TensorBoard常用函数和类![]() http://t.csdn.cn/Hqi9c
http://t.csdn.cn/Hqi9c
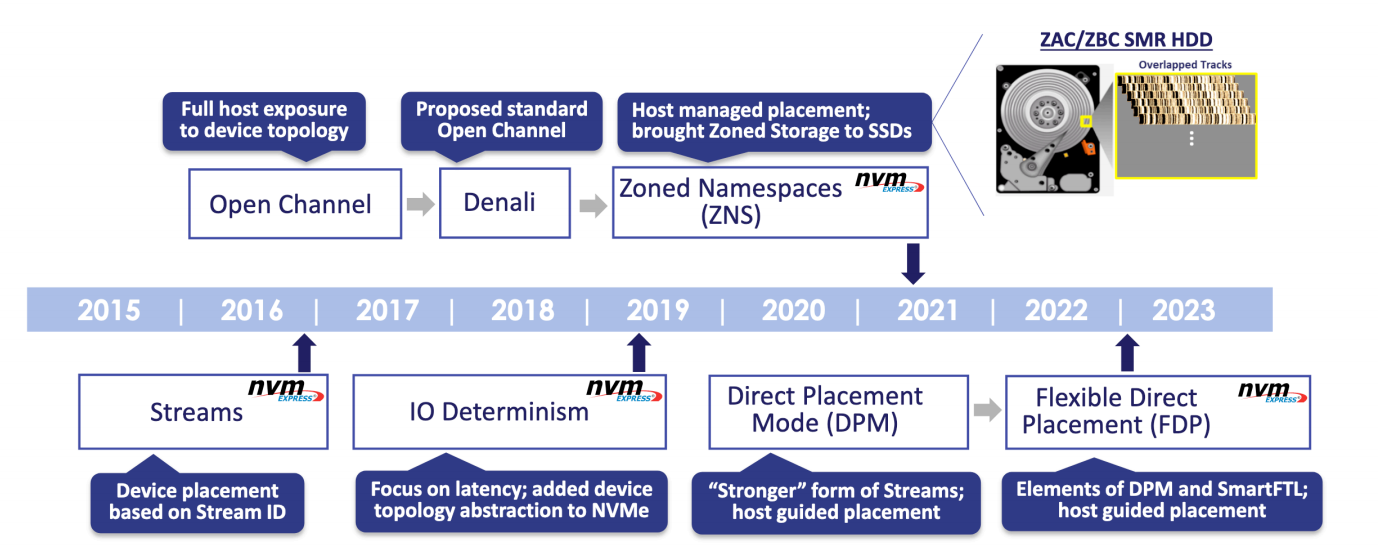
TensorBoard可视化的过程:
①确定一个整体的图表,明确从这个图表中获取哪些数据的信息
②确定在程序的哪些节点、以什么样的方式进行汇总数据的运算,以记录信息,比如在反向传播定义以后,使用tf.summary.scalar记录损失值的变换
③运行所有的summary节点。由于一个程序中经常会有多个summary节点,为了减少一个一个手动启动的繁琐,可以使用tf.summary.merge_all将所有summary节点合并成一个节点,在启动运行
④使用tf.summary.FileWriter将运行后输出的数据保存到本地磁盘中
⑤运行整个程序,完成执行后,win+R打开终端,输入tensorboard --logdir 文件上一级路径
以下是具体操作:
示例代码如下:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 25 20:07:18 2023
@author: ASUS
"""
import tensorflow.compat.v1 as tf
import numpy as np
import matplotlib.pyplot as plt
import os
tf.compat.v1.disable_eager_execution()#这个函数用于禁用 TensorFlow 2 中的即时执行模式,以便能够使用 TensorFlow 1.x 的计算图执行方式。
#1.准备数据
train_X = np.linspace(-1, 1,100)#train_X 是一个从 -1 到 1 的等间距数组,用作输入特征。
train_Y = 5 * train_X + np.random.randn(*train_X.shape) * 0.7#train_Y 是根据 train_X 生成的目标值,在真实值的基础上加上了一些噪声。
#2.搭建模型
#通过占位符定义
X = tf.placeholder("float")#X 和 Y 是 TensorFlow 的占位符(Placeholder),用于在执行时提供输入和标签数据。
Y = tf.placeholder("float")
