Mysql
- 数据库基础知识
- 为什么要使用数据库
- 数据保存在内存
- 数据保存在文件
- 数据保存在数据库
- 什么是SQL?
- 什么是MySQL?
- 数据库三大范式是什么
- mysql有关权限的表都有哪几个
- MySQL的binlog有几种录入格式?分别有什么区别?
- 数据类型
- mysql有哪些数据类型
- 引擎
- MySQL存储引擎MyISAM与InnoDB区别
- MyISAM索引与InnoDB索引的区别?
- InnoDB引擎的4大特性
- 存储引擎选择
- 索引
- 什么是索引?
- 索引有哪些优缺点?
- 索引使用场景(重点)
- 索引有哪几种类型?
- 索引的数据结构(b树,hash)
- 索引的基本原理
- 索引算法有哪些?
- 索引设计的原则?
- 创建索引的原则(重中之重)
- 第一种方式:在执行CREATE TABLE时创建索引
- 第二种方式:使用ALTER TABLE命令去增加索引
- 第三种方式:使用CREATE INDEX命令创建
- 创建索引时需要注意什么?
- 使用索引查询一定能提高查询的性能吗?为什么
- 百万级别或以上的数据如何删除
- 前缀索引
- 什么是最左前缀原则?什么是最左匹配原则
- B树和B+树的区别
- 使用B树的好处
- 使用B+树的好处
- Hash索引和B+树所有有什么区别或者说优劣呢?
- 数据库为什么使用B+树而不是B树
- B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据
- 什么是聚簇索引?何时使用聚簇索引与非聚簇索引
- 非聚簇索引一定会回表查询吗?
- 联合索引是什么?为什么需要注意联合索引中的顺序?
- 事务
- 什么是数据库事务?
- 事物的四大特性(ACID)介绍一下? 什么是脏读?幻读?不可重复读?
- 什么是脏读?幻读?不可重复读?
- 什么是事务的隔离级别?MySQL的默认隔离级别是什么?
- 锁
- 对MySQL的锁了解吗
- 隔离级别与锁的关系
- 按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
- 从锁的类别上分MySQL都有哪些锁呢? 像上面那样子进行锁定岂不是有点阻碍并发效率了
- MySQL中InnoDB引擎的行锁是怎么实现的?
- InnoDB存储引擎的锁的算法有三种
- 什么是死锁?怎么解决?
- 数据库的乐观锁和悲观锁是什么?怎么实现的?
- 视图
- 为什么要使用视图?什么是视图?
- 视图有哪些特点?
- 视图的使用场景有哪些?
- 视图的优点
- 视图的缺点
- 什么是游标?
- 存储过程与函数
- 什么是存储过程?有哪些优缺点?
- 触发器
- 什么是触发器?触发器的使用场景有哪些?
- MySQL中都有哪些触发器?
- 常用SQL语句
- SQL语句主要分为哪几类 超键、候选键、主键、外键分别是什么?
- 超键、候选键、主键、外键分别是什么?
- SQL约束有哪几种?
- 六种关联查询
- 1. 交叉连接(CROSS JOIN)
- 2. 内连接(INNER JOIN)
- 3. 外连接(LEFT JOIN/RIGHT JOIN)
- 4. 联合查询(UNION与UNION ALL)
- 全连接(FULL JOIN)
- 表连接面试题
- 什么是子查询
- 子查询的三种情况
- mysql中in和exists区别
- varchar与char的区别
- varchar(50)中50的涵义
- int(20)中20的涵义
- mysql为什么这么设计
- mysql中int(10)和char(10)以及varchar(10)的区别
- FLOAT和DOUBLE的区别是什么?
- drop、delete与truncate的区别 三者都表示删除,但是三者有一些差别:
- UNION与UNIONALL的区别?
- SQL优化
- 如何定位及优化SQL语句的性能问题? 创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因?
- SQL的生命周期?
- 大表数据查询,怎么优化
- 超大分页怎么处理?
- mysql分页
- 慢查询日志
- 关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?慢查询都怎么优化过?
- 为什么要尽量设定一个主键?
- 主键使用自增ID还是UUID?
- 字段为什么要求定义为not null?
- 如果要存储用户的密码散列,应该使用什么字段进行存储?
- 优化查询过程中的数据访问
- 优化长难的查询语句
- 优化特定类型的查询语句
- 优化关联查询
- 优化子查询
- 优化LIMIT分页
- 优化UNION查询
- 优化WHERE子句
- 数据库优化
- 为什么要优化
- 数据库结构优化
- MySQL数据库cpu飙升到500%的话他怎么处理?
- 大表怎么优化?某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么 做的?分表分库了有什么问题?有用到中间 件么?他们的原理知道么?
- 1. 限定数据的范围:
- 2. 读/写分离:
- 3. 缓存:
- 4. 垂直分区
- 4. 垂直分表
- 适用场景
- 缺点
- 水平分区:
- 水平分表
- 适用场景
- 水平切分的缺点
- 分库分表后面临的问题
- MySQL的复制原理以及流程
- 主从复制的作用
- MySQL主从复制解决的问题
- MySQL主从复制工作原理
- 基本原理流程,3个线程以及之间的关联
- 复制过程
- 第一步:
- 第二步:
- 第三步:
- 读写分离有哪些解决方案?
- 方案一
- 优点:
- 缺点:
- 方案二
- 方案三
- 缺点:
- 备份计划,mysqldump以及xtranbackup的实现原理
- (1)备份计划
- (2)备份恢复时间
- (3)备份恢复失败如何处理
- (4)mysqldump和xtrabackup实现原理
- 数据表损坏的修复方式有哪些?
- MySQL记录binlog的方式主要包括三种模式?每种模式的优缺点是什么?
- ① STATEMENT模式(SBR)
- Statement level(默认) 优点:
- 缺点:
- ② ROW模式(RBR)
- 优点:
- 缺点:
- ③ MIXED模式(MBR)
- 优缺点
- MySQL锁
- 乐观锁
- 悲观锁
- 共享锁(读锁)
- 排它锁(写锁)
- 表级锁
- 行级锁
- MySQL InnoDB中,乐观锁、悲观锁、共享锁、排它锁、行锁、表锁、死锁概念的理解
- 存储引擎查看
- 乐观锁
- 举例
- 悲观锁
- 共享锁
- 排它锁
- 行锁
- 表锁
- 死锁
- 解除正在死锁的状态有两种方法:
- 第一种:
- 1.查询是否锁表
- 2.查询进程
- 3.杀死进程id(就是上面命令的id列)
- 第二种:
- 1:查看当前的事务
- 2:查看当前锁定的事务
- 3:查看当前等锁的事务
- 4:杀死进程
- 产生死锁的四个必要条件:
- 有助于最大限度地降低死锁的方法:
- 分布式事务的原理2阶段提交,同步异步阻塞非阻塞;
- 数据库事务隔离级别,MySQL默认的隔离级别
- Spring如何实现事务
- Spring 事物四种实现方式:
- spring事务管理(详解和实例)
- 1 初步理解
- 2 核心接口
- 2.1 事务管理器
- 2.1.1 JDBC事务
- 2.1.2 Hibernate事务
- 2.1.3 Java持久化API事务(JPA)
- 2.1.4 Java原生API事务
- 2.2 基本事务属性的定义
- 2.2.1 传播行为
- (1)PROPAGATION_REQUIRED
- (2)PROPAGATION_SUPPORTS
- (3)PROPAGATION_MANDATORY
- (4)PROPAGATION_REQUIRES_NEW
- (5)PROPAGATION_NOT_SUPPORTED
- (6)PROPAGATION_NEVER
- (7)PROPAGATION_NESTED
- 2.2.2 隔离级别
- (1)并发事务引起的问题
- (2)隔离级别
- 2.2.3 只读
- 2.2.4 事务超时
- 2.2.5 回滚规则
- 2.3 事务状态
- 3 编程式事务
- 3.1 编程式和声明式事务的区别
- 3.2 如何实现编程式事务?
- 3.2.1 使用TransactionTemplate采用TransactionTemplate和采用其他Spring模板,如JdbcTempalte和HibernateTemplate是一样的方法。它使用回调方法,把应用程序从处理取得和释放资源中解脱出来。如同其他模板,TransactionTemplate是线程安全的。代码片段:
- 3.2.2 使用PlatformTransactionManager
- 4 声明式事务
- 4.1 配置方式
- (1)每个Bean都有一个代理
- (2)所有Bean共享一个代理基类
- (3)使用拦截器
- (4)使用tx标签配置的拦截器
- (5)全注解
- 4.2 一个声明式事务的实例
- Spring事务管理及几种简单的实现
- 1.编程式事务管理实现:
- 2.基于TransactionProxyFactoryBean的声明式事务管理
- 3.基于AspectJ的XML声明式事务管理
- 4.基于注解的声明式事务管理
- JDBC如何实现事务
- 嵌套事务实现
- 场景1:
- 场景2:
- 场景3:
- 场景4:
- 场景5:
- 场景6:
- Spring事务管理--(二)嵌套事物详解
- 一、前言
- 二、spring嵌套事物
- 1、展示项目代码--简单测springboot项目
- 2、外部起事物,内部起事物,内外都无Try Catch
- 3、外部起事物,内部起事物,外部有Try Catch
- 4、外部起事物,内部起事物,内部有Try Catch
- 5、外部起事物,内部起事物,内外有Try Catch
- 三、嵌套事物总结
- 四、正确的嵌套事物实例
- 分布式事务实现;
- 分布式事务与解决方案
- 前言
- 产生原因
- 数据库分库分表:
- 应用SOA化:
- 应用场景
- 支付、转账:
- 在线下单:
- 电商场景:流量充值业务
- 数据库事务
- 事务类型:
- 隔离级别及引发现象:(略谈)
- Spring事务传播行为:(略谈)
- 事务种类:
- 如何保证强一致性
- 本地事务(mysql 之 InnoDB):
- 分布式事务:
- 实现分布式事务解决方案
- 基于XA协议的两阶段提交(2PC)
- 补偿事务(TCC)
- 本地消息表(MQ 异步确保)
- MQ 事务消息
- Sagas 事务模型
- 其他补偿方式
- 总结
- SQL的整个解析、执行过程原理、SQL行转列;
- mysql行转列、列转行
- 行转列
- 列转行
- 红黑树的实现原理和应用场景;
- MySql的存储引擎的不同
- MySQL存储引擎之Myisam和Innodb总结性梳理
- Mysql优化系列--Innodb引擎下mysql自身配置优化
- Mysql怎么分表,以及分表后如果想按条件分页查询怎么办(如果不是按分表字段来查询的话,几乎效率低下, 无解)
- mysql 数据库 分表后 怎么进行分页查询?Mysql分库分表方案?
- mysql大数据量使用limit分页,随着页码的增大,查询效率越低下。
- 测试实验
- 1. 直接用limit start, count分页语句, 也是我程序中用的方法:
- 2. 对limit分页问题的性能优化方法
- MySQL分表自增ID解决方案
- 理解分布式id生成算法SnowFlake
- 概述
- Talk is cheap, show you the code
- 代码理解
- 负数的二进制表示
- 用位运算计算n个bit能表示的最大数值
- 用mask防止溢出
- 用位运算汇总结果
- 观察
- 扩展
- MySql的主从实时备份同步的配置,以及原理(从库读主库的binlog),读写分离
- Mysql主从同步的实现原理
- MySQL索引背后的数据结构及算法原理
- 摘要
- 数据结构及算法基础
- 索引的本质
- B-Tree和B+Tree
- B-Tree
- B+Tree
- 带有顺序访问指针的B+Tree
- 为什么使用B-Tree(B+Tree)
- 主存存取原理
- 磁盘存取原理
- 局部性原理与磁盘预读
- B-/+Tree索引的性能分析
- MySQL索引实现
- MyISAM索引实现
- InnoDB索引实现
- 索引使用策略及优化
- 示例数据库
- 最左前缀原理与相关优化
- 情况一:全列匹配。
- 情况二:最左前缀匹配。
- 情况三:查询条件用到了索引中列的精确匹配,但是中间某个条件未提供。
- 情况四:查询条件没有指定索引第一列。
- 情况五:匹配某列的前缀字符串。
- 情况六:范围查询。
- 情况七:查询条件中含有函数或表达式。
- 索引选择性与前缀索引
- InnoDB的主键选择与插入优化
- 后记
- mysql的锁--行锁,表锁,乐观锁,悲观锁
- Mysql中的MVCC
- 1. Innodb的事务相关概念
- 2. 行的更新过程
- 2-1. 初始数据行
- 2-2. 事务1更改该行的各字段的值
- 2-3事务2修改该行的值
- 2-4. 事务提交
- 2-5. Insert Undo log
- 3. 事务级别
- 4. MVCC
- 5. 总结
- mysql索引原理之聚簇索引
- 学习笔记_mysql索引原理之B+/-Tree
- 关系型和非关系型数据库区别
- 我的Mysql死锁排查过程(案例分析)
- 死锁起因
- 分析
- 阅读死锁日志
- 死锁形成流程图
- 拓展
- 总结
- MySql优化
- MySQL 对于千万级的大表要怎么优化?
