距离矢量路由协议RIP(含Cisco模拟器实验命令配置)
简介
距离矢量路由协议(Routing Information Protocol, RIP)是一种内部网关协议,它位于应用层,使用520 UDP端口。RIP基于距离矢量算法(Bellham-Ford)根据metric来衡量目的地址的距离。
原理
基本原理
对于RIP协议,路由器只会和相邻的路由器交换路由表,通常包含:
- 目的网络
- 距离
- 下一跳路由
RIP规定每经过一个路由器跳数加1,最多15跳,当一个路由条目对应的跳数为16跳的时候会被认为距离是无限大,即不可达。
RIP工作流程如下:
- 路由器激活RIP,立刻发送一个Request报文和一个Response报文,并开始监听链路上的RIP协议报文。
- 对应的接口会周期性发送Response报文。一个Response报文最多携带25个路由条目,当超过这个数字时使用多个报文。
- 当另一启用了RIP的路由器接收Request报文后,会使用相应的Response报文回应,并在该报文中携带对应的路由信息。
- 当另一启用了RIP的路由器接收Response报文后,会解析该报文中的路由信息,如果报文中的路由条目是自己未发现的,并且路由的度量值有效,则路由器将学习该路由并加载到路由表。(同时设置度量值、出接口、下一跳)
计时器
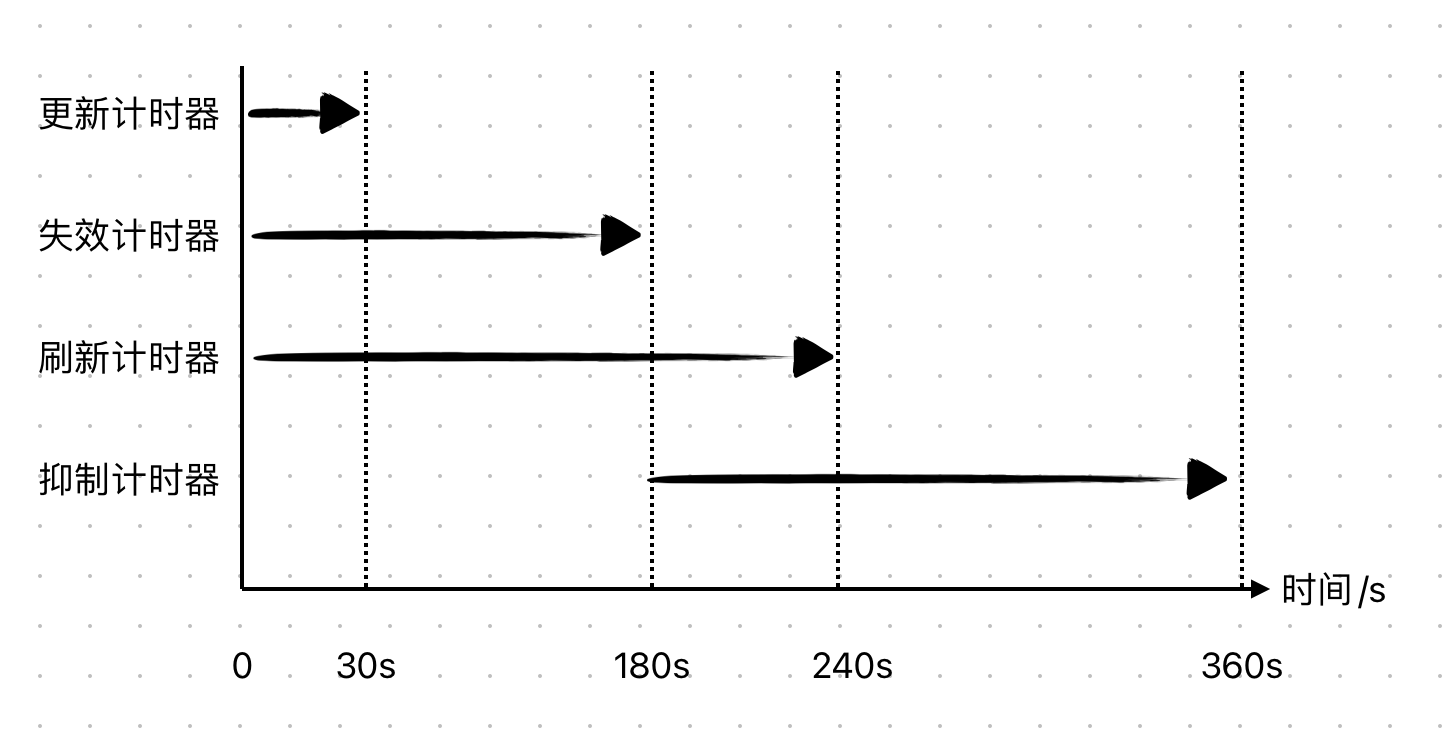
RIP主要有四个计时器:
- 更新计时器(Update timer):每次更新 30 seconds RIP,都是完整路由表,不过要排除被 split-horizon 抑制的路由条目。 为了防止路由表全局同步,update timer 值被设计成一个小范围内的随机值 (25-35s),思科路由器上一般为 25.5-30s。随机值的意义在于防止同时更新洪泛Response报文导致不必要的冲突。
- 失效计时器(Invalid timer):路由器在 180s 内没有收到特定路由条目的更新,则视此路由条 目为非法或不可达,将它的 hop count 设置为 16。启动失效计时器,标志这条路由条目失效,并且这个路由器会给所有相邻的路由器发送更新消息通告这条路由条目失效。标记为 16 跳。
- 刷新计时器(Flush Timer或garbage collection timer flush): 计时器满时,该路由条目将会从路由表中被移除,默认为 240s。
