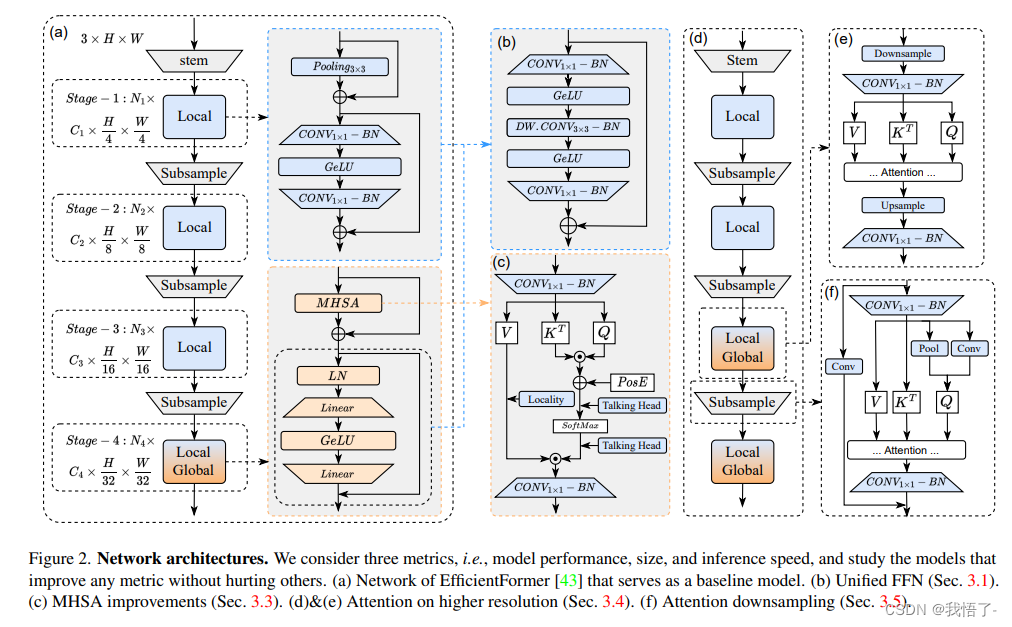
EfficientFormerV2
随着视觉Transformers(ViTs)在计算机视觉任务中的成功,最近的技术试图优化ViT的性能和复杂性,以实现在移动设备上的高效部署。研究人员提出了多种方法来加速注意力机制,改进低效设计,或结合mobile-friendly的轻量级卷积来形成混合架构。然而,ViT及其变体仍然比轻量级的CNNs具有更高的延迟或更多的参数,即使对于多年前的MobileNet也是如此。实际上,延迟和大小对于资源受限硬件上的高效部署都至关重要。在这项工作中,论文研究了一个中心问题,ViT模型是否可以像MobileNet一样快速运行并保持类似的大小?论文重新审视了ViT的设计选择,并提出了一种具有低延迟和高参数效率的改进型超网络。论文进一步引入了一种细粒度联合搜索策略,该策略可以通过同时优化延迟和参数量来找到有效的架构。所提出的模型EfficientFormerV2在ImageNet-1K上实现了比MobileNetV2和MobileNetV1高约4%的top-1精度,具有相似的延迟和参数。论文证明,适当设计和优化的ViT可以以MobileNet级别的大小和速度实现高性能。
原文地址:Rethinking Vision Transformers for MobileNet Size and Speed
EfficientFormerV2代码实现
"""
EfficientFormer_v2
"""
import os
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Dict
import itertools
import numpy as np
from timm.models.layers import DropPath, trunc_normal_, to_2tuple
__all__ = ['efficientformerv2_s0', 'efficientformerv2_s1', 'efficientformerv2_s2', 'efficientformerv2_l']
EfficientFormer_width = {
'L': [40, 80, 192, 384], # 26m 83.3% 6attn
'S2': [32, 64, 144, 288], # 12m 81.6% 4attn dp0.02
'S1': [32, 48, 120, 224], # 6.1m 79.0
'S0': [32, 48, 96, 176], # 75.0 75.7
}
EfficientFormer_depth = {
'L': [5, 5, 15, 10], # 26m 83.3%
'S2': [4, 4, 12, 8], # 12m
'S1': [3, 3, 9, 6], # 79.0
'S0': [2, 2, 6, 4], # 75.7
}
# 26m
expansion_ratios_L = {
'0': [4, 4, 4, 4, 4],
'1': [4, 4, 4, 4, 4],
'2': [4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4],
'3': [4, 4, 4, 3, 3, 3, 3, 4, 4, 4],
}
# 12m
expansion_ratios_S2 = {
'0': [4, 4, 4, 4],
'1': [4, 4, 4, 4],
'2': [4, 4, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4],
'3': [4, 4, 3, 3, 3, 3, 4, 4],
}
# 6.1m
expansion_ratios_S1 = {
'0': [4, 4, 4],
'1': [4, 4, 4],
'2': [4, 4, 3, 3, 3, 3, 4, 4, 4],
'3': [4, 4, 3, 3, 4, 4],
}
# 3.5m
expansion_ratios_S0 = {
'0': [4, 4],
'1': [4, 4],
'2': [4, 3, 3, 3, 4, 4],
'3': [4, 3, 3, 4],
}
class Attention4D(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7,
act_layer=nn.ReLU,
stride=None):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
if stride is not None:
self.resolution = math.ceil(resolution / stride)
self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),
nn.BatchNorm2d(dim), )
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')
else:
self.resolution = resolution
self.stride_conv = None
self.upsample = None
self.N = self.resolution ** 2
self.N2 = self.N
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),
nn.BatchNorm2d(self.num_heads * self.d),
)
self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,
kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d), )
self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.proj = nn.Sequential(act_layer(),
nn.Conv2d(self.dh, dim, 1),
nn.BatchNorm2d(dim), )
points = list(itertools.product(range(self.resolution), range(self.resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, C, H, W = x.shape
if self.stride_conv is not None:
x = self.stride_conv(x)
q = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v)
v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
attn = (
(q @ k) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
# attn = (q @ k) * self.scale
attn = self.talking_head1(attn)
attn = attn.softmax(dim=-1)
attn = self.talking_head2(attn)
x = (attn @ v)
out = x.transpose(2, 3).reshape(B, self.dh, self.resolution, self.resolution) + v_local
if self.upsample is not None:
out = self.upsample(out)
out = self.proj(out)
return out
def stem(in_chs, out_chs, act_layer=nn.ReLU):
