台大官方网站:ML 2023 Spring (ntu.edu.tw)
【生成式AI】Diffusion Model 概念讲解 (1/2)_哔哩哔哩_bilibili
PS: 又出新课程了 计算机发展太快了 希望有机会再完整学一遍2233
正式开始上课---------------------------------------------------------
P1
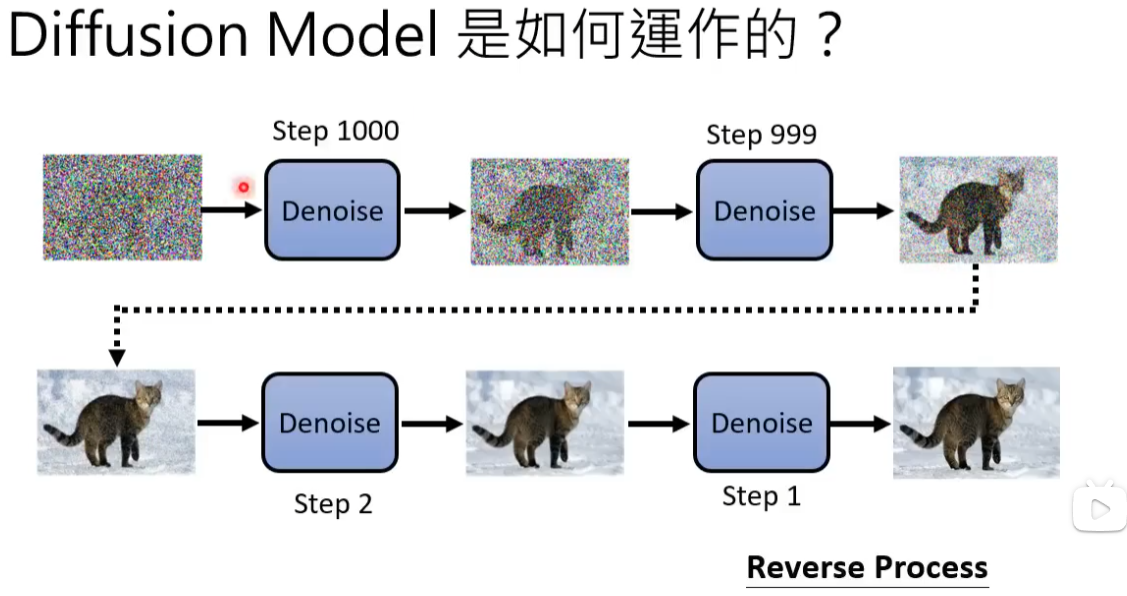
