文章目录
- 前言
- 一、什么是 Ribbon
- 二、Ribbon 实现负载均衡的原理
- 2.1 负载均衡的流程
- 2.2 Ribbon 实现负载均衡的源码剖析
- 三、Ribbon 负载均衡策略
- 3.1 负载均衡策略
- 3.2 演示 Ribbon 负载均衡策略的更改
- 四、Ribbon 的饥饿加载
- 4.1查看 Ribbon 的懒加载
- 4.2 Ribbon 的饥饿加载模式
前言
在前文《深入理解 Eureka 注册中心的原理、服务的注册与发现》中,介绍了如何使用 Eureka 实现服务的注册与拉取,并且通过添加 @LoadBalanced 注解实现了负载均衡。这种自动化的背后隐藏着许多疑问:
- 服务是在何时进行拉取的?
- 负载均衡是如何实现的?
- 负载均衡的原理和策略又是什么?
本文旨在深入探讨使用 Eureka 实现负载均衡的原理,为我们理解微服务架构中服务调用的内部机制提供更清晰的认识。通过解答这些疑惑,我们将更好地理解服务发现、负载均衡的运作方式,为构建高性能、稳定的分布式系统打下坚实的基础。
一、什么是 Ribbon
Ribbon 是一个基于 HTTP 和 TCP 客户端的负载均衡器。在微服务架构中,服务的调用通常涉及到负载均衡的问题,即在多个服务提供方中选择一个进行调用。Ribbon 提供了一种简单而有效的负载均衡解决方案。