return nn.Sequential(
nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs // 2),
act_layer(),
nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs),
act_layer(),
)
class LGQuery(torch.nn.Module):
def __init__(self, in_dim, out_dim, resolution1, resolution2):
super().__init__()
self.resolution1 = resolution1
self.resolution2 = resolution2
self.pool = nn.AvgPool2d(1, 2, 0)
self.local = nn.Sequential(nn.Conv2d(in_dim, in_dim, kernel_size=3, stride=2, padding=1, groups=in_dim),
)
self.proj = nn.Sequential(nn.Conv2d(in_dim, out_dim, 1),
nn.BatchNorm2d(out_dim), )
def forward(self, x):
local_q = self.local(x)
pool_q = self.pool(x)
q = local_q + pool_q
q = self.proj(q)
return q
class Attention4DDownsample(torch.nn.Module):
def __init__(self, dim=384, key_dim=16, num_heads=8,
attn_ratio=4,
resolution=7,
out_dim=None,
act_layer=None,
):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.resolution = resolution
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
if out_dim is not None:
self.out_dim = out_dim
else:
self.out_dim = dim
self.resolution2 = math.ceil(self.resolution / 2)
self.q = LGQuery(dim, self.num_heads * self.key_dim, self.resolution, self.resolution2)
self.N = self.resolution ** 2
self.N2 = self.resolution2 ** 2
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),
nn.BatchNorm2d(self.num_heads * self.d),
)
self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,
kernel_size=3, stride=2, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d), )
self.proj = nn.Sequential(
act_layer(),
nn.Conv2d(self.dh, self.out_dim, 1),
nn.BatchNorm2d(self.out_dim), )
points = list(itertools.product(range(self.resolution), range(self.resolution)))
points_ = list(itertools.product(
range(self.resolution2), range(self.resolution2)))
N = len(points)
N_ = len(points_)
attention_offsets = {}
idxs = []
for p1 in points_:
for p2 in points:
size = 1
offset = (
abs(p1[0] * math.ceil(self.resolution / self.resolution2) - p2[0] + (size - 1) / 2),
abs(p1[1] * math.ceil(self.resolution / self.resolution2) - p2[1] + (size - 1) / 2))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N_, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, C, H, W = x.shape
q = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N2).permute(0, 1, 3, 2)
k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v)
v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
attn = (
(q @ k) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
# attn = (q @ k) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(2, 3)
out = x.reshape(B, self.dh, self.resolution2, self.resolution2) + v_local
out = self.proj(out)
return out
class Embedding(nn.Module):
def __init__(self, patch_size=3, stride=2, padding=1,
in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2d,
light=False, asub=False, resolution=None, act_layer=nn.ReLU, attn_block=Attention4DDownsample):
super().__init__()
self.light = light
self.asub = asub
if self.light:
self.new_proj = nn.Sequential(
nn.Conv2d(in_chans, in_chans, kernel_size=3, stride=2, padding=1, groups=in_chans),
nn.BatchNorm2d(in_chans),
nn.Hardswish(),
nn.Conv2d(in_chans, embed_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(embed_dim),
)
self.skip = nn.Sequential(
nn.Conv2d(in_chans, embed_dim, kernel_size=1, stride=2, padding=0),
nn.BatchNorm2d(embed_dim)
)
elif self.asub:
self.attn = attn_block(dim=in_chans, out_dim=embed_dim,
