与编码器结构(encoder-only) 的语言模型结构相反, 解码器结构(decoder-only) 的语言模型结构只包含trans- former 结构里的 decoder 部分。在 BERT 发布之前的 GPT- 1 就是 decoder-only 的语言模型, 但在 GPT-3 发布并展 示其惊人表现后, decoder-only 的语言模型数量呈现井喷式地增长, 直到现在依旧是占比最大的模型类型。这类 模型更适合被用来执行生成词汇类任务, 前面介绍过 GPT- 1,GPT-2 和 GPT-3,这里主要介绍的是模型参数量大 于 100 亿的生成式大语言模型。
PaLM
PaLM,全名为 Pathways Language Model,是一款使用了 Pathways,一种能在数千或数万个加速器芯 片上高效训练神经网络的机器学习系统, 并在 7800 亿 token 的高质量文本上训练一个 5400 亿参数稠密激活的自 回归 Transformer 。PaLM 的模型结构是在标准的 transformer 模型的 decoder 部分上进行了几处调整:
-
SwiGLU 激活函数使用 SwiGLU 激活函数作为 MLP 的中间激活函数, 因为与其他激活函数相比能显著提 高质量。
-
并行层 在 Transformer 块中使用并行表述而非序列表述,具体来说,标准的表述为:
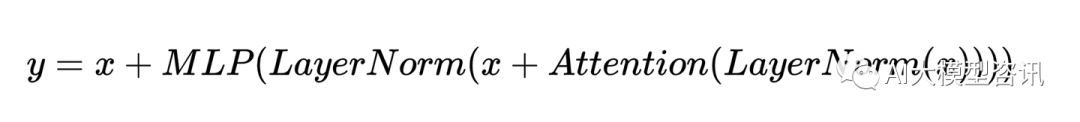
并行表述为:

-
由于 MLP 和 Attention 输入矩阵的乘法可以被融合, 平行表述的方式提高了 15%大规模的训练速度。在 8B 规模模型下效果略有下降, 但在 62B 规模模型下没有。由此推断并行表述对 540B 规模模型的表现没有影响。
-
多 Query 注意力 标准的 Transformer 使用 k 个注意力头, 每个时间步的输入向量被线性投影为形状为 [k, h] 的“query”,“key”,和“value”向量, 其中h 是注意力头的尺寸。在这里, 每个头的 key/value 投影是共享的, 即 key 和 value 被投影为 [1, h],但 query 仍被投影为 [k, h]。这对模型的质量和训练速度没有影响, 但 明显降低了自回归解码的时间成本。这是因为在自回归解码时 key/value 张量在实例之间不共享, 而且一次 只解码一个 token ,导致标准的多头注意力在加速器硬件上的效率很低。
-
RoPE 嵌入层使用RoPE 嵌入而非绝对或相对位置嵌入,因为 RoPE 嵌入向量在长序列的表现更好。
-
共享输入-输出嵌入层 共享输入和输出嵌入矩阵。
-
无 biases 所有 dense kernels 和 layer norms 都没有使用biases ,这可以增加大模型的训练稳定性。
-
