一:安装jdk,并配置环境变量。
在对应的所有的节点上进行安装。
mkdir /opt/app/java
cd /opt/app/java
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%
2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"
tar -zxvf jdk-8u141-linux-x64.tar.gz
mv jdk1.8.0_141/ jdk
cd jdk/bin
./java -version

vim /etc/profile
export JAVA_HOME=/opt/app/java/jdk
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=.:$JAVA_HOME/bin:$JAVA_HOME/lib:$PATH
source /etc/profile
二:安装zookeeper。
https://blog.csdn.net/weixin_43446246/article/details/123327143
三:安装hadoop。
下载安装包
mkdir /opt/app/hadoop
cd /opt/app/hadoop
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.1.2.tar.gz
tar -zxvf hadoop-3.1.2.tar.gz
所有创建文件夹
mkdir /data/src/hadoop-3.1.2/ect/hadoop
修改配置文件
cd /opt/app/hadoop/hadoop-3.1.2/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/opt/app/java/jdk
export HADOOP_CONF=/data/src/hadoop-3.1.2/ect/hadoop

vim core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop-data/hdfs/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
vim hdfs-site.xml
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>node01:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>node02:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>node01:9870</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>node02:9870</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/cluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop-data/jn</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/dfs/dn</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
vim workers
node01
node02
node03
copy到其他节点。
scp -r /opt/app/hadoop/hadoop-3.1.2 root@node02:/opt/app/hadoop/hadoop-3.1.2
scp -r /opt/app/hadoop/hadoop-3.1.2 root@node03:/opt/app/hadoop/hadoop-3.1.2
所有机器全部配置环境变量
vim /etc/profile
#hadoop
export HADOOP_HOME=/opt/app/hadoop/hadoop-3.1.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
四:启动hadoop
- 启动JournalNode 所有机器执行命令。
hdfs --daemon start journalnode

- 格式化NameNode
node01>> hdfs namenode -format
node01>> hdfs --daemon start namenode
node02>> hdfs namenode -bootstrapStandby
node01>> hdfs zkfc -formatZK
node01>> start-dfs.sh
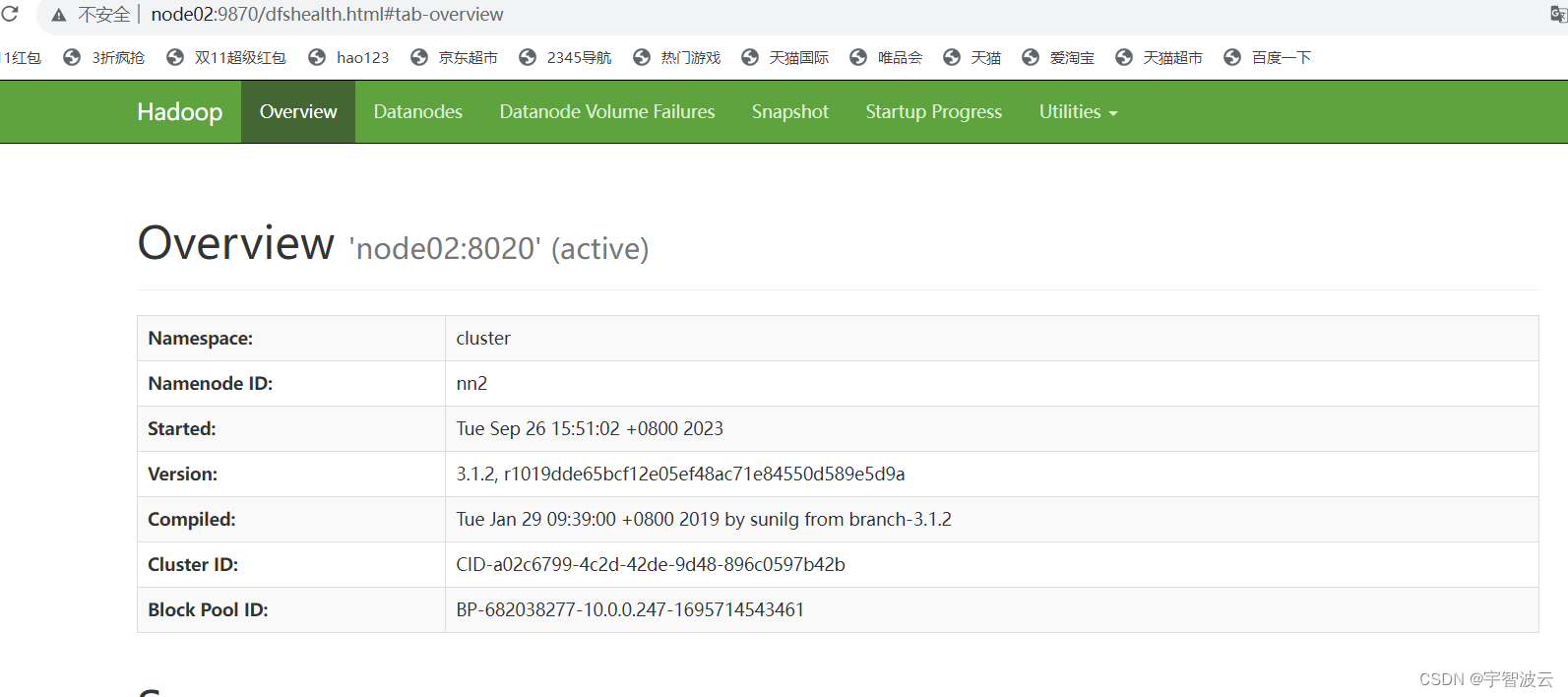
访问地址
http://node01:9870
http://node02:9870