一.kdb5_util: Password mismatch while reading master key from keyboard
1>.错误复现

2>.错误原因分析
在初始化Kerberos数据库时需要输入密码,2次密码输入不一致就会导致该错误。
3>.解决方案
重新执行"kdb5_util -r YINZHENGJIE.COM create -s"指令,输入2次相同的密码即可。
二.kdb5_util: Required parameters in kdc.conf missing while initializing kerberos admin interface
1>.错误复现
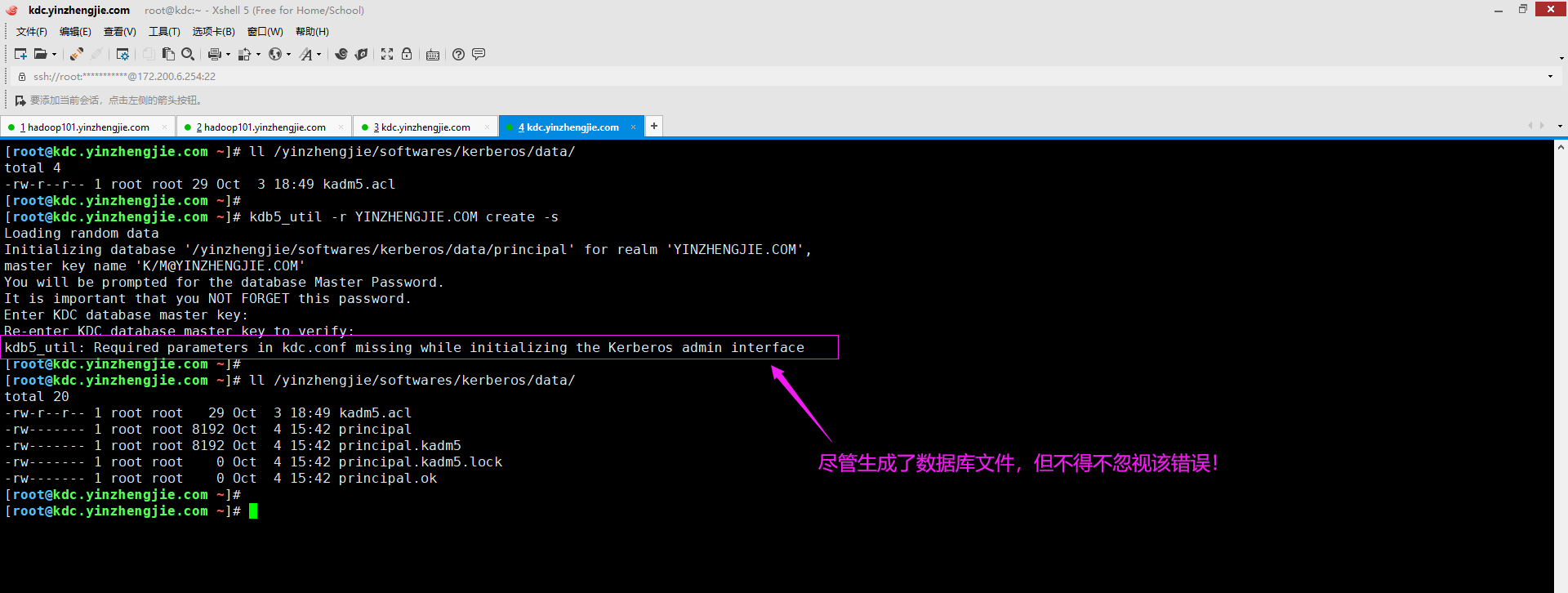
2>.错误原因分析
一般情况下出现在配置文件(kdc.conf)中的"supported_enctypes"的某个加密类型不可用。
3>.解决方案
![]()
下面我针对"supported_enctypes"做了修改,大家可以做个对比。使用修改后的参数问题得到解决,之所以贴出来修改后的是为了提供一个参考。 修改前: supported_enctypes = aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal 修改后: supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal
![]()
三.kadmin.local: Required parameters in kdc.conf missing while initializing kadmin.local interface
1>.错误复现

2>.错误原因分析
一般情况下出现在配置文件(kdc.conf)中的"supported_enctypes"的某个加密类型不可用。
3>.解决方案
参考案例二。
四.kadmin.local: Cannot open DB2 database '/yinzhengjie/softwares/kerberos/data/principal': No such file or directory while initializing kadmin.local interface
1>.错误复现

2>.错误原因分析
报错很明显提示咱们找不到DB数据库相关信息。一般情况下是我们在安装Kerberos时没有做数据库初始化操作。
3>.解决方案
注意观察KDC配置文件("kdc.conf")的"database_name"属性。当我们对Kerberos数据库做了初始化操作时,对生成对应的文件哟~
初始化Kerberos数据库的命令如下:
kdb5_util -r YINZHENGJIE.COM create -s
五.(Error): WARNING! Cannot find dictionary file /yinzhengjie/softwares/kerberos/data/dict/words, continuing without one.
1>.错误复现
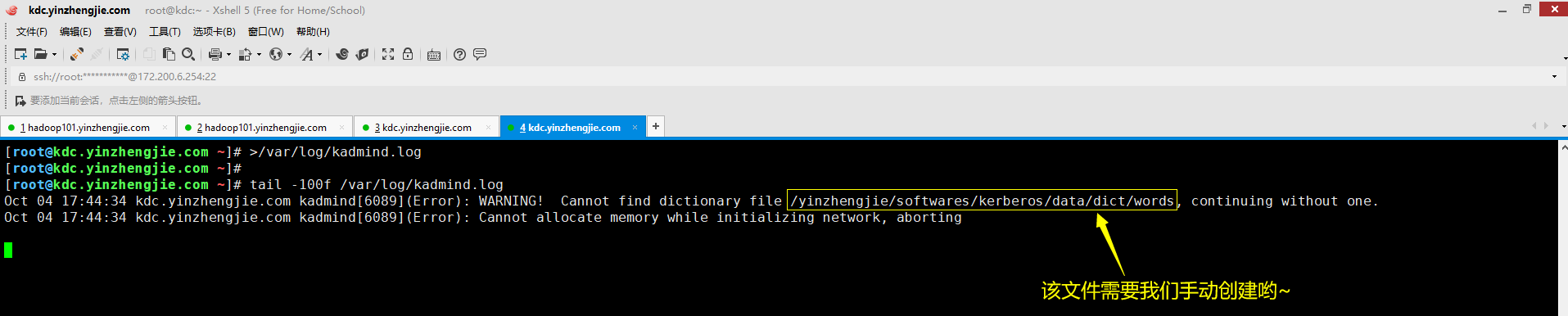
2>.错误原因分析
根据日志的报错信息可判断,是因为没有对应的文件(由kdc.conf配置文件的"dict_file"标签指定路径)导致的报错信息,但这并不影响您启动程序。
3>.解决方案
![]()
解决方法很简单,创建响应的文件即可,操作案例如下所示: [root@kdc.yinzhengjie.com ~]# mkdir -pv /yinzhengjie/softwares/kerberos/data/dict mkdir: created directory ‘/yinzhengjie/softwares/kerberos/data/dict’ [root@kdc.yinzhengjie.com ~]# [root@kdc.yinzhengjie.com ~]# vim /yinzhengjie/softwares/kerberos/data/dict/words [root@kdc.yinzhengjie.com ~]# [root@kdc.yinzhengjie.com ~]# cat /yinzhengjie/softwares/kerberos/data/dict/words 123456 [root@kdc.yinzhengjie.com ~]#
![]()
六.Couldn't open log file ${KERBEROS_HOME}/logs/kadmind.log: No such file or directory
1>.错误复现
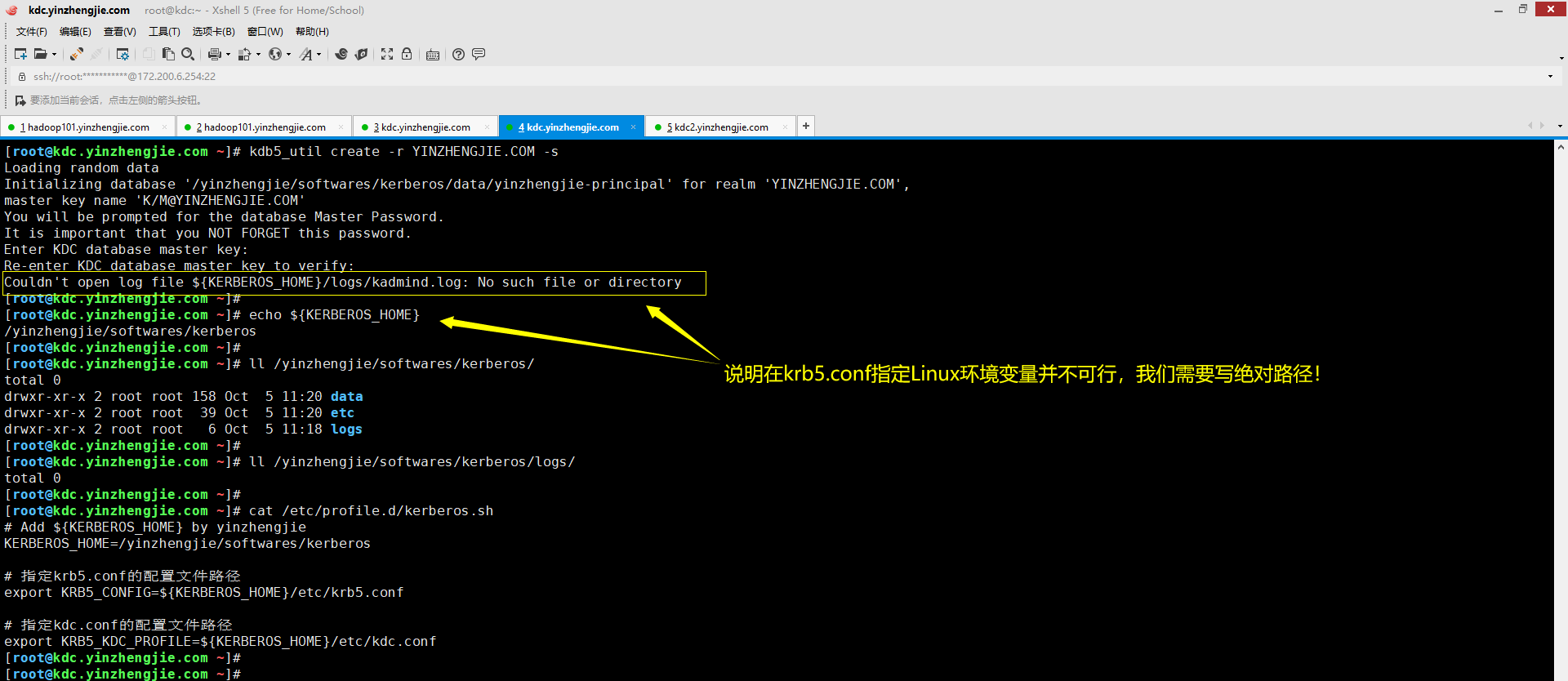
2>.错误原因分析
一般是krb5.conf配置文件中的[logging]的"admin_server"标签对应的路径并不存在,建议写绝对路径,若写自定义的Linux变量可能不会被识别哟!
3>.解决方案
![]()
指定绝对路径即可,下面是我修改krb5.conf配置文件的过程。
修改前:
[logging]
default = FILE:${KERBEROS_HOME}/logs/krb5libs.log
kdc = FILE:${KERBEROS_HOME}/logs/krb5kdc.log
admin_server = FILE:${KERBEROS_HOME}/logs/kadmind.log
修改后:
[logging]
default = FILE:/yinzhengjie/softwares/kerberos/logs/krb5libs.log
kdc = FILE:/yinzhengjie/softwares/kerberos/logs/krb5kdc.log
admin_server = FILE:/yinzhengjie/softwares/kerberos/logs/kadmind.log
![]()
七.kdb5_util: Cannot open DB2 database '/yinzhengjie/softwares/kerberos/data/yinzhengjie-principal': File exists while creating database '/yinzhengjie/softwares/kerberos/data/yinzhengjie-principal'
1>.错误复现
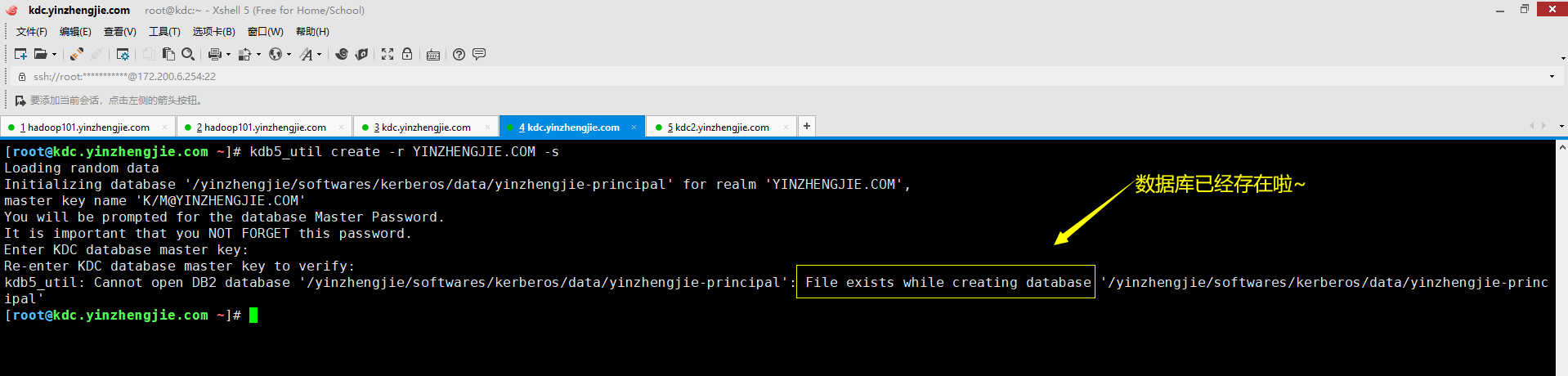
2>.错误原因分析
数据库已经存在啦,因此会出现上图所示的错误。 温馨提示: Kerberos的数据库初始化一次即可,无需初始化第二次,若你的管理员密码忘记了那就得重新初始化了,但这意味之前的数据必须全部删除。生产环境中要慎重啊!
3>.解决方案
![]()
方案一: 删除已存在的数据库文件,重新执行初始化操作,这意味着之前的所有数据全部丢失!生产环境要慎重哟,尽量避免不要这样干! 方案二: 放弃重新初始化操作,因为已经存在数据库文件了,直接使用现有数据库即可,除非你不得不重新初始化操作(比如忘记了KDC管理员的密码)! 温馨提示: 初始化的数据库密码一定要记住哈,这样可以给你减少不必要的麻烦!
