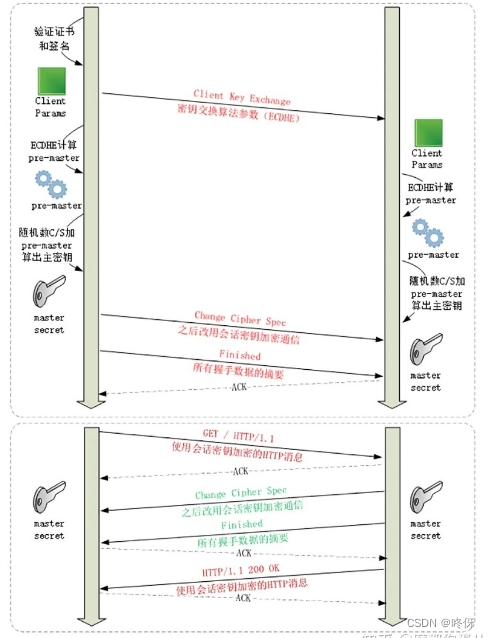
目标识别项目:基于Yolov7-LPRNet的动态车牌目标识别算法模型(一)
前言
目标识别如今以及迭代了这么多年,普遍受大家认可和欢迎的目标识别框架就是YOLO了。按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。从基本的YOLOv1版本到如今v8版本,完成了多次蜕变,现在已经相当成熟并且十分的亲民。我见过很多初学目标识别的同学基本上只花一周时间就可以参照案例实现一个目标检测的项目,这全靠YOLO强大的解耦性和部署简易性。初学者甚至只需要修改部分超参数接口,调整数据集就可以实现目标检测了。但是我想表达的并不是YOLO的原理有多么难理解,原理有多难推理。一般工作中要求我们能够运行并且能够完成目标检测出来就可以了,更重要的是数据集的标注。我们不需要完成几乎难以单人完成的造目标检测算法轮子的过程,我们需要理解YOLO算法中每个超参数的作用以及影响。就算我们能够训练出一定准确度的目标检测模型,我们还需要根据实际情况对生成结果进行一定的改写:例如对于图片来说一共出现了几种目标;对于一个视频来说,定位到具体时间出现了识别的目标。这都是需要我们反复学习再练习的本领。
完成目标检测后,我们应该输出定位出来的信息,YOLO是提供输出设定的超参数的,我们需要根据输出的信息对目标进行裁剪得到我们想要的目标之后再做上层处理。如果是车牌目标识别的项目,我们裁剪出来的车牌就可以进行OCR技术识别出车牌字符了,如果是安全帽识别项目,那么我们可以统计一张图片或者一帧中出现检测目标的个数做出判断,一切都需要根据实际业务需求为主。本篇文章主要是OCR模型对车牌进行字符识别,结合YOLO算法直接定位目标进行裁剪,裁剪后生成OCR训练数据集即可。
其中数据集的质量是尤为重要的,决定了模型的上限,因此想要搭建一个效果较好的目标识别算法模型,就需要处理流程较为完善的开源数据集。本篇文章采用的是CCPD数据集,那么不再过多描述,让我们直接开始项目搭建。
数据集收集
CCPD:https://github.com/Fanstuck/CCPD
一般来说目前常用来训练车牌目标识别项目的数据集都采用了CCPD数据集,CCPD是一个大型的、多样化的、经过仔细标注的中国城市车牌开源数据集。CCPD数据集主要分为CCPD2019数据集和CCPD2020(CCPD-Green)数据集。CCPD2019数据集车牌类型仅有普通车牌(蓝色车牌),CCPD2020数据集车牌类型仅有新能源车牌(绿色车牌)。
CCPD2019数据集
CCPD2019数据集主要采集于合肥市停车场,采集时间为上午7:30到晚上10:00,停车场采集人员手持Android POS机对停车场的车辆拍照进行数据采集。所拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、雨天、雪天等。CCPD2019数据集包含了25万多幅中国城市车牌图像和车牌检测与识别信息的标注。主要介绍如下:
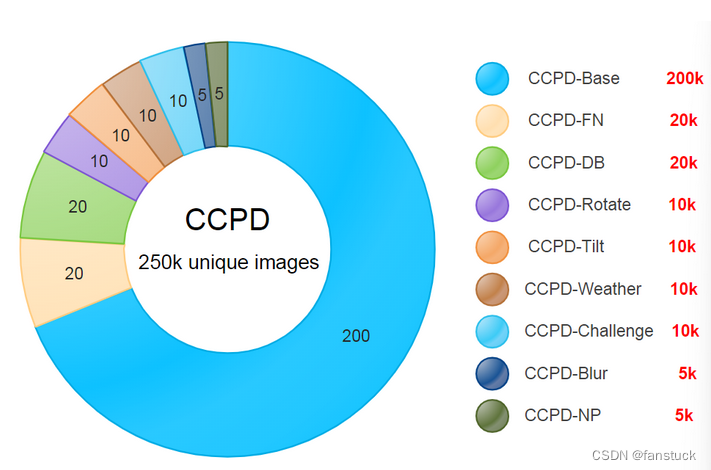
| 类别 | 描述 | 图片数 |
|---|---|---|
| CCPD-Base | 通用车牌图片 | 200k |
| CCPD-FN | 车牌离摄像头拍摄位置相对较近或较远 | 20k |
| CCPD-DB | 车牌区域亮度较亮、较暗或者不均匀 | 20k |
| CCPD-Rotate | 车牌水平倾斜20到50度,竖直倾斜-10到10度 | 10k |
| CCPD-Tilt | 车牌水平倾斜15到45度,竖直倾斜15到45度 | 10k |
| CCPD-Weather | 车牌在雨雪雾天气拍摄得到 | 10k |
| CCPD-Challenge | 在车牌检测识别任务中较有挑战性的图片 | 10k |
| CCPD-Blur | 由于摄像机镜头抖动导致的模糊车牌图片 | 5k |
| CCPD-NP | 没有安装车牌的新车图片 | 5k |
