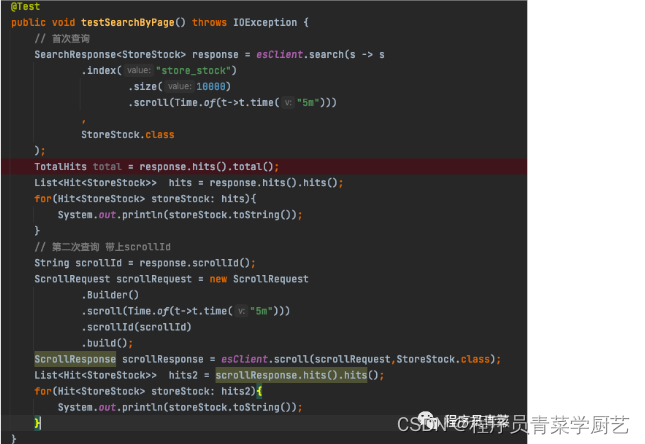
目录
1、前言
2、网络结构
(1)、Transformers的总体架构可以分为四部分
(2)、输入文本包含
(3)、输出部分包含
(4)、编码器部分
(5)、解码器部分
1、前言
处理序列任务的时候,首要的选择就是RNN。但是RNN主要思想就是把前一时刻的输出作为这一时刻的输入,因此导致RNN在训练过程中后一个时刻的输入依赖于前一个时刻的输出,无法进行并行处理,导致模型训练的速度慢,比CNN模型要慢几倍到十几倍。
后来又提出使用CNN来替代RNN,速度上确实取得了一定的优势,但在面对更长的序列的时候,CNN的卷积核限制了视野的大小,导致无法看到更全局的信息。
最后直到self-Attention层的出现,才解决了这样的问题,也就是后来的transformer。
2、网络结构
transformer的总体网络结构如图所示:

(1)、Transformers的总体架构可以分为四部分
- 输入部分
- 输出部分
- 编码器部分
- 解码器部分
(2)、输入文本包含
- 源文本嵌入层及其位置编码
- 目标文本嵌入层及其位置编码器

(3)、输出部分包含
- 线性层
- softmax层

(4)、编码器部分
- 由N 个编码器层堆叠而成
- 每个编码器是由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接

(5)、解码器部分
- 由N 个解码器层堆叠而成
- 每个编码器是由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接









![[02] Multi-sensor KIT: DSP 矩阵运算-加法,减法和逆矩阵,放缩,乘法和转置矩阵](https://img-blog.csdnimg.cn/5bdb682377664789b177f9edfffe3542.png)