单词表 使用带有 256k tokens 的 SentencePiece[26] 单词表, 原因是为了能够支持训练语料库中的大量语言, 而不需要过度 tokenization。单词表是完全无损且可逆的, 说明单词表中留有空白处(对代码来说尤其重 要),且未登录的 Unicode 字符被分为 UTF-8 字节, 每个字节都是一个单词表的 token。数字总会被分为单独的数值 token ( 123.4 -> 1 2 3 . 4 )。
在数据集方面, PaLM 收集了 7800 亿 token 的代表了广泛的自然语言使用样例的高质量语料。该数据集混 合了过滤过的网页、书籍、维基百科、新闻文章、源代码和社交媒体对话, 且该数据集是基于用于训练 LaMDA 和 GLaM 的数据集。所有的模型只训练一个 epoch,并选择混合比例避免重复数据。除了自然语言之外, 该数据 集中还包含代码数据。预训练数据集中的源代码是从 Github 上的开源仓库中获取的, 并通过仓库中的 license 过 滤文件,总共限制了 24 种编程语言且到得到了196GB 的源代码。最后基于 Levenshtein 距离移除重复的文件。
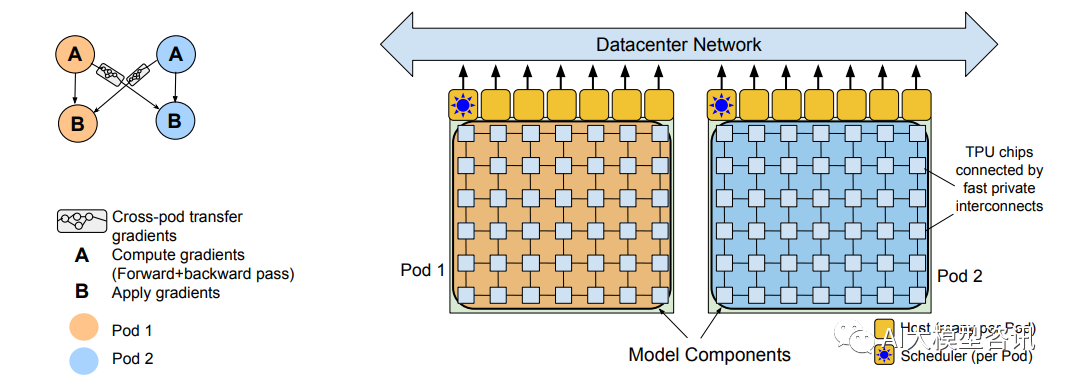
Pathways 系统跨两个 TPU v4 pods 执行两路 pod 级别的数据并行
从结果上来看, PaLM 的表现有:
-
该模型在 6144 个 TPU v4 芯片上高效的训练了一个 540B 参数的语言模型, 这是以前的模型未曾达到过的 规模。
-
语言模型的表现还没有随着规模的改善达到饱和点。
-
在许多困难的语言理解和生成任务上有突破性的能力。
-
在三种不同规模, 8B ,62B ,540B,的模型中, 从 62B 到 540B 规模的表现变化比从 8B 到 62B 规模的表 现提升的极其迅速,说明当模型达到足够大的规模时能够展现出新的能力。
-
优秀的多语言理解能力。
-
比起 8B 模型, 62B 和 540B 模型会产生更高的毒性。比起人类生成文本,模型受到提示的影响更严重。
BLOOM
BLOOM 是在 2021 年 5 月至 2022 年 5 月的一年时间里完成训练并发布的。初始版本发布于 2022 年 5 月 19 日。BLOOM 是 BigScience Large Open-science Open-access Mul-tilingual Language Model 首字母的缩写。BigScience 不是财团, 也不是正式成立的实体。这是一个由 HuggingFace 、GENCI 和 IDRIS 发起的开放式协作组织, 以及 一个同名的研究研讨会(workshop) ,BLOOM 由 BigScience 社区开发和发布, 共 60 个国家和 250 多个机构 的 1000 多名研究人员参与 BLOOM 的项目, 。BLOOM 是在 46 种自然语言和 13 种编程语言上训练的 1760 亿 参数语言模型, 该模型是在 Jean Zay 上训练的, Jean Zay 是由 GENCI 管理的法国政府资助的超级计算机, 安装在法国国家科学研究中心 (CNRS) 的国家计算中心 IDRIS。所需硬件为 384 张 80GB A100 GPU,训练框架为Megatron-DeepSpeed,训练时长为 3.5 个月,训练 BLOOM 的算力成本超过 300 万欧元。