- 产生死锁的必要条件
- 操作系统:死锁的产生、条件、和解锁
- 产生死锁的原因主要是:
- 产生死锁的四个必要条件:
- 死锁的解除与预防
- 死锁排除的方法
数据库基础知识
为什么要使用数据库
数据保存在内存
- 优点:存取速度快
- 缺点:数据不能永久保存
数据保存在文件
- 优点:数据永久保存
- 缺点:
- 1)速度比内存操作慢,频繁的IO操作。
- 2)查询数据不方便
数据保存在数据库
- 1)数据永久保存
- 2)使用SQL语句,查询方便效率高。
- 3)管理数据方便
什么是SQL?
结构化查询语言 (Structured Query Language) 简称SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
什么是MySQL?
MySQL是一个关系型数据库管理系统,由瑞典MySQLAB公司开发,属于Oracle旗下产品。MySQL是最
流行的关系型数据库管理系统之一,在WEB应用方面,MySQL是最好的
RDBMS(RelationalDatabaseManagementSystem,关系数据库管理系统)应用软件之一。在Java企业级
开发中非常常用,因为MySQL是开源免费的,并且方便扩展。
数据库三大范式是什么
- 第一范式:每个列都不可以再拆分。
- 第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
- 第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我 们经常会为了性能而妥协数据库的设计
mysql有关权限的表都有哪几个
MySQL服务器通过权限表来控制用户对数据库的访问,权限表存放在mysql数据库里,由
mysql_install_db脚本初始化。这些权限表分别user,db,table_priv,columns_priv和host。下面分
别介绍一下这些表的结构和内容:
- user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
- db权限表:记录各个帐号在各个数据库上的操作权限。
- table_priv权限表:记录数据表级的操作权限。
- columns_priv权限表:记录数据列级的操作权限。
- host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和 REVOKE语句的影响。
MySQL的binlog有几种录入格式?分别有什么区别?
有三种格式,statement,row和mixed。
- statement模式下,每一条会修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少
了binlog日志量,节约了IO,提高性能。由于sql的执行是有上下文的,因此在保存的时候需要保存
相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。 - row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,
基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如altertable),因此这种模式的 文件保存的信息太多,日志量太大。 - mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行 记录。
数据类型
mysql有哪些数据类型
引擎
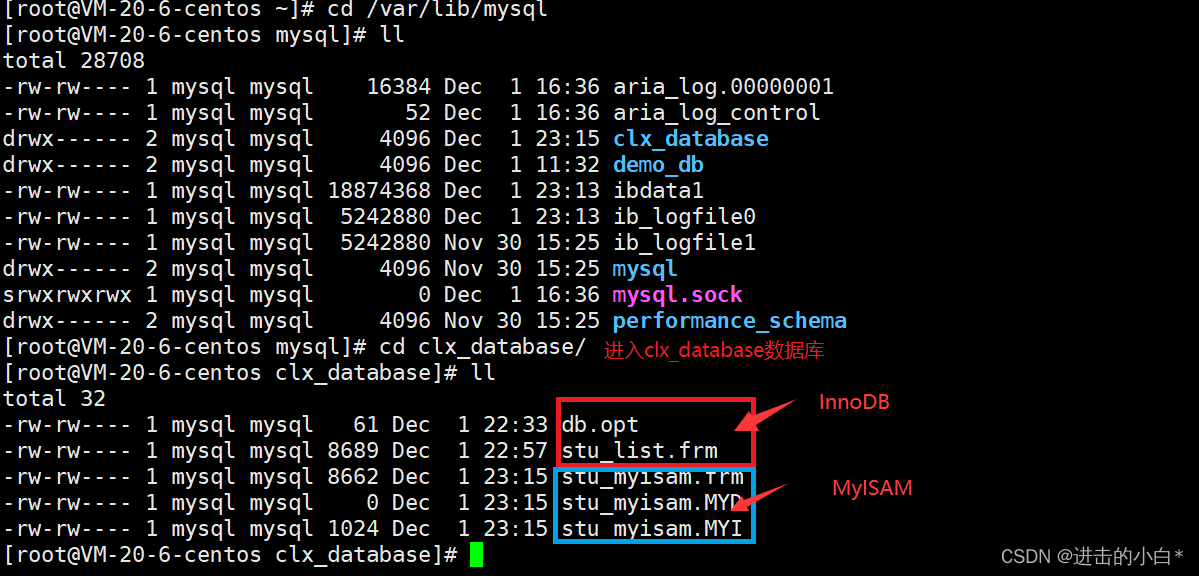
MySQL存储引擎MyISAM与InnoDB区别
存储引擎Storageengine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实
现。
常用的存储引擎有以下:
Innodb引擎: Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。它的
设计的目标就是处理大数据容量的数据库系统。
MyIASM引擎(原本Mysql的默认引擎): 不提供事务的支持,也不支持行级锁和外键。
MEMORY引擎: 所有的数据都在内存中,数据的处理速度快,但是安全性不高。
MyISAM与InnoDB区别
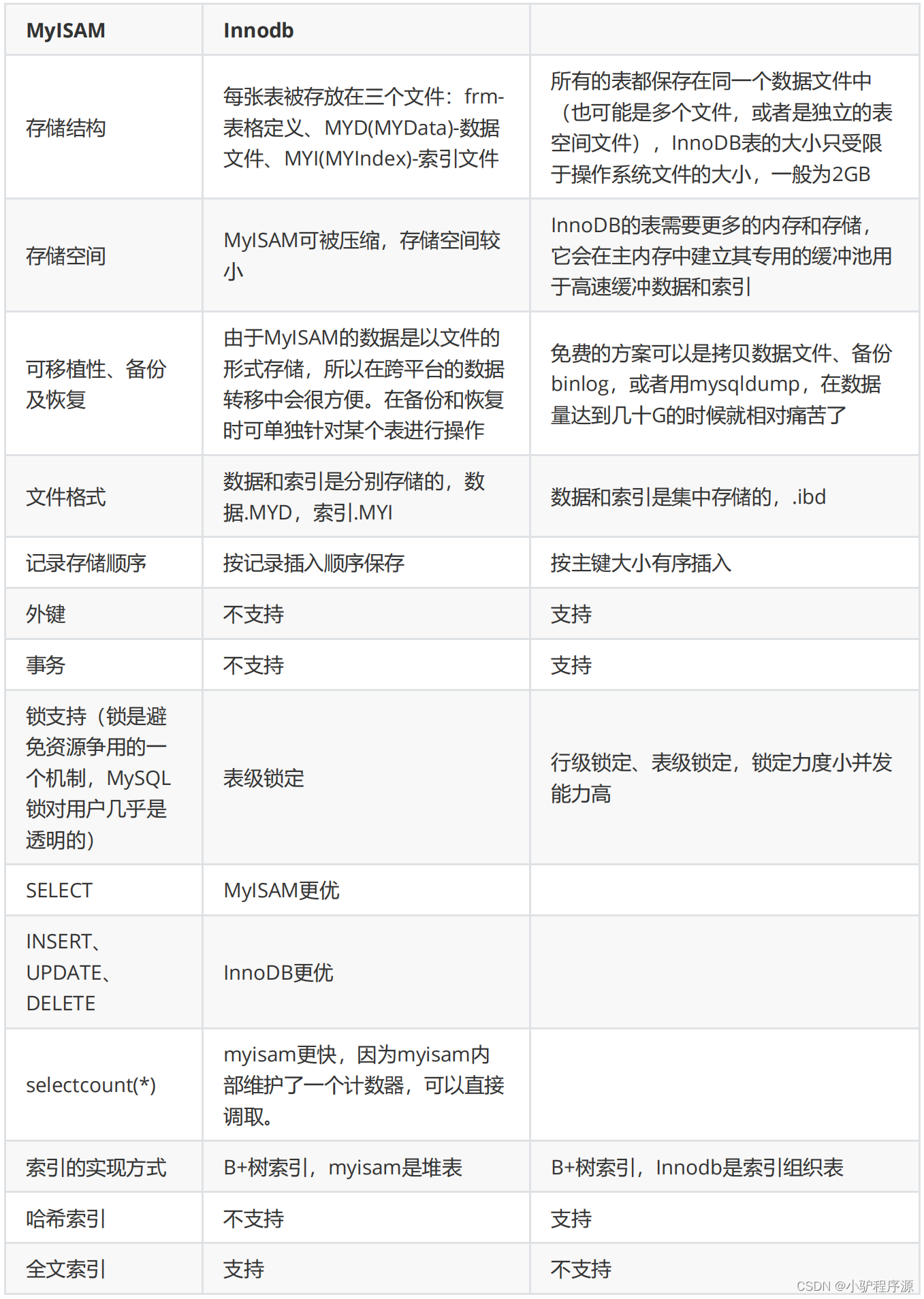
MyISAM索引与InnoDB索引的区别?
- InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
- InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
- MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
- InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会 非常高效。
InnoDB引擎的4大特性
- 插入缓冲(insertbuffer)
- 二次写(doublewrite)
- 自适应哈希索引(ahi)
- 预读(readahead)
存储引擎选择
如果没有特别的需求,使用默认的Innodb即可。
MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,
支持事务和外键。比如OA自动化办公系统。
索引
什么是索引?
- 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
- 索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一 个文件,它是要占据物理空间的。
索引有哪些优缺点?
索引使用场景(重点)

上图中,根据id查询记录,因为id字段仅建立了主键索引,因此此SQL执行可选
的索引只有主键索引,如果有多个,最终会选一个较优的作为检索的依据。
1 增加一个没有建立索引的字段
2 alter table innodb1 add sex char(1);
3 按sex检索时可选的索引为null 4EXPLAINSELECT*frominnodb1wheresex='男';

可以尝试在一个字段未建立索引时,根据该字段查询的效率,然后对该字段建立索引(altertable表名addindex(字段名)),同样的SQL执行的效率,你会发现查询效率 会有明显的提升(数据量越大越明显)。
orderby
当我们使用orderby将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
但是,如果我们对该字段建立索引altertable表名addindex(字段名),那么由于索引本身是有序的,因此直
接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的
索引对应的数据,而不用像上述那取出所有数据进行排序再返回某个范围内的数据。(从磁盘取数据是
最影响性能的)
join
对join语句匹配关系(on)涉及的字段建立索引能够提高效率
索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一
个字段没有建立索引就会做全表扫描),这叫索引覆盖。
因此我们需要尽可能的在select后只写必要的查询字段,以增加索引覆盖的几率。
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
索引有哪几种类型?