resolution=resolution, act_layer=act_layer)
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.conv = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.bn = norm_layer(embed_dim) if norm_layer else nn.Identity()
else:
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
if self.light:
out = self.new_proj(x) + self.skip(x)
elif self.asub:
out_conv = self.conv(x)
out_conv = self.bn(out_conv)
out = self.attn(x) + out_conv
else:
x = self.proj(x)
out = self.norm(x)
return out
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0., mid_conv=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.mid_conv = mid_conv
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
if self.mid_conv:
self.mid = nn.Conv2d(hidden_features, hidden_features, kernel_size=3, stride=1, padding=1,
groups=hidden_features)
self.mid_norm = nn.BatchNorm2d(hidden_features)
self.norm1 = nn.BatchNorm2d(hidden_features)
self.norm2 = nn.BatchNorm2d(out_features)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = self.act(x)
if self.mid_conv:
x_mid = self.mid(x)
x_mid = self.mid_norm(x_mid)
x = self.act(x_mid)
x = self.drop(x)
x = self.fc2(x)
x = self.norm2(x)
x = self.drop(x)
return x
class AttnFFN(nn.Module):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.ReLU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
resolution=7, stride=None):
super().__init__()
self.token_mixer = Attention4D(dim, resolution=resolution, act_layer=act_layer, stride=stride)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop, mid_conv=True)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1 * self.token_mixer(x))
x = x + self.drop_path(self.layer_scale_2 * self.mlp(x))
else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x))
return x
class FFN(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop, mid_conv=True)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_2 * self.mlp(x))
else:
x = x + self.drop_path(self.mlp(x))
return x
def eformer_block(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, vit_num=1, resolution=7, e_ratios=None):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
mlp_ratio = e_ratios[str(index)][block_idx]
if index >= 2 and block_idx > layers[index] - 1 - vit_num:
if index == 2:
stride = 2
else:
stride = None
blocks.append(AttnFFN(
dim, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
resolution=resolution,
stride=stride,
))
else:
blocks.append(FFN(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
blocks = nn.Sequential(*blocks)
return blocks
class EfficientFormerV2(nn.Module):
def __init__(self, layers, embed_dims=None,
mlp_ratios=4, downsamples=None,
pool_size=3,
norm_layer=nn.BatchNorm2d, act_layer=nn.GELU,
num_classes=1000,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=True,
vit_num=0,
resolution=640,
e_ratios=expansion_ratios_L,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = stem(3, embed_dims[0], act_layer=act_layer)
network = []
for i in range(len(layers)):
stage = eformer_block(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios,
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
resolution=math.ceil(resolution / (2 ** (i + 2))),
vit_num=vit_num,
e_ratios=e_ratios)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]:
# downsampling between two stages
if i >= 2:
asub = True
else:
asub = False
network.append(
Embedding(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i + 1],
resolution=math.ceil(resolution / (2 ** (i + 2))),
asub=asub,