Ribbon 最初是 Netflix 公司开发的,后来成为 Spring Cloud 项目的一部分。它的主要作用是在服务消费者和提供者之间实现均衡的流量分发,确保每个服务提供者都能够得到适当的请求,避免出现服务过载或资源浪费的情况。
具体而言,Ribbon 实现了以下功能:
-
负载均衡算法: Ribbon 支持多种负载均衡算法,例如轮询、随机、权重轮询等,使得服务消费者可以根据实际场景选择适当的负载均衡策略。
-
服务实例的自动发现: Ribbon 与 Eureka 等服务注册中心集成,能够自动获取可用的服务实例列表。
-
故障转移和重试机制: Ribbon 具备故障转移和重试功能,可以在服务提供者发生故障时自动切换到其他健康的实例,提高系统的稳定性和可用性。
在 Spring Cloud 中,Ribbon 作为一个负载均衡的客户端组件,通过拦截微服务的调用请求,动态地选择目标服务实例,从而分配请求的负载,实现了对服务调用的细粒度控制。
二、Ribbon 实现负载均衡的原理
2.1 负载均衡的流程
Ribbon 实现负载均衡的流程图如下:
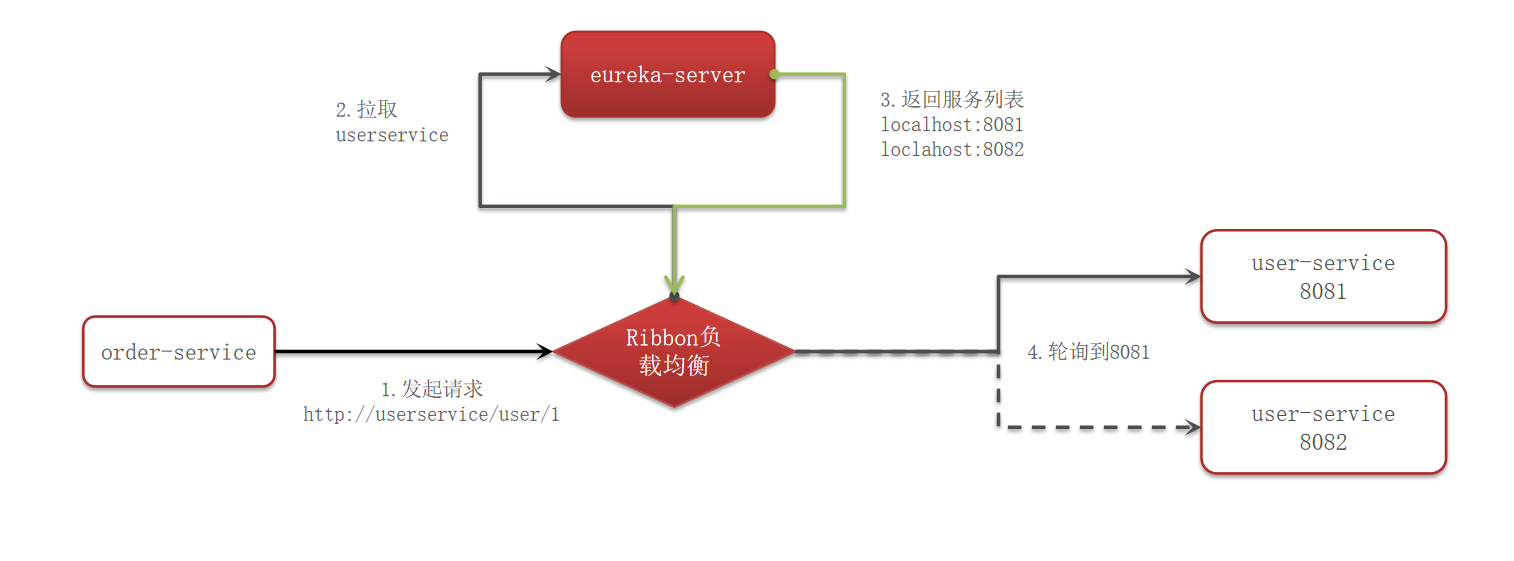
下面是对这个流程的详细说明:
- 首先,服务消费者发起请求,Ribbon 负载均衡器收到请求之后,获取请求路径中的服务名称,例如
userservice。 - 然后负载均衡器使用这个获取到的服务名称去向 Eureka Service 拉取对应的服务。
- 在实际生产中,一个服务一般都会有多个实例,因此拉取到的就是一个服务列表,列表中包含了这个服务所有正常实例的 IP 和端口号。
- 负载均衡器在获取到这个列表之后,使用当前采取的负载均衡策略去选择一个合适的服务,然后再访问这个服务。
这个流程确保了服务的请求能够被合理地分发到多个实例中,从而实现了负载均衡。
2.2 Ribbon 实现负载均衡的源码剖析
首先,Ribbon 实现负载均衡使用到的一个类叫做 LoadBalancerInterceptor负载均衡拦截器,可以通过 IDEA 查看它的源码:
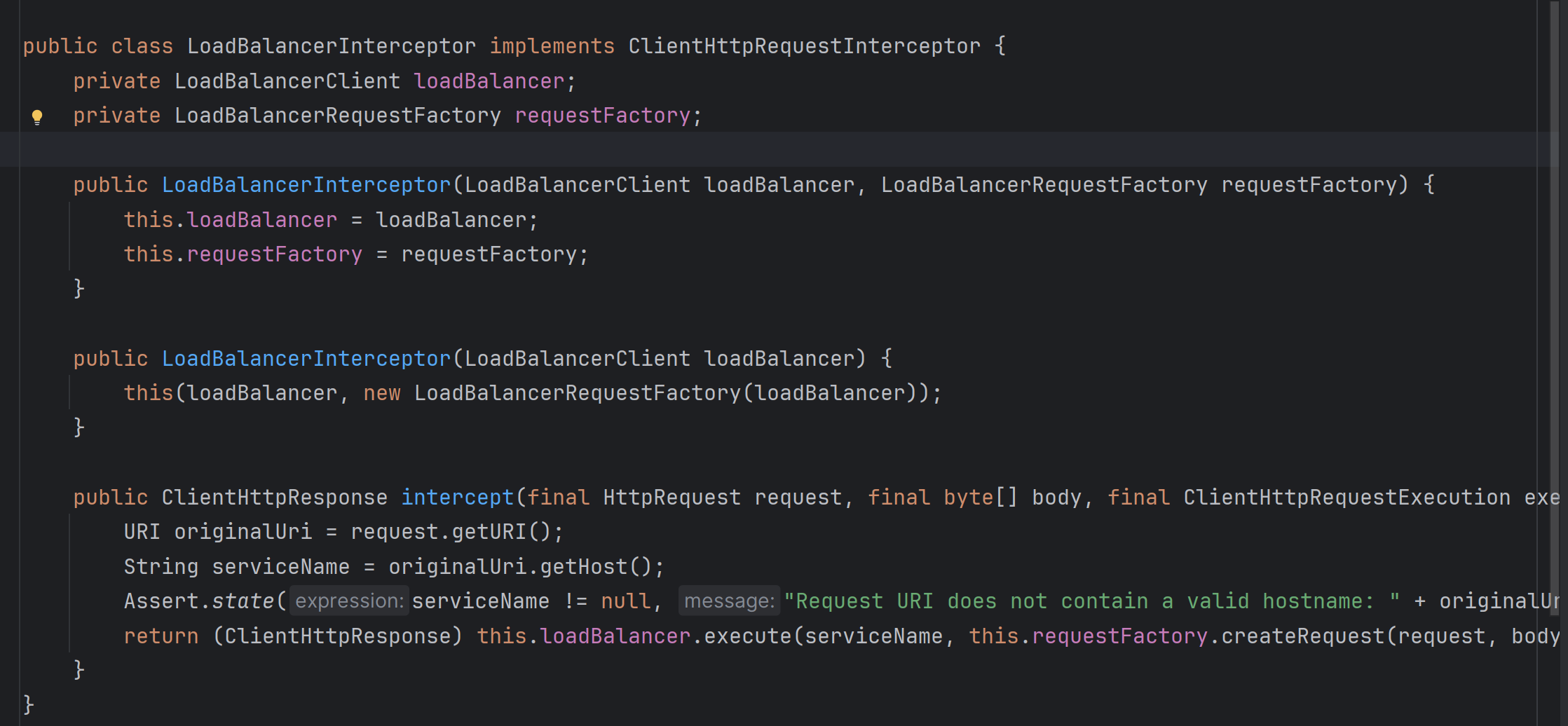
发现它实现了一个 ClientHttpRequestInterceptor接口,即客户端 HTTP 请求拦截器:

它会拦截 RestTemplate 发生的 HTTP 请求,ClientHttpRequestInterceptor 是一个接口,并且其中包含了一个 intercept 方法,因此LoadBalancerInterceptor 作为实现这个接口的类也一定重写了 intercept 方法,此时我们可以在这个方法中设置一个断点进行调试,以追踪代码的运行:

-
request.getURI()获取请求地址:

-
originalUri.getHost()获取到了请求的地址中的主机名,此时获取到的就是服务的名称,也就是userservice:

3. 当找到了服务的名称之后,接下来要做的工作就是向 EurekaServer 去拉取对应的服务了,然后这个方法就把获取到的服务名交给了一个RibbonLoadBalancerClient (Ribbon负载均衡客户端)进行处理。

4. 继续调试代码,进入execute 方法:
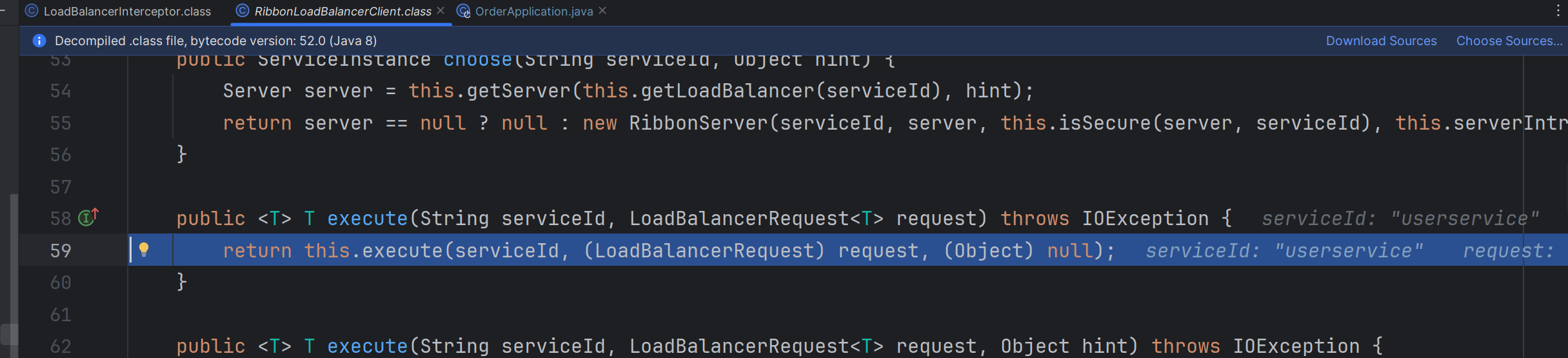
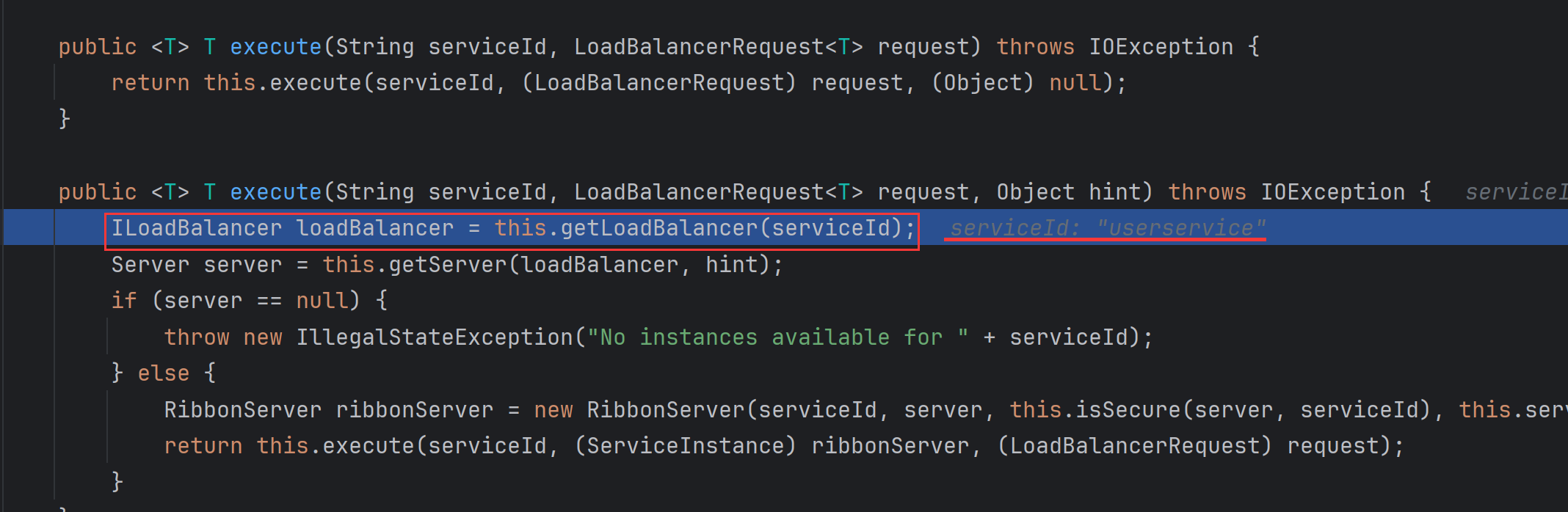
- 继续往下走,就得到了一个
LoadBalancer对象,:
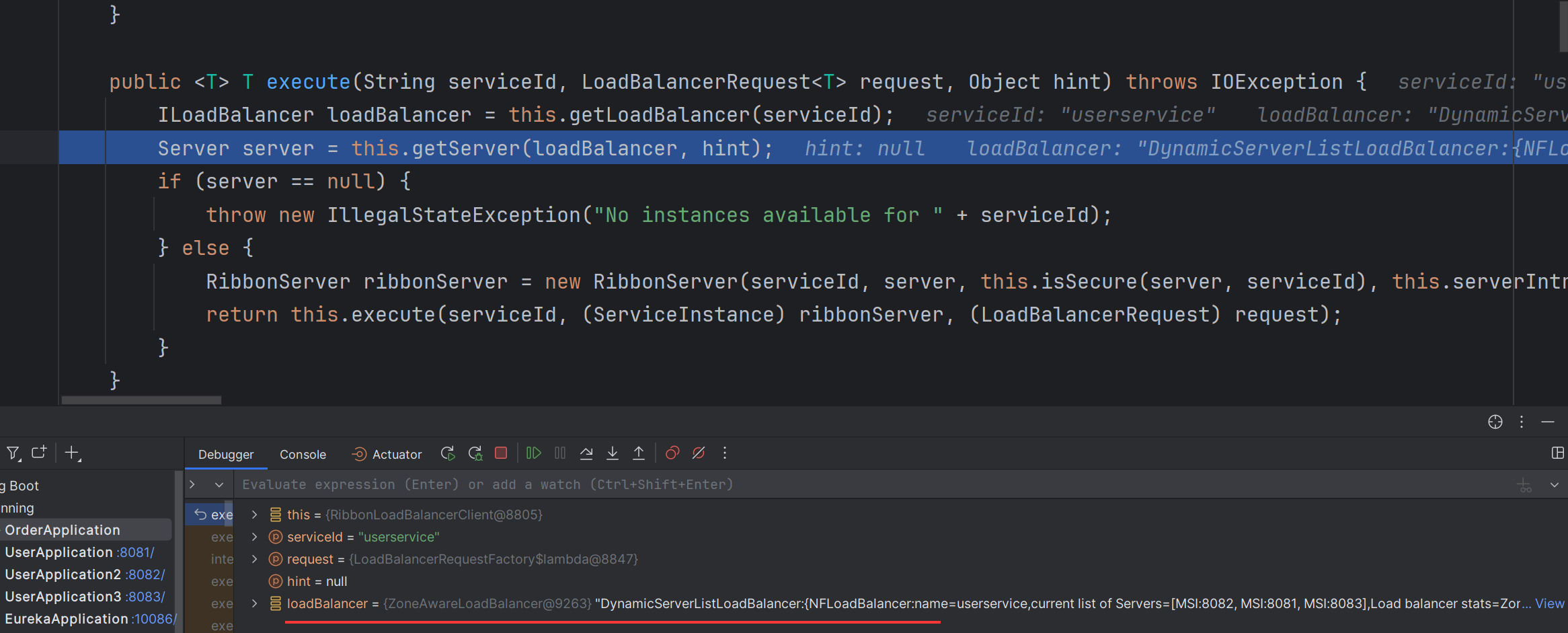