主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
创建唯一索引可以通过
ALTER TABLE table_name ADD UNIQUE(column);
创建唯一组合索引可以通过
ALTER TABLE table_name ADD UNIQUE(column1,column2);
普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
创建普通索引可以通过
ALTER TABLE table_name ADD INDEX index_name(column);
创建组合索引可以通过
ALTER TABLE table_name ADD INDEX index_name (column1, column2, column3);
全文索引: 是目前搜索引擎使用的一种关键技术。
创建全文索引可以通过
ALTER TABLE table_name ADD FULL TEXT(column);
索引的数据结构(b树,hash)
索引的数据结构和具体存储引擎的实现有关,在MySQL中使用较多的索引有
Hash索引,B+树索引等,而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引。对于哈希
索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索
引,查询性能快;其余大部分场景,建议选择BTree索引。
1)B树索引mysql通过存储引擎取数据,基本上90%的人用的就是InnoDB了,按照实现方式分,
InnoDB的索引类型目前只有两种:BTREE(B树)索引和HASH索引。B树索引是Mysql数据库中使用频
繁的索引类型,基本所有存储引擎都支持
BTree索引。通常我们说的索引不出意外指的就是(B树)索引(实际是用B+树实现的,因为在查看表索
引时,mysql一律打印BTREE,所以简称为B树索引)
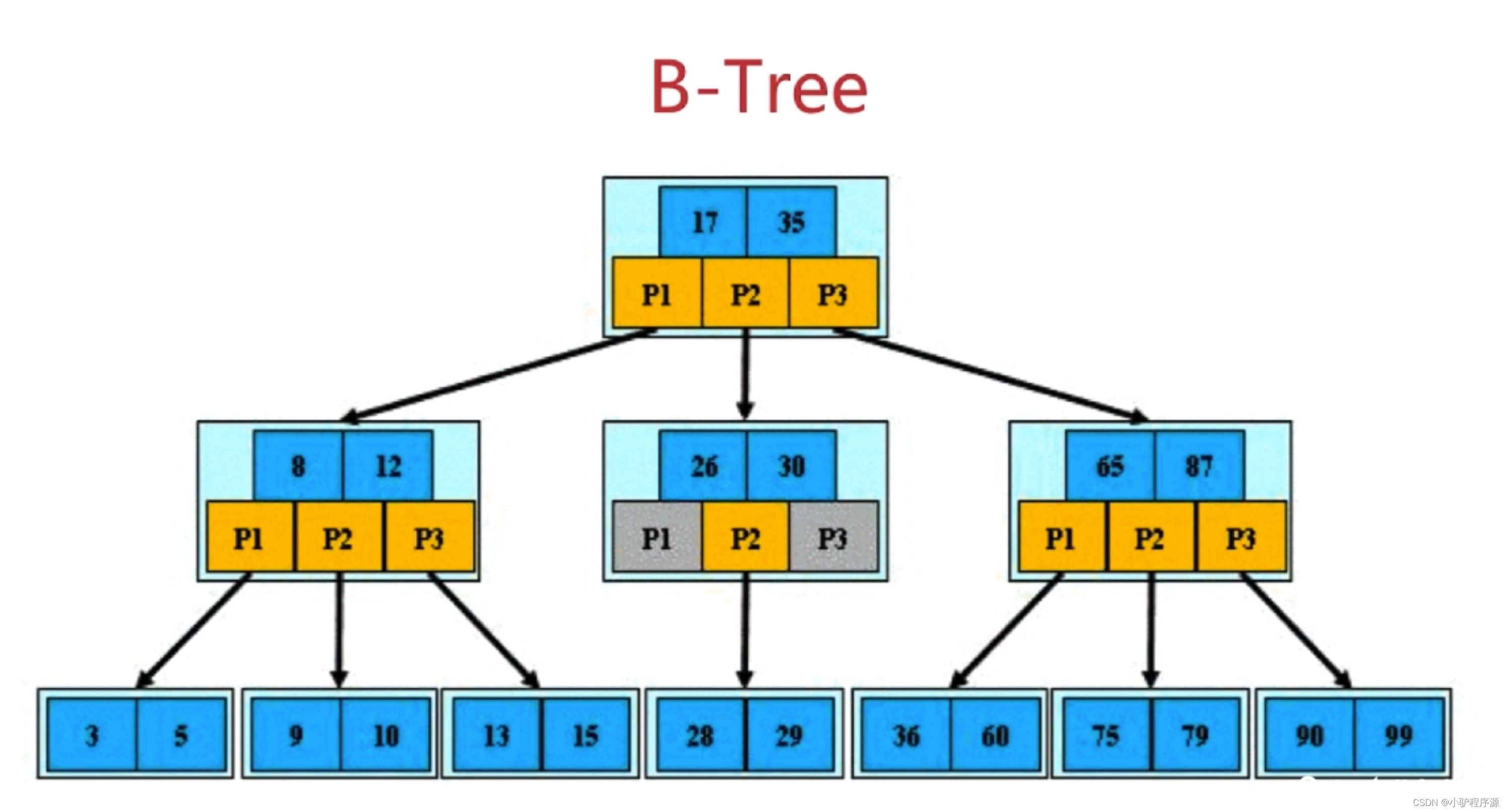
查询方式:
主键索引区:PI(关联保存的时数据的地址)按主键查询,
普通索引区:si(关联的id的地址,然后再到达上面的地址)。所以按主键查询,速度快
B+tree性质:
- 1.)n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
- 2.)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依 关键字的大小自小而大顺序链接。
- 3.)所有的非终端结点可以看成是索引部分,结点中仅含其子树中的大(或小)关键字。
- 4.)B+树中,数据对象的插入和删除仅在叶节点上进行。
- 5.)B+树有2个头指针,一个是树的根节点,一个是小关键码的叶节点。2)哈希索引简要说下,类似于 数据结构中简单实现的HASH表(散列表)一样,当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。当然这只是简略模拟图。
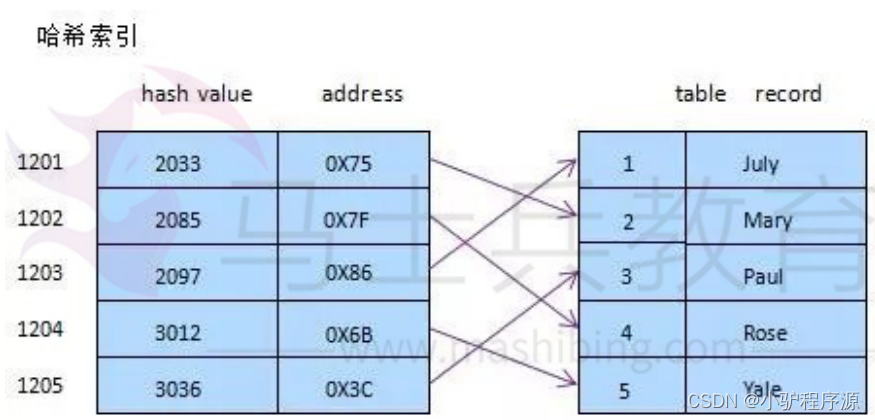
索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理很简单,就是把无序的数据变成有序的查询
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
索引算法有哪些?
索引算法有BTree算法和Hash算法
BTree算法
BTree是常用的mysql数据库索引算法,也是mysql默认的算法。因为它不仅可以被用在=,>,>=,<,<=和
between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的
常量,例如:
1 --只要它的查询条件是一个不以通配符开头的常量
2 select * from user where name like 'jack%';
3 --如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
4 select * from user where name like '%jack';
Hash算法
HashHash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索
引需要从根节点到枝节点,后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
索引设计的原则?
- 1.适合索引的列是出现在where子句中的列,或者连接子句中指定的列
- 2.基数较小的类,索引效果较差,没有必要在此列建立索引
- 3.使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
- 4.不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
创建索引的原则(重中之重)
索引虽好,但也不是无限制的使用,好符合一下几个原则
- 1)左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、
between、like)就停止匹配,比如a=1andb=2andc>3andd=4如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。 - 2)较频繁作为查询条件的字段才去创建索引
- 3)更新频繁字段不适合创建索引
- 4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,多也就三种,区分度实在太低)
- 5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改 原来的索引即可。
- 6)定义有外键的数据列一定要建立索引。
- 7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
- 8)对于定义为text、image和bit的数据类型的列不要建立索引。创建索引的三种方式,删除索引
第一种方式:在执行CREATE TABLE时创建索引
CREATE TABLE user_index2(
id INT auto_increment PRIMARYKEY,
first_name VARCHAR(16),
last_name VARCHAR(16),
id_card VARCHAR(18),
information text,
KEY name(first_name,last_name),
FULL TEXT KEY(information),
UNIQUEKEY(id_card)
);
第二种方式:使用ALTER TABLE命令去增加索引
ALTER TABLE table_name ADD INDEX index_name(column_list);
ALTERTABLE用来创建普通索引、UNIQUE索引或PRIMARYKEY索引。
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分
隔。
索引名index_name可自己命名,缺省时,MySQL将根据第一个索引列赋一个名称。另外,
ALTERTABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
第三种方式:使用CREATE INDEX命令创建
CREATE INDEX index_name ON table_name(column_list);
CREATEINDEX可对表增加普通索引或UNIQUE索引。(但是,不能创建PRIMARYKEY索引)
删除索引
根据索引名删除普通索引、唯一索引、全文索引:altertable表名dropKEY索引名
1 alter table user_index drop KEY name;
2 alter table user_index drop KEY id_card;
3 alter table user_index drop KEY information;
删除主键索引:alter table表名drop primarykey(因为主键只有一个)。这里值得注意的是,如果主键
自增长,那么不能直接执行此操作(自增长依赖于主键索引):
alter table user_index drop primary key;

1 alter table user_index
2 --重新定义字段
3 MODIFY id int,
4 drop PRIMARYKEY
但通常不会删除主键,因为设计主键一定与业务逻辑无关
创建索引时需要注意什么?
- 非空字段:应该指定列为NOTNULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查
询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值 或者一个空串代替空值; - 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()
函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高; - 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大 效率越高。
使用索引查询一定能提高查询的性能吗?为什么
通常,通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
索引需要空间来存储,也需要定期维护,每当有记录在表中增减或索引列被修改时,索引本身也会被修
改。这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5次的磁盘I/O。因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEXRANGESCAN)适用于两种情况:
基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
基于非唯一性索引的检索
百万级别或以上的数据如何删除
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修 改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所
以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数
量是成正比的。
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分
钟左右。 - 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。
前缀索引
语法:index(field(10)),使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
前提:前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相
同。
实操的难度:在于前缀截取的长度。我们可以利用
select count(*)/count(distinctleft(password,prefixLen));
通过从调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
什么是最左前缀原则?什么是最左匹配原则
顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中
使用最频繁的一列放在最左边。
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)
就停止匹配,比如a=1andb=2andc>3andd=4如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建
立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
=和in可以乱序,比如a=1andb=2andc=3建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化
成索引可以识别的形式
B树和B+树的区别
在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树
中,内部节点都是键,没有值,叶子节点同时存放键和值。
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。

使用B树的好处
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热
点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更
快地缩小查找范围。B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需
要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每
一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间
Hash索引和B+树所有有什么区别或者说优劣呢?
首先要知道Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应
的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树。
对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然
后根据查询判断是否需要回表查询数据。
么可以看出他们有以下的不同:
hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查
询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范
围。
hash索引不支持使用索引进行排序,原理同上。
hash索引不支持模糊查询以及多列索引的最左前缀匹配。原理也是因为hash函
数的不可预测。AAAA和AAAAB的索引没有相关性。
hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索
引,覆盖索引等)的时候可以只通过索引完成查询。
hash索引虽然在等值查询上较快,但是不稳定。性能不可预测,当某个键值存在大量重复的时候,发生
hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节
点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。
而不需要使用hash索引。
数据库为什么使用B+树而不是B树
B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本
身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引
查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引
使用,其内部结点比B树小,盘块能容纳的结
点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读
写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,
只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺
序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的
查找路径长度相同,导致每一个关键字的查询效率相当。
B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序
连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁
的,而B树不支持这样的操作。
增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以
有序的链表结构存储,这样可很好提高增删效率
B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据
在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就
是聚簇索引和非聚簇索引。在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键
建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再
次进行回表查询。
什么是聚簇索引?何时使用聚簇索引与非聚簇索引
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过
key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索
引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二
次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再
是行的物理位置,而是主键值
何时使用聚簇索引与非聚簇索引
非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了
索引,那么就不必再进行回表查询
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee
where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
联合索引是什么?为什么需要注意联合索引中的顺序?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要
按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序
为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排
序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对
于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在
建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在
前面。此外可以根据特例的查询或者表结构进行单独的调整。
事务
什么是数据库事务?
