大模型和智能问答系统
- 大模型前的智能问答系统
- 传统管道式架构存在的问题
大模型前的智能问答系统
大模型统一代指以ChatGPT为代表的,参数量相比以前模型有明显量级变化的生成模型。
智能问答系统,按照应用可以划分*任务型 *和 非任务型。
任务型问答系统,按照技术实现方式可以划分为,管道式(pipeline)和端到端(end-to-end)。
任务型问答系统,多基于管道式方案进行。
如:Rasa的 NLU+Core模块,对应管道架构中的自然语言理解(NLU)+对话管理(DM);
科大讯飞的AIUI平台,需要对意图和槽位进行设置;
思必驰的整体交互逻辑,也把NLU和DM进行了区分。
管道式问答系统的具体架构如下图:
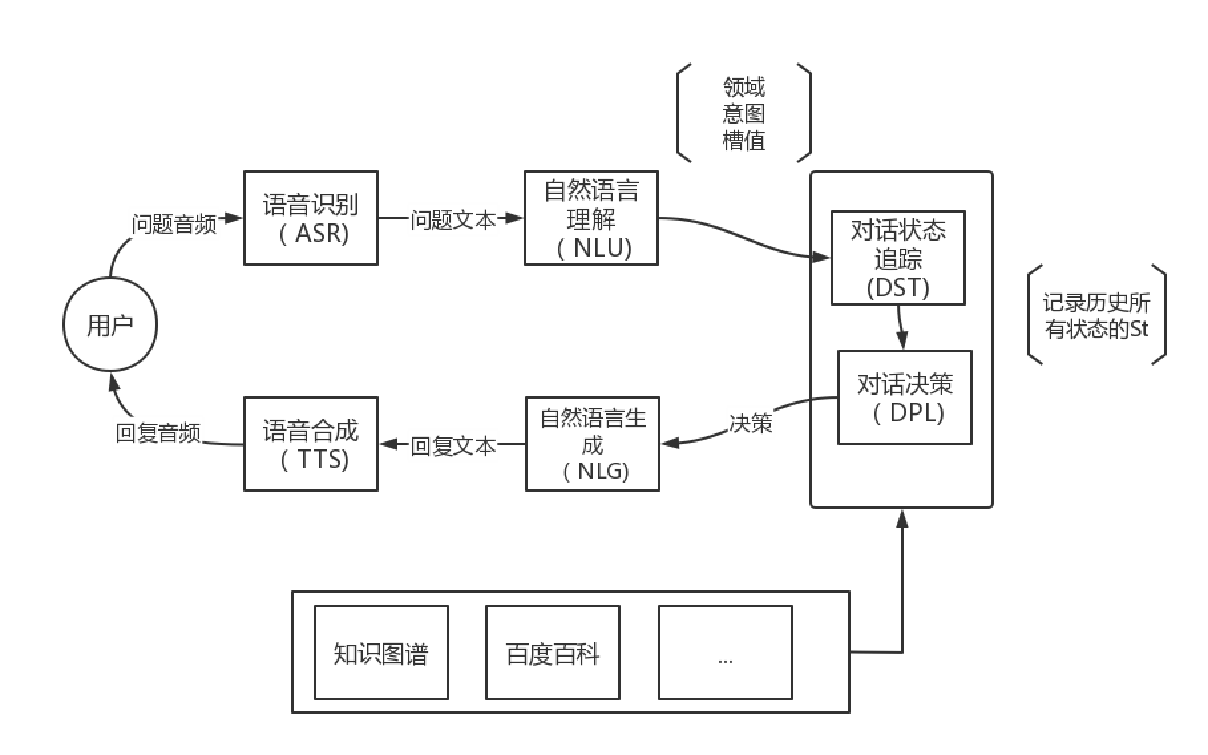
ASR:将音频识别成文本;
NLU:识别文本的意图和槽位信息,供系统决策使用;
DST:追踪和存储历史的对话状态,供决策使用;
DPL:基于历史信息(意图/槽位/系统回复),做决策;
NLG:生成回复文本;
TTS:将文本转化为语音;
传统管道式架构存在的问题
1.NLU基于上下文的理解:多数意图识别是基于本轮文本进行识别。但存在部分需要基于上轮文本进行识别的情况,如:
一轮:今天天气怎么样?
二轮:明天呐?
