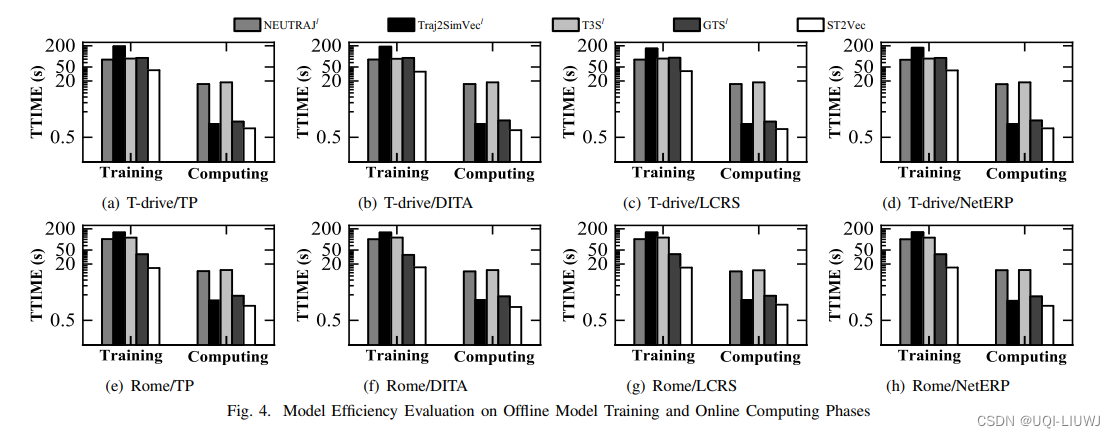
"""
Run YOLOv5 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
Usage - sources:
$ python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
"""
import argparse
import os
import platform
import sys
from pathlib import Path
import torch
FILE = Path( __file__) . resolve( )
ROOT = FILE. parents[ 0 ]
if str ( ROOT) not in sys. path:
sys. path. append( str ( ROOT) )
ROOT = Path( os. path. relpath( ROOT, Path. cwd( ) ) )
from models. common import DetectMultiBackend
from utils. dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils. general import ( LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from utils. plots import Annotator, colors, save_one_box
from utils. torch_utils import select_device, smart_inference_mode
@smart_inference_mode ( )
def run (
weights= ROOT / 'yolov5s.pt' ,
source= ROOT / 'data/images' ,
data= ROOT / 'data/coco128.yaml' ,
imgsz= ( 640 , 640 ) ,
conf_thres= 0.70 ,
iou_thres= 0.50 ,
max_det= 1000 ,
device= '0' ,
view_img= False ,
save_txt= False ,
save_conf= False ,
save_crop= False ,
nosave= False ,
classes= None ,
agnostic_nms= False ,
augment= False ,
visualize= False ,
update= False ,
project= ROOT / 'runs/detect' ,
name= 'exp' ,
exist_ok= False ,
line_thickness= 3 ,
hide_labels= False ,
hide_conf= False ,
half= False ,
dnn= False ,
vid_stride= 1 ,
) :
'''第一部分: 对source进行额外的判断'''
source = str ( source)
save_img = not nosave and not source. endswith( '.txt' )
is_file = Path( source) . suffix[ 1 : ] in ( IMG_FORMATS + VID_FORMATS)
is_url = source. lower( ) . startswith( ( 'rtsp://' , 'rtmp://' , 'http://' , 'https://' ) )
webcam = source. isnumeric( ) or source. endswith( '.streams' ) or ( is_url and not is_file)
screenshot = source. lower( ) . startswith( 'screen' )
if is_url and is_file:
source = check_file( source)
'''第二部分: 新建保存结果的文件夹'''
save_dir = increment_path( Path( project) / name, exist_ok= exist_ok)
( save_dir / 'label' if save_txt else save_dir) . mkdir( parents= True , exist_ok= True )
'''第三部分:加载模型的权重'''
device = select_device( device)
model = DetectMultiBackend( weights, device= device, dnn= dnn, data= data, fp16= half)
stride, names, pt = model. stride, model. names, model. pt
imgsz = check_img_size( imgsz, s= stride)
'''第四部分:加载待预测的图片'''
bs = 1
if webcam:
view_img = check_imshow( warn= True )
dataset = LoadStreams( source, img_size= imgsz, stride= stride, auto= pt, vid_stride= vid_stride)
bs = len ( dataset)
elif screenshot:
dataset = LoadScreenshots( source, img_size= imgsz, stride= stride, auto= pt)
else :
dataset = LoadImages( source, img_size= imgsz, stride= stride, auto= pt, vid_stride= vid_stride)
vid_path, vid_writer = [ None ] * bs, [ None ] * bs
'''第五部分:执行模型的推理,产生预测结果,画出预测框'''
model. warmup( imgsz= ( 1 if pt or model. triton else bs, 3 , * imgsz) )
seen, windows, dt = 0 , [ ] , ( Profile( ) , Profile( ) , Profile( ) )
for path, im, im0s, vid_cap, s in dataset:
with dt[ 0 ] :
im = torch. from_numpy( im) . to( model. device)
im = im. half( ) if model. fp16 else im. float ( )
im /= 255
if len ( im. shape) == 3 :
im = im[ None ]
with dt[ 1 ] :
visualize = increment_path( save_dir / Path( path) . stem, mkdir= True ) if visualize else False
