添加日志转发请求,发送给Follower节点
CompletableFuture<PushEntryResponse> responseFuture = dLedgerRpcService.push(request);
// 加入到pendingMap中,key为消息的index,value为当前时间
pendingMap.put(index, System.currentTimeMillis());
responseFuture.whenComplete((x, ex) -> {
try {
// 处理请求响应
PreConditions.check(ex == null, DLedgerResponseCode.UNKNOWN);
DLedgerResponseCode responseCode = DLedgerResponseCode.valueOf(x.getCode());
switch (responseCode) {
case SUCCESS: // 如果成功
// 从pendingMap中移除
pendingMap.remove(x.getIndex());
// 更新updatePeerWaterMark
updatePeerWaterMark(x.getTerm(), peerId, x.getIndex());
// 唤醒
quorumAckChecker.wakeup();
break;
case INCONSISTENT_STATE: // 如果响应状态为INCONSISTENT_STATE
logger.info("[Push-{}]Get INCONSISTENT_STATE when push index={} term={}", peerId, x.getIndex(), x.getTerm());
changeState(-1, PushEntryRequest.Type.COMPARE); // 转为COMPARE状态
break;
default:
logger.warn("[Push-{}]Get error response code {} {}", peerId, responseCode, x.baseInfo());
break;
}
} catch (Throwable t) {
logger.error("", t);
}
});
lastPushCommitTimeMs = System.currentTimeMillis();
}
private PushEntryRequest buildPushRequest(DLedgerEntry entry, PushEntryRequest.Type target) {
PushEntryRequest request = new PushEntryRequest(); // 创建PushEntryRequest
request.setGroup(memberState.getGroup());
request.setRemoteId(peerId);
request.setLeaderId(leaderId);
// 设置Term
request.setTerm(term);
// 设置消息
request.setEntry(entry);
request.setType(target);
// 设置commitIndex,最后一条得到集群中大多数节点响应的消息index
request.setCommitIndex(dLedgerStore.getCommittedIndex());
return request;
}
}
为了便于将Leader节点的转发和Follower节点的处理逻辑串起来,这里添加了Follower对APPEND请求的处理链接,Follower处理APPEND请求。
Leader节点消息比较
处于以下两种情况之一时,会认为数据出现了不一致的情况,将状态更改为Compare:
(1)Leader节点在调用checkAndFreshState检查的时候,发现当前Term与memberState记录的不一致或者LeaderId为空或者LeaderId与memberState记录的LeaderId不一致;
(2)Follower节点在处理消息APPEND请求在进行校验的时候(Follower节点请求校验链接),发现数据出现了不一致,会在请求的响应中设置不一致的状态INCONSISTENT_STATE,通知Leader节点;
在COMPARE状态下,会调用doCompare方法向Follower节点发送比较请求,处理逻辑如下:
- 调用
checkAndFreshState校验状态; - 判断是否是
COMPARE或者TRUNCATE请求,如果不是终止处理; - 如果compareIndex为-1(changeState方法将状态改为COMPARE时中会将compareIndex置为-1),获取LedgerEndIndex作为compareIndex的值进行更新;
- 如果compareIndex的值大于LedgerEndIndex或者小于LedgerBeginIndex,依旧使用LedgerEndIndex作为compareIndex的值,所以单独加一个判断条件应该是为了打印日志,与第3步做区分;
- 根据compareIndex获取消息entry对象,调用buildPushRequest方法构建COMPARE请求;
- 向Follower节点推送建COMPARE请求进行比较,这里可以快速跳转到Follwer节点对COMPARE请求的处理;
状态更改为COMPARE之后,compareIndex的值会被初始化为-1,在doCompare中,会将compareIndex的值更改为Leader节点的最后一条写入的消息,也就是LedgerEndIndex的值,发给Follower节点进行对比。
向Follower节点发起请求后,等待COMPARE请求返回响应,请求中会将Follower节点最后成功写入的消息的index设置在响应对象的EndIndex变量中,第一条写入的消息记录在BeginIndex变量中:
-
请求响应成功:
- 如果compareIndex与follower返回请求中的EndIndex相等,表示没有数据不一致的情况,将状态更改为APPEND;
- 其他情况,将truncateIndex的值置为compareIndex;
-
如果请求中返回的EndIndex小于当前节点的LedgerBeginIndex,或者BeginIndex大于LedgerEndIndex,也就是follower与leader的index不相交时, 将truncateIndex设置为Leader的BeginIndex;
根据代码中的注释来看,这种情况通常发生在Follower节点出现故障了很长一段时间,在此期间Leader节点删除了一些过期的消息;
-
compareIndex比follower的BeginIndex小,将truncateIndex设置为Leader的BeginIndex;
根据代码中的注释来看,这种情况请通常发生在磁盘出现故障的时候。
-
其他情况,将compareIndex的值减一,从上一条消息开始继续对比;
-
如果truncateIndex的值不为-1,调用doTruncate方法进行处理;
public class DLedgerEntryPusher {
private class EntryDispatcher extends ShutdownAbleThread {
private void doCompare() throws Exception {
while (true) {
// 校验状态
if (!checkAndFreshState()) {
break;
}
// 如果不是COMPARE请求也不是TRUNCATE请求
if (type.get() != PushEntryRequest.Type.COMPARE
&& type.get() != PushEntryRequest.Type.TRUNCATE) {
break;
}
// 如果compareIndex为-1并且LedgerEndIndex为-1
if (compareIndex == -1 && dLedgerStore.getLedgerEndIndex() == -1) {
break;
}
// 如果compareIndex为-1
if (compareIndex == -1) {
// 获取LedgerEndIndex作为compareIndex
compareIndex = dLedgerStore.getLedgerEndIndex();
logger.info("[Push-{}][DoCompare] compareIndex=-1 means start to compare", peerId);
} else if (compareIndex > dLedgerStore.getLedgerEndIndex() || compareIndex < dLedgerStore.getLedgerBeginIndex()) {
logger.info("[Push-{}][DoCompare] compareIndex={} out of range {}-{}", peerId, compareIndex, dLedgerStore.getLedgerBeginIndex(), dLedgerStore.getLedgerEndIndex());
// 依旧获取LedgerEndIndex作为compareIndex,这里应该是为了打印日志所以单独又加了一个if条件
compareIndex = dLedgerStore.getLedgerEndIndex();
}
// 根据compareIndex获取消息
DLedgerEntry entry = dLedgerStore.get(compareIndex);
PreConditions.check(entry != null, DLedgerResponseCode.INTERNAL_ERROR, "compareIndex=%d", compareIndex);
// 构建COMPARE请求
PushEntryRequest request = buildPushRequest(entry, PushEntryRequest.Type.COMPARE);
