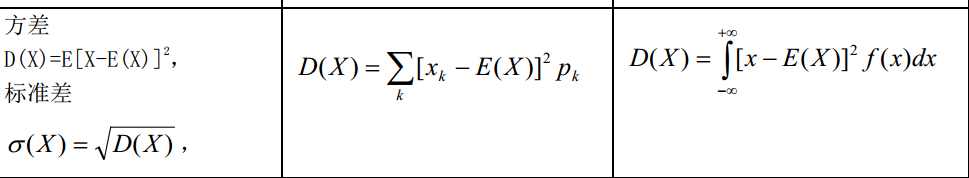数据集及wen件目录介绍:
数据集:工作台 - Heywhale.com

一、前期工作
1.1 数据详情
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import os,PIL,random,pathlib
data_dir = 'D:/P7/49-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[3] for path in data_paths]
print(classeNames)
image_count = len(list(data_dir.glob('*/*.png')))
print("图片总数为:",image_count)
1.2 图片预处理:
详见:写文章-CSDN创作中心![]() https://mp.csdn.net/mp_blog/creation/editor/133411331
https://mp.csdn.net/mp_blog/creation/editor/133411331
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder("D:/P7/49-data",transform=train_transforms)
print(total_data)
标签量化处理:
print(total_data.class_to_idx)![]()
1.4 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)
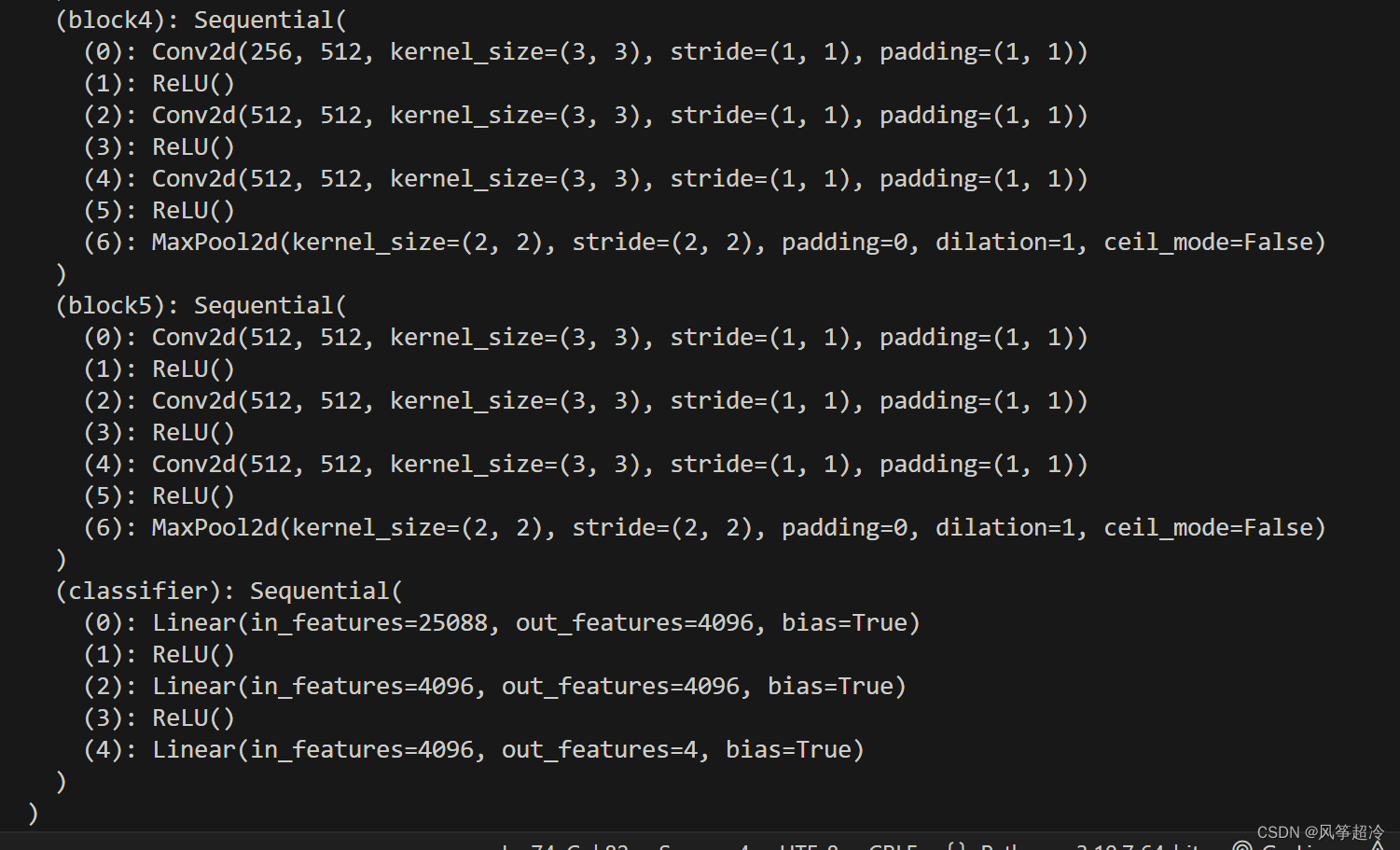
二、搭建VGG—16模型
import torch.nn.functional as F
class vgg16(nn.Module):
def __init__(self):
super(vgg16, self).__init__()
# 卷积块1
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块2
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块3
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块4
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块5
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=512*7*7, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = vgg16().to(device)
print(model)