#定义学习参数的变量
W = tf.Variable(tf.compat.v1.random_normal([1]),name="weight")#W 和 b 是学习参数的变量,可以被模型训练调整。
b = tf.Variable(tf.zeros([1]),name="bias")
#定义运算
z = tf.multiply(X,W) + b#z 是通过将输入特征 X 与权重 W 相乘并加上偏差 b 得到的预测值。
#定义损失函数
cost = tf.reduce_mean(tf.square(Y - z))#cost 是损失函数,计算预测值与真实值之间的平方差的平均值。
#定义学习率
learning_rate = 0.01#learning_rate 是学习率,用来控制优化算法在每次迭代中更新参数的步长。
#设置优化函数
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)#optimizer 是梯度下降优化器,用于最小化损失函数。
#3.迭代训练
#初始化所有变量
init = tf.global_variables_initializer()
#定义迭代参数
training_epochs = 20#training_epochs 是迭代训练的轮数。
display_step = 2#display_step 是控制训练过程中打印输出的步长。
#定义保存路径
savedir = "log4/"
#启动Session
with tf.Session() as sess:#with tf.Session() as sess: 创建一个会话,在该会话中执行计算图操作。
sess.run(init)#sess.run(init) 运行初始化操作,初始化所有变量。
tf.summary.scalar("loss", cost)
#合并所有的summary
merged_summary_op = tf.summary.merge_all()
#创建summary_write用于写文件
summary_writer = tf.summary.FileWriter(os.path.join(savedir,'summary_log'),sess.graph)
for epoch in range(training_epochs):
for(x,y) in zip(train_X,train_Y):