CCPD2019/CCPD-Base中的图像被拆分为train/val数据集。使用CCPD2019中的子数据集(CCPD-DB、CCPD-Blur、CCPD-FN、CCPD-Rotate、CCPD-Tilt、CCPD-Challenge)进行测试。

CCPD2020数据集
CCPD2020数据集采集方法应该和CCPD2019数据集类似。CCPD2020仅仅有新能源车牌图片,包含不同亮度,不同倾斜角度,不同天气环境下的车牌。CCPD2020中的图像被拆分为train/val/test数据集,train/val/test数据集中图片数分别为5769/1001/5006。

=
车牌号码说明
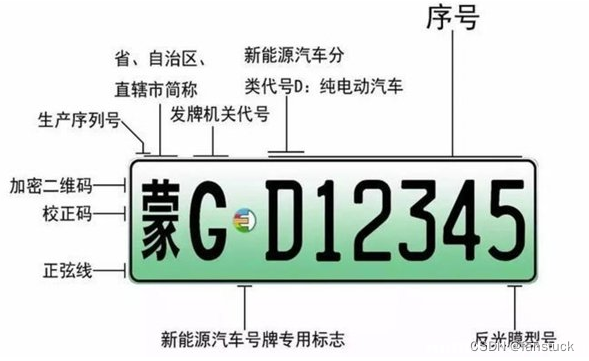
车牌第一位是汉字:代表该车户口所在的省级行政区,为各(省、直辖市、自治区)的简称,比如:北京是京,上海是沪,湖南就是湘…
车牌第二位是英文字母:代表该车户口所在的地级行政区,一般为各地级市、地区、自治州字母代码,一般按省级车管所以各地级行政区状况分划排名:(字母“A”为省会、首府或直辖市中心城区的代码,其字母排名不分先后)
另在编排地级行政区英文字母代码时,跳过I和O,O往往被用作警车或者机关单位。
- 省份:[“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”, “浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”, “川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”]
- 地市:[‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’,‘X’, ‘Y’, ‘Z’]
- 车牌字典:[‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’,‘Y’, ‘Z’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
绿牌和蓝牌区别如下:
-
颜色区别:小型新能源车牌采用“渐变绿”的配色,大型新能源车牌采用“黄绿双拼色”,绿牌的字体颜色为黑色;而传统燃油车蓝牌则采用“纯蓝色”设计,字体颜色为白色;
-
号码编排:普通蓝牌共有7位字符;新能源车牌有8位字符;新能源绿牌的号码共有6位数,其中小型新能源汽车牌照的字母设计在第一位,大型新能源汽车牌照的字母设计在最后一位。其中车牌首字母为“D/A/B/C/E”的,代表“纯电动车”;首字母为“F/G/H/J/K”的,代表“非纯电动汽车”。而普通燃油车蓝牌的号码只有5位数,首字母或数字一般不代表任何含义,只有部分地区会给营运类车型划分特定字母。
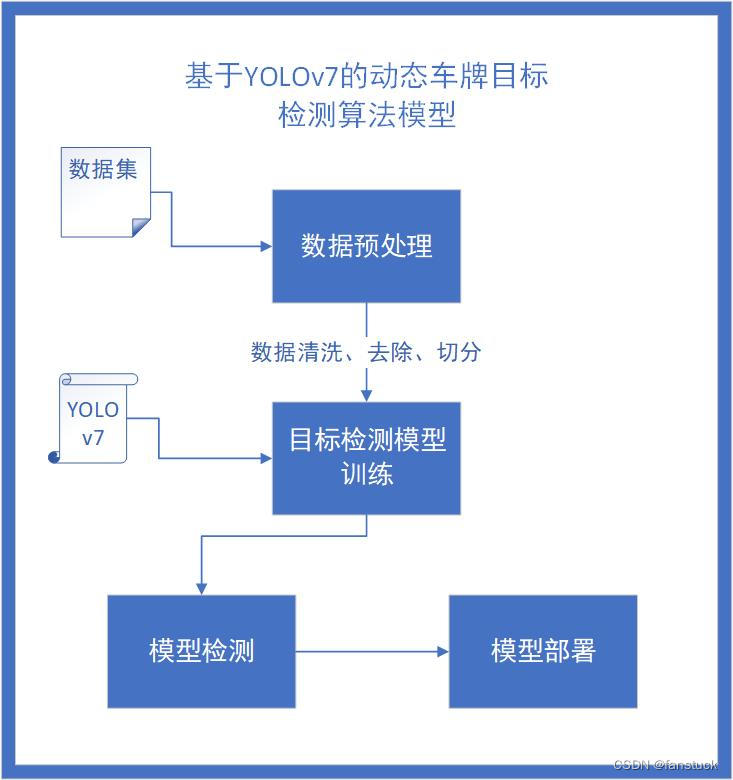
目标识别模型具体搭建框架
数据预处理
CCPD数据集没有专门的标注文件,每张图像的文件名就是该图像对应的数据标注。【025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg】,其文件名的含义如下:
- 025:车牌区域占整个画面的比例;
- 95_113: 车牌水平和垂直角度, 水平95°, 竖直113°
- 154&383_386&473:标注框左上、右下坐标,左上(154, 383), 右下(386, 473)
- 386&473_177&454_154&383_363&402:标注框四个角点坐标,顺序为右下、左下、左上、右上
- 0_0_22_27_27_33_16:车牌号码映射关系如下: 第一个0为省份 对应省份字典provinces中的’皖’,;第二个0是该车所在地的地市一级代码,对应地市一级代码字典alphabets的’A’;后5位为字母和文字, 查看车牌号ads字典,如22为Y,27为3,33为9,16为S,最终车牌号码为皖AY339S
因此我们需要根据图片文件的目录名称来拆分信息:
def getinfo_annotations(image_file):
'''
细节看文档
:param image_file:
:return:
'''
try:
annotations = image_file.split('-')