// 发送COMPARE请求
CompletableFuture<PushEntryResponse> responseFuture = dLedgerRpcService.push(request);
// 获取响应结果
PushEntryResponse response = responseFuture.get(3, TimeUnit.SECONDS);
PreConditions.check(response != null, DLedgerResponseCode.INTERNAL_ERROR, "compareIndex=%d", compareIndex);
PreConditions.check(response.getCode() == DLedgerResponseCode.INCONSISTENT_STATE.getCode() || response.getCode() == DLedgerResponseCode.SUCCESS.getCode()
, DLedgerResponseCode.valueOf(response.getCode()), "compareIndex=%d", compareIndex);
long truncateIndex = -1;
// 如果返回成功
if (response.getCode() == DLedgerResponseCode.SUCCESS.getCode()) {
// 如果compareIndex与 follower的EndIndex相等
if (compareIndex == response.getEndIndex()) {
// 改为APPEND状态
changeState(compareIndex, PushEntryRequest.Type.APPEND);
break;
} else {
// 将truncateIndex设置为compareIndex
truncateIndex = compareIndex;
}
} else if (response.getEndIndex() < dLedgerStore.getLedgerBeginIndex()
|| response.getBeginIndex() > dLedgerStore.getLedgerEndIndex()) {
/*
The follower's entries does not intersect with the leader.
This usually happened when the follower has crashed for a long time while the leader has deleted the expired entries.
Just truncate the follower.
*/
// 如果请求中返回的EndIndex小于当前节点的LedgerBeginIndex,或者BeginIndex大于LedgerEndIndex
// 当follower与leader的index不相交时,这种情况通常Follower节点出现故障了很长一段时间,在此期间Leader节点删除了一些过期的消息
// 将truncateIndex设置为Leader的BeginIndex
truncateIndex = dLedgerStore.getLedgerBeginIndex();
} else if (compareIndex < response.getBeginIndex()) {
/*
The compared index is smaller than the follower's begin index.
This happened rarely, usually means some disk damage.
Just truncate the follower.
*/
// compareIndex比follower的BeginIndex小,通常发生在磁盘出现故障的时候
// 将truncateIndex设置为Leader的BeginIndex
truncateIndex = dLedgerStore.getLedgerBeginIndex();
} else if (compareIndex > response.getEndIndex()) {
/*
The compared index is bigger than the follower's end index.
This happened frequently. For the compared index is usually starting from the end index of the leader.
*/
// compareIndex比follower的EndIndex大
// compareIndexx设置为Follower的EndIndex
compareIndex = response.getEndIndex();
} else {
/*
Compare failed and the compared index is in the range of follower's entries.
*/
// 比较失败
compareIndex--;
}
// 如果compareIndex比当前节点的LedgerBeginIndex小
if (compareIndex < dLedgerStore.getLedgerBeginIndex()) {
truncateIndex = dLedgerStore.getLedgerBeginIndex();
}
// 如果truncateIndex的值不为-1,调用doTruncate开始删除
if (truncateIndex != -1) {
changeState(truncateIndex, PushEntryRequest.Type.TRUNCATE);
doTruncate(truncateIndex);
break;
}
}
}
}
}
在doTruncate方法中,会构建TRUNCATE请求设置truncateIndex(要删除的消息的index),发送给Follower节点,通知Follower节点将数据不一致的那条消息删除,如果响应成功,可以看到接下来调用了changeState将状态改为APPEND,在changeState中,调用了updatePeerWaterMark更新节点的复制进度为出现数据不一致的那条消息的index,同时也更新了writeIndex,下次从writeIndex处重新给Follower节点发送APPEND请求进行消息写入:
private class EntryDispatcher extends ShutdownAbleThread {
private void doTruncate(long truncateIndex) throws Exception {
PreConditions.check(type.get() == PushEntryRequest.Type.TRUNCATE, DLedgerResponseCode.UNKNOWN);
DLedgerEntry truncateEntry = dLedgerStore.get(truncateIndex);
PreConditions.check(truncateEntry != null, DLedgerResponseCode.UNKNOWN);
logger.info("[Push-{}]Will push data to truncate truncateIndex={} pos={}", peerId, truncateIndex, truncateEntry.getPos());
// 构建TRUNCATE请求
PushEntryRequest truncateRequest = buildPushRequest(truncateEntry, PushEntryRequest.Type.TRUNCATE);
// 向Folower节点发送TRUNCATE请求
PushEntryResponse truncateResponse = dLedgerRpcService.push(truncateRequest).get(3, TimeUnit.SECONDS);
PreConditions.check(truncateResponse != null, DLedgerResponseCode.UNKNOWN, "truncateIndex=%d", truncateIndex);
PreConditions.check(truncateResponse.getCode() == DLedgerResponseCode.SUCCESS.getCode(), DLedgerResponseCode.valueOf(truncateResponse.getCode()), "truncateIndex=%d", truncateIndex);
lastPushCommitTimeMs = System.currentTimeMillis();
// 更改回APPEND状态
changeState(truncateIndex, PushEntryRequest.Type.APPEND);
}
private synchronized void changeState(long index, PushEntryRequest.Type target) {
logger.info("[Push-{}]Change state from {} to {} at {}", peerId, type.get(), target, index);
switch (target) {
case APPEND:
compareIndex = -1;
// 更新节点的复制进度,改为出现数据不一致的那条消息的index
updatePeerWaterMark(term, peerId, index);
// 唤醒quorumAckChecker
quorumAckChecker.wakeup();
// 更新writeIndex
writeIndex = index + 1;
if (dLedgerConfig.isEnableBatchPush()) {
resetBatchAppendEntryRequest();
}
break;
// ...
