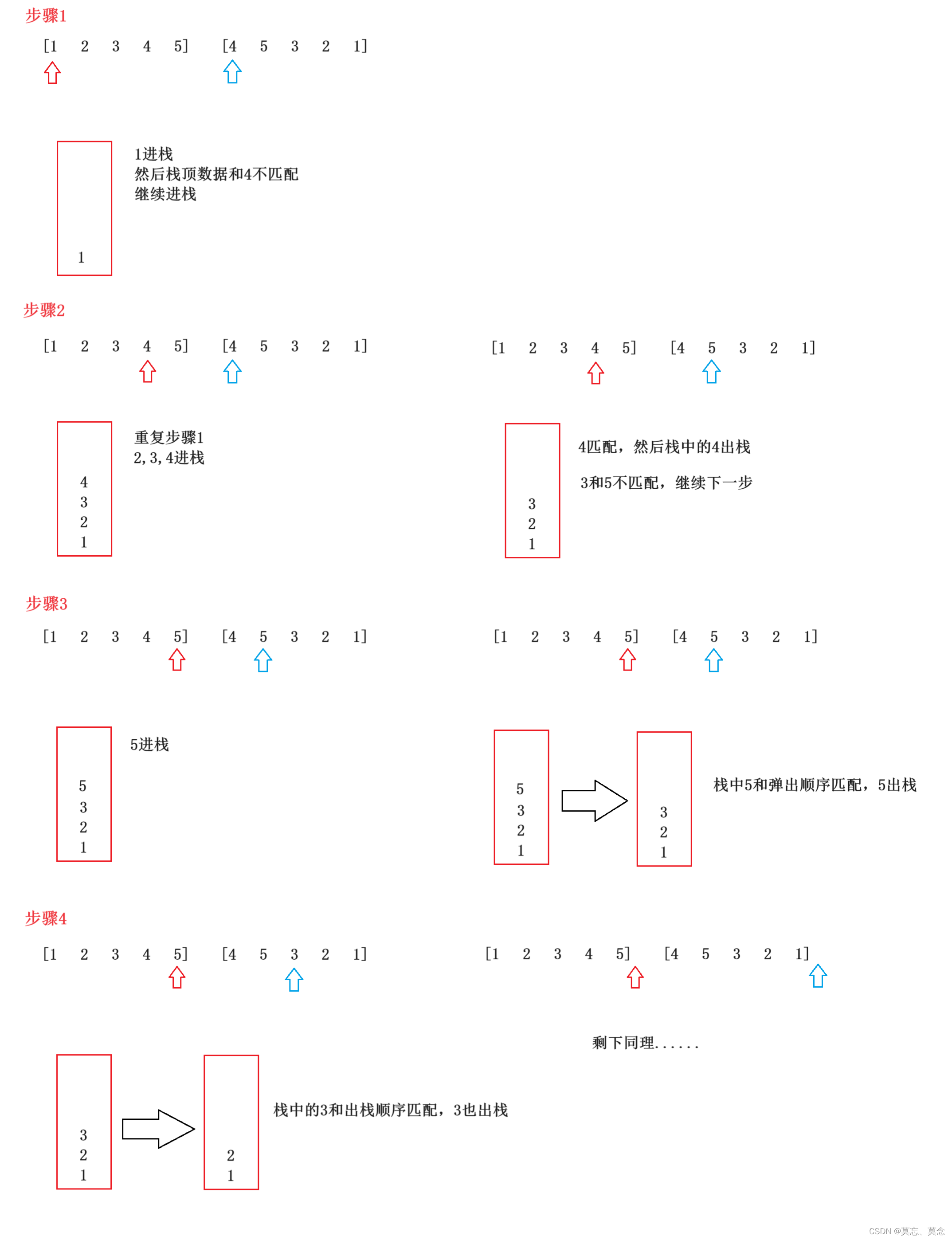
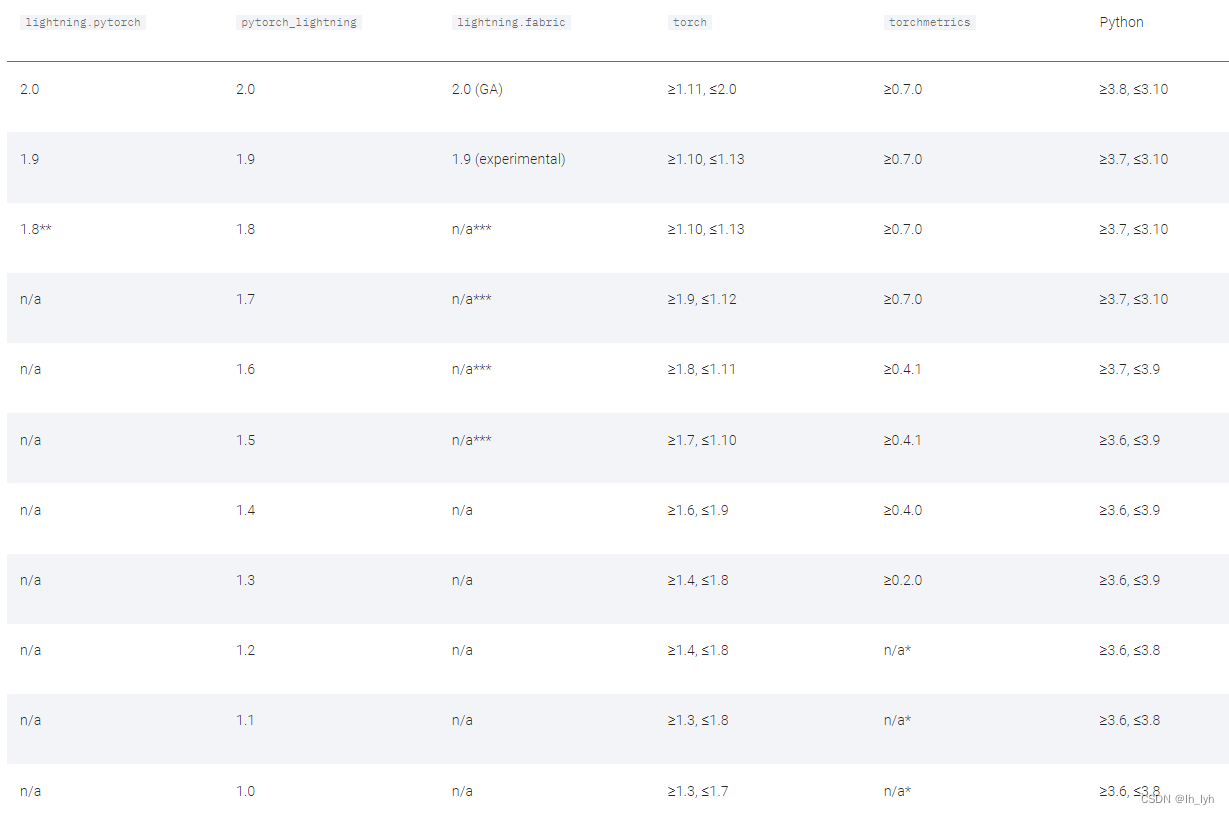
PyTorch深度学习实战(18)——目标检测
- 0. 前言
- 1. 目标检测
- 1.1 基本概念
- 1.2 目标检测应用
- 1.3 模型训练流程
- 2. 创建自定义目标检测数据集
- 2.1 安装图片标注工具
- 2.2 数据集标注
- 3. 区域提议
- 3.1 基本概念
- 3.2 利用 SelectiveSearch 生成区域提议
- 3.3 生成区域提议
- 4. 交并比
- 4.1 交并比概念
- 4.2 实现 IoU 计算函数
- 5. 非极大值抑制
- 6. 平均精度均值
- 小结
- 系列链接
0. 前言
目标检测是计算机视觉领域中的重要任务,旨在识别图像或视频中的特定类别物体,并确定它们的位置。与图像分类任务只需判断整个图像属于哪个类别不同,目标检测还需要标记出目标在图像中的边界框。例如在自动驾驶场景中,不仅需要检测道路图像是否包含车辆、人行道和行人,还需要确定它们在图像中的位置。目标检测的应用非常广泛,包括智能监控、自动驾驶、人脸识别、物体跟踪、图像搜索等。在本节中,将介绍目标检测的相关基础,使用 ybat 标记目标对象边界框,使用选择性搜索提取区域提议,并使用交并比 (Intersection over Union, IoU) 和平均精度均值度量边界框预测的准确性。
1. 目标检测
1.1 基本概念
目标检测 (Object Detection) 的目的是找出图像中所有感兴趣的目标(对象),并确定这些目标的类别和位置,是计算机视觉领域的核心问题之一。随着自动驾驶汽车、人脸检测和智能视频监控等应用的兴起,人们愈加重视更加快速、准确的目标检测系统。这些系统不仅需要对图像中的对象进行识别和分类,还需要通过在目标对象周围绘制适当的矩形框来定位图像中的每一个目标。目标检测的输出比图像分类更加复杂,可以通过下图明显看出两者之间的差别:

在上图中可以看出,图像分类仅简单地说明图像中存在的物体的类别,物体定位绘制边界框来标记图像中存在的物体,而目标检测需要在图像中每个物体周围绘制边界框并确定物体类别。
1.2 目标检测应用
目标检测能够在图像中存在的各种对象周围绘制边界框,在各个领域中有着广泛的应用,为各种视觉任务提供了重要的基础技术支持,包括:
- 智能安防:目标检测可以应用于安防监控系统中,实时检测人员、车辆或其他可疑物体的出现,用于安全警报、行为分析等
- 自动驾驶:目标检测是自动驾驶系统中的重要组成部分,用于识别和跟踪道路上的车辆、行人、交通信号灯等,以帮助车辆做出决策和规划行驶路径
- 人脸识别:目标检测可用于人脸识别系统中,检测人脸并确定其位置,进而提取特征进行身份验证或比对
- 物体跟踪:目标检测能够实现对特定物体在视频中的实时跟踪,如运动目标检测、运动轨迹分析等
- 图像搜索:通过目标检测,可以识别图像中的物体,并用于图像搜索引擎中的物体识别、相似图片推荐等功能
- 视频分析:目标检测可以应用于视频分析任务,如行为识别、活动监测、交通流量统计等
