HDFS里面的几个组件,分别有哪些功能和作用?
- Namenode:主角色,负责和客户端进行沟通.
- Datanode:从角色,负责存储数据
- Secondary namenode:秘书,服务器数据的收集,将信息传递给namenode
- 注:Namenode宕机时集群会通过选举机制(standby)重新选取新Namenode,Secondary namenode自始至终都无法替代Namenode
HDFS是Hadoop生态下的分布式文件系统,基于Linux本地文件系统上的文件系统。HDFS的工作流程如下:
HDFS客户端向NameNode发送请求,获取文件或目录的元数据信息。
NameNode返回元数据信息给客户端。
客户端根据元数据信息在本地文件中查找数据块。
数据块被分成多个数据块块,每个数据块块都被复制到不同的机器上。
当客户端需要读取数据时,NameNode会返回数据块块的地址给客户端。
HDFS数据写入

(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回DataNode节点。
(5)客户端通过FSDataOutputStream模块请求第一个节点上传数据,第一个节点收到请求会继续调用第二个节点,然后第二个节点调用点三个节点,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS数据读取
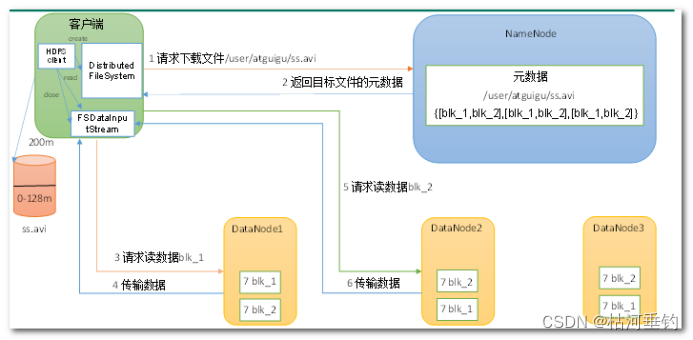
(1)客户端通过DistributedFileSystem(分布式文件系统)向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。













![[Qt]QListView 重绘实例之一:背景重绘](https://img-blog.csdnimg.cn/4778002354934de48f1fdc1baea411c1.png#pic_center)