二轮是基于一轮的省略。
还有那种仅参考本轮为意图A,参考上轮信息为意图B的情况。
2.对话管理模块(DM),一直没有找到成熟的解决方案。
DM就是存储历史信息,并基于历史和当前轮数信息,决定下一步的动作(action)。这相当于人类的大脑的决策过程。
该模块,从开始的基于规则做特定的逻辑处理,到基于状态机转移,到基于深度学习模型(如rasa的ted模型),一直都不能做到通用和智能。
3.自然语言生成(NLG)本身就是一种生成。 前期通过将回复答案提前预制,通过分类模型选择哪个预制回复的方式,缺乏通用性和智能化。
且*以Bert为代表的自编码式的深度学习模型,其更适合做分类任务。*而想要做好智能问答系统(通用/友好),NLG应该是一种生成模型。
#大模型在任务型问答系统中应用
大模型的相关应用,也是当下探索的热点。下面也是本人的一点理解,勿喷
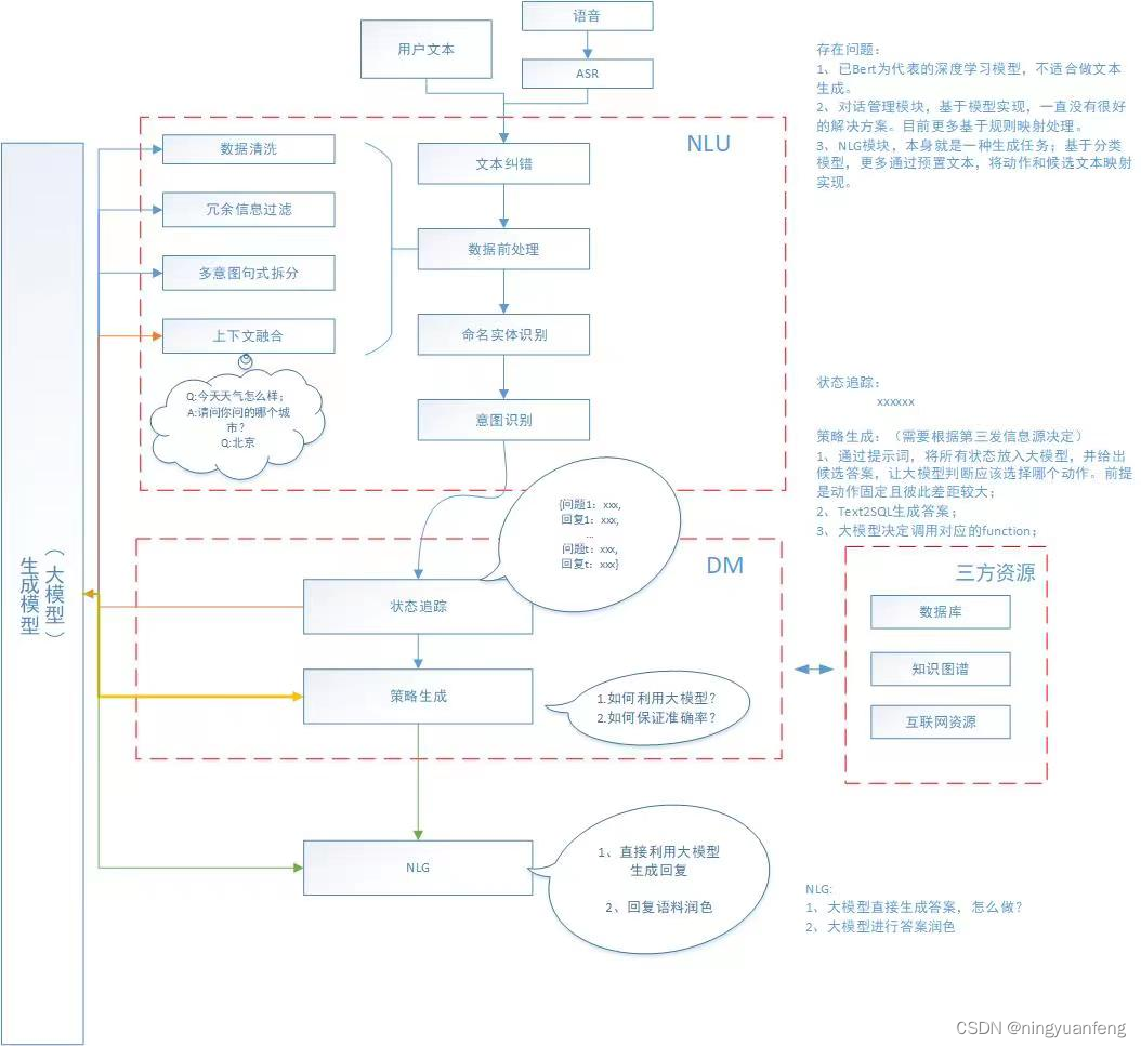
后续补充
#大模型智能问答系统
langchain架构,如果将agent引擎使用大模型,基本上就是大模型智能对话的架构了,个人理解,后续有时间补充