目录
1. Mysql批量Kill删除processlist
1.1查看进程、拼接、导出、执行
1.2常见错误解决方案
2.关于时区
3.内存占用优化
记录一下生产过程中的一些场景和命令使用方法,不定期进行更新
1. Mysql批量Kill删除processlist
1.1查看进程、拼接、导出、执行
show PROCESSLIST
查询出相关id
SELECT concat('KILL ',id,';') FROM information_schema.processlist WHERE user='znyg' and info like "%select round(sum%";
导出数据保存在txt
当然可以直接导出
SELECT concat('KILL ',id,';') FROM information_schema.processlist WHERE user='znyg' and info like "%select round(sum%" INTO OUTFILE 'G:/temp/student.txt';
在mysql中执行
mysql>source kill_thread_id.txt1.2常见错误解决方案
错误代码: 1290 The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
出现错误提示原因是权限问题
通过show variables like ‘%secure%’;查看 secure-file-priv 当前的值是什么
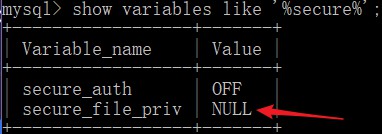
发现secure_file_priv的值为NULL, 导出的数据必须是这个值的指定路径才可以导出,默认是NULL就代表禁止导出
通过mysql的配置文件my.ini可以修改其值。在my.ini文件中添加如下
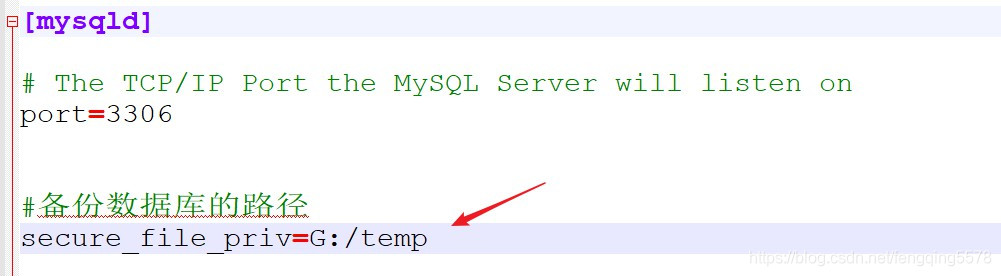
重启mysql服务,执行show variables like ‘%secure%’;
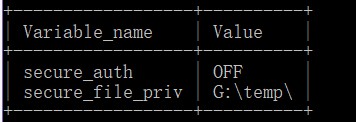
接下来就可以导出表数据到G:\temp目录的文件中了
SELECT * FROM student INTO OUTFILE ‘G:/tem/student.txt’;2.关于时区
程序时间与数据库时间相差13小时或14小时,甚至相差20几个小时
在进行数据库开发的时候,和时间打交道就会涉及到时区,一个日期时间字段从
应用层 → 数据库客户端 → 数据库服务端
传递过程中会跟以下几个时区打交道:
- JVM 时区(默认取操作系统时区,见后文)
- 数据库客户端设置的时区参数(
serverTimezone),数据库会话的时区 - 数据库服务端的时区(默认取操作系统时区,见后文)
- 操作系统时区
要想在时区问题少踩坑(比如存在库里面的时间多了几个小时)可以这样做:
- 数据库服务端的时区参数
time_zone设置一个明确的值,比如+8:00。这个不是必须的,但是建议设置。
数据库客户端通过serverTimezone参数设置自己的时区,这一步至关重要,它应该程序打印出的时区,mysql的时区保持一致
System.out.println("==================="+TimeZone.getDefault());
我遇到的这个问题场景如下:serverTimezone 写成了大写 serverTimeZone
jdbc:mysql://192.168.32.132:33080/demo_2021?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
mysql时区显示如下:
| show variables like ‘%time_zone%’; | |
| system_time_zone | CST |