![]()
八.kadmind: Cannot allocate memory while initializing network, aborting
1>.错误复现

2>.错误原因分析
3>.解决方案
九.官方故障排除案例
博主推荐阅读: https://web.mit.edu/kerberos/krb5-latest/doc/admin/troubleshoot.html
∨∧Page 2
Hadoop集群常见报错汇总
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.org.apache.hadoop.security.KerberosAuthException: Login failure for user: hdfs/hadoop101.yinzhengjie.com@YINZHENGJIE.COM from keytab /yinzhengjie/softwares/hadoop/etc/hadoop/conf/hdfs.keytab javax.security.auth.login.LoginException: Unable to obtain password from user
1>.错误复现
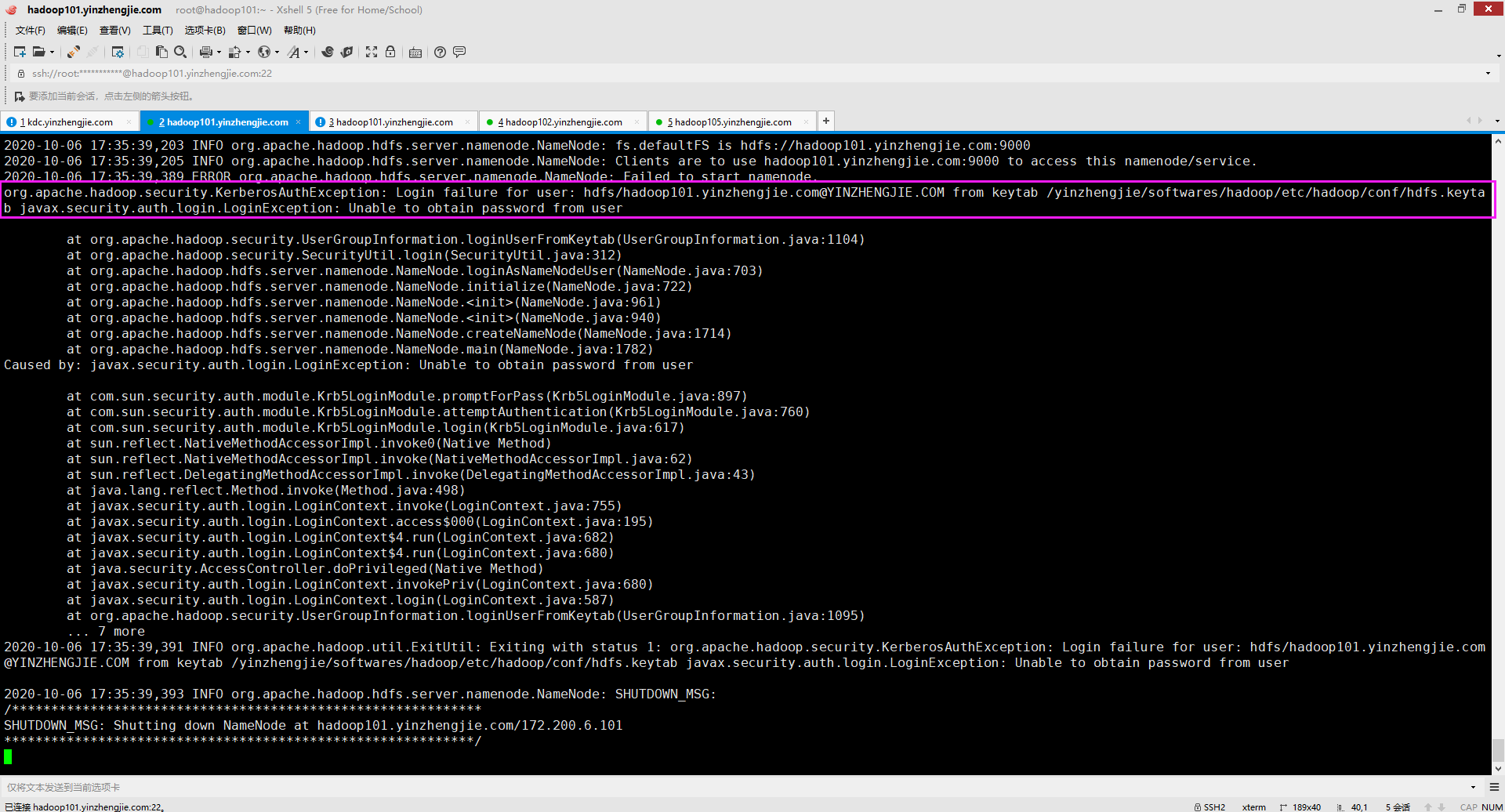
2>.错误原因分析
如上图所示,/yinzhengjie/softwares/hadoop/etc/hadoop/conf/hdfs.keytab文件是存在的,报错是"Unable to obtain password from user"。这就需要我们去检查"hdfs.keytab"文件是否有对应主体(本案例是"hdfs/hadoop101.yinzhengjie.com@YINZHENGJIE.COM")的信息。
3>.解决方案
检查hdfs.keytab文件是否有对应的服务主体。若没有就需要去KDC服务器重新抽取新的keytab文件并分发到Hadoop集群各节点,若有对应主体就得手动验证登录,验证该主体是否可以成功登录。
二.java.io.IOException: Security is enabled but block access tokens (via dfs.block.access.token.enable) aren't enabled. This may cause issues when clients attempt to connect to a DataNode. Aborting NameNode
1>.错误复现

2>.错误原因分析
错误原因以及很明显了,是由于没有启用"dfs.block.access.token.enable",其值默认为"false"。在配置Kerberos集群时必须将其值设置为"true"。 温馨提示: 块访问令牌确保只有授权用户访问DataNodes上的HDFS数据。客户端从NameNode接收到块ID后,将从DataNodes中检索数据。Namenode还发放客户端发送到DataNode的块访问令牌以及数据块访问请求,以用于数据访问。
3>.解决方案
![]()
如下所示,将上图报错的参数设置为"true"问题得到解决。别忘记修改hdfs-site.xml文件后,要同步到集群的其它节点哟~
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
<description>如果为"true",则访问令牌用作访问数据节点的功能。如果为"false",则在访问数据节点时不检查访问令牌。默认值为"false"</description>
</property>
![]()
三.java.lang.RuntimeException: Cannot start secure DataNode without configuring either privileged resources or SASL RPC data transfer protection and SSL for HTTP. Using privileged resources in combination with SASL RPC data transfer protection is not supported.
1>.错误复现
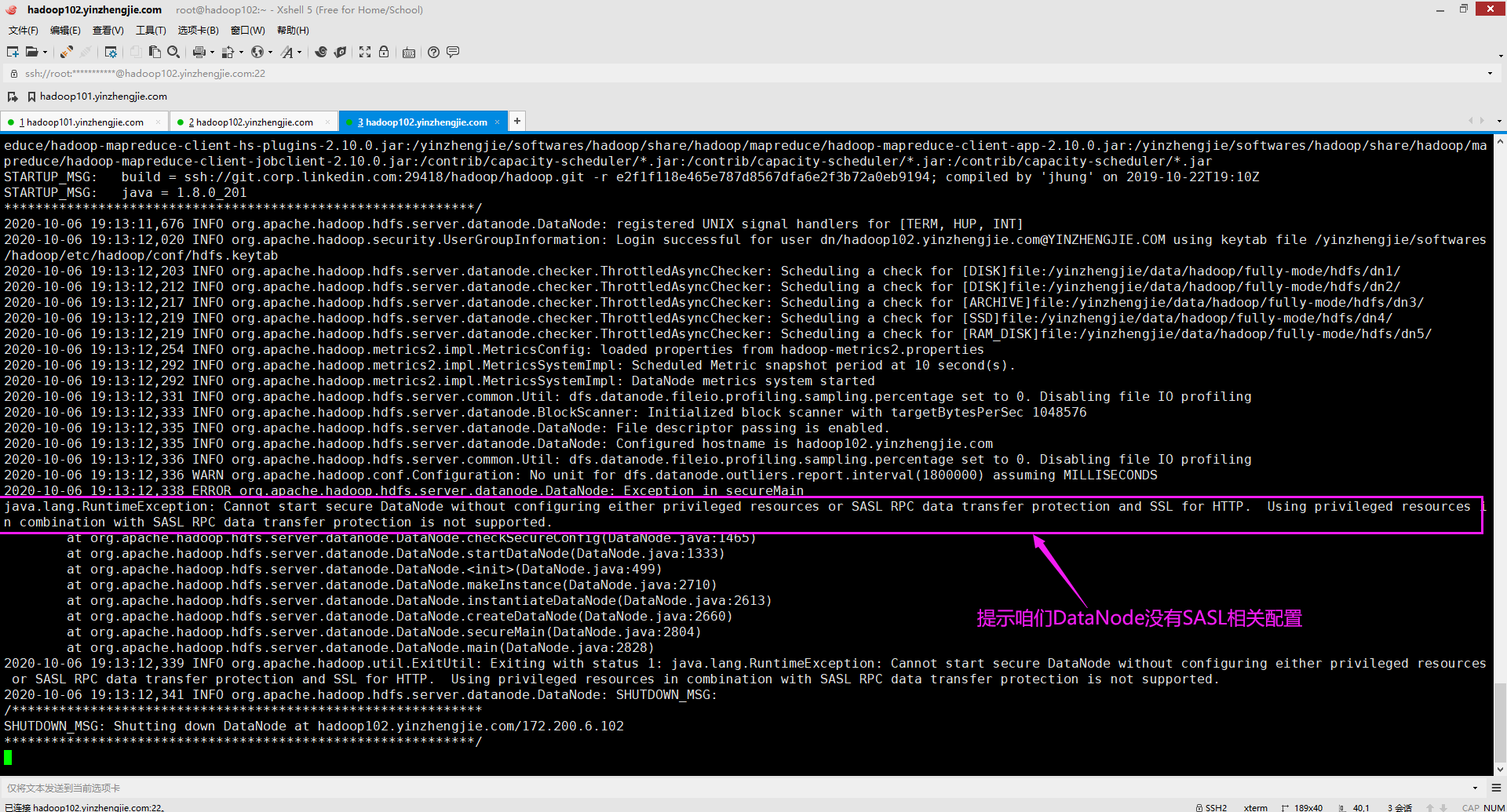
2>.错误原因分析
如果不配置特权资源或SASL RPC数据传输保护和HTTP的SSL,则无法启动secure DataNode。不支持将特权资源与SASL RPC数据传输保护结合使用。此时我们需要配置"dfs.http.policy"属性。
3>.解决方案
![]()
如下所示,修改hdfs-site.xml配置文件中的"dfs.data.transfer.protection"和"dfs.http.policy"属性即可。 <!-- DataNode SASL配置,若不指定可能导致DataNode启动失败 --> <property> <name>dfs.data.transfer.protection</name> <value>integrity</value> <description>逗号分隔的SASL保护值列表,用于在读取或写入块数据时与DataNode进行安全连接。可能的值为:"authentication"(仅表示身份验证,没有完整性或隐私), "integrity"(意味着启用了身份验证和完整性)和"privacy"(意味着所有身份验证,完整性和隐私都已启用)。如果dfs.encrypt.data.transfer设置为true,则它将取代dfs.data.transfer.protection的设置,并强制所有连接必须使用专门的加密SASL握手。对于与在特权端口上侦听的DataNode的连接,将忽略此属性。在这种情况下,假定特权端口的使用建立了足够的信任。</description> </property> <property> <name>dfs.http.policy</name> <value>HTTPS_ONLY</value> <description>确定HDFS是否支持HTTPS(SSL)。默认值为"HTTP_ONLY"(仅在http上提供服务),"HTTPS_ONLY"(仅在https上提供服务,DataNode节点设置该值),"HTTP_AND_HTTPS"(同时提供服务在http和https上,NameNode和Secondary NameNode节点设置该值)。</description> </property>
![]()
四.java.io.IOException: java.security.GeneralSecurityException: The property 'ssl.server.keystore.location' has not been set in the ssl configuration file.
