LLM之Colossal-LLaMA-2:Colossal-LLaMA-2的简介、安装、使用方法之详细攻略
导读:2023年9月25日,Colossal-AI团队推出了开源模型Colossal-LLaMA-2-7B-base。Colossal-LLaMA-2项目的技术细节,主要核心要点总结如下:
>> 数据处理阶段。文章提到利用多种中文和英文数据集构建语料库,然后对语料进行预处理,将其转化为jsonl格式进行数据增强。
>> 词汇表扩充。文章提到将LLaMA-2原有3.2万词汇扩充至6.9万词汇,增加中文词汇覆盖率。同时初始化新的词嵌入矩阵。
>> 训练策略。文章提出采取分阶段训练策略,第一阶段基于LLaMA-2的预训练,第二阶段注入中文知识,第三阶段对知识进行重复训练。同时提出采用“桶式训练”更均匀划分数据集。
>> 命令行参数与模型导入使用。文章给出了Colossal-LLaMA-2训练与模型导入Transforms中的详细命令行参数与代码示例。
>> 评估结果。文章给出了Colossal-LLaMA-2在多个中文和英文任务上的智能化测评结果,与其他模型进行了性能对比。
>> 技术细节。文章从数据、词汇表、训练策略、任意域知识迁移四个角度阐述了项目的技术实现细节。
目录
Colossal-LLaMA-2的简介
0、技术特点
(1)、数据
(2)、分词器
(3)、训练策略
(3.1)、多阶段训练
(3.2)、基于桶的训练
(4)、跨领域大模型的桥接
1、性能评估
2、应用示例
3、训练日志
Colossal-LLaMA-2的安装
0、环境配置
1、安装软件包
2、运行使用
(1)、初始化标记器准备
(2)、初始化模型准备
(3)、数据准备
(4)、训练的命令行参数
(5)、运行命令
Colossal-LLaMA-2的使用方法
1、模型推理:从Transformers(推断)导入
Colossal-LLaMA-2的简介
2023年9月25日,Colossal-AI团队推出了开源模型Colossal-LLaMA-2-7B-base。这个模型是LLaMA-2的一个衍生版本,在15小时内使用64个A800 GPU进行了约85亿个标记的持续预训练。以不到1000美元的成本,您可以获得与从头开始预训练需要数百万美元的模型类似的结果。它在LLaMA-2许可证和Apache 2.0许可证下授权,没有额外的商业使用限制。这个解决方案还可以用来构建特定领域知识或任务的模型。
Colossal-LLaMA-2-7B-base旨在适应中文和英文,具有4096个标记的广泛上下文窗口。值得注意的是,与标准中文和英文评估指标(包括C-Eval和MMLU等)等规模相当的模型相比,它在基准测试中表现出色。
| 地址 | GitHub地址:https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2 |
| 时间 | 2023年9月25日 |
| 作者 | Colossal-AI |
0、技术特点
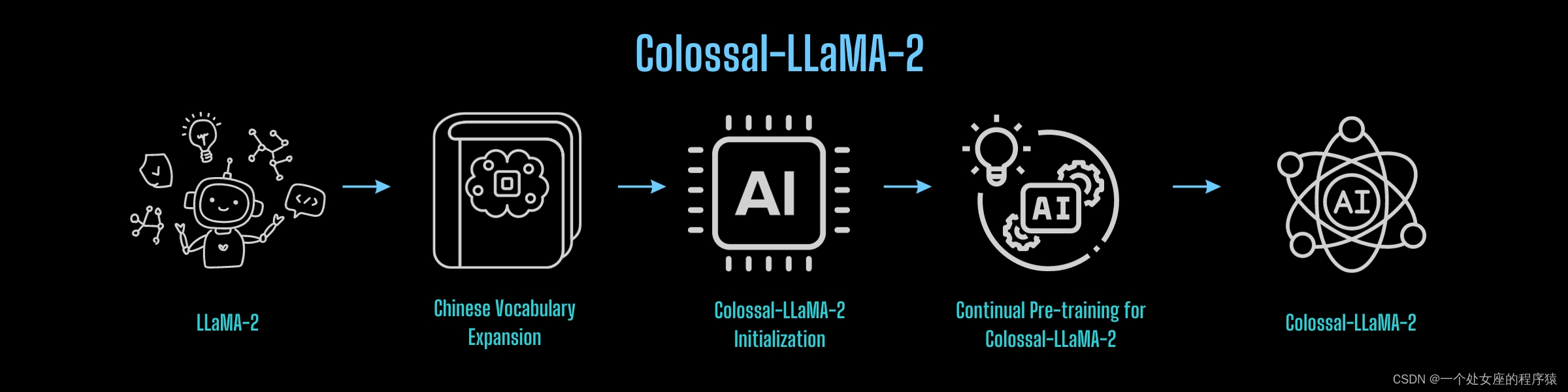
为了增强LLaMA-2在理解和生成中文内容方面的能力,Colossal-AI团队提出了继续使用中英文语料库对LLaMA-2模型进行预训练的方案。总体流程如下:
(1)、数据
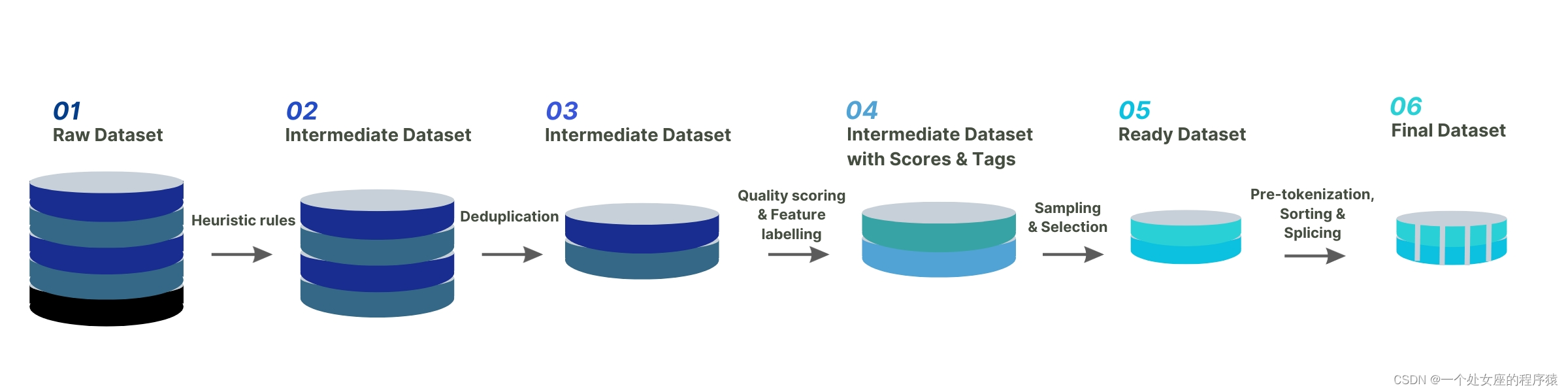
| 简介 | 像LLaMA-2这样的大型语言模型已经使用了多种高质量数据集进行训练,取得了令人鼓舞的成果。提升LLaMA-2在中文语料库中的性能,同时保持其在英语中的熟练度,关键取决于两个关键因素:数据集的组成,涵盖了英语和中文内容,以及每个组成数据集的质量。 以下图表显示了用于Colossal-LLaMA-2的数据处理流程。 |
| ❗️重要提示:我们将很快开源我们的数据处理工具包,敬请关注! |
重要通知:
本项目使用的所有训练数据均来自公开的知名数据集。
我们不使用评估基准的测试数据进行训练。