rate = annotations[0]# 车牌区域占整个画面的比例;
angles = annotations[1].split('-')# 车牌水平和垂直角度, 水平95°, 竖直113°
box = annotations[2].split('_')# 标注框左上、右下坐标,左上(154, 383), 右下(386, 473)
boxes = [list(map(int, i.split('&'))) for i in box]
point = annotations[3].split('_') # 标注框四个角点坐标,顺序为右下、左下、左上、右上
points = [list(map(int, i.split('&'))) for i in point]
plate = annotations[4].split("_") # licenses 标注框四个角点坐标,顺序为右下、左下、左上、右上
plates = plate_analysis_licenses(plate)
except Exception as e:
boxes = []
points = []
plates = []
angles = []
info = {"filename": image_file, "boxes": boxes, "points": points,
"plates": plates, "angles": angles}
return info
此外我们还需要编写出解析代表识别车牌字符的数字编码:
def plate_analysis_licenses(plate):
'''
细节看文档
:param plate:
:return:车牌info
'''
provinces = ["皖", "沪", "津", "渝",
"冀", "晋", "蒙", "辽",
"吉", "黑", "苏", "浙",
"京", "闽", "赣", "鲁",
"豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵",
"云", "藏", "陕", "甘",
"青", "宁", "新", "警", "学", "O"]
alphabets=['A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q',
'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q',
'R', 'S', 'T', 'U', 'V',
'W', 'X','Y', 'Z', '0',
'1', '2', '3', '4', '5',
'6', '7', '8', '9', 'O']
result = [provinces[int(plate[0])], alphabets[int(plate[1])]]
result += [ads[int(p)] for p in plate[2:]]
result = "".join(result)
#print(plate,result)
return result
这样以来我们可以获取所有文件名称解析出的内容,包括检测框的坐标以及车牌的信息,具体解析情况可以绘制展示代码:
def draw_box(image, box):
"""
:param image:
:param box:
:return: 边界框
"""
draw = ImageDraw.Draw(image)
draw.rectangle([tuple(box[0]), tuple(box[1])], outline="#00FF00", width=3)
def draw_point(image,point):
'''
绘制四个关键点
:param image:
:param point:
:return:
'''
draw = ImageDraw.Draw(image)
for p in point:
center = (p[0],p[1])
radius = 5
right = (center[0]+radius,center[1]+radius)
left = (center[0] - radius, center[1] - radius)