}
type.set(target);
}
}
EntryHandler
EntryHandler用于Follower节点处理Leader发送的消息请求,对请求的处理在handlePush方法中,根据请求类型的不同做如下处理:
- 如果是
APPEND请求,将请求加入到writeRequestMap中; - 如果是
COMMIT请求,将请求加入到compareOrTruncateRequests; - 如果是
COMPARE或者TRUNCATE,将请求加入到compareOrTruncateRequests;
handlePush方法中,并没有直接处理请求,而是将不同类型的请求加入到不同的请求集合中,请求的处理是另外一个线程在doWork方法中处理的。
public class DLedgerEntryPusher {
private class EntryHandler extends ShutdownAbleThread {
ConcurrentMap<Long, Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>>> writeRequestMap = new ConcurrentHashMap<>();
BlockingQueue<Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>>> compareOrTruncateRequests = new ArrayBlockingQueue<Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>>>(100);
public CompletableFuture<PushEntryResponse> handlePush(PushEntryRequest request) throws Exception {
CompletableFuture<PushEntryResponse> future = new TimeoutFuture<>(1000);
switch (request.getType()) {
case APPEND: // 如果是Append
if (request.isBatch()) {
PreConditions.check(request.getBatchEntry() != null && request.getCount() > 0, DLedgerResponseCode.UNEXPECTED_ARGUMENT);
} else {
PreConditions.check(request.getEntry() != null, DLedgerResponseCode.UNEXPECTED_ARGUMENT);
}
long index = request.getFirstEntryIndex();
// 将请求加入到writeRequestMap
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> old = writeRequestMap.putIfAbsent(index, new Pair<>(request, future));
if (old != null) {
logger.warn("[MONITOR]The index {} has already existed with {} and curr is {}", index, old.getKey().baseInfo(), request.baseInfo());
future.complete(buildResponse(request, DLedgerResponseCode.REPEATED_PUSH.getCode()));
}
break;
case COMMIT: // 如果是提交
// 加入到compareOrTruncateRequests
compareOrTruncateRequests.put(new Pair<>(request, future));
break;
case COMPARE:
case TRUNCATE:
PreConditions.check(request.getEntry() != null, DLedgerResponseCode.UNEXPECTED_ARGUMENT);
writeRequestMap.clear();
// 加入到compareOrTruncateRequests
compareOrTruncateRequests.put(new Pair<>(request, future));
break;
default:
logger.error("[BUG]Unknown type {} from {}", request.getType(), request.baseInfo());
future.complete(buildResponse(request, DLedgerResponseCode.UNEXPECTED_ARGUMENT.getCode()));
break;
}
wakeup();
return future;
}
}
}
EntryHandler同样继承了ShutdownAbleThread,所以会启动线程执行doWork方法,在doWork方法中对请求进行了处理:
-
如果compareOrTruncateRequests不为空,对请求类型进行判断:
- TRUNCATE:调用handleDoTruncate处理;
- COMPARE:调用handleDoCompare处理;
- COMMIT:调用handleDoCommit处理;
-
如果不是第1种情况,会认为是APPEND请求:
(1)LedgerEndIndex记录了最后一条成功写入消息的index,对其 + 1表示下一条待写入消息的index;
(2)根据待写入消息的index从writeRequestMap获取数据,如果获取为空,调用checkAbnormalFuture进行检查;
(3)获取不为空,调用handleDoAppend方法处理消息写入;
这里可以看出,Follower是从当前记录的最后一条成功写入的index(LedgerEndIndex),进行加1来处理下一条需要写入的消息的。
public class DLedgerEntryPusher {
private class EntryHandler extends ShutdownAbleThread {
@Override
public void doWork() {
try {
// 判断是否是Follower
if (!memberState.isFollower()) {
waitForRunning(1);
return;
}
// 如果compareOrTruncateRequests不为空
if (compareOrTruncateRequests.peek() != null) {
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = compareOrTruncateRequests.poll();
PreConditions.check(pair != null, DLedgerResponseCode.UNKNOWN);
switch (pair.getKey().getType()) {
case TRUNCATE: // TRUNCATE
handleDoTruncate(pair.getKey().getEntry().getIndex(), pair.getKey(), pair.getValue());
break;
case COMPARE: // COMPARE
handleDoCompare(pair.getKey().getEntry().getIndex(), pair.getKey(), pair.getValue());
break;
case COMMIT: // COMMIT
handleDoCommit(pair.getKey().getCommitIndex(), pair.getKey(), pair.getValue());
break;
default:
break;
}
} else {
// 设置消息Index,为最后一条成功写入的消息index + 1
long nextIndex = dLedgerStore.getLedgerEndIndex() + 1;
// 从writeRequestMap取出请求
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.remove(nextIndex);
// 如果获取的请求为空,调用checkAbnormalFuture进行检查
if (pair == null) {
checkAbnormalFuture(dLedgerStore.getLedgerEndIndex());
waitForRunning(1);
return;
}
PushEntryRequest request = pair.getKey();
if (request.isBatch()) {
handleDoBatchAppend(nextIndex, request, pair.getValue());
} else {
// 处理
handleDoAppend(nextIndex, request, pair.getValue());
}
}
} catch (Throwable t) {
DLedgerEntryPusher.logger.error("Error in {}", getName(), t);
DLedgerUtils.sleep(100);
}
}
}
Follower数据不一致检查
checkAbnormalFuture
方法用于检查数据的一致性,处理逻辑如下:-
如果距离上次检查的时间未超过1000ms,直接返回;
-
更新检查时间lastCheckFastForwardTimeMs的值;
-
如果writeRequestMap为空表示目前没有写入请求,暂不需要处理;
-
调用
checkAppendFuture方法进行检查;
public class DLedgerEntryPusher {
private class EntryHandler extends ShutdownAbleThread {
/**
* The leader does push entries to follower, and record the pushed index. But in the following conditions, the push may get stopped.