这个对象的名称叫做“动态服务列表均衡器”,查看这个对象的内容,可以发现服务列表中服务的数量为3,这三个服务就是获取到的三个user-service向 EurekaServer 中注册的服务。
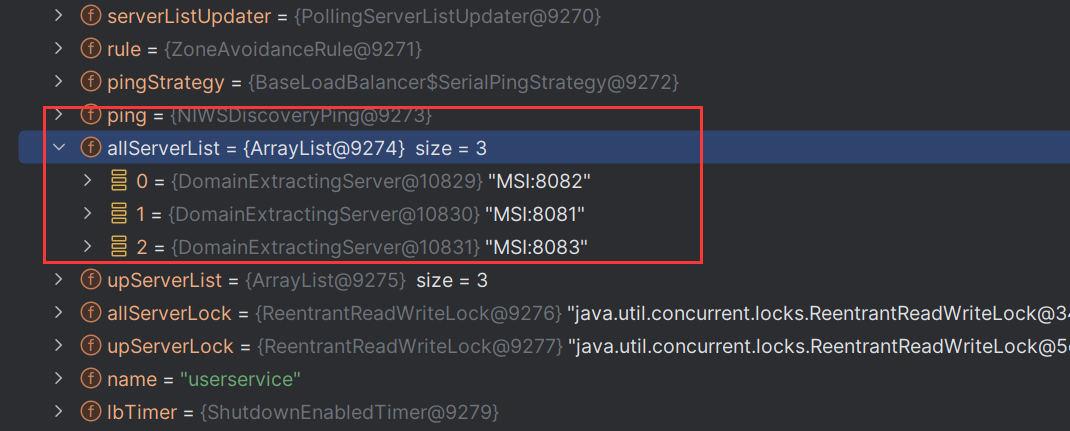
因此getLoadBalancer 方法的作用就是根据服务名称向 EurekaServer 中寻找服务列表。当找到了服务列表之后,我们就可以大胆的猜测,下一步所要做的工作就是进行负载均衡操作了。
-
此时,我们进入
getServer方法:
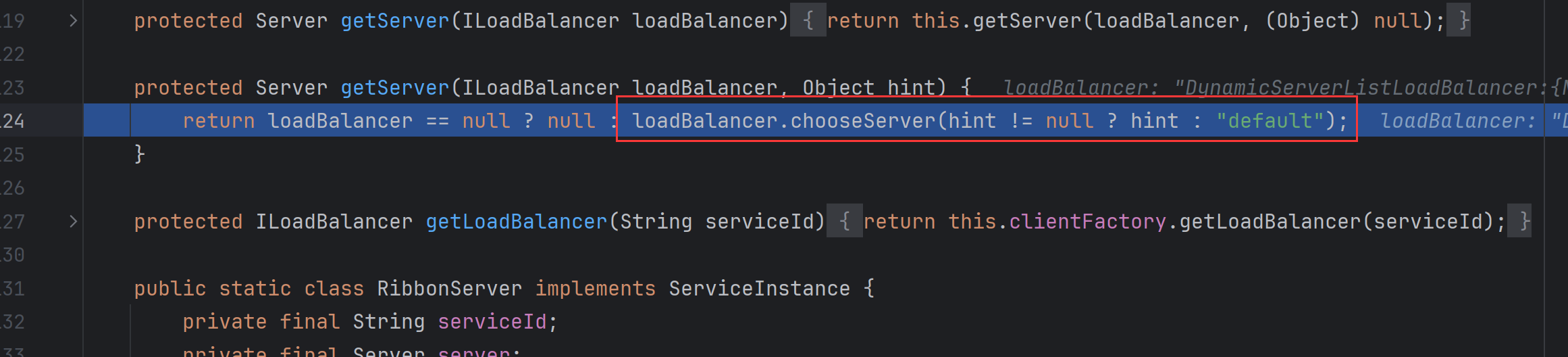
-
接下来就调用了
chooseServer方法,进入这个方法:
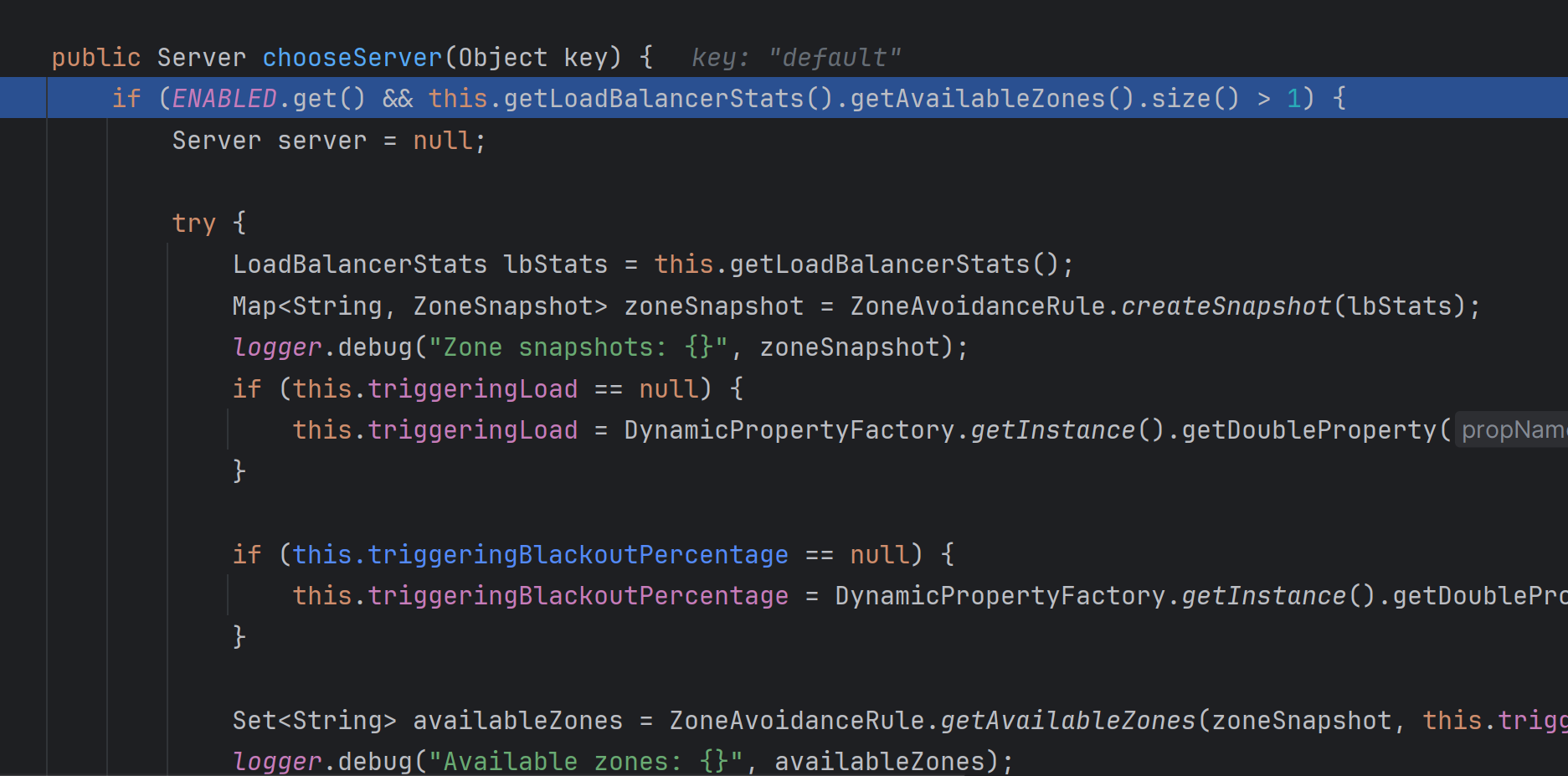
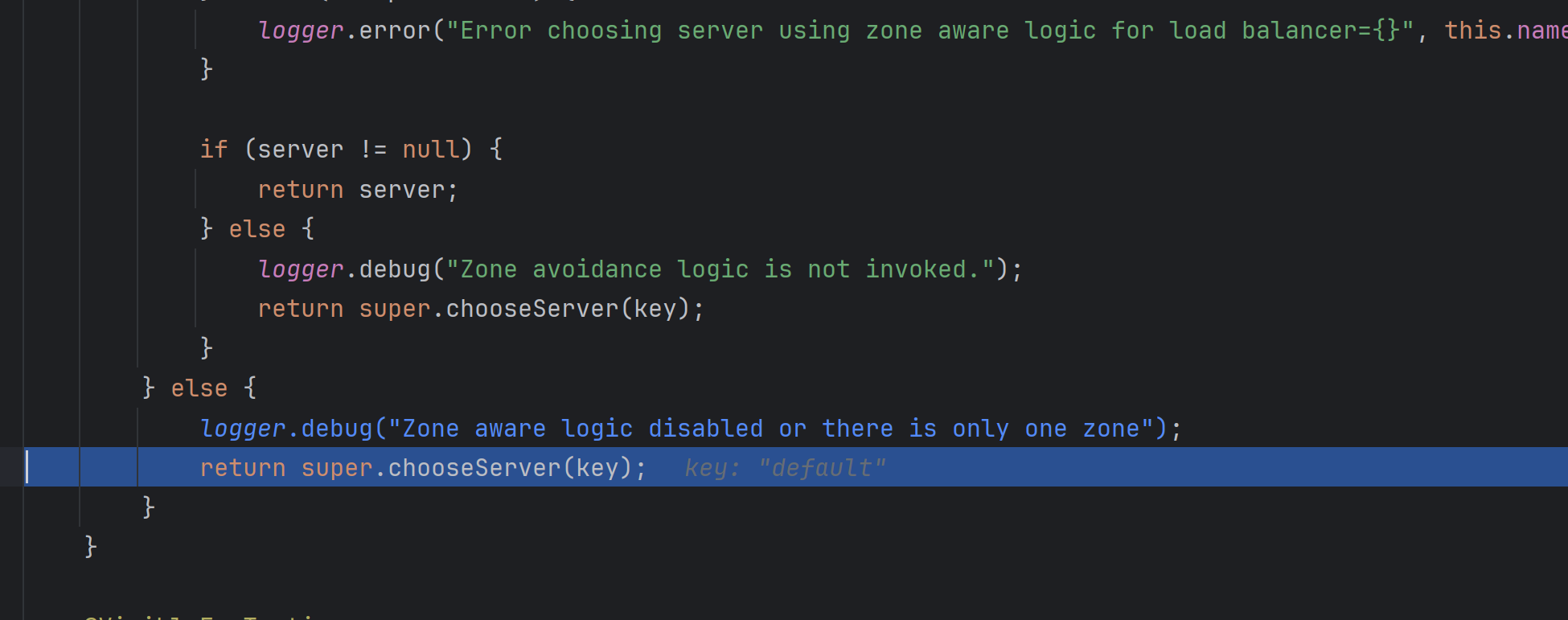
8. 然后再进入chooseServer 方法,最后找到了rule.choose方法:

此时查看 rule 对象,发现是一个接口:
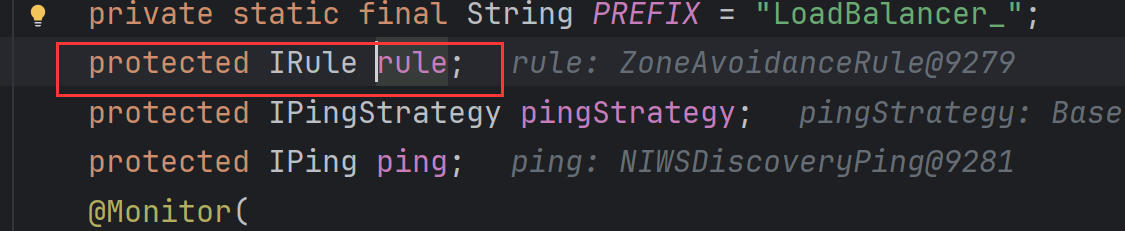
既然是接口,那么就有实现类:
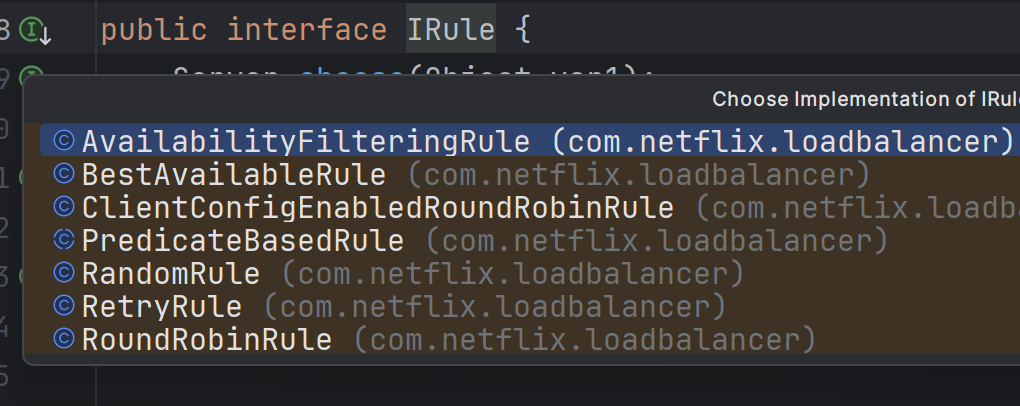