- 医学影像:目标检测可以用于医学影像中的疾病诊断,例如肿瘤检测、器官分割等
- 工业质检:目标检测可用于工业生产中的质量控制和缺陷检测,如产品表面缺陷检测、产品计数等
1.3 模型训练流程
通常,训练目标检测模型需要以下步骤:
- 数据收集和标注:收集包含目标物体的图像或视频数据,并进行标注,标记出目标物体的位置和类别,标注可以使用矩形边界框 (
bounding box),同时还可以标注目标的类别标签 - 数据预处理:对收集到的数据进行预处理,包括图像尺寸调整、颜色空间转换、图像增强等,还可以进行数据增强操作如镜像翻转、旋转、缩放等,以扩充数据集并提高模型的泛化能力
- 构建模型:选择合适的目标检测模型架构,根据任务需求和数据集特点,可以选择使用预训练模型作为基础,并对其进行微调或自定义模型结构
- 定义损失函数:根据目标检测任务的性质,定义适当的损失函数,常见的损失函数包括目标分类损失和边界框回归损失。通过最小化损失函数,优化模型参数,使其能够更准确地预测目标物体的位置和类别
- 模型训练:使用标注的数据集对目标检测模型进行训练,通过反向传播算法更新模型参数,不断优化模型的性能,训练过程中需要选择合适的学习率、批次大小等训练超参数,以平衡模型的收敛速度和泛化能力
- 模型评估和调优:使用验证集或测试集对训练好的模型进行评估,并根据评估结果进行模型的调优,常见的评估指标包括准确率 (
accuracy)、召回率 (recall)、精确率 (precision) 和平均精度均值 (mAP) 等 - 模型部署和应用:完成模型的训练和调优后,可以将其部署到生产环境中,用于实际目标检测任务的应用,在部署过程中,可能需要考虑模型的性能优化、硬件限制以及实时性等因素
2. 创建自定义目标检测数据集
目标检测能够输出图像中每个对象的类别及其边界框,为了训练模型,我们必须创建输入-输出数据,其中输入是图像,输出是给定图像中对象周围的边界框以及对象对应的类别。需要注意的是,检测检测边界框需要图像周围边界框四个角的像素位置。
为了训练目标检测模型,我们需要标记图像中所有对象的边界框坐标。在本节中,我们将学习创建训练数据集的方法,使用图像作为输入,图像中对象类别及其对应边界框存储在 XML 文件中作为输出。接下来,我们将使用 ybat 工具标注图像中对象的边界框和对应类别。此外,我们还将检查包含标注类别和边界框信息的 XML 文件。
2.1 安装图片标注工具
可以从 GitHub 中下载 ybat-master.zip 并解压。打开解压后的文件夹,使用浏览器打开 ybat.html,可以看到原始空白页面:

2.2 数据集标注
在开始创建图像对应的标注数据前,首先需要在 classes.txt 文件中存储的所有可能的类别,如下所示:

接下来,标注用于目标检测模型的训练数据集,包括在对象周围标注边界框,并为边界框中的对象分配类别标签:
- 上传需要要标注的所有图片
- 上传
classes.txt文件 - 选择需要标注的图像文件,然后在要标记的每个对象周围绘制边界框,并且要确保在绘制边界框前为边界框中的对象选择正确的类别(在