- 抑制计时器(Holddown Timer): 只有当失效计时器周期结束时,抑制计时器才会被激活。一旦路由器收到了关于某条路由条目的更新,并发现其 metric 值比本路由表中记录的 metric值大时,将会对这条路由设置 holddown timer,直至计时器周期结束才会接受这条次优路径,默认为 180s。
缺点
RIP协议有如下缺点:
- 过于简单,以跳数为依据计算度量值,经常得出非最优路由。例如:2 跳 64K 专线,和 3 跳 1000M 光纤,显然多跳一下没什么不好。
- 度量值以 16 为限,不适合大的网络。解决路由环路问题,16 跳在 rip 中被认为是无穷大,RIP是一种域内路由算法自治路由算法,多用于园区网和企业网。
- 收敛性差,时间经常大于 5 分钟。
- 消耗带宽很大。完整的复制路由表,把自己的路由表复制给所有邻居,尤其在低速广域网链路上更以显式的全量更新。
- 容易产生环路(先天缺陷,有后天的防环机制)
- 缺少主动发现网络变化机制(无拓扑信息,不知道全网链路,只知道自己直连)
防环机制
在刚在我们就说到过,RIP协议发送路由表,如果路由表相互包含则容易产生环路。协议本身就容易导致环路,故需要一系列防环机制:
- 跳数上限:上限16跳,设定包的生命周期,这在一定程度上减少了环路产生带来的问题,但无法避免。
- 水平分割:不向原始路由更新来的方向再次发送路由更新信息,即单向更新、单向反馈。可以进入某个接口,使用命令 no ip split-horizon 关闭水平分割。例如,R1路由从Fa0/0接口向R2路由的Fa0/1接口发送路由信息,对于R2来讲不再从Fa0/1接口发送路由更信息。
- 路由毒化:又叫路由中毒。若 RIP 的路由条目出现故障时,会立即将此路由标记为 16 跳,并发送给邻居,告知邻居此路由有问题,尽快删除。
- 抑制计时器:抑制计时器告诉路由器把可能影响路由的任何改变暂时保持一段时间, 抑制时间通常比更新信息发送到整个网络的时间要长。
- 毒性逆转:如果Z的最短路径要通过邻居Y,那么它将告诉Y自己到目的节点的距离是无穷大。这样,Z向Y撒了一个善意的谎言,使得只要Z经过Y选路到X,它就会一直持续讲述这个谎言,这样Y也就永远不会尝试从Z选路到X了,也就避免了环路问题。由于这个方案不用路由间更新报文,所以优先于路由毒化。
