文章目录
- 两种机器学习类型
- 强化学习定义
- 强化学习交互过程
- 强化学习系统要素
- 历史(History)
- 状态(State)
- 策略(Policy)
- 奖励(Reward)
- 价值函数(Value Function)
- 模型(Model)
- 迷宫例子
- 强化学习智能体分类
- 参考
两种机器学习类型

- 预测
- 根据数据预测所需输出(有监督学习) P ( y ∣ x ) P(y|x) P(y∣x)
- 生成数据实例(无监督学习) P ( x , y ) P(x,y) P(x,y)
- 决策
- 在动态环境中采取行动(强化学习)
- 转变到新的状态
- 获得即时奖励
- 随着时间的推移最大化累计奖励
- 在动态环境中采取行动(强化学习)
预测和决策的区别:行动是否会使得环境发生改变。
强化学习与其他机器学习的区别:
- 无监督,只有奖励信号;
- 反馈延迟;
- 时间序列,不同数据之间存在相关性或依赖关系(Non i.i.d data);
- agents的行动会影响到接受到的数据序列。
在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布就不同。
强化学习中有一个关于数据分布的概念,叫作占用度量(occupancy measure),归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程中,采样到一个具体的状态动作对(state-action pair)的概率分布。
占用度量有一个很重要的性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
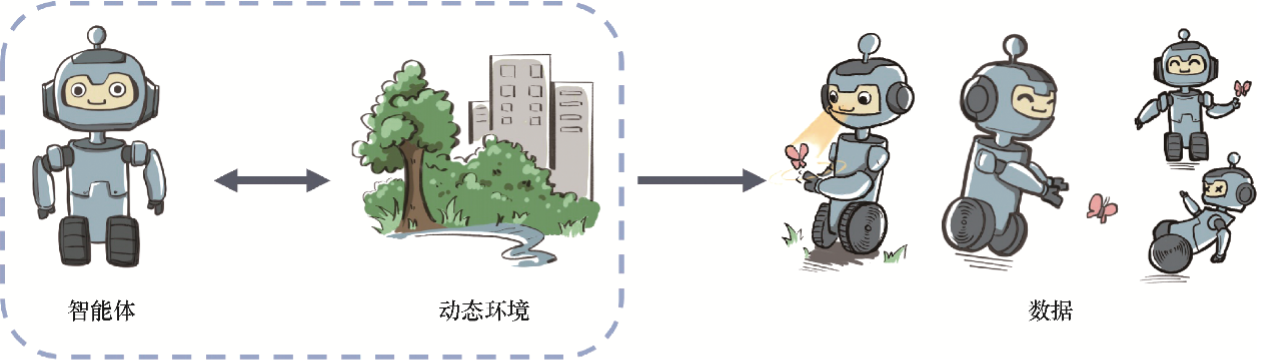
强化学习定义
强化学习用智能体(agent)这个概念来表示做决策的机器。相比于有监督学习中的“模型”,强化学习中的“智能体”强调机器不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境,而不只是给出一些预测信号。

强化学习:通过从交互学习中实现目标的计算方法
- 感知:在某种程度上感知周围环境
- 行动:采取行动来影响状态或者达到目标
- 目标:随着时间的推移,最大化奖励
强化学习交互过程

Agent的每一步 t t t:
- 获取观测 O t O_t Ot
- 获得奖励 R t R_t Rt
- 执行行动 A t A_t At
环境的每一步 t t t:
- 获得行动 A t A_t At
- 给出观测 O t + 1 O_{t+1} Ot+1
- 给出奖励 R t + 1 R_{t+1} Rt+1
在环境这一步 t = t + 1 t=t+1 t=t+1
强化学习系统要素
历史(History)
过去
O
i
,
R
i
,
A
i
O_i,R_i,A_i
Oi,Ri,Ai的序列
H
t
=
O
1
,
R
1
,
A
1
,
.
.
.
,
A
t
−
1
,
O
t
,
R
t
H_t = O_1, R_1, A_1, ..., A_{t−1}, O_t, R_t
Ht=O1,R1,A1,...,At−1,Ot,Rt
- 一直到 t t t时刻所有的可观测变量
- 根据历史决定下一步:(Agent: A i A_i Ai; Env: O i + 1 , R i + 1 O_{i+1},R_{i+1} Oi+1,Ri+1)
状态(State)
用于确定接下来会发生的事情( O , R , A O,R,A O,R,A)
- 是一个关于历史的函数 S t = f ( H t ) S_t = f (H_t) St=f(Ht) f ( H t ) f(H_t) f(Ht)在部分情况下难以直接得到(POMDP)
策略(Policy)
- 智能体的行为,从状态到动作的映射
- 确定性策略(Deterministic policy): a = π ( s ) a=\pi(s) a=π(s)
- 随机策略(Stochastic policy): π ( a ∣ s ) = P [ A t = a ∣ S t = s ] π(a|s) = \mathbb P[A_t = a|S_t = s] π(a∣s)=P[At=a∣St=s]
奖励(Reward)
- 定义强化学习目标的标量,评价状态好坏
价值函数(Value Function)
- 对于未来累计奖励的预测
- 用于评估在给定的策略下,状态的好坏
v π ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] v_\pi(s)=\mathbb{E}_\pi\left[R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+...\mid S_t=s\right] vπ(s)=Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s]
模型(Model)
- 用于预测环境下一步会做什么
- 预测下一步状态 P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] \mathcal{P}_{ss^{\prime}}^a=\mathbb{P}[S_{t+1}=s^{\prime}\mid S_t=s,A_t=a] Pss′a=P[St+1=s′∣St=s,At=a]
- 预测下一步的(即时)奖励 R s a = E [ R t + 1 ∣ S t = s , A t = a ] \mathcal{R}_s^a=\mathbb{E}\left[R_{t+1}\mid S_t=s,A_t=a\right] Rsa=E[Rt+1∣St=s,At=a]
迷宫例子
找到最短路径

- 奖励 R R R: 每一步为-1;
- 动作 A A A: N, E, S, W;
- 状态 S S S: Agent的位置;
- 箭头代表了每一步状态的策略 π ( s ) π(s) π(s);
- 数字代表了每一步的价值 v π ( s ) v_\pi(s) vπ(s)(距离Goal的格数);
强化学习智能体分类
- 基于模型的强化学习
- 策略(和/或)价值函数
- 环境模型
- Example:迷宫、围棋
- 模型无关的强化学习(通常情况下我们没法准确知道环境的模型)
- 策略(和/或)价值函数
- 没有环境模型
- Atari Example
Atari Example

- 规则未知
- 从交互中进行学习(环境是一个黑箱)
- 在操作杆上选择行动并查看分数和像素画面
其他类型
-
基于价值
- 没有策略(隐含)
- 价值函数
-
基于策略
- 策略
- 没有价值函数
-
Actor-Critic
- 策略
- 价值函数

强化学习本质的思维方式
强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断发生改变的。
由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
参考
[1] 伯禹AI
[2] https://www.deepmind.com/learning-resources/introduction-to-reinforcement-learning-with-david-silver
[3] 动手学强化学习