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库
从一种一致性状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。
假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小
红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小
红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
事物的四大特性(ACID)介绍一下? 什么是脏读?幻读?不可重复读?
关系性数据库需要遵循ACID规则,具体内容如下:
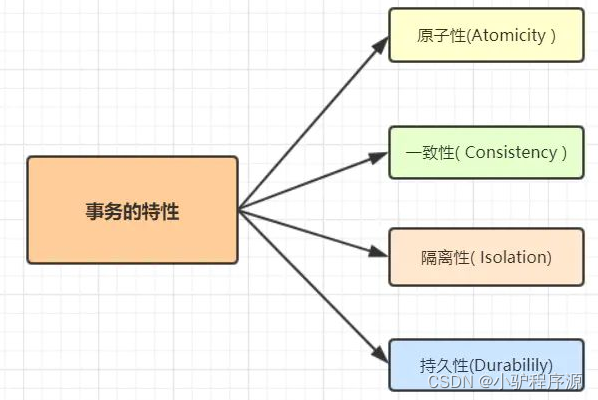
- 原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的
结果是相同的; - 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各
并发事务之间数据库是独立的; - 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该
对其有任何影响。
什么是脏读?幻读?不可重复读?
脏读(Drity Read):
某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):
在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):
在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数
据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据
是它先前所没有的。
什么是事务的隔离级别?MySQL的默认隔离级别是什么?
为了达到事务的四大特性,数据库定义了4种不同的事务隔离级别,由低到高依次为Read
uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、
不可重复读、幻读这几类问题。
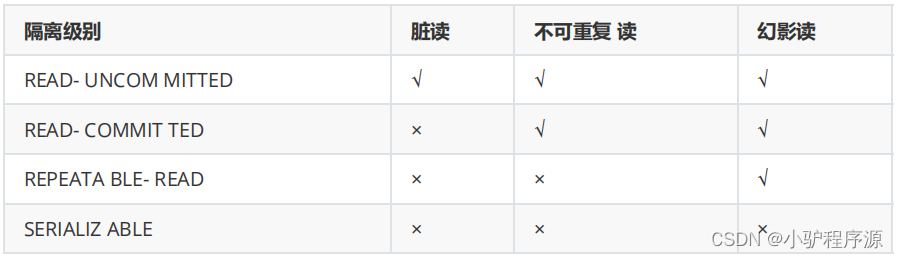
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导 致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读 或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻 读。
这里需要注意的是:Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle默认采用的
READ_COMMITTED隔离级别
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过
保存修改的旧版本信息来支持并发一致性读和回滚等特性。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读
取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读)并不会有
任何性能损失。
InnoDB 存储引擎在 分布式事务 的情况下一般会用到SERIALIZABLE(可串行化)隔离级别。
锁
对MySQL的锁了解吗
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来
保证访问的次序,锁机制就是这样的一个机制。
就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请
到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用。
隔离级别与锁的关系
在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修
改的数据上的排他锁冲突
在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁;
在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须
等待事务执行完毕以后才释放共享锁。
SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完
成。
按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和
页级锁(BDB引擎 )。
MyISAM和InnoDB存储引擎使用的锁:
- MyISAM采用表级锁(table-level locking)。
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
行级锁,表级锁和页级锁对比
行级锁 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减
少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,
并发度也最高。
表级锁 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消
耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表
共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,
并发度最低。
页级锁 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级
冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和
行锁之间,并发度一般
从锁的类别上分MySQL都有哪些锁呢? 像上面那样子进行锁定岂不是有点阻碍并发效率了
从锁的类别上来讲,有共享锁和排他锁。
共享锁: 又叫做读锁。 当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
排他锁: 又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其
他的排他锁,共享锁都相斥。
用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的。 一种是真
正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以。
锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。
他们的加锁开销从大到小,并发能力也是从大到小。
MySQL中InnoDB引擎的行锁是怎么实现的?
答:InnoDB是基于索引来完成行锁 例:
select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id不是索引键那么InnoDB将
完成表锁,并发将无从谈起
InnoDB存储引擎的锁的算法有三种
- Record lock:单个行记录上的锁
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
- Next-key lock:record+gap 锁定一个范围,包含记录本身
相关知识点:
- innodb对于行的查询使用next-key lock
- Next-locking keying为了解决Phantom Problem幻读问题
- 当查询的索引含有唯一属性时,将next-key lock降级为record key
- Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
- 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法
- 1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
- 2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
- 3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
数据库的乐观锁和悲观锁是什么?怎么实现的?
数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏
事务的隔离性和统一性以及数据库的统一性。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并
发控制主要采用的技术手段。
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。在查询完数据的时候就把事务锁
起来,直到提交事务。实现方式:使用数据库中的锁机制乐观锁:假设不会发生并发冲突,只在提交操
作时检查是否违反数据完整性。在修改数据的时候把事务锁起来,通过version的方式来进行锁定。实现
方式:乐一般会使用版本号机制或CAS算法实现。
两种锁的使用场景从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像
乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开
销,加大了系统的整个吞吐量。
但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
视图
为什么要使用视图?什么是视图?
为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。所谓视
图,本质上是一种虚拟表,在物理上是不存在的,其内容与真实的表相似,包含一系列带有名称的列和
行数据。但是,视图并不在数据库中以储存的数据值形式存在。行和列数据来自定义视图的查询所引用
基本表,并且在具体引用视图时动态生成。
视图使开发者只关心感兴趣的某些特定数据和所负责的特定任务,只能看到视图中所定义的数据,而不
是视图所引用表中的数据,从而提高了数据库中数据的安全性
视图有哪些特点?
视图的特点如下:
- 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。
- 视图的建立和删除不影响基本表。
- 对视图内容的更新(添加,删除和修改)直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。视图的操作包括创建视图,查看视图,删除视 图和修改视图。
视图的使用场景有哪些?
视图根本用途:简化sql查询,提高开发效率。如果说还有另外一个用途那就是兼容老的表结构。
下面是视图的常见使用场景:重用SQL语句;
- 简化复杂的SQL操作。在编写查询后,可以方便的重用它而不必知道它的基本查询细节;使用表的 组成部分而不是整个表;
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据
视图的优点
- 查询简单化。视图能简化用户的操作
- 数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护
逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
视图的缺点
- 性能。数据库必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所
定义,那么,即使是视图的一个简单查询,数据库也把它变成一个复杂的结合体,需要花费一定的
时间 - 修改限制。当用户试图修改视图的某些行时,数据库必须把它转化为对基本表的某些行的修改。事
实上,当从视图中插入或者删除时,情况也是这样。对于简单视图来说,这是很方便的,但是,对
于比较复杂的视图,可能是不可修改的这些视图有如下特征:
- 有UNIQUE等集合操作符的视图。
- 有GROUP BY子句的视图。
- 有诸如AVG\SUM\MAX等聚合函数的视图。
- 使用DISTINCT关键字的视图。
- 连接表的视图(其中有些例外)
什么是游标?
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,每个游标区都有一个名字。用户
可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理
存储过程与函数
什么是存储过程?有哪些优缺点?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需要创建一次,以后在该程序
中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
优点
- 1) 存储过程是预编译过的,执行效率高。
- 2) 存储过程的代码直接存放于数据库中,通过存储过程名直接调用,减少网络通讯。
- 3) 安全性高,执行存储过程需要有一定权限的用户。
- 4) 存储过程可以重复使用,减少数据库开发人员的工作量。
缺点
- 1) 调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。
- 2) 移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问 题。
- 3) 重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
- 4) 如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致 数据结构的变化,接着就是系统的相关问题了,
后如果用户想维护该系统可以说是很难很难、而且代价是空前的,维护起来更麻烦。
触发器
什么是触发器?触发器的使用场景有哪些?
触发器是用户定义在关系表上的一类由事件驱动的特殊的存储过程。触发器是指一段代码,当触发某个
事件时,自动执行这些代码。
使用场景
- 可以通过数据库中的相关表实现级联更改。
- 实时监控某张表中的某个字段的更改而需要做出相应的处理。
- 例如可以生成某些业务的编号。
- 注意不要滥用,否则会造成数据库及应用程序的维护困难。
- 大家需要牢记以上基础知识点,重点是理解数据类型CHAR和VARCHAR的差异,表存储引擎 InnoDB和MyISAM的区别。
MySQL中都有哪些触发器?
- Before Insert
- After Insert
- Before Update
- After Update
- Before Delete
- After Delete
常用SQL语句
SQL语句主要分为哪几类 超键、候选键、主键、外键分别是什么?
数据定义语言DDL(Data Ddefinition Language)CREATE,DROP,ALTER 主要为以上操作 即对逻辑
结构等有操作的,其中包括表结构,视图和索引。
数据查询语言DQL(Data Query Language)SELECT这个较为好理解 即查询操作,以select关键字。各种简单查询,连接查询等 都属于DQL。
数据操纵语言DML(Data Manipulation Language)INSERT,UPDATE,DELETE
主要为以上操作 即对数据进行操作的,对应上面所说的查询操作 DQL与DML共同构建了多数初级程序
员常用的增删改查操作。而查询是较为特殊的一种 被划分到DQL中。
数据控制功能DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK
主要为以上操作 即对数据库安全性完整性等有操作的,可以简单的理解为权限控制等
超键、候选键、主键、外键分别是什么?
超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属
性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键:是 小超键,即没有冗余元素的超键。
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。
一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)
外键:在一个表中存在的另一个表的主键称此表的外键。
SQL约束有哪几种?