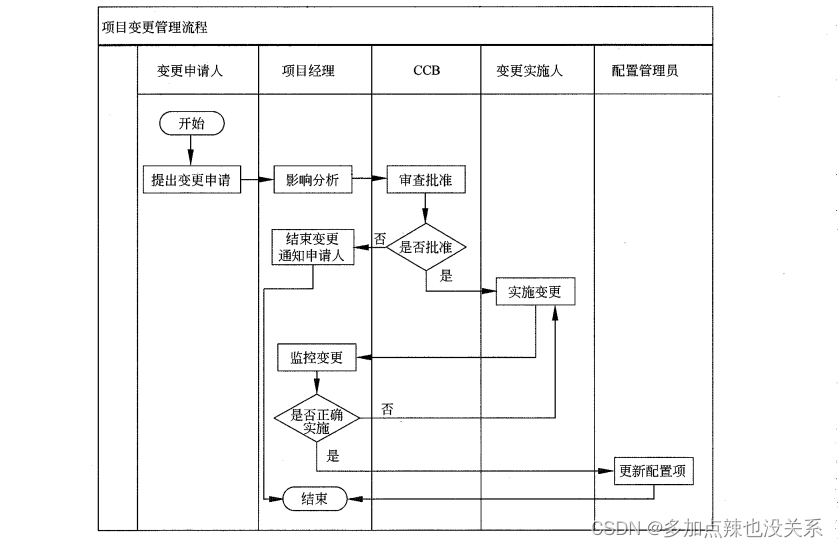
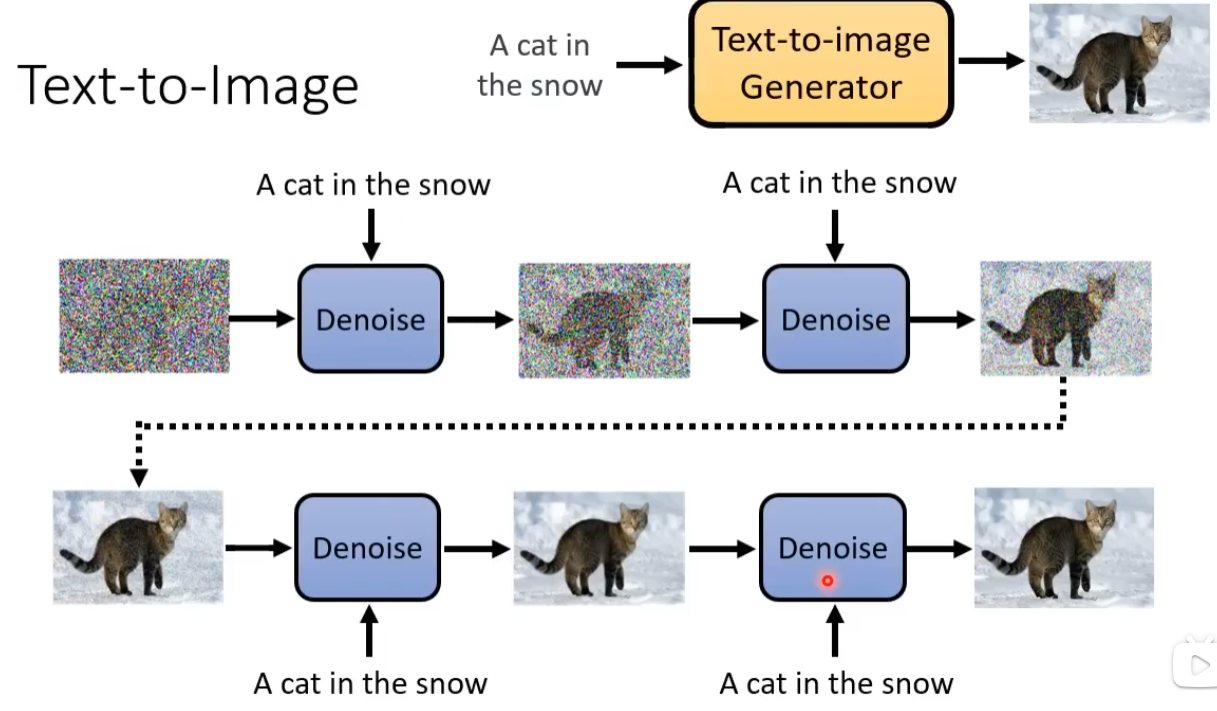
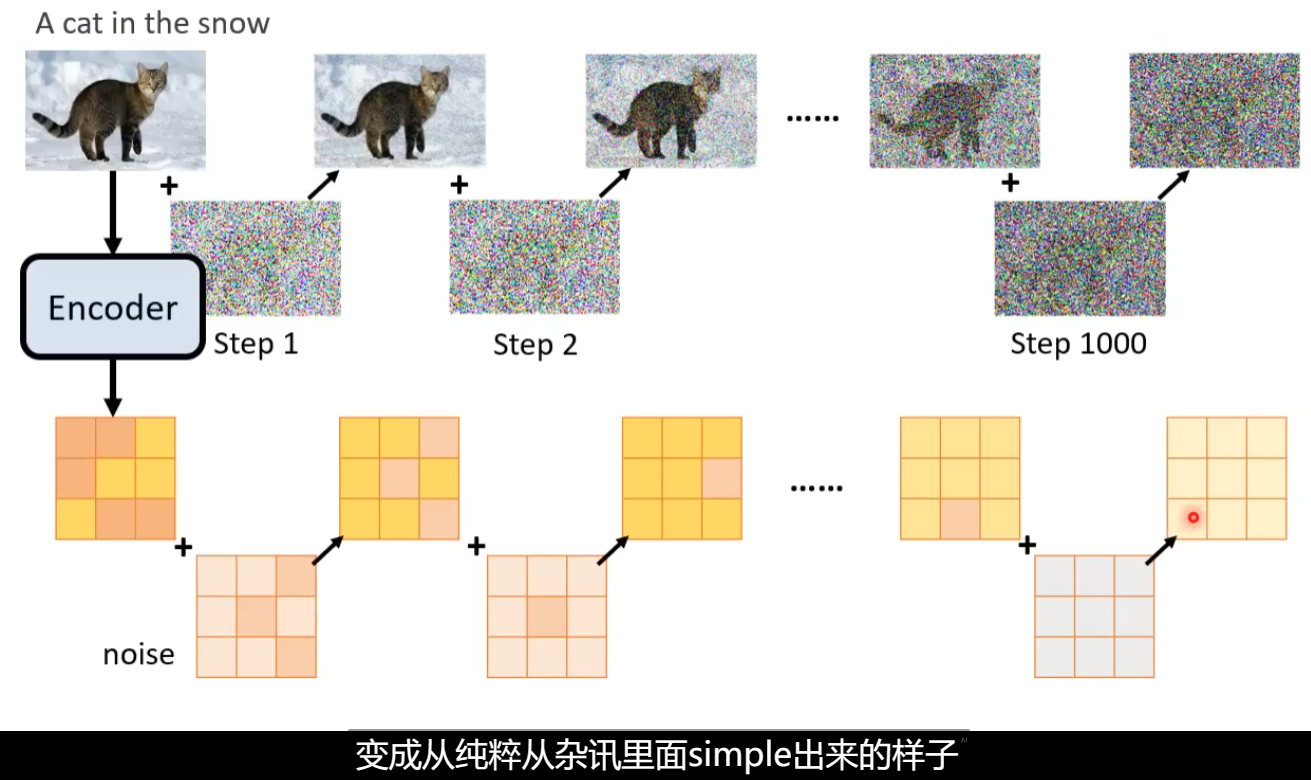
生成图片的过程: 从一个高斯分布中采样出一个vector,这个vector的维度跟你要生成的图片维度大小是一致的,比如256*256。将采样得到的矢量按照顺序拍成一张图片,随后进行多次降噪(Denoise),多次降噪的过程被称为Reverse Process。以上过程类似于大理石雕塑 传神!
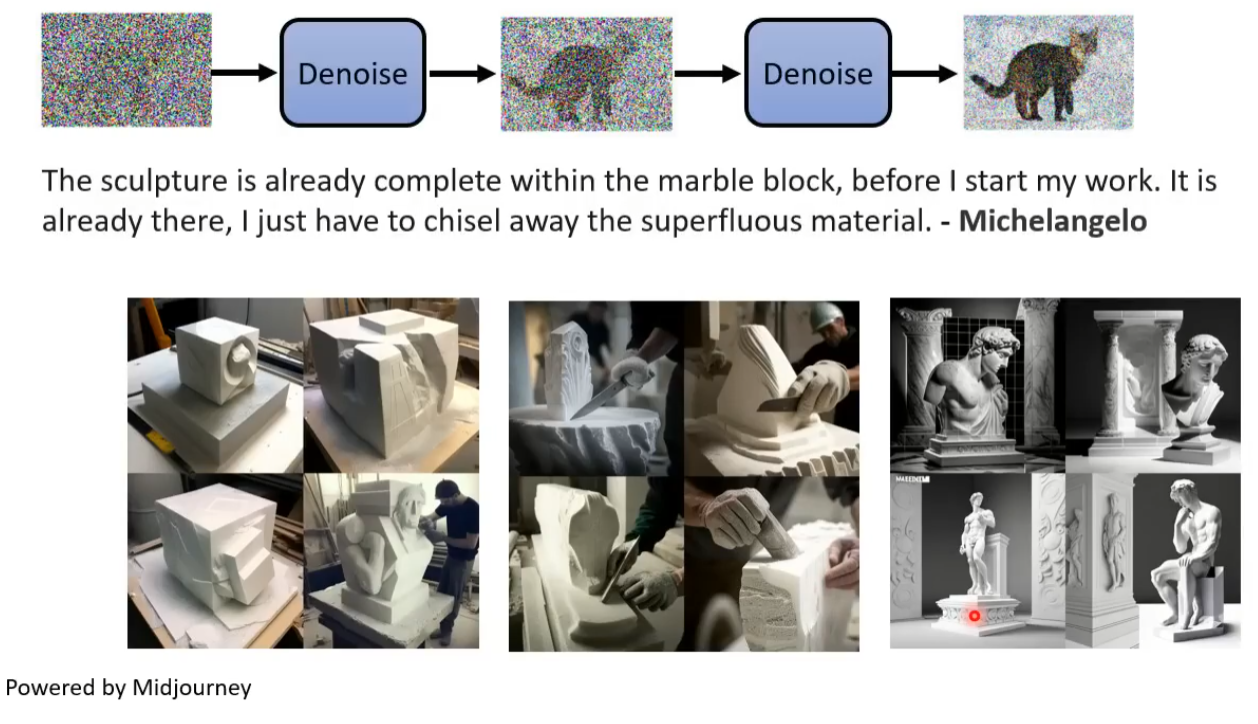

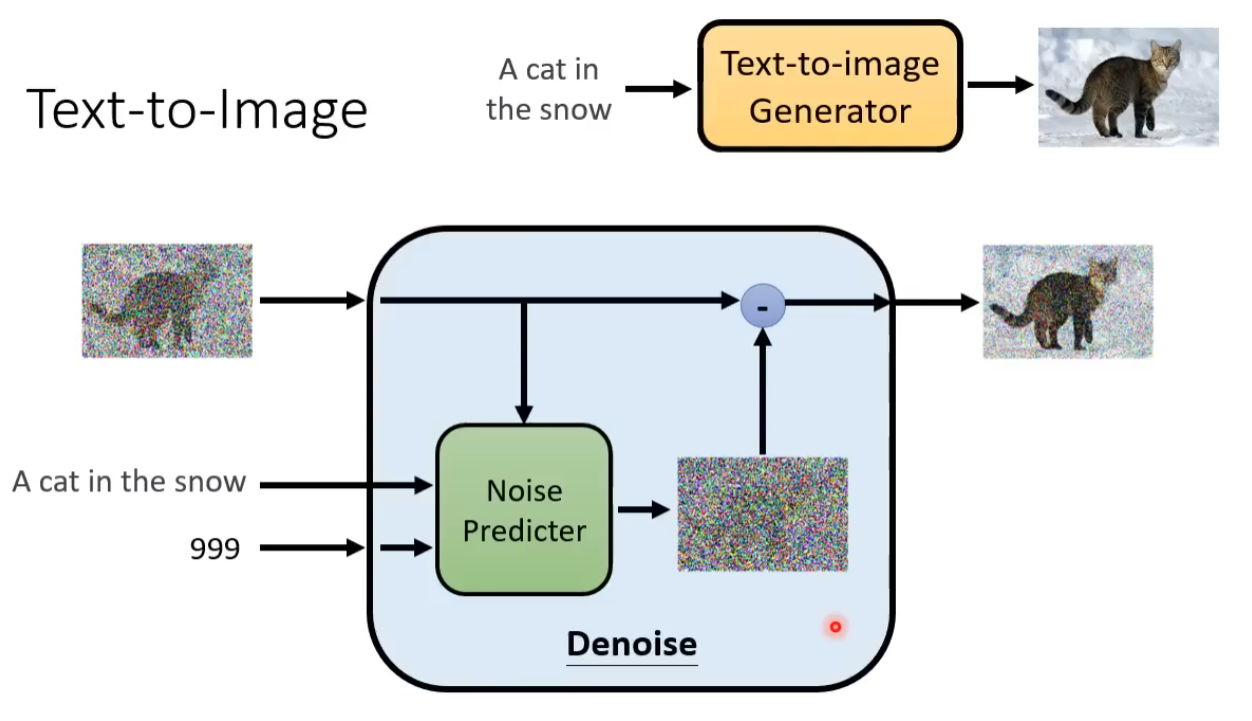
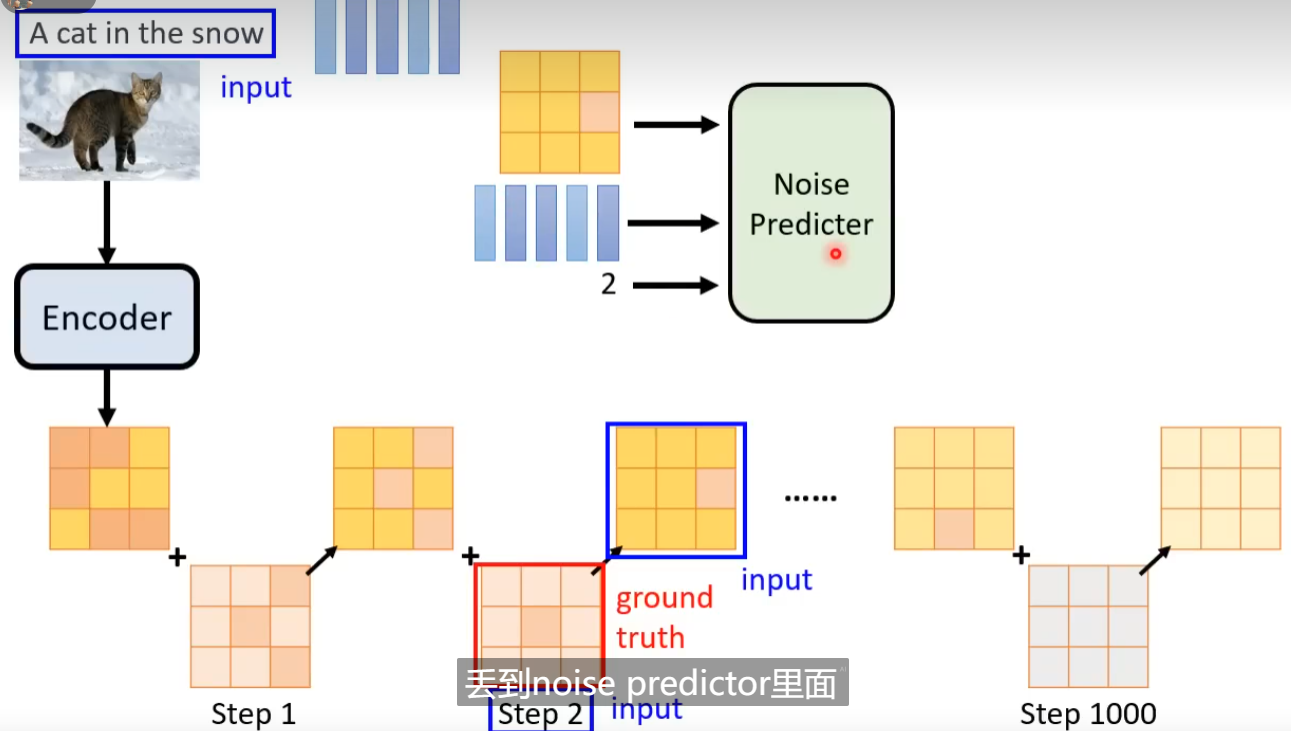
输入除了采样得到的图像(在本案例中)还有一个数字表示还有进行降噪的次数(图片含噪音的严重程度)。
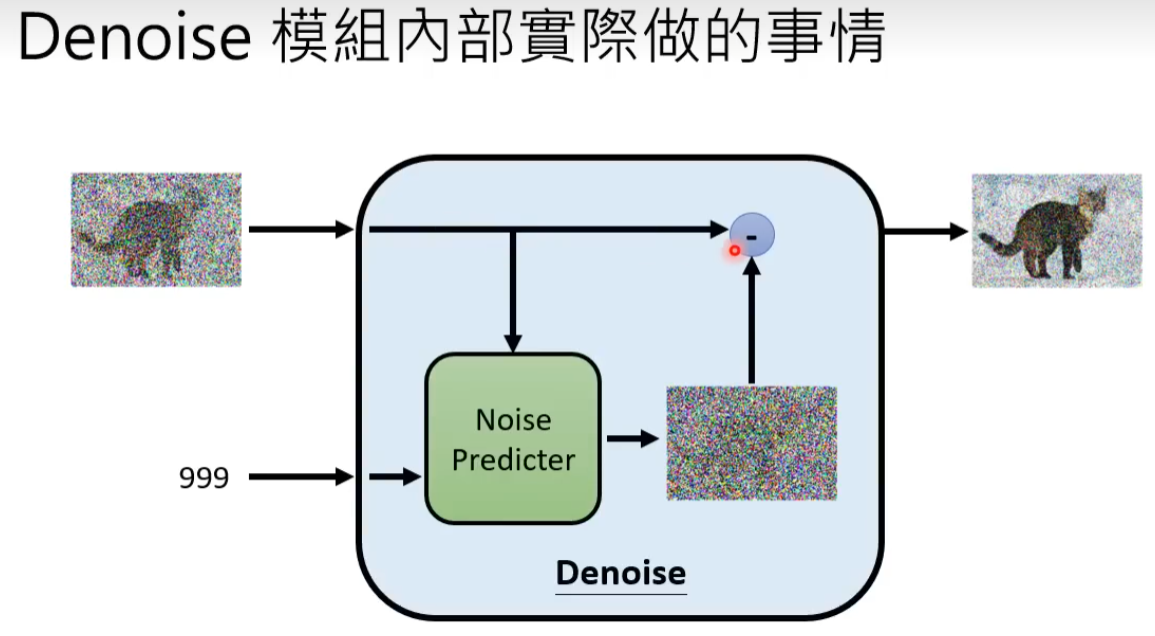
通过噪音预测生成的图片(理想状态下图片中仅含有杂讯)去减掉原本的输入,得到降噪后的图片。
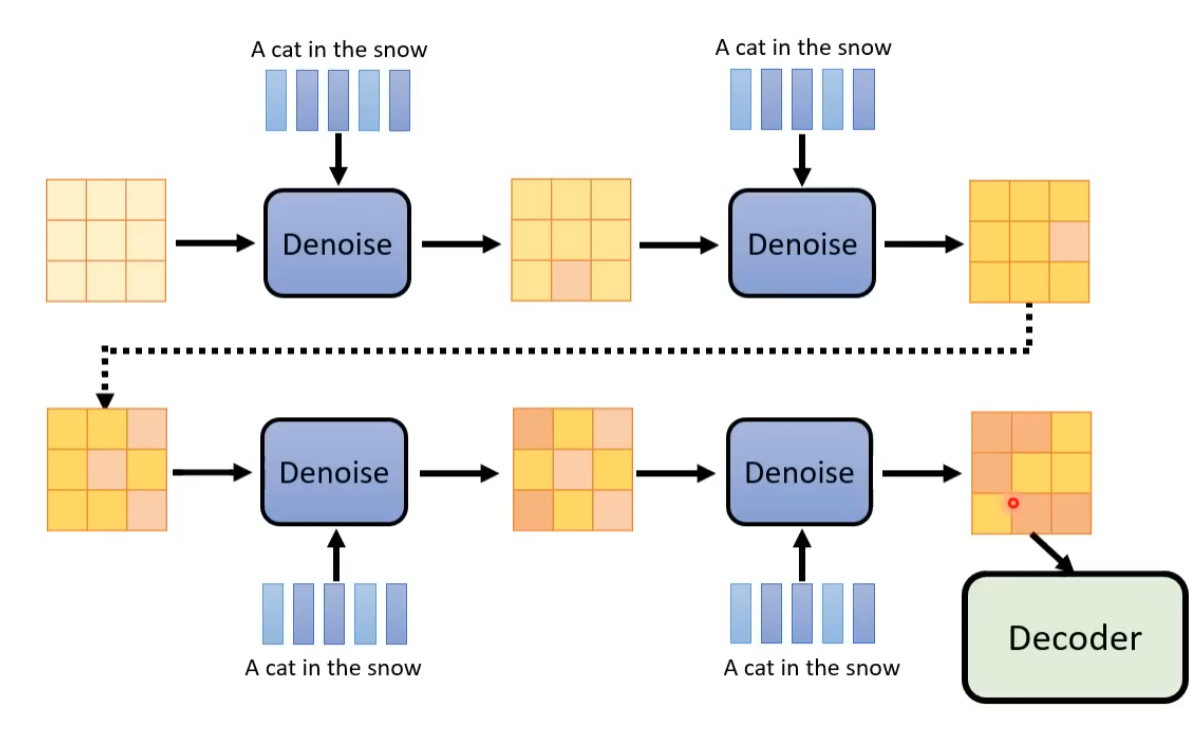
产生一张图片和产生Noise其难度是不一样的,如果训练的Denoise Model能够产生带杂讯的猫,说明该模型几乎已经会画一只猫了。产生一张带杂讯的猫跟产生一张图片中的杂讯其难度是不一样的。End to End model 直接产生一张去噪后的图片是比较困难的。
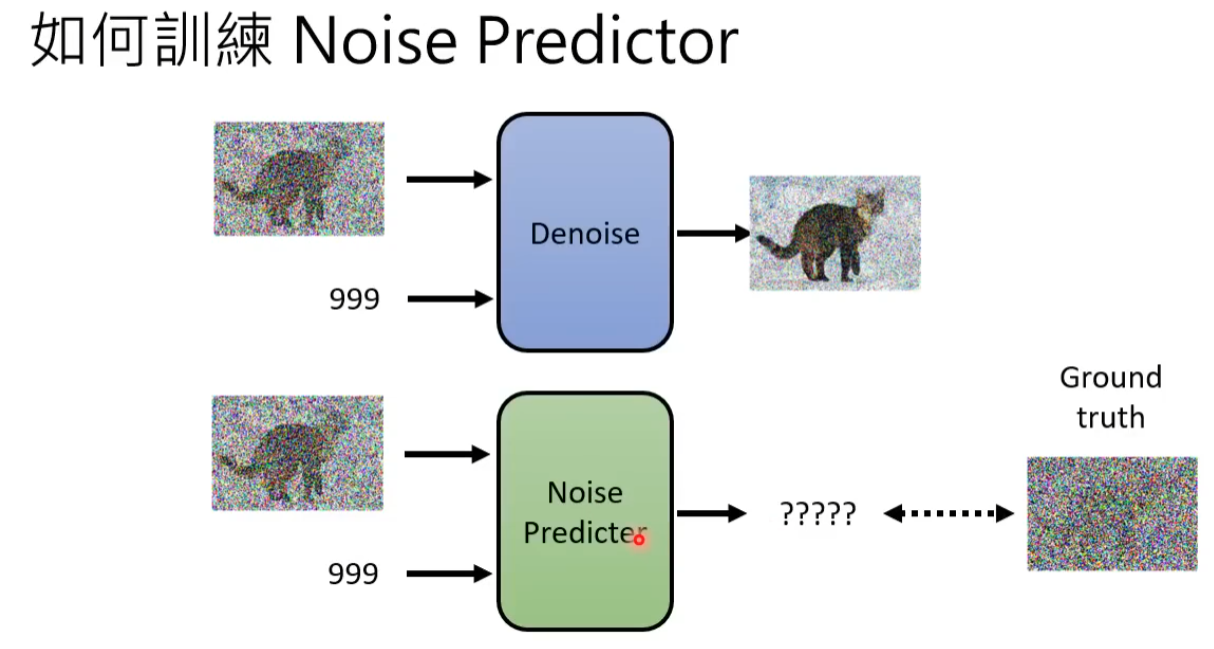
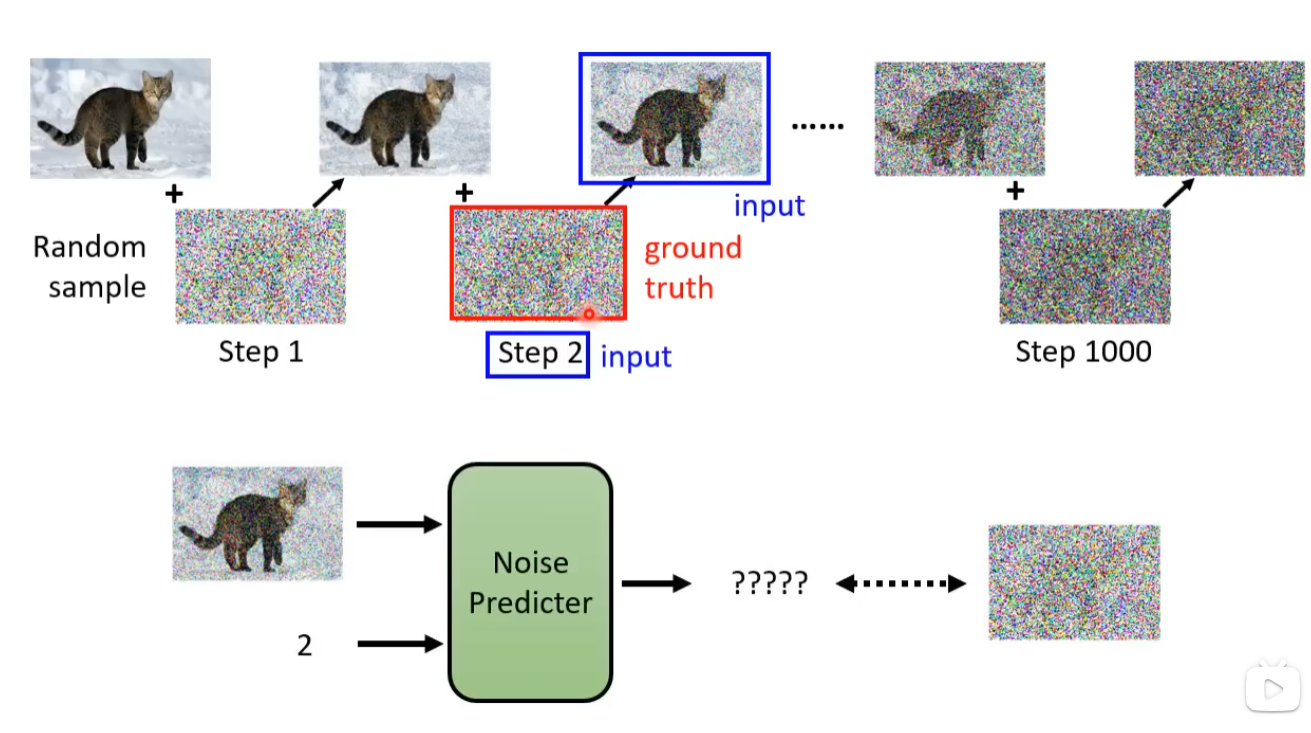
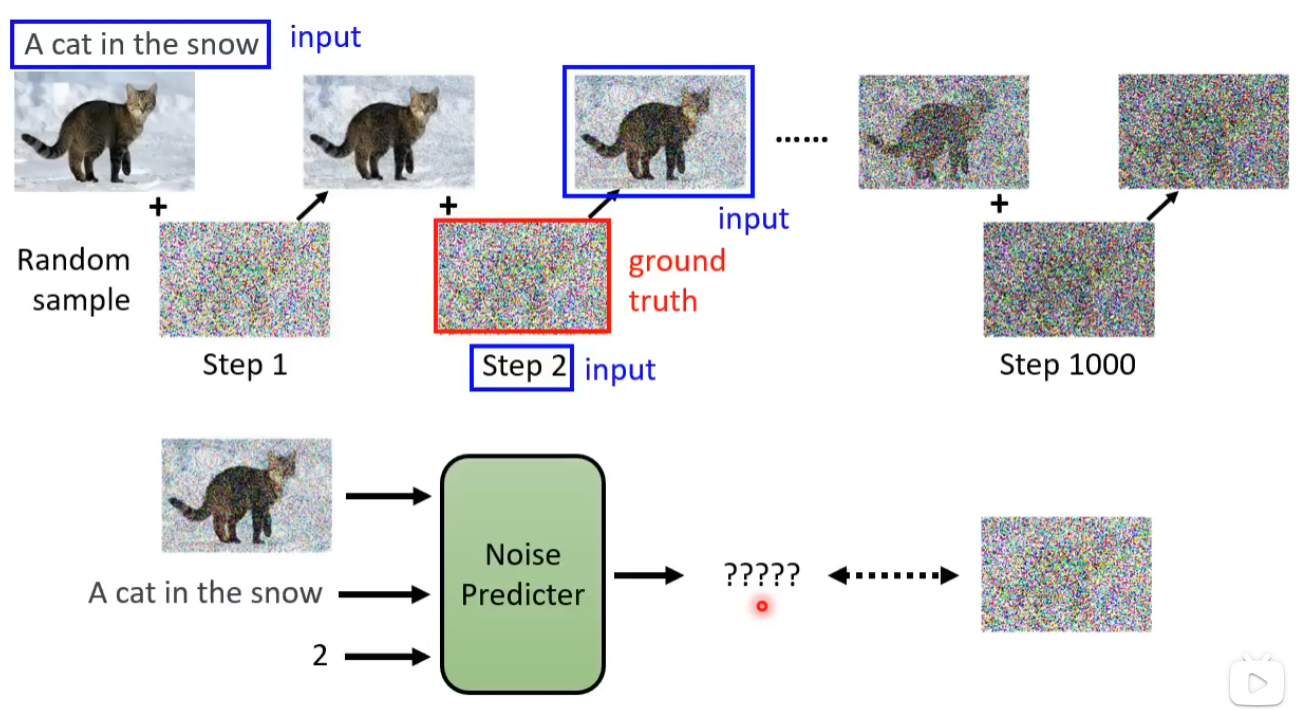
输入的杂讯由人为产生(非图像研究方向,So..)通过多次增加杂质,图像愈发不清楚

这里噪音预测的内容即为随机生成的杂讯图。

P2
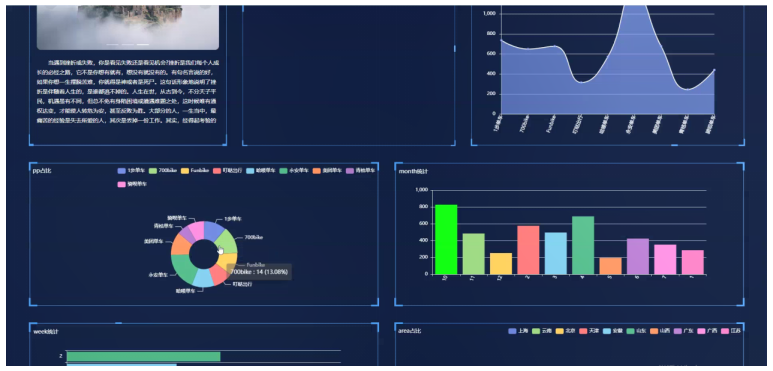
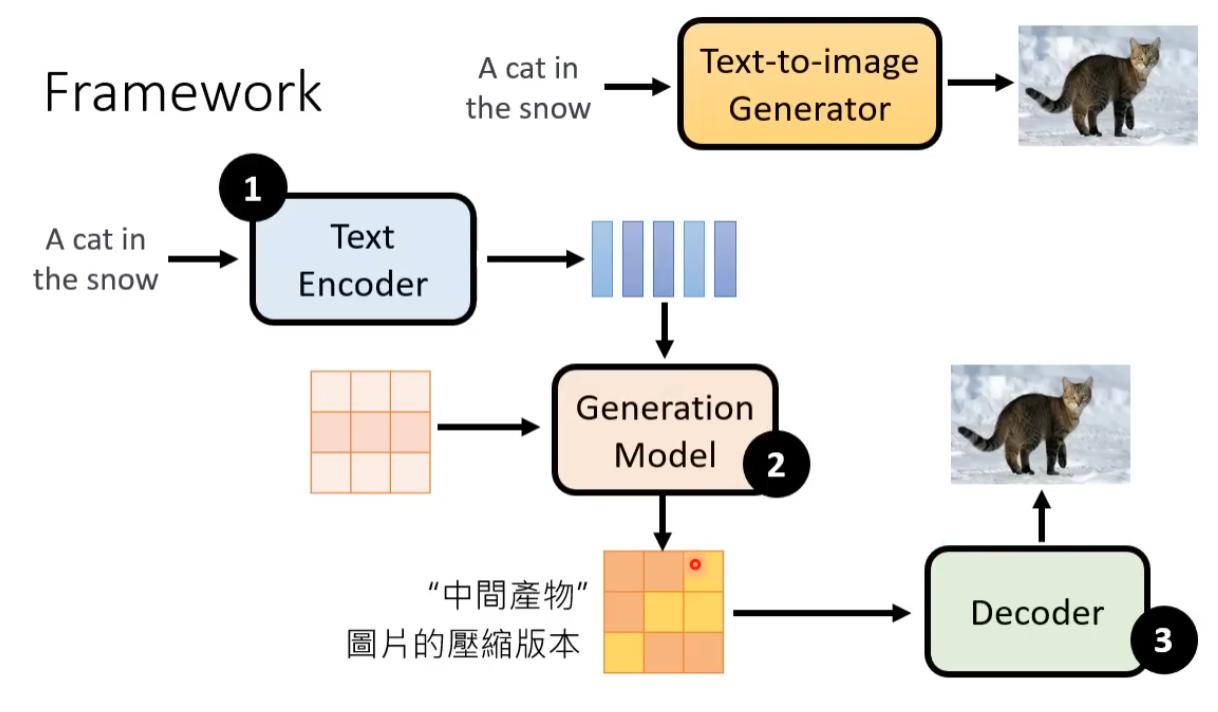 通常三个模型分开进行训练最后进行组合。
通常三个模型分开进行训练最后进行组合。
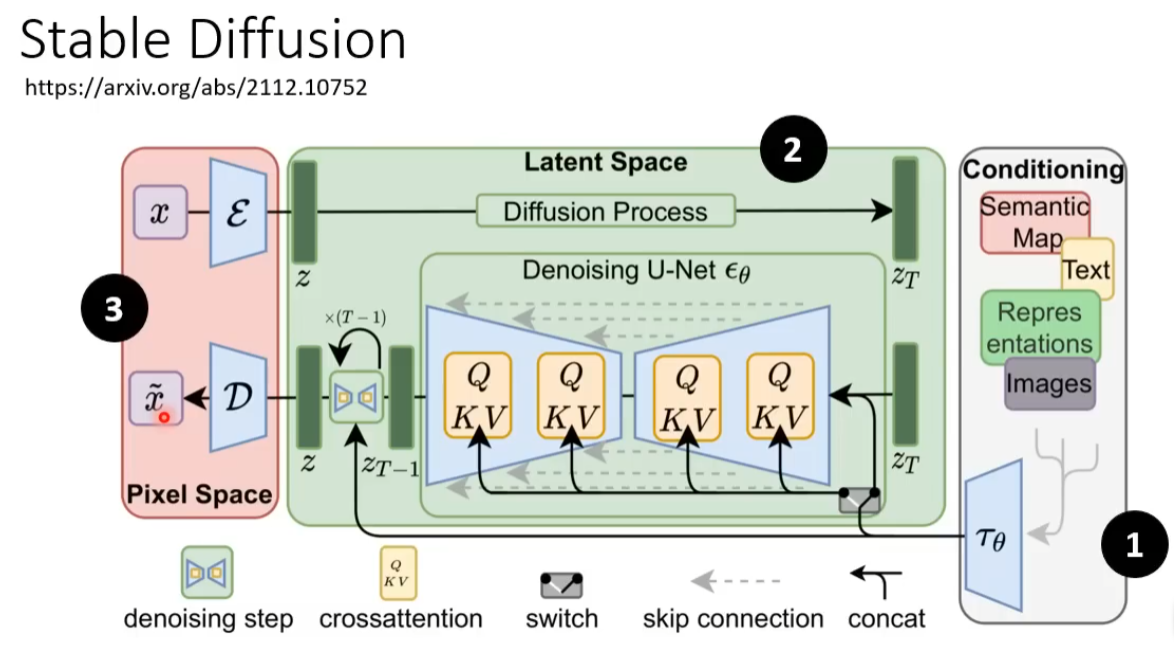
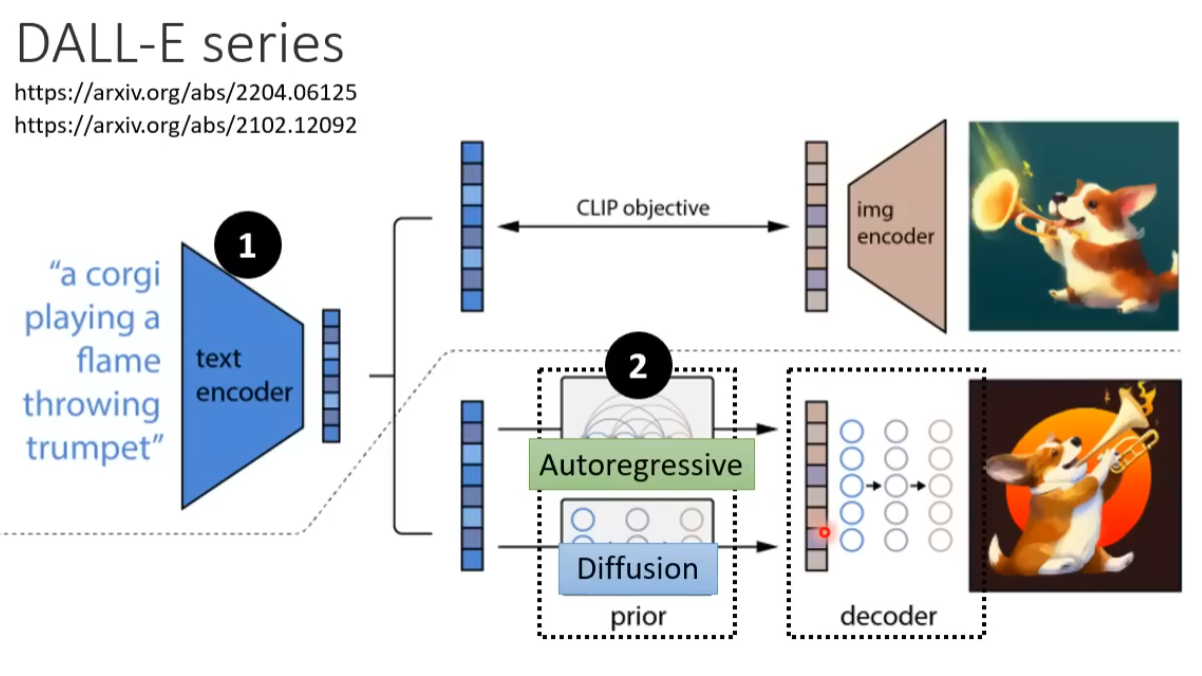
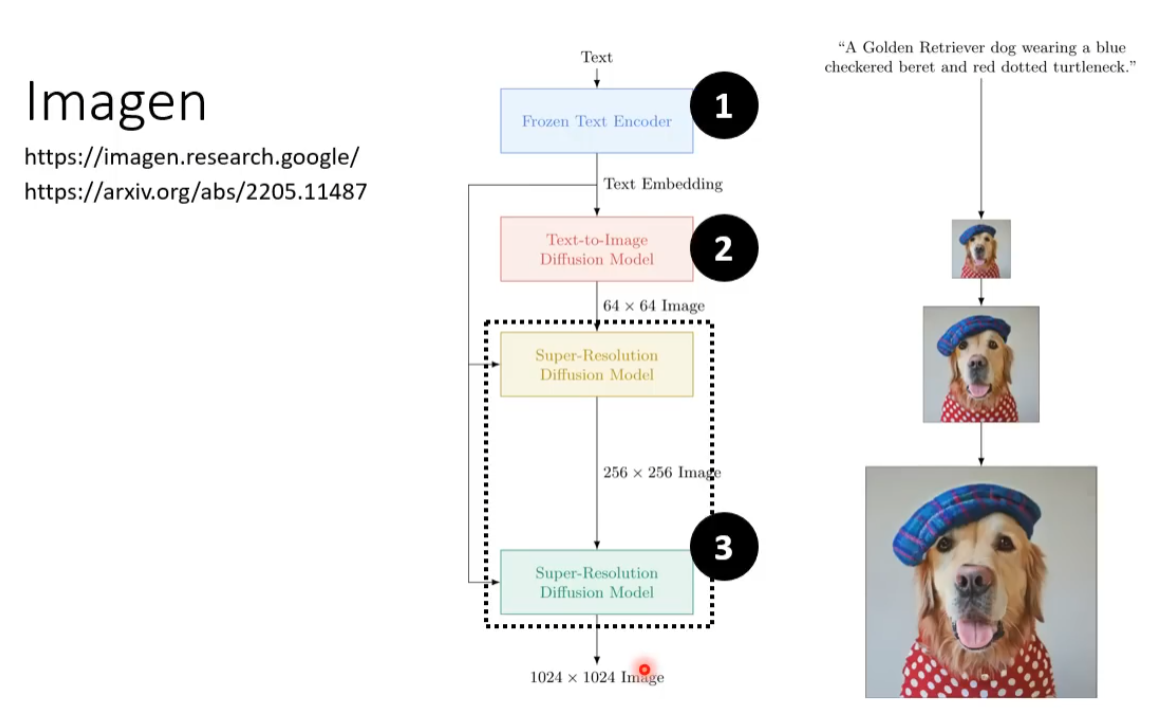
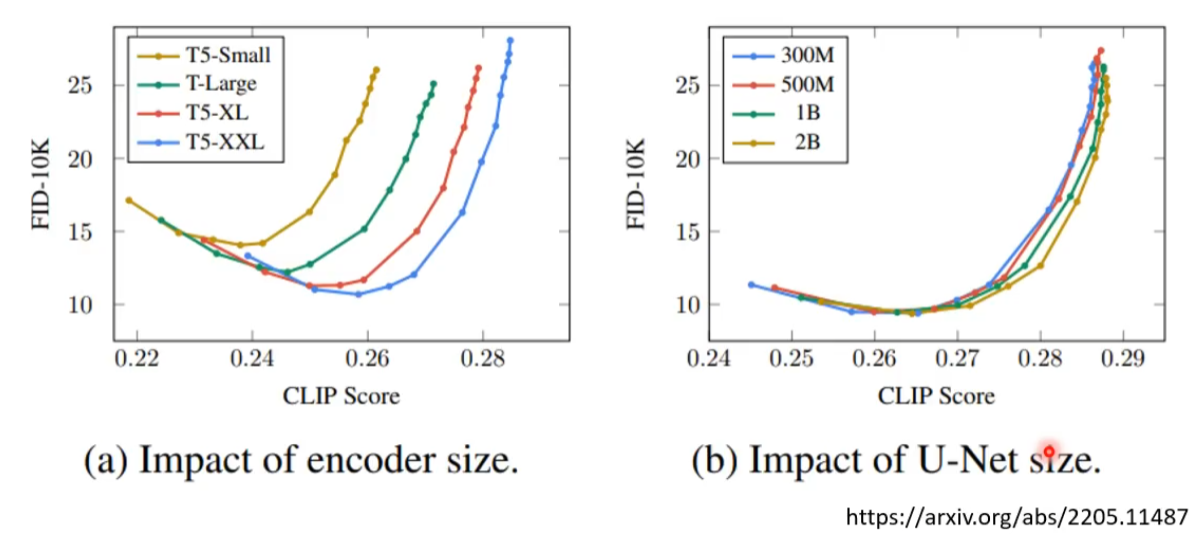
FID值越小,生成的图片越好 CLIP 越大越好 文字编码的大小较影响生成图片的质量。这里的U-Net是指噪音预测模块的大小。 在图b中,增大噪音预测模块的大小对模型性能提示有限。
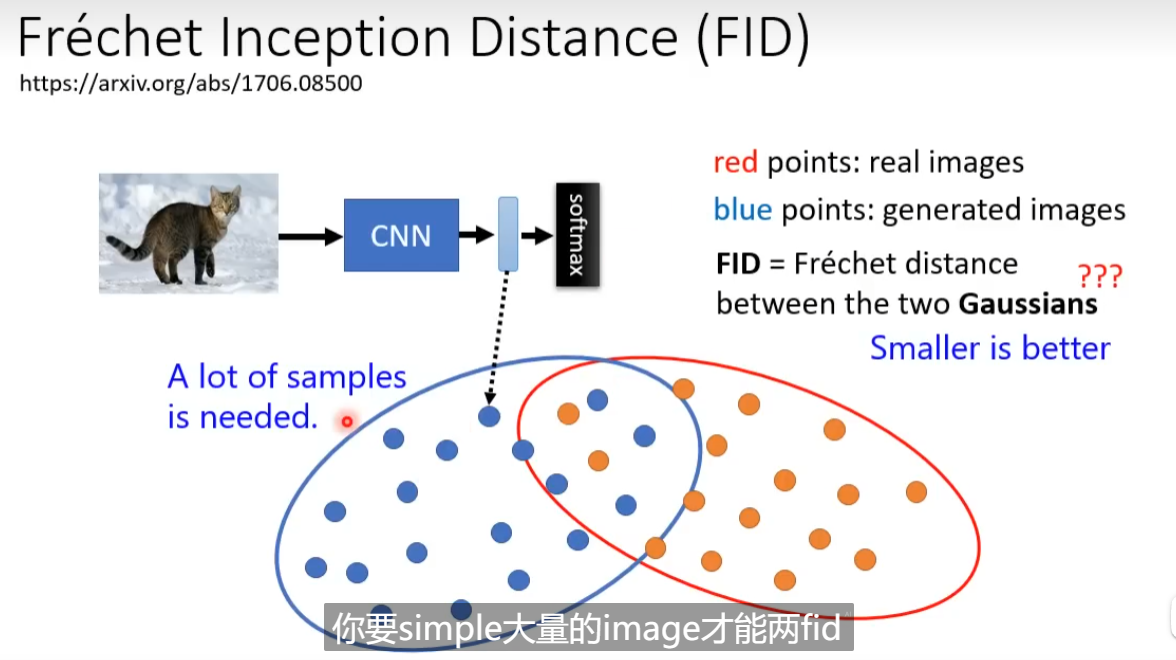 现有一种训练好的图像分类的模型,得到cnn的特征representaion, 两者之间分布的距离表示真实图与生成图之间的相似程度。