训练数据
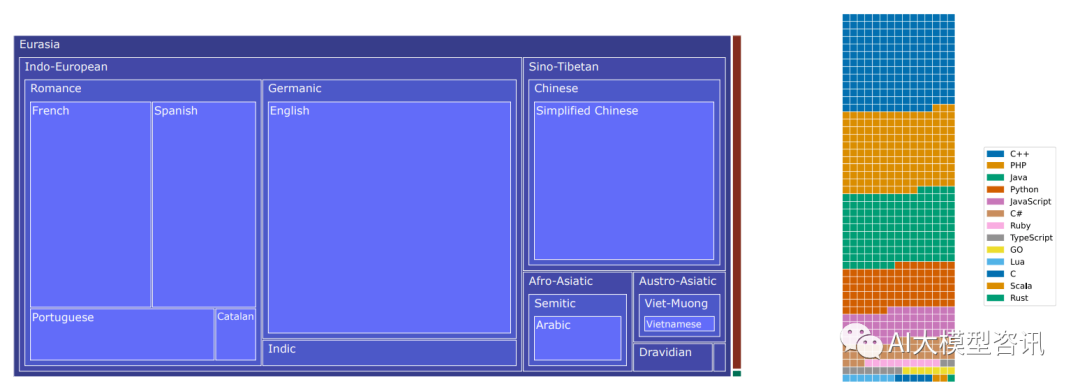
BLOOM ROOTS 数据中的语言分布
BLOOM 是在一个称为 ROOTS 的语料上训练的, 其是一个由 498 个 Hugging Face 数据集组成的语料。共计 1.61TB 的文本, 包含 46 种自然语言和 13 种编程语言, 共 3500 亿词元。上图中展示了该数据集的高层概览, 展示了每种语言及其语属、语系和宏观区域。训练数据的处理包含以下几个步骤,如下图所示:
-
获得源数据: 第一步涉及到从确定的数据源中获得文本数据, 这包含从各种格式的 NLP 数据集中下载和提 取文本字段、从档案中抓取和处理大量的 PDF 文件、从目录中的 192 个网站条目和数据工作组成员选择的 另一些地理上不同的 456 个网站中提取和预处理文本。后者需要开发新工具来从 Common Crawl WARC 文 件中的 HTML 中抽取文本。我们能够从 539 个网络的所有 URL 中找到并提取可用的数据。
-
质量过滤: 在获得文本后, 我们发现大多数源中包含了大量的非自然语言, 例如预处理错误、 SEO 页面或 者垃圾。为了过滤非自然语言, 我们定义了一组质量指标, 其中高质量文本被定义为“由人类为人类编写 的”,不区分内容或者语法的先验判断。重要的是, 这些指标以两种主要的方法来适应每个源的需求。首 先, 它们的参数, 例如阈值和支持项列表是由每个语言的流利使用者单独选择的。第二、我们首先检测每 个独立的源来确定哪些指标最有可能确定出非自然语言。这两个过程都是由工具进行支持来可视化影响。
-
去重和隐私编辑: 使用两种重复步骤来移除几乎重复的文档, 并编辑了从 OSCAR 语料中确定出的个人身 份信息。因为其被认为是最高隐私风险的来源, 这促使我们使用基于正则表达式的编辑, 即使表达式有一 些假阳性的问题。
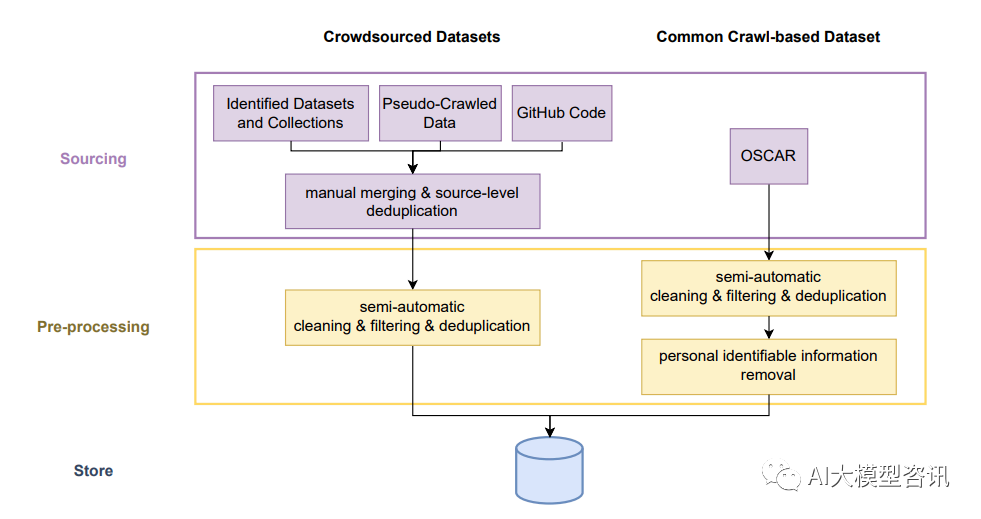
BLOOM 的数据处理步骤示意图
模型架构
虽然大多数现代语言模型都是基于 Transformer 架构, 但是架构实现之间存在着显著的不同。显然, 原始 的 Transformer 是基于 encoder-decoder 架构的, 许多流行的模型仅选择 encoder-only 或者 decoder-only 方法。当 前, 所有超过 100B 参数的 state-of-the-art 模型都是 decoder-only 模型。在选择架构为 Decoder 方法之后, 对原始 Transformer 架构提出了许多的更改。在 BLOOM 中采用了两种变化:
-
