单机模式的缺点
Redis虽然有持久化技术保证Redis奔溃后重启可以恢复数据,但是,单机模式下还是存在两方面问题。一方面Redis一旦宕机,数据恢复需要一定的时间,这段时间内,都不能接收和处理请求;另一方面,如果硬盘发生损坏,无论AOF文件还是RDB文件都会丢失,也就无法恢复了。
主从复制模式
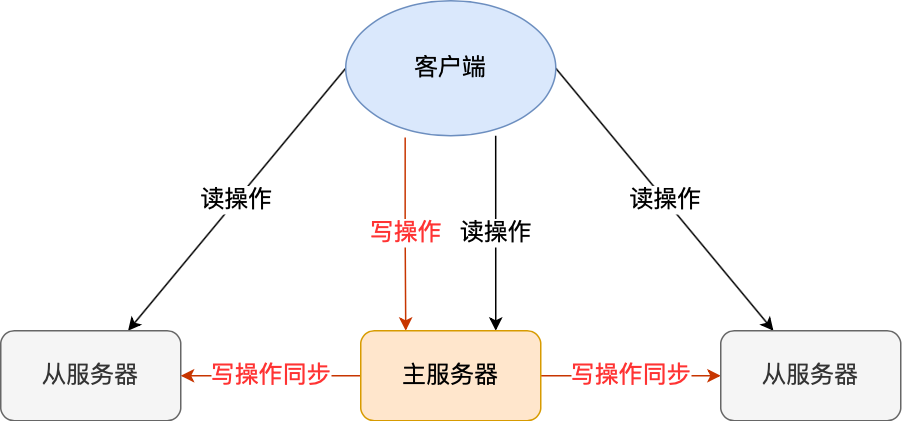
Redis提供了主从复制模式,将数据备份到多台服务器上,较好地保证数据的丢失,同时,一台服务器故障后,其它服务器还能够提供服务。
另外,Redis主从复制模式下,是读写分离的。主服务器负责读写操作并将写操作同步给从服务器,而从服务器只负责读操作。
第一次同步
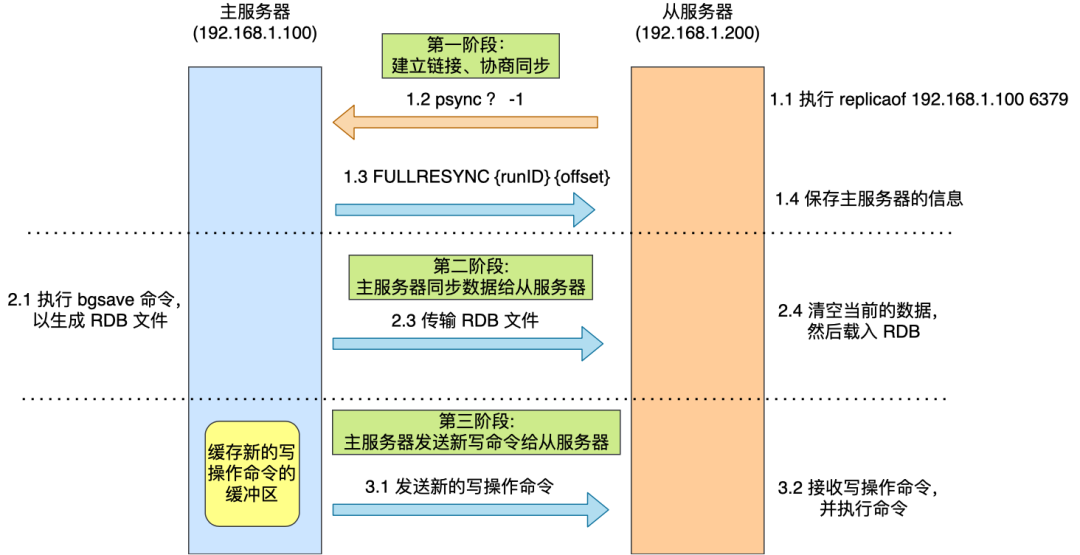
当我们发起slaveof或者replicaof命令时,从服务器就会向主服务器发送一条psync指令(包含主服务器id和复制进度,这里一开始时为随机id和-1),表明自己要与之进行数据同步,主服务器收到命令后,响应一个全量复制的命令(包含主服务器的id和复制进度),从服务器收到后报错主服务器信息。接着,主服务器执行bgsave命令,生成RDB文件,然后将生成的RDB文件传输给从服务器,从服务器收到后,清空自己的数据,然后载入这个RDB文件到内存。为了保证主从一致,在主服务器生成RDB文件、传输RDB文件和从服务器加载RDB文件的过程中,都会记录写操作命令到一个replication buffer的缓冲区。在从服务器载入RDB文件到内存后,会给主服务器发送一个确认消息。主服务器收到后,将replication buffer缓冲区中的写操作命令发送给从服务器,从服务执行这些写操作命令,这样,主从服务器达到一致。