(2)、分词器
| 简介 | 原始LLaMA-2词汇表包含不到一千个汉字,因此在有效编码全面的中文文本方面表现不佳。其次,使用字节标记对于变压器编码器来捕捉汉字的语义细微差别构成了挑战。 为了解决上述问题,我们将LLaMA-2词汇表从32,000扩展到69,104。为了使LLaMA-2模型适用于Colossal-LLaMA-2分词器,我们通过计算原始LLaMA-2嵌入的均值来初始化新的单词嵌入,然后将这些新行附加到原始嵌入矩阵的末尾。 |
| 扩展词汇表大小的优势 | 扩展词汇表大小的优势: >> 提高字符串序列编码的压缩率。 >> 增强信息的完整性。 >> 使编码的序列包含更多有价值的信息,从而在理论上提高了章节级编码的能力。 在资源有限的情况下,大词汇量大小的优势: >> 训练数据集有限,存在大量未使用的标记,这些标记可能没有被有效地学习。 >> 过多的词汇扩展会导致嵌入相关参数增加,导致内存使用增加,从而影响训练过程的效率。 |
| 为了平衡两方面的需求,我们最终将词汇表构建为69,104个大小。下表比较了7B级别的各种模型。 |
| Model | Vocabulary Size | Compression Rate | Average Length of Samples (token-level) |
|---|---|---|---|
| Colossal-LLaMA-2 | 69104 | 0.659 | 73.682 |
| LLaMA-2-7B | 32000 | 1.205 | 134.689 |
| Atom-7B | 65000 | 0.634 | 70.915 |
| Baichuan-7B | 64000 | 0.678 | 75.857 |
| Baichuan2-7B-base | 125696 | 0.570 | 63.761 |
| Chatglm2-6B | 64789 | 0.645 | 72.178 |
| InternLM-7B | 103168 | 0.566 | 63.349 |
| Qwen-7B | 151643 | 0.578 | 64.703 |
| Tigerbot-7B-base | 60515 | 0.630 | 70.515 |
| Yayi-7B-llama2 | 32005 | 1.214 | 135.689 |
| Chinese-llama-2-7b | 55296 | 0.668 | 74.690 |
| Chinese-Falcon-7B | 90046 | 0.669 | 74.858 |
| LinkSoul-Chinese-Llama-2-7b | 40076 | 0.958 | 107.089 |
| Ziya-LLaMA-13B-v1.1 | 39410 | 0.958 | 107.074 |
(3)、训练策略
(3.1)、多阶段训练
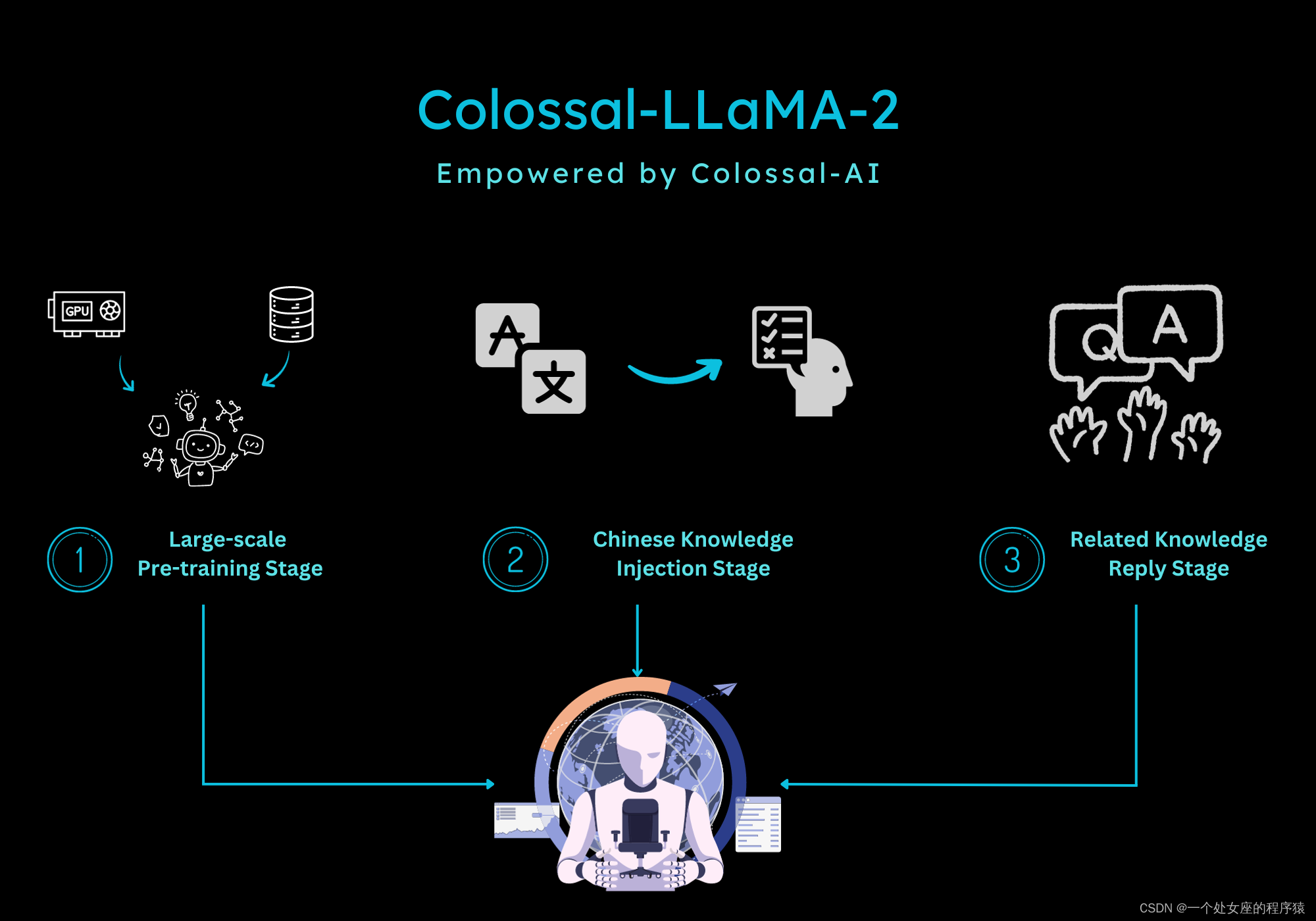
| 简介 | 为了增强模型的性能并充分发挥原始LLaMA-2的潜力,我们开发了多阶段训练策略。此策略旨在在一系列阶段中系统地释放模型的能力。 |
| 三阶段 | 因此,我们将训练过程分为三个阶段: >> 大规模预训练阶段(由LLaMA-2进行):这个初始阶段旨在从头开始建立模型的基本能力。它需要使用包含不少于1万亿标记的大型数据集。 >> 注入中文知识阶段:在这个阶段,我们将中文知识引入模型。它需要访问一个包含与中文语言相关的全面知识的高质量数据集。 >> 知识重播阶段:通过问答(QA)机制重播知识,包括中文和英文领域。 完成这个多阶段训练过程后,模型在英语和中文基准测试中表现出了显著的改进。 下图说明了训练Colossal-LLaMA-2的三个阶段。 |
(3.2)、基于桶的训练
| 背景 | 我们的实验表明,训练数据集中的分布以及各种与主题相关的数据点的排列,显著影响了模型的整体性能,特别是在持续预训练LLaMA-2的情况下。 |
