文章目录
Interval Join(时间区间 Join)
Interval Join(时间区间 Join)
Interval Join 定义(支持 Batch\Streaming):Interval Join 在离线的概念中是没有的。Interval Join 可以让一条流去 Join 另一条流中前后一段时间内的数据。
应用场景:为什么有 Regular Join 还要 Interval Join 呢?刚刚的案例也讲了,Regular Join 会产生回撤流,但是在实时数仓中一般写入的 sink 都是类似于 Kafka 这样的消息队列,然后后面接 clickhouse 等引擎,这些引擎又不具备处理回撤流的能力。所以可以理解 Interval Join 就是用于消灭回撤流的。
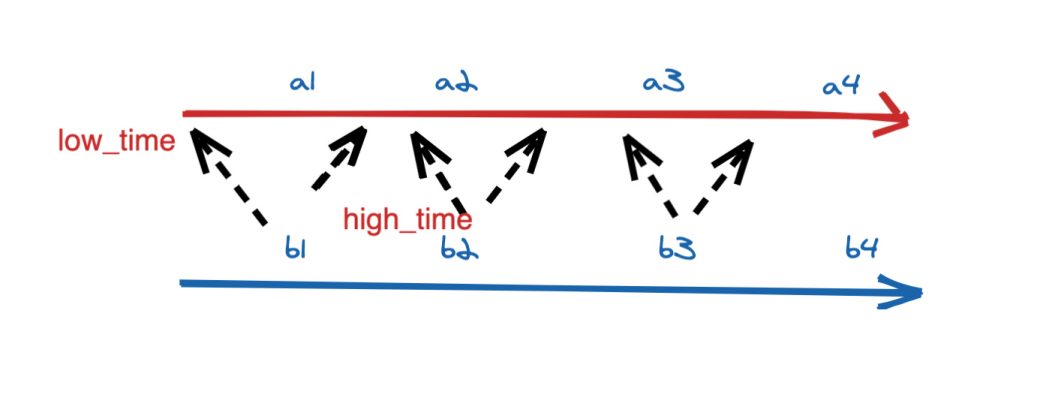
Interval Join 包含以下几种(以 L 作为左流中的数据标识,R 作为右流中的数据标识):
- Inner Interval Join:流任务中,只有两条流 Join 到(满足 Join on 中的条件:两条流的数据在时间区间 + 满足其他等值条件)才输出,输出 +[L, R]
- Left Interval Join:流任务中,左流数据到达之后,如果没有 Join 到右流的数据,就会等待(放在 State 中等),如果之后右流之后数据到达之后,发现能和刚刚那条左流数据 Join 到,则会输出 +[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间)。如果发现发现左流 State 中的数据过期了,就把左流中过期的数据从 State 中删除,然后输出 +[L, null],如果右流 State 中的数据过期了,就直接从 State 中删除。
- Right Interval Join:和 Left Interval Join 执行逻辑一样,只不过左表和右表的执行逻辑完全相反
- Full Interval Join:流任务中,左流或者右流的数据到达之后,如果没有 Join 到另外一条流的数据,就会等待(左流放在左流对应的 State 中等,右流放在右流对应的 State 中等),如果之后另一条流数据到达之后,发现能和刚刚那条数据 Join 到,则会输出 +[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间),发现 State 中的数据能够过期了,就将这些数据从 State 中删除并且输出(左流过期输出 +[L, null],右流过期输出 -[null, R])
可以发现 Inner Interval Join 和其他三种 Outer Interval Join 的区别在于,Outer 在随着时间推移的过程中,如果有数据过期了之后,会根据是否是 Outer 将没有 Join 到的数据也给输出。
使用示例:
间隔联接需要至少一个等联接谓词和在两侧限制时间的联接条件。可以通过比较两个输入表中相同类型的时间属性(即处理时间或事件时间)的两个适当的范围谓词(<, <=, >=, >)BETWEEN谓词或单个相等谓词来定义这种条件。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.orderId AND
o.ordertime BETWEEN s.shiptime - INTERVAL '4' HOUR AND s.shiptime如果订单在收到订单后四个小时内发货,则上面的示例会将所有订单与其相应的发货合并在一起。
实际案例:还是刚刚的案例,曝光日志关联点击日志筛选既有曝光又有点击的数据,条件是曝光关联之后发生 4 小时之内的点击,并且补充点击的扩展参数(show inner interval click):
下面为 Inner Interval Join:
Flink SQL> CREATE TABLE show_log_table (
log_id BIGINT,
show_params STRING,
`timestamp` bigint,
row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),
watermark for row_time as row_time
) WITH (
'connector' = 'socket',
'hostname' = 'node1',
'port' = '8888',
'format' = 'csv'
);
Flink SQL> CREATE TABLE click_log_table (
log_id BIGINT,
click_params STRING,
`timestamp` bigint,
row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),
watermark for row_time as row_time
)
WITH (
'connector' = 'socket',