draw.ellipse((left, right), fill="#FF0000")
def draw_label(image,label):
'''
绘制车牌
:param image:
:param label:
:return:
'''
draw = ImageDraw.Draw(image)
font = ImageFont.truetype('simsun.ttc',64)
draw.text((30,30),label,font=font,fill="#FF0000")
def image_show(imagepath,box,points,label):
'''
图片展示
:param imagepath:
:param box:
:param points:
:param label:
:return:
'''
image=Image.open(imagepath)
draw_label(image,label)
draw_point(image,points)
draw_box(image,box)
image.show()
效果如下:

那么能够获取图片的关键信息之后,我们就可以开始建立我们模型的训练数据集和测试数据集了。首先我们需要明确,该项目我们需要完成对车牌的检测,也就是能够在图片或者视频帧中定位到车牌的坐标。定位之后还要能够识别出车牌上面的字符信息。拆解这两部分我们需要建立两种模型,一种是目标检测的算法模型,例如YOLO、R-CNN、SSD等,另一种是OCR文字识别模型,例如CRNN、PlateNet、LPRNet等。那么第一步我们需要搭建能够定位车牌信息的目标检测模型。
数据集准备
我们现在需要将CCPD数据集转换YOLO格式标注数据集,YOLO文本标注数据集样例如:

txt每个数值分别代表:检测框中心点坐标x,检查框中心点坐标y,检查框宽w,检测框高h。
通过解析每个图片得到的信息很容易完成:
def create_txt_file(file_path,image_name,image_width, image_height, bbox_coords_list, class_index):
yolo_lines = []
bbox_coords_lists=[]
bbox_coords_lists.append(bbox_coords_list)
for bbox_coords in bbox_coords_lists:
print(bbox_coords)
x_center = (bbox_coords[0][0] + bbox_coords[1][0]) / (2 * image_width)
y_center = (bbox_coords[0][1] + bbox_coords[1][1]) / (2 * image_height)
width = (bbox_coords[1][0] - bbox_coords[0][0]) / image_width
height = (bbox_coords[1][1] - bbox_coords[0][1]) / image_height
yolo_lines.append(f"{class_index} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
save_path = os.path.join(file_path, "label", f"{image_name}.txt")
for i, line in enumerate(yolo_lines):
txt_filename = f"{image_name}.txt"
txt_path = save_path
with open(txt_path, "w") as txt_file:
txt_file.write(line)
上述代码将生成对应的YOLO目标标注文本文件,一些具体功能参数不清楚的可以去看本人github开源代码,有详细说明。
随后就是划分训练和测试数据集了,CCPD有9类性质不同的车牌图片,这里统一使用CCPD-Base数据集,主要是方便处理和展示,如果大家想要追求更好的效果可以依次提取其他数据集的图片,我们的目的是构建轻量级数据不用那么多数据量增加本地计算机负担,故从原本数据集抽取3W张图片进行训练,仅抽取CCPD-base数据集的图片。