ALiBi 位置嵌入: 相比于在 embedding 层添加位置信息, ALiBi 直接基于 keys 和queries 的距离来衰减注意 力分数。虽然 ALiBi 的最初动机是它能够外推至更长的序列, 我们发现其在原始序列长度上也能够带来更 平衡的训练以及更好的下游表现,超越了可学习 embeddings 和旋转embeddings。
-
Embedding LayerNorm: 在训练 104B 参数模型的初步试验中, 我们尝试在嵌入层后立即进行 layer nor- malization,正如 bitsandbytes 库及其 StableEmbedding 层所推荐的那样。我们发现这可以显著的改善训练 稳定性。尽管我们在 Le Scao et al. 工作中发现其对 zero-shot 泛化有惩罚, 但我们还是在 BLOOM 的第一个 embedding 层后添加了额外的 layer normalization 层来避免训练不稳定性。注意初步的 104B 实验中使用 float16,而最终的训练上使用 bfloat16。因为 float16 一直被认为是训练 LLM 时观察的许多不稳定的原因。bfloat16 有可能缓解对 embedding LayerNorm 的需要。

BLOOM 的架构图
InstructGPT
InstructGPT在 GPT-3 的基础上提出了“Alignment”的概念, 即让模型的输出与人类的意图对齐, 避免 产生虚假的事实以及有害的内容。预训练模型自诞生之始, 一个备受诟病的问题就是预训练模型的偏见性。因 为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的, 对比完全由人工规则控制的专家系统来 说, 预训练模型就像一个黑盒子。没有人能够保证预训练模型不会生成一些包含种族歧视, 性别歧视等危险内 容, 因为它的几十 GB 甚至几十 TB 的训练数据里几乎肯定包含类似的训练样本。因此 InstructGPT 的目标理念 是有用的(helpful),可信的(honest)和无害的(harmless)。InstructGPT 采用了 GPT-3 的结构,通过指示学习 构建训练样本来训练一个奖励模型,并通过这个奖励模型的分数来指导强化模型的训练。
训练方式
InstructGPT 的训练方式分为三步, 如下图所示, 其中第二步和第三步的奖励模型和强化学习的 SFT 模型 可以反复迭代优化:
-
监督微调:根据采集的 SFT 数据集对 GPT-3 进行有监督的微调(Supervised FineTune ,SFT );
-