此时发现的实现类就是负载均衡的规则了。大致的规则有随机、轮询等等。
- 最后,通过默认的规则,就选择到了 8082 这个端口的服务了。
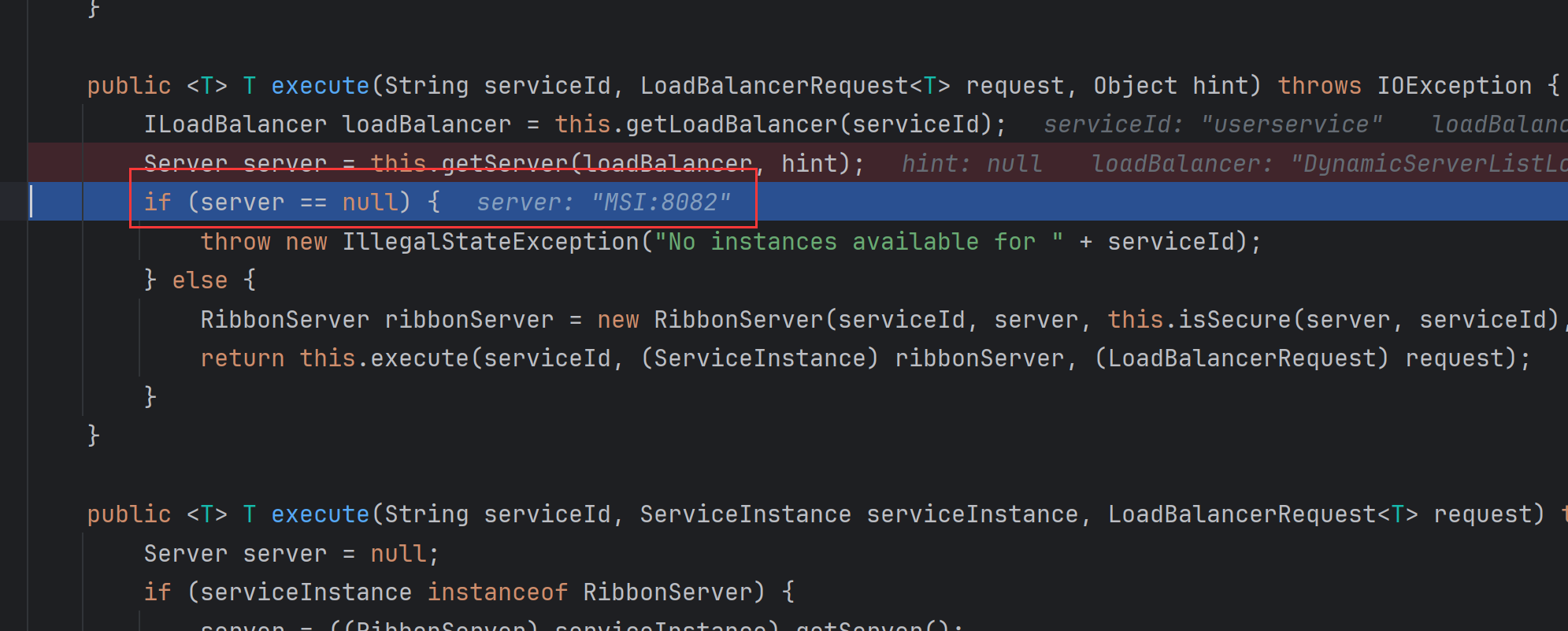
接下来就可以使用真正的IP和端口号去代替 userservice ,然后去访问指定了服务了。
以上就是 Ribbon 实现负载均衡的源码剖析,通过调试了方法深入探索了服务发现与负载均衡是实现流程,帮助我们更好的理解了服务发现、负载均衡的运作方式
三、Ribbon 负载均衡策略
3.1 负载均衡策略
通过上面的源码分析不难发现,Ribbon 的负载均衡规则是一个叫做 IRule 的接口来定义的,每一个子接口都是一种规则。
关于 IRule 接口的继承体系如下图所示:
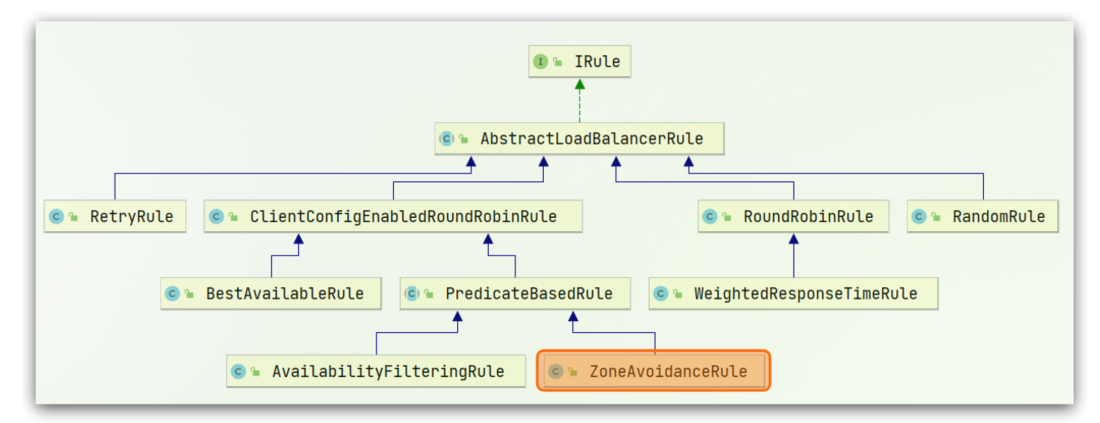
关于 Ribbon 的负载均衡策略可以总结如下表所示:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对短路和并发数过高的服务器进行忽略 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器 |
