深度学习分布式系统
- 前言
- 1. 数据并行:参数服务器
- 2. 流水线并行:GPipe
- 3. 张量并行:Megatron LM
- 4. 切片并行:ZeRO
- 5. 异步分布式:PATHWAYS
- 总结
- 参考链接
前言
最近跟着李沐老师的视频学习了深度学习分布式系统的发展。这里说是分布式系统,其实还是有点勉强,准确来说是分布式的框架,但是毕竟是系统的文章,基于提出的框架也做了很多系统上的优化,姑且算是分布式系统吧。深度学习近些年随着Transformer模型的流行,呈现出模型越来越大,层数越来越深的趋势,然而在硬件方面,由于成本和技术的限制,难以匹配模型容量的快速发展,比如现有最新的深度学习专业加速器H100,其在容量上也只有80G,连LLaMA 7B都训不起来,因此单机多卡或者多机多卡已经成为模型训练主流的硬件配置。模型如何在多卡上高效运行,不同卡之间如何通信便是本篇学习笔记所关注的重点。
本篇博客主要从数据并行,模型并行,张量并行和参数切片四个方向对深度学习分布式系统进行介绍,分别涉及参数服务器、GPipe、Megatron-LM和Zero四篇文章,此外还会提及来自谷歌的Pathways,该文章的核心是如何将Jax拓展到上千TPU核上。
1. 数据并行:参数服务器
参数服务器这篇工作可谓是李沐老师成名之作,发表在OSDI2014。这篇文章提出了一个用于分布式机器学习问题的参数服务器框架。数据和任务都分布在工作节点上,而服务器节点维护全局的共享参数,表示为密集或稀疏的向量和矩阵。该框架管理节点之间的异步数据通信,支持灵活的一致性模型,具有弹性可扩展和持续容错特性。
对于大规模机器学习系统一直面临三个方面的问题:规模,算法和效率,如何在大规模的模型下,执行高效的分布式算法是业界的痛点。
参数服务器提供了五个关键的特性:高效通信,灵活一致模型,弹性可扩展性,容错性和耐久性和易用性。这些特性使得参数服务器可以作为通用的分布式系统处理工业界最大规模的数据。
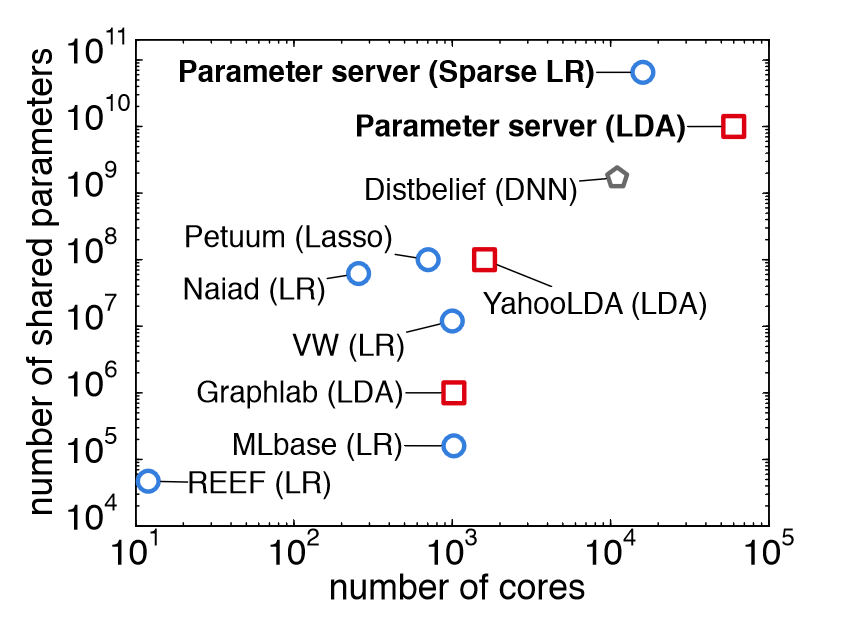