1>.错误复现
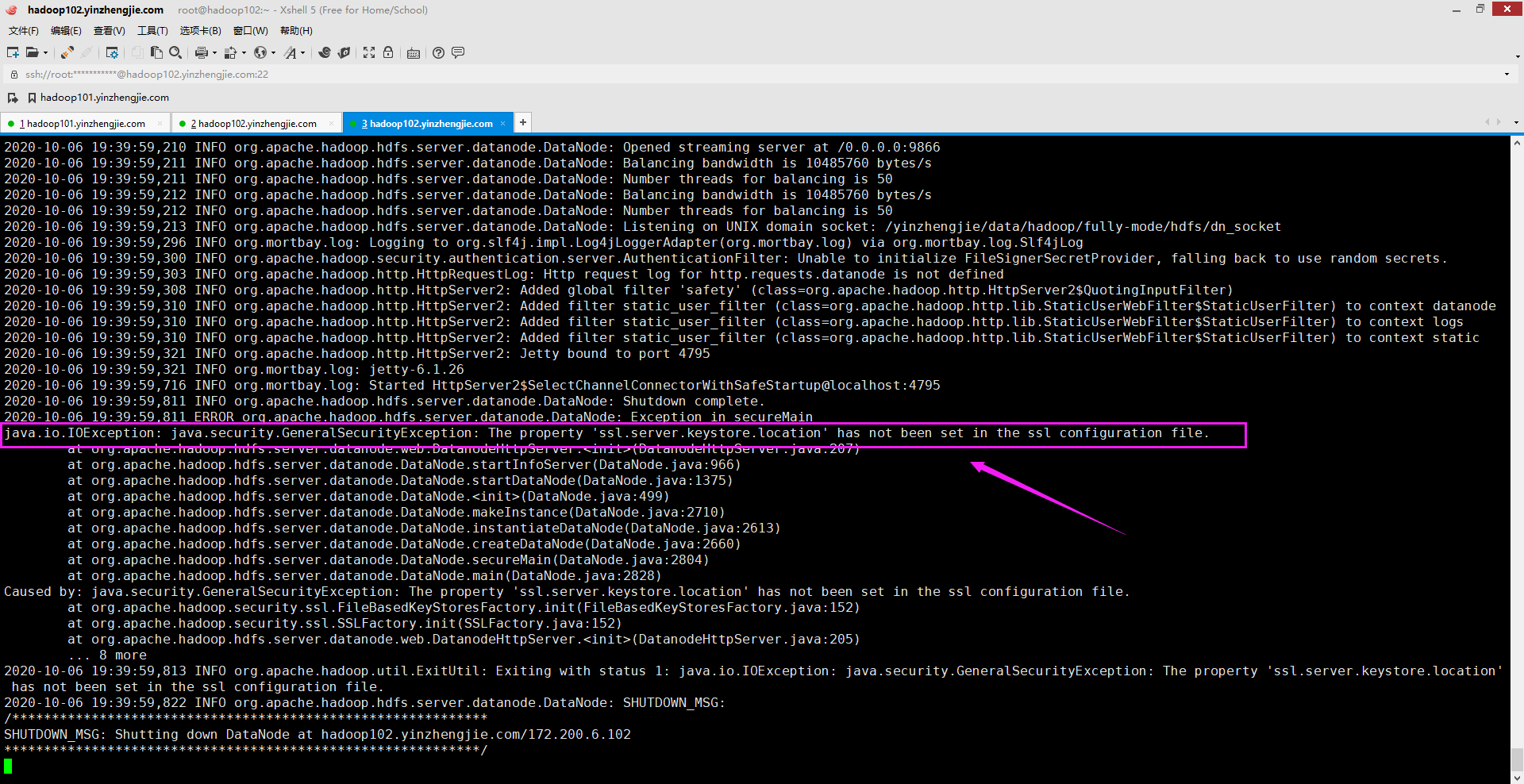
2>.错误原因分析
未给HTTPS SSL配置的密钥库位置。指定该熟悉的值在"${HADOOP_HOME}/etc/hadoop/ssl-server.xml"文件中指定即可。
3>.解决方案
检查Hadoop集群是否配置了https,若未配置可参考我之前写的笔记即可。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13461151.html
五.javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Clock skew too great (37) - PROCESS_TGS)]
1>.错误复现

2>.错误原因分析
这个错误已经很明显了,是因为当前节点机器和KDC机器的时间差太大了,您可用登录一下KDC服务器查看一下时间,再登录DataNode节点查看一下时间。 事实上你会发现这个差距的确不小,如下图所示(很抱歉哈,当时的命令行被我敲击的"history"命令给覆盖了,但下图配置chrony进行时间同步后,从结果上来看差距还是蛮大的,直接相差接近16个小时哟~),我的DataNode和KDC服务器之间的时间差的确很大。
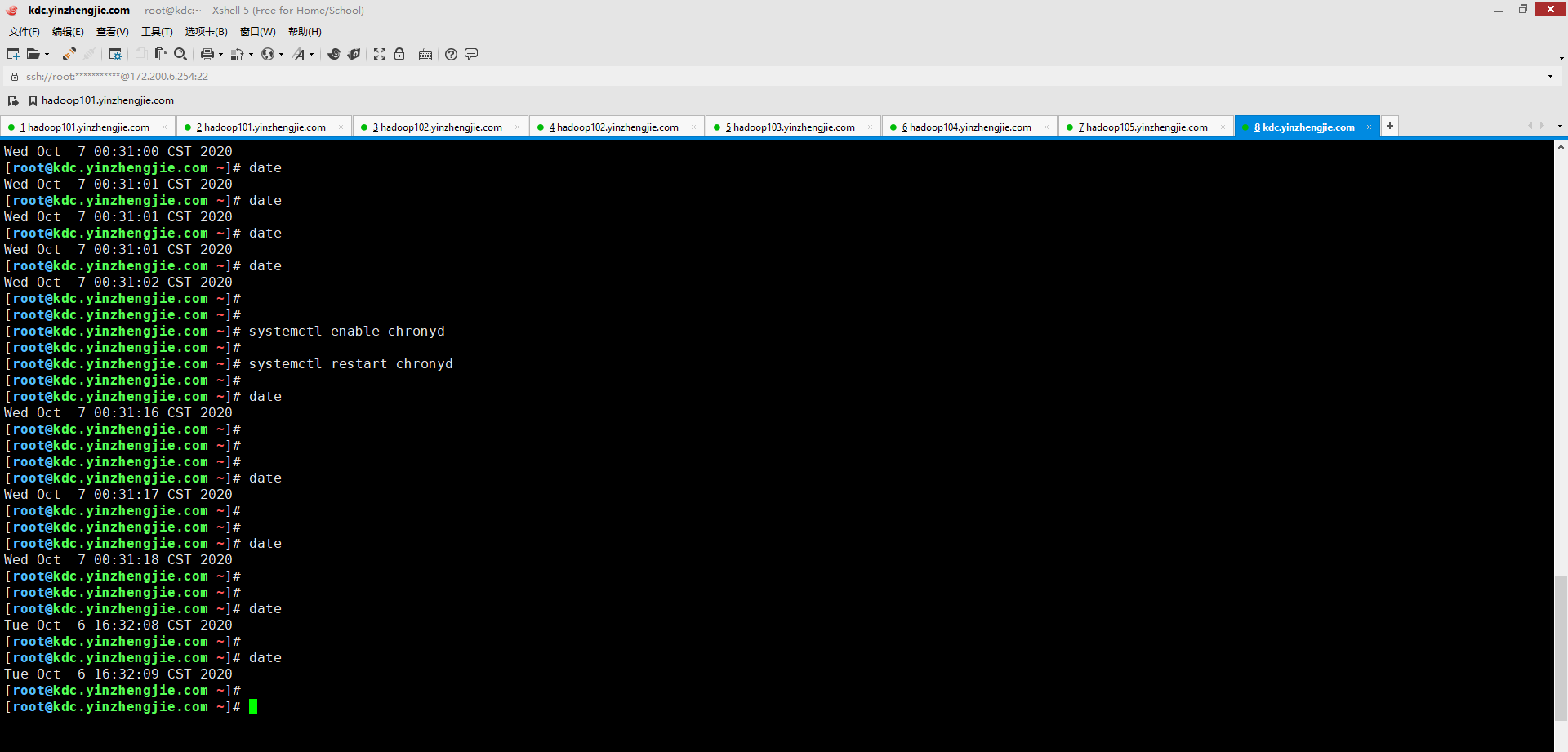
3>.解决方案
知道错误原因在哪里了,那么解决起来就不是事情了,毕竟您已经找到要解决的方向了,关于集群时间同步的组件比如nptd或者chrony均可以解决该问题。我推荐大家使用chrony组件来进行集群内时间同步。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/12292549.html
六.ls: Failed on local exception: java.io.IOException: javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]; Host Details : local host is: "hadoop102.yinzhengjie.com/172.200.6.102"; destination host is: "hadoop101.yinzhengjie.com":9000;
1>.错误复现
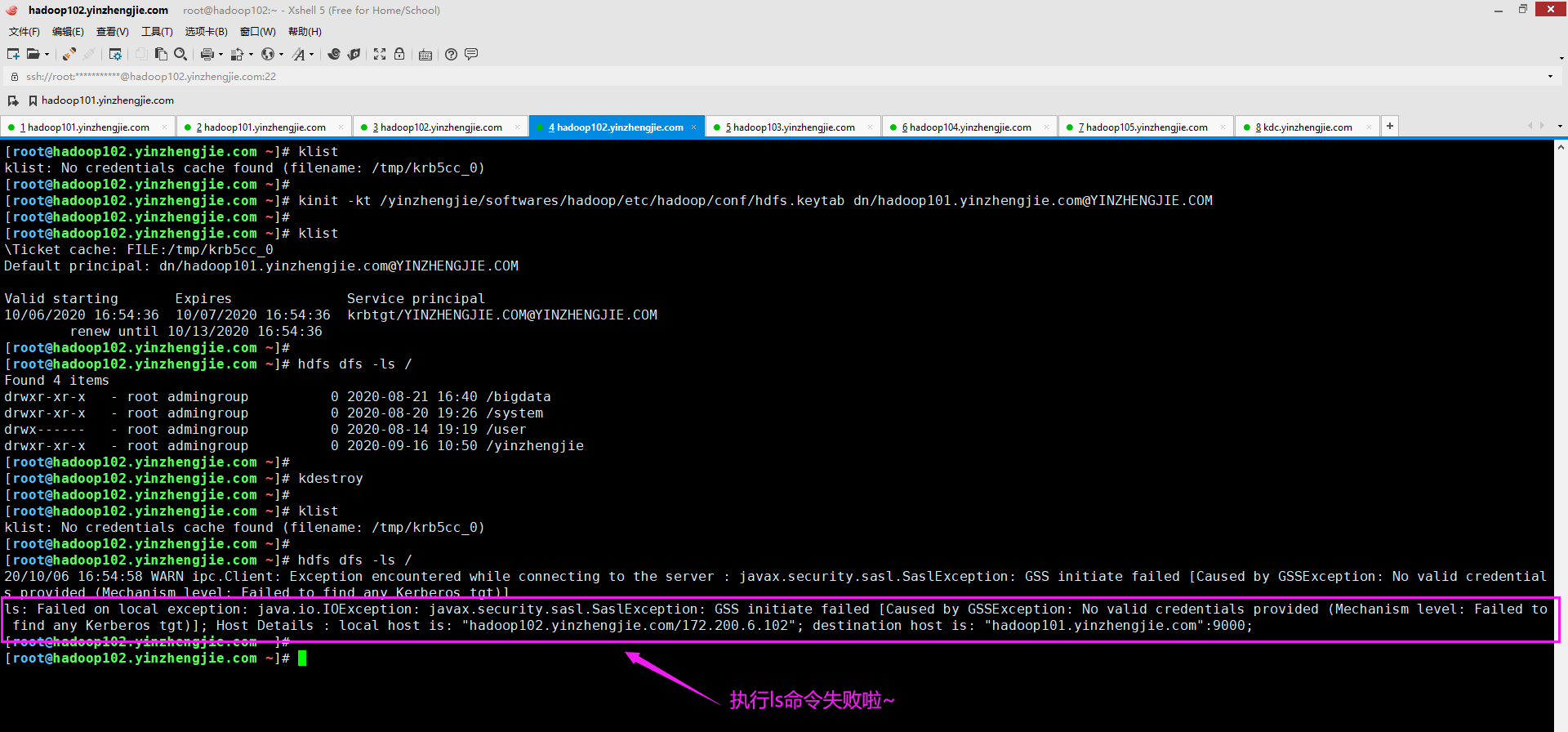
2>.错误原因分析
从上图想必大家已经看出端倪了,没错,就是未提供有效凭据。这是我们启用了Kerberos认值后,若再想要使用命令行进行访问的话,就必须先做Kerberos认证才行!
3>.解决方案
如下图所示,进行Kerberos验证即可访问HDFS集群啦~关于如何基于Kerberos的KDC服务器创建主体以及keytab文件,可以参考我之前的笔记。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/13616881.html
![]()
[root@hadoop102.yinzhengjie.com ~]# kinit -kt /yinzhengjie/softwares/hadoop/etc/hadoop/conf/hdfs.keytab dn/hadoop101.yinzhengjie.com@YINZHENGJIE.COM
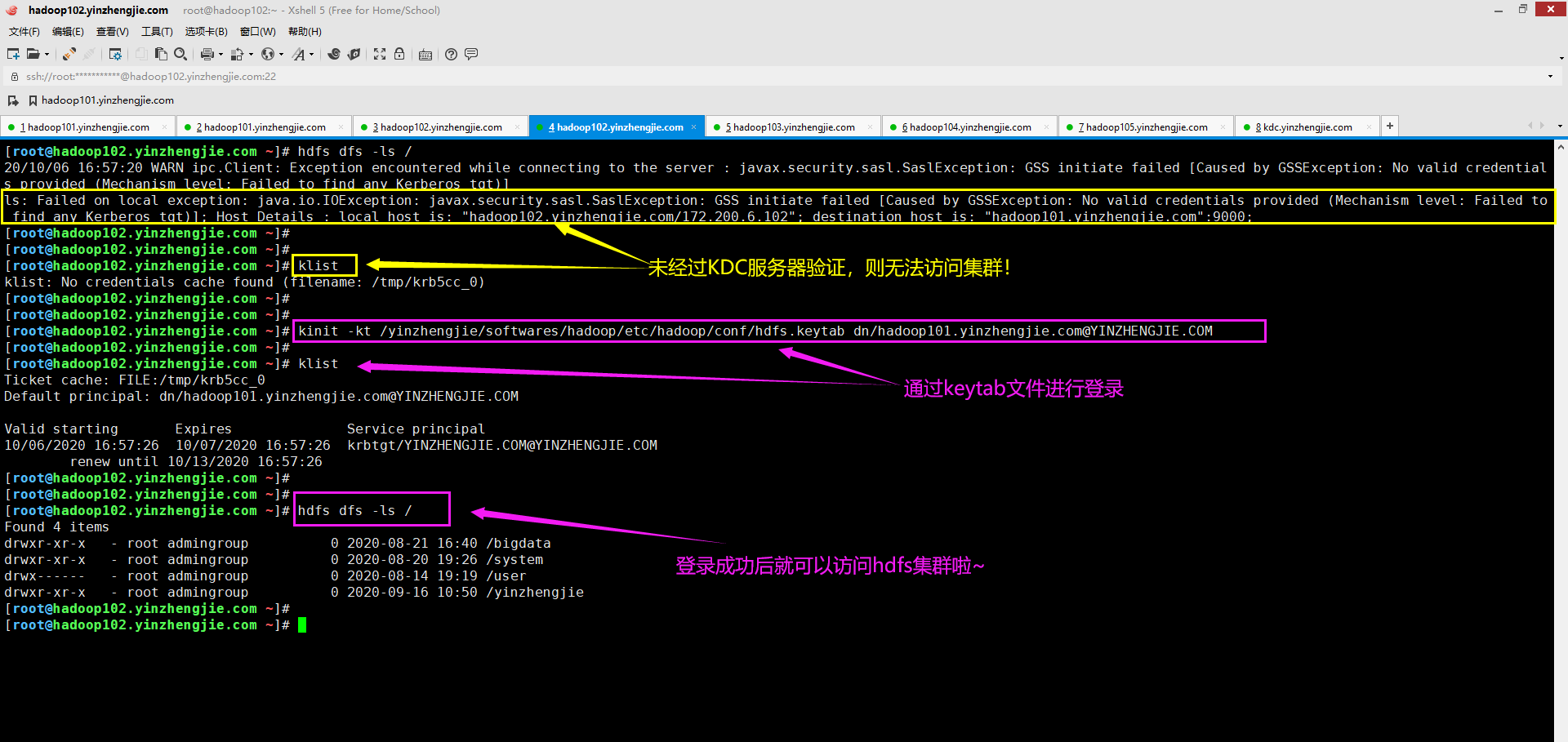
六.Exception in thread "main" java.lang.IllegalArgumentException: Can't get Kerberos realm
1>.错误复现
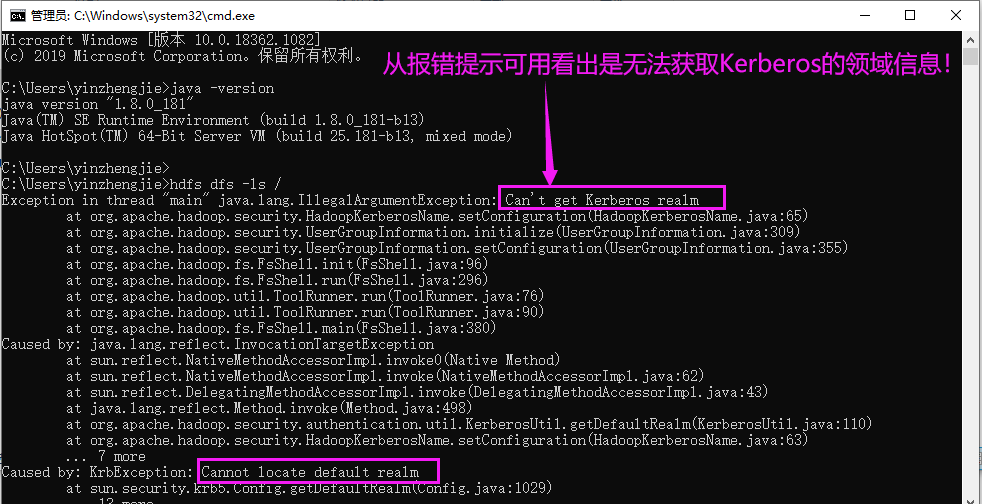
2>.错误原因分析
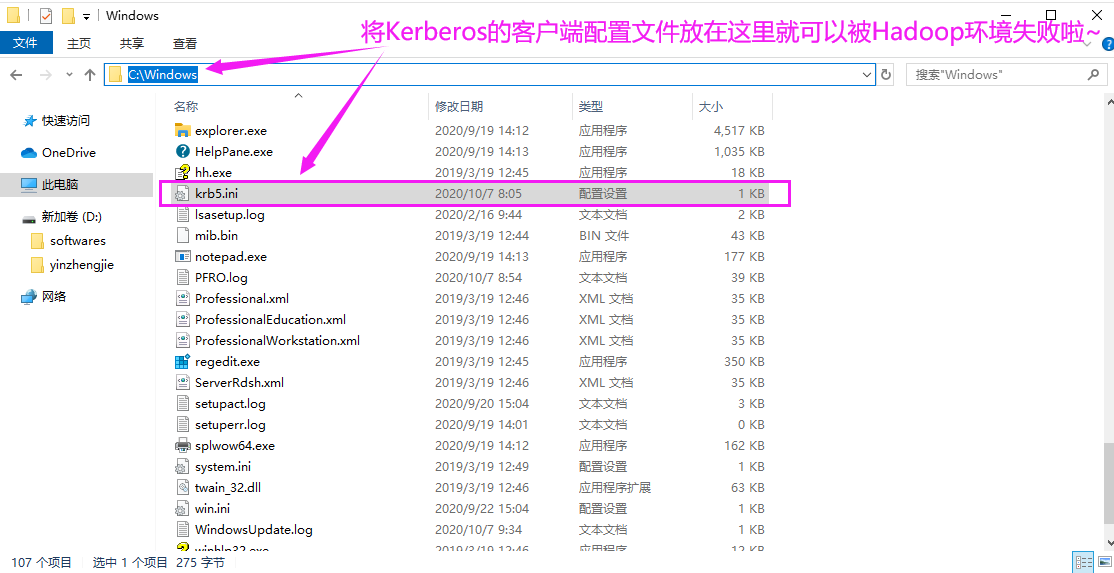
从上图Java的堆栈的报错信息可以看出,获取不到默认的Kerberos领域(realm)信息。这种情况大多数都是由于配置文件未放置到正确的路径导致的。 我们按照Kerberos习惯性将Kerberos的配置文件放置在"C:\ProgramData\MIT\Kerberos5"路径,但Hadoop查找Kerberos文件并不会去该路径找,它会去"C:\Windows\krb5.ini"找,若找不到就会报错!
