数据库其它调优策略
1. 数据库调优的措施
1.1 调优的目标
- 尽可能节省系统资源,以便系统可以提供更大负荷的服务。(吞吐量更大)
- 合理的结构设计和参数调整,以提高用户操作响应的速度。(响应速度更快)
- 减少系统的瓶颈,提高MySQL数据库整体的性能。
1.2 如何定位调优问题
- 用户的反馈(主要)
- 日志分析(主要)
- 服务器资源使用监控
- 数据库内部状况监控
- 其它
1.3 调优的维度和步骤
第1步:选择适合的 DBMS
第2步:优化表设计
第3步:优化逻辑查询
第4步:优化物理查询
物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等),通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。
第5步:使用 Redis 或 Memcached 作为缓存
因为数据都是存放到数据库中,我们需要从数据库层中取出数据放到内存中进行业务逻辑的操作,当用户量增大的时候,如果频繁地进行数据查询,会消耗数据库的很多资源。如果我们将常用的数据直接放到内存中,就会大幅提升查询的效率。
键值存储数据库可以帮我们解决这个问题。
常用的键值存储数据库有 Redis 和 Memcached,它们都可以将数据存放到内存中。
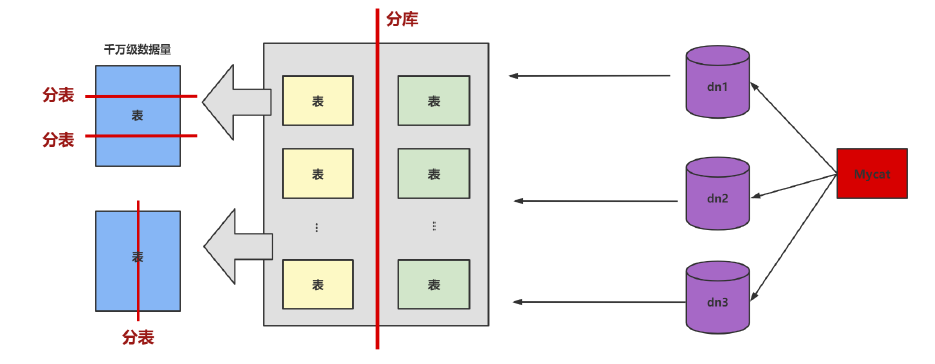
第6步:库级优化
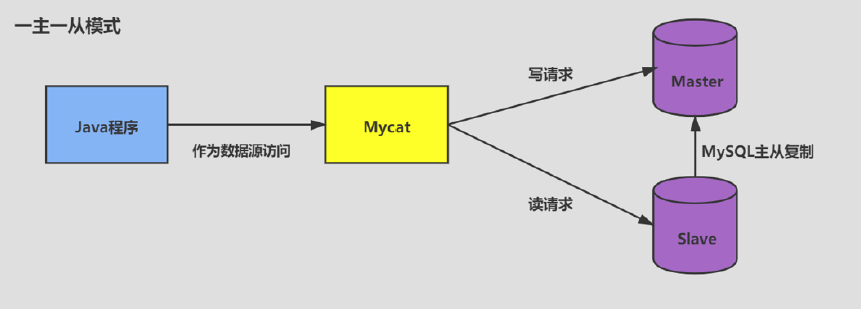
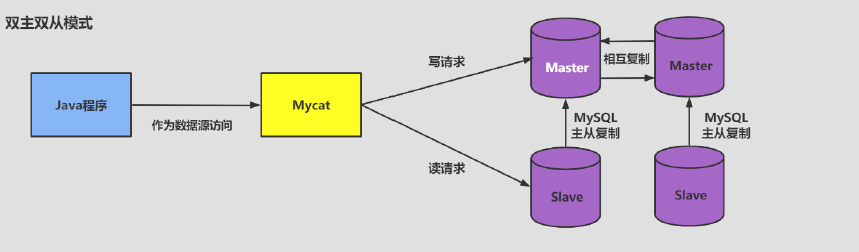
1、读写分离
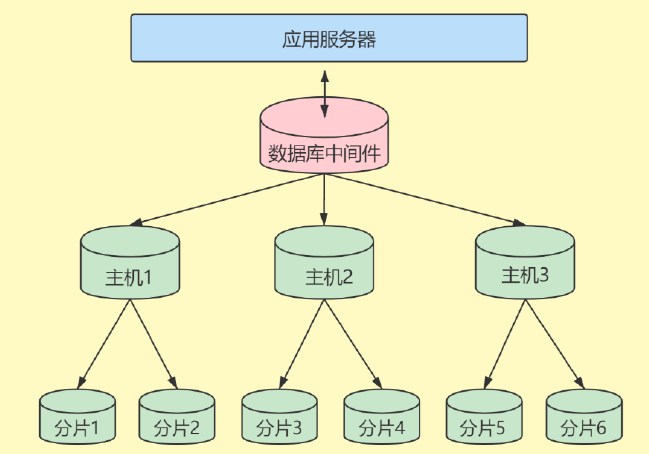
2、数据分片
2. 优化MySQL服务器
2.1 优化服务器硬件
服务器的硬件性能直接决定着MySQL数据库的性能。硬件的性能瓶颈直接决定MySQL数据库的运行速度和效率。针对性能瓶颈提高硬件配置,可以提高MySQL数据库查询、更新的速度。 (1) 配置较大的内存 (2) 配置高速磁盘系统 (3) 合理分布磁盘I/O (4) 配置多处理器
2.2 优化MySQL的参数
-
innodb_buffer_pool_size:这个参数是Mysql数据库最重要的参数之一,表示InnoDB类型的表和索引的最大缓存。它不仅仅缓存索引数据,还会缓存表的数据。这个值越大,查询的速度就会越快。但是这个值太大会影响操作系统的性能。 -
key_buffer_size:表示索引缓冲区的大小。索引缓冲区是所有的线程共享。增加索引缓冲区可以得到更好处理的索引(对所有读和多重写)。当然,这个值不是越大越好,它的大小取决于内存的大小。如果这个值太大,就会导致操作系统频繁换页,也会降低系统性能。对于内存在4GB 左右的服务器该参数可设置为256M 或384M 。 -
table_cache:表示同时打开的表的个数。这个值越大,能够同时打开的表的个数越多。物理内存越大,设置就越大。默认为2402,调到512-1024最佳。这个值不是越大越好,因为同时打开的表太多会影响操作系统的性能 -
query_cache_size:表示查询缓冲区的大小。可以通过在MySQL控制台观察,如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,就要增加Query_cache_size的值;如果Qcache_hits的值非常大,则表明查询缓冲使用非常频繁,如果该值较小反而会影响效率,那么可以考虑不用查询缓存;Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。MySQL8.0之后失效。该参数需要和query_cache_type配合使用 -
query_cache_type的值是0时,所有的查询都不使用查询缓存区。但是query_cache_type=0并不会导致MySQL释放query_cache_size所配置的缓存区内存- 当