上图是同时期,在不同系统上执行最大监督和无监督学习实验的规模。很明显,本文的系统能够在数量级更大的处理器上覆盖数量级更大的数据。下图是参数服务器的架构图:

参数服务器节点分组为一个服务器组和多个工作组,如上图所示。
对于服务器组:
- 服务器组中的一个服务器节点维护全局共享参数的一个分区。
- 服务器节点之间相互通信以复制或迁移参数以实现可靠性和可扩展性。
- 服务器管理节点维护服务器数据一致性,如节点的生命周期。
对于工作组:
- 每个工作组运行一个应用程序。
- 节点通常在本地存储一部分训练数据用来计算局部统计数据如梯度。
- 节点仅与服务器节点之间通信,更新和共享参数。
- 每个工作组都有一个调度程序节点,分配任务并监控节点。
参数服务器支持独立的参数命令空间,这允许工作组将其共享的参数集与其他组分离。当然不同工作组也可以共享命名空间,可以用多个工作组并行处理深度学习应用。
参数服务器旨在简化分布式机器学习应用程序。
- 共享参数表示为(key, value)向量,利于线性代数运算。
- 共享参数分布在一组服务器节点上。
- 任何节点都可以上传本地参数并从远程节点拉取参数。
- 默认情况下任务是工作节点执行,也可以通过用户定义的函数分配给服务器节点。
- 任务是异步的并且并行运行。
- 参数服务器为算法设计者提供了灵活性,可以通过任务依赖图和判断来选择一致性模型传输参数的子集。
方法部分其实有很多精妙的方法和细节的实现,包括一致性模型,KKT过滤器,值缓存,压缩零等,这些细节可以看这篇博客进行深入的理解。下图是参数服务器和其他分布式机器学习系统的对比:
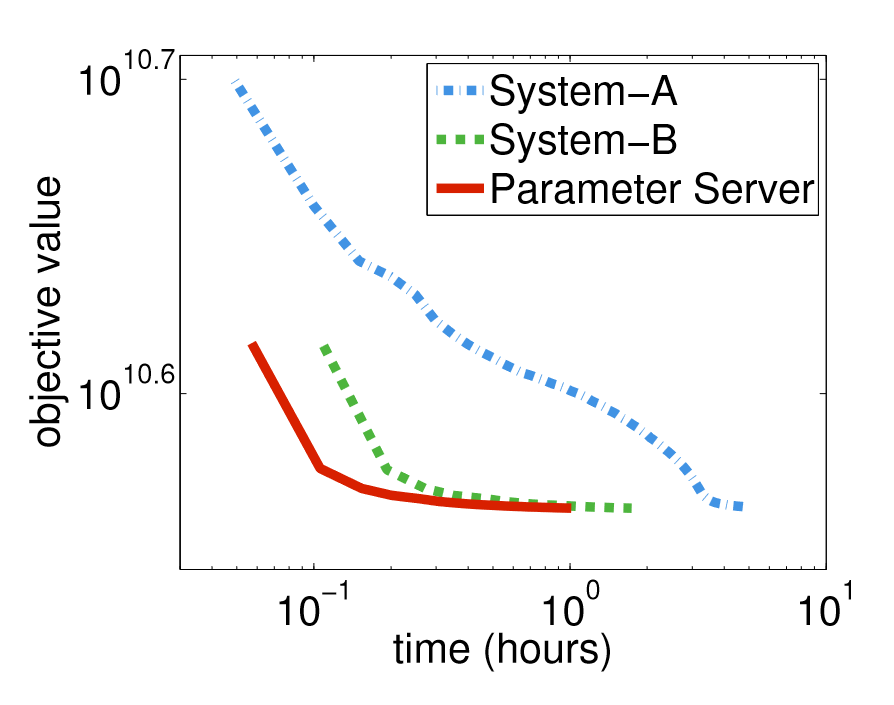
在回归模型收敛速度上,系统B优于A,因为实现了更好的算法。参数服务器优于系统B,因为参数服务器降低了网络流量以及应用了宽松一致性的模型。
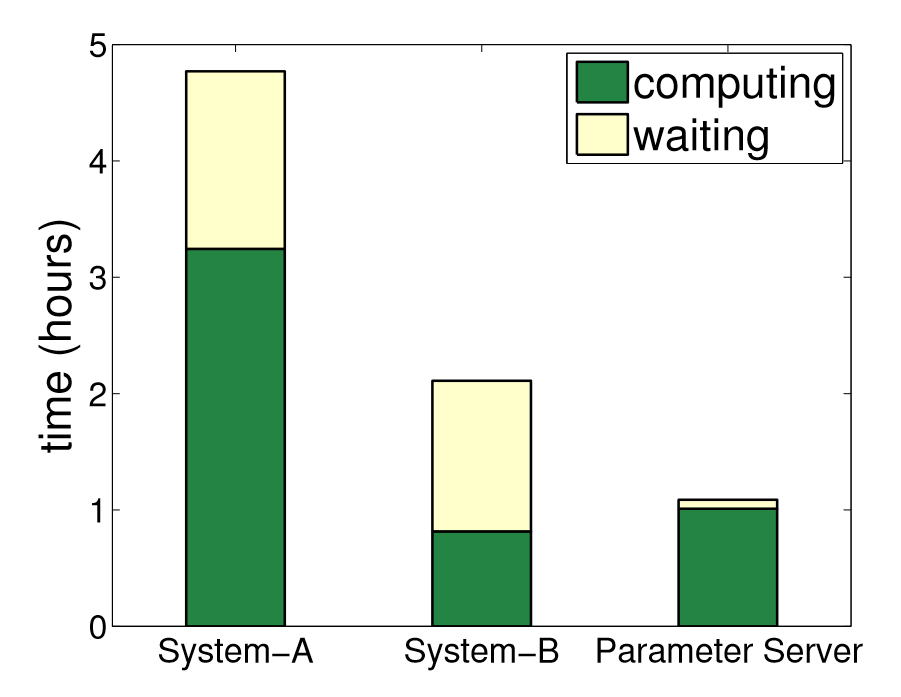
上图是逻辑回归期间,每个节点在计算和等待上的时间,显然参数服务器可以更好提高工作节点的利用率。