3>.解决方案
如下图所示,将"C:\ProgramData\MIT\Kerberos5\krb5.ini"拷贝一份到"C:\Windows\krb5.ini"即可解决问题。
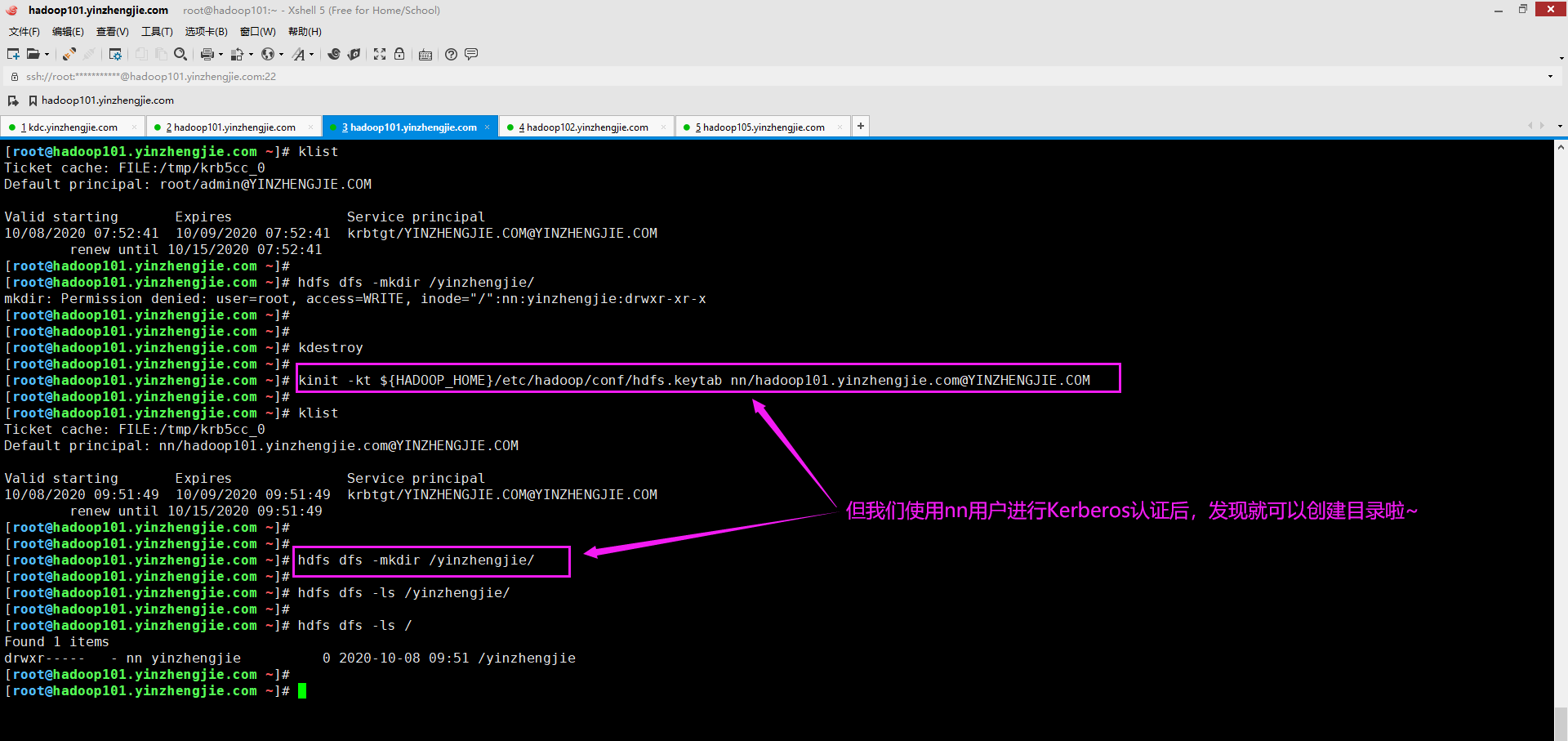
七.mkdir: Permission denied: user=root, access=WRITE, inode="/":nn:yinzhengjie:drwxr-xr-x
1>.错误复现
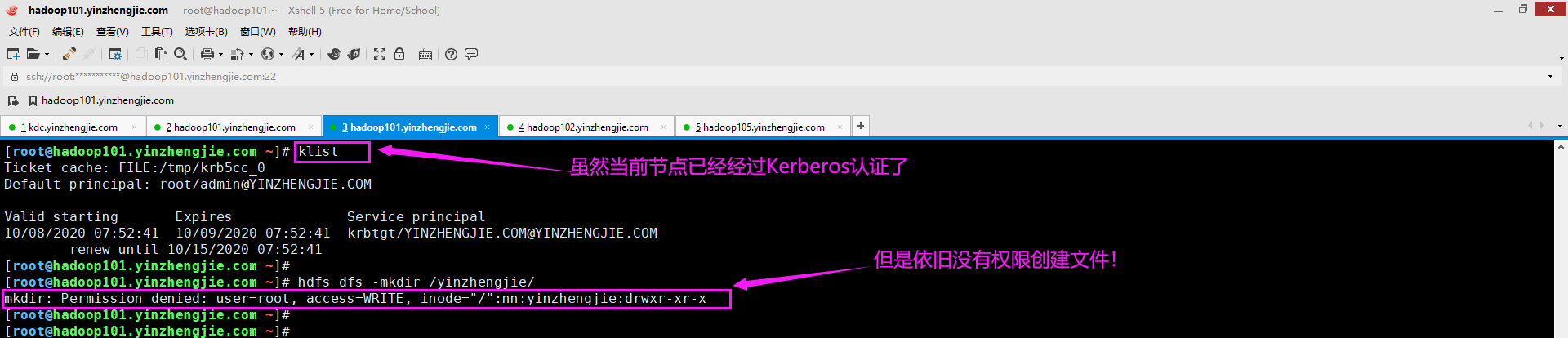
2>.错误原因分析
很明显,这是权限问题导致的,它说当前用户是root,而根节点的超级用户是nn,超级用户组是yinzhengjie。很明显,root用户既不属于HDFS的超级用户,也不属于HDFS的超级用户组。因此权限创建目录时权限被拒绝。
3>.解决方案
找到错误原因就可以对症下药啦,解决方法很简单,如下图所示,我们只需要将Kerberos认证用户更换为HDFS的超级用户即可。
八.The ServiceName: mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid.The valid service name should only contain a-zA-Z0-9_ and can not start with numbers
1>.错误复现
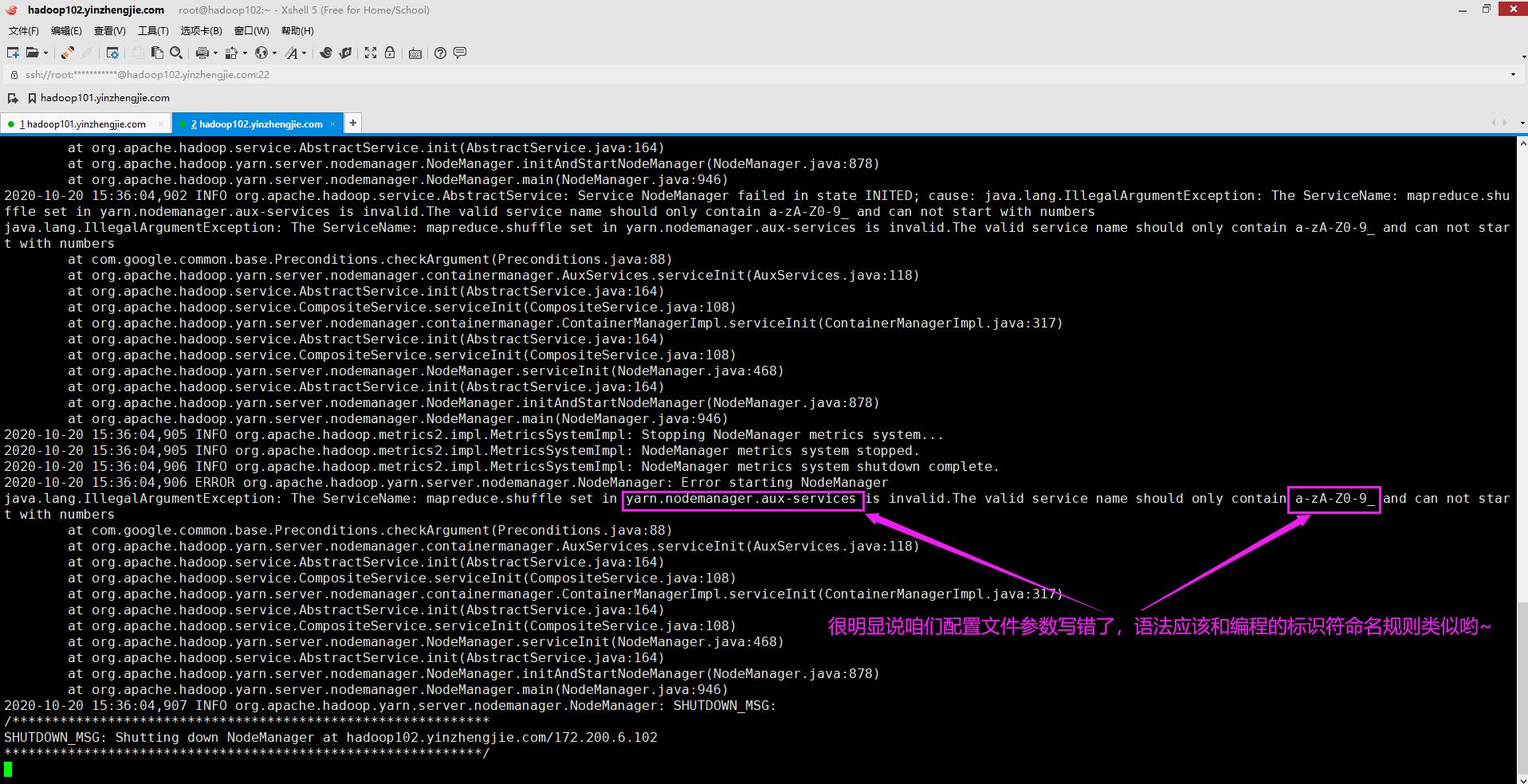
2>.错误原因分析
从报错信息估计很多小伙伴已经定位问题了,说是yarn.nodemanager.aux-services配置参数无效。yarn.nodemanager.aux-services的值应该设置为"a-zA-Z0-9_"。
于是,我检查了自己的配置文件(${HADOOP_HOME}/etc/hadoop/yarn-site.xml),发现的确是出现问题了,如下图所示。
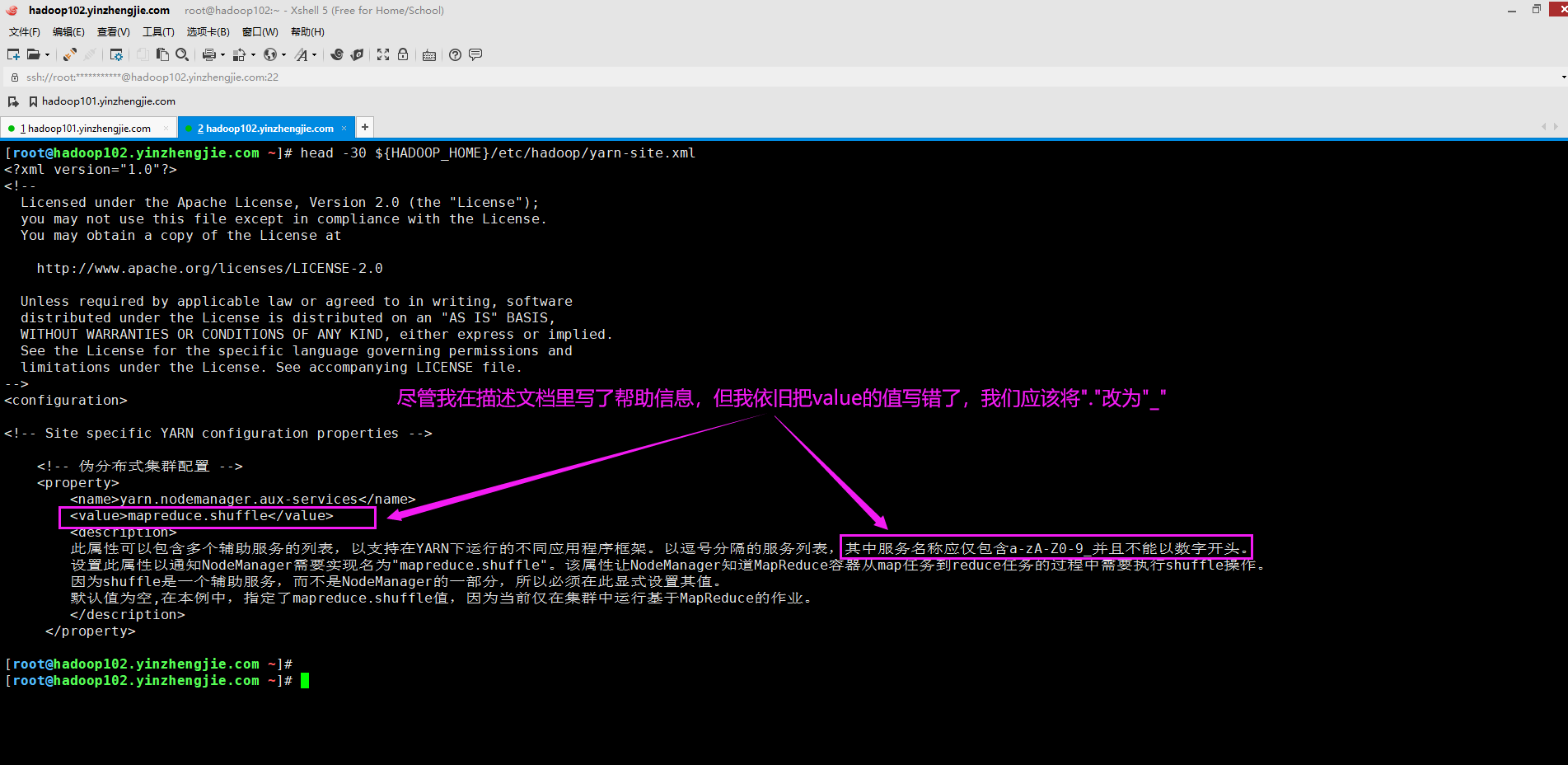
3>.解决方案
如下图所示,将对应的value修改后分发到Hadoop节点即可。
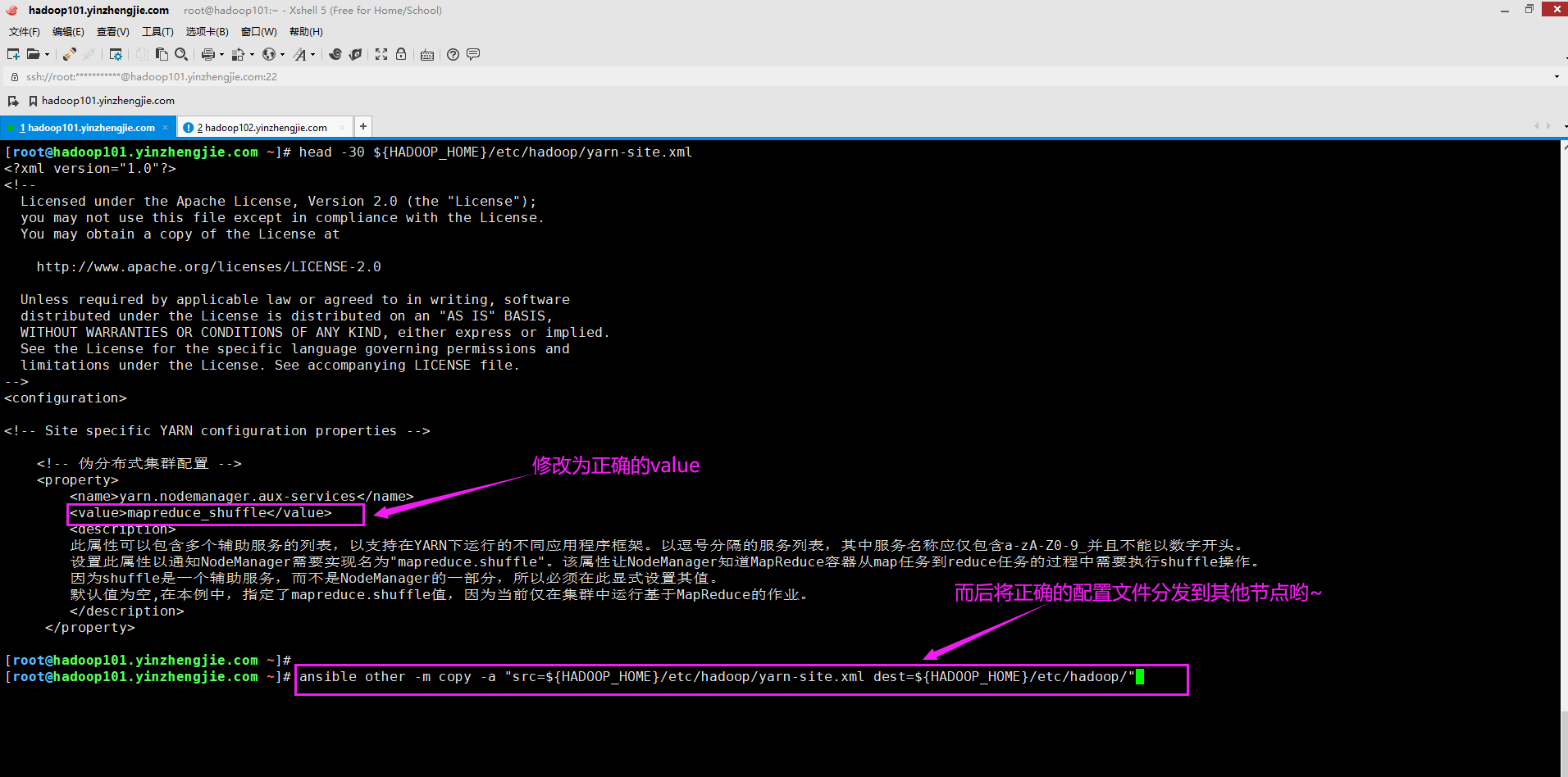