| time_zone | SYSTEM |
这时显示的时间:别怀疑,这特喵的还是没发生的时间,serverTimezone就这个参数写错
| 操作系统 | mysql |
| [root@d-sn-003 ~]# date 2021年 03月 19日 星期五 13:58:33 CST | select now(); 2021-03-20 02:59:38 |

记录下,容器MySQL挂载时区相关,两者都是修改时区相关,一个是和操作系统保存同步,一个是直接指定
environment:
MYSQL_ROOT_PASSWORD: 12345678
TZ: Asia/Shanghai
volumes:
- /etc/localtime:/etc/localtime3.内存占用优化
问题情况:
1.某日发现公司线上系统的Mysql某个实例的从库长时间内存占用达到60%如下图
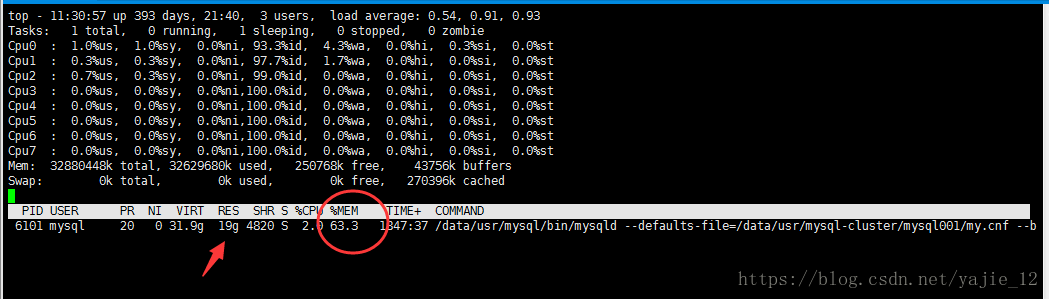
2.于是开始按照以下步骤排查:
(1).查看mysql里的线程,观察是否有长期运行或阻塞的sql:
show full processlist
经查看,没有发现相关线程,可排除该原因
(2).疑似mysql连接使用完成后没有真正释放内存,查看mysql内存,缓存的相关配置,使用如
show global variables like ‘%sort_buffer_size%’;
查看相关的配置项,结果列表汇总如下
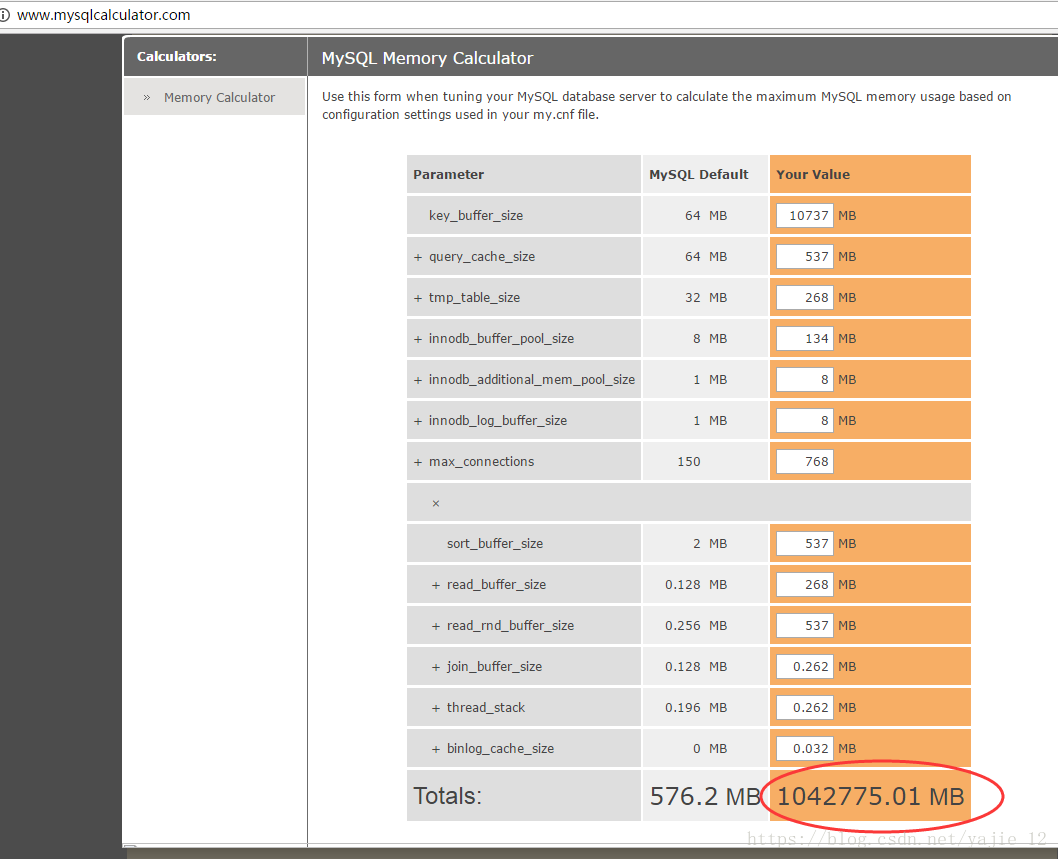
( 注:上图为mysql使用内存计算器,具体地址为http://www.mysqlcalculator.com/ )
其中左列为mysql默认配置,右列为当前数据库的配置,可见预期内存使用最大值足足达到了1T,不符合当前系统负载量,说明当前配置不合理,需要进行调整
(3).参数情况
key_buffer_size = 32M //key_buffer_size指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。只对MyISAM表起作用。即使你不使用MyISAM表,但是内部的临时磁盘表是MyISAM表,也要使用该值。由于我的数据库引擎为innodb,大部分表均为innodb,此处取默认值一半32M。
query_cache_size = 64M //查询缓存大小,当打开时候,执行查询语句会进行缓存,读写都会带来额外的内存消耗,下次再次查询若命中该缓存会立刻返回结果。默认改选项为关闭,打开则需要调整参数项query_cache_type=ON。此处采用默认值64M。
tmp_table_size = 64M //范围设置为64-256M最佳,当需要做类似group by操作生成的临时表大小,提高联接查询速度的效果,调整该值直到created_tmp_disk_tables / created_tmp_tables * 100% <= 25%,处于这样一个状态之下,效果较好,如果网站大部分为静态内容,可设置为64M,如果为动态页面,则设置为100M以上,不宜过大,导致内存不足I/O堵塞。此处我们设置为64M。
innodb_buffer_pool_size = 8196M //这个参数主要作用是缓存innodb表的索引,数据,插入数据时的缓冲。专用mysql服务器设置的大小: 操作系统内存的70%-80%最佳。由于我们的服务器还部署有其他应用,估此处设置为8G。此外,这个参数是非动态的,要修改这个值,需要重启mysqld服务。设置的过大,会导致system的swap空间被占用,导致操作系统变慢,从而减低sql查询的效率。
innodb_additional_mem_pool_size = 16M //用来存放Innodb的内部目录,这个值不用分配太大,系统可以自动调。不用设置太高。通常比较大数据设置16M够用了,如果表比较多,可以适当的增大。如果这个值自动增加,会在error log有中显示的。此处我们设置为16M。