Classes区域中) - 以所需格式保存数据

例如,如果要保存为 PascalVOC 格式时,会以压缩文件的形式(.zip)下载 XML 文件,绘制矩形边界框后的 XML 文件内容如下:

从上图中可以看出,bndbox 字段包含与图像中感兴趣的对象对应的 x 和 y 坐标的最小值和最大值的坐标,可以使用 name 字段提取与图像中的对象对应的类别。
bndbox 字段包含了图像中感兴趣对象左上角坐标 (xmin 和 ymin 分别对应于 x 和 y 坐标)和右下角坐标 (xmax 和 ymax 分别对应于 x 和 y 坐标),通过 name 字段,我们可以提取出边界框中对象对应的类别标签,如 “person” 或 “car” 等。以上信息将用于训练目标检测模型以精确地识别和分类这些对象。
我们已经了解了如何标注图像中的对象(包括类别标签和边界框),接下来,我们将深入研究识别图像中对象的关键技术。首先,我们将介绍区域提议(图像中最有可能包含对象的区域)。
3. 区域提议
3.1 基本概念
区域提议 (Region Proposal) 是目标检测中的一项重要技术,用于生成可能包含目标物体的候选区域。假设在一张图像中,我们感兴趣的对象包含天空和人物,假设背景(天空)的像素强度变化不大,而前景(人)的像素强度变化很大。根据以上描述,我们可以得出以下结论,图像中包含两类区域:人和天空;在人的图像区域内,对应于头发的像素与对应于面部的像素具有不同的强度,因此说明一个区域内可以存在多个子区域。
区域提议可以用于识别像素相似的区域,这些区域的位置和大小通常是不确定的,因此需要使用区域提议算法来提出可能的位置和大小,以便进一步处理,区域提议可以帮助我们在目标检测中识别图像中存在的对象位置。此外,使用区域提议算法有助于目标对象定位,即确定一个完全适合图像中对象的边界框。
区域提议算法通常基于区域分割、合并方法,对输入图片进行分割,识别出可能存在目标的区域,然后将这些区域作为输入到后续的目标检测算法。区域提议可以加速目标检测的过程,因为目标检测算法可以只在这些可能包含目标的区域中执行,而不是全图扫描,从而提高检测速度。接下来,我们首先了解如何根据图像生成区域提议。
3.2 利用 SelectiveSearch 生成区域提议
选择性搜索 (Selective Search) 是一种经典的区域提议算法,用于生成可能包含目标物体的候选区域,基于图像分割和区域合并的思想,通过逐步合并相似的区域来生成候选区域。它的基本思想是通过对图像进行分层分组,生成不同尺度和大小的图像区域。这些区域被视为候选检测区域,以便后续的检测器可以针对这些区域进行进一步处理。Selective Search 算法通过以下操作生成候选区域:
- 将图像分割成多个区域,每个区域由相似的颜色、纹理和结构特征组成
- 使用图像分割结果形成初始的候选区域集合
- 计算候选区域之间的相似度,并将相似度最高的候选区域合并成更大的区域,更新候选区域集合
SelectiveSearch根据不同尺度和比例下的相似性将区域进行多次合并,得到一组更精细的候选区域- 重复执行第
3和第4步,得到一组不重叠且可靠的候选区域