九.Aggregation is not enabled. Try the nodemanager at hadoop104.yinzhengjie.com:31424
1>.错误复现
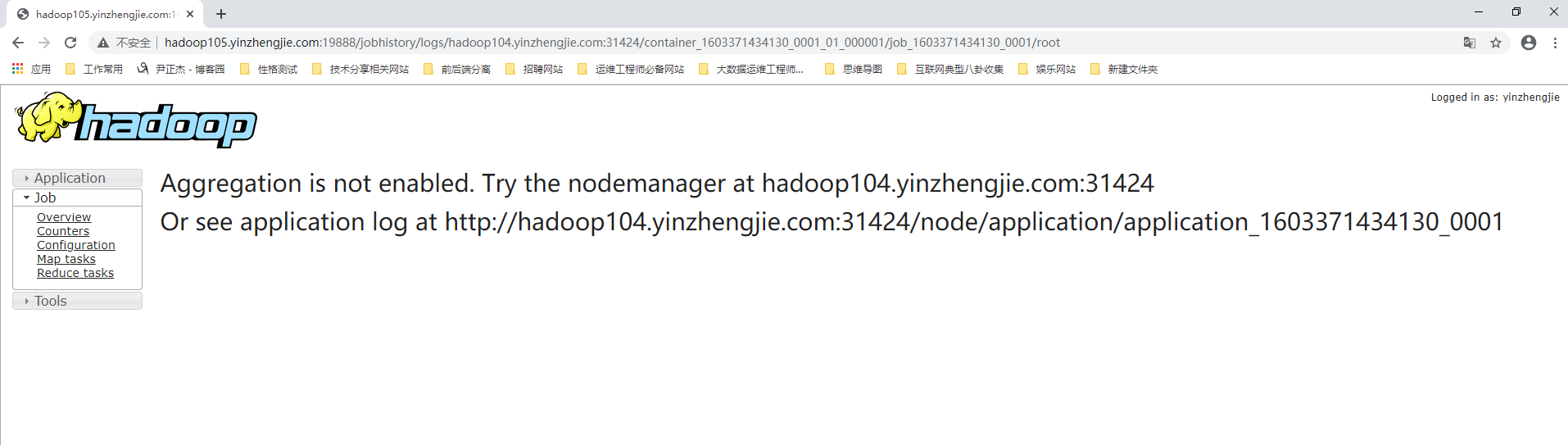
2>.错误原因分析
这个错误原因是由于我们没有启用日志聚合功能导致的,想要解决该问题,可以开启日志聚合功能,即将"yarn.log-aggregation-enable"的值设置为true。 温馨提示: 如果你将"yarn.log-aggregation-enable"的值设置为其他值,例如"ture",你依旧会发现日志功能没有启动哟~
3>.解决方案
![]()
如下所示,将"yarn.log-aggregation-enable"的值设置为"true"即可。 <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description> 每个DataNode上的NodeManager使用此属性来聚合应用程序日志。默认值为"false",启用日志聚合时,Hadoop收集作为应用程序一部分的每个容器的日志,并在应用完成后将这些文件移动到HDFS。 可以使用"yarn.nodemanager.remote-app-log-dir"和"yarn.nodemanager.remote-app-log-dir-suffix"属性来指定在HDFS中聚合日志的位置。 </description> </property>
![]()
十.Failed while trying to construct the redirect url to the log server. Log Server url may not be configured
1>.错误复现
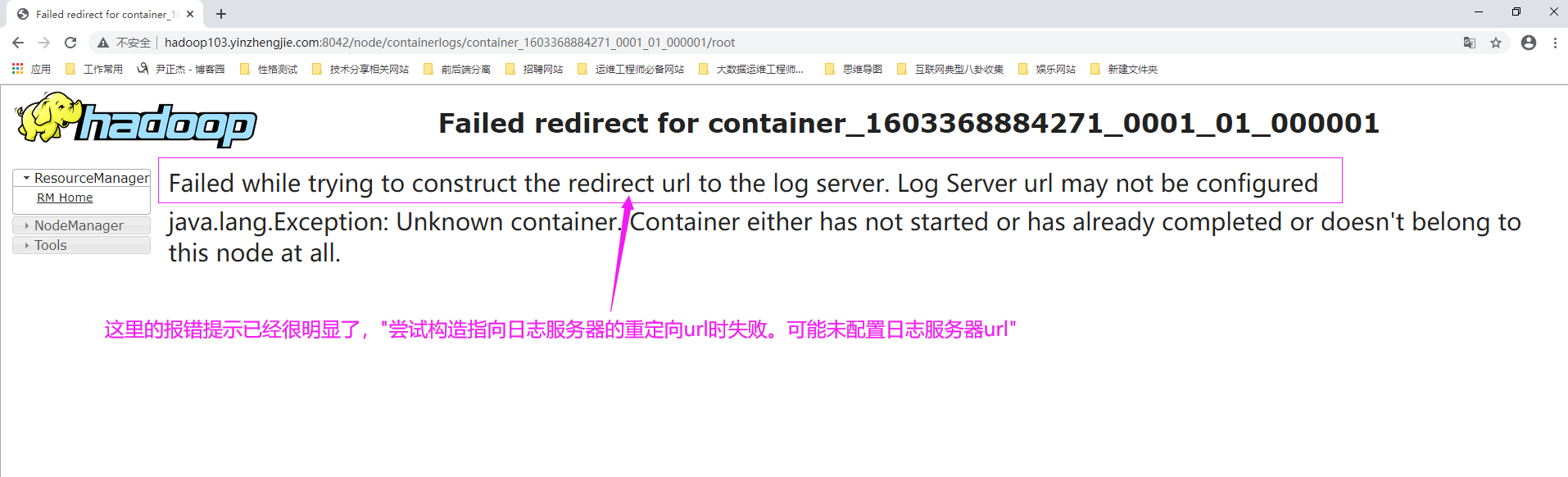
2>.错误原因分析
我们知道开启日志聚合不仅仅要将"yarn.log-aggregation-enable"的值设置为true,还需指定正确的"yarn.log.server.url"参数。 根据错误提示信息,想必大家也大概定位问题了,说是连接聚合日志服务器失败了,此时请检查"yarn-site.xml"配置文件中的"yarn.log.server.url"属性值是否配置正确,即是否指向了正确的日志聚合服务器呢?