innodb_log_buffer_size = 8M //InnoDB的写操作,将数据写入到内存中的日志缓存中,由于InnoDB在事务提交前,并不将改变的日志写入到磁盘中,因此在大事务中,可以减轻磁盘I/O的压力。通常情况下,如果不是写入大量的超大二进制数据(a lot of huge blobs),4MB-8MB已经足够了。此处我们设置为8M。
max_connections = 800 //最大连接数,根据同时在线人数设置一个比较综合的数字,最大不超过16384。此处我们根据系统使用量综合评估,设置为800。
sort_buffer_size = 2M //是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。官方文档推荐范围为256KB~2MB,这里我们设置为2M。
read_buffer_size = 2M //(数据文件存储顺序)是MySQL读入缓冲区的大小,将对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区,read_buffer_size变量控制这一缓冲区的大小,如果对表的顺序扫描非常频繁,并你认为频繁扫描进行的太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能,read_buffer_size变量控制这一提高表的顺序扫描的效率 数据文件顺序。此处我们设置得比默认值大一点,为2M。
read_rnd_buffer_size = 250K //是MySQL的随机读缓冲区大小,当按任意顺序读取行时(列如按照排序顺序)将分配一个随机读取缓冲区,进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要大量数据可适当的调整该值,但MySQL会为每个客户连接分配该缓冲区所以尽量适当设置该值,以免内存开销过大。表的随机的顺序缓冲 提高读取的效率。此处设置为跟默认值相似,250KB。
join_buffer_size = 250K //多表参与join操作时的分配缓存,适当分配,降低内存消耗,此处我们设置为250KB。
thread_stack = 256K //每个连接线程被创建时,MySQL给它分配的内存大小。当MySQL创建一个新的连接线程时,需要给它分配一定大小的内存堆栈空间,以便存放客户端的请求的Query及自身的各种状态和处理信息。Thread Cache 命中率:Thread_Cache_Hit = (Connections – Threads_created) / Connections * 100%;命中率处于90%才算正常配置,当出现“mysql-debug: Thread stack overrun”的错误提示的时候需要增加该值。此处我们配置为256K。
binlog_cache_size = 250K // 为每个session 分配的内存,在事务过程中用来存储二进制日志的缓存。作用是提高记录bin-log的效率。没有什么大事务,dml也不是很频繁的情况下可以设置小一点,如果事务大而且多,dml操作也频繁,则可以适当的调大一点。前者建议是1048576 –1M;后者建议是: 2097152 – 4194304 即 2–4M。此处我们根据系统实际,配置为250KB。
调整后各项性能参数如下图,且经过图表计算,实例使用的内存将稳定在12G左右,符合当前系统负载情况

之后重启Mysql实例,发现内存占用量回落,并且长时间内没有再次发生占用过高情况,优化成功。
总结:
具体涉及到内存分配,缓存的参数及其具体作用在此不一一赘述,后续可自行查阅相关资料,只有多次根据实际观测结果调优,才能得到符合当前业务系统运行的最佳配置。