pred = model( im, augment= augment, visualize= visualize)
with dt[ 2 ] :
'''
最终得到[1,5,6,[类别]]
1:是一个batch
5:是将上万个检测框降低到5个检测框
6: 目标的 x_left_up,y_left_up,x_right_down,y_right_down,置信度,目标所属类别()
'''
pred = non_max_suppression( pred, conf_thres, iou_thres, classes, agnostic_nms, max_det= max_det)
'''
遍历pred,遍历一个batch中的每个图片
'''
for i, det in enumerate ( pred) :
seen += 1
if webcam:
p, im0, frame = path[ i] , im0s[ i] . copy( ) , dataset. count
s += f' { i} : ' else :
p, im0, frame = path, im0s. copy( ) , getattr ( dataset, 'frame' , 0 )
p = Path( p)
save_path = str ( save_dir / p. name)
txt_path = str ( save_dir / 'label' / p. stem) + ( '' if dataset. mode == 'image' else f'_ { frame} ' )
s += '%gx%g ' % im. shape[ 2 : ]
gn = torch. tensor( im0. shape) [ [ 1 , 0 , 1 , 0 ] ]
imc = im0. copy( ) if save_crop else im0
annotator = Annotator( im0, line_width= line_thickness, example= str ( names) )
if len ( det) :
det[ : , : 4 ] = scale_boxes( im. shape[ 2 : ] , det[ : , : 4 ] , im0. shape) . round ( )
for c in det[ : , 5 ] . unique( ) :
n = ( det[ : , 5 ] == c) . sum ( )
s += f" { n} { names[ int ( c) ] } { 's' * ( n > 1 ) } , " for * xyxy, conf, cls in reversed ( det) :
if save_txt:
xywh = ( xyxy2xywh( torch. tensor( xyxy) . view( 1 , 4 ) ) / gn) . view( - 1 ) . tolist( )
line = ( cls, * xywh, conf) if save_conf else ( cls, * xywh)
with open ( f' { txt_path} .txt' , 'a' ) as f:
f. write( ( '%g ' * len ( line) ) . rstrip( ) % line + '\n' )
if save_img or save_crop or view_img:
c = int ( cls)
label = None if hide_labels else ( names[ c] if hide_conf else f' { names[ c] } { conf: .2f } ' )
annotator. box_label( xyxy, label, color= colors( c, True ) )
if save_crop:
save_one_box( xyxy, imc, file = save_dir / 'crops' / names[ c] / f' { p. stem} .jpg' , BGR= True )
im0 = annotator. result( )
if view_img:
if platform. system( ) == 'Linux' and p not in windows:
windows. append( p)
cv2. namedWindow( str ( p) , cv2. WINDOW_NORMAL | cv2. WINDOW_KEEPRATIO)
cv2. resizeWindow( str ( p) , im0. shape[ 1 ] , im0. shape[ 0 ] )
cv2. imshow( str ( p) , im0)
cv2. waitKey( 1 )
if save_img:
if dataset. mode == 'image' :
cv2. imwrite( save_path, im0)
else :
if vid_path[ i] != save_path:
vid_path[ i] = save_path
if isinstance ( vid_writer[ i] , cv2. VideoWriter) :
vid_writer[ i] . release( )
if vid_cap:
fps = vid_cap. get( cv2. CAP_PROP_FPS)
w = int ( vid_cap. get( cv2. CAP_PROP_FRAME_WIDTH) )
h = int ( vid_cap. get( cv2. CAP_PROP_FRAME_HEIGHT) )
else :
fps, w, h = 30 , im0. shape[ 1 ] , im0. shape[ 0 ]
save_path = str ( Path( save_path) . with_suffix( '.mp4' ) )
vid_writer[ i] = cv2. VideoWriter( save_path, cv2. VideoWriter_fourcc( * 'mp4v' ) , fps, ( w, h) )
vid_writer[ i] . write( im0)
'''第六部分:打印输出信息'''
LOGGER. info( f" { s} { '' if len ( det) else '(no detections), ' } { dt[ 1 ] . dt * 1E3 : .1f } ms" )
t = tuple ( x. t / seen * 1E3 for x in dt)
LOGGER. info( f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape { ( 1 , 3 , * imgsz) } ' % t)
if save_txt or save_img:
s = f"\n { len ( list ( save_dir. glob( 'label/*.txt' ) ) ) } label saved to { save_dir / 'label' } " if save_txt else ''
LOGGER. info( f"Results saved to { colorstr( 'bold' , save_dir) } { s} " )
if update:
strip_optimizer( weights[ 0 ] )
def parse_opt ( ) :
parser = argparse. ArgumentParser( )
parser. add_argument( '--weights' , nargs= '+' , type = str , default= ROOT / 'yolov5s.pt' , help = 'model path or triton URL' )
parser. add_argument( '--source' , type = str , default= ROOT / 'data/images' , help = 'file/dir/URL/glob/screen/0(webcam)' )
parser. add_argument( '--data' , type = str , default= ROOT / 'data/coco128.yaml' , help = '(optional) dataset.yaml path' )
parser. add_argument( '--imgsz' , '--img' , '--img-size' , nargs= '+' , type = int , default= [ 640 ] , help = 'inference size h,w' )
parser. add_argument( '--conf-thres' , type = float , default= 0.60 , help = 'confidence threshold' )
parser. add_argument( '--iou-thres' , type = float , default= 0.55 , help = 'NMS IoU threshold' )
parser. add_argument( '--max-det' , type = int , default= 1000 , help = 'maximum detections per image' )
parser. add_argument( '--device' , default= '' , help = 'cuda device, i.e. 0 or 0,1,2,3 or cpu' )
parser. add_argument( '--view-img' , action= 'store_true' , help = 'show results' )
parser. add_argument( '--save-txt' , action= 'store_true' , help = 'save results to *.txt' )
parser. add_argument( '--save-conf' , action= 'store_true' , help = 'save confidences in --save-txt label' )
parser. add_argument( '--save-crop' , action= 'store_true' , help = 'save cropped prediction boxes' )
parser. add_argument( '--nosave' , action= 'store_true' , help = 'do not save images/videos' )
parser. add_argument( '--classes' , nargs= '+' , type = int , help = 'filter by class: --classes 0, or --classes 0 2 3' )
parser. add_argument( '--agnostic-nms' , action= 'store_true' , help = 'class-agnostic NMS' )
parser. add_argument( '--augment' , action= 'store_true' , help = 'augmented inference' )
parser. add_argument( '--visualize' , action= 'store_true' , help = 'visualize features' )
parser. add_argument( '--update' , action= 'store_true' , help = 'update all models' )
parser. add_argument( '--project' , default= ROOT / 'runs/detect' , help = 'save results to project/name' )
parser. add_argument( '--name' , default= 'exp' , help = 'save results to project/name' )
parser. add_argument( '--exist-ok' , action= 'store_true' , help = 'existing project/name ok, do not increment' )
parser. add_argument( '--line-thickness' , default= 3 , type = int , help = 'bounding box thickness (pixels)' )
parser. add_argument( '--hide-labels' , default= False , action= 'store_true' , help = 'hide label' )
parser. add_argument( '--hide-conf' , default= False , action= 'store_true' , help = 'hide confidences' )
parser. add_argument( '--half' , action= 'store_true' , help = 'use FP16 half-precision inference' )
parser. add_argument( '--dnn' , action= 'store_true' , help = 'use OpenCV DNN for ONNX inference' )
parser. add_argument( '--vid-stride' , type = int , default= 1 , help = 'video frame-rate stride' )
opt = parser. parse_args( )
opt. imgsz *= 2 if len ( opt. imgsz) == 1 else 1
print_args( vars ( opt) )
return opt
def main ( opt) :
check_requirements( ROOT / 'requirements.txt' , exclude= ( 'tensorboard' , 'thop' ) )
run( ** vars ( opt) )
if __name__ == '__main__' :
opt = parse_opt( )
main( opt)