触发更新与Silent模式
触发更新(Trigger Update)与周期性更新不同,它不会触发接收端的路由器重置其 update timer, 因为这样会引起许多路由器在同时重置它们的 update timer,最终导致全局路由同步,而这是我们不希望看到的。 同时为 了避免 trigger storm(触发更新风暴),会产生一个随机值(1-5 秒), 连续的触发更新必须等待相 应的时间才可再被发出。 当路由表发生变化时,更新报文立即广播给相 邻的所有路由器,而不是 等待 30 秒的更新周期。同样,当一个路由器刚启动 RP 路由协议时,它广播请求报文。收到此广播 的相邻路由器立即应答一个更新报文, 而不必等到下一个更新周期。这样,网络拓扑的变化会最快 地在网络上传播开, 减少了路由循环产生的可能性。
Silent模式(Silent Mode) 在 UNIX 系统上,使用 routed -q 参数可以将 RIP 置于一种“silent”模式,这种模式下不会主动发送路由更新,只是监听并根据需要修改自已本地的路由表。
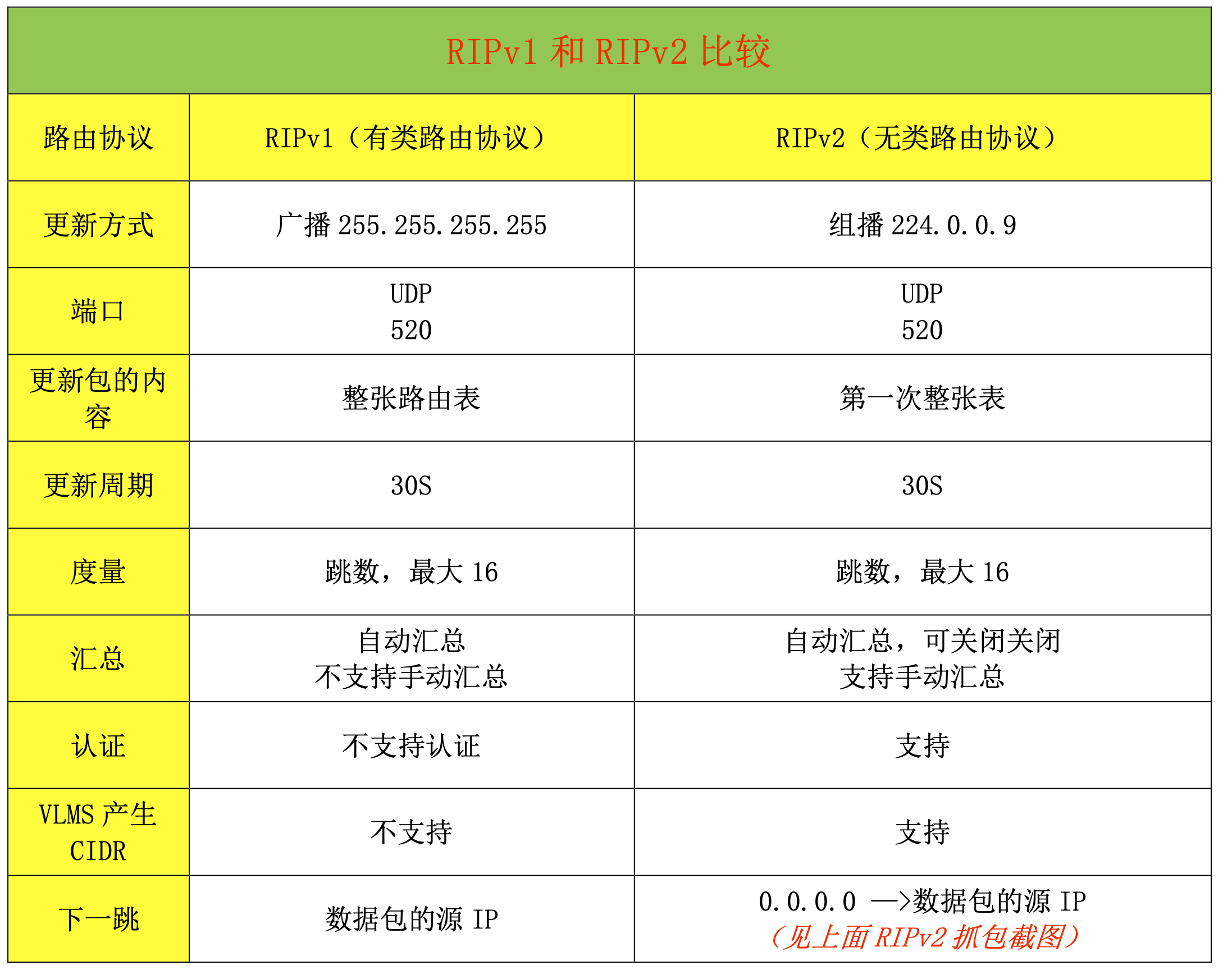
RIPv1
报文结构
RIPv1报文结构如下图所示

下面来说说各个字段的功能:
- 命令(Command):用于标识RIP报文类型。当值为1的时候,报文为Request;当值为2的时候,报文为Response类型。
- 版本(Version):在RIPv1中,该字段为1。
- 地址簇标识符(Address Family Identity AFI):该字段为2的时候表示IP协议;该字段为0表示且报文为Request类型,则说明用于向直连路由请求整个路由表,同时仅包含一个路由条目,目的IP地址为
0.0.0.0,度量值即metric跳数为16。 - IP地址(IP Address):路由的目的网络地址。
- 度量值(Metric):到达目的网络的开销值。
问题
通过报文结构我们就能看到缺少了一个很重要的东西——子网掩码。没错,RIPv1版本协议并不支持在报文中携带目的网络的子网掩码。
因此,有类别路由选择协议首先必须匹配一个目的地址对应 A,B,C 类的主网络号,对于每一个通过路由器的数据包有如下操作:
- 如果目的地址是一个路由器直接相连的主网络的成员,那么该网络的路由器接口 上配置的子网掩码将被用来确定目的的地址的子网,因此,在那个主网络中必须自始至终 地统一使用这个相同的子网掩码。
- 如果目的地址不是一个和路由器直接相连的主网络的成员,那么路由器将仅仅尝 试去匹配该目的的地址对应于A类,B类或 C类的主网络号。
我们抓包看一下:
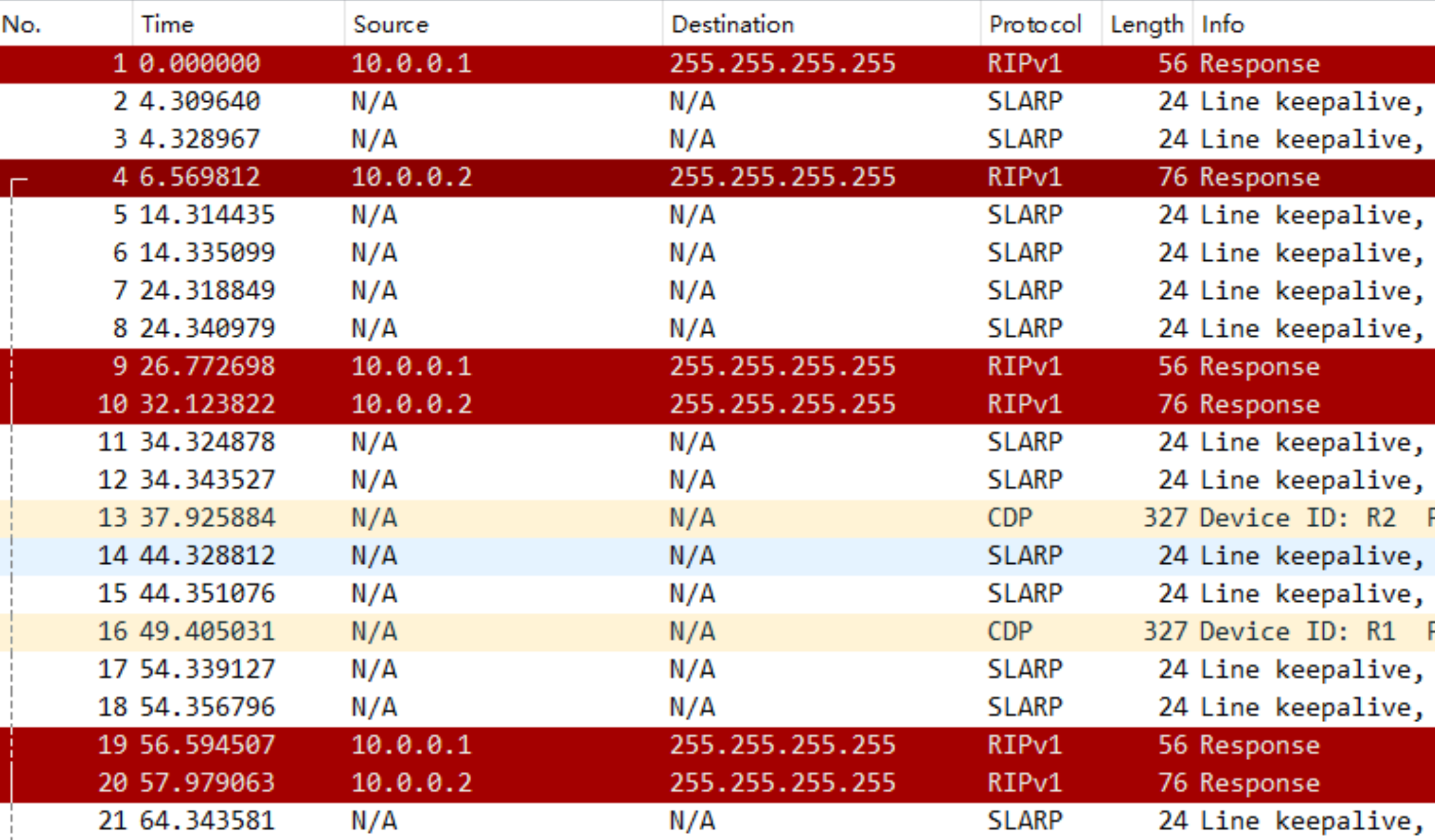
更详细的信息如下图:
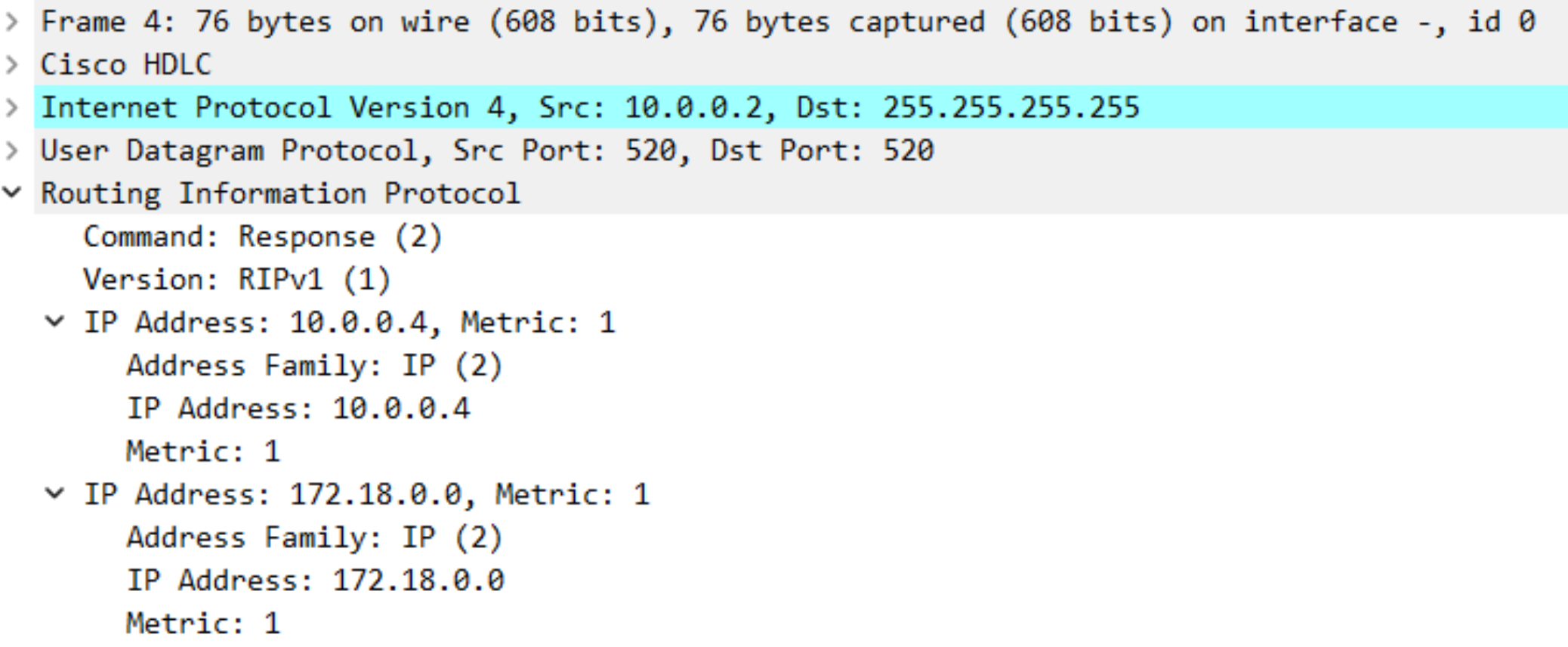
由此可得知:RIPv1 仅支持有类路由协议,并且在路由更新中不发送子网掩码。使用广播每 30 秒(实际是 25.5-30 秒)发送一次完整的更新。
此外RIPv1还不支持口令验证,这具有一定的不安全性。
解决问题
最省心的方案要么换协议,要么启用RIPv2版本。如果非要用RIPv1,可以给路由器配置第二个IP地址,使其成为一个连续的子网。
所谓连续的子网:母网相同,子网掩码一致。例如:192.169.1.0/24与192.168.2.0/24。
实验
接下来我们通过Cisco Packet Tracer模拟器来看一下。
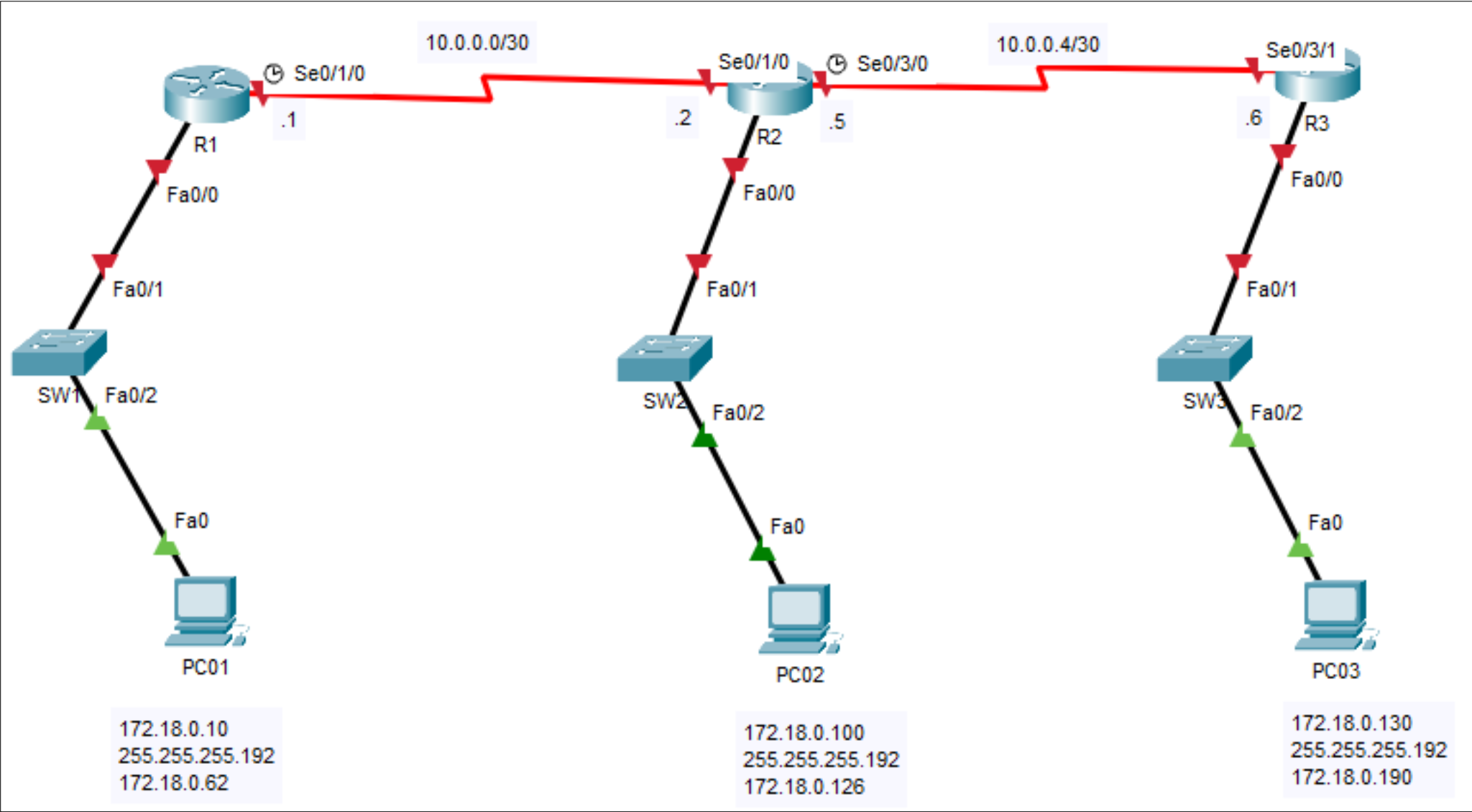
在上述样例中,各个路由器的Fa0/0端口都与对应的交换机相连,该接口地址为下方对应标签的第三行,例如R1路由器的Fa0/0接口IP地址为172.18.0.64子网掩码为255.255.255.192。此时下方主机的默认网关也是这个地址。
同样的下方标签的第一行为主机地址,例如PC01的地址为172.18.0.10。
其余接口的IP已经在相应链路上给出。例如R1 Se0/1/0接口IP为10.0.0.1/30。
迅速对上述拓扑完成基本配置:
//R1
en
config t
int f0/0
ip address 172.18.0.62 255.255.255.192
no shutdown
int s0/1/0
ip address 10.0.0.1 255.255.255.252
no shutdown
//R2
en
config t
int f0/0
ip address 172.18.0.126 255.255.255.192
no shutdown
int s0/1/0
ip address 10.0.0.2 255.255.255.252
