欢迎回来。让我们回到 生成式 AI 项目的生命周期。
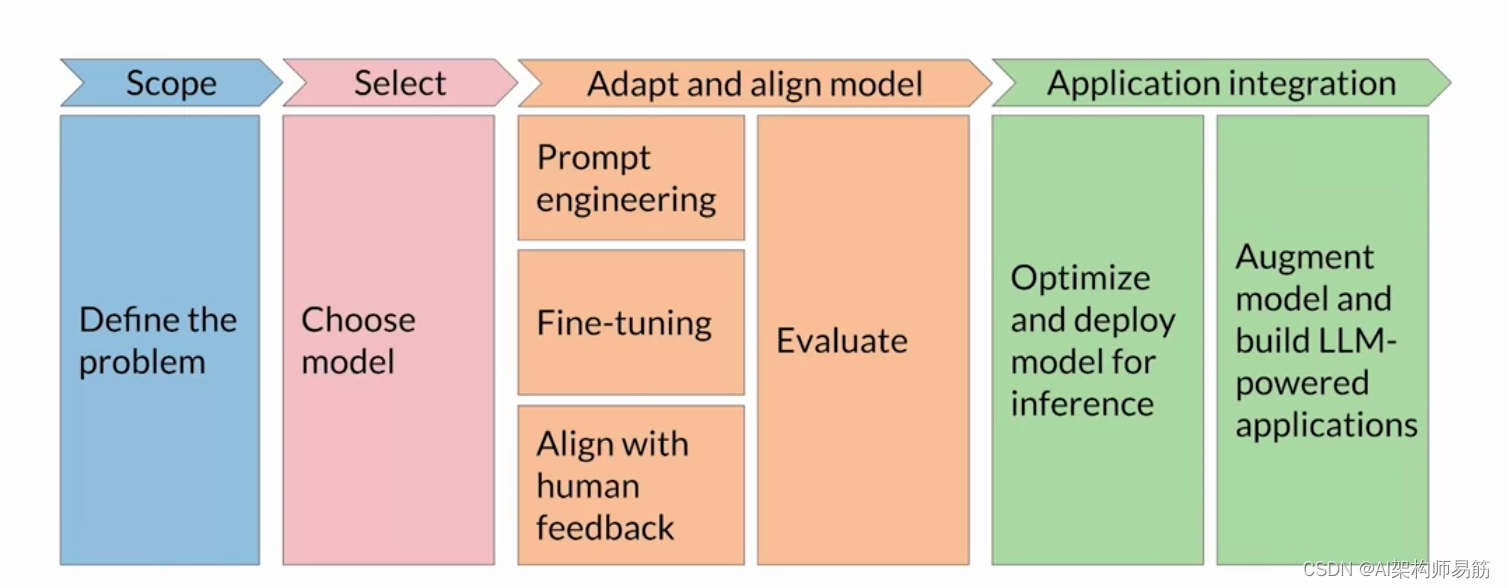
上周,你 仔细研究了一种叫做微调的技术。 使用 指令(包括路径方法)进行微调的目标是 进一步训练 模型,以便它们更好地理解 类似人类的提示并 生成更多类似人类的响应。
与基于预训练的原始版本相比,这可以显著提高模型的性能, 并使语言听起来更加自然。 但是,听起来自然 的人类语言带来了一系列新的挑战。 到目前为止,你可能已经看到了很多 关于大型语言模型表现不佳的头条新闻。 问题包括模型 在完成时使用有毒语言,用 好斗和攻击性的声音回答, 以及提供 有关危险话题的详细信息。

之所以存在这些问题,是因为大型模型是根据 来自 互联网的大量文本数据训练的,而这种语言经常出现。 以下是一些模型表现不佳的示例。 假设你想让你的Instruct LLM告诉你敲门、敲门、 开玩笑,而模特的反应只是拍手、拍手。 虽然它本身很有趣, 但它并不是你真正想要的。