NOT NULL: 用于控制字段的内容一定不能为空(NULL)。
UNIQUE: 控件字段内容不能重复,一个表允许有多个 Unique 约束。
PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
FOREIGN KEY: 用于预防破坏表之间连接的动作,也能防止非法数据插入外键列,因为它必须是它指向
的那个表中的值之一
CHECK: 用于控制字段的值范围。
六种关联查询
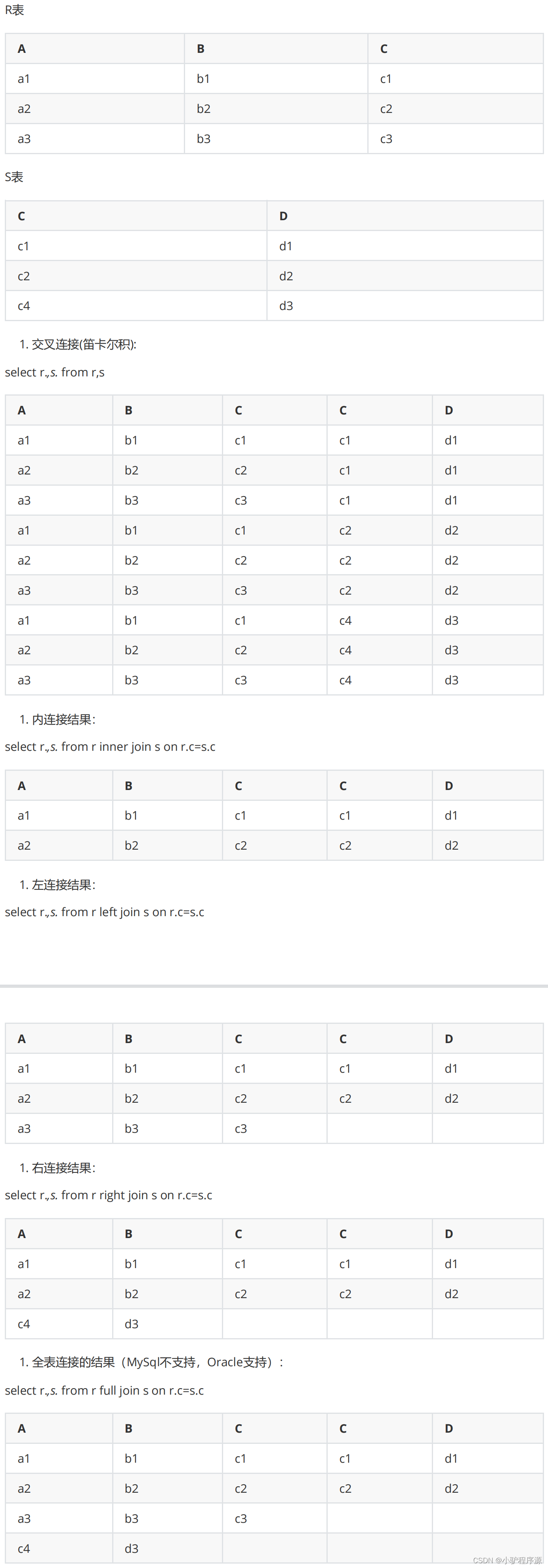
1. 交叉连接(CROSS JOIN)
SELECT * FROM A,B(,C)或者SELECT * FROM A CROSS JOIN B (CROSS JOIN C)#没有任何关联条件,结果是笛卡尔积,结果集会很大,没有意义,很少使用内连接(INNER
JOIN)SELECT * FROM A,B WHERE A.id=B.id或者SELECT * FROM A INNER JOIN B
ON A.id=B.id多表中同时符合某种条件的数据记录的集合,INNER JOIN可以缩写为JOIN
2. 内连接(INNER JOIN)
内连接分为三类
等值连接:ON A.id=B.id 不等值连接:ON A.id > B.id
自连接:SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid
3. 外连接(LEFT JOIN/RIGHT JOIN)
左外连接:LEFT OUTER JOIN, 以左表为主,先查询出左表,按照ON后的关联
条件匹配右表,没有匹配到的用NULL填充,可以简写成LEFT JOIN
右外连接:RIGHT OUTER JOIN, 以右表为主,先查询出右表,按照ON后的关
联条件匹配左表,没有匹配到的用NULL填充,可以简写成RIGHT JOIN
4. 联合查询(UNION与UNION ALL)
SELECT * FROM A
UNION
SELECT * FROM B
UNION ...
就是把多个结果集集中在一起,UNION前的结果为基准,需要注意的是联合查
询的列数要相等,相同的记录行会合并如果使用UNION ALL,不会合并重复的记录行效率 UNION 高于
UNION ALL
全连接(FULL JOIN)
MySQL不支持全连接
可以使用LEFT JOIN 和UNION和RIGHT JOIN联合使用
SELECT * FROM A LEFT JOIN B ON A.id=B.id
UNION
SELECT * FROM A RIGHT JOIN B ON A.id=B.id
表连接面试题
有2张表,1张R、1张S,R表有ABC三列,S表有CD两列,表中各有三条记录。
什么是子查询
- 条件:一条SQL语句的查询结果做为另一条查询语句的条件或查询结果
- 嵌套:多条SQL语句嵌套使用,内部的SQL查询语句称为子查询。
子查询的三种情况
- 子查询是单行单列的情况:结果集是一个值,父查询使用:=、 <、 > 等运算符
1 -- 查询工资最高的员工是谁?
2 select * from employee where salary=(select max(salary) from employee);
- 子查询是多行单列的情况:结果集类似于一个数组,父查询使用:in 运算符
1 -- 查询工资最高的员工是谁?
2 select * from employee where salary=(select max(salary) from employee);
- 子查询是多行多列的情况:结果集类似于一张虚拟表,不能用于where 条件,用于select子句中做
为子表
1 -- 1) 查询出2011年以后入职的员工信息
2 -- 2) 查询所有的部门信息,与上面的虚拟表中的信息比对,找出所有部门ID相等的员工。
3 select * from
dept d, (select * from employee where join_date >'2011-1- 1') e
where
e.dept_id = d.id;
4 -- 使用表连接:
5 select d.*, e.* from
dept d
inner join employee e on d.id = e.dept_id
where e.join_date >'2011-1-1'
mysql中in和exists区别
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop
循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不
准确的。这个是要区分环境的。
- 如果查询的两个表大小相当,那么用in和exists差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
- not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而
not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
varchar与char的区别
char的特点
char表示定长字符串,长度是固定的;如果插入数据的长度小于char的固定长度时,则用空格填充;
因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多
余的空间,是空间换时间的做法;
对于char来说, 多能存放的字符个数为255,和编码无关 varchar的特点
varchar表示可变长字符串,长度是可变的;
插入的数据是多长,就按照多长来存储;
varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间
换空间的做法;
对于varchar来说, 多能存放的字符个数为65532 总之,结合性能角度(char更快)和节省磁盘空间角
度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。
varchar(50)中50的涵义
多存放50个字符,varchar(50)和(200)存储hello所占空间一样,但后者在排
序时会消耗更多内存,因为order by col采用fixed_length计算col长度
(memory引擎也一样)。在早期 MySQL 版本中, 50 代表字节数,现在代表字符数。
int(20)中20的涵义
是指显示字符的长度。20表示 大显示宽度为20,但仍占4字节存储,存储范围不变;
不影响内部存储,只是影响带 zerofill 定义的 int 时,前面补多少个 0,易于报表展示
mysql为什么这么设计
对大多数应用没有意义,只是规定一些工具用来显示字符的个数;int(1)和 int(20)存储和计算均一样;
mysql中int(10)和char(10)以及varchar(10)的区别
- int(10)的10表示显示的数据的长度,不是存储数据的大小; chart(10)和varchar(10)的10表示存储
数据的大小,即表示存储多少个字符。
int(10) 10位的数据长度 9999999999,占32个字节,int型4位 char(10) 10位固定字符串,不足补空格
多10个字符
varchar(10) 10位可变字符串,不足补空格 多10个字符
- char(10)表示存储定长的10个字符,不足10个就用空格补齐,占用更多的存储空间
- varchar(10)表示存储10个变长的字符,存储多少个就是多少个,空格也按一个字符存储,这一点
是和char(10)的空格不同的,char(10)的空格表示占位不算一个字符
FLOAT和DOUBLE的区别是什么?
FLOAT类型数据可以存储至多8位十进制数,并在内存中占4字节。
DOUBLE类型数据可以存储至多18位十进制数,并在内存中占8字节。
drop、delete与truncate的区别 三者都表示删除,但是三者有一些差别:
| DELETE | Truncate | Drop | - |
|---|---|---|---|
| 类型 | 属于DML | 属于DDL | 属于DDL |
| 回滚 | 可回滚 | 不可回滚 | 不可回滚 |
| 删除内容 | 表结构还在,删除表的全部或者一部分数据行 | 表结构还在,删除表中的所有数据 | 从数据库中删除表,所有的数据 |
| 行,索引和权限也会被删除 | |||
| 删除速度 | 删除速度慢,需要逐行删除 | 删除速度快 | 删除速度快 |
UNION与UNIONALL的区别?
如果使用UNION ALL,不会合并重复的记录行
效率 UNION 高于 UNION ALL
SQL优化
如何定位及优化SQL语句的性能问题? 创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因?
对于低性能的SQL语句的定位, 重要也是 有效的方法就是使用执行计划, MySQL提供了explain命令来
查看语句的执行计划。 我们知道,不管是哪种数据库,或者是哪种数据库引擎,在对一条SQL语句进行
执行的过程中都会做很多相关的优化,对于查询语句,最重要的优化方式就是使用索引。 而执行计划,
就是显示数据库引擎对于SQL语句的执行的详细情况,其中包含了是否使用索引,使用什么索引,使用
的索引的相关信息等。
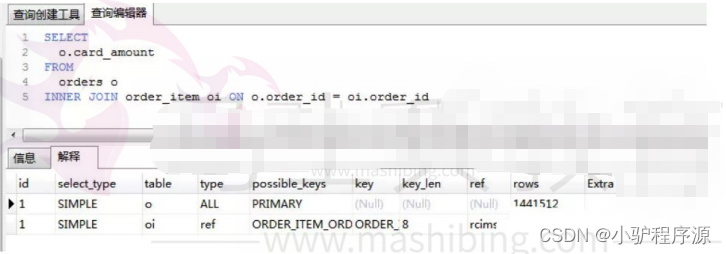
执行计划包含的信息 id 有一组数字组成。表示一个查询中各个子查询的执行顺序;
- id相同执行顺序由上至下。
- id不同,id值越大优先级越高,越先被执行。
- id为null时表示一个结果集,不需要使用它查询,常出现在包含union等查询语句中。
select_type 每个子查询的查询类型,一些常见的查询类型。
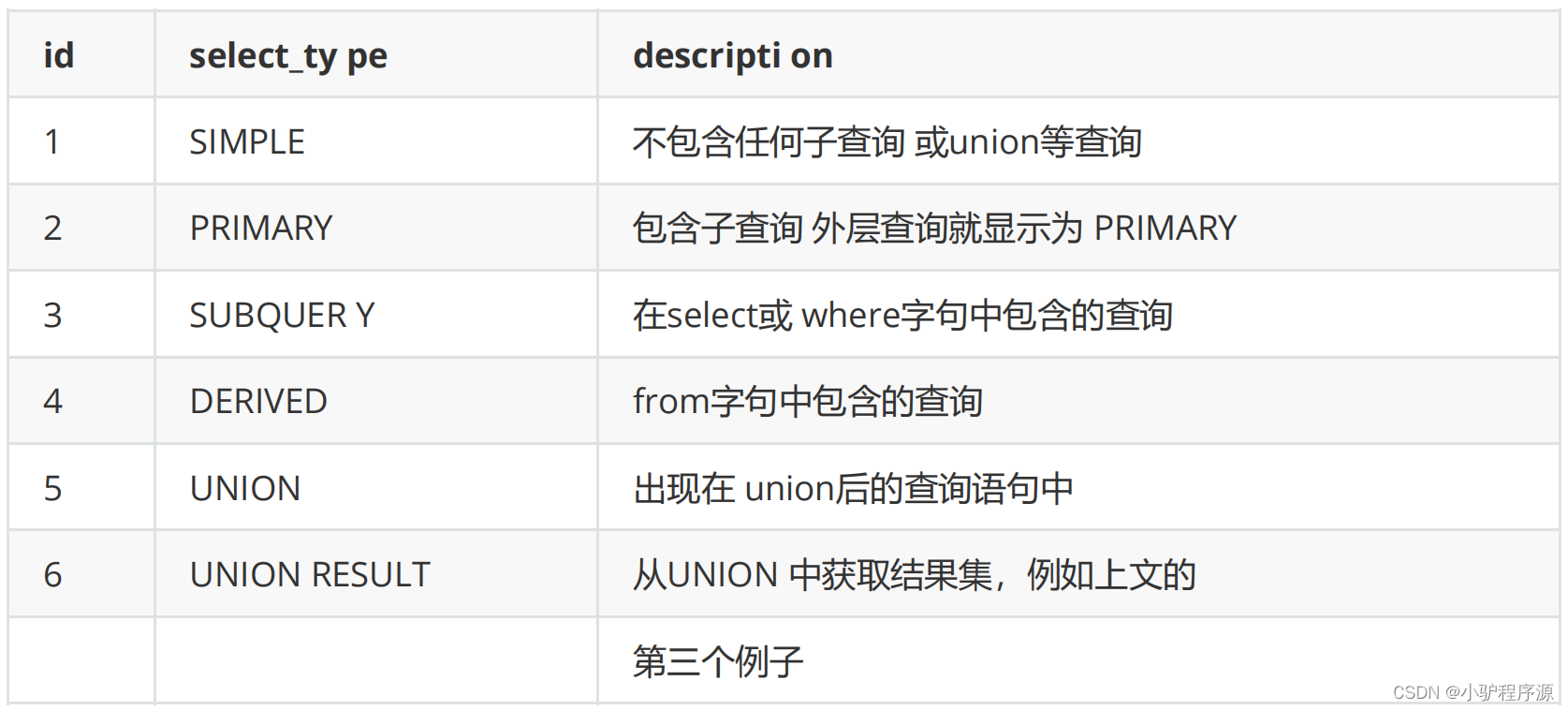
table 查询的数据表,当从衍生表中查数据时会显示 x 表示对应的执行计划id
partitions 表分区、表创建的时候可以指定通过那个列进行表分区。 举个例子:
1 create table tmp (
2 id int unsigned not null AUTO_INCREMENT,
3 name varchar(255),
4 PRIMARY KEY(id))
5 engine=innodb partition by key(id) partitions 5;
type(非常重要,可以看到有没有走索引) 访问类型
ALL 扫描全表数据 index 遍历索引 range 索引范围查找 index_subquery 在子查询中使用 ref
unique_subquery 在子查询中使用 eq_ref ref_or_null 对Null进行索引的优化的 ref fulltext 使用全文索
引
ref 使用非唯一索引查找数据 eq_ref 在join查询中使用PRIMARY KEYorUNIQUE NOT NULL索引关联。
possible_keys 可能使用的索引,注意不一定会使用。查询涉及到的字段上若存在索引,则该索引将被
列出来。当该列为 NULL时就要考虑当前的SQL是否需要优化了。
key 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL。 TIPS:查询中若使用了覆盖
索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
key_length 索引长度
ref 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 rows 返回估算的结果集数
目,并不是一个准确的值。
extra 的信息非常丰富,常见的有:
- Using index 使用覆盖索引
- Using where 使用了用where子句来过滤结果集
- Using filesort 使用文件排序,使用非索引列进行排序时出现,非常消耗性能,尽量优化。
- Using temporary 使用了临时表 sql优化的目标可以参考阿里开发手册
【推荐】
SQL性能优化的目标:至少要达到 range 级别,要求是ref级别,如果可以是 consts 更好。、
说明:
1) consts 单表中 多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2) ref 指的是使用普通的索引(normal index)。
3) range 对索引进行范围检索。 反例:explain表的结果,type=index,索引物理文件全扫描,速度非常慢,这个index级别比较range还低,与全表扫描是小巫见大巫
SQL的生命周期?
