文章目录
- 前言
- 多租户的四种实现方案
- 单数据源多数据库
- 实现思路
- 代码实现
- 总结
前言
多租户(Multi-Tenancy)是一种软件架构设计模式,旨在使单个应用程序可以同时为多个租户(如不同组织、用户或客户)提供服务,每个租户都拥有独立的数据和配置,并且彼此之间相互隔离。实现多租户架构可以帮助企业降低成本、简化管理并提高效率。
在设计多租户系统之前,我们需要明确业务需求和预期目标。是否希望租户之间完全隔离,还是允许一些共享资源?我们需要考虑以下几个方面:
数据隔离:每个租户的数据应该彼此隔离,不同租户之间不能直接访问或共享数据。可以通过使用独立的数据库或者使用数据表中的租户ID进行区分来实现数据隔离。
身份认证与授权:多租户系统需要支持各个租户的身份认证和授权,确保只有合法的用户能够访问自己所属的租户资源。
水平扩展:多租户系统可能会面临大量用户和数据增长的挑战,因此需要具备水平扩展的能力,以保持系统的高性能和可靠性。
配置管理:每个租户可能有不同的配置需求,例如与邮件、支付和存储等集成的参数设置。因此,应该提供一种可灵活配置的机制,使租户能够根据自己的需求进行定制。
安全性和隔离:多租户系统需要确保租户之间的安全隔离,以防止潜在的数据泄露和访问冲突。在设计系统时,应考虑到对于敏感数据的保护和各种攻击的预防。
资源利用率:为了提高资源利用率,可以考虑共享某些通用的资源,如计算资源、存储空间和网络带宽。这样可以减少成本,并提供更高的效率。
多租户的四种实现方案
常见的设计方案大致分为4种:
1、所有租户使用同一数据源下同一数据库下共同数据表(单数据源单数据库单数据表)
2、所有租户使用同一数据源下同一数据库下不同数据表(单数据源单数据库多数据表)
3、所有租户使用同一数据源下不同数据库下不同数据表(单数据源多数据库多数据表)
4、所有租户使用不同数据源下不同数据库下不同数据表(多数据源多数据库多数据表)
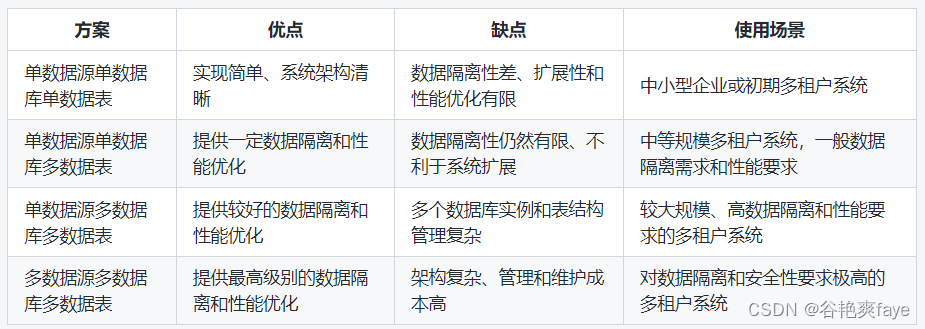
第一、二种相对来说比较简单。我们本文主要对第三种展开讲解
单数据源多数据库
多租户的最终目的就是要实现数据隔离,在但数据源多数据库中,也就是当有了一个新的租户要进行注册的时候,要实现去创建一个数据库和对应的数据库表。
现在就有了问题,应该如何去动态的去创建数据库呢?
实现思路
1、创建数据库:可以数用传统的方式,通过sql语句去创建
2、创建数据库表:在创建完数据库之后,使用sql语句去创建表
下文的代码中使用了读取xml文件中的sql去创建
代码实现
在resources下创建一个xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<document>
<statement>
<name>create-tenant</name>
<script>
DROP DATABASE IF EXISTS `sys_user${tenant_id}`;
CREATE DATABASE ${database};
USE ${database};
CREATE TABLE `sys_user` (
`user_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`dept_id` bigint(20) DEFAULT NULL COMMENT '部门ID',
`user_name` varchar(30) NOT NULL COMMENT '用户账号',
`nick_name` varchar(30) NOT NULL COMMENT '用户昵称',
`user_type` varchar(2) DEFAULT '00' COMMENT '用户类型(00系统用户)',
`email` varchar(50) DEFAULT '' COMMENT '用户邮箱',
`phonenumber` varchar(11) DEFAULT '' COMMENT '手机号码',
`sex` char(1) DEFAULT '0' COMMENT '用户性别(0男 1女 2未知)',
`avatar` varchar(100) DEFAULT '' COMMENT '头像地址',
`password` varchar(100) DEFAULT '' COMMENT '密码',
`status` char(1) DEFAULT '0' COMMENT '帐号状态(0正常 1停用)',
`del_flag` char(1) DEFAULT '0' COMMENT '删除标志(0代表存在 2代表删除)',
`login_ip` varchar(128) DEFAULT '' COMMENT '最后登录IP',
`login_date` datetime DEFAULT NULL COMMENT '最后登录时间',
`create_by` varchar(64) DEFAULT '' COMMENT '创建者',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_by` varchar(64) DEFAULT '' COMMENT '更新者',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` varchar(500) DEFAULT NULL COMMENT '备注',
`auth_id` varchar(30) DEFAULT NULL COMMENT '其他项目用户id(积分)',
`ding_id` varchar(50) DEFAULT NULL COMMENT '用户dingid',
`tenant_id` varchar(100) DEFAULT NULL COMMENT '公司id',
`open_id` varchar(50) DEFAULT NULL COMMENT '微信用户唯一标识',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='用户信息表';
</script>
</statement>
</document>
这是对应的创建数据库的语句。
获取xml文件中信息:
@Component
public class ExecSqlConfig {
private final Map<String, String> sqlContainer = new HashMap<>();
public ExecSqlConfig() throws Exception {
// 1.创建Reader对象
SAXReader reader = new SAXReader();
// 2.加载xml
InputStream inputStream = new ClassPathResource("create-library.xml").getInputStream();
Document document = reader.read(inputStream);
// 3.获取根节点