| 简介 | 为了实现更平衡的分布并控制数据集的排序,我们采用了一种方法,将每个子数据集划分为离散的箱。然后将这些箱组合在一起,构建单独的数据桶,其中每个子数据集贡献一个箱。 |
(4)、跨领域大模型的桥接
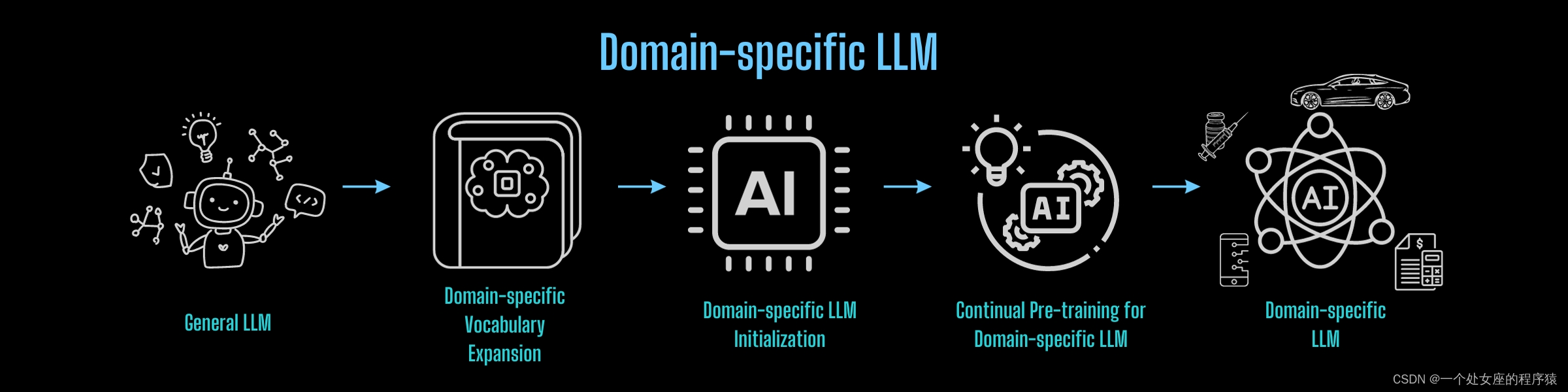
将上述过程应用于任何领域的知识转移,可以实现成本效益的轻量级领域特定基础大模型的构建。
1、性能评估
| 我们在4个数据集上进行了全面评估,并将我们的Colossal-Llama-2-7b-base模型与各种模型进行了比较。 >> 我们对MMLU使用了5-shot,并基于第一个预测的标记的逻辑值计算分数。 >> 我们对CMMLU使用了5-shot,并基于第一个预测的标记的逻辑值计算分数。 >> 我们对AGIEval使用了5-shot,只计算了4个选择题的得分,使用了精确匹配和第一个预测的标记的逻辑值的组合指标。如果精确匹配或第一个预测的标记中的任何一个是正确的,模型将获得分数。 >> 我们对GAOKAO-Bench使用了0-shot,只基于第一个预测的标记的逻辑值计算4个选择题的得分。所有数据集的生成配置都是贪婪搜索。 >> 我们还提供了CEval分数,这些分数来自其最新的排行榜或模型的官方存储库。 | |
| 括号中的分数对应于模型的官方存储库中的分数。 >> 我们对ChatGLM模型使用zero-shot。 >> Qwen-7B现在在Hugging Face中无法访问,我们使用的是它在无法访问之前的最新版本。仅对于数据集MMLU,提示将是"xxx Answer:"(去掉冒号后的空格),并且我们会计算Qwen-7B的"A"、"B"、"C"和"D"的逻辑值。与其他模型相比,Qwen-7B更具确定性。例如,"A"上的逻辑值可以为-inf,softmax将精确为0。 >> 对于其他模型和其他数据集,我们计算"A"、"B"、"C"和"D"的逻辑值。 ❗️有关评估方法的更多详细信息和结果的再现,请参阅ColossalEval。 |
| Backbone | Tokens Consumed | MMLU | CMMLU | AGIEval | GAOKAO | CEval | ||
|---|---|---|---|---|---|---|---|---|
| - | 5-shot | 5-shot | 5-shot | 0-shot | 5-shot | |||
| Baichuan-7B | - | 1.2T | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 | |
| Baichuan-13B-Base | - | 1.4T | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 | |
| Baichuan2-7B-Base | - | 2.6T | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 | |
| Baichuan2-13B-Base | - | 2.6T | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 | |
| ChatGLM-6B | - | 1.0T | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 | |
| ChatGLM2-6B | - | 1.4T | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 | |
| InternLM-7B | - | 1.6T | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 | |
| Qwen-7B | - | 2.2T | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 | |
