目录
前言:
一.配置环境
1.安装clickhouse驱动
2.配置clickhouse环境
二.spark 集成clickhouse
直接上代码,里面有一些注释哦!
前言:
在大数据处理和分析领域,Spark 是一个非常强大且广泛使用的开源分布式计算框架。而 ClickHouse 则是一个高性能、可扩展的列式数据库,特别适合用于实时分析和查询大规模数据。将 Spark 与 ClickHouse 集成可以充分发挥它们各自的优势,使得数据处理和分析更加高效和灵活。
一.配置环境
1.安装clickhouse驱动
在idea中的maven中安装依赖包
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.1</version>
</dependency>2.配置clickhouse环境
(未安装clickhouse可参考文章:安装配置clickhouse)
修改clickhouse配置文件,使其可以远程连接
进入目录:cd /etc/clickhouse-server/

编辑 config.xml,将listen_host注释打开,一般是注释状态!

二.spark 集成clickhouse
直接上代码,里面有一些注释哦!
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{avg, broadcast, col, month, to_timestamp, when, year}
object DomeThree {
def main(args: Array[String]): Unit = {
//new spark
val conf = new SparkConf().setMaster("local[*]").setAppName("three")
.set("spark_testing_memory", "2222222222").set("dfs.client.use.datanode.hostname", "root") //设置spark运行容量 和 dfs的用户
System.setProperty("HADOOP_USER_NAME","root")
// 创建SparkSession(根据自己需求配置)
val sc = new SparkSession.Builder()
.config("hive.metastore.uris", "thrift://192.168.23.xx:9083")
.config("hive.metastore.warehouse", "hdfs://192.168.23.xx://9000/user/hive/warehouse")
.config("spark.sql.storeAssignmentPolicy", "LEGACY")
.config(conf)
.enableHiveSupport()
.getOrCreate()
// 以jdbc为连接方式进行连接
val frame = sc.read.format("jdbc")
.option("driver","ru.yandex.clickhouse.ClickHouseDriver" )// 配置driver
.option("url", "jdbc:clickhouse://192.168.23.xx:8123") // 配置url
.option("user", "default")
.option("password", "123456")
.option("dbtable", "shtd_result.cityavgcmpprovince")
.load()
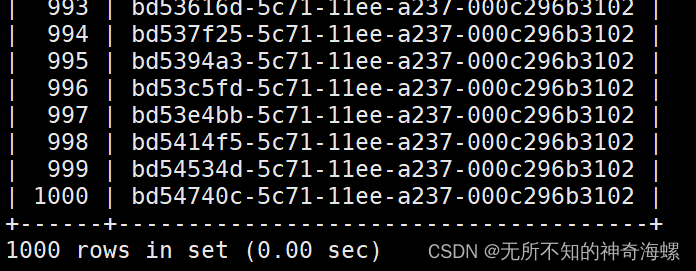
frame.show() //查看表格
}
}控制台打印(因为建的是空表模拟数据的)