现有一种训练好的图像分类的模型,得到cnn的特征representaion, 两者之间分布的距离表示真实图与生成图之间的相似程度。
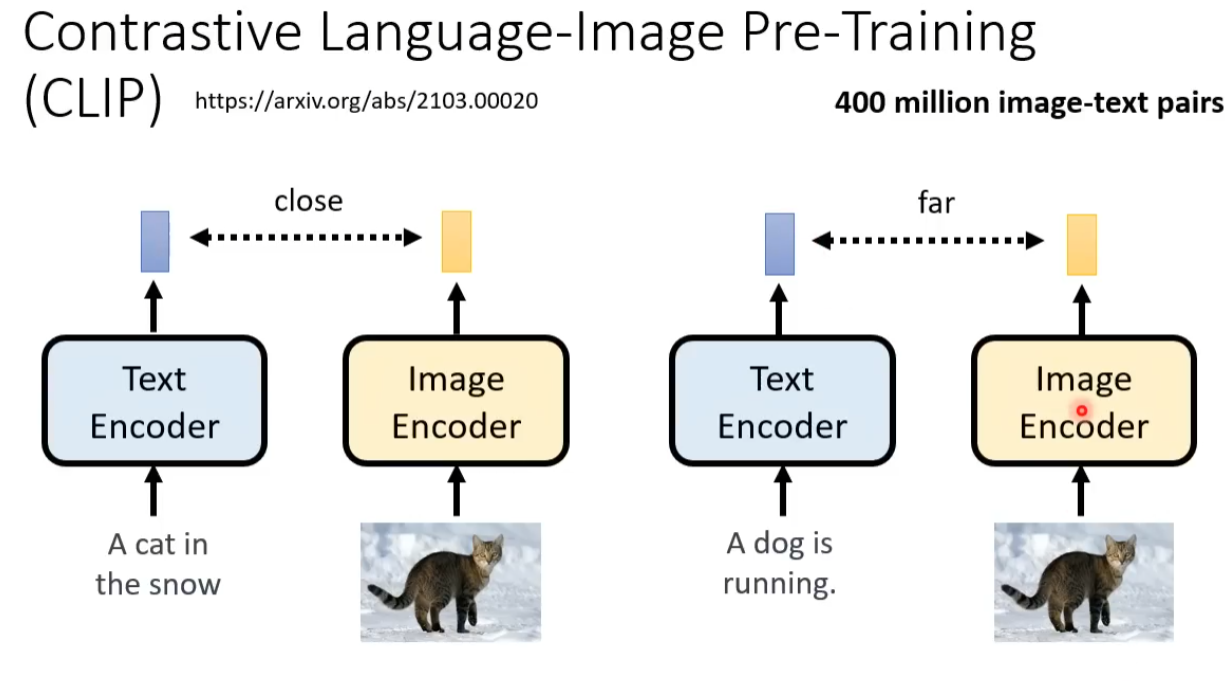
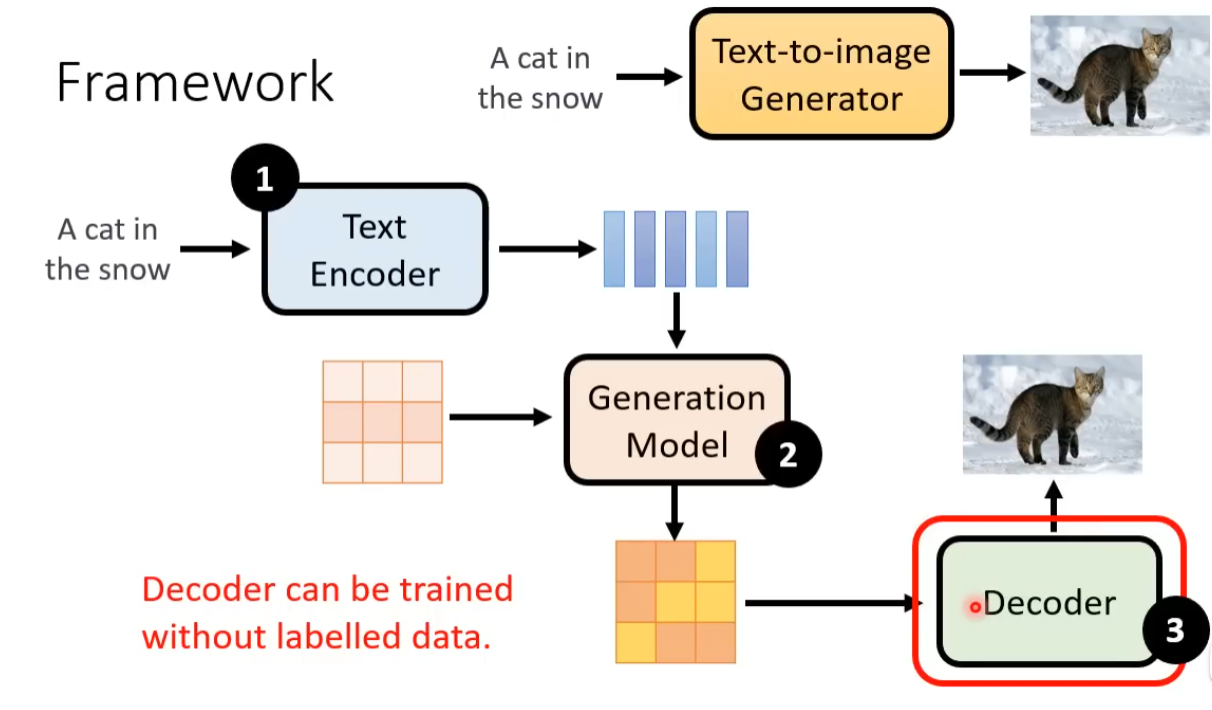
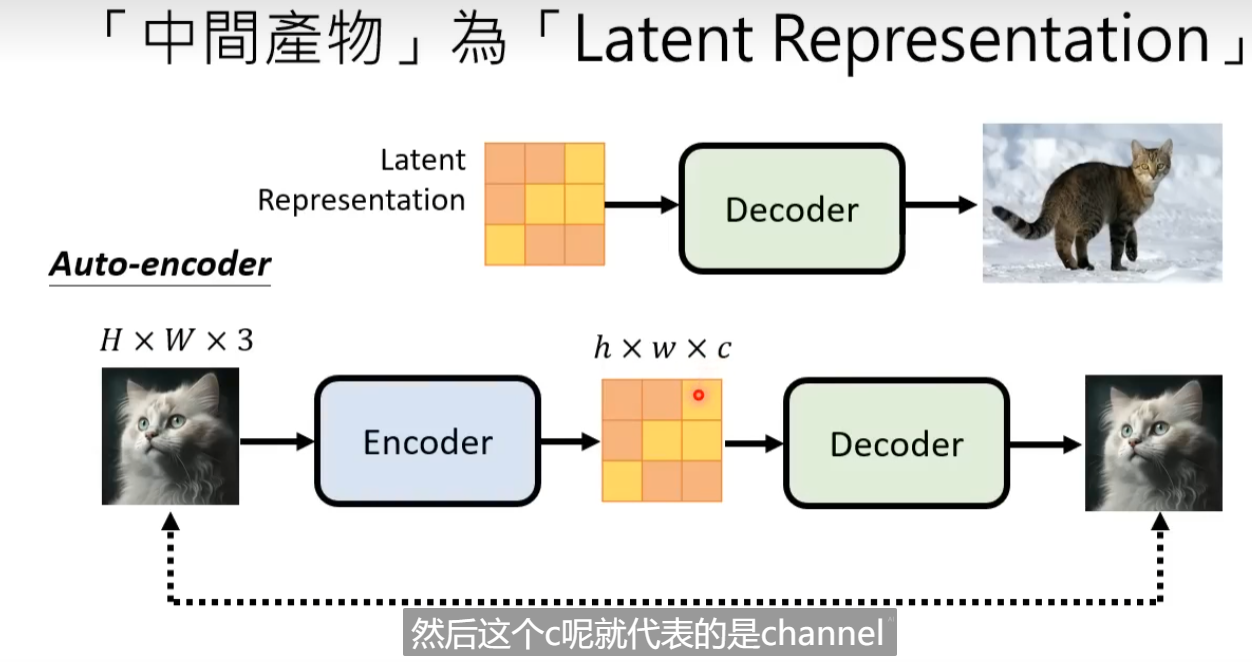
下一节讲数学原理了 心情复杂。。。。。