命令传播
主从服务器在进行第一次同步后,为了避免频繁地建立和端口TCP连接,主服务器和从服务器之间会维持一个TCP长连接,用于后续主服务器将写操作指令传播给从服务器。
分摊主服务器的压力
主服务器要与许多的从服务器进行全量复制时,主服务器会不停的忙于fork子进程生成RDB文件,如果主服务器的内存很大,fork子进程时复制主进程的页表也会很大,这样就会导致阻塞主进程;
另外,传输RDB文件也会耗费主服务器的网络带宽,不利于响应命令请求。
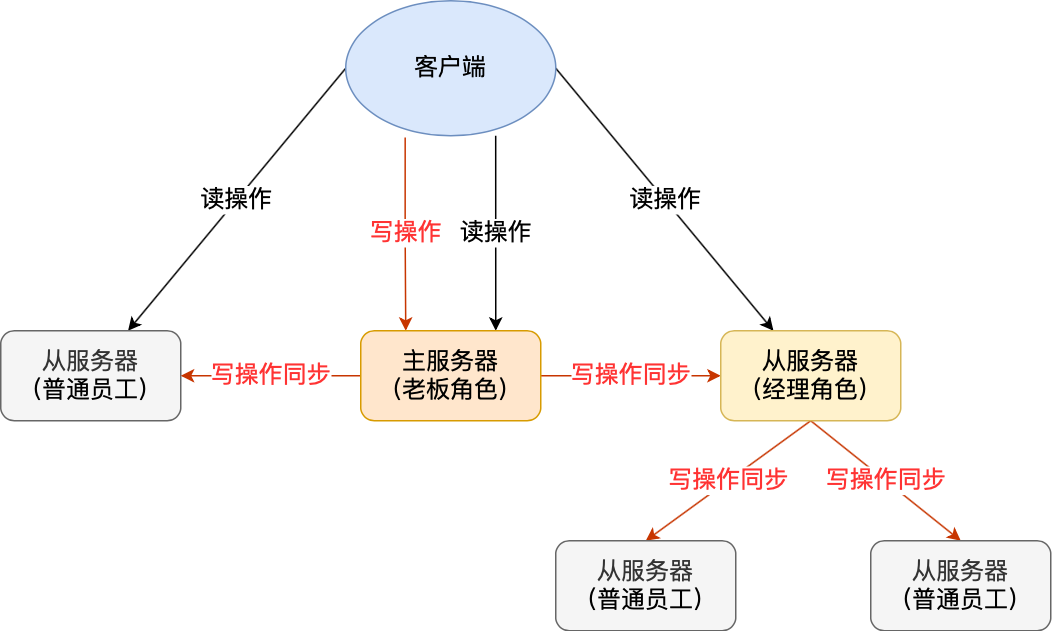
因此,我们需要对从服务器执行slaveof或者replicaof命令,使其也有自己的从服务器,这样,从服务器在同步主服务器(老板)的同时,也可以将数据同步给自己(经理)的从服务器(普通员工),便分摊了主服务器的压力
增量复制
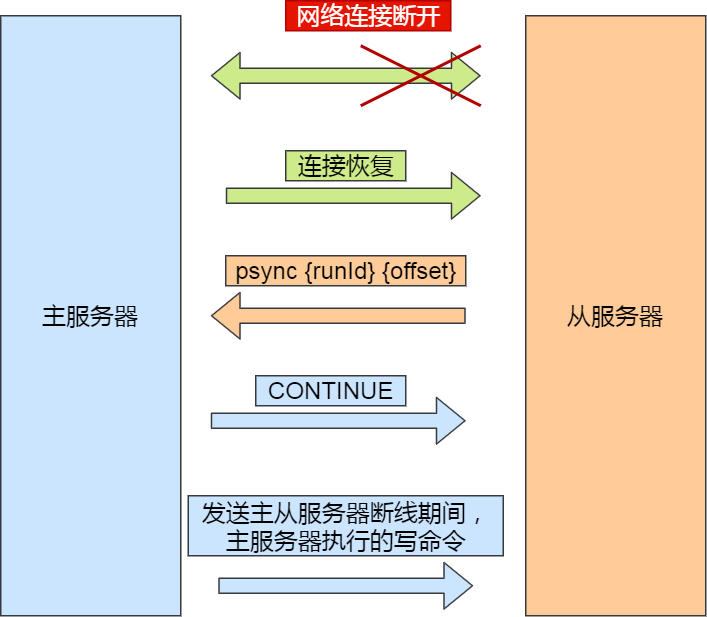
当从服务器与主服务器断开TCP连接时,主服务器就无法向从服务器继续进行写操作的命令传播,这时,为了保证主从数据的一致性,Redis2.8之前,采用的方法是,在从服务器与主服务器重连之后,直接进行全量复制,但是,由于从服务器其实本身之前可能已经同步了一部分数据,这时再清空进行全量复制,开销就太大了。