3>.解决方案
![]()
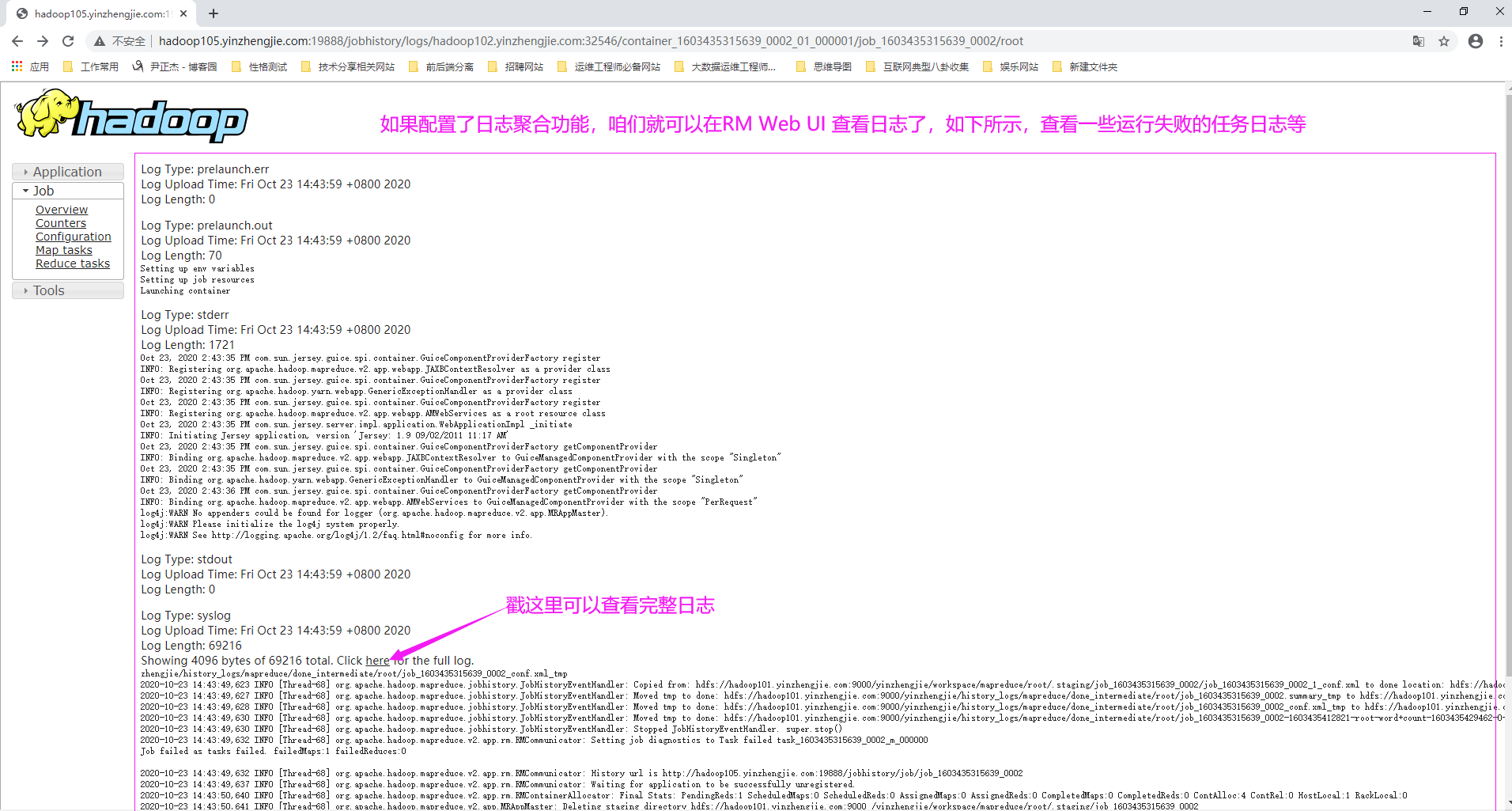
如下所示,我们只需为"yarn.log.server.url"配置JobHistoryServer的URL即可。 <property> <name>yarn.log.server.url</name> <value>http://hadoop105.yinzhengjie.com:19888/yinzhengjie/history_logs/aggregation</value> <description>指定日志聚合服务器的URL,若不指定,默认值为空。</description> </property> 温馨提示: 当我们配置好yarn.log-aggregation-enable和yarn.log.server.url属性后,建议重启一下YARN和HistoryServer服务,使得配置立即生效。 如果您也能在ResourceManager Web UI看到类型下面的日志信息,说明您的日志聚合功能配置是正确的哟~
![]()
十一.Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
1>.错误复现
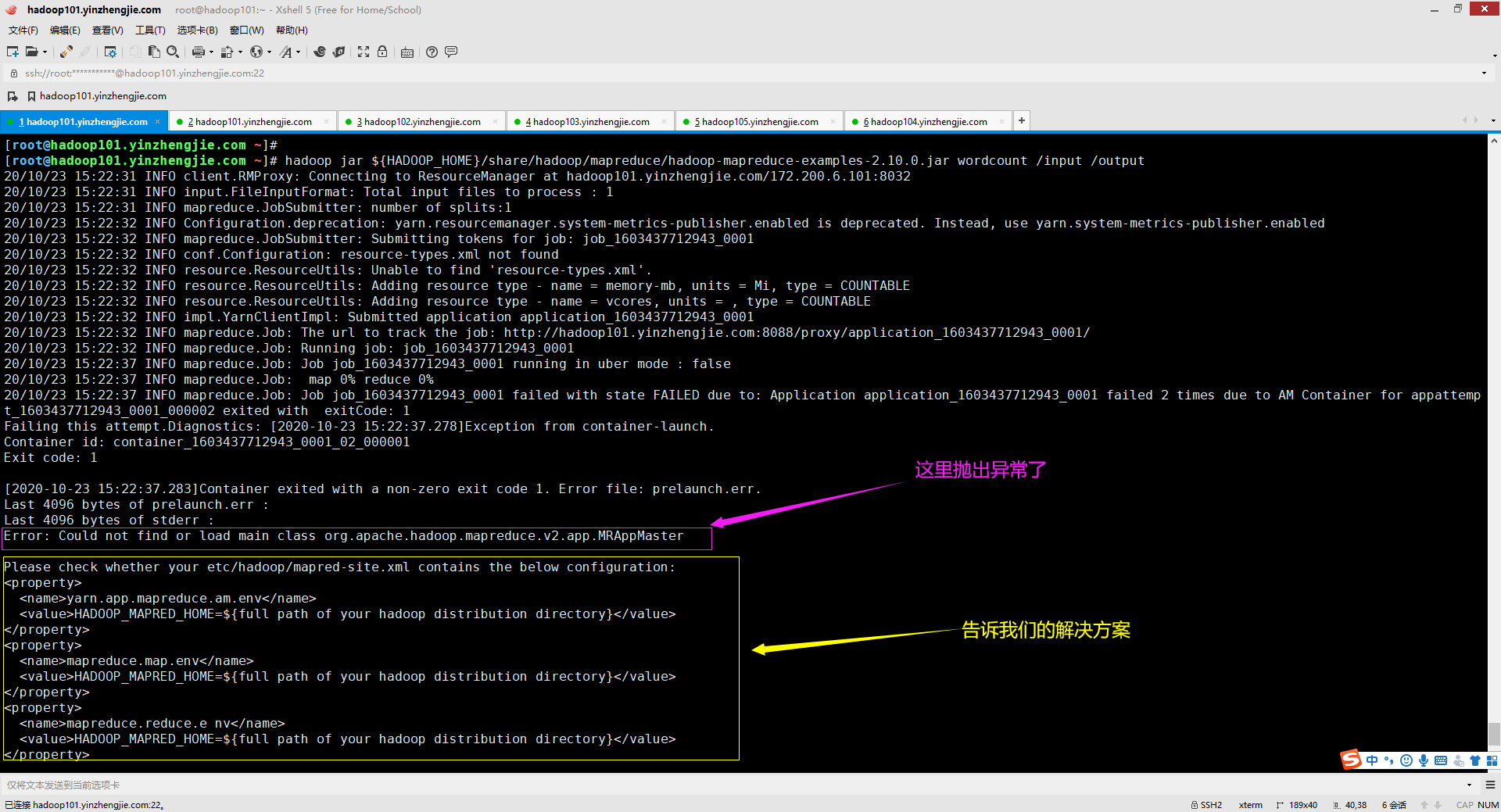
2>.错误原因分析
从上图的报错信息("Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster")可得知,这是由于找不到主类导致的,解决方案上图已经给出来了,需要我们手动指定Hadoop的环境变量。
3>.解决方案
![]()
我参考其提示信息,分别将"yarn.app.mapreduce.am.env","mapreduce.map.env"和"mapreduce.reduce.env"的值设置成"HADOOP_MAPRED_HOME=${HADOOP_HOME}",发现并没有解决问题。
于是我又将这3个值改值改为绝对路径"HADOOP_MAPRED_HOME=/yinzhengjie/softwares/hadoop"(改成绝对路径我是怀疑过mapred-site.xml识别不了"$HADOOP_HOME变量的"),发现依旧解决不了问题。
目前给出两个解决方案:
方案一(修改"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"配置文件):
要么就不设置"yarn.application.classpath"的值,即将其设置为空。
如下图所示,建议将"yarn.application.classpath"的值设置为:"yarn classpath"命令的执行结果。
方案二(修改"${HADOOP_HOME}/etc/hadoop/mapred-site.xml"配置文件):
要么就不设置"yarn.app.mapreduce.am.env","mapreduce.map.env"和"mapreduce.reduce.env"的值,即将其设置为空。
若要设置,若要设置,建议将"mapreduce.application.classpath"的值设置为"mapred classpath"命令的执行结果。
![]()
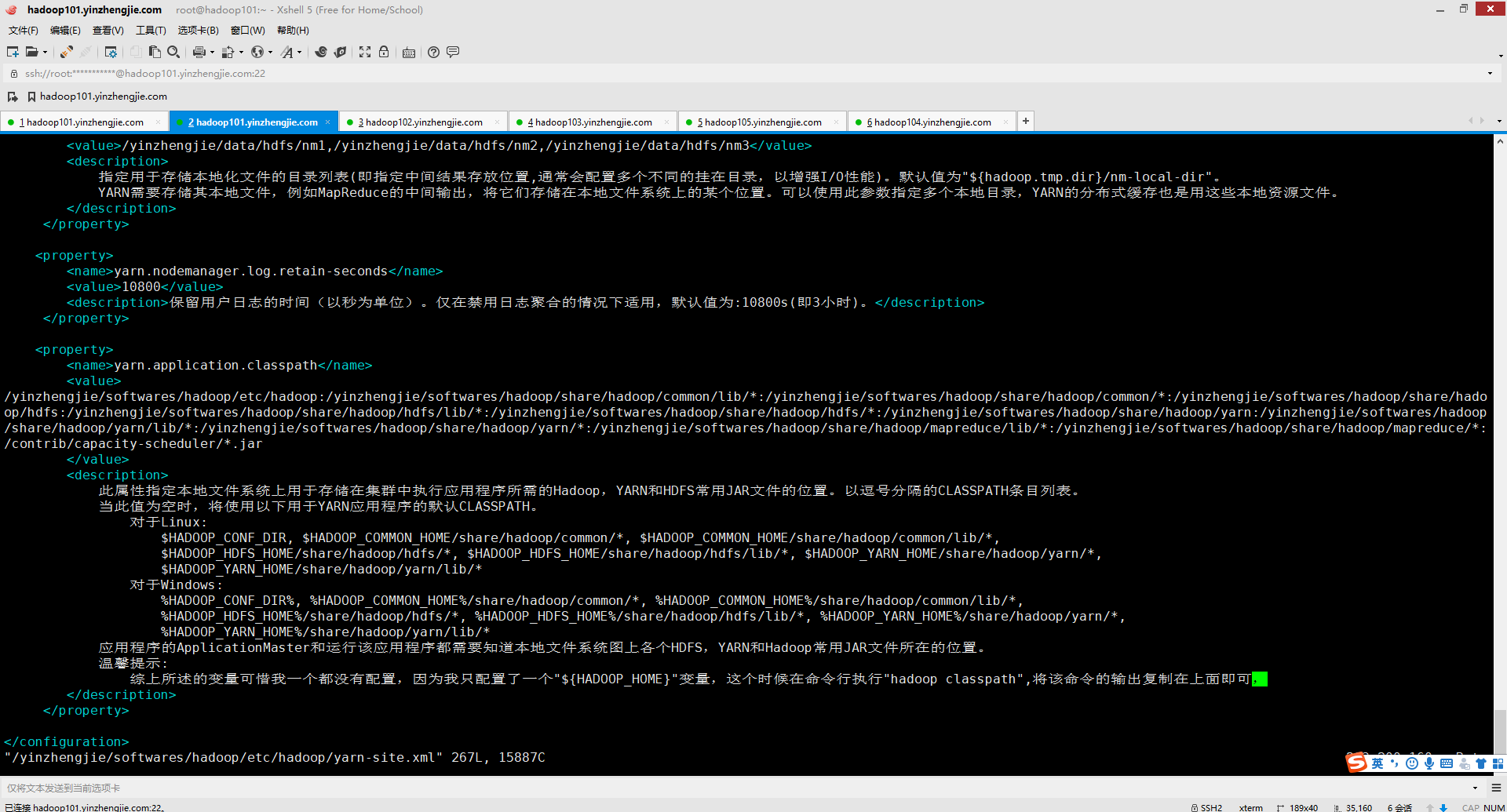
十二.Container exited with a non-zero exit code 1. Error file: prelaunch.err.
1>.错误复现
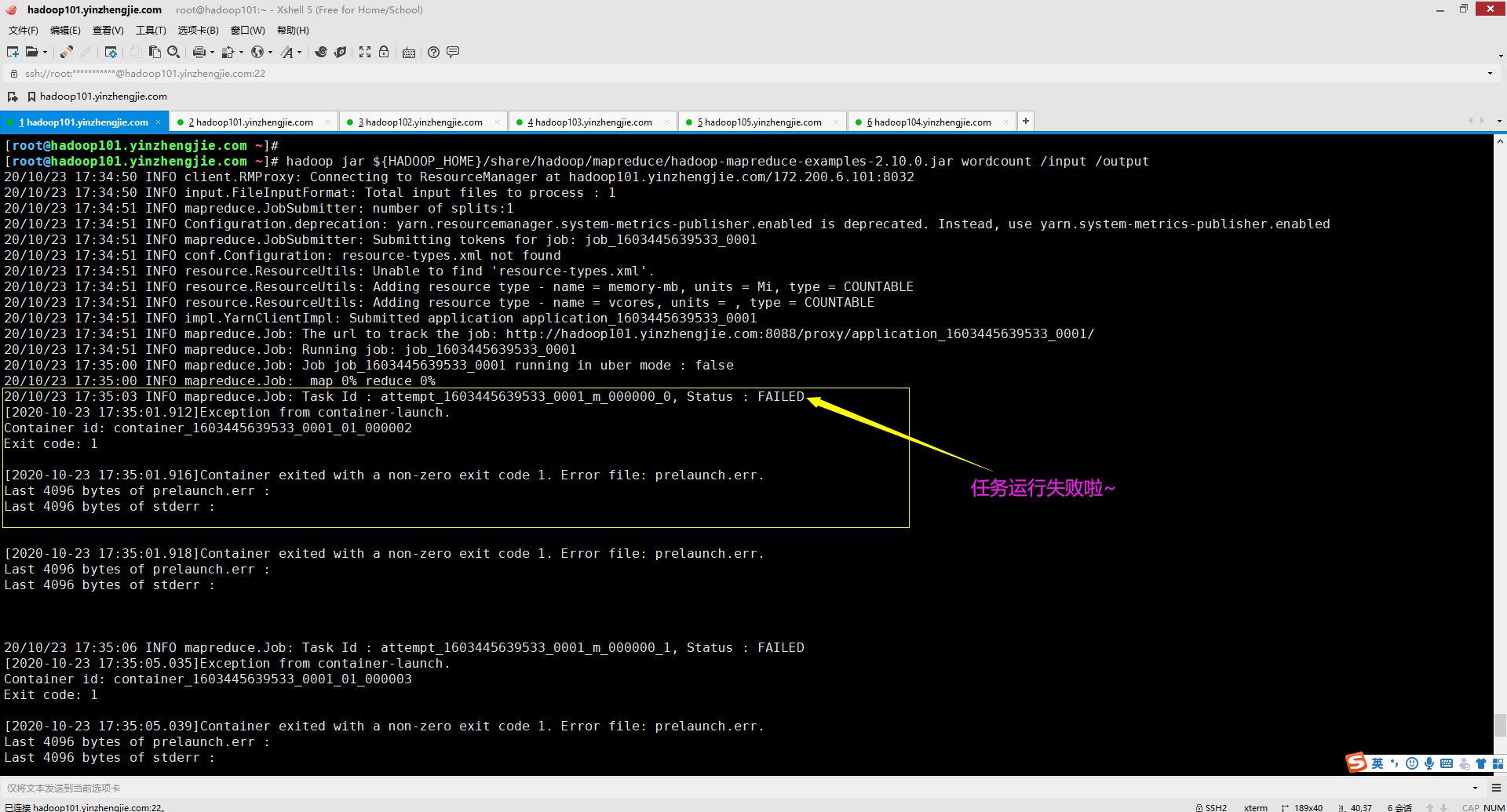
2>.错误原因分析
![]()
不得不说,这个问题的确困扰了我一个上午,我还去网上尝试了几乎所有的解决方案,没有一种能解决的,我当时很郁闷啊。
但仔细看看错误输出,其中"prelaunch.err "是启动前错误,也就是在container启动之前就出问题了,这个时候我终于得到了启发,问题应该定位跟启动JVM相关的参数上。
如下图所示,我检查了"${HADOOP_HOME}/etc/hadoop/mapred-site.xml"的参数,下面有关于"mapreduce.map.java.opts"的值我设置为"-Xmx1536"。
可能有的小伙伴已经发现错误了,我少写了一个计量单位(比如KB,MB,GB等),问题就出在这里,应该写的值为"-Xmx1536m",问题得到解决。