* * If the follower is abnormally shutdown, its ledger end index may be smaller than before. At this time, the leader may push fast-forward entries, and retry all the time.
* * If the last ack is missed, and no new message is coming in.The leader may retry push the last message, but the follower will ignore it.
* @param endIndex
*/
private void checkAbnormalFuture(long endIndex) {
// 如果距离上次检查的时间未超过1000ms
if (DLedgerUtils.elapsed(lastCheckFastForwardTimeMs) < 1000) {
return;
}
// 更新检查时间
lastCheckFastForwardTimeMs = System.currentTimeMillis();
// 如果writeRequestMap表示没有写入请求,暂不需要处理
if (writeRequestMap.isEmpty()) {
return;
}
// 检查
checkAppendFuture(endIndex);
}
}
}
checkAppendFuture方法中的入参endIndex,表示当前待写入消息的index,也就是当前节点记录的最后一条成功写入的index(LedgerEndIndex)值加1,方法的处理逻辑如下:
-
将
minFastForwardIndex初始化为最大值,minFastForwardIndex用于找到最小的那个出现数据不一致的消息index; -
遍历
writeRequestMap,处理每一个正在进行中的写入请求:
(1)由于消息可能是批量的,所以获取当前请求中的第一条消息index,记为firstEntryIndex;
(2)获取当前请求中的最后一条消息index,记为lastEntryIndex;
(3)如果lastEntryIndex如果小于等于endIndex的值,进行如下处理:- 对比请求中的消息与当前节点存储的消息是否一致,如果是批量消息,遍历请求中的每一个消息,并根据消息的index从当前节的日志中获取消息进行对比,由于endIndex之前的消息都已成功写入,对应的写入请求还在writeRequestMap中表示可能由于某些原因未能从writeRequestMap中移除,所以如果数据对比一致的情况下可以将对应的请求响应设置为完成,并从writeRequestMap中移除;如果对比不一致,进入到异常处理,构建响应请求,状态设置为INCONSISTENT_STATE,通知Leader节点出现了数据不一致的情况;
(4)如果第一条消息firstEntryIndex与endIndex + 1相等(这里不太明白为什么不是与endIndex 相等而是需要加1),表示该请求是endIndex之后的消息请求,结束本次检查;
(5)判断当前请求的处理时间是否超时,如果未超时,继续处理下一个请求,如果超时进入到下一步;
(6)走到这里,如果firstEntryIndex比minFastForwardIndex小,说明出现了数据不一致的情况,此时更新minFastForwardIndex,记录最小的那个数据不一致消息的index; -
如果minFastForwardIndex依旧是MAX_VALUE,表示没有数据不一致的消息,直接返回;
-
根据minFastForwardIndex从writeRequestMap获取请求,如果获取为空,直接返回,否则调用
buildBatchAppendResponse方法构建请求响应,表示数据出现了不一致,在响应中通知Leader节点;
private class EntryHandler extends ShutdownAbleThread {
private void checkAppendFuture(long endIndex) {
// 初始化为最大值
long minFastForwardIndex = Long.MAX_VALUE;
// 遍历writeRequestMap的value
for (Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair : writeRequestMap.values()) {
// 获取每个请求里面的第一条消息index
long firstEntryIndex = pair.getKey().getFirstEntryIndex();
// 获取每个请求里面的最后一条消息index
long lastEntryIndex = pair.getKey().getLastEntryIndex();
// 如果小于等于endIndex
if (lastEntryIndex <= endIndex) {
try {
if (pair.getKey().isBatch()) { // 批量请求
// 遍历所有的消息
for (DLedgerEntry dLedgerEntry : pair.getKey().getBatchEntry()) {
// 校验与当前节点存储的消息是否一致
PreConditions.check(dLedgerEntry.equals(dLedgerStore.get(dLedgerEntry.getIndex())), DLedgerResponseCode.INCONSISTENT_STATE);
}
} else {
DLedgerEntry dLedgerEntry = pair.getKey().getEntry();
// 校验请求中的消息与当前节点存储的消息是否一致
PreConditions.check(dLedgerEntry.equals(dLedgerStore.get(dLedgerEntry.getIndex())), DLedgerResponseCode.INCONSISTENT_STATE);
}
// 设置完成
pair.getValue().complete(buildBatchAppendResponse(pair.getKey(), DLedgerResponseCode.SUCCESS.getCode()));
logger.warn("[PushFallBehind]The leader pushed an batch append entry last index={} smaller than current ledgerEndIndex={}, maybe the last ack is missed", lastEntryIndex, endIndex);
} catch (Throwable t) {
logger.error("[PushFallBehind]The leader pushed an batch append entry last index={} smaller than current ledgerEndIndex={}, maybe the last ack is missed", lastEntryIndex, endIndex, t);
// 如果出现了异常,向Leader节点发送数据不一致的请求
pair.getValue().complete(buildBatchAppendResponse(pair.getKey(), DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
// 处理之后从writeRequestMap移除
writeRequestMap.remove(pair.getKey().getFirstEntryIndex());
continue;
}
// 如果firstEntryIndex与endIndex + 1相等,表示该请求是endIndex之后的消息请求,结束本次检查
if (firstEntryIndex == endIndex + 1) {
return;
}
// 判断响应是否超时,如果未超时,继续处理下一个
TimeoutFuture<PushEntryResponse> future = (TimeoutFuture<PushEntryResponse>) pair.getValue();
if (!future.isTimeOut()) {
continue;
}
// 如果firstEntryIndex比minFastForwardIndex小
if (firstEntryIndex < minFastForwardIndex) {
// 更新minFastForwardIndex
minFastForwardIndex = firstEntryIndex;
}
}
// 如果minFastForwardIndex依旧是MAX_VALUE,表示没有数据不一致的消息,直接返回
if (minFastForwardIndex == Long.MAX_VALUE) {
return;
}
// 根据minFastForwardIndex获取请求