| Llama-2-7B | - | 2.0T | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - | |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | 37.43 | 29.92 | 32.00 | 27.57 | - | |
| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | 38.56 | 31.52 | 30.99 | 25.95 | - | |
| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 | |
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | 43.73 | 42.04 | 37.64 | 30.61 | - | |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | 48.41 | 38.31 | 38.45 | 27.72 | - | |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | 49.96 | 41.10 | 39.83 | 33.00 | - | |
| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | 50.25 | 40.99 | 40.04 | 30.54 | - | |
| Colossal-LLaMA-2-7b-base | Llama-2-7B | 0.0085T | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 |
2、应用示例
有关更多问答示例,请参阅Colossal-LLaMA-2-7B-base示例。
| Question Type | Question | Colossal-LLaMA-2-7b-base |
|---|---|---|
| Knowledge Quiz (Tourism) | 请问武汉的最佳的旅行季节是什么时候? | 3-4月份到武汉赏樱,10月份到武汉看黄陂枫树。武汉的最佳的旅行季节是春秋,3-4月份到武汉赏樱,10月份到武汉看黄陂枫树。武汉,简称“汉”别称江城,是湖北省省会,中部六省唯一的副省级市,特大城市,中国中部地区的中心城市,全国重要的工业基地、科教基地和综合交通枢纽。 |
| Knowledge Quiz (Computer Science) | 在计算机中,什么是RAM?与ROM有什么区别? | RAM是随机存取内存,可以随时读写,但是断电之后会丢失数据。存储数据比较快,但是需要不断的进行通电供电。ROM是只读内存,只能读取数据,不能写入数据。断电之后,存储的数据也不会丢失,但是需要不断进行通电。两者的价格和性能上会有区别,而且在使用的时候,RAM需要不断的供电,而ROM断电数据不丢失。 |
| Knowledge Quiz (Literature) | 古代文学与现代文学有哪些区别和共通之处? | 古代文学与现代文学有三点区别,现代文学更加通俗易懂,具有可读性,而古代文学相对来说更加注重形式,缺乏可读性。现代文学和古代文学,同属于中华文学大花园中的一枝花蕾。但是它们由于历史的原因,有着不同的特点,具体表现在,现代文学有更丰富的描写方法,更强烈的主观色彩和更突出的抒情色彩,而古代文学的主要特征是在创作风格上的多样化。 |
| Emotional Analysis | 请判断这个句子的情绪是否正面:我迫不及待想见到她!!!”。 | 这一句是情绪是正向的。是在期待见面的喜悦情绪。 |
| Translation | 将以下句子翻译成英语。 我喜欢看电影和读书。 | I like watching movies and reading books. |