no shutdown
int s0/3/0
ip address 10.0.0.5 255.255.255.252
no shutdown
//R3
en
config t
int f0/0
ip address 172.18.0.190 255.255.255.192
no shutdown
int s0/3/1
ip address 10.0.0.6 255.255.255.252
no shutdown
上述命令并没有给出特定的模式,直接打开路由的CLI然后复制粘贴进去(别复制注释)就行,我们的重点不在此处。(如果你不懂此处命令请参考我之前关于交换机和路由器基本配置的文章。)
接下来我们启用RIP
在R1上,我们用RIPv1宣告直连的网络
R1(config)#router rip
R1(config-router)#v 1
R1(config-router)#network 172.18.0.0
R1(config-router)#network 10.0.0.0
R1(config-router)#exit
R2和R3也是同理
R2(config)#router rip
R2(config-router)#v 1
R2(config-router)#network 172.18.0.64
R2(config-router)#network 10.0.0.0
R2(config-router)#network 10.0.0.4
R2(config-router)#exit
R3(config)#router rip
R3(config-router)#v 1
R3(config-router)#network 172.18.0.128
R3(config-router)#network 10.0.0.4
R3(config-router)#exit
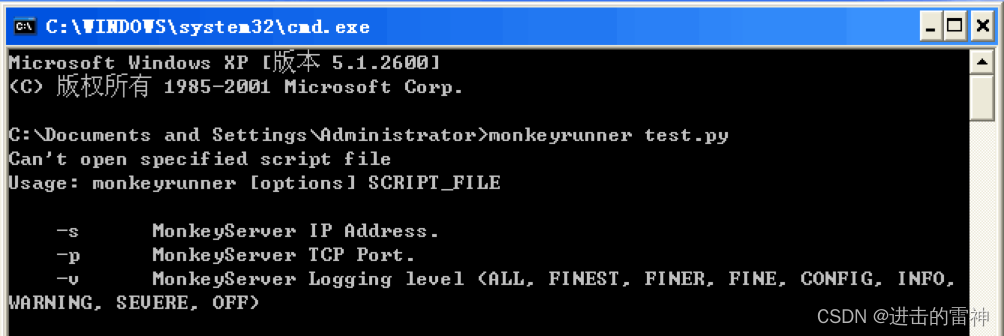
在R1上执行debug命令
R1#debug ip rip
发现弹出如下信息
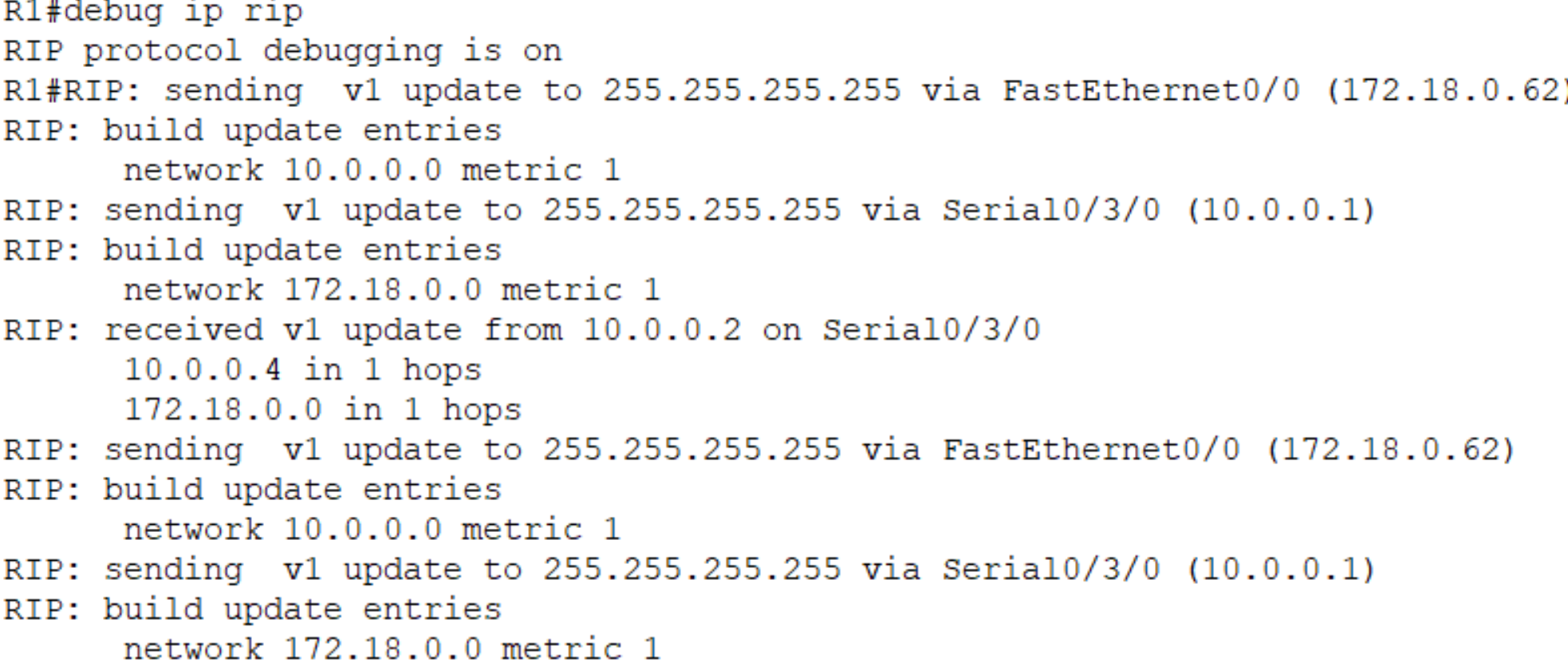
观察上图,发送的目的地址都是255.255.255.255,这说明v1使用广播
在R1中使用命令,查看数据库中学习的条目
R1#show ip rip database

再看看路由表