| RetryRule | 重试机制的选择逻辑 |
Ribbon 提供了这些内置的负载均衡规则,同时也支持自定义负载均衡规则。在实际应用中,根据业务特点选择合适的负载均衡策略是非常重要的。下面演示了 Ribbon 负载均衡策略的更改。
3.2 演示 Ribbon 负载均衡策略的更改
通过定义IRule实现可以修改负载均衡规则,有两种方式:
- 代码方式:在
order-service中的OrderApplication启动类中,定义一个新的IRule,并使用@Bean注解注册到 Spring 容器中:
@Bean
public IRule randomRule(){
return new RandomRule();
}
- 配置文件方式:在
order-service的application.yml文件中,添加新的配置也可以修改规则:
# 修改 Ribbon 负载均衡策略
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
例如,下面是修改了负载均衡策略之后,再次使用 order-service 访问订单的结果。可以发现,现在不再是以轮询的方式挑选user-service服务了,而是以随机的方式进行挑选了。

四、Ribbon 的饥饿加载
4.1查看 Ribbon 的懒加载
当我们重新启动 order-service 服务,然后在浏览器中进行订单访问,可以发现如下的现象:
当 order-service 服务启动后,第一次访问服务可以发现耗时需要三百多毫秒:

然后,再次访问多次,可以发现耗时都变成了十几毫米:
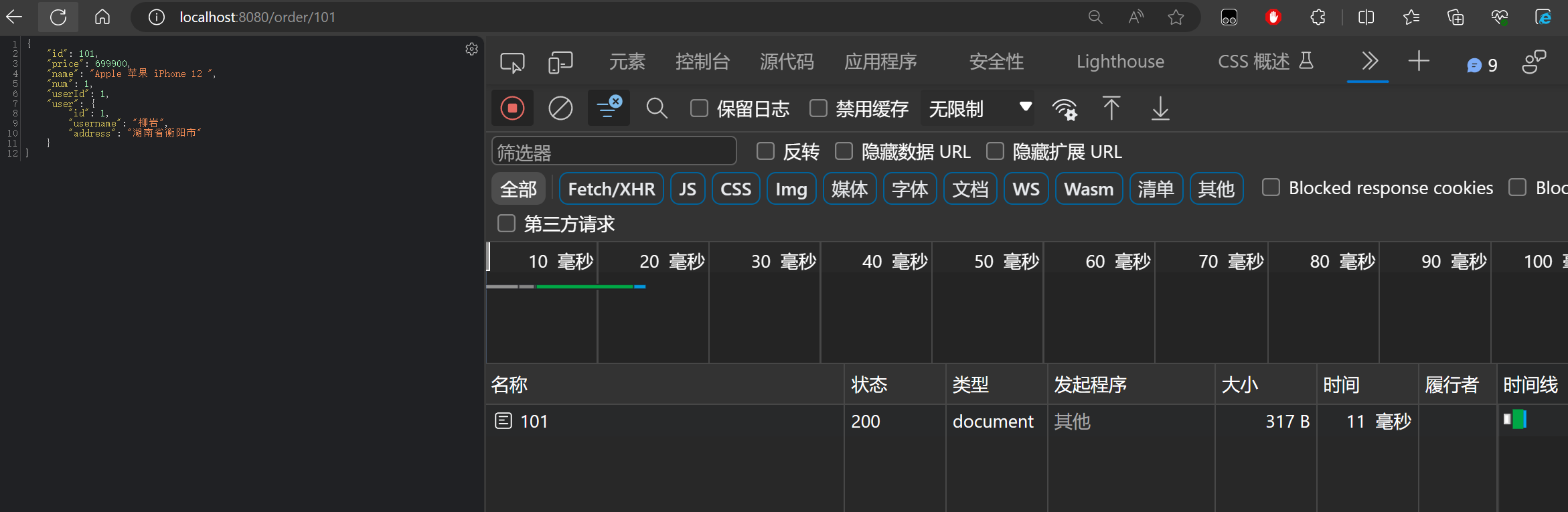
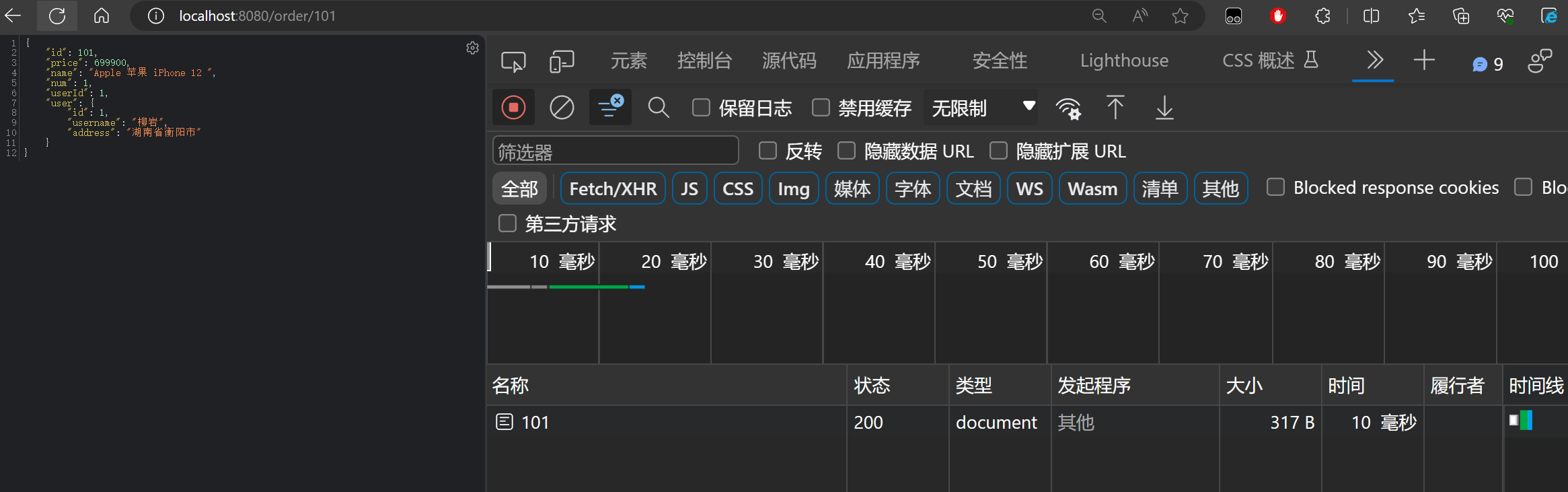
通过以上的现象就可以发现,Ribbon 默认采用的是懒加载模式,就像单例模式的懒汉模式一样,第一次访问的时候才会去创建LoadBalanceClient实例,请求时间会很长。
4.2 Ribbon 的饥饿加载模式
为了解决上述懒加载的耗时问题,Ribbon 还提供了饥饿加载模式,饥饿加载则会在项目启动时创建,降低第一次访问的耗时。
通过下面配置开启饥饿加载:
此时重启 order-service服务:
在启动服务的时候,就会发现日志变得更多了:
这个日志的内容就是加载LoadBalanceClient实例所产生的日志。
再次首次访问 order-service服务,就会发现消耗的时间变短了: