Elasticsearch(简称为ES)是一个基于Lucene的开源搜索和分析引擎,提供了丰富的聚合查询功能。聚合查询指的是在搜索结果上执行分组、汇总和统计等操作,以便从大量数据中提取有用的信息和洞察。
这篇文章主要介绍检索相关的操作,单值、多值、范围、模糊等查询方式,使用bool支持多种条件复杂查询。
一、环境准备
版本
Docker version 20.10.22
elasticsearch:7.13.3
kibana:7.13.3
ps:具体启动命令参考第一篇ES博客
二、聚合查询(metrics)
metrics 聚合查询是 Elasticsearch 聚合查询的一种类型,用于计算某个字段的统计指标,如平均值、总和、最大值、最小值、计数等。
常用统计方法
下面是常用的统计值:
- avg:计算数值字段的平均值。
- sum:对数值字段进行求和。
- min:找到数值字段的最小值。
- max:找到数值字段的最大值。
- stats:计算数值字段的最小值、最大值、平均值和总和。
查询示例
还是以bank索引为例子,"size": 0可以不返回原始数据。
// 查询薪水的平均值
POST /bank/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
},
// 不需要查询原数据,只返回聚合结果
"size": 0,
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
// 查询各种指标
POST /bank/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
},
"size": 0,
"aggs": {
"stats_balance": {
"stats": {
"field": "balance"
}
}
}
}
// 返回值
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"stats_balance" : {
"count" : 1000,// 数量
"min" : 1011.0,// 最小值
"max" : 49989.0,// 最大值
"avg" : 25714.837,// 平均值
"sum" : 2.5714837E7// 总和
}
}
}
三、桶聚合查询(Bucket)
桶聚合查询(Bucket Aggregations)是 Elasticsearch 聚合查询的一种类型,用于按照指定条件将文档分配到不同的"桶"中,并对每个桶进行聚合操作。桶聚合可以根据不同的字段值或范围进行分组和统计,以便提取有关数据集的更详细的信息和洞察。
PS:在桶查询中会有自定义名称,我这里会使用**_self**的后缀来体现。
常用查询类型
以下是一些常见的桶聚合查询类型及其功能:
- terms:根据某个字段的值进行分组,创建多个桶,并统计每个桶中的文档数量。
- date_histogram:根据时间字段将文档分配到不同的时间段桶中。
- range:根据某个字段的值范围将文档分配到不同的桶,并在每个桶上执行其他聚合操作。
- histogram:根据数值字段将文档分配到不同的数值段桶中,可以指定桶的间隔大小,并对每个数值段桶进行其他聚合操作。
- geo_distance:根据地理位置字段将文档分配到不同的距离范围桶中,可以指定中心点和距离范围,并在每个距离范围桶上执行其他聚合操作。
- nested:用于在嵌套的文档结构中进行聚合操作。可以创建多级的嵌套聚合来处理复杂的嵌套数据。
聚合查询
根据年龄进行分组查询。
类似于MySQL中的group by命令,对相同字段进行聚合,等价于select count(*) from bank group by age;
POST /bank/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
},
