目录
1.介绍
2. YOLOv5修改backbone为ConvNeXt
2.1修改common.py
2.2 修改yolo.py
2.3修改yolov5.yaml配置
1.介绍
- 论文地址:https://arxiv.org/abs/2201.03545
- 官方源代码地址:https://github.com/facebookresearch/ConvNeXt.git
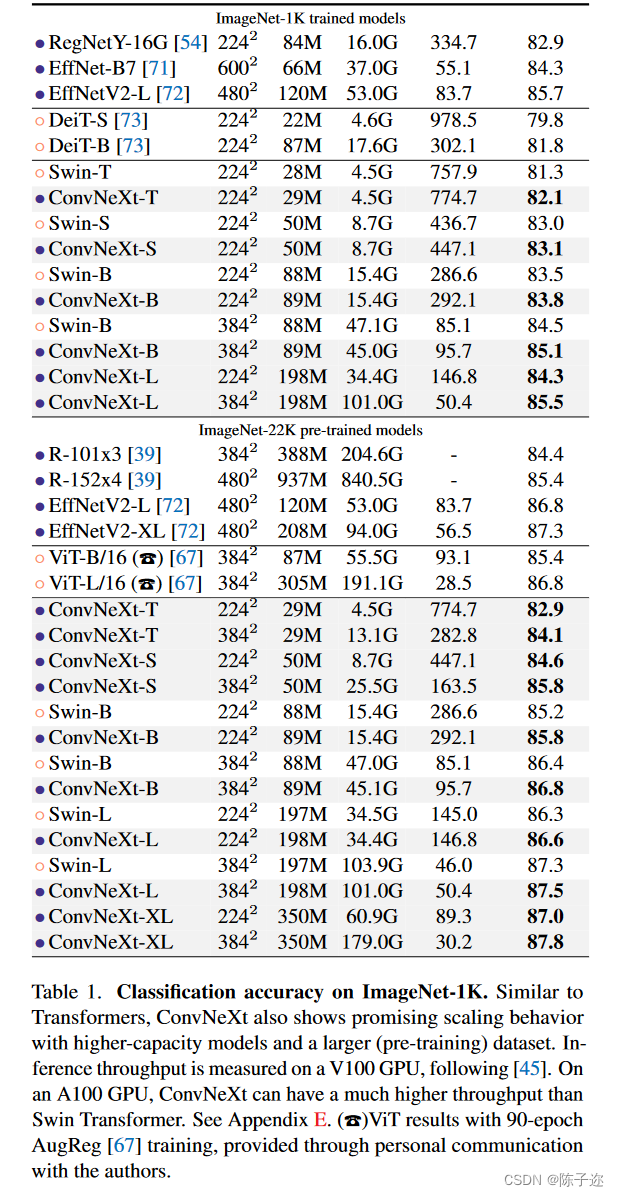
自从ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。回顾近一年,在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央。卷积神经网络要被Transformer取代了吗?也许会在不久的将来。今年(2022)一月份,Facebook AI Research和UC Berkeley一起发表了一篇文章A ConvNet for the 2020s,在文章中提出了ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率,参看下图(原文表12)。看来ConvNeXt的提出强行给卷积神经网络续了口命。
ConvNeXt是一种由Facebook AI Research和UC Berkeley共同提出的卷积神经网络模型。它是一种纯卷积神经网络,由标准卷积神经网络模块构成,具有精度高、效率高、可扩展性强和设计非常简单的特点。ConvNeXt在2022年的CVPR上发表了一篇论文,题为“面向2020年代的卷积神经网络”。ConvNeXt已在ImageNet-1K和ImageNet-22K数据集上进行了训练,并在多个任务上取得了优异的表现。ConvNeXt的训练代码和预训练模型均已在GitHub上公开。
ConvNeXt是基于ResNet50进行改进的,其与Swin Transformer一样,具有4个Stage;不同的是ConvNeXt将各Stage中Block的数量比例从3:4:6:3改为了与Swin Transformer一样的1:1:3:1。 此外,在进行特征图降采样方面,ConvNeXt采用了与Swin Transformer一致的步长为4,尺寸为4×4的卷积核。
ConvNeXt的优点包括:
ConvNeXt是一种纯卷积神经网络,由标准卷积神经网络模块构成,具有精度高、效率高、可扩展性强和设计非常简单的特点。
ConvNeXt在ImageNet-1K和ImageNet-22K数据集上进行了训练,并在多个任务上取得了优异的表现。
ConvNeXt采用了Transformer网络的一些先进思想对现有的经典ResNet50/200网络做一些调整改进,将Transformer网络的最新的部分思想和技术引入到CNN网络现有的模块中从而结合这两种网络的优势,提高CNN网络的性能表现.
ConvNeXt的缺点包括:
ConvNeXt并没有在整体的网络框架和搭建思路上做重大的创新,它仅仅是依照Transformer网络的一些先进思想对现有的经典ResNet50/200网络做一些调整改进.
ConvNeXt相对于其他CNN模型而言,在某些情况下需要更多计算资源.
2. YOLOv5修改backbone为ConvNeXt
2.1修改common.py
将以下代码,添加进common.py。
############## ConvNext ##############
import torch.nn.functional as F
class LayerNorm_s(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class ConvNextBlock(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm_s(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class CNeB(nn.Module):
# CSP ConvNextBlock with 3 convolutions by iscyy/yoloair
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(ConvNextBlock(c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
############## ConvNext ##############
2.2 修改yolo.py
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB]:

2.3修改yolov5.yaml配置
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, CNeB, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, CNeB, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, CNeB, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, CNeB, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, CNeB, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, CNeB, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, CNeB, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
后续会更新v7、v8版本