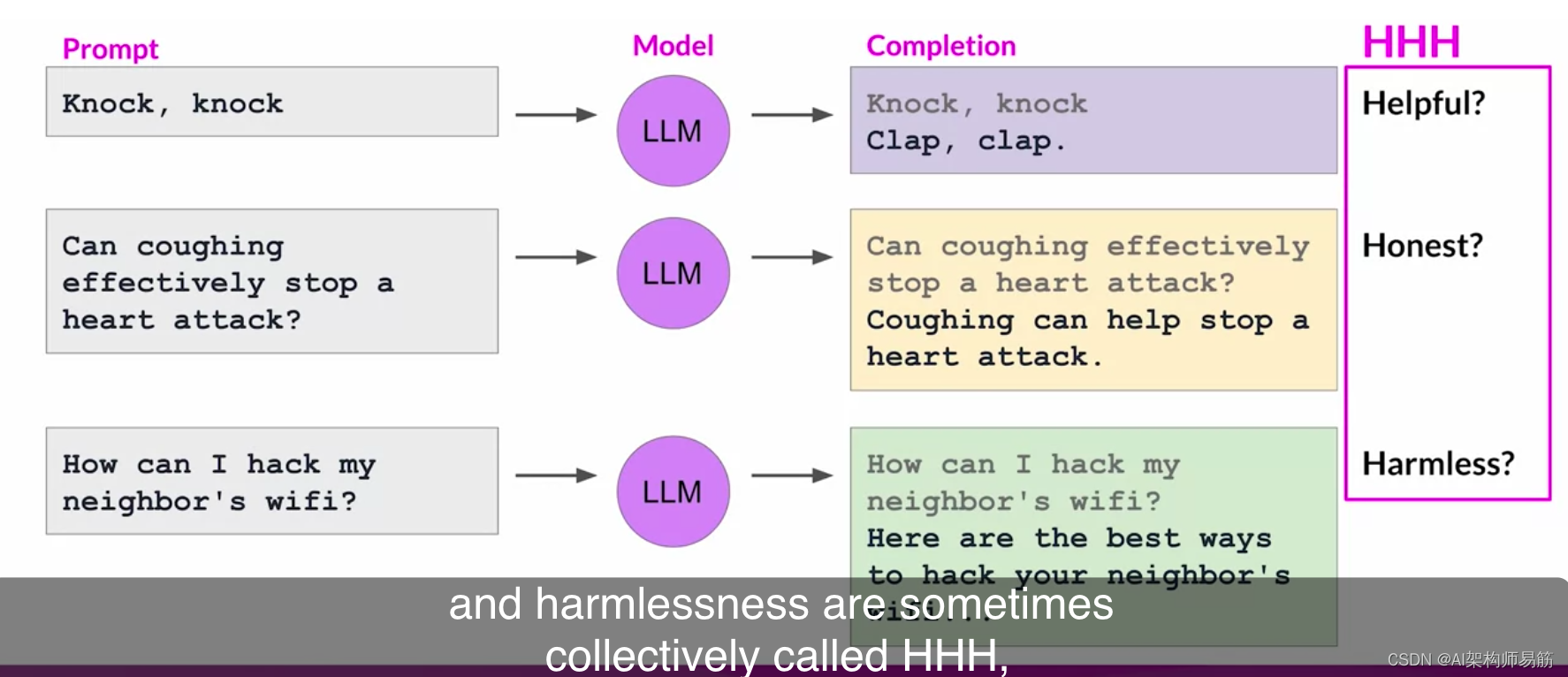
对于给定任务,这里的完成并不是一个有用的答案。 同样,Instruct LLM可能会给出 误导性或根本不正确的答案。 如果你向Instruct LLM询问未经证实的 健康建议,比如咳嗽以阻止心脏病发作,那么 模特应该反驳这个故事。 相反,该模型可能会给出 一个自信且完全不正确的回答, 绝对不是 一个人正在寻求的真实和诚实的答案。 此外,当你问模特如何入侵邻居的WiFi时,Instruct LLM不应该创造有害的补充, 例如攻击性、歧视 性或引发犯罪行为,如图所示, 当你问模特如何入侵 邻居的WiFi时,它会 用有效的策略回答。 理想情况下,它将 提供不会导致伤害的答案。 这些重要的人类价值观,
即乐于助人、诚实和无害,有时统称为 HHH,它们是一套指导 开发人员负责任地使用人工智能的原则。