在我的这篇博客中,我做了针对于参数服务器的总结和个人的一些思考,主要分析其前瞻性,但是在我看了更多的前沿分布式机器学习系统后,我发现参数服务器的本质的工作是数据并行,只不过沐神将更多精力放在了节点之间通信开销和模型执行效率上,并没有过多提及数据并行的问题。
在大模型飞速发展的今天,传统的数据并行方法已经难以支撑大模型在单个工作节点上的运行,如何在可控开销范围内,将大模型运行起来,是当前相关研究人员亟待解决的问题。
2. 流水线并行:GPipe
为了解决大模型无法在单张显卡上运行的问题,GPipe提出了模型并行的方法,这篇工作来自于google团队,并中稿于NeurIPS2019。一篇系统的文章中稿于机器学习三大顶会之一的NeurIPS实属罕见,也恰恰证明这篇工作在深度学习领域的影响力。
GPipe的核心是模型并行,或者说是流水线并行。现有的模型模型并行方法在结构上有限制或要求,或者只能针对特定的任务。然而模型并行是大势所趋,下面是现有的模型在CV和NLP任务上的表现:
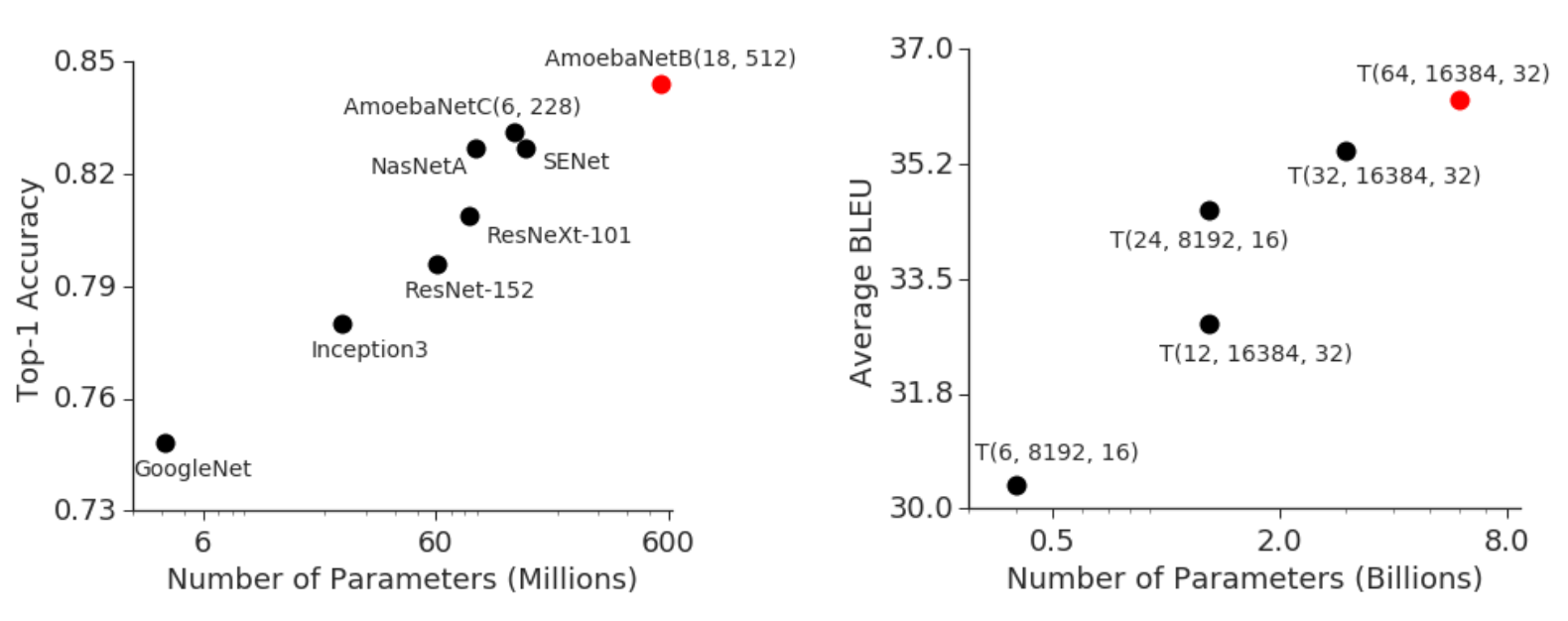
可以看到模型的参数越多,模型的性能就越好,而模型太大现有的硬件难以支持,因此一个通用的模型并行的算法可以解燃眉之急。
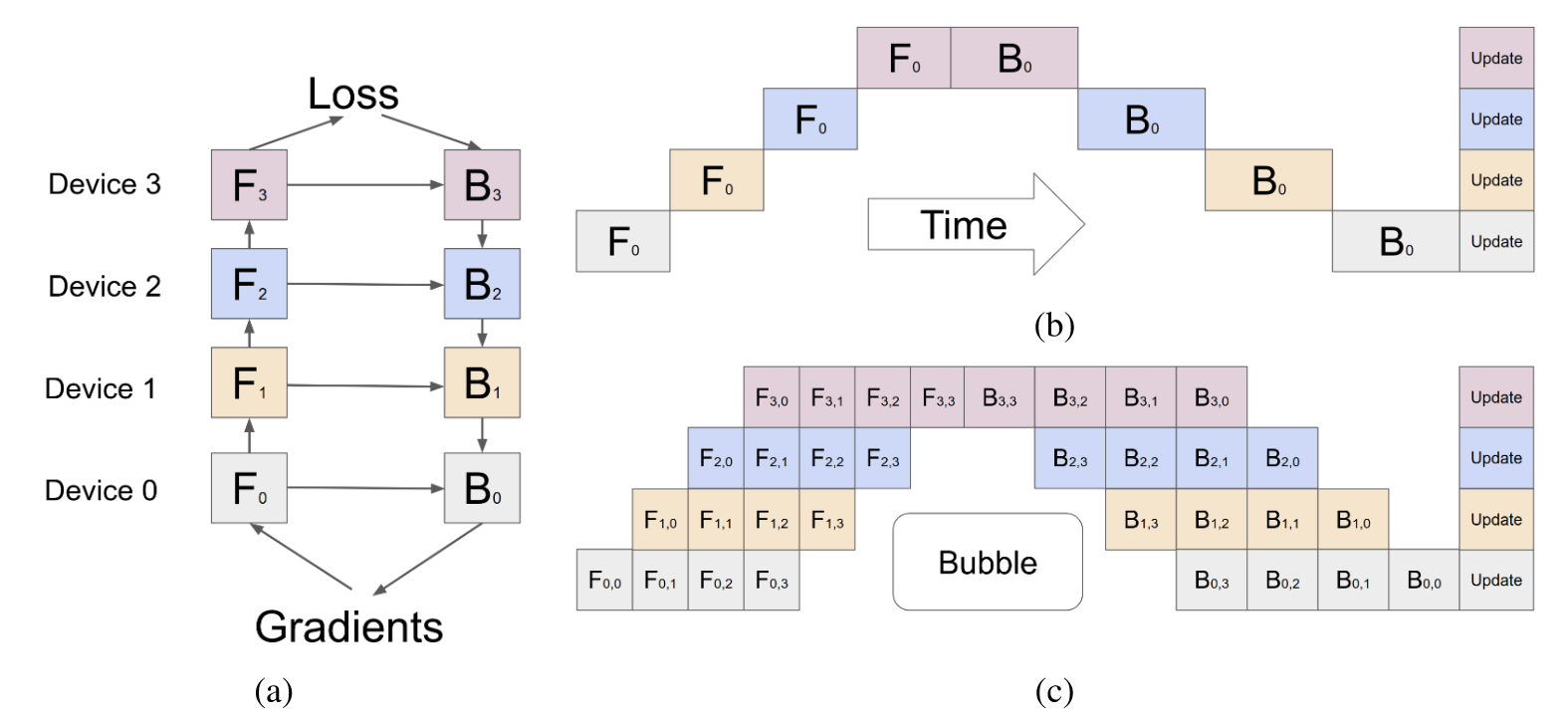
上图是GPipe的解决方案,其核心思想可以分为三点:
- 模型按层进行分组,每个组是连续的层序列。
- 提出microbatch的概念。
- re-materialization方法。
具体来说,(a)中将整个模型分成四个组,分别存储在四个不同的加速器中,这样虽然能够将模型运行起来,但是效率低下,如(b)所示,在训练阶段,每次只有一个加速器在执行计算,其它机器都在等待。为此,作者提出了microbatch,将输入的mini-batch进一步切分,达到类似于操作系统中流水线并行的效果,如(c)所示,除了Bubble的部分没有利用起来,其它时间段所有机器都在执行训练任务,大大提高了训练效率。
尽管如此,在训练过程中,由于梯度反向传播阶段需要保留每个microbatch的激活才能计算,因此占用了大量内存,如下图所示:
为了进一步减少内存的开销,作者提出re-materialization重计算技术,训练时将中间的激活丢弃,在反向传播时重新计算。这样虽然会带来额外的20%—30%计算开销,但也显著降低了加速器的内存占用。
最后总结一下GPipe这篇工作,GPipe具有高效性、灵活性和可靠性的特点,方法简单,效果显著,但是GPipe的缺点在于很难均匀地切分模型,导致每一块加速器运行时间很难同步,就会造成等待的现象。此外,额外的计算开销降低了模型的效率。因此,既然横向切分还是存在一定的问题,纵向切分可不可以解决这些问题呢?这就是接下来提到的张量并行,也是很多工作认为的真正的模型并行。
3. 张量并行:Megatron LM
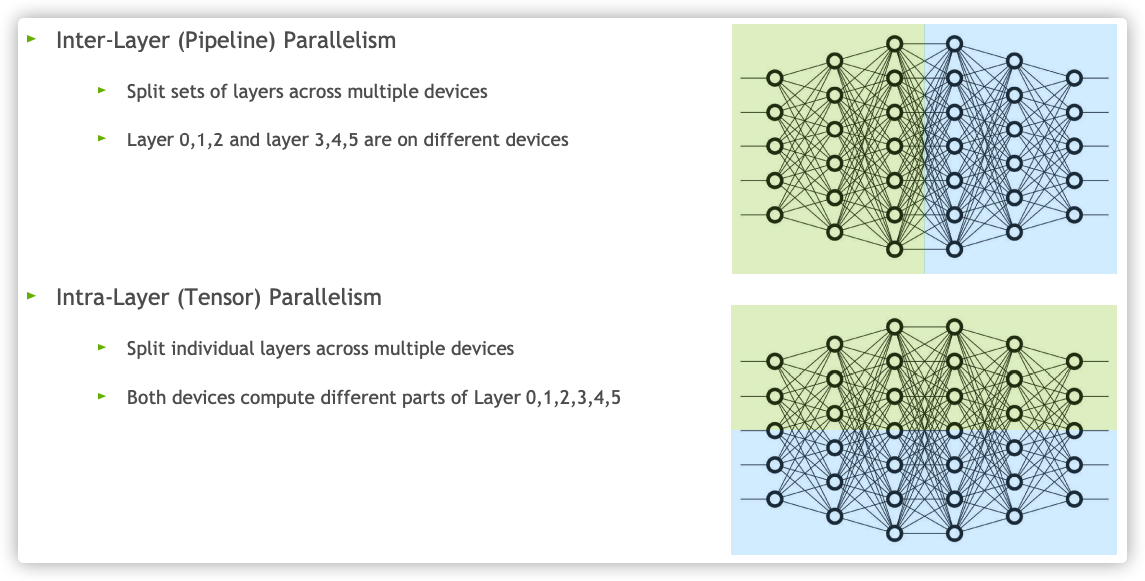
来自NVIDIA的Megatron LM是典型的张量并行方法,它的通用性不如GPipe,只针对Transformer模型。现有的模型并行方法主要分为两种:流水线并行和张量并行。
- 流水线并行把模型的不同层放在不同的设备上。
- 张量并行则是层内纵向切分,将权重参数放到不同的设备中。
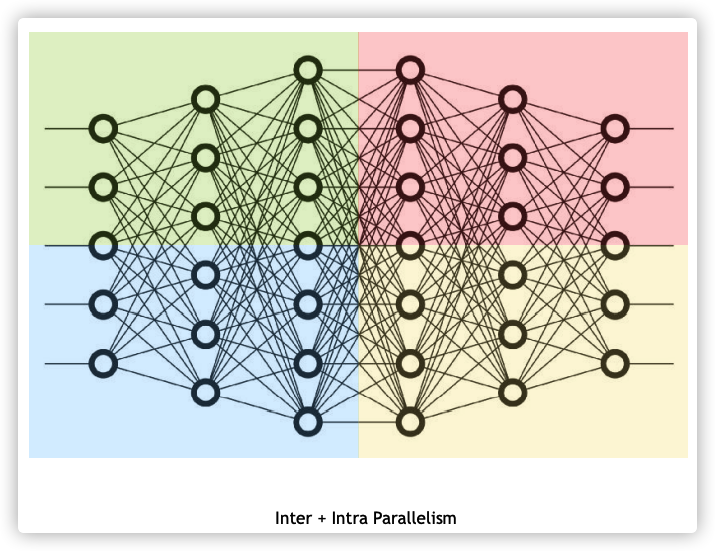
从另个角度来看,两种切分同时存在,是正交和互补的。
Megatron LM对Transformer的张量切片在每一层要进行两次,一次是对自注意力层进行切分,另一次是对FFN层进行切分。具体的切分过程如下图所示:
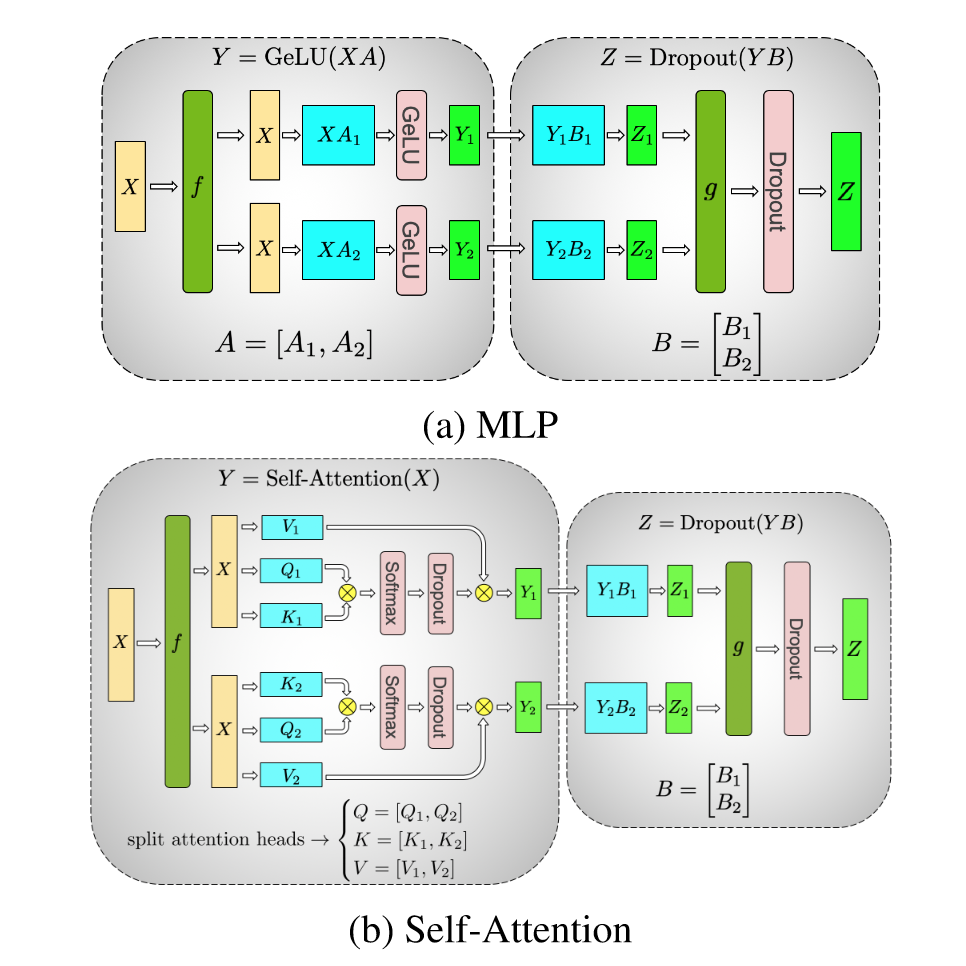
对于切割的部分,每次经过一层就要进行all-reduce,来保证参数的传递,这就导致了两个问题:
- all-reduce通信通过服务器之间的链接,这比服务器内多卡带宽NVLink要慢的多。
- 高度的模型并行产生很多小矩阵乘法,会降低GPU的利用率。
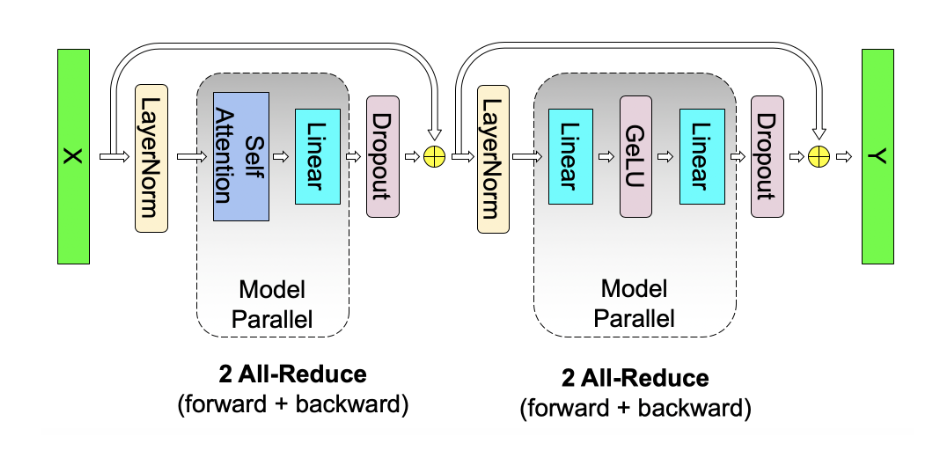
每层Transformer模块就需要进行四次的操作(前向两次,反向两次),也就是说,随着模型的层数加深,Megatron LM所需的通信成本就要线性增大。
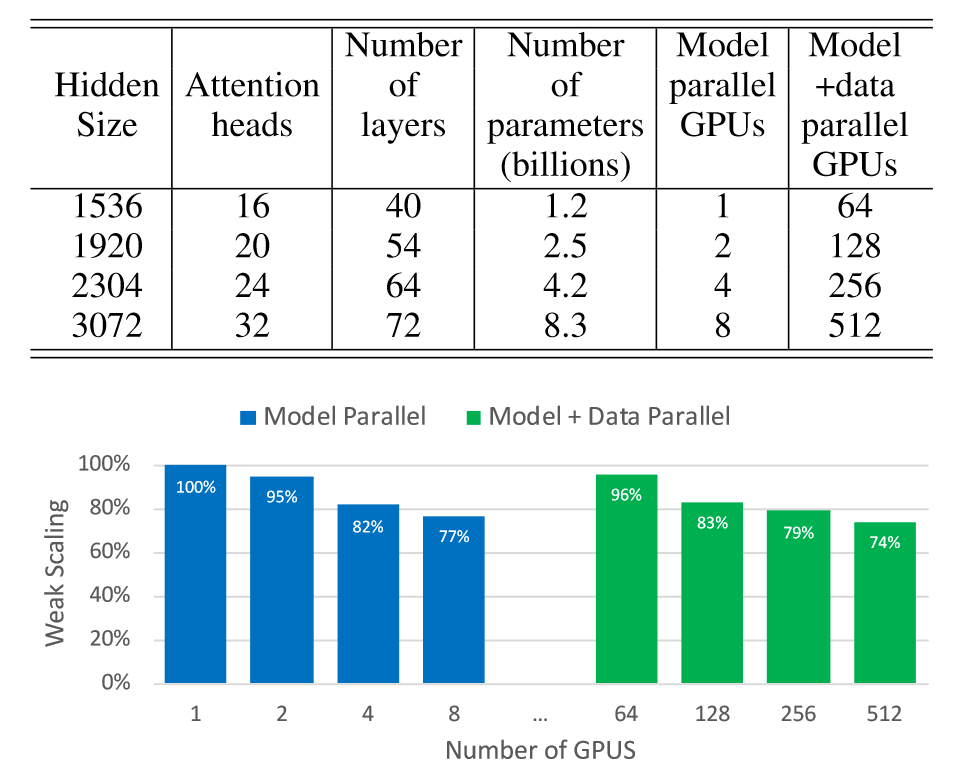