'hostname' = 'node1',
'port' = '9999',
'format' = 'csv'
);
Flink SQL> SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
INNER JOIN click_log_table ON show_log_table.log_id = click_log_table.log_id
AND show_log_table.row_time BETWEEN click_log_table.row_time - INTERVAL '10' SECOND AND click_log_table.row_time;开启netcat的8888端口,输入数据:
1,hadoop,1658300800 ->2022-07-20 15:06:40开启netcat的9999端口,输入数据:
1,zhangsan,1658300805 ->2022-07-20 15:06:45输出结果如下:
s_id s_params c_id c_params
1 hadoop 1 zhangsan9999端口,继续输入数据:
1,zhangsan,1658300811 -> 2022-07-20 15:06:51
输出结果没有反应,因为这个时间:2022-07-20 15:06:51超过了时间区间下限。
如果是 Left Interval Join:
Flink SQL> SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
LEFT JOIN click_log_table ON show_log_table.log_id = click_log_table.log_id
AND show_log_table.row_time BETWEEN click_log_table.row_time - INTERVAL '5' SECOND AND click_log_table.row_time + INTERVAL '5' SECOND;开启netcat的8888端口,输入数据:
1,hadoop,1658300800 ->2022-07-20 15:06:40开启netcat的9999端口,输入数据:
1,zhangsan,1658300805 ->2022-07-20 15:06:45输出结果如下:
s_id s_params c_id c_params
1 hadoop 1 zhangsan8888端口,继续输入数据:
1,hadoop,1658300801 ->2022-07-20 15:06:41
1,hadoop,1658300811 ->2022-07-20 15:06:51输出结果如下:
s_id s_params c_id c_params
1 hadoop 1 zhangsan
1 hadoop 1 zhangsan2022-07-20 15:06:51这条数据不会有任何的输出,因为已经超过了右表的边界。
如果是 Full Interval Join:
Flink SQL> SELECT
show_log_table.log_id as s_id,
show_log_table.show_params as s_params,
click_log_table.log_id as c_id,
click_log_table.click_params as c_params
FROM show_log_table
FULL JOIN click_log_table ON show_log_table.log_id = click_log_table.log_id
AND show_log_table.row_time BETWEEN click_log_table.row_time - INTERVAL '5' SECOND AND click_log_table.row_time + INTERVAL '5' SECOND;开启netcat的8888端口,输入数据:
1,hadoop,1658300800 ->2022-07-20 15:06:40
1,hadoop,1658300801 ->2022-07-20 15:06:41开启netcat的9999端口,输入数据:
1,zhangsan,1658300805 ->2022-07-20 15:06:45
1,zhangsan,1658300811 ->2022-07-20 15:06:51输出结果如下:
s_id s_params c_id c_params
1 hadoop 1 zhangs
1 hadoop 1 zhangsan- 关于 Interval Join 的注意事项:
实时 Interval Join 可以不是 等值 join。等值 join 和 非等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,然后将满足条件的数据进行关联输出
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