query_cache_type=1时,所有的查询都将使用查询缓存区,除非在查询语句中指定SQL_NO_CACHE ,如SELECT SQL_NO_CACHE * FROM tbl_name - 当
query_cache_type=2时,只有在查询语句中使用SQL_CACHE 关键字,查询才会使用查询缓存区。使用查询缓存区可以提高查询的速度,这种方式只适用于修改操作少且经常执行相同的查询操作的情况
- 当
-
sort_buffer_size:表示每个需要进行排序的线程分配的缓冲区的大小。增加这个参数的值可以提高ORDER BY 或GROUP BY 操作的速度。默认数值是2 097 144字节(约2MB)。对于内存在4GB左右的服务器推荐设置为6-8M,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 6= 600MB。 -
join_buffer_size= 8M :表示联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。 -
read_buffer_size:表示每个线程连续扫描时为扫描的每个表分配的缓冲区的大小(字节) 。当线程从表中连续读取记录时需要用到这个缓冲区。SET SESSION read_buffer_size=n可以临时设置该参数的值。默认为64K,可以设置为4M -
innodb_flush_log_at_trx_commit:表示何时将缓冲区的数据写入日志文件,并且将日志文件写入磁盘中。该参数对于innoDB引擎非常重要。该参数有3个值,分别为0、1和2。该参数的默认值为1 -
值为1 时,表示每次提交事务时将数据写入日志文件并将日志文件写入磁盘进行同步。该模式是最安全的,但也是最慢的一种方式。因为每次事务提交或事务外的指令都需要把日志写入(flush)硬盘。
-
值为2 时,表示每次提交事务时将数据写入日志文件, 每隔1秒将日志文件写入磁盘。该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失
-
innodb_log_buffer_size:这是 InnoDB 存储引擎的事务日志所使用的缓冲区。为了提高性能,也是先将信息写入 Innodb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中 -
max_connections:表示允许连接到MySQL数据库的最大数量,默认值是 151 。如果状态变量connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections 的值。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。这个连接数不是越大越好,因为这些连接会浪费内存的资源。过多的连接可能会导致MySQL服务器僵死 -
back_log:用于控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 对于Linux系统推荐设置为小于512的整数,但最大不超过900。如果需要数据库在较短的时间内处理大量连接请求, 可以考虑适当增大back_log 的值。 -
thread_cache_size: 线程池缓存线程数量的大小,当客户端断开连接后将当前线程缓存起来,当在接到新的连接请求时快速响应无需创建新的线程 。这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。那么为了提高性能可以增大该参数的值。默认为60,可以设置为120。
可以通过如下几个MySQL状态值来适当调整线程池的大小:
mysql> show global status like 'Thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 2 |
| Threads_connected | 1 |