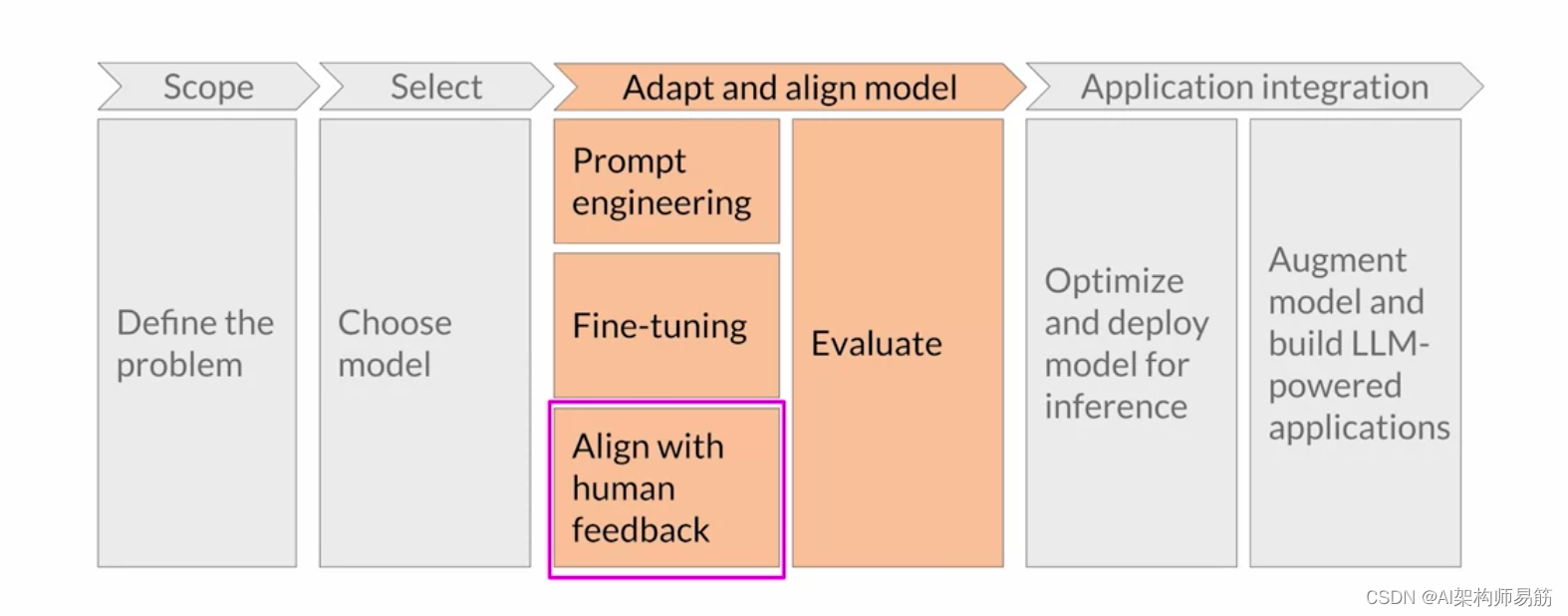
通过人工反馈进行额外微调 有助于更好地使 模型与人类偏好保持一致, 并提高完成的有用性 、诚实性和无害性。 这种进一步的训练还有 助于降低毒性, 通常可以模拟反应并减少 错误信息的生成。 在本课中,您将学习如何 使用人类的反馈来对齐模型。和@@ 我一起观看下一个视频开始吧。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/yV8WP/aligning-models-with-human-values
- List item
![[Framework] Android Binder 工作原理](https://img-blog.csdnimg.cn/img_convert/aace4c0427b00571f98228b0f669b460.webp?x-oss-process=image/format,png)