- 应用服务器与数据库服务器建立一个连接
- 数据库进程拿到请求sql
- 解析并生成执行计划,执行
- 读取数据到内存并进行逻辑处理
- 通过步骤一的连接,发送结果到客户端
- 关掉连接,释放资源
大表数据查询,怎么优化
- 优化shema、sql语句+索引;
- 第二加缓存,memcached, redis;
- 主从复制,读写分离;
- 垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
- 水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
超大分页怎么处理?
超大的分页一般从两个方向上来解决
- 数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于select * from table where age 20
limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然
后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select
id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由
于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以select
from table where id > 1000000 limit 10,效率也是不错的,优化的可能性有许多种, 但是核心思想 都一样,就是减少load的数据 - 从需求的角度减少这种请求…主要是不做类似的需求(直接跳转到几百万页之后的具体某一页.只允
许逐页查看或者按照给定的路线走,这样可预测,可缓存)以及防止ID泄漏且连续被人恶意攻击.
解决超大分页,其实主要是靠缓存,可预测性的提前查到内容,缓存至redis等k-V数据库中,直接返回即可.
在阿里巴巴《Java开发手册》中,对超大分页的解决办法是类似于上面提到的第一种.
【推荐】利用延迟关联或者子查询优化超多分页场景。 说明:MySQL并不是跳过offset
行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的
低下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。 正例:先快速定位需要获取
的id段,然后再关联:
SELECT a.* FROM
表1 a,(select id from 表1 where 条件 LIMIT 100000,20) b
where a.id=b.id
mysql分页
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的 大数目。初始记录行的偏移量是 0(而不是 1)
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
如果只给定一个参数,它表示返回 大的记录行数目:
mysql> SELECT * FROM table LIMIT 5; //检索前5 个记录行
换句话说,LIMIT n 等价于 LIMIT 0,n。
慢查询日志
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考。
开启慢查询日志
配置项:
slow_query_log 可以使用show variables like ‘slov_query_log’查看是否开启,如果状态值为
OFF,可以使用set GLOBAL slow_query_log = on来开启,它会在datadir下产生一个xxx-slow.log的文
件。
设置临界时间
配置项:long_query_time 查看:show VARIABLES like ‘long_query_time’,单位秒设置:set
long_query_time=0.5
实操时应该从长时间设置到短的时间,即将 慢的SQL优化掉
查看日志,一旦SQL超过了我们设置的临界时间就会被记录到xxx-slow.log中
关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?慢查询都怎么优化过?
在业务系统中,除了使用主键进行的查询,其他的我都会在测试库上测试其耗时,慢查询的统计主要由
运维在做,会定期将业务中的慢查询反馈给我们。慢查询的优化首先要搞明白慢的原因是什么? 是查询
条件没有命中索引?是 load了不需要的数据列?还是数据量太大?所以优化也是针对这三个方向来的,
首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多
结果中并不需要的列,对语句进行分析以及重写。
分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能
的命中索引。
如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向 的分表。
为什么要尽量设定一个主键?
主键是数据库确保数据行在整张表唯一性的保障,即使业务上本张表没有主键,也建议添加一个自增长
的ID列作为主键。设定了主键之后,在后续的删改查的时候可能更加快速以及确保操作数据范围安全。
主键使用自增ID还是UUID?
推荐使用自增ID,不要使用UUID。
因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上
存储了主键索引以及全部的数据(按照顺序),如果主键索引是自增ID,那么只需要不断向后排列即可,如
果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很
多的内存碎片,进而造成插入性能的下降。
总之,在数据量大一些的情况下,用自增主键性能会好一些。
关于主键是聚簇索引,如果没有主键,InnoDB会选择一个唯一键来作为聚簇索引,如果没有唯一键,会
生成一个隐式的主键。
字段为什么要求定义为not null?
null值会占用更多的字节,且会在程序中造成很多与预期不符的情况。
如果要存储用户的密码散列,应该使用什么字段进行存储?
密码散列,盐,用户身份证号等固定长度的字符串应该使用char而不是varchar 来存储,这样可以节省
空间且提高检索效率。
优化查询过程中的数据访问
访问数据太多导致查询性能下降确定应用程序是否在检索大量超过需要的数据,可能是太多行或列确认
MySQL服务器是否在分析大量不必要的数据行避免犯如下SQL语句错误
查询不需要的数据。解决办法:使用limit解决
多表关联返回全部列。解决办法:指定列名
总是返回全部列。解决办法:避免使用SELECT * 重复查询相同的数据。解决办法:可以缓存数据,下次
直接读取缓存是否在扫描额外的记录。解决办法:
使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优
化:
使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。
改变数据库和表的结构,修改数据表范式
重写SQL语句,让优化器可以以更优的方式执行查询。
优化长难的查询语句
一个复杂查询还是多个简单查询
MySQL内部每秒能扫描内存中上百万行数据,相比之下,响应数据给客户端就要慢得多
使用尽可能小的查询是好的,但是有时将一个大的查询分解为多个小的查询是很有必要的。
切分查询将一个大的查询分为多个小的相同的查询
一次性删除1000万的数据要比一次删除1万,暂停一会的方案更加损耗服务器开销。
分解关联查询,让缓存的效率更高。
执行单个查询可以减少锁的竞争。
在应用层做关联更容易对数据库进行拆分。
查询效率会有大幅提升。
较少冗余记录的查询
优化特定类型的查询语句
count()会忽略所有的列,直接统计所有列数,不要使用count(列名) MyISAM中,没有任何where条件的
count()非常快。
当有where条件时,MyISAM的count统计不一定比其它引擎快。
可以使用explain查询近似值,用近似值替代count(*) 增加汇总表使用缓存
优化关联查询
确定ON或者USING子句中是否有索引。
确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引
优化子查询
用关联查询替代
优化GROUP BY和DISTINCT
这两种查询据可以使用索引来优化,是 有效的优化方法关联查询中,使用标识列分组的效率更高
如果不需要ORDER BY,进行GROUP BY时加ORDER BY NULL,MySQL不会再进行文件排序。
WITH ROLLUP超级聚合,可以挪到应用程序处理
优化LIMIT分页
LIMIT偏移量大的时候,查询效率较低
可以记录上次查询的 大ID,下次查询时直接根据该ID来查询
优化UNION查询
UNION ALL的效率高于UNION
优化WHERE子句
解题方法对于此类考题,先说明如何定位低效SQL语句,然后根据SQL语句可能低效的原因做排查,先
从索引着手,如果索引没有问题,考虑以上几个方面,数据访问的问题,长难查询句的问题还是一些特
定类型优化的问题,逐一回答。
SQL语句优化的一些方法?
- 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫 描,如:
select id from t where num is null
-- 可以在num上设置默认值0,确保表中num列没有null值,
-- 然后这样查询:
select id from t where num=0
- 3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
- 4.应尽量避免在 where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,
如:
select id from t where num=10 or num=20
-- 可以这样查询:
select id from t where num=10
union all
select id from t where num=20
- 5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
-- 对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
-
6.下面的查询也将导致全表扫描:select id from t where name like ‘% 李%’若要提高效率,可以考虑全文检索。
-
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
--可以改为强制查询使用索引:
select id from t with (index(索引名)) where num=@num
- 8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描如:
select id from t where num/2=100
-- 应改为:
select id from t where num=100*2
- 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’
-- name以abc开头的id应改为:
select id from t where name like ‘abc%’
- 10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
数据库优化
为什么要优化
系统的吞吐量瓶颈往往出现在数据库的访问速度上随着应用程序的运行,数据库的中的数据会越来越
多,处理时间会相应变慢数据是存放在磁盘上的,读写速度无法和内存相比优化原则:减少系统瓶颈,
减少资源占用,增加系统的反应速度
数据库结构优化
一个好的数据库设计方案对于数据库的性能往往会起到事半功倍的效果。
需要考虑数据冗余、查询和更新的速度、字段的数据类型是否合理等多方面的内容。
将字段很多的表分解成多个表对于字段较多的表,如果有些字段的使用频率很低,可以将这些字段分离
出来形成新表。
因为当一个表的数据量很大时,会由于使用频率低的字段的存在而变慢。
增加中间表对于需要经常联合查询的表,可以建立中间表以提高查询效率。
通过建立中间表,将需要通过联合查询的数据插入到中间表中,然后将原来的联合查询改为对中间表的
查询。
增加冗余字段设计数据表时应尽量遵循范式理论的规约,尽可能的减少冗余字段,让数据库设计看起来
精致、优雅。但是,合理的加入冗余字段可以提高查询速度。
表的规范化程度越高,表和表之间的关系越多,需要连接查询的情况也就越多,性能也就越差。
注意:
冗余字段的值在一个表中修改了,就要想办法在其他表中更新,否则就会导致数据不一致的问题
MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出
占用高的进程,并进行相关处理。
如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在
运行。找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、
改 sql、改内存参数)之后,再重新跑这些 SQL。
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情
况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
大表怎么优化?某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么 做的?分表分库了有什么问题?有用到中间 件么?他们的原理知道么?