上图展示了Megatron LM的性能,随着单组GPU的增加,模型的性能稳定下降,在多服务器单卡时,模型仍有96%的性能,随着每个服务器中GPU的增加,模型的性能相对于单服务器相同卡的情况性能要略差些。
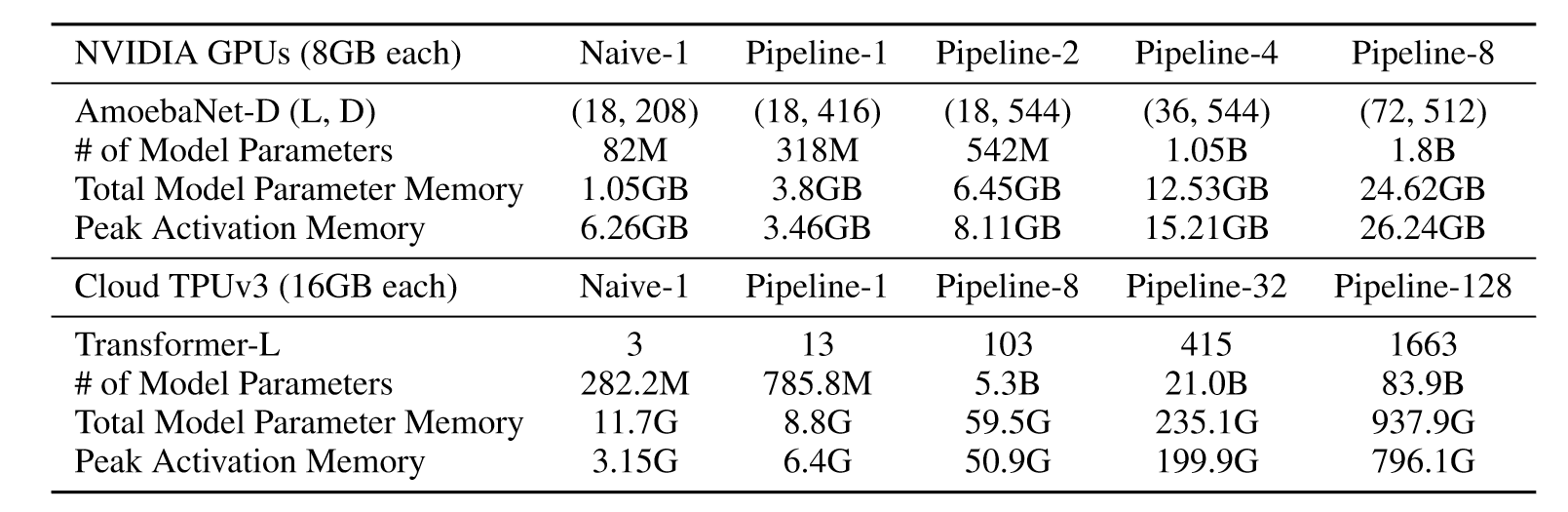
最后总结一下,Megatron实现了张量的并行,在训练性能上要优于GPipe,可以接近真正意义上的单卡训练,并且切分起来更加方便,无需考虑均匀分配问题。此外,它的局限性也很明显,首先它只对Transformer进行切分,第二它的通信量很大(大概是GPipe的10倍),不能做异步,等于用时间换空间。最后,这里的Megatron LM最多只能做到八卡并行,因为每张卡都存储了相同的输入和输出,占用了大量的显存空间,这在切片并行时可以得到解决。
4. 切片并行:ZeRO
在2022年3月,PyTorch提出了一个新的分布式API名叫FSDP,即完全分片的数据并行,其背后的思想就来自于ZeRO。ZeRO考虑的是如何将数据并行用到超大规模的神经网络训练上,并且在模型过大的时候如何将不需要的模块放到一个地方,在需要的时候再拿过来用。所以,也可以说ZeRO的核心思想是数据并行和模型并行。
当前对于模型装不下GPU的情况,虽然有模型并行和张量并行等方法,但是仍有scaling的瓶颈。比如张量并行对模型垂直切开,对于每个层都需要进行通信,当模型进一步扩大时性能会急速下降。ZeRO的作者分析,现有模型内存消耗主要分为两个部分:
- 对于大型模型,大部分内存被模型参数占用,包括Adam动量和方差、梯度和参数等。
- 激活值,临时缓存和碎片。
这里举个例子来说,对于1.5B的GPT-2模型,训练时采用半精度fp16,在Adam更新模型时需要采用fp32,这一块占用24GB的空间,然而真正算梯度的时候只需要3GB的显存,其余的21GB大部分时间都不会用上。此外在长度为1000、batch为32时,中间结果需要60GB的显存来存储。
针对上面问题,作者首先提出对模型的优化算法ZeRO-DP,即将模型切块放在不同地方,用的时候再拿来。其次是如何优化中间状态,称作ZeRO-R。