| Threads_created | 3 |
| Threads_running | 2 |
+-------------------+-------+
4 rows in set (0.01 sec)
当 Threads_cached 越来越少,但 Threads_connected 始终不降,且 Threads_created 持续升高,可适当增加 thread_cache_size 的大小。
- wait_timeout :指定一个请求的最大连接时间,对于4GB左右内存的服务器可以设置为5-10
- interactive_timeout :表示服务器在关闭连接前等待行动的秒数
这里给出一份my.cnf的参考配置:
[mysqld]
port = 3306 serverid = 1 socket = /tmp/mysql.sock skip-locking #避免MySQL的外部锁定,减少
出错几率增强稳定性。
skip-name-resolve #禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权要使用IP地址方式,否则MySQL将无法正常处理连接请求!
back_log = 384
key_buffer_size = 256M
max_allowed_packet = 4M
thread_stack = 256K
table_cache = 128K
sort_buffer_size = 6M
read_buffer_size = 4M
read_rnd_buffer_size=16M
join_buffer_size = 8M
myisam_sort_buffer_size =64M
table_cache = 512
thread_cache_size = 64
query_cache_size = 64M
tmp_table_size = 256M
max_connections = 768
max_connect_errors = 10000000
wait_timeout = 10
thread_concurrency = 8 #该参数取值为服务器逻辑CPU数量*2,在本例中,服务器有2颗物理CPU,而每颗物理CPU又支持H.T超线程,所以实际取值为4*2=8
skipnetworking #开启该选项可以彻底关闭MySQL的TCP/IP连接方式,如果WEB服务器是以远程连接的方式访问MySQL数据库服务器则不要开启该选项!否则将无法正常连接!
table_cache=1024
innodb_additional_mem_pool_size=4M #默认为2M
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=2M #默认为1M
innodb_thread_concurrency=8 #你的服务器CPU有几个就设置为几。建议用默认一般为8
tmp_table_size=64M #默认为16M,调到64-256最挂
thread_cache_size=120
query_cache_size=32M
2.3 案例分析
电商平台的数据量太多,CPU使用率过高,对数据库进行调优
调整系统参数InnoDB_flush_log_at_trx_commit
默认值是1,修改为2,不用每次提交事务的时候都启动磁盘读写,在大并发的场景,可以改善系统效率降低CPU使用率
调整系统参数InnoDB_buffer_pool_size
InnoDB存储引擎使用缓存来存储索引和数据。值越大,可以加载到缓存区的索引和数据量越多,需要的磁盘读写就越少,修改参数为64G,磁盘读写次数可以大幅度降低,可以充分利用内存,释放一些CPU的资源
调整系统参数InnoDB_buffer_pool_instances
可以提高系统的并行处理能力,允许多个进程同时处理不同部分的缓存区
遇到CPU资源不足的问题,2个思路
- 疏通拥堵路段,消除瓶颈,让等待的时间更短
- 开拓新的通道,增加并行处理能力