sess.run(optimizer,feed_dict={X:x,Y:y})#sess.run(optimizer,feed_dict={X:x,Y:y}) 执行一次优化器操作,将当前的输入特征 x 和标签值 y 传入模型。
summary_str = sess.run(merged_summary_op,feed_dict = {X:x,Y:y})
summary_writer.add_summary(summary_str,epoch)
if epoch % display_step == 0:#每隔 display_step 轮迭代打印一次损失值和当前的参数值。
loss=sess.run(cost,feed_dict={X:train_X,Y:train_Y})
#测试模型
print("Epoch:",epoch+1,"cost=",loss,"W=",sess.run(W),"b=",sess.run(b))
print("Finished!")
#使用 matplotlib 库绘制训练数据点和拟合直线。
plt.plot(train_X,train_Y,'ro',label='Original data')#绘制原始数据点。
plt.plot(train_X,sess.run(W)*train_X+sess.run(b),'--',label='Fittedline')#绘制拟合的直线。
plt.legend()#添加图例。
plt.show()#显示图形。
#4.利用模型
print("x=0.2,z=",sess.run(z,feed_dict={X:0.2}))#使用训练好的模型,传入输入特征 0.2 来计算预测值 z。
运行后会生成文件如下

win+R打开终端,输入tensorboard --logdir C:\Users\ASUS\.spyder-py3\log4\summary_log
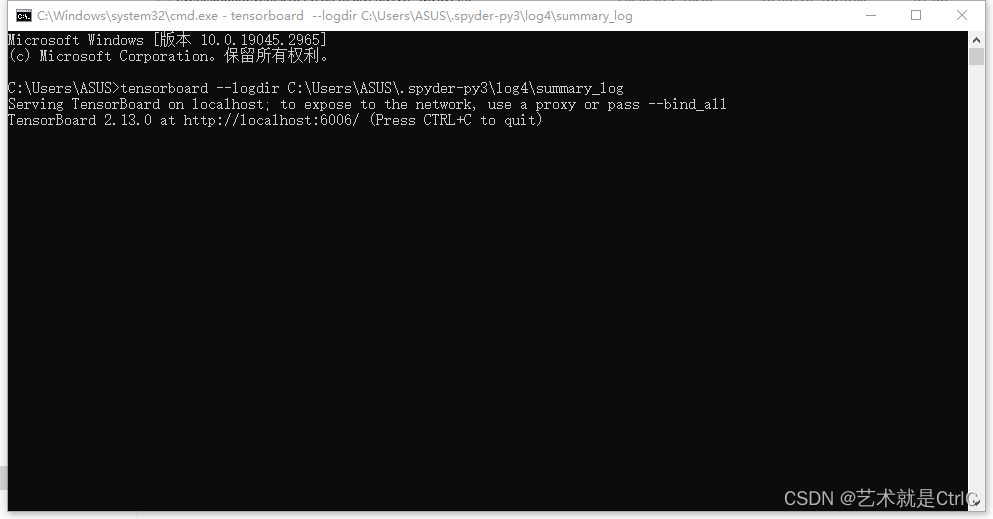
复制其中的http://localhost:6006/,打开浏览器跳转来到tensorboard可视化界面,如下:
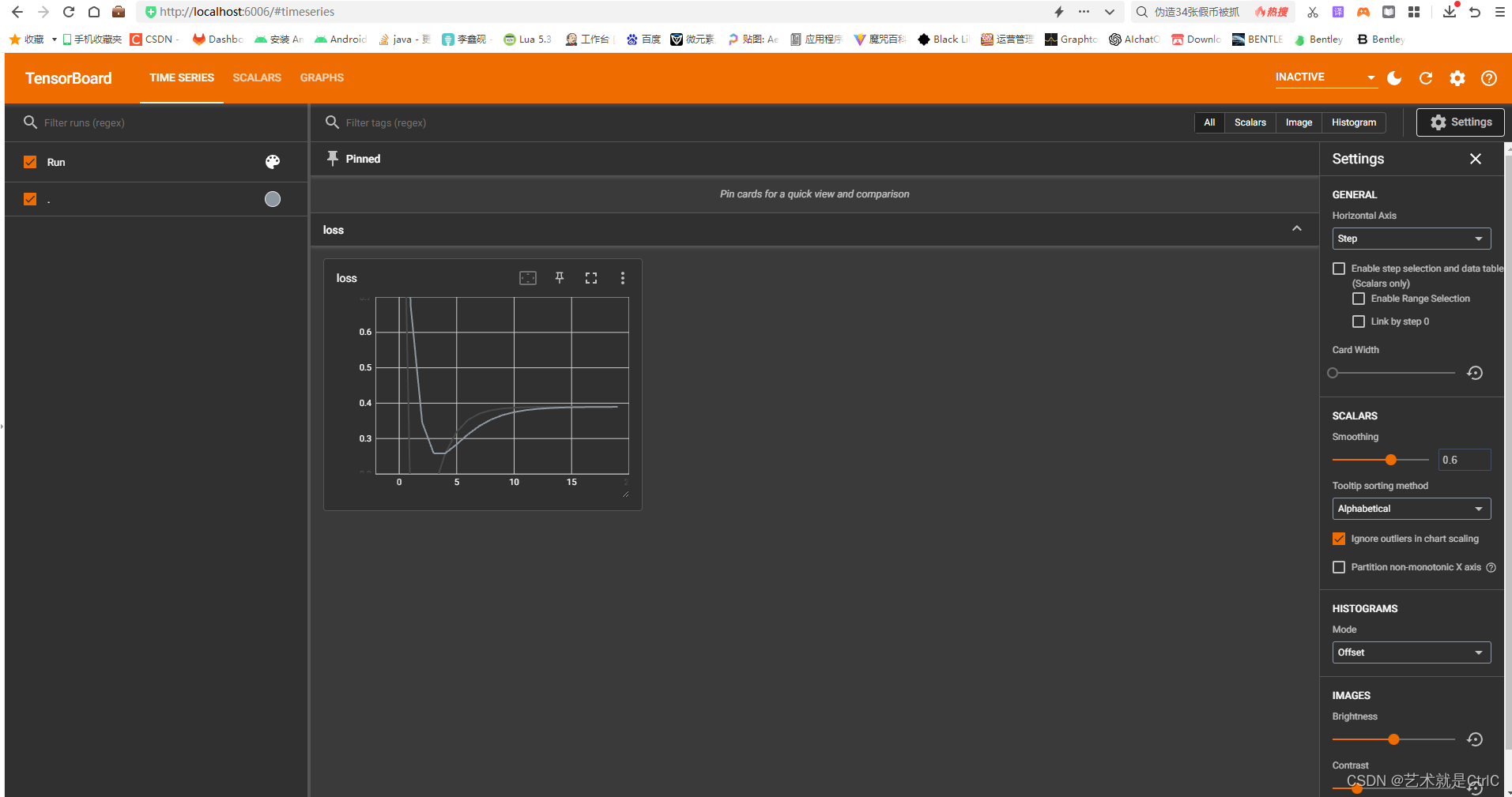
Tensorboard显示图片示例![]() http://t.csdn.cn/Ok1w5
http://t.csdn.cn/Ok1w5