具体来说,对于ZeRO-DP,有如下的insight:
- 数据并行比模型并行效率高。
- 当前的并行方法都需要维护中间值。
因此ZeRO-DP采用数据并行的方法,并且对于某个中间值,只存储在一个GPU上,当别的GPU需要的时候再通信从该GPU上接收数据,其思想类似于参数服务器。
对于ZeRO-R,它的思想是说在Megatron中,每一层的参数虽然是并行的,但是输入却是相同的,即复制的,这个值可能会很大,因此ZeRO-R将这些输入也分成块,当一个GPU需要的时候,向其他拥有该分块的节点发送请求,这是一种带宽换空间的方法。对于缓存,给定固定的大小,当数据不用时就删除。对于碎片则采用内存整理。
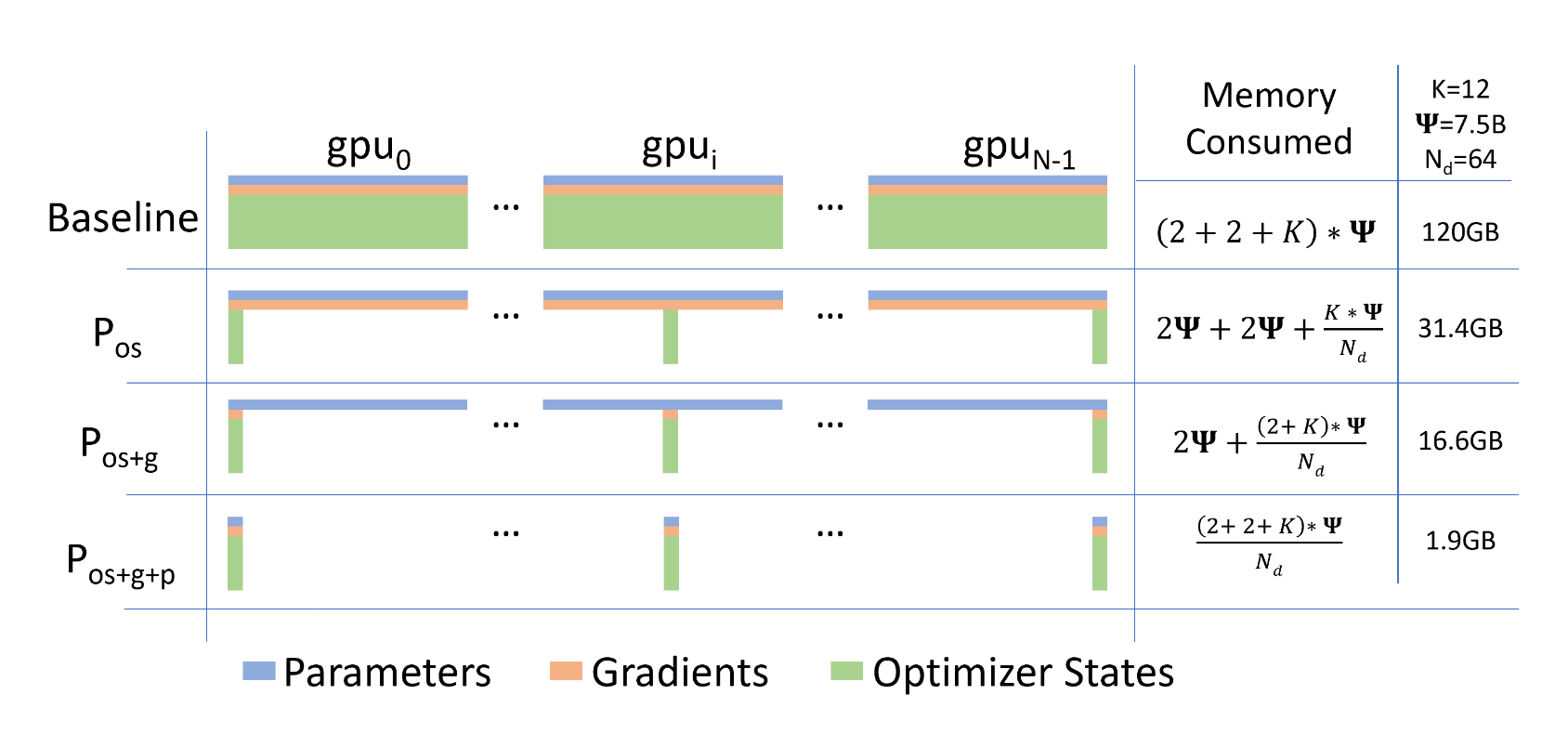 、
、
ZeRO-DP的过程如上表所示,其中
P
o
s
\mathrm{P_{os}}
Pos、
P
o
s
+
g
\mathrm{P_{os+g}}
Pos+g和
P
o
s
+
g
+
p
\mathrm{P_{os+g+p}}
Pos+g+p分别称为zero1,zero2和zero3,zero1对应着优化器参数的切片,zero2对应着zero1和梯度的切片,而zero3对应着zero2和模型参数的切片,可以看到当三种切片都采用的时候,单张卡上的显存占用明显减少。下表是不同规模模型对zero的使用情况:
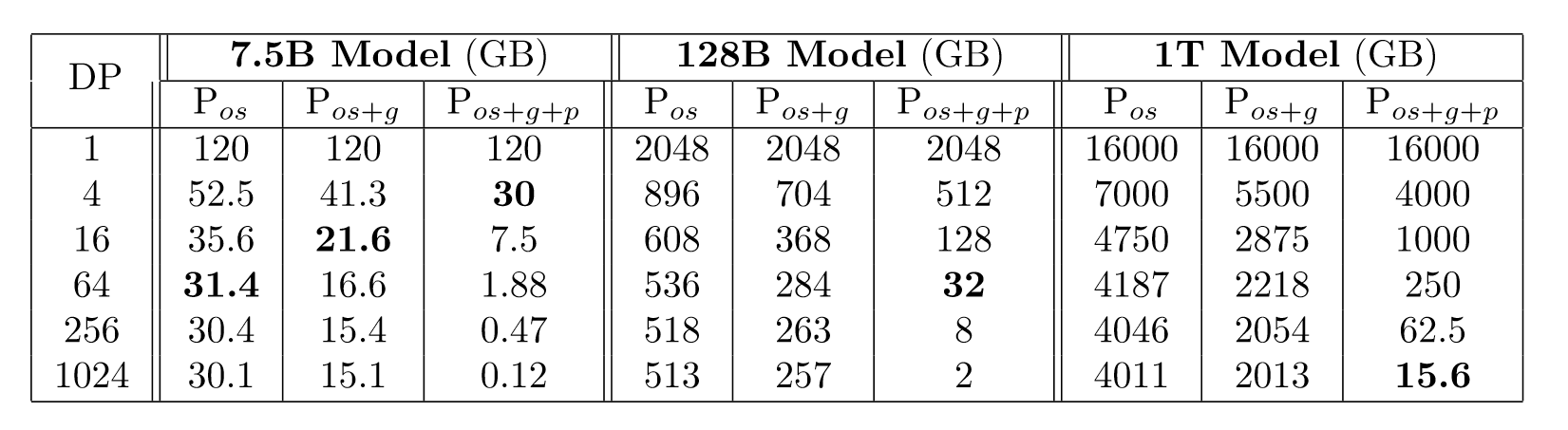
当模型越来越大的时候,比如1T的模型,也能在zero3、1024张GPU下运行。
ZeRO-R对中间变量进行处理降低其占用的内存。
P
a
P_a
Pa对输入(激活)做切分,和张量并行结合使用。
C
B
\mathrm{C}_B
CB对模型的通信参数做了一个固定的缓存,在同时并行GPU数量很多的情况下,每次向单个GPU发送的参数数量可能很小,因此通过设计一个缓存来尽可能发送更多的数据,提高模型的带宽通信效率,同时通过一个计时器防止较大的通信延时。但是过多的缓存会带来碎片问题,
M
D
\mathrm{M}_D