"size": 0,
"aggs": {
// 自定义查询名称
"age_group_self": {
"terms": {
"field": "age"
}
}
}
}
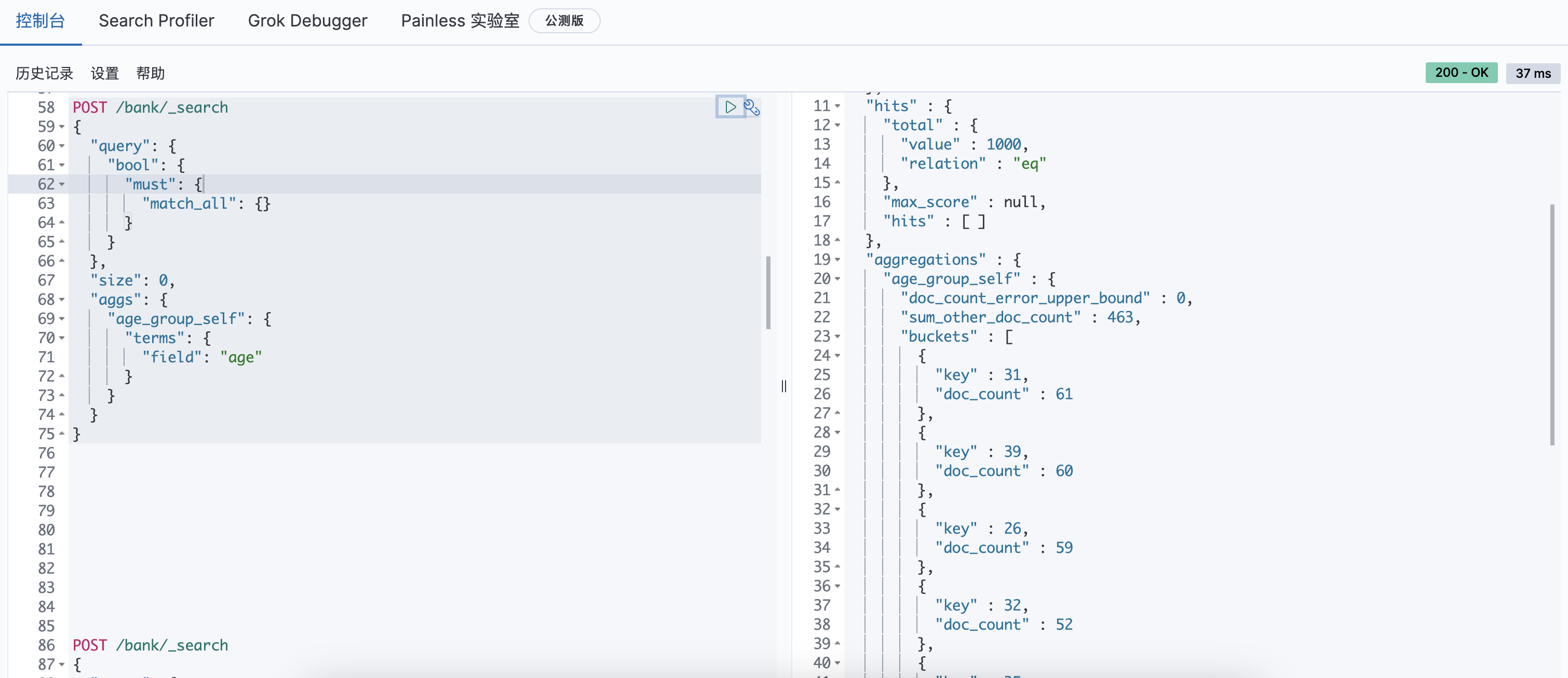
聚合统计查询(进阶)
在对年龄分组后,查询组的平均薪水。
等价于select avg(balance) from bank group by age;
POST /bank/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
},
"size": 0,
"aggs": {
// 第一次根据年龄聚合
"age_group_self": {
"terms": {
"field": "age"
},
// 在每个年龄聚合内容内,取平均数
"aggs": {
"avg_balance_group_self": {
"avg": {
"field": "balance"
}
}
}
}
}
}
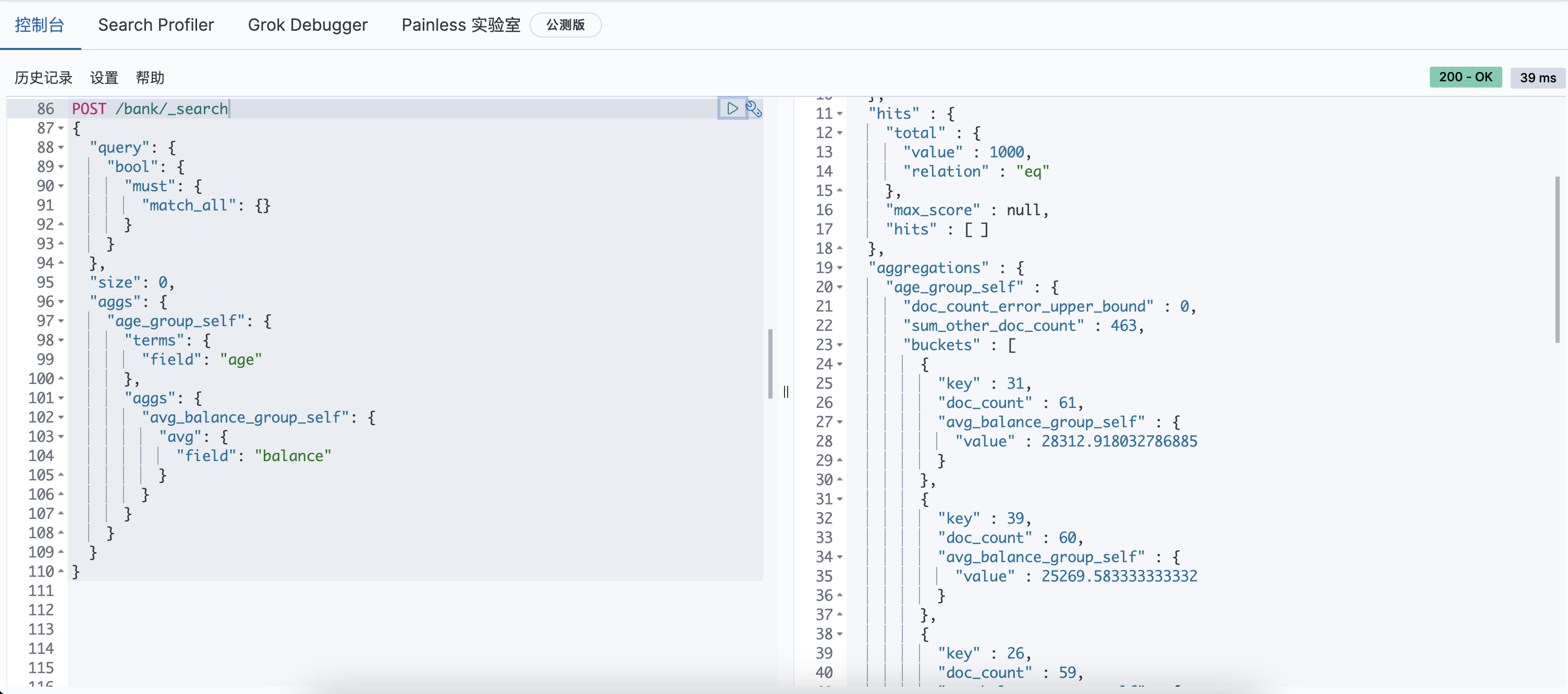
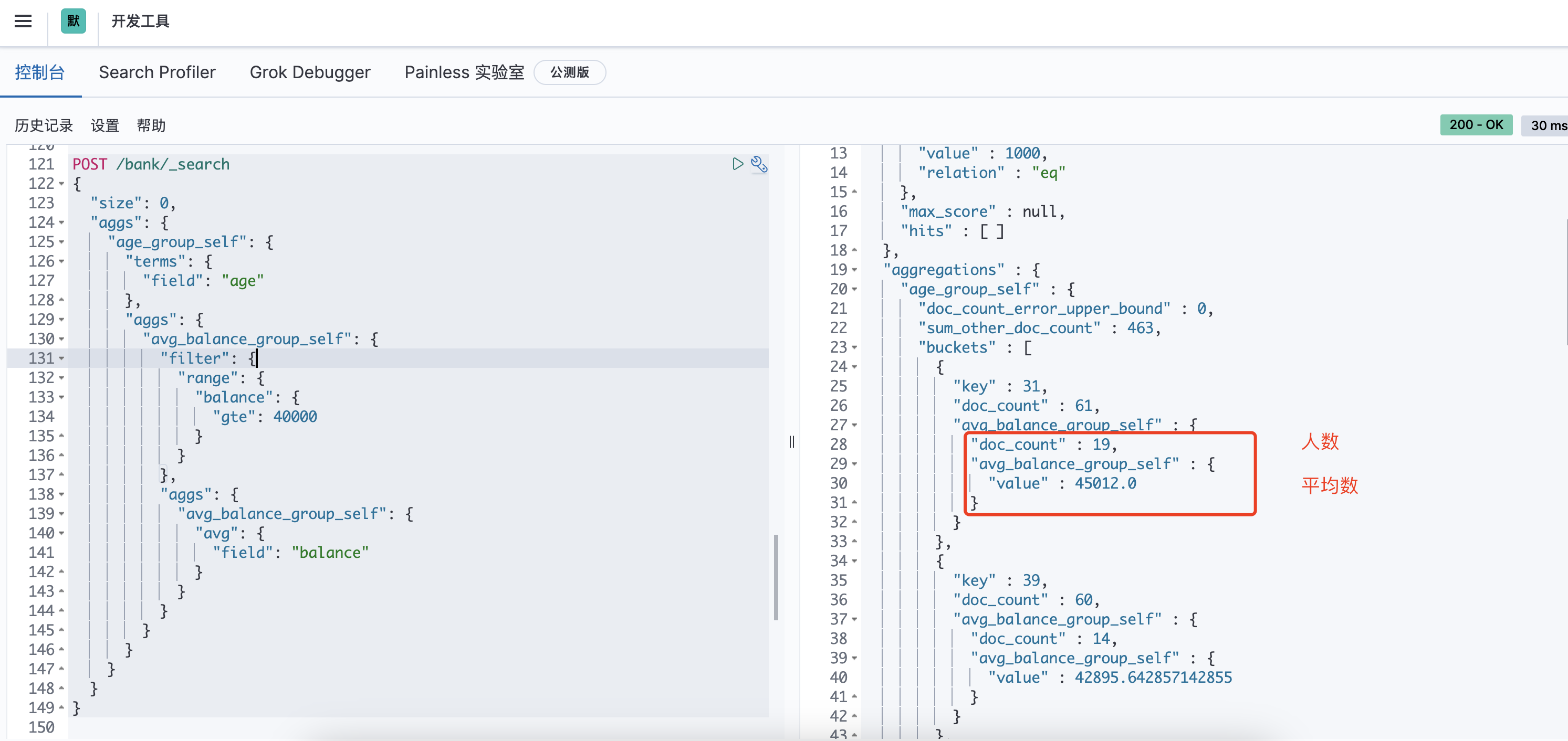
聚合过滤统计查询(再进阶)
更近一步,查询每个年龄段中,薪水大于40000的人员平均工资。
等价于select avg(balance) from bank group by age having balance >= 40000;
POST /bank/_search
{
"size": 0,
"aggs": {
"age_group_self": {
"terms": {
"field": "age"
},
"aggs": {
// 相比增加过滤条件
"avg_balance_group_self": {
"filter": {
"range": {
"balance": {
"gte": 40000
}
}
},