奖励模型训练:从移除了最后的 unembedding layer 的监督微调模型开始, 训练了一个接收提示和回答并输 出一个标化奖励的模型。这次选择了 60 亿参数的奖励模型, 不仅因为这能节省成本, 而且经实验, 1750 亿参数的奖励模型并不稳定。该奖励模型是在在同一输入的两个模型输出之间进行比较的数据集上进行训 练。使用 cross-entropy loss,并比较标签, 奖励之间的差异表示标注人员更喜欢一种回答的对数概率。为了加快对比收集, 标注人员要在 K = 4 和 K = 9 的回答之间进行排名, 这会为每名标注人员每个提示产生 (2(K)) 个比较。因为每个标记任务中的比较都有关联, 将它们放入一个数据集中会使奖励模型过于拟合, 因 此要将每个提示的 (2(K)) 个对比作为单独的 batch 元素训练。这使得计算过程更加高效, 因为每次完成只需 要奖励模型一次的向前传递,且不会出现过于拟合,并提高了准确率。该奖励模型的损失函数为:
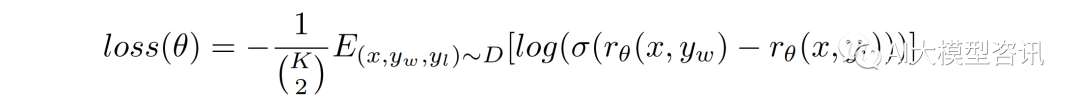
其中 rθ (x, y) 是提示 x,补全 y,参数为 θ 的奖励模型的标量输出, yw 是 yw 和 yl 中更好的补全, D 是人 类比较的数据集。
-
强化学习:InstructGPT 使用 PPO[56] 作为强化学习的baseline。InstructGPT 在一个 bandit 环境中用 PPO 微 调了监督微调模型。该环境展示一个随机的客户提示并期望该提示的回答。给予一个提示和回答, 它产生 了又奖励模型决定的奖励并结束该 episode。另外,每个 token 上被添加了监督微调模型的 KL 惩罚以轻奖 励模型的过度优化。该 value function 从奖励模型初始化。这些模型叫做 PPO。为了修复公共 NLP 数据集 的性能回归,预训练梯度被加入到 PPO 的梯度中,并称为“PPO-ptx”。其目标函数为:
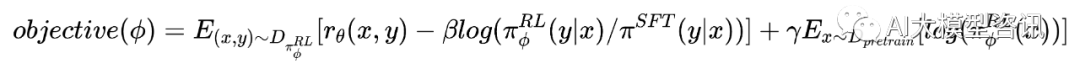
其中 πϕ(RL) 是学习到的强化学习策略, π SFT 是监督训练模型, Dpretrain 是预训练分布。KL 奖励系数 β 和 预训练损失系数 γ 分别控制 KL 惩罚和预训练梯度的强度。对于 PPO 模型, γ = 0。除非特殊说明, 这里 的 InstructGPT 指的都是 PPO-ptx 模型。
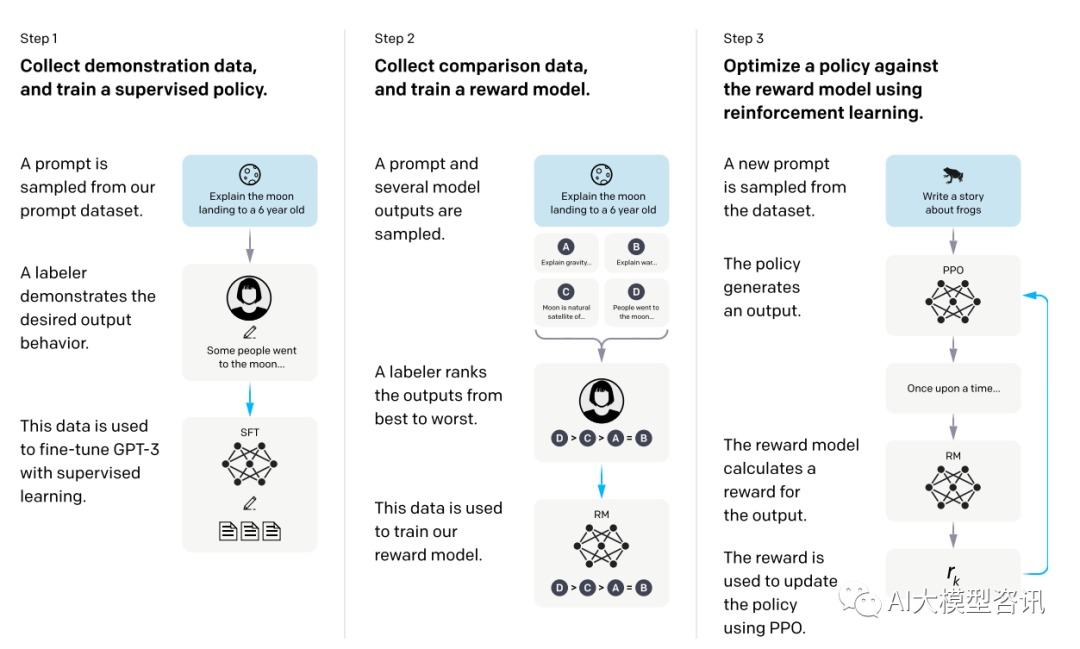
步骤一:监督微调。步骤二:奖励模型训练。步骤三:通过 PPO 在奖励模型上强化学习
训练数据
为了构建 InstructGPT 模型, 让该模型在 OpenAI 的 PlayGround 收集指示数据, 从而收集创建三个数据集, 这些数据的分布情况如下图1.16所示:1. 监督微调的数据:让标注人员加上指示的答案;2. 奖励模型训练的数 据:让标注人员给模型输出排序;3. 根据奖励模型标注来生成训练强化学习模型的数据。根据 InstructGPT 的训 练步骤, 其需要的这些数据也有些许差异:这三个数据总共加起来, 有 77K 条, 而其中涉及人工的, 只有 46K。也就是 GPT-3 继续在 77K 的数据上进行了进一步微调,就得到了 InstructGPT。
SFT 数据集