MD进行了碎片化管理,它将需要维护的内存开在了预选设定好的位置,其他位置都是可以随时析构的。
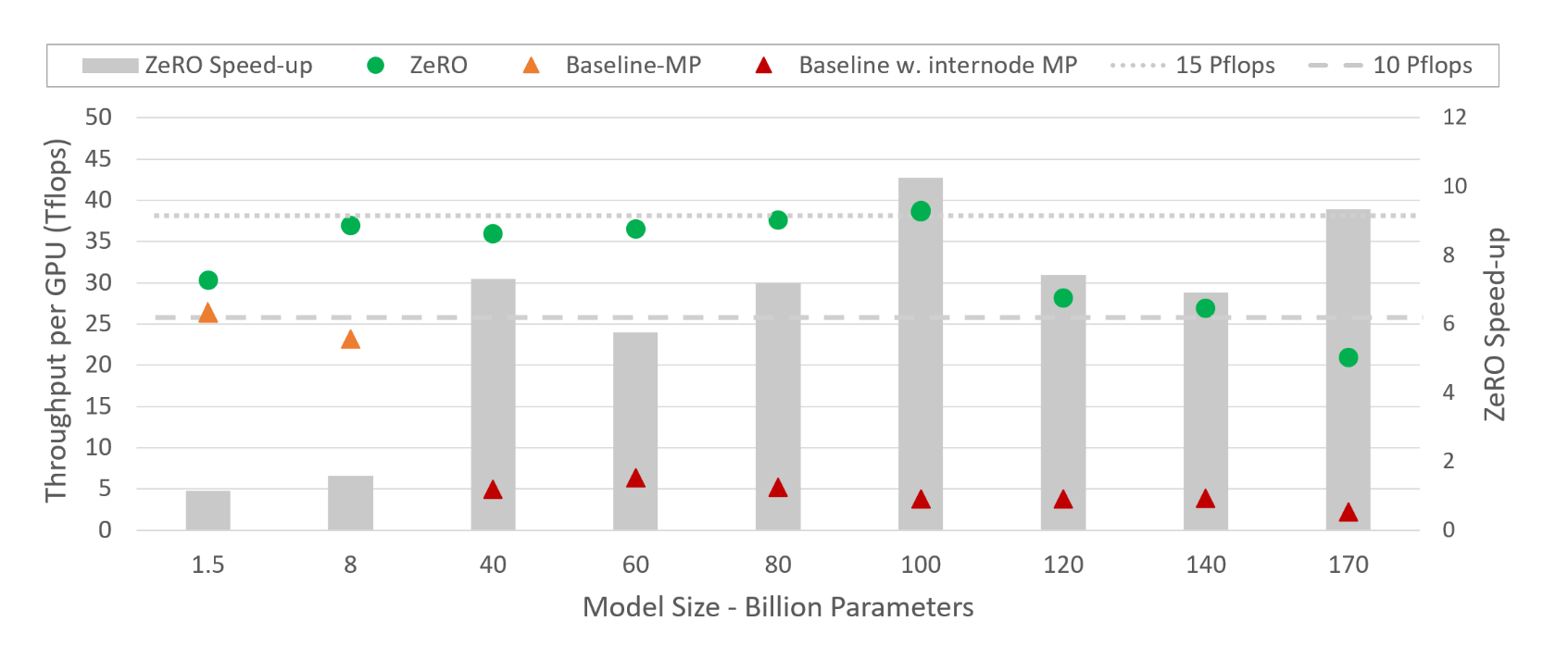
实验见上图所示,ZeRO和基线Megatron LM进行了对比,其中Megatron LM在超过8卡上由于需要不同机器之间的通信因此带来巨大的通信开销,导致性能大幅下降,而ZeRO却能一直保持比较稳定的计算峰值,当然也随着机器的增多逐渐下滑。
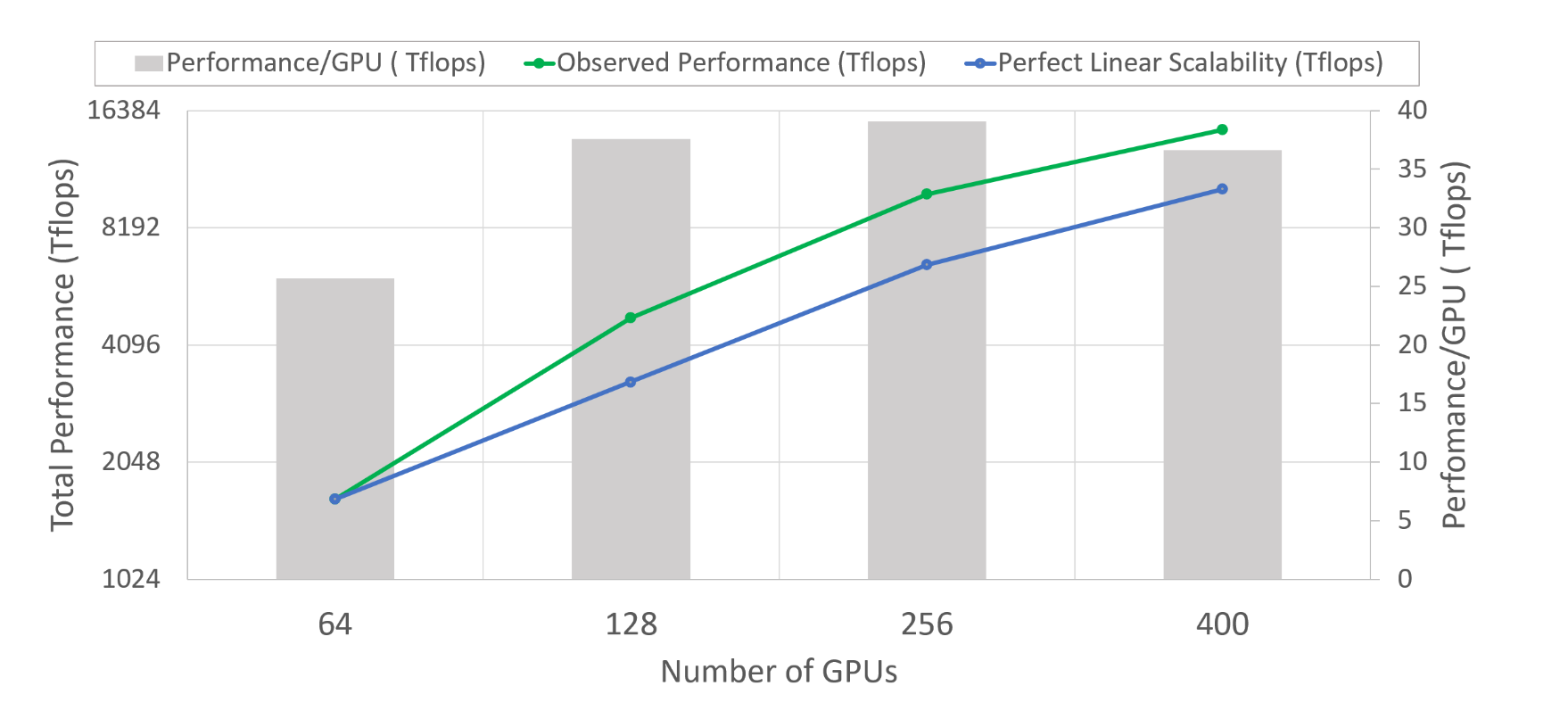
上图更能直接展示ZeRO超线性增长的趋势,其中随着GPU数量翻倍,模型的整体性能翻了不止一倍,这是因为随着单张卡上模型的参数变小,可以输入更大批量的数据,每块卡上矩阵变大,可以更高效利用GPU的多核,此外计算和通信比也变得更好了。
总结一下,ZeRO的算法相对来说还是比较简单实用的,其核心思想是all reduce时不需要在所有节点上重复,只需要在各自节点上all reduce就好。在不用完整数据的时候,维护好自己那一块就好,当需要的时候,再通过通信得到完整的数据。
5. 异步分布式:PATHWAYS
最后简单提及一下来自谷歌的PATHWAYS工作。该工作的核心为两点:
- 异步:通信延迟和调度延迟的处理。
- 分布式:针对更大规模模型在TPU上运行的处理。
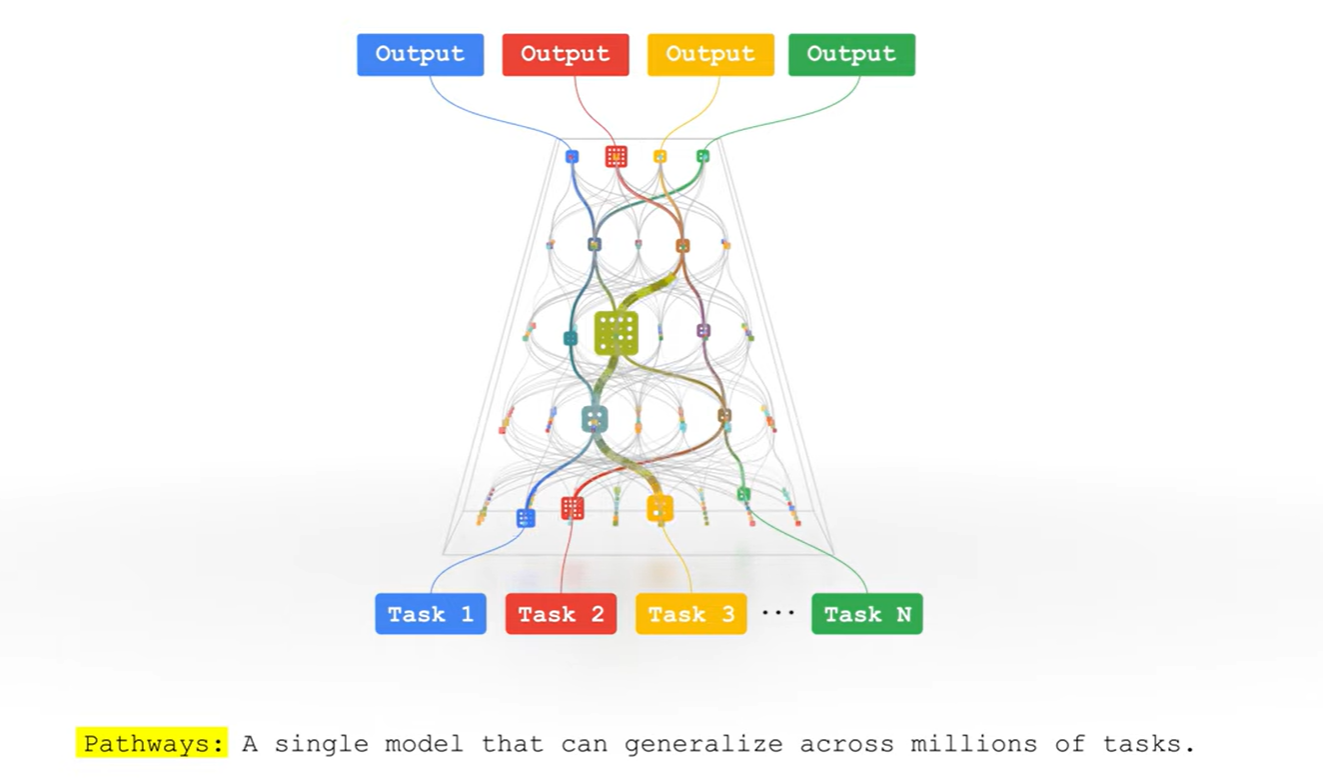
当前的分布式ML系统有着模型较大、计算稀疏、硬件异构等特性,并且难以进行异步计算。作者提出了岛的概念,来解决硬件异构性的问题,提高模型的灵活性,以及提升硬件的利用率。作者的愿景是开发出标准化的基础模型,可以适应多个下游任务,通过多任务多路复用资源提高集群的利用率,如下图所示:
现有的ML分布式系统架构如下图所示:

其中单控制器模型虽然灵活但是效率低,多控制器通信和调度延迟会带来挑战。
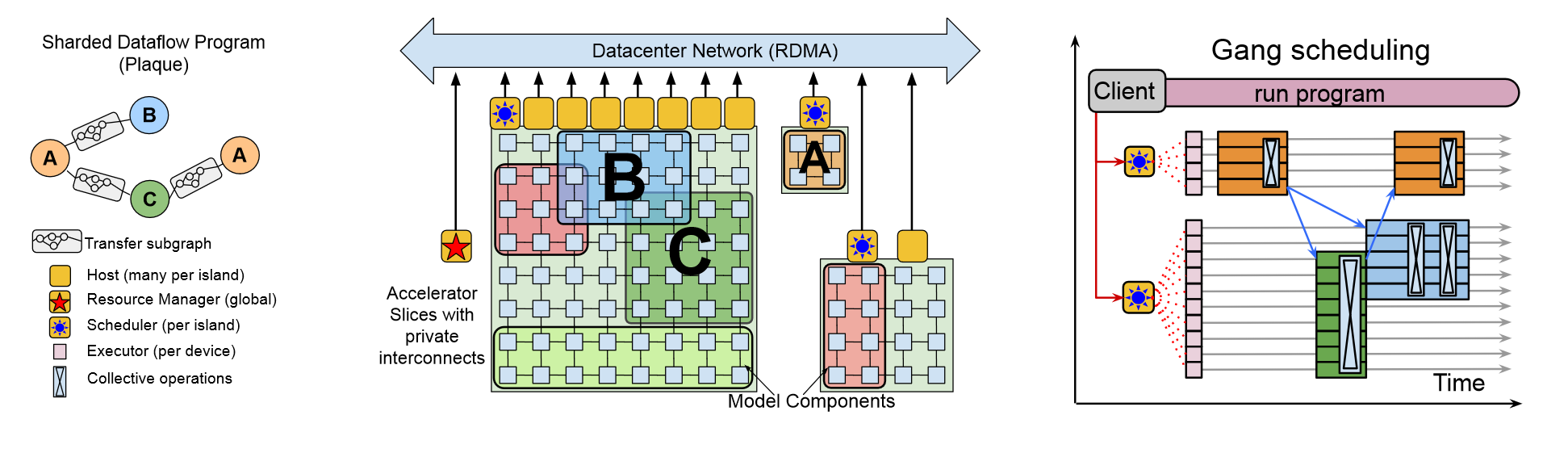