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.get(minFastForwardIndex);
if (pair == null) { // 如果未获取到直接返回
return;
}
logger.warn("[PushFastForward] ledgerEndIndex={} entryIndex={}", endIndex, minFastForwardIndex);
// 向Leader返回响应,响应状态为INCONSISTENT_STATE
pair.getValue().complete(buildBatchAppendResponse(pair.getKey(), DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
private PushEntryResponse buildBatchAppendResponse(PushEntryRequest request, int code) {
PushEntryResponse response = new PushEntryResponse();
response.setGroup(request.getGroup());
response.setCode(code);
response.setTerm(request.getTerm());
response.setIndex(request.getLastEntryIndex());
// 设置当前节点的LedgerBeginIndex
response.setBeginIndex(dLedgerStore.getLedgerBeginIndex());
// 设置LedgerEndIndex
response.setEndIndex(dLedgerStore.getLedgerEndIndex());
return response;
}
}
Follower节点消息写入
handleDoAppend
handleDoAppend方法用于处理Append请求,将Leader转发的消息写入到日志文件:-
从请求中获取消息Entry,调用appendAsFollower方法将消息写入文件;
-
调用updateCommittedIndex方法将Leader请求中携带的commitIndex更新到Follower本地,后面在讲
QuorumAckChecker时候会提到;
public class DLedgerEntryPusher {
private class EntryHandler extends ShutdownAbleThread {
private void handleDoAppend(long writeIndex, PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
PreConditions.check(writeIndex == request.getEntry().getIndex(), DLedgerResponseCode.INCONSISTENT_STATE);
// 将消息写入日志
DLedgerEntry entry = dLedgerStore.appendAsFollower(request.getEntry(), request.getTerm(), request.getLeaderId());
PreConditions.check(entry.getIndex() == writeIndex, DLedgerResponseCode.INCONSISTENT_STATE);
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
// 更新CommitIndex
dLedgerStore.updateCommittedIndex(request.getTerm(), request.getCommitIndex());
} catch (Throwable t) {
logger.error("[HandleDoWrite] writeIndex={}", writeIndex, t);
future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
}
}
}
写入文件
同样以DLedgerMmapFileStore为例,看下appendAsFollower方法的处理过程,前面已经讲过appendAsLeader的处理逻辑,他们的处理过程相似,基本就是将entry内容写入buffer,然后再将buffer写入数据文件和索引文件,这里不再赘述:
public class DLedgerMmapFileStore extends DLedgerStore {
@Override
public DLedgerEntry appendAsFollower(DLedgerEntry entry, long leaderTerm, String leaderId) {
PreConditions.check(memberState.isFollower(), DLedgerResponseCode.NOT_FOLLOWER, "role=%s", memberState.getRole());
PreConditions.check(!isDiskFull, DLedgerResponseCode.DISK_FULL);
// 获取数据Buffer
ByteBuffer dataBuffer = localEntryBuffer.get();
// 获取索引Buffer
ByteBuffer indexBuffer = localIndexBuffer.get();
// encode
DLedgerEntryCoder.encode(entry, dataBuffer);
int entrySize = dataBuffer.remaining();
synchronized (memberState) {
PreConditions.check(memberState.isFollower(), DLedgerResponseCode.NOT_FOLLOWER, "role=%s", memberState.getRole());
long nextIndex = ledgerEndIndex + 1;
PreConditions.check(nextIndex == entry.getIndex(), DLedgerResponseCode.INCONSISTENT_INDEX, null);
PreConditions.check(leaderTerm == memberState.currTerm(), DLedgerResponseCode.INCONSISTENT_TERM, null);
PreConditions.check(leaderId.equals(memberState.getLeaderId()), DLedgerResponseCode.INCONSISTENT_LEADER, null);
// 写入数据文件
long dataPos = dataFileList.append(dataBuffer.array(), 0, dataBuffer.remaining());
PreConditions.check(dataPos == entry.getPos(), DLedgerResponseCode.DISK_ERROR, "%d != %d", dataPos, entry.getPos());
DLedgerEntryCoder.encodeIndex(dataPos, entrySize, entry.getMagic(), entry.getIndex(), entry.getTerm(), indexBuffer);
// 写入索引文件
long indexPos = indexFileList.append(indexBuffer.array(), 0, indexBuffer.remaining(), false);
PreConditions.check(indexPos == entry.getIndex() * INDEX_UNIT_SIZE, DLedgerResponseCode.DISK_ERROR, null);
ledgerEndTerm = entry.getTerm();
ledgerEndIndex = entry.getIndex();
if (ledgerBeginIndex == -1) {
ledgerBeginIndex = ledgerEndIndex;
}
updateLedgerEndIndexAndTerm();
return entry;
}
}
}
Compare
handleDoCompare
用于处理COMPARE请求,compareIndex为需要比较的index,处理逻辑如下:- 进行校验,主要判断compareIndex与请求中的Index是否一致,以及请求类型是否是COMPARE;
- 根据compareIndex获取消息Entry;
- 构建响应内容,在响应中设置当前节点以及同步的消息的BeginIndex和EndIndex;
public class DLedgerEntryPusher {
private class EntryHandler extends ShutdownAbleThread {