| Logical Reasoning | All books have the same weight, 10 books weigh 5kg, what is the weight of 2 books? | To find the weight of 2 books, we can use the following steps: 1. Determine the weight of 1 book. 2. Multiply the weight of 1 book by the number of books. Step 1: Determine the weight of 1 book. Since 10 books weigh 5kg, we can divide 5kg by 10 to find the weight of 1 book. 5kg ÷ 10 = 0.5kg Step 2: Multiply the weight of 1 book by the number of books. To find the weight of 2 books, we multiply the weight of 1 book by 2. 0.5kg × 2 = 1kg So, the weight of 2 books is 1kg. |
| Information Extraction | The company's annual conference, featuring keynote speakers and exclusive product launches, will be held at the Los Angeles Convention Center from October 20th to October 23rd, 2021. Extract the date mentioned in the above sentence. | The date mentioned in the sentence is October 20th to October 23rd, 2021. |
| Error Correction | Please correct the syntax error and restructure the sentence: "Went to the store me and my friend." | The given sentence "Went to the store me and my friend." is incorrect due to a syntax error and it lacks a subject. The corrected version with proper grammar and sentence structure would be: "My friend and I went to the store." |
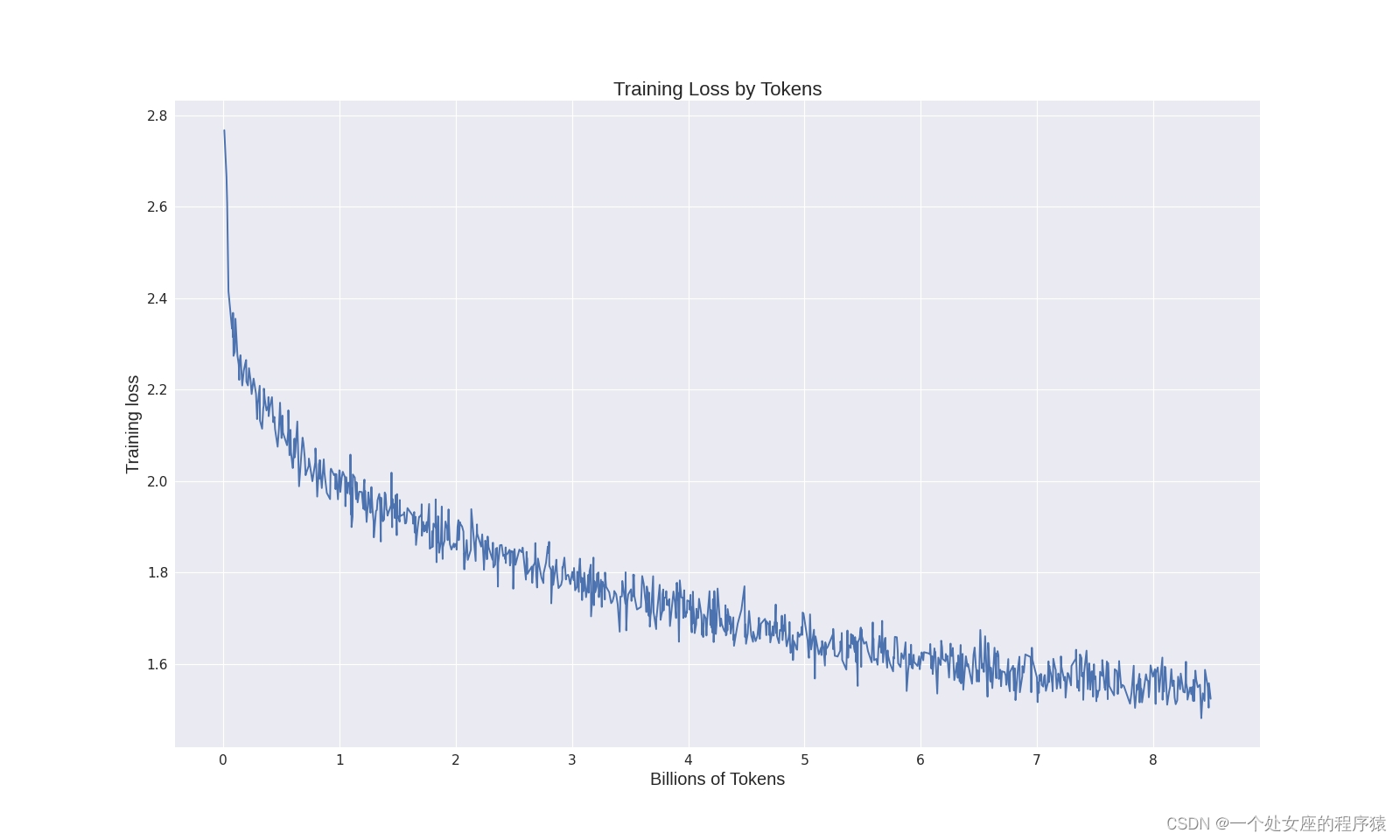
3、训练日志
我们还记录了实验的训练日志。

Colossal-LLaMA-2的安装
0、环境配置
| 硬件配置 | 此实验在总共8台计算节点上执行,配有64个A800 GPU,用于LLaMA-2-7B(约1000美元成本)。节点之间使用RDMA连接,节点内的GPU通过NVLink完全连接。此脚本在CUDA 11.7上进行了测试,CUDA版本要求11.7或更高。 您还可以在8个A100/A800服务器上完成大约5天的工作。 |
| 框架版本 | PyTorch。PyTorch版本应低于2.0.0且高于1.12.1。 |
1、安装软件包
| 所需的软件包 | |
| 其它包 | 安装xentropy、layer_norm和rotary |
2、运行使用
(1)、初始化标记器准备