R1#show ip route
信息如下
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
C 10.0.0.0/30 is directly connected, Serial0/1/0
L 10.0.0.1/32 is directly connected, Serial0/1/0
R 10.0.0.4/30 [120/1] via 10.0.0.2, 00:00:24, Serial0/1/0
172.18.0.0/16 is variably subnetted, 2 subnets, 2 masks
C 172.18.0.0/26 is directly connected, FastEthernet0/0
L 172.18.0.62/32 is directly connected, FastEthernet0/0
发现找不到对应的主机网络的条目——不存在172.18.0.64和172.18.0.128网络。这正是因为RIPv1没有传递子网掩码的功能,且子网不连续造成的。
另外,对于同一网络,若该路由既有直连又从其它路由器中接收到条目,由于直连网络matric值比从其它路由收到的条目小,所以并不会更新条目。
我们给对应的PC设好IP地址之后发现也是Ping不通的(此处不演示)。
我们尝试给路由器之间的链路分配与主机网络相连续的网络的IP地址试一试。
R1(config-if)#ip addr 172.18.1.1
R1(config-if)#ip addr 172.18.1.1 255.255.255.192
R2(config)#int se0/1/0
R2(config-if)#ip addr 172.18.1.2 255.255.255.192
R2(config-if)#int se0/3/0
R2(config-if)#ip addr 172.18.2.1 255.255.255.192
R3(config)#int se0/3/1
R3(config-if)#ip addr 172.18.2.2 255.255.255.192
然后尝试在PC1上Ping PC3
ping 172.18.0.130
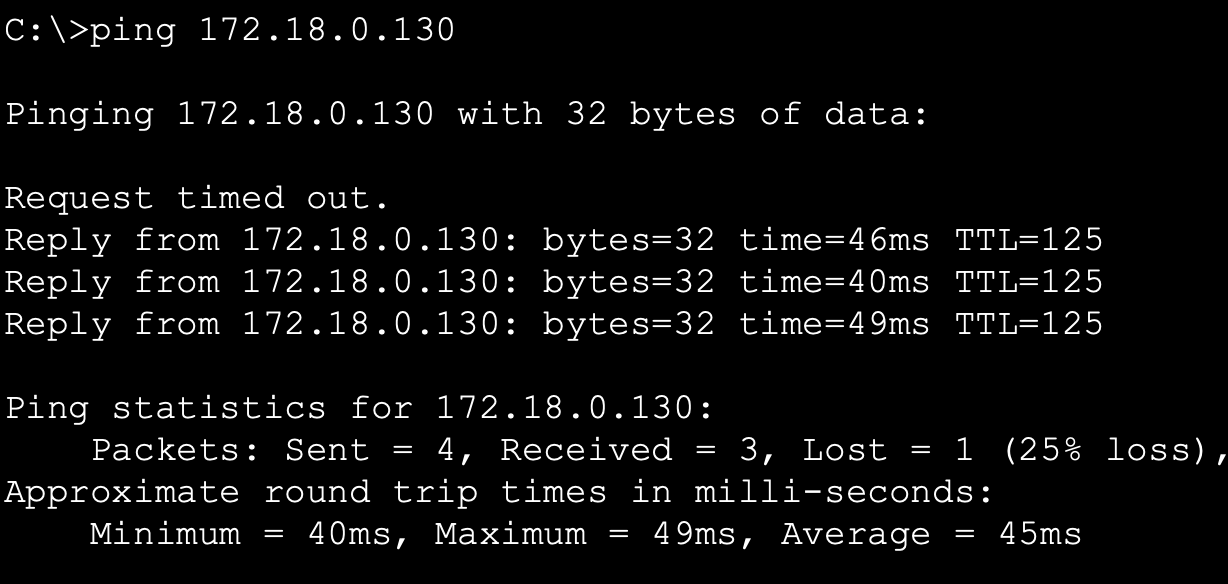
见证奇迹的时刻到了,我们的网络竟然Ping通了!