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
1. 限定数据的范围:
务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内
2. 读/写分离:
经典的数据库拆分方案,主库负责写,从库负责读;
3. 缓存:
使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
有就是通过分库分表的方式进行优化,主要有垂直分表和水平分表
4. 垂直分区
根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了
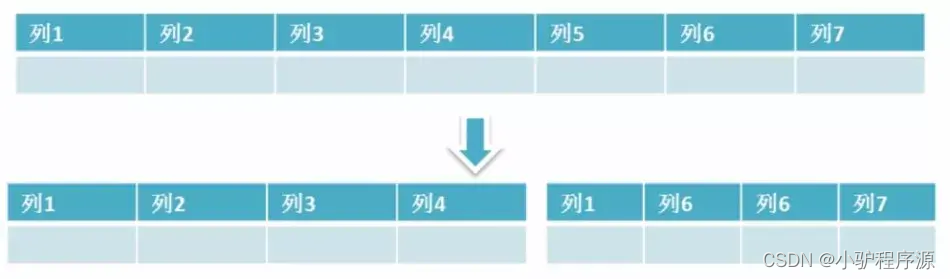
垂直拆分的优点: 可以使得行数据变小,在查询时减少读取的Block数,减少 I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
4. 垂直分表
把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中
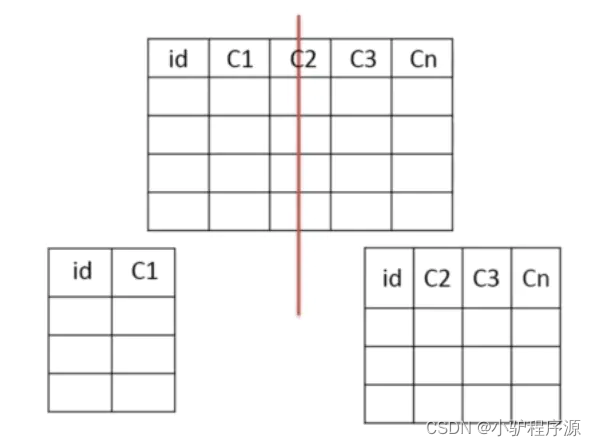
适用场景
1、 如果一个表中某些列常用,另外一些列不常用
2、 可以使数据行变小,一个数据页能存储更多数据,查询时减少I/O次数
缺点
1、有些分表的策略基于应用层的逻辑算法,一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差
2、对于应用层来说,逻辑算法增加开发成本
3、管理冗余列,查询所有数据需要join操作
水平分区:
保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。水平拆分可以支撑非常大的数据量。
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
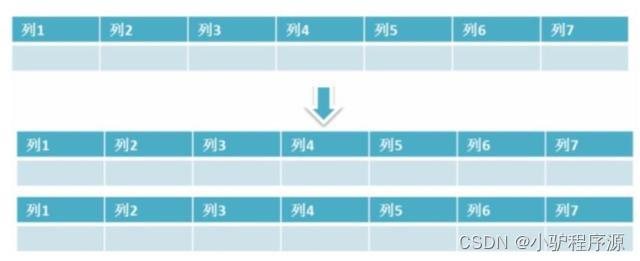
水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 水平拆分最好分库 。
水平拆分能够支持非常大的数据量存储,应用端改造也少,但 分片事务难以解决 ,跨界点Join性能较差,逻辑复杂。
《Java工程师修炼之道》的作者推荐尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度 ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
水平分表
表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询次数
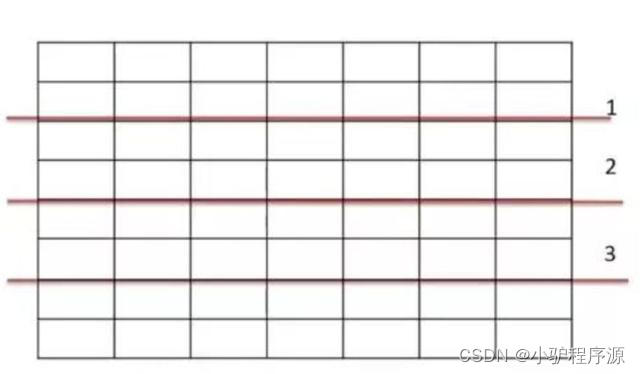
适用场景
1、表中的数据本身就有独立性,例如表中分表记录各个地区的数据或者不同时期的数据,特别是有些数据常用,有些不常用。
2、需要把数据存放在多个介质上。
水平切分的缺点
1、给应用增加复杂度,通常查询时需要多个表名,查询所有数据都需UNION操作
2、在许多数据库应用中,这种复杂度会超过它带来的优点,查询时会增加读一个索引层的磁盘次数
下面补充一下数据库分片的两种常见方案:
1、客户端代理:分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
2、中间件代理:在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。我们现在谈的Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
分库分表后面临的问题
- 事务支持:分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
- 跨库join:只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。分库分表方案产品
- 跨节点的count,order by,group by以及聚合函数问题:这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
- 数据迁移,容量规划,扩容等问题:来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了Sharding扩容的难度。
- ID问题
- 一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由.一些常见的主键生成策略
- UUID
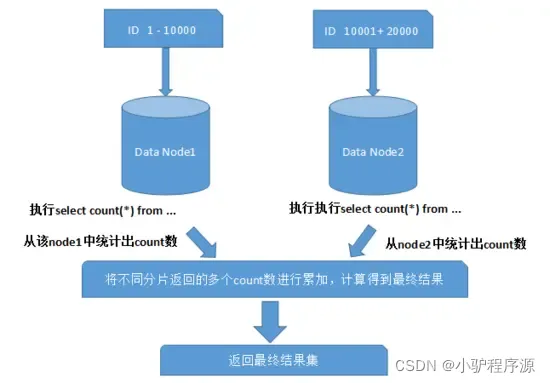
使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。Twitter的分布式自增ID算法Snowflake 在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位 机器ID 10位 毫秒内序列12位 - 跨分片的排序分页般来讲,分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,情况就会变得比较复 杂了。为了 终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回 的结果集进行汇总和再次排序,后再返回给用户。如下图所
MySQL的复制原理以及流程
主从复制:将主数据库中的DDL和DML操作通过二进制日志(BINLOG)传输到从数据库上,然后将这些日志重新执行(重做);从而使得从数据库的数据与主数据库保持一致。
主从复制的作用
- 主数据库出现问题,可以切换到从数据库。
- 可以进行数据库层面的读写分离。
- 可以在从数据库上进行日常备份。
MySQL主从复制解决的问题
- 数据分布:随意开始或停止复制,并在不同地理位置分布数据备份
- 负载均衡:降低单个服务器的压力
- 高可用和故障切换:帮助应用程序避免单点失败
- 升级测试:可以用更高版本的MySQL作为从库
MySQL主从复制工作原理
- 在主库上把数据更高记录到二进制日志
- 从库将主库的日志复制到自己的中继日志
- 从库读取中继日志的事件,将其重放到从库数据中
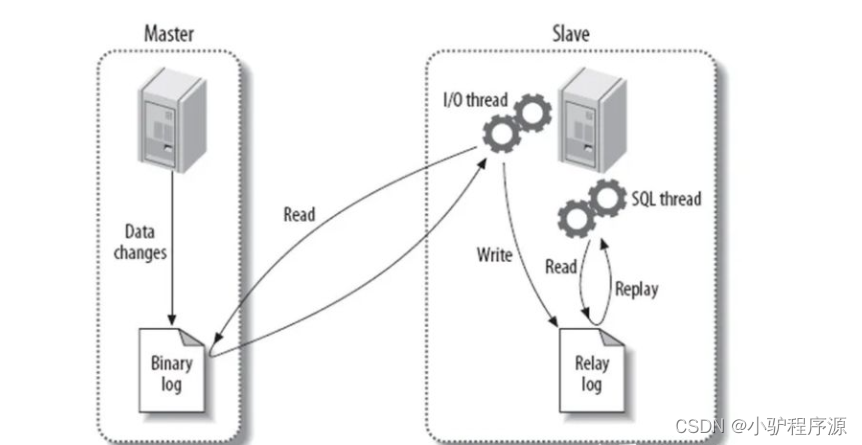
基本原理流程,3个线程以及之间的关联
主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中;
从:sql执行线程——执行relay log中的语句;
复制过程
Binary log:主数据库的二进制日志
Relay log:从服务器的中继日志
第一步:
master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
第二步:
salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
第三步:
SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
读写分离有哪些解决方案?
读写分离是依赖于主从复制,而主从复制又是为读写分离服务的。因为主从复制要求slave不能写只能读(如果对slave执行写操作,那么show slave status将会呈现Slave_SQL_Running=NO,此时你需要按照前面提到的手动同步一下slave)。
方案一
使用mysql-proxy代理
优点:
直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号,mysql官方不建议实际生产中使用
缺点:
降低性能, 不支持事务
方案二
使用AbstractRoutingDataSource+aop+annotation在dao层决定数据源。 如果采用了mybatis, 可以将读写分离放在ORM层,比如mybatis可以通过mybatis plugin拦截sql语句,所有的insert/update/delete都访问master库,所有的select 都访问salve库,这样对于dao层都是透明。plugin实现时可以通过注解或者分析语句是读写方法来选定主从库。不过这样依然有一个问题, 也就是不支持事务, 所以我们还需要重写一下DataSourceTransactionManager, 将read-only的事务扔进读库, 其余的有读有写的扔进写库。
方案三
使用AbstractRoutingDataSource+aop+annotation在service层决定数据源,可以支持事务.
缺点:
类内部方法通过this.xx()方式相互调用时,aop不会进行拦截,需进行特殊处理。
备份计划,mysqldump以及xtranbackup的实现原理
(1)备份计划
视库的大小来定,一般来说 100G 内的库,可以考虑使用 mysqldump 来做,因为 mysqldump更加轻巧灵活,备份时间选在业务低峰期,可以每天进行都进行全量备份(mysqldump 备份出来的文件比较小,压缩之后更小)。
100G 以上的库,可以考虑用 xtranbackup 来做,备份速度明显要比 mysqldump 要快。一般是选择一周一个全备,其余每天进行增量备份,备份时间为业务低峰期。
(2)备份恢复时间
物理备份恢复快,逻辑备份恢复慢
这里跟机器,尤其是硬盘的速率有关系,以下列举几个仅供参考
20G的2分钟(mysqldump)
80G的30分钟(mysqldump)
111G的30分钟(mysqldump)
288G的3小时(xtra)
3T的4小时(xtra)
逻辑导入时间一般是备份时间的5倍以上
(3)备份恢复失败如何处理
首先在恢复之前就应该做足准备工作,避免恢复的时候出错。比如说备份之后的有效性检查、权限检查、空间检查等。如果万一报错,再根据报错的提示来进行相应的调整。
(4)mysqldump和xtrabackup实现原理
mysqldump
mysqldump 属于逻辑备份。加入–single-transaction 选项可以进行一致性备份。后台进程会先设置 session 的事务隔离级别为 RR(SET SESSION TRANSACTION ISOLATION LEVELREPEATABLE READ),之后显式开启一个事务(START TRANSACTION /*!40100 WITH CONSISTENTSNAPSHOT */),这样就保证了该事务里读到的数据都是事务事务时候的快照。之后再把表的数据读取出来。如果加上–master-data=1 的话,在刚开始的时候还会加一个数据库的读锁(FLUSH TABLES WITH READ LOCK),等开启事务后,再记录下数据库此时 binlog 的位置(showmaster status),马上解锁,再读取表的数据。等所有的数据都已经导完,就可以结束事务
Xtrabackup:
xtrabackup 属于物理备份,直接拷贝表空间文件,同时不断扫描产生的 redo 日志并保存下来。最后完成 innodb 的备份后,会做一个 flush engine logs 的操作(老版本在有 bug,在5.6 上不做此操作会丢数据),确保所有的 redo log 都已经落盘(涉及到事务的两阶段提交
概念,因为 xtrabackup 并不拷贝 binlog,所以必须保证所有的 redo log 都落盘,否则可能会丢最后一组提交事务的数据)。这个时间点就是 innodb 完成备份的时间点,数据文件虽然不是一致性的,但是有这段时间的 redo 就可以让数据文件达到一致性(恢复的时候做的事
情)。然后还需要 flush tables with read lock,把 myisam 等其他引擎的表给备份出来,备份完后解锁。这样就做到了完美的热备。
数据表损坏的修复方式有哪些?