Element root = document.getRootElement();
// 4.遍历每个statement
List<Element> statements = root.elements("statement");
for (Element statement : statements) {
String name = null;
String sql = null;
List<Element> elements = statement.elements();
// 5.拿到name和script加载到内存中管理
for (Element element : elements) {
if ("name".equals(element.getName())) {
name = element.getText();
} else if ("script".equals(element.getName())) {
sql = element.getText();
}
}
sqlContainer.put(name, sql);
}
}
public String get(String name) {
return sqlContainer.get(name);
}
}
sql执行脚本:
在脚本中去读取了ExecSqlConfig 文件中的信息
@Component
public class ExecSqlUtil {
@Autowired
private ExecSqlConfig execSqlConfig ;
@Autowired
private DataSource dataSource ;
/**
* @description: 把模板中的数据库名称替换为新租户的名称
* @author:
* @date: 2023/9/27 15:05
* @param: [name , replaceMap]
* @return: void
**/
@SneakyThrows
public void execSql(String name, Map<String, String> replaceMap) {
try {
// 获取SQL脚本模板
String sql = execSqlConfig.get(name);
// 替换模板变量
for (Map.Entry<String, String> entity : replaceMap.entrySet()) {
sql = sql.replace(entity.getKey(), entity.getValue());
}
ScriptRunner scriptRunner = new ScriptRunner(dataSource.getConnection());
// 执行SQL
scriptRunner.runScript(new StringReader(sql));
}catch (Exception e){
e.printStackTrace();
}
}
}
业务逻辑
public void addTenantLibrary(TanentModel tanentModel) {
try {
if (!(tanentModel.getDescription().isEmpty()||tanentModel.getTenantContact().isEmpty()||tanentModel.getTel().isEmpty()||tanentModel.getTenantName().isEmpty())){
//判断数据源中是否已经存在该数据库
int flag= tantentMapper.insertTantentAdmin(tanentModel.getTenantName());
if (flag>0){
throw new Exception("已存在该数据库");
}else {
Map<String,String> map=new HashMap<>();
map.put("${database}",tanentModel.getTenantName());
map.put("${project_name}",tanentModel.getTenantName());
map.put("${leader}",tanentModel.getTenantContact());
map.put("${phone}",tanentModel.getTel());
map.put("${description}",tanentModel.getDescription());
execSqlUtil.execSql("create-tenant",map);
}
}
}catch (Exception e){
e.printStackTrace();
throw new RuntimeException(e.getMessage()); // 将异常信息作为响应的一部分返回给前端
}
}
在业务逻辑的代码中,map.put(“${database}”,tanentModel.getTenantName());是替换的xml文件中的变量
总结
在多租户架构中,单数据源多数据库是一种常见的实现方案。通过使用不同的数据库实例或者数据库模式,我们可以实现对每个租户独立的数据存储,并保持彼此之间的隔离性。在本文中,我们讨论了单数据源多数据库的实现方案和一些关键考虑因素。
总结而言,单数据源多数据库方案为多租户系统提供了以下优势:
数据隔离:每个租户拥有独立的数据库,数据之间互不干扰,确保了租户数据的隔离性和安全性。
性能优化:通过将租户数据分散到多个数据库中,可以减轻单一数据库的负载压力,提高系统的性能和吞吐量。
扩展性:当租户数量增加时,可以通过新增数据库实例或者数据库服务器来水平扩展系统,以满足不断增长的业务需求。
容错性:单数据源多数据库方案降低了租户之间的相互影响,当某个数据库发生故障时,其他数据库仍然可以正常运行,提高了系统的容错性和可用性。
在实施单数据源多数据库方案时,我们需要注意以下几个关键因素:
数据迁移和同步:对于已有的多租户系统,将现有数据迁移到新的数据库中可能需要一定的工作量。同时,为保持数据的一致性,我们需要确保数据在多个数据库之间的同步。
租户管理和路由策略:需要实现租户的动态管理和路由策略,确保每个请求能够正确地路由到对应的数据库。这可以通过维护租户-数据库映射关系或者使用中间件进行请求路由来实现。
数据库连接和资源管理:在系统设计中,需要考虑数据库连接的管理和资源分配。合理配置数据库连接池以及优化数据库查询等操作,可以提高系统的性能和资源利用率。
安全性和权限控制:在设计数据库架构时,需要考虑安全性和权限控制的需求。确保不同租户之间的数据访问和操作是受限的,并遵循数据隐私与保护的法律规定。
综上所述,单数据源多数据库是实现多租户系统的一种有效方案,它提供了良好的数据隔离、性能优化和扩展性。然而,在实施过程中需要综合考虑数据迁移、租户管理、资源管理和安全性等因素,以确保系统的稳定性和可靠性。通过合理的设计和实施,单数据源多数据库方案可以为多租户系统提供高效、安全且可扩展的数据存储解决方案。