SelectiveSearch 算法的优点在于它可以生成高质量的候选区域,并且具有较好的鲁棒性,适用于多种目标检测任务。接下来,我们使用 Python 实现选择性搜索的过程。
在 Python 中,Selective Search for Object Recognition (selectivesearch) 是常用的选择性搜索算法库,能够方便地使用选择性搜索算法生成候选区域。
(1) 安装所需的库:
pip install selectivesearch
(2) 加载图像以及所需库:
import selectivesearch
from skimage.segmentation import felzenszwalb
import cv2
from matplotlib import pyplot as plt
import numpy as np
img_r = cv2.imread('4.jpeg')
img = cv2.cvtColor(img_r, cv2.COLOR_BGR2GRAY)
(3) 基于图像的颜色、纹理、大小和形状,从图像中提取 felzenszwalb 分割:
segments_fz = felzenszwalb(img, scale=200)
在 felzenszwalb 方法中,scale 代表可以在图像分割中形成的聚类数,scale 的数值越高,保留原始图像细节的程度就越高。换句话说,scale 值越高,生成的分割内容越精细。
(4) 绘制原始图像和分割后的图像:
plt.figure(figsize=(10,10))
plt.subplot(121)
plt.imshow(cv2.cvtColor(img_r, cv2.COLOR_BGR2RGB))
plt.title('Original Image')
plt.subplot(122)
plt.imshow(segments_fz)
plt.title('Image post \nfelzenszwalb segmentation')
plt.show()

从以上输出可以看出,属于同一组的像素在分割结果图中具有相似的像素值。具有相似值的像素构成一个区域提议。使用区域提议有助于目标检测,因为我们可以将每个区域提议传递给网络并预测区域提议是背景还是目标对象。此外,如果区域提议是一个目标对象,该区域可以用于识别偏移量以获取与对象边界框以及与区域提议中的内容对应的类别。了解了 SelectiveSearch 算法原理后,我们使用选择性搜索函数来获取给定图像的区域提议。
3.3 生成区域提议
在本节中,我们将使用选择性搜索定义 extract_candidates 函数,以便为后续的目标检测模型训练奠定基础。
(1) 定义从图像中提取区域提议的函数 extract_candidates()。
将图像作为输入参数:
def extract_candidates(img):
使用 selectivesearch 库中提供的 selective_search 方法获取图像中的候选区域:
img_lbl, regions = selectivesearch.selective_search(img, scale=200, min_size=2000)
计算图像区域并初始化一个列表(候选区域),使用该列表来存储通过定义阈值的候选区域:
candidates = []
仅获取超过图像总面积 5% 且不超过图像面积 100% 的区域作为候选区域并返回:
for r in regions:
if r['rect'] in candidates:
continue
if r['size'] < (0.05*img_area):
continue
if r['size'] > (1*img_area):
continue
x, y, w, h = r['rect']
candidates.append(list(r['rect']))
return candidates
(2) 导入相关库与图像:
img = cv2.imread('4.jpeg')
candidates = extract_candidates(img)
(3) 提取候选区域在图像上可视化:
import matplotlib.patches as mpatches
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))
ax.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
for x, y, w, h in candidates:
rect = mpatches.Rectangle(
(x, y), w, h,
fill=False,
edgecolor='red',
linewidth=1)
ax.add_patch(rect)
plt.show()

上图中的网格表示使用 selective_search 方法获取的区域提议(候选区域)。
我们已经了解了如何生成区域提议,接下来,继续学习如何利用区域提议进行目标检测和定位。一个区域提议如果与图像中的任意一个目标对象位置有很高的重合面积,就会被标记为包含该对象的提议,而与其交集很小的区域提议将被标记为背景。在下一节中,我们将介绍如何计算候选区域与真实边界框的交集。
4. 交并比
4.1 交并比概念
交并比 (Intersection over Union, IoU) 是常用的评估目标检测和图像分割算法性能的指标,用于度量两个区域之间的重叠程度。在目标检测中,IoU 是通过计算预测边界框与真实边界框之间的交集和并集之比来衡量预测框与真实框之间的相似程度。
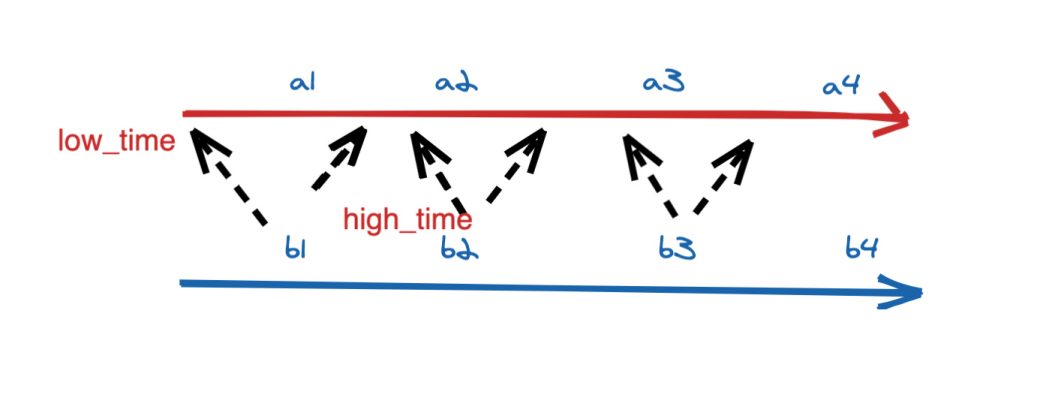
Intersection over Union 中的 Intersection 计算预测的边界框和实际边界框的重叠面积,而 Union 计算预测的边界框和实际边界框的组合面积,IoU 是两个边界框之间的重叠区域与两个边界框的组合区域之比,如下图所示:

在上图中,蓝色边界框作为真实边界框,红色边界框作为预测边界框,IoU 是两个边界框之间的重叠区域与组合区域的比值。在下图中,可以观察到随着边界框之间重叠程度的变化,IoU 指标的变化情况:

从上图中,可以看到随着重叠区域的减少,IoU 也随之减少,当两个边界框没有重叠时,IoU 值为 0。了解了 IoU 的计算原理后,我们使用 Python 创建一个计算 IoU 的函数,以便在目标检测模型中使用。
4.2 实现 IoU 计算函数
定义函数,将两个边界框作为输入并返回 IoU 作为输出。
(1) 定义 get_iou() 函数,将 boxA 和 boxB 作为输入,其中 boxA 和 boxB 是两个不同的边界框(可以将 boxA 视为真实边界框,将 boxB 视为区域提议):
def get_iou(boxA, boxB, epsilon=1e-5):
我们需要额外定义 epsilon 参数来解决两个边界框之间的并集为 0 时的情况,以避免出现除零错误。
(2) 计算交集框坐标:
x1 = max(boxA[0], boxB[0])
y1 = max(boxA[1], boxB[1])
x2 = min(boxA[2], boxB[2])
y2 = min(boxA[3], boxB[3])
x1 存储了两个边界框之间最左侧 x 坐标的最大值,y1 存储最上面的 y 坐标的最大值,x2 和 y2 分别存储了两个边界框之间最右边的 x 坐标和最底部的 y 坐标的最小值,对应于两个边界框间的相交部分。
(3) 计算相交区域(重叠区域)对应的宽和高:
width = (x2 - x1)
height = (y2 - y1)
(4) 计算重叠面积 (area_overlap):
if (width<0) or (height <0):
return 0.0
area_overlap = width * height
在以上代码中,指定如果重叠区域对应的宽度或高度小于 0,则相交的面积为 0。否则,重叠(相交)面积等于相交区域的宽度乘以高度。
(5) 计算两个边界框对应的组合面积:
area_a = (boxA[2] - boxA[0]) * (boxA[3] - boxA[1])
area_b = (boxB[2] - boxB[0]) * (boxB[3] - boxB[1])
area_combined = area_a + area_b - area_overlap
在以上代码中,计算两个边界框的组合面积,首先计算 area_a+area_b,然后在计算 area_combined 时减去重叠区域 area_overlap,因为 area_overlap 被计算两次(计算 area_a 时计算一次,计算 area_b 时计算一次)。
(6) 计算 IoU 并返回:
iou = area_overlap / (area_combined+epsilon)
return iou
在以上代码中,将 iou 计算为重叠面积 (area_overlap) 与组合面积 (area_combined) 之比并返回。
我们已经了解了如何创建训练数据集和IoU的计算,接下来,我们将学习非极大值抑制,它有助于去除模型预测时得到的冗余预测框,从对象周围不同的可能边界框中筛选出最具代表性的候选框。
5. 非极大值抑制
在目标检测中,常常会得到多个预测框(如区域提议),这些预测框可能彼此重叠的。例如,在下图中,图像中的人物周围生成了多个区域提议:

使用非极大值抑制 (non-maximum suppression, NMS) 能够从多个候选区域中识别出包含目标对象的边界框,并将其它边界框丢弃。非极大值 (Non-maximum) 指的是那些未包含最高概率(但包含目标对象)的框,而抑制 (Suppression) 是指丢弃那些不包含最高概率(但包含目标对象)的框。在非极大值抑制中,我们会识别出具有最高概率的边界框,并丢弃所有其他与该边界框的 IoU 大于某个阈值的边界框,这些边界框的概率较低,可能不包含对象。
在 PyTorch 中,使用 torchvision.ops 模块中的 nms 函数可以执行非极大值抑制。nms 函数根据边界框坐标、物体在边界框内的置信度以及 IoU 阈值来识别要保留的边界框。使用非极大值抑制可以避免得到过多的冗余检测结果,提高检测效率,同时也可以减少误检和漏检。
6. 平均精度均值
mAP (mean Average Precision) 表示平均精度均值,是一种常用的评估目标检测算法性能的指标。它综合考虑了不同类别的精度,并对检测结果进行排序和阈值设定。接下来,我们首先解释精度,然后介绍平均精度,最后讲解 mAP 的计算方法。
精度 (Precision) 计算公式如下:
P
r
e
c
i
s
i
o
n
=
T
r
u
e
P
o
s
i
t
i
v
e
T
r
u
e
P
o
s
i
t
i
v
e
+
F
a
l
s
e
P
o
s
i
t
i
v
e
Precision=\frac{True\ Positive}{True\ Positive+False\ Positive}
Precision=True Positive+False PositiveTrue Positive
真正例 (True Positive) 是指预测的边界框正确地预测出了相应的目标类别,并且与真实边界框的交并比 (IoU) 大于给定阈值;假正例 (False Positive) 是指预测的边界框错误地预测出了目标类别或者与真实边界框的交并比低于定义的阈值。此外,如果同一个真实边界框有多个预测边界框,只有一个边界框能定义为真正例,其余边界框归为假正例。
平均精度 (Average Precision, AP) 表示在不同 IoU 阈值下计算出的精度值的平均值,mAP 是数据集中所有目标类别在不同 IoU 阈值下计算出的精度值的平均值。
小结
目标检测是计算机视觉领域中的重要任务,它旨在从图像或视频中准确地定位和识别出感兴趣的目标物体,目标是将输入图像中的目标区域框出,并为每个目标提供正确的类别标签,在许多应用领域都有广泛的应用,包括智能监控、自动驾驶、人脸识别等。在本节中,介绍了如何利用 ybat 准备训练数据集、使用 SelectiveSearch 库实现区域提议算法、对模型的预测执行非极大值抑制以及衡量模型性能。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习