| jsonl格式存储 | 使用附加的中文标记初始化新的标记器。附加的中文标记以jsonl格式存储,如下所示: {"piece": "你好"} {"piece": "人工智能"} |
| 脚本命令 | 初始化新标记器的命令如下: export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION='python' python colossal_llama2/tokenizer/init_tokenizer.py --source_tokenizer_dir "<SOURCE_TOKENIZER_DIR>" --target_tokenizer_dir "<TARGET_TOKENIZER_DIR>" --expand_tokens_file "<NEW_TOKENS_FILE>.jsonl" |
| CLI参数的详细信息 | 以下是关于CLI参数的详细信息: 源标记器目录:--source_tokenizer_dir。源标记器的目录。它至少应包含三个文件:special_tokens_map.json、tokenizer.model和tokenizer_config.json。 目标标记器目录:--target_tokenizer_dir。目标标记器的目录。 要添加的标记:--expand_tokens_file。要添加到标记器的附加标记。 |
(2)、初始化模型准备
| 脚本命令 | 通过计算原始模型检查点的均值来初始化新的模型检查点。初始化新模型检查点的命令如下: python colossal_llama2/model/init_model.py --source_model_and_tokenizer_path "<SOURCE_MODEL_AND_TOKENIZER_DIR>" --target_tokenizer_path "<TARGET_TOKENIZER_DIR>" --target_model_path "<TARGET_MODEL_DIR>" "<TARGET_MODEL_DIR>"可以与"<TARGET_TOKENIZER_DIR>"相同。 |
| CLI参数的详细信息 | 以下是关于CLI参数的详细信息: 源模型和标记器路径:--source_model_and_tokenizer_path。源文件夹包含模型和标记器,例如Hugging Face格式的LLaMA-2模型。 目标标记器路径:--target_tokenizer_path。新标记器文件夹的路径,从上一步生成。 目标模型路径:--target_model_path。保存新模型的路径,以Hugging Face格式保存。 |
| 重要提示 | 重要提示:一旦初始化新模型检查点,复制您的新标记器文件(special_tokens_map.json、tokenizer.model和tokenizer_config.json)到新模型文件夹中。 |
(3)、数据准备
| jsonl格式数据 | 原始数据应格式化为jsonl格式。每个数据点应具有以下字段: >> source(str,必需):在计算损失时忽略此部分。默认可以为空。 >> target(str,必需):将计算损失。 >> category(str,必需):每个数据点的标签。 示例: {"source": "", "target": "Lionel Andrés Messi(Spanish pronunciation: [ljoˈnel anˈdɾes ˈmesi] (i); born 24 June 1987), also known as Leo Messi, is an Argentine professional footballer who plays as a forward for and captains both Major League Soccer club Inter Miami and the Argentina national team.", "category": "sports"} {"source": "猜谜语:一身卷卷细毛,吃的青青野草,过了数九寒冬,无私献出白毛。(打一动物)", "target": "白羊", "category": "riddle"} 您可以自定义类别标签或使用未知来定义类别。 |