![]()
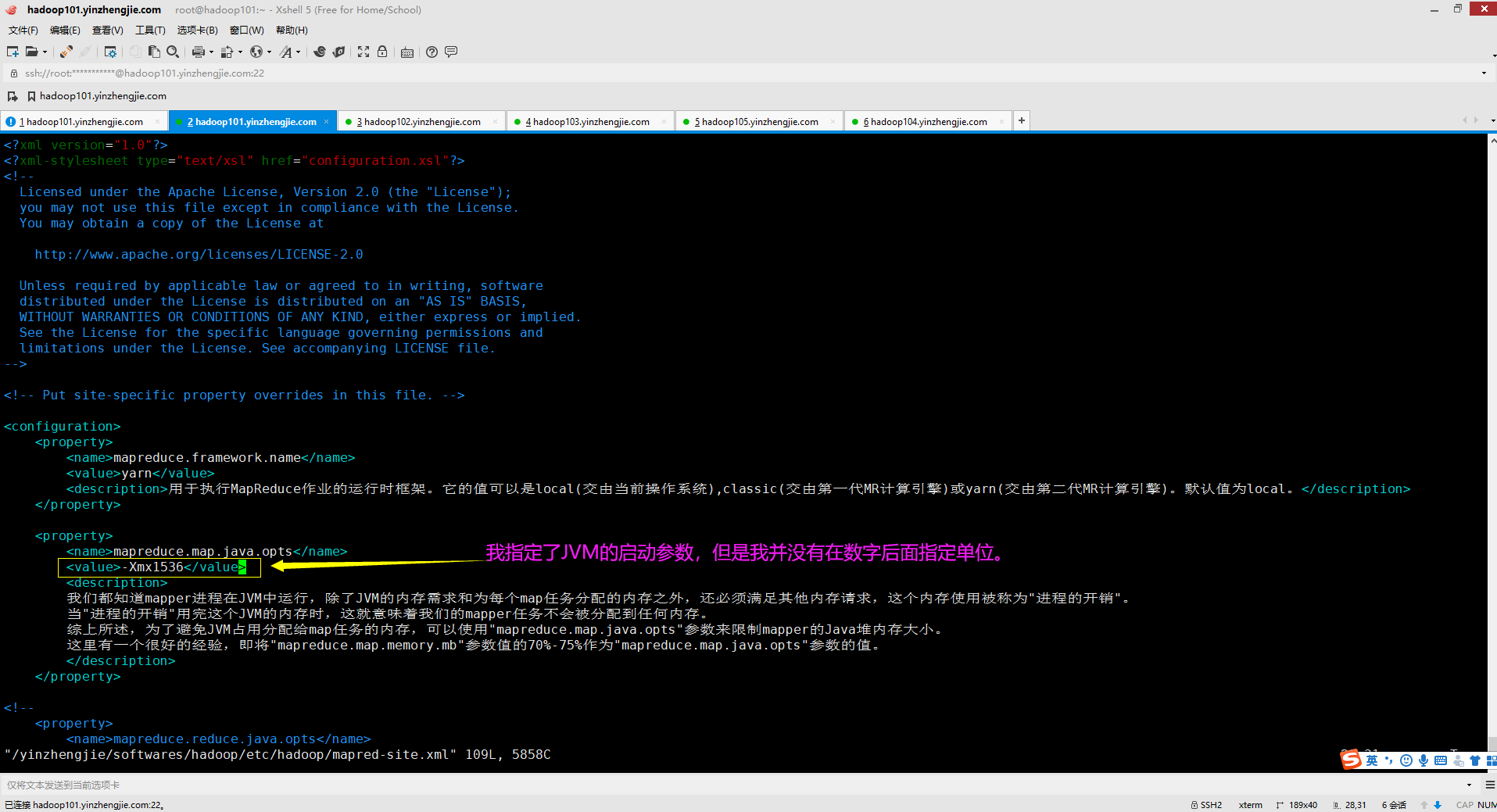
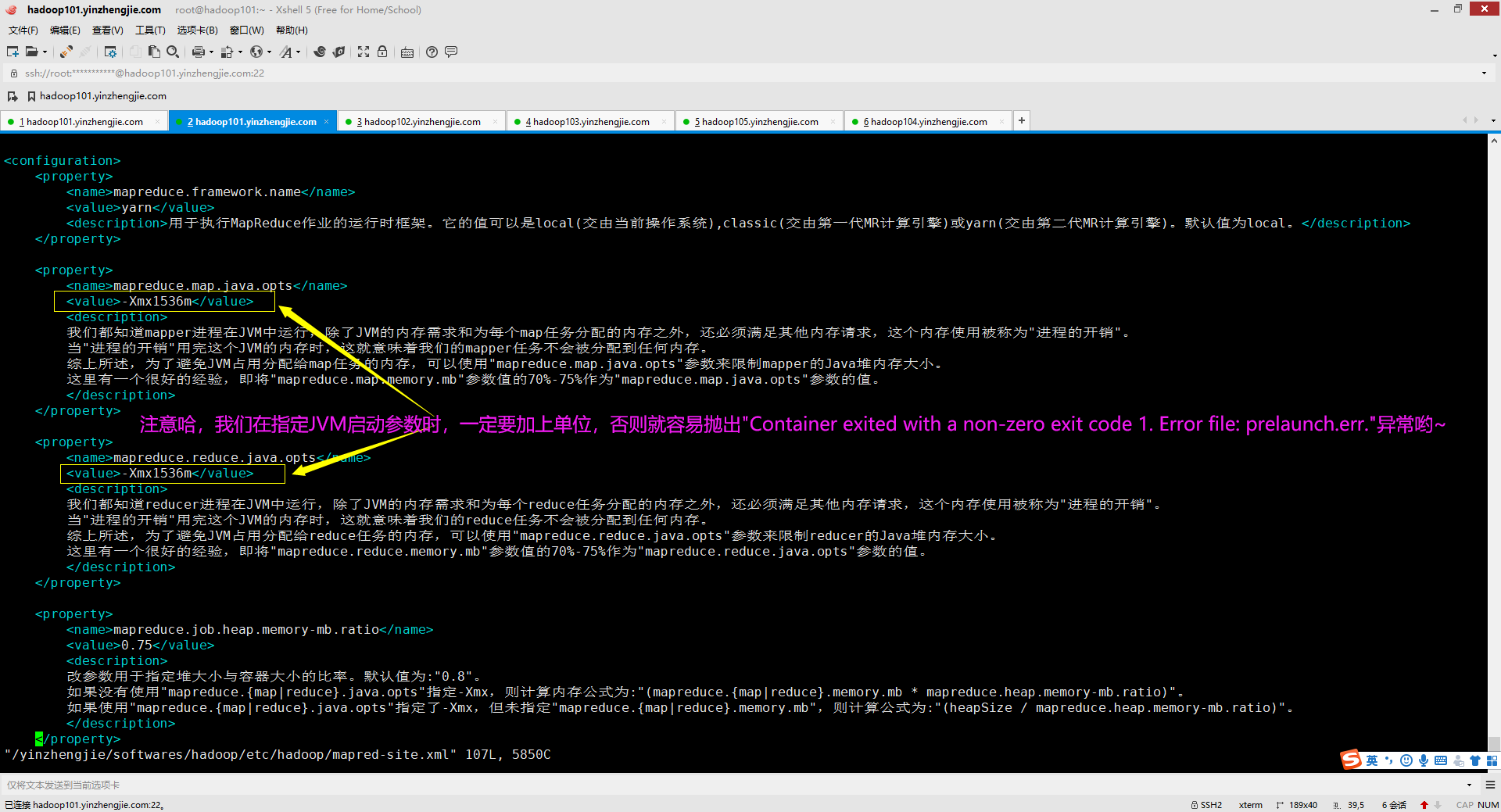
3>.解决方案
如下图所示,我们在指定JVM启动参数时,一定要加上单位,否则就容易抛出"Container exited with a non-zero exit code 1. Error file: prelaunch.err."异常哟~ 排除问题的方案: 我这里有个方法虽然笨,但无论遇到任何问题都可以用该方法来定位问题,那就是用排除法,即将配置正确的项保留,把配置不确定的项注释掉,如上图所示,我就是采用该方法来定位问题的。
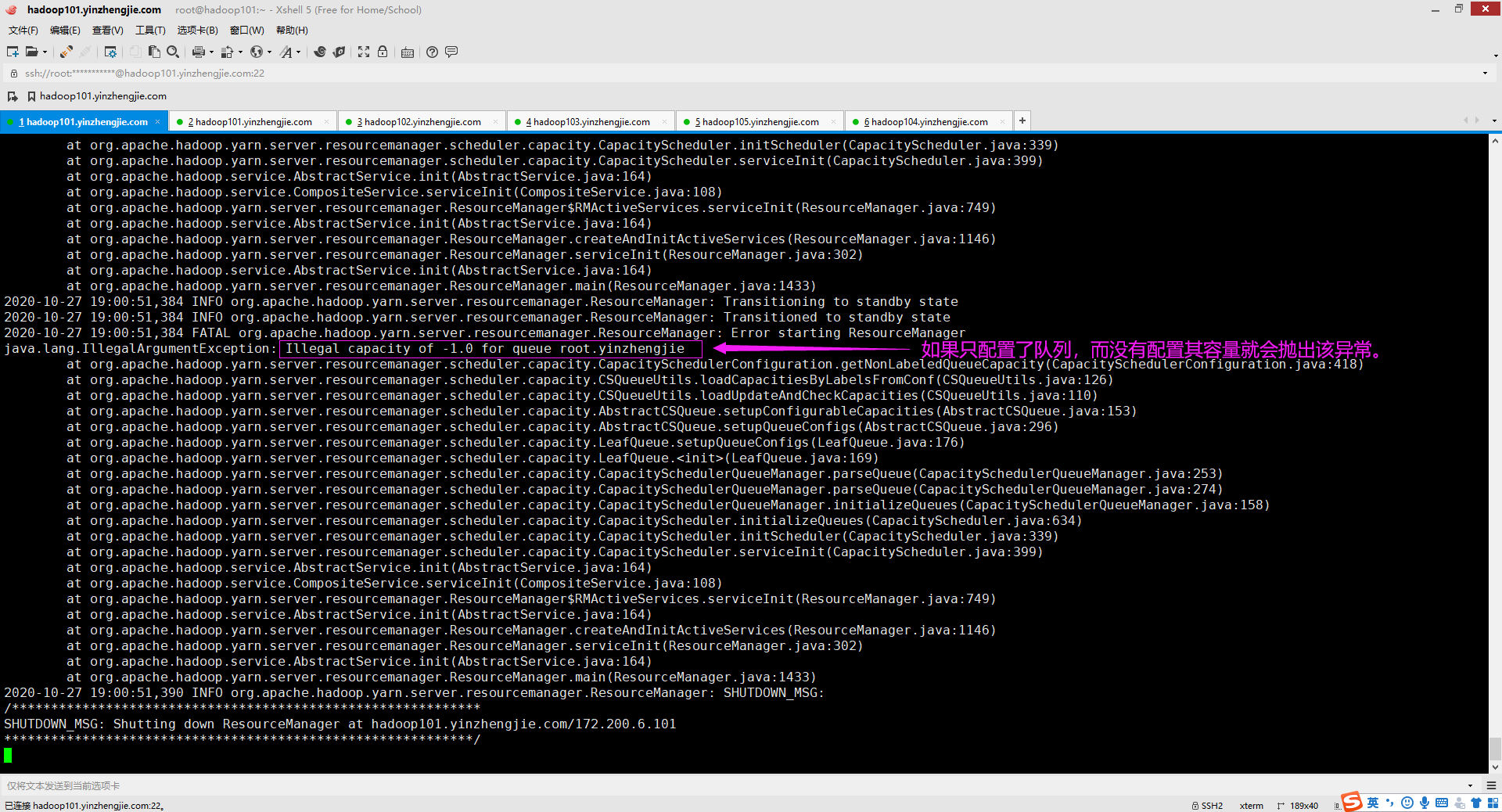
十三.java.lang.IllegalArgumentException: Illegal capacity of -1.0 for queue root.yinzhengjie
1>.错误复现
2>.错误原因
我们都知道Apache Hadoop的调度器默认是容量调度,因此我们需要为咱们定义的队列按照百分比配置其容量大小,若没有配置就会抛出异常。
3>.解决方案
![]()
既然知道错误原因在哪里了,那解决起来相对来说就比较简单了。如下所示,我为容量调度器指定了2个自顶级队列,分别为:"default"和"yinzhengjie"。 <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,yinzhengjie</value> <description>这是为root顶级队列定义子队列,默认值为:"default"</description> </property> 但光配置上面是不够的,我们还需要为队列分配容量,假设让"yinzhengjie"队列的容量是"default"队列容量的4倍,我们可以这样配置: <property> <name>yarn.scheduler.capacity.root.yinzhengjie.capacity</name> <value>80</value> <description>指定"yinzhengjie"队列的大小,这里指定的是一个"yinzhengjie"队列占"root"队列的百分比,即80%的资源</description> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>20</value> <description>指定"default"队列大小,占root队列的20%的资源</description> </property>
![]()
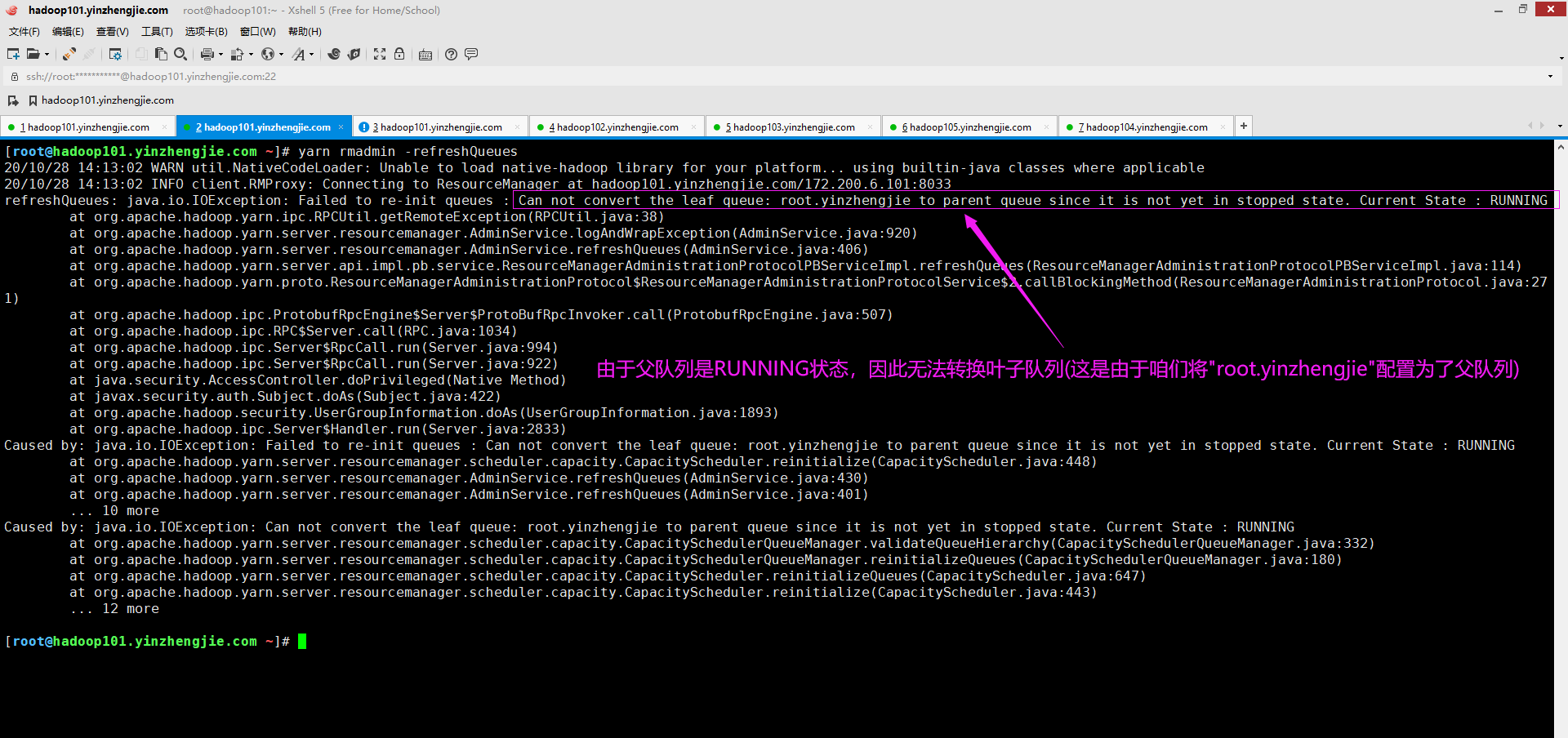
十四.refreshQueues: java.io.IOException: Failed to re-init queues : Can not convert the leaf queue: root.yinzhengjie to parent queue since it is not yet in stopped state. Current State : RUNNING
1>.错误复现
2>.错误原因
众所周知,我们仅能向容量调度器的叶子队列提交Job,而不能向父队列提交Job。 那么问题已经很明显了,是由于我们将现有的叶子队列更改为父队列导致的错误,因为叶子队列正在运行(其队列状态为:RUNNING),要想将一个队列设置为父队列,则其状态必须为STOPPED。
3>.解决方案
如果单纯解决该错误的话比较简单,要么还原配置,要么使得现有配置生效。 我们应该仔细检查配置文件,是否真的要按照配置文件执行,要使得现有配置文件生效,则必须让父队列由RUNNING状态变为STOPPED状态,最简单的办法就是重启YARN集群。 当然,通过检查配置文件发现,是由于你"手误"把配置文件配错了(也就是说配置语法没问题,但并不符合你之前设计的逻辑),这时候应该及时还原之前的配置,避免重启YARN集群导致此配置真的生效啦~
十五.Failed to re-init queues : The parent queue:yinzhengjie state is STOPPED, child queue:operation state cannot be RUNNING.