由此可见对于RIPv1不发送子网掩码,我们需要使用连续的子网来解决问题。
但是这种解决问题的方式经常不符合我们的规范,在某些特定的情况下我们就想要不连续的子网,然后就有了RIPv2协议。
RIPv2
报文结构
RIPv2版本报文结构如下图
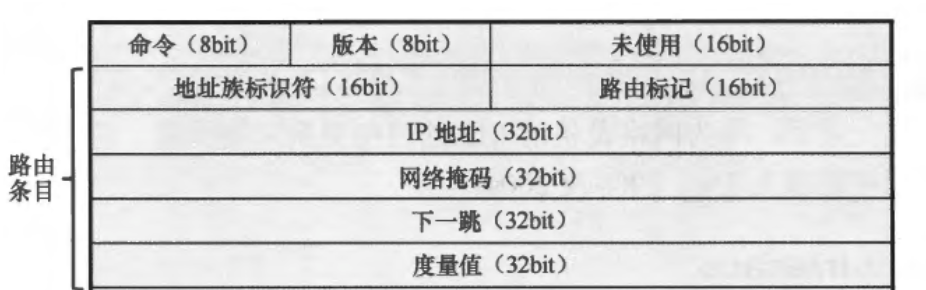
我们发现相比于RIPv1,v2版本的报文头多了网络掩码、下一跳、路由标记这几个字段。我们一下仅介绍与RIPv1不同的字段:
- 版本(Version):在RIPv2中该字段值为2。
- 网络掩码(Netmask):目的网络的掩码。RIPv1没有这一项,不支持可变子网掩码(Variable Length Subnet Mask, VLSM),而RIPv2支持了这一点。
- 路由标记(Route Tag):为路由设置标记信息,缺省为0。当一条外部路由被引入RIP从而形成一条RIP路由时,RIP可以为该路由设置路由标记,当这条路由在整个RIP域内传播时,路由标记不会丢失。
- 下一跳(Next Hop):RIPv2新增,使得路由器在多路访问网络上可以避免次优路径现象。一般情况下,在路由器所发送的路由更新中,路由条目的“下一跳”字段会被设置为
0.0.0.0,此时收到该路由的路由器将路由条目加载到路由表时,将路由的更新源视为到达目的网段的下一跳。在某些特殊的场景下,该字段值会被设置为非0.0.0.0。
RIPv2的新增功能
我们同样来抓一次包:
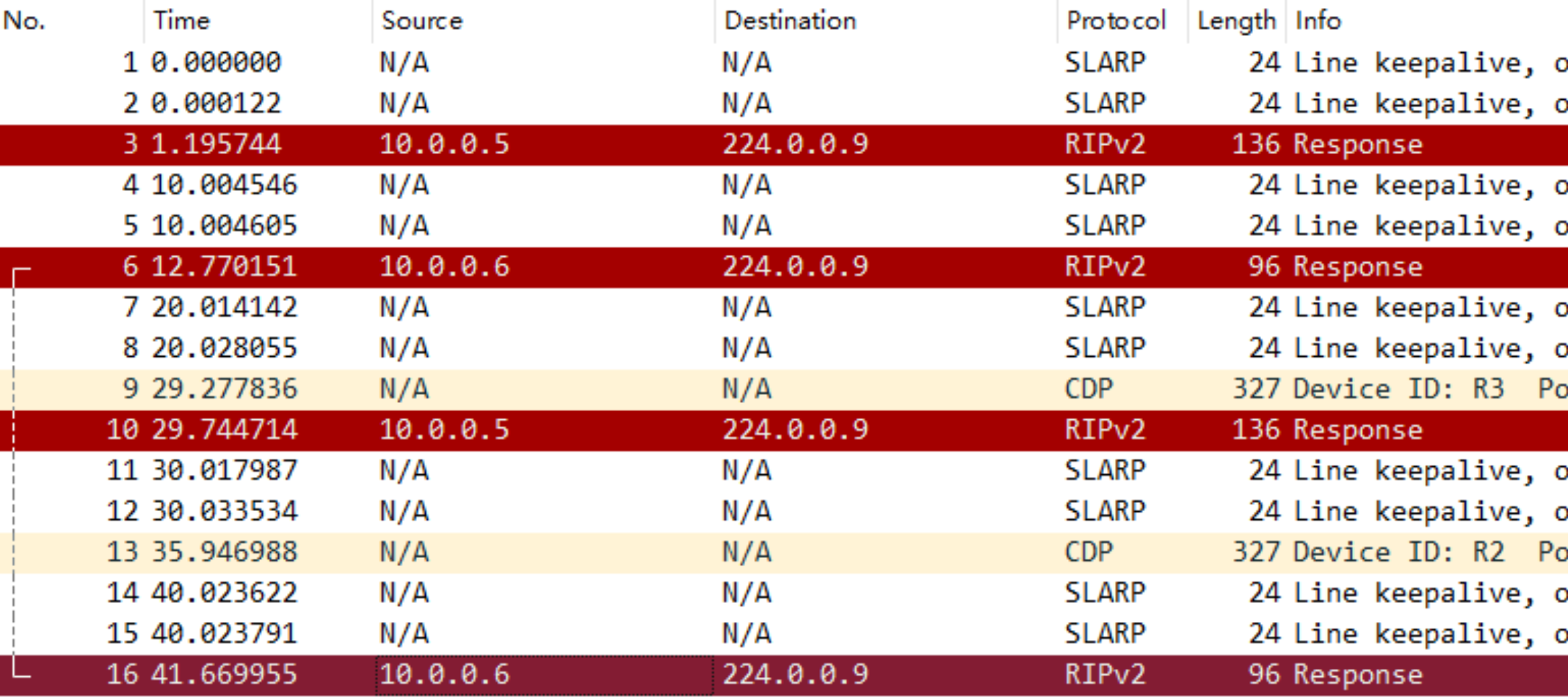
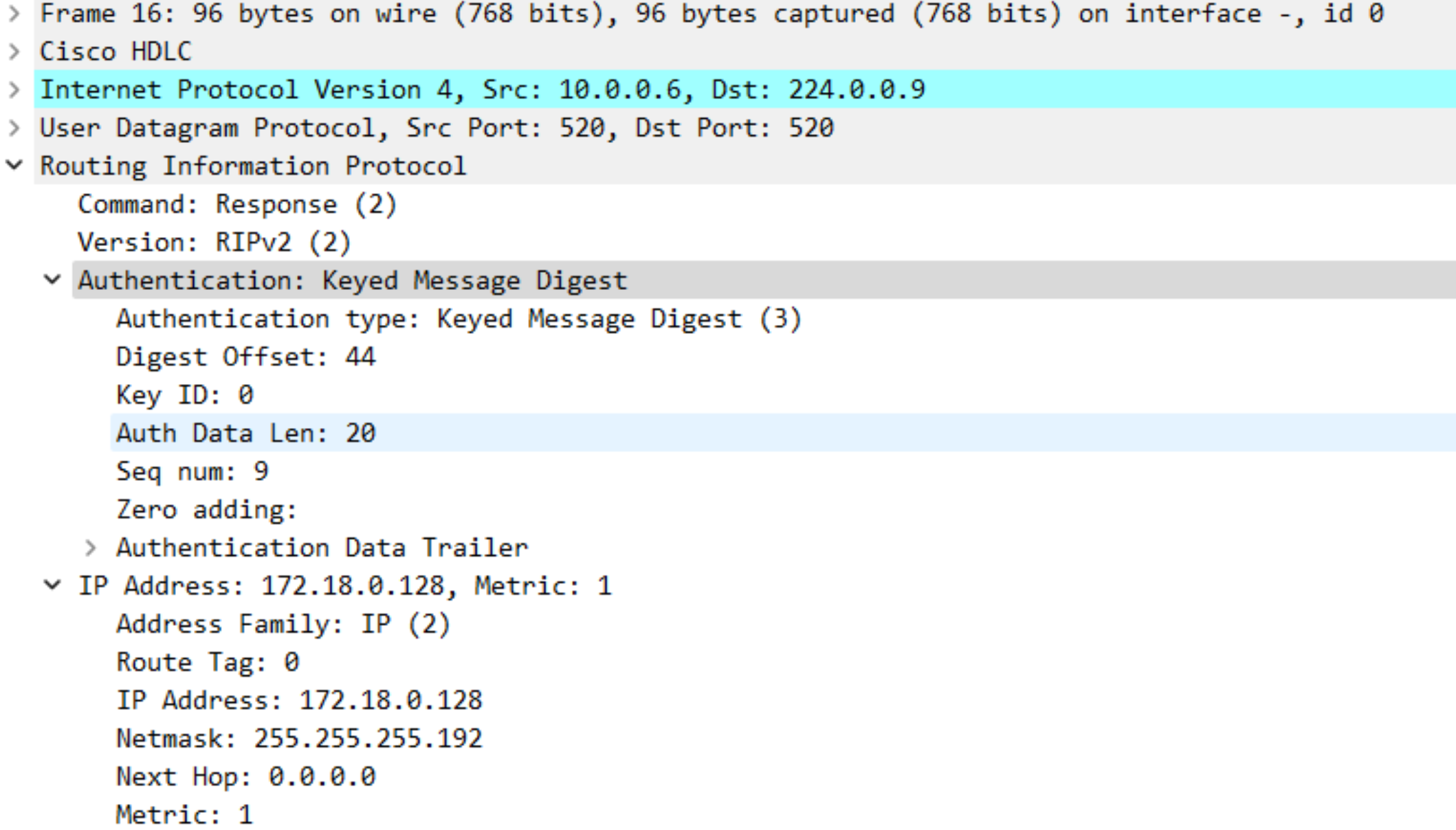
可见RIPv2相比于RIPv1使用组播的方式而非广播。
在 RIP 中的身份验证中,路由信息协议 RIPv2 的 Cisco 实现支持身份验证,密钥管理,路由汇总, 无类域间路由(CIDR)和可变长度子网掩码(VLSM)。
RIPv2发送路由条目时第一次发送整张表。此外,RIPv2支持自动汇总和手动汇总,自动汇总能关闭(只有关闭自动汇总才能启用手动汇总)。而RIPv1仅支持自动汇总且无法关闭。
实验
与RIPv1一样,我们构建类似的拓扑
为主机配置相应的IP,为路由器设置基本的配置。
基础配置方案与RIPv1实验部分一致,我们主要看RIP配置部分:
对于R1,我们开启RIPv2,宣告网络
R1(config)#router rip
R1(config-router)#v 2
R1(config-router)#network 172.18.0.0
R1(config-router)#network 10.0.0.0
R1(config-router)#exit
对于R2和R3同理
R2(config)#router rip
R2(config-router)#v 2
R2(config-router)#network 172.18.0.64
R2(config-router)#network 10.0.0.0
R2(config-router)#network 10.0.0.4
R2(config-router)#exit