private CompletableFuture<PushEntryResponse> handleDoCompare(long compareIndex, PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
// 校验compareIndex与请求中的Index是否一致
PreConditions.check(compareIndex == request.getEntry().getIndex(), DLedgerResponseCode.UNKNOWN);
// 校验请求类型是否是COMPARE
PreConditions.check(request.getType() == PushEntryRequest.Type.COMPARE, DLedgerResponseCode.UNKNOWN);
// 获取Entry
DLedgerEntry local = dLedgerStore.get(compareIndex);
// 校验请求中的Entry与本地的是否一致
PreConditions.check(request.getEntry().equals(local), DLedgerResponseCode.INCONSISTENT_STATE);
// 构建请求响应,这里返回成功,说明数据没有出现不一致
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
} catch (Throwable t) {
logger.error("[HandleDoCompare] compareIndex={}", compareIndex, t);
future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
return future;
}
private PushEntryResponse buildResponse(PushEntryRequest request, int code) {
// 构建请求响应
PushEntryResponse response = new PushEntryResponse();
response.setGroup(request.getGroup());
// 设置响应状态
response.setCode(code);
// 设置Term
response.setTerm(request.getTerm());
// 如果不是COMMIT
if (request.getType() != PushEntryRequest.Type.COMMIT) {
// 设置Index
response.setIndex(request.getEntry().getIndex());
}
// 设置BeginIndex
response.setBeginIndex(dLedgerStore.getLedgerBeginIndex());
// 设置EndIndex
response.setEndIndex(dLedgerStore.getLedgerEndIndex());
return response;
}
}
}
Truncate
Follower节点对Truncate的请求处理在handleDoTruncate方法中,主要是根据Leader节点发送的truncateIndex,进行数据删除,将truncateIndex之后的消息从日志中删除:
private class EntryDispatcher extends ShutdownAbleThread {
// truncateIndex为待删除的消息的index
private CompletableFuture<PushEntryResponse> handleDoTruncate(long truncateIndex, PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
logger.info("[HandleDoTruncate] truncateIndex={} pos={}", truncateIndex, request.getEntry().getPos());
PreConditions.check(truncateIndex == request.getEntry().getIndex(), DLedgerResponseCode.UNKNOWN);
PreConditions.check(request.getType() == PushEntryRequest.Type.TRUNCATE, DLedgerResponseCode.UNKNOWN);
// 进行删除
long index = dLedgerStore.truncate(request.getEntry(), request.getTerm(), request.getLeaderId());
PreConditions.check(index == truncateIndex, DLedgerResponseCode.INCONSISTENT_STATE);
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
// 更新committedIndex
dLedgerStore.updateCommittedIndex(request.getTerm(), request.getCommitIndex());
} catch (Throwable t) {
logger.error("[HandleDoTruncate] truncateIndex={}", truncateIndex, t);
future.complete(buildResponse(request, DLedgerResponseCode.INCONSISTENT_STATE.getCode()));
}
return future;
}
}
Commit
前面讲到Leader节点会向Follower节点发送COMMIT请求,COMMIT请求主要是更新Follower节点本地的committedIndex的值,记录集群中最新的那条获取大多数响应的消息的index,在后面QuorumAckChecker中还会看到:
private class EntryHandler extends ShutdownAbleThread {
private CompletableFuture<PushEntryResponse> handleDoCommit(long committedIndex, PushEntryRequest request,
CompletableFuture<PushEntryResponse> future) {
try {
PreConditions.check(committedIndex == request.getCommitIndex(), DLedgerResponseCode.UNKNOWN);
PreConditions.check(request.getType() == PushEntryRequest.Type.COMMIT, DLedgerResponseCode.UNKNOWN);
// 更新committedIndex
dLedgerStore.updateCommittedIndex(request.getTerm(), committedIndex);
future.complete(buildResponse(request, DLedgerResponseCode.SUCCESS.getCode()));
} catch (Throwable t) {
logger.error("[HandleDoCommit] committedIndex={}", request.getCommitIndex(), t);
future.complete(buildResponse(request, DLedgerResponseCode.UNKNOWN.getCode()));
}
return future;
}
}
QuorumAckChecker
QuorumAckChecker用于Leader节点等待Follower节点复制完毕,处理逻辑如下:
-
如果pendingAppendResponsesByTerm的个数大于1,对其进行遍历,如果KEY的值与当前Term不一致,说明数据已过期,将过期数据置为完成状态并从pendingAppendResponsesByTerm中移除;
-
如果peerWaterMarksByTerm个数大于1,对其进行遍历,同样找出与当前TERM不一致的数据,进行清理;
-
获取当前Term的peerWaterMarks,peerWaterMarks记录了每个Follower节点的日志复制进度,对所有的复制进度进行排序,取出处于中间位置的那个进度值,也就是消息的index值,这里不太好理解,举个例子,假如一个Leader有5个Follower节点,当前Term为1:
{ "1" : { // TERM的值,对应peerWaterMarks中的Key "节点1" : "1", // 节点1复制到第1条消息 "节点2" : "1", // 节点2复制到第1条消息 "节点3" : "2", // 节点3复制到第2条消息 "节点4" : "3", // 节点4复制到第3条消息 "节点5" : "3" // 节点5复制到第3条消息 } }对所有Follower节点的复制进度倒序排序之后的list如下:
[3, 3, 2, 1, 1]取5 / 2 的整数部分为2,也就是下标为2处的值,对应节点3的复制进度(消息index为2),记录在quorumIndex变量中,节点4和5对应的消息进度大于消息2的,所以对于消息2,集群已经有三个节点复制成功,满足了集群中大多数节点复制成功的条件。
如果要判断某条消息是否集群中大多数节点已经成功写入,一种常规的处理方法,对每个节点的复制进度进行判断,记录已经复制成功的节点个数,这样需要每次遍历整个节点,效率比较低,所以这里RocketMQ使用了一种更高效的方式来判断某个消息是否获得了集群中大多数节点的响应。
-
quorumIndex之前的消息都以成功复制,此时就可以更新提交点,调用
updateCommittedIndex方法更新CommitterIndex的值; -
处理处于quorumIndex和lastQuorumIndex(上次quorumIndex的值)之间的数据,比如上次lastQuorumIndex的值为1,本次quorumIndex为2,由于quorumIndex之前的消息已经获得了集群中大多数节点的响应,所以处于quorumIndex和lastQuorumIndex的数据需要清理,从pendingAppendResponsesByTerm中移除,并记录数量ackNum;
-
如果ackNum为0,表示quorumIndex与lastQuorumIndex相等,从quorumIndex + 1处开始,判断消息的写入请求是否已经超时,如果超时设置WAIT_QUORUM_ACK_TIMEOUT并返回响应;这一步主要是为了处理超时的请求;
-
如果上次校验时间超过1000ms或者needCheck为true,更新节点的复制进度,遍历当前term所有的请求响应,如果小于quorumIndex,将其设置成完成状态并移除响应,表示已完成,这一步主要是处理已经写入成功的消息对应的响应对象AppendEntryResponse,是否由于某些原因未移除,如果是需要进行清理;
-
更新lastQuorumIndex的值;
private class QuorumAckChecker extends ShutdownAbleThread {
@Override
public void doWork() {
try {
if (DLedgerUtils.elapsed(lastPrintWatermarkTimeMs) > 3000) {
logger.info("[{}][{}] term={} ledgerBegin={} ledgerEnd={} committed={} watermarks={}",
memberState.getSelfId(), memberState.getRole(), memberState.currTerm(), dLedgerStore.getLedgerBeginIndex(), dLedgerStore.getLedgerEndIndex(), dLedgerStore.getCommittedIndex(), JSON.toJSONString(peerWaterMarksByTerm));
lastPrintWatermarkTimeMs = System.currentTimeMillis();
}
// 如果不是Leader
if (!memberState.isLeader()) {
waitForRunning(1);
return;
}
// 获取当前的Term
long currTerm = memberState.currTerm();
checkTermForPendingMap(currTerm, "QuorumAckChecker");
checkTermForWaterMark(currTerm, "QuorumAckChecker");
// 如果pendingAppendResponsesByTerm的个数大于1
if (pendingAppendResponsesByTerm.size() > 1) {
// 遍历,处理与当前TERM不一致的数据
for (Long term : pendingAppendResponsesByTerm.keySet()) {
// 如果与当前Term一致
if (term == currTerm) {
continue;
}
// 对VALUE进行遍历
for (Map.Entry<Long, TimeoutFuture<AppendEntryResponse>> futureEntry : pendingAppendResponsesByTerm.get(term).entrySet()) {
// 创建AppendEntryResponse
AppendEntryResponse response = new AppendEntryResponse();
response.setGroup(memberState.getGroup());
response.setIndex(futureEntry.getKey());
response.setCode(DLedgerResponseCode.TERM_CHANGED.getCode());
response.setLeaderId(memberState.getLeaderId());
logger.info("[TermChange] Will clear the pending response index={} for term changed from {} to {}", futureEntry.getKey(), term, currTerm);
// 设置完成
futureEntry.getValue().complete(response);
}
// 移除
pendingAppendResponsesByTerm.remove(term);
}
}
// 处理与当前TERM不一致的数据
if (peerWaterMarksByTerm.size() > 1) {
for (Long term : peerWaterMarksByTerm.keySet()) {
if (term == currTerm) {
continue;
}
logger.info("[TermChange] Will clear the watermarks for term changed from {} to {}", term, currTerm);
peerWaterMarksByTerm.remove(term);
}
}
// 获取当前Term的peerWaterMarks,也就是每个Follower节点的复制进度
Map<String, Long> peerWaterMarks = peerWaterMarksByTerm.get(currTerm);
// 对value进行排序
List<Long> sortedWaterMarks = peerWaterMarks.values()
.stream()
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
// 取中位数
long quorumIndex = sortedWaterMarks.get(sortedWaterMarks.size() / 2);
// 中位数之前的消息都已同步成功,此时更新CommittedIndex
dLedgerStore.updateCommittedIndex(currTerm, quorumIndex);
// 获取当前Term的日志转发请求响应
ConcurrentMap<Long, TimeoutFuture<AppendEntryResponse>> responses = pendingAppendResponsesByTerm.get(currTerm);
boolean needCheck = false;
int ackNum = 0;
// 从quorumIndex开始,向前遍历,处理处于quorumIndex和lastQuorumIndex(上次quorumIndex的值)之间的数据
for (Long i = quorumIndex; i > lastQuorumIndex; i--) {
try {
// 从responses中移除
CompletableFuture<AppendEntryResponse> future = responses.remove(i);
if (future == null) { // 如果响应为空,needCheck置为true
needCheck = true;
break;
} else if (!future.isDone()) { // 如果未完成
AppendEntryResponse response = new AppendEntryResponse();
response.setGroup(memberState.getGroup());
response.setTerm(currTerm);
response.setIndex(i);
response.setLeaderId(memberState.getSelfId());