1>.错误复现
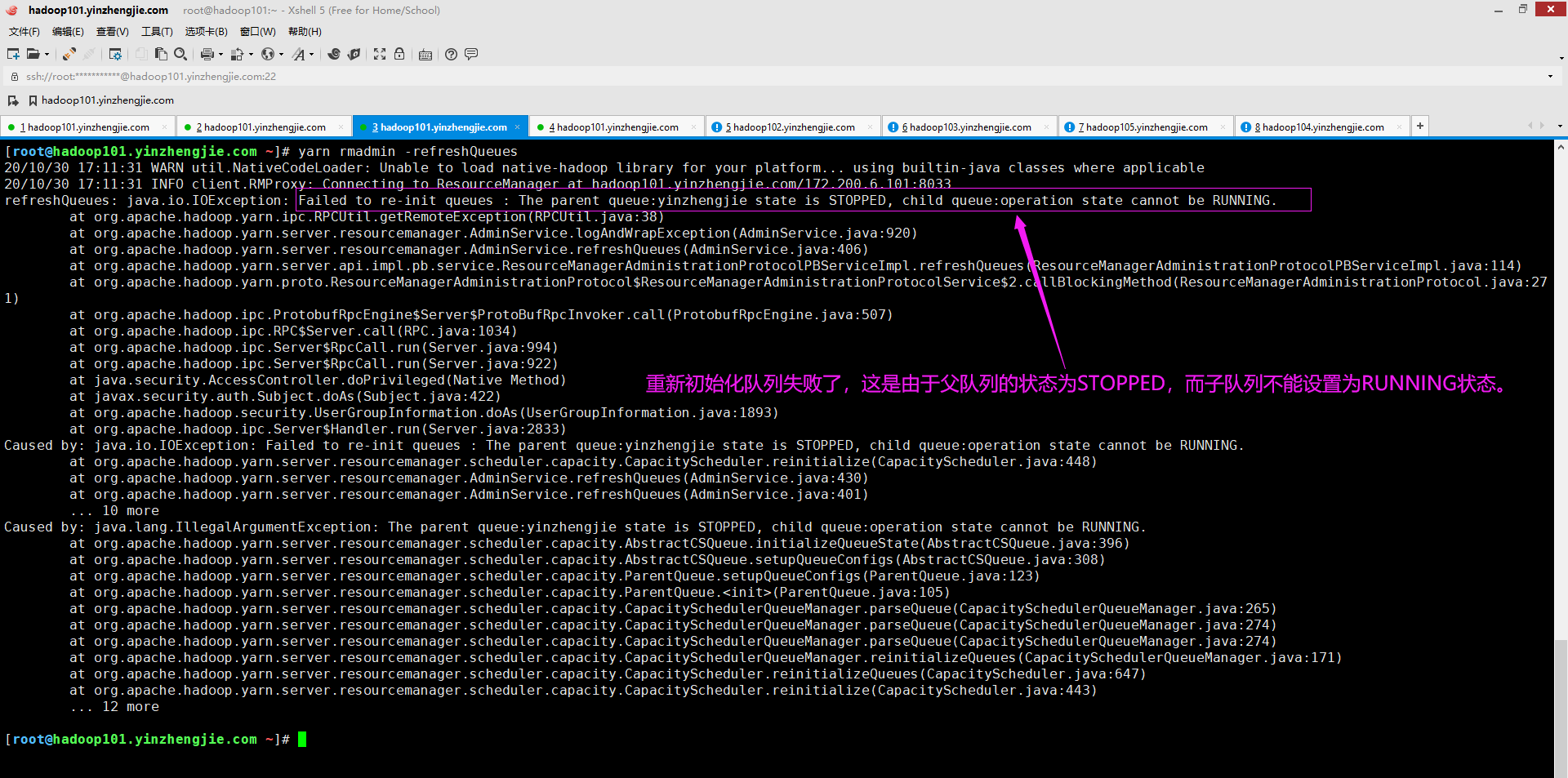
2>.错误原因分析
![]()
错误原因已经提示的很明显了,说是父队列状态为STOPPED状态,而子队列的状态为RUNNING状态。
仔细检查了文档"${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml"的配置内容如下(果真是将父队列设置为了STOPPED状态,而子队列设置为了"RUNNING"状态):
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
...
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.state</name>
<value>STOPPED</value>
<description>将"root.yinzhengjie"队列的状态设置为"RUNNING"状态</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.operation.state</name>
<value>RUNNING</value>
<description></description>
</property>
...
[root@hadoop101.yinzhengjie.com ~]#
![]()
3>.解决方案
![]()
解决方案就是仔细检查"${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml"的配置内容,观察你配置的队列其父队列是否为STOPPED状态。
若真想启用当前队列为RUNNING状态,则需要将其父队列改为RUNNING状态,当然,如果父队列为RUNNING状态,则子队列依旧是可以设置为STOPPED状态的哟~
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
...
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.state</name>
<value>RUNNING</value>
<description>将"root.yinzhengjie"队列的状态设置为"RUNNING"状态</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.yinzhengjie.operation.state</name>
<value>RUNNING</value>
<description></description>
</property>
...
[root@hadoop101.yinzhengjie.com ~]#
![]()
十六.Logs not available for job_1604871808583_0020. Aggregation may not be complete.
1>.错误复现
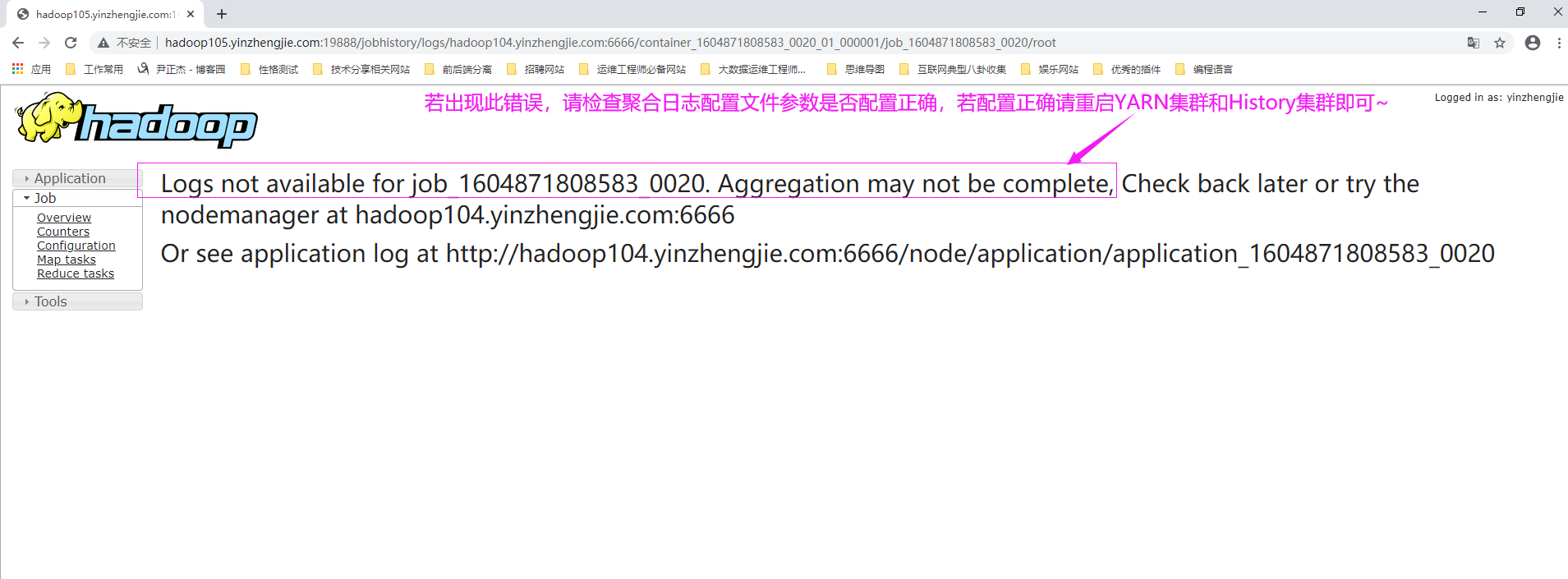
2>.错误原因分析
![]()
出现此错误可能有以下两种情况: (1)配置日志聚合的参数可能出现错误; (2)日志聚合的参数配置正确,但未重启YARN和HistoryServer服务。 温馨提示: 当配置启用日志聚合功能后,需要重启服务才能生效哟~
![]()
3>.解决方案
检查日志聚合相关参数是否配置正确,若配置正确请重启YARN集群和HistoryServer服务即可。
十七.
十八.
十九.ls: Failed on local exception: java.io.IOException: javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)];
1>.错误复现
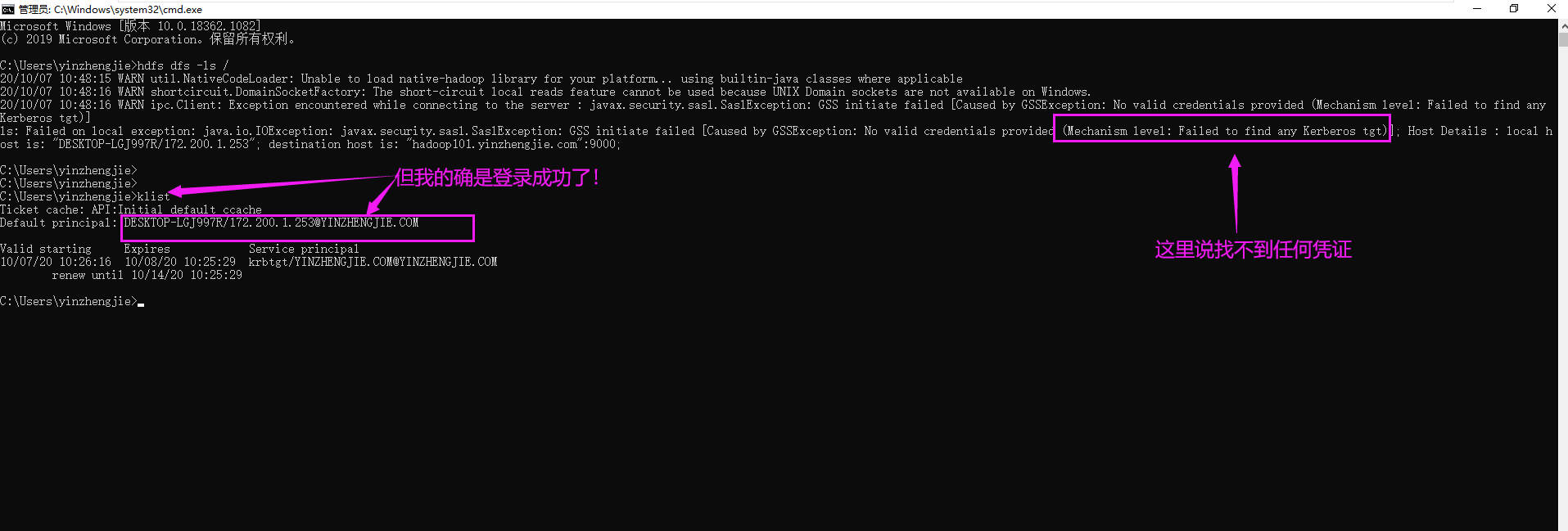
2>.错误原因分析
![]()
错误原因已经很明显了,说是找不到Kerberos凭证,但我的字符终端已经进行了Kerberos验证。首先排除时间同步问题,因为我的Windows主机和KDC服务器时间是同步的!其次排除票据过期问题,因为我的票据距离过期还有24小时! 于是我上网上找了很多文章,基本上解决思路如下面2个连接所示: https://community.cloudera.com/t5/Community-Articles/Alternate-days-why-do-i-see-GSSException-No-valid/ta-p/248378 https://aws.amazon.com/cn/premiumsupport/knowledge-center/kerberos-expired-ticket-emr/ 基本套路都是一样的,都是让先进性Kerberos认证,可问题在于我已经认证过了,依旧出现该问题!因此,本错误案例我没有找到错误原因,我初步怀疑和操作系统有关!因为同样的配置文件在Linux上做相同的操作的确是可以访问到数据的哟~
![]()
3>.解决方案
建议使用Linux操作系统进行尝试,因为Linux操作系统经过Kerberos验证成功后就可以正常访问HDFS集群,但是window操作系统目前还没有找到靠谱的解决方案。 有该问题的解决方案科请不吝赐教。可在博客出留言,谢谢~





![[题]欧拉函数 #欧拉函数](https://img-blog.csdnimg.cn/d7aa7888ca784610923212130c44d20c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_Q1NETiBAWS5ZTA==,size_38,color_FFFFFF,t_70,g_se,x_16)