| 脚本命令 | 将jsonl数据集转换为arrow格式的命令如下: python prepare_pretrain_dataset.py --data_input_dirs "<JOSNL_DIR_1>,<JOSNL_DIR_2>,<JOSNL_DIR_3>" --tokenizer_dir "<TOKENIZER_DIR>" --data_cache_dir "jsonl_to_arrow_cache" --data_jsonl_output_dir "spliced_tokenized_output_jsonl" --data_arrow_output_dir "spliced_tokenized_output_arrow" --max_length 4096 --num_spliced_dataset_bins 10 |
| CLI参数的详细信息 | 以下是关于CLI参数的详细信息: 源数据目录:data_input_dirs。每个<JOSNL_DIR>可以包含多个jsonl格式的文件。 标记器目录:tokenizer_dir。Hugging Face格式的标记器的路径。 数据缓存目录:data_cache_dir。用于存储Hugging Face数据缓存的目录。默认情况下将在本地创建缓存文件夹。 jsonl格式输出目录:data_jsonl_output_dir。用于存储以jsonl格式转换的数据集的输出目录。 arrow格式输出目录:data_arrow_output_dir。用于存储以arrow格式转换的数据集的输出目录,可以直接用于训练。 最大长度:max_length。切割样本的最大长度。默认值为4096。 每个类别的箱数:num_spliced_dataset_bins。每个类别的箱数,用于基于桶的训练。 |
(4)、训练的命令行参数
| 脚本命令 | 您可以使用colossalai run来启动多节点训练: colossalai run --nproc_per_node 每个节点的GPU数量 --hostfile 主机文件 \ train.py --其他配置 |
| 示例主机文件 | 以下是一个示例主机文件: hostname1 hostname2 hostname3 hostname4 确保主节点可以通过ssh无需密码访问所有节点(包括自身)。 |
| CLI参数的详细信息 | 以下是关于CLI参数的详细信息: 预训练模型路径:--pretrained。预训练模型在Hugging Face格式中的路径。 数据集路径:--dataset。预标记数据集的路径。 Booster插件:--plugin。支持gemini、gemini_auto、zero2、zero2_cpu和3d。有关更多详情,请参阅Booster插件。 要加载的中间检查点:--load_checkpoint。中间检查点的路径。保存的检查点包含了lr_scheduler、optimizer、running_states.json和模型。如果load_checkpoint指向模型文件夹,只会加载模型权重,而不加载其他支持多阶段训练的状态。 保存间隔:--save_interval。保存检查点的间隔(步数)。默认值为1000。 检查点目录:--save_dir。保存检查点和中间状态的目录路径。中间状态包括lr_scheduler、optimizer、running_states.json和模型。 Tensorboard目录:--tensorboard_dir。保存Tensorboard日志的路径。 配置文件:--config_file。保存配置文件的路径。 训练周期数:--num_epochs。训练周期数。默认值为1。 