response.setPos(((AppendFuture) future).getPos());
future.complete(response);
}
// 记录ACK节点的数量
ackNum++;
} catch (Throwable t) {
logger.error("Error in ack to index={} term={}", i, currTerm, t);
}
}
// 如果ackNum为0,表示quorumIndex与lastQuorumIndex相等
// 这一步主要是为了处理超时的请求
if (ackNum == 0) {
// 从quorumIndex + 1处开始处理
for (long i = quorumIndex + 1; i < Integer.MAX_VALUE; i++) {
TimeoutFuture<AppendEntryResponse> future = responses.get(i);
if (future == null) { // 如果为空,表示还没有第i条消息,结束循环
break;
} else if (future.isTimeOut()) { // 如果第i条消息的请求已经超时
AppendEntryResponse response = new AppendEntryResponse();
response.setGroup(memberState.getGroup());
// 设置超时状态WAIT_QUORUM_ACK_TIMEOUT
response.setCode(DLedgerResponseCode.WAIT_QUORUM_ACK_TIMEOUT.getCode());
response.setTerm(currTerm);
response.setIndex(i);
response.setLeaderId(memberState.getSelfId());
// 设置完成
future.complete(response);
} else {
break;
}
}
waitForRunning(1);
}
// 如果上次校验时间超过1000ms或者needCheck为true
// 这一步主要是处理已经写入成功的消息对应的响应对象AppendEntryResponse,是否由于某些原因未移除,如果是需要进行清理
if (DLedgerUtils.elapsed(lastCheckLeakTimeMs) > 1000 || needCheck) {
// 更新节点的复制进度
updatePeerWaterMark(currTerm, memberState.getSelfId(), dLedgerStore.getLedgerEndIndex());
// 遍历当前term所有的请求响应
for (Map.Entry<Long, TimeoutFuture<AppendEntryResponse>> futureEntry : responses.entrySet()) {
// 如果小于quorumIndex
if (futureEntry.getKey() < quorumIndex) {
AppendEntryResponse response = new AppendEntryResponse();
response.setGroup(memberState.getGroup());
response.setTerm(currTerm);
response.setIndex(futureEntry.getKey());
response.setLeaderId(memberState.getSelfId());
response.setPos(((AppendFuture) futureEntry.getValue()).getPos());
futureEntry.getValue().complete(response);
// 移除
responses.remove(futureEntry.getKey());
}
}
lastCheckLeakTimeMs = System.currentTimeMillis();
}
// 更新lastQuorumIndex
lastQuorumIndex = quorumIndex;
} catch (Throwable t) {
DLedgerEntryPusher.logger.error("Error in {}", getName(), t);
DLedgerUtils.sleep(100);
}
}
}
持久化
Leader节点在某个消息的写入得到集群中大多数Follower节点的响应之后,会调用updateCommittedIndex将消息的index记在committedIndex中,上面也提到过,Follower节点在收到Leader节点的APPEND请求的时候,也会将请求中设置的Leader节点的committedIndex更新到本地。
在持久化检查点的persistCheckPoint方法中,会将LedgerEndIndex和committedIndex写入到文件(ChecktPoint)进行持久化(Broker停止或者FLUSH的时候):
ledgerEndIndex:Leader或者Follower节点最后一条成功写入的消息的index;
committedIndex:如果某条消息转发给Follower节点之后得到了集群中大多数节点的响应成功,将对应的index记在committedIndex表示该index之前的消息都已提交,已提交的消息可以被消费者消费,Leader节点会将值设置在APPEND请求中发送给Follower节点进行更新或者发送COMMIT请求进行更新;
public class DLedgerMmapFileStore extends DLedgerStore {
public void updateCommittedIndex(long term, long newCommittedIndex) {
if (newCommittedIndex == -1
|| ledgerEndIndex == -1
|| term < memberState.currTerm()
|| newCommittedIndex == this.committedIndex) {
return;
}
if (newCommittedIndex < this.committedIndex
|| newCommittedIndex < this.ledgerBeginIndex) {
logger.warn("[MONITOR]Skip update committed index for new={} < old={} or new={} < beginIndex={}", newCommittedIndex, this.committedIndex, newCommittedIndex, this.ledgerBeginIndex);
return;
}
// 获取ledgerEndIndex
long endIndex = ledgerEndIndex;
// 如果新的提交index大于最后一条消息的index
if (newCommittedIndex > endIndex) {
// 更新
newCommittedIndex = endIndex;
}
Pair<Long, Integer> posAndSize = getEntryPosAndSize(newCommittedIndex);
PreConditions.check(posAndSize != null, DLedgerResponseCode.DISK_ERROR);
this.committedIndex = newCommittedIndex;
this.committedPos = posAndSize.getKey() + posAndSize.getValue();
}
// 持久化检查点
void persistCheckPoint() {
try {
Properties properties = new Properties();
// 设置LedgerEndIndex
properties.put(END_INDEX_KEY, getLedgerEndIndex());
// 设置committedIndex
properties.put(COMMITTED_INDEX_KEY, getCommittedIndex());
String data = IOUtils.properties2String(properties);
// 将数据写入文件
IOUtils.string2File(data, dLedgerConfig.getDefaultPath() + File.separator + CHECK_POINT_FILE);
} catch (Throwable t) {
logger.error("Persist checkpoint failed", t);
}
}
}
参考
【中间件兴趣圈】源码分析 RocketMQ DLedger(多副本) 之日志复制(传播)
RocketMQ版本:4.9.3







![[React] 性能优化相关](https://img-blog.csdnimg.cn/715adda780f14b599d911c4465ead2b5.png)