PASSWAYS的设计如上图所示,其中PLAQUE优化支持稀疏通信,让模型能够高效收发数据,一组加速器构成了PASSWAYS的后端,这些加速器被分为紧密相连的孤岛,孤岛之间通过DCN连接。岛内的TPU是高带宽连接的,岛与岛之间需要共享的数据中心网络,速度较慢。PASSWAYS的资源管理器负责集中管理岛屿上的设备,可以根据用户的需求进行加速器的分配。
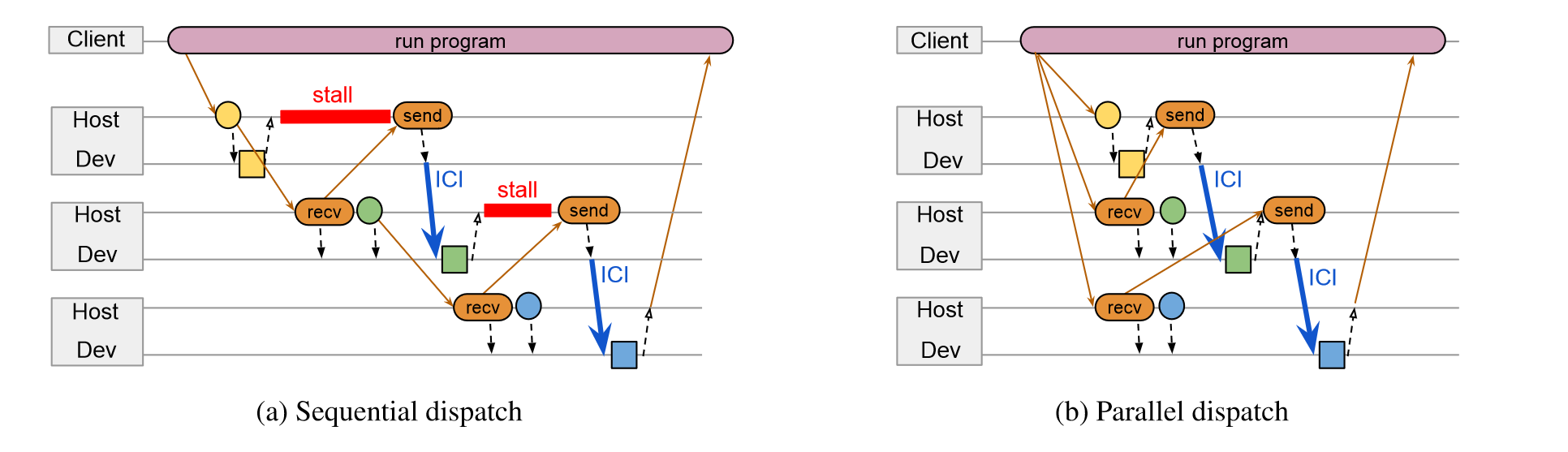
数据的分发上也采用了并行的分发,客户端编译后提前知道了发送的形状和接受的形状,减少了服务器额外的等待时间。
之所以没有细说PATHWAYS是因为它只是针对谷歌的TPU进行优化,而不能泛化到GPU中,并且文中的设想并没有真正实现,因此只需要简单了解就好了。
总结
本文对近十年来面向大模型的分布式机器学习的系统进行了介绍,从一开始的数据并行,到后来的流水线并行,再到张量并行,以及最后的切片并行,分布式机器学习系统的工作把能并行的数据都做了并行,大大减少了单张卡上的内存占用,也让更大的模型在大规模集群上运行起来成为了可能,当然,并行上的工作已经差不多了,后续的工作更多会在通信上进行优化,以及模型异步的实现,其本质的目标都是让即使是很大的模型也像在单张卡上运行的效果,正如PASSWAYS的设想那样,让多个小模型集成为一个超大的模型,从而泛化到更多任务上,或者是大一统的模型,能够处理所有任务,总之,这样的工作都离不开底层分布式系统的设计,除非在硬件上真正实现巨大的突破。
参考链接
https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf
https://blog.csdn.net/HERODING23/article/details/128701938
https://proceedings.neurips.cc/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
https://arxiv.org/pdf/1910.02054.pdf
https://arxiv.org/pdf/1909.08053.pdf
https://arxiv.org/pdf/2203.12533.pdf