R3(config)#router rip
R3(config-router)#v 2
R3(config-router)#network 172.18.0.128
R3(config-router)#network 10.0.0.4
R3(config-router)#exit
使用同样的命令查看R1路由表:
R1#show ip route
我们发现一个重要的问题:R1 路由表中还是只存在有类网络的路由条目,无法看到具体到达 R3 直连 172.18.0.128/26 的条目!
按理说RIPv2支持VLSM,我们应该能在路由表中看到R3的172.18.0.128/26才对。
实际上RIPv2的自动汇总是默认开启的,它仍会如v1那样将网络合并汇总,我们需要将自动汇总手动关闭。
实际上很简单,只需要在RIP配置模式下执行一条命令即可
R1(config)#router rip
R1(config-router)#no auto-summary
对于R2和R3一样
R2(config)#router rip
R2(config-router)#no auto-summary
R3(config)#router rip
R3(config-router)#no auto-summary
协议兼容性
在配置RIP时,如果不指定版本,接口默认情况下是能接收v1和v2的报文的,但是却只能发送v1的报文;在指定版本的情况下,RIPv1只能接收和发送v1的报文,RIPv2只能接收和发送v2的报文。
总结
其它命令(加密、查看信息等)
基本
查看 rip database (从邻居收集来的信息)
R1#show ip rip database
关闭自动汇总
R1(config-router)#no auto-summary
查看 RIP 配置
R1#show run | section rip
查看路由表
R1(config)#Show ip rout
指定一个接口可以发送的 RIP 的版本
R1(config-if)#ip rip send version 2
允许接口的地址和路由选择更新使用全 0 子网
R1(config-if)#ip subnet-zero
手动开始汇总
R1(config)#interface serial 0/3/0
R1(config-if)#ip summary-address rip 10.0.0.0 255.0.0.0
RIP加密
R1(config)#key chain cisco //定义 rip 中加密密钥链
R1(config-keychain)#key 0 //定义密钥
R1(config-keychain-key)#key-string cisco //定义密钥值
R1(config-if)#ip rip authentication key-chain cisco //在接口上调用密钥
R1(config-if)#ip rip authentication mode text //选择加密方式 明文
R1(config-if)#ip rip authentication mode md5 //选择加密方式 密文