微批量大小:--micro_batch_size。每个GPU的批量大小。默认值为1。 学习率:--lr。学习率。默认值为3e-4。 最大长度:--max_length。上下文的最大长度。默认值为4096。 混合精度:--mixed_precision。混合精度。默认值为"fp16"。支持"fp16"和"bf16"。 梯度剪裁:--gradient_clipping。梯度剪裁。默认值为1.0。 权重衰减:-w、--weight_decay。权重衰减。默认值为0.1。 热身步数:-s、--warmup_steps。热身步数。默认值由0.025的热身比例计算得出。 梯度检查点:--use_grad_checkpoint。是否使用梯度检查点。默认值为False。这会节省内存但会降低速度。建议在使用大批量大小进行训练时启用此选项。 闪存注意力:--use_flash_attn。如果要使用闪存注意力,必须安装flash-attn和相关软件包。默认值为False。这有助于加速训练并节省内存。建议始终使用闪存注意力。 冻结非嵌入参数:--freeze_non_embeds_params。冻结非嵌入参数。在扩展词汇量大小后对齐嵌入很有帮助。 张量并行规模:--tp。三维并行规模。默认值为1。 零阶段:--zero。三维并行的零阶段。默认值为1。 |
(5)、运行命令
| 实验的示例bash | 还提供了一个实验的示例bash。以下是运行实验的步骤: >> 创建您自己的主机文件:cp hostfile.example hostfile。 >> 创建您自己的bash:cp train.example.sh train.sh。 >> 将您的真实主机IP或主机名添加到主机文件中。 >> 在您的train.sh中更新全局变量和参数。 >> 使用bash train.sh运行实验。 |
| 全局变量的详细信息 | 以下是每个实验的全局变量的详细信息: PROJECT_NAME:每个实验的项目名称。 PARENT_SAVE_DIR:保存模型检查点的父文件夹。 PARENT_TENSORBOARD_DIR:保存Tensorboard日志的父文件夹。 PARENT_CONFIG_FILE:保存每个实验配置的父文件夹。 PRETRAINED_MODEL_PATH:本地预训练模型检查点的路径。 dataset:所有准备好的数据的路径。通常是准备数据的输出路径、--data_arrow_output_dir的子文件夹列表,如果有多个子文件夹,请列出它们所有。例如: declare -a dataset=( "<DIR_1>/part-00000" "<DIR_1>/part-00001" "<DIR_2>/part-00000" ) |
Colossal-LLaMA-2的使用方法
1、模型推理:从Transformers(推断)导入
要使用Transformers加载Colossal-LLaMA-2-7B-base模型,请使用以下代码:
您还可以从���HuggingFace下载模型权重。
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("hpcai-tech/Colossal-LLaMA-2-7b-base", device_map="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("hpcai-tech/Colossal-LLaMA-2-7b-base", trust_remote_code=True)
input = "离离原上草,"
inputs = tokenizer(input, return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs,
max_new_tokens=256,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True)[len(input):])