act_layer=act_layer, norm_layer=norm_layer,
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, resolution, resolution))]
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
return outs
def forward(self, x):
x = self.patch_embed(x)
x = self.forward_tokens(x)
return x
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def efficientformerv2_s0(weights='', **kwargs):
model = EfficientFormerV2(
layers=EfficientFormer_depth['S0'],
embed_dims=EfficientFormer_width['S0'],
downsamples=[True, True, True, True, True],
vit_num=2,
drop_path_rate=0.0,
e_ratios=expansion_ratios_S0,
**kwargs)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
def efficientformerv2_s1(weights='', **kwargs):
model = EfficientFormerV2(
layers=EfficientFormer_depth['S1'],
embed_dims=EfficientFormer_width['S1'],
downsamples=[True, True, True, True],
vit_num=2,
drop_path_rate=0.0,
e_ratios=expansion_ratios_S1,
**kwargs)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
def efficientformerv2_s2(weights='', **kwargs):
model = EfficientFormerV2(
layers=EfficientFormer_depth['S2'],
embed_dims=EfficientFormer_width['S2'],
downsamples=[True, True, True, True],
vit_num=4,
drop_path_rate=0.02,
e_ratios=expansion_ratios_S2,
**kwargs)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
def efficientformerv2_l(weights='', **kwargs):
model = EfficientFormerV2(
layers=EfficientFormer_depth['L'],
embed_dims=EfficientFormer_width['L'],
downsamples=[True, True, True, True],
vit_num=6,
drop_path_rate=0.1,
e_ratios=expansion_ratios_L,
**kwargs)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
if __name__ == '__main__':
inputs = torch.randn((1, 3, 640, 640))
model = efficientformerv2_s0('eformer_s0_450.pth')
res = model(inputs)
for i in res:
print(i.size())
model = efficientformerv2_s1('eformer_s1_450.pth')
res = model(inputs)
for i in res:
print(i.size())
model = efficientformerv2_s2('eformer_s2_450.pth')
res = model(inputs)
for i in res:
print(i.size())
model = efficientformerv2_l('eformer_l_450.pth')
res = model(inputs)
for i in res:
print(i.size())
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
is_backbone = False
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
try:
t = m
m = eval(m) if isinstance(m, str) else m # eval strings
except:
pass
for j, a in enumerate(args):
with contextlib.suppress(NameError):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
args[j] = a
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif isinstance(m, str):
t = m
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
elif m in {efficientformerv2_s0}: #可添加更多Backbone
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
yaml配置文件修改
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, efficientformerv2_s0, [False]], # 4
[-1, 1, SPPF, [1024, 5]], # 5
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 6
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7
[[-1, 3], 1, Concat, [1]], # cat backbone P4 8
[-1, 3, C3, [512, False]], # 9
[-1, 1, Conv, [256, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11
[[-1, 2], 1, Concat, [1]], # cat backbone P3 12
[-1, 3, C3, [256, False]], # 13 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 14
[[-1, 10], 1, Concat, [1]], # cat head P4 15
[-1, 3, C3, [512, False]], # 16 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 17
[[-1, 5], 1, Concat, [1]], # cat head P5 18
[-1, 3, C3, [1024, False]], # 19 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]