# -*- coding:utf-8 -*-
# @Author: fanstuck
# @Time: 2023/8/24 17:02
# @File: Sampling_of_CCPD_files.py
import os
import random
import shutil
def Random_sampling_of_documents(source_directory,target_directory,num):
'''
目录文件下随机抽样
:param :source_directory
:param :target_directory
:return:
'''
# 选择抽取的图片数量
num_images_to_extract = num
# 获取目录中所有图片文件
all_image_files = [file for file in os.listdir(source_directory) if file.lower().endswith(('.png', '.jpg', '.jpeg'))]
# 随机抽取指定数量的图片文件
selected_image_files = random.sample(all_image_files, num_images_to_extract)
# 将选中的图片文件复制到目标目录
for image_file in selected_image_files:
source_path = os.path.join(source_directory, image_file)
target_path = os.path.join(target_directory, image_file)
shutil.copy(source_path, target_path)
准备工作还差一步,我们需要切割数据集分为训练数据集,测试数据集和真值数据集。这里划分已经随机抽样的3W车牌数据进,进行训练:测试:真值=7:2:1的划分:
def split_dataset(source_dir,train_dir,test_dir,val_dir,train_ratio,test_ratio,val_ratio):
# 获取目录中的所有图片文件名
image_files = [f for f in os.listdir(source_dir) if f.endswith(".jpg") or f.endswith(".txt")]
# 计算划分数量
total_count = len(image_files)
train_count = int(total_count * train_ratio)
test_count = int(total_count * test_ratio)
val_count = total_count - train_count - test_count
# 划分图片并移动到对应目录
for i, image_file in enumerate(image_files):
if i < train_count:
dest_dir = train_dir
elif i < train_count + test_count:
dest_dir = test_dir
else:
dest_dir = val_dir
source_path = os.path.join(source_dir, image_file)
dest_path = os.path.join(dest_dir, image_file)
shutil.copy(source_path, dest_path)
这样以来我们就处理好了整个YOLO模型目标检测数据集,可以开始进行模型训练了。本项目文章量和代码量偏多,文章将分好几部分依次记录完,有想要入门目标检测技术的朋友十分推荐关注博主和我一起完成整个项目的搭建,整个项目将在Github上面开源且完全可部署。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。