因此Redis2.8之后,主服务器在与从服务器命令传播或者断开期间,都会将写操作命令写入一个repl back buffer中,repl back buffer是一个环形的缓冲区(会覆盖之前的数据)。从服务器与主服务器重新连接上后,从服务器发送一个psync指令(包含了主服务器的id和从服务器自己的复制偏移量offset),主服务器收到之后,向从服务器发送一个continue响应命令,告知从服务器接下来将以增量复制的方式进行数据同步。
主服务器会根据自己写到的位置master_repl_offset和从服务器同步到的位置slave_repl_offset之间的差距,判断从服务器要读取的数据是否还包含在repl_backlog_buffer。
如果存在,则采用增量复制,将增量数据写入到replication buffer缓冲区中,replication buffer缓冲区中,就是在全量复制过程中,保存的即将要传播给从服务器的命令。
如果不存在,则采用全量复制。
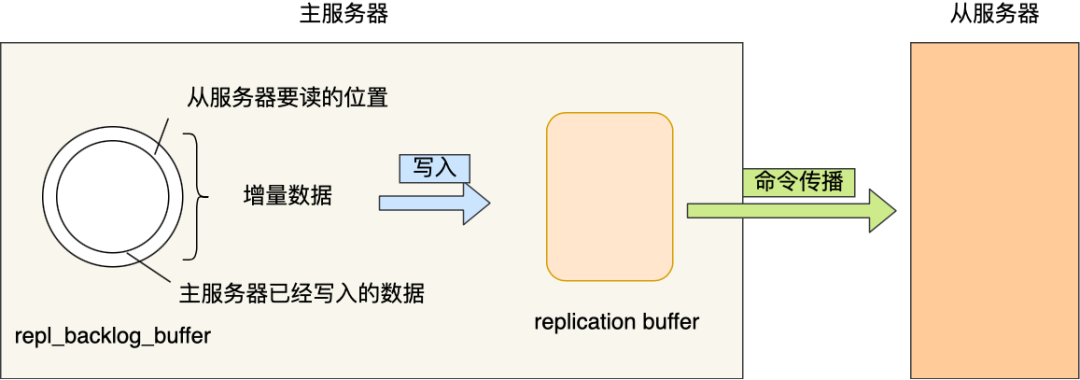
为了保证网络恢复后,尽量采用增量复制的方式进行数据恢复,我们会控制repl_backlog_buffer的
空间大小(默认1MB)大于second * write_size _per_second,second表示从服务器断线后重新连上主服务器平均耗时, write_size _per_second表示主服务器平均每秒钟产生的写操作的数量




![[架构之路-225]:计算机体系结构 - 分类方法大汇总](https://img-blog.csdnimg.cn/00bf032590184d90aa72c9abf47b592b.png)