// 因为增加了过滤条件,然后把过滤后的结果进行聚合
"aggs": {
"avg_balance_group_self": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}
桶选择器
查询人数在55以上的年龄有哪些。
这里使用了bucket_selector 桶选择器,分别有多个参数,介绍如下。
{
"bucket_selector": {
"buckets_path": {
// my_var1 是这个桶的路径中使用脚本中的变量的名称
// the_sum 路径的度量所使用的变量。
"my_var1": "the_sum",
"my_var2": "the_value_count"
},
// 在这个聚合上运行的脚本。这个脚本可以是内置的,文件或索引。
"script": "params.my_var1 > params.my_var2"
}
}
查询示例
POST /bank/_search
{
"size": 0,
"aggs": {
"age_group_self": {
"terms": {
"field": "age"
},
"aggs": {
"age_count_self": {
"value_count": {
"field": "age"
}
},
"bucket_filter_self": {
"bucket_selector": {
"buckets_path": {
"count": "age_count_self"
},
"script": "params.count > 55"
}
}
}
}
}
}

四、总结
在聚合查询中,aggs 命令下首先是一个自定义命名的查询,在这之下可以继续做 aggs 操作,可以对数据进行过滤、排序等操作,再通过最外部的 query 命令进行检索。
在聚合中,是不会过滤桶的个数的,哪怕桶内已经没有符合要求的数据了,这个时候需要使用桶选择器对桶进行过滤。