SFT 数据集是用来训练第 1 步有监督的模型, 即使用采集的新数据, 按照 GPT-3 的训练方式对 GPT-3 进行 微调。因为 GPT-3 是一个基于提示学习的生成模型, 因此 SFT 数据集也是由提示-答复对组成的样本。SFT 数据 一部分来自使用 OpenAI 的 PlayGround 的用户, 另一部分来自OpenAI 雇佣的 40 名标注工(labeler)。并且他们对 labeler 进行了培训。在这个数据集中, 标注工的工作是根据内容自己编写指示, 并且要求编写的指示满足下 面三点:
-
简单任务(Plain):标注人员被要求给出一个任意的任务,并保证任务的多样性。
-
Few-shot 任务:标注人员想出一个指示,并提供一些问答的例子。
-
用户相关(User-based):标注人员根据 OpenAI API 上用户提出的案例来构建任务,编写指示。
RM 数据集
RM 数据集用来训练第二步的奖励模型, 需要为 InstructGPT 的训练设置一个奖励目标, 要尽可能全面且真 实的对齐我们需要模型生成的内容。可以通过人工标注的方式来提供这个奖励, 通过人工对可以给那些涉及偏 见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT 的做法是先让模型生成一批 候选文本,让后通过标注人员根据生成数据的质量对这些生成内容进行排序。
PPO 数据集
InstructGPT 的 PPO 数据没有进行标注, 它均来自 GPT-3 的 API 的用户。既又不同用户提供的不同种类的生 成任务,其中占比最高的包括生成任务(45.6% ), QA ( 12.4%),头脑风暴(11.2%),对话(8.4%)等。
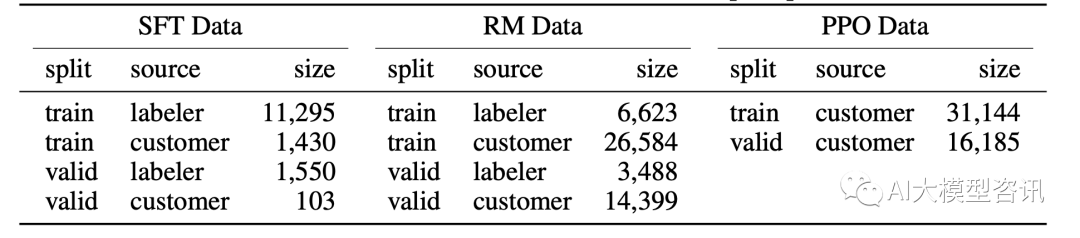
SFT 、RM 和 PPO 数据集的分布和大小
从结果上来看,相比于 GPT-3 ,InstructGPT 有以下特点:
-
标注者更倾向于 InstructGPT 的输出,在真实性上比 GPT-3 有明显进步。
-
InstructGPT 模型在无害性上有些进步,但在偏见方面没有明显改善。
-
InstructGPT 在 RLHF 微调分布之外的指令的任务也有良好表现。
-
RLHF 微调程序会降低模型在通用NLP 任务上的效果。
-
对有害的指示可能会输出有害的答复。
-
InstructGPT 依旧会犯简单的错误,模型会对简单概念的过分解读。
ChatGPT 是 InstructGPT 的姐妹模型, 两者都使用了指示学习和人类反馈的强化学习(RLHF) 方法。但 Chat- GPT 使用了不同且规模更大的数据收集设置,以及 ChatGPT 是根据 GPT-3.5 系列中的一个模型微调获得的。
GPT-4则是 OpenAI 最新的语言模型, 但至今没有公布其技术细节和代码, 只给出了技术报告。比起之 前的 GPT 系列, GPT-4 展现了更优秀的逻辑推理,理解图表,生成安全文本,编程,理解其他语言等能力。
ps:欢迎扫码关注公众号^_^.