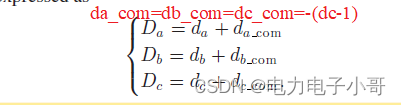踩坑
一开始运行的时候会出来很多其他的日志信息,这里我忘了设置settings.py中LOG_LEVEL='ERROR'
获取xpath
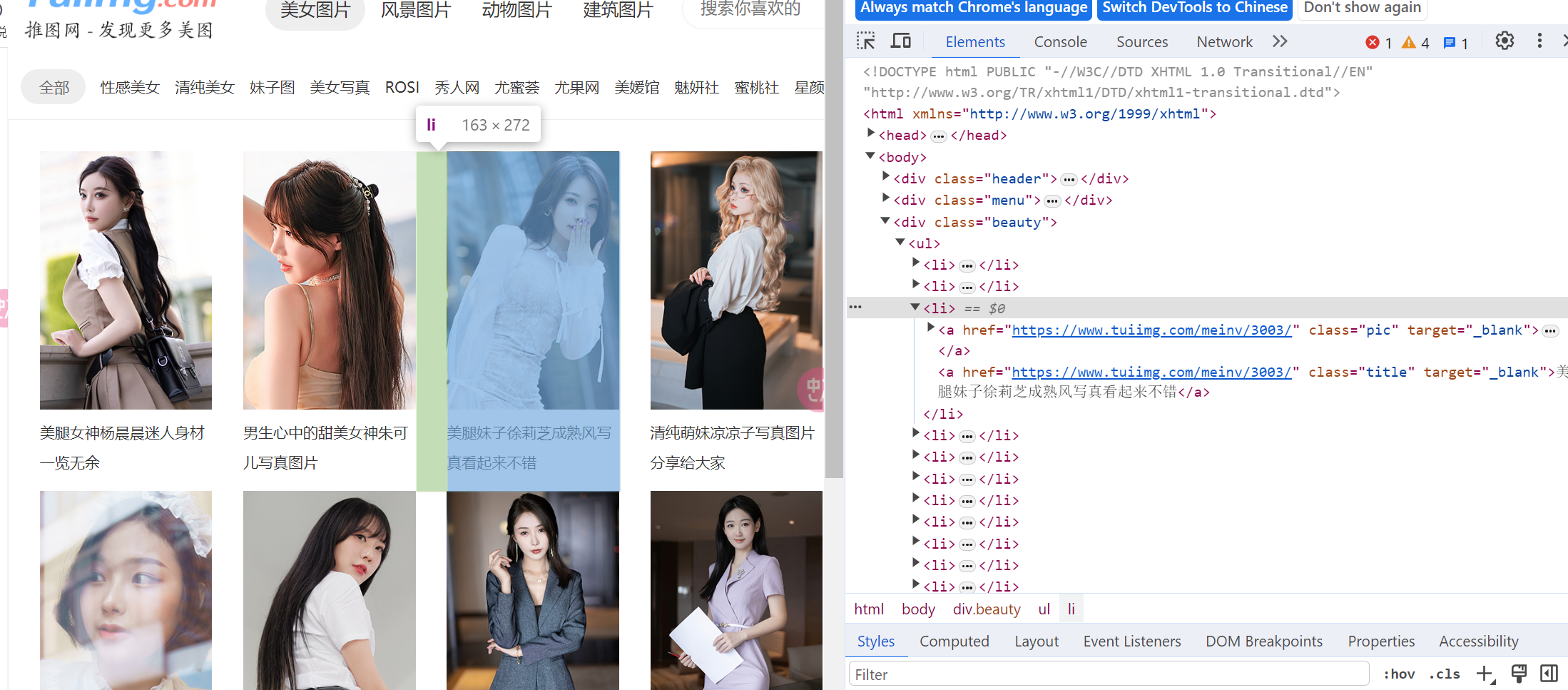
这里获取xpath比较简单。
首先发现所有的照片+文字都是在li标签下的,所以第一步是获取所有的li标签,得到li标签的列表。
li_list = response.xpath("/html/body/div[3]/ul/li")
然后再从li标签当前的xpath下获取对应文字的照片。这里一定一定要注意从当前li标签向下找时,必须要加dot!!!
for li in li_list:
img_name = li.xpath("./a[2]/text()").extract() # xpath得到是是一个selector对象。
# 对列表调用extract后,将列表的每一个Selector对象中的data对应的字符串提取了出来
如何获取多页数据?
点击不同页数观察其url,发现如下特点:
page2 => https://www.tuiimg.com/meinv/list_2.html
page3 => https://www.tuiimg.com/meinv/list_3.html
page7 => https://www.tuiimg.com/meinv/list_7.html
所以得到所有的页面url
这里通过自行手动发送请求发送
使用format格式模拟当前页的url,然后对该url发起请求
# 用于构造一个请求对象,以便在Scrapy爬虫中发送给指定的URL,并在请求返回后调用指定的回调函数
yield scrapy.Request(url=new_url, callback=self.parse)
meinv.py
import scrapy
class MeinvSpider(scrapy.Spider):
name = "meinv"
# allowed_domains = ["www.tuiimg.com"]
start_urls = ["http://www.tuiimg.com/meinv/"]
# 生成一个通用的url模板,用于后面修改
url = 'https://www.tuiimg.com/meinv/list_%d.html'
page_num = 2
def parse(self, response):
# 页面数据有很多页,获取多页的数据
li_list = response.xpath("/html/body/div[3]/ul/li")
print("page:", self.page_num)
for li in li_list:
img_name = li.xpath("./a[2]/text()").extract() # xpath得到是是一个selector对象。使用extract得到文字。
print(img_name)
# 获取前10页的数据
if self.page_num <= 10:
new_url = format(self.url%self.page_num) # 拼在一起
self.page_num += 1
# 手动发送请求:callback()回调函数专门用于数据处理。
# 用于构造一个请求对象,以便在Scrapy爬虫中发送给指定的URL,并在请求返回后调用指定的回调函数
yield scrapy.Request(url=new_url, callback=self.parse)