使用 myisamchk 来修复,具体步骤:
1)修复前将mysql服务停止。
2)打开命令行方式,然后进入到mysql的/bin目录。
3)执行myisamchk –recover 数据库所在路径/*.MYI
使用repair table 或者 OPTIMIZE table命令来修复,REPAIR TABLE table_name 修复表 OPTIMIZE TABLE table_name 优化表 REPAIR TABLE 用于修复被破坏的表。OPTIMIZE TABLE 用于回收闲置的数据库空间,当表上的数据行被删除时,所占据的磁盘空间并没有立即被回收,使用了OPTIMIZE TABLE命令后这些空间将被回收,并且对磁盘上的数据行进行重排(注意:是磁盘上,而非数据库)。
MySQL记录binlog的方式主要包括三种模式?每种模式的优缺点是什么?
mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行 的复制
(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应 的,binlog的格
式也有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的 数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave 中的数据不一致( 如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会
出现 问题)
Statement level(默认) 优点:
statement模式记录的更改的SQ语句事件,并非每条更改记录,所以大大减少了binlog日志量,节约磁盘IO,提高性能。
缺点:
statement level下对一些特殊功能的复制效果不是很好,比如:函数、存储过程的复制。由于row level是基于每一行的变化来记录的,所以不会出现类似问题
② ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出 现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺 点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
优点:
row level的binlog日志内容会非常清楚的记录下每一行数据被修改的细节。而且不会出现某些特定情况下存储过程或function,以及trigger的调用和触发器无法被正确复制的问题。
缺点:
row level下,所有执行的语句当记录到日志中的时候,都以每行记录的修改来记录,这样可能会产生大量的日志内容,产生的binlog日志量是惊人的。批量修改几百万条数据,那么记录几百万行……
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT 模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
优缺点
Mixed 实际上就是前两种模式的结合。在Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种
MySQL锁
乐观锁
用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即 为数据
增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实 现。当读取数据
时,将version字段的值一同读出,数据每更新一次,对此version值加1。当我 们提交更新的时候,判
断数据库表对应记录的当前版本信息与第一次取出来的version值进行比 对,如果数据库表当前版本号
与第一次取出来的version值相等,则予以更新,否则认为是过期 数据。
悲观锁
在进行每次操作时都要通过获取锁才能进行对相同数据的操作,这点跟java中synchronized很 相似,共
享锁(读锁)和排它锁(写锁)是悲观锁的不同的实现
共享锁(读锁)
共享锁又叫做读锁,所有的事务只能对其进行读操作不能写操作,加上共享锁后在事务结束之前 其他事
务只能再加共享锁,除此之外其他任何类型的锁都不能再加了。
排它锁(写锁)
若某个事物对某一行加上了排他锁,只能这个事务对其进行读写,在此事务结束之前,其他事务 不能对
其进行加任何锁,其他进程可以读取,不能进行写操作,需等待其释放。
表级锁
innodb 的行锁是在有索引的情况下,没有索引的表是锁定全表的
行级锁
行锁又分共享锁和排他锁,由字面意思理解,就是给某一行加上锁,也就是一条记录加上锁。 注意:行级
锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级 锁。
MySQL InnoDB中,乐观锁、悲观锁、共享锁、排它锁、行锁、表锁、死锁概念的理解
MySQL/InnoDB的加锁,一直是一个面试中常问的话题。例如,数据库如果有高并发请求,如何保证数
据完整性?产生死锁问题如何排查并解决?我在工作过程中,也会经常用到,乐观锁,排它锁,等。于
是今天就对这几个概念进行学习,屡屡思路,记录一下。
注:MySQL是一个支持插件式存储引擎的数据库系统。本文下面的所有介绍,都是基于InnoDB存储引 擎,其他引擎的表现,会有较大的区别。
存储引擎查看
MySQL给开发者提供了查询存储引擎的功能,我这里使用的是MySQL5.6.4,可以使用:
SHOW ENGINES
乐观锁
用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增
加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,
将version字段的值一同读出,数据每更新一次,对此version值加1。当我们提交更新的时候,判断数据
库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次
取出来的version值相等,则予以更新,否则认为是过期数据。
举例
1、数据库表设计
三个字段,分别是 id,value、version
select id,value,version from TABLE where id=#{id}
2、每次更新表中的value字段时,为了防止发生冲突,需要这样操作
update TABLE set value=2,version=version+1
where id=#{id}
and version=#{version};
悲观锁
与乐观锁相对应的就是悲观锁了。悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行
每次操作时都要通过获取锁才能进行对相同数据的操作,这点跟java中的synchronized很相似,所以悲
观锁需要耗费较多的时间。另外与乐观锁相对应的,悲观锁是由数据库自己实现了的,要用的时候,我
们直接调用数据库的相关语句就可以了。
说到这里,由悲观锁涉及到的另外两个锁概念就出来了,它们就是共享锁与排它锁。共享锁和排它锁是
悲观锁的不同的实现,它俩都属于悲观锁的范畴。
使用,排它锁 举例
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,
也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。
我们可以使用命令设置MySQL为非autocommit模式:
set autocommit=0;
# 设置完autocommit后,我们就可以执行我们的正常业务了。具体如下:
# 1. 开始事务
begin;/begin work;/start transaction; (三者选一就可以)
# 2. 查询表信息
select status from TABLE where id=1 for update;
# 3. 插入一条数据
insert into TABLE (id,value) values (2,2);
# 4. 修改数据为
update TABLE set value=2 where id=1;
# 5. 提交事务
commit;/commit work;
共享锁
共享锁又称 读锁 read lock,是读取操作创建的锁。其他用户可以并发读取数据,但任何事务都不能对
数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。
如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获得共享锁的事务
只能读数据,不能修改数据
打开第一个查询窗口
begin;/begin work;/start transaction; (三者选一就可以)
SELECT * from TABLE where id = 1 lock in share mode;
然后在另一个查询窗口中,对id为1的数据进行更新
update TABLE set name="www.souyunku.com" where id =1;
此时,操作界面进入了卡顿状态,过了超时间,提示错误信息
如果在超时前,执行 commit ,此更新语句就会成功。
[SQL]update test_one set name="www.souyunku.com" where id =1;
[Err] 1205 - Lock wait timeout exceeded; try restarting transaction
加上共享锁后,也提示错误信息
update test_one set name="www.souyunku.com" where id =1 lock in share mode;
[SQL]update test_one set name="www.souyunku.com" where id =1 lock in share mode;
[Err] 1064 - You have an error in your SQL syntax; check the manual that
corresponds to your MySQL server version for the right syntax to use near 'lock in share mode' at line 1
在查询语句后面增加 LOCK IN SHARE MODE ,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。
加上共享锁后,对于update,insert,delete 语句会自动加排它锁。
排它锁
排他锁 exclusive lock(也叫writer lock)又称 写锁。
排它锁是悲观锁的一种实现,在上面悲观锁也介绍过。
若事务 1 对数据对象A加上X锁,事务 1 可以读A也可以修改A,其他事务不能再对A加任何锁,直到事物
1 释放A上的锁。这保证了其他事务在事物 1 释放A上的锁之前不能再读取和修改A。排它锁会阻塞所有
的排它锁和共享锁
读取为什么要加读锁呢:防止数据在被读取的时候被别的线程加上写锁,
使用方式:在需要执行的语句后面加上 for update 就可以了
行锁
行锁又分共享锁和排他锁,由字面意思理解,就是给某一行加上锁,也就是一条记录加上锁。
**注意:**行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁。
共享锁:
名词解释:共享锁又叫做读锁,所有的事务只能对其进行读操作不能写操作,加上共享锁后在事务结束
之前其他事务只能再加共享锁,除此之外其他任何类型的锁都不能再加了。
SELECT * from TABLE where id = "1" lock in share mode; //结果集的数据都会加共享锁
排他锁:
名词解释:若某个事物对某一行加上了排他锁,只能这个事务对其进行读写,在此事务结束之前,其他
事务不能对其进行加任何锁,其他进程可以读取,不能进行写操作,需等待其释放。
select status from TABLE where id=1 for update;
可以参考之前演示的共享锁,排它锁语句
由于对于表中,id字段为主键,就也相当于索引。执行加锁时,会将id这个索引为1的记录加上锁,那么这
个锁就是行锁。
表锁
如何加表锁
innodb 的行锁是在有索引的情况下,没有索引的表是锁定全表的.
Innodb中的行锁与表锁
前面提到过,在Innodb引擎中既支持行锁也支持表锁,那么什么时候会锁住整张表,什么时候或只锁住
一行呢?
只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发
性能。
行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁。行级锁的
缺点是:由于需要请求大量的锁资源,所以速度慢,内存消耗大。
死锁
死锁(Deadlock)
所谓死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无
外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待
的进程称为死锁进程。由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协
助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象死锁。
解除正在死锁的状态有两种方法:
第一种:
1.查询是否锁表
show OPEN TABLES where In_use > 0;
2.查询进程
如果您有SUPER权限,您可以看到所有线程。否则,您只能看到您自己的线程
show processlist
3.杀死进程id(就是上面命令的id列)
kill id
第二种:
1:查看当前的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
2:查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
3:查看当前等锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
4:杀死进程
kill 线程ID
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限
的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。
产生死锁的四个必要条件:
- (1) 互斥条件:一个资源每次只能被一个进程使用。
- (2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- (3)不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
- (4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
虽然不能完全避免死锁,但可以使死锁的数量减至最少。将死锁减至最少可以增加事务的吞吐量并减少
系统开销,因为只有很少的事务回滚,而回滚会取消事务执行的所有工作。由于死锁时回滚而由应用程
序重新提交。
有助于最大限度地降低死锁的方法:
(1)按同一顺序访问对象。
(2)避免事务中的用户交互。
(3)保持事务简短并在一个批处理中。
(4)使用低隔离级别。
(5)使用绑定连接
分布式事务的原理2阶段提交,同步异步阻塞非阻塞;
数据库事务隔离级别,MySQL默认的隔离级别
Mysql默认隔离级别:Repeatable Read
| 隔离级别 | 脏读 | 不和重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read uncommitted) | √ | √ | √ |
| 读已提交(Read committed) | × | √ | √ |
| 可重复读(Repeatable read) | × | × | √ |
| 可串行化(Serializable) | × | × | × |
Spring如何实现事务
Spring 事物四种实现方式:
- 基于编程式事务管理实现
- 基于TransactionProxyFactoryBean的声明式事务管理
- 基于AspectJ的XML声明式事务管理
- 基于注解的声明式事务管理
spring事务管理(详解和实例)
1 初步理解
理解事务之前,先讲一个你日常生活中最常干的事:取钱。
比如你去ATM机取1000块钱,大体有两个步骤:首先输入密码金额,银行卡扣掉1000元钱;然后ATM
出1000元钱。这两个步骤必须是要么都执行要么都不执行。如果银行卡扣除了1000块但是ATM出钱失
败的话,你将会损失1000元;如果银行卡扣钱失败但是ATM却出了1000块,那么银行将损失1000元。
所以,如果一个步骤成功另一个步骤失败对双方都不是好事,如果不管哪一个步骤失败了以后,整个取
钱过程都能回滚,也就是完全取消所有操作的话,这对双方都是极好的。
事务就是用来解决类似问题的。事务是一系列的动作,它们综合在一起才是一个完整的工作单元,这些
动作必须全部完成,如果有一个失败的话,那么事务就会回滚到最开始的状态,仿佛什么都没发生过一
样。
在企业级应用程序开发中,事务管理必不可少的技术,用来确保数据的完整性和一致性。
事务有四个特性:ACID
- 原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要 么全部完成,要么完全不起作用。
- 一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
- 隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他 事务隔离开来,防止数据损坏。
- 持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影
响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器 中。
2 核心接口
Spring事务管理的实现有许多细节,如果对整个接口框架有个大体了解会非常有利于我们理解事务,下
面通过讲解Spring的事务接口来了解Spring实现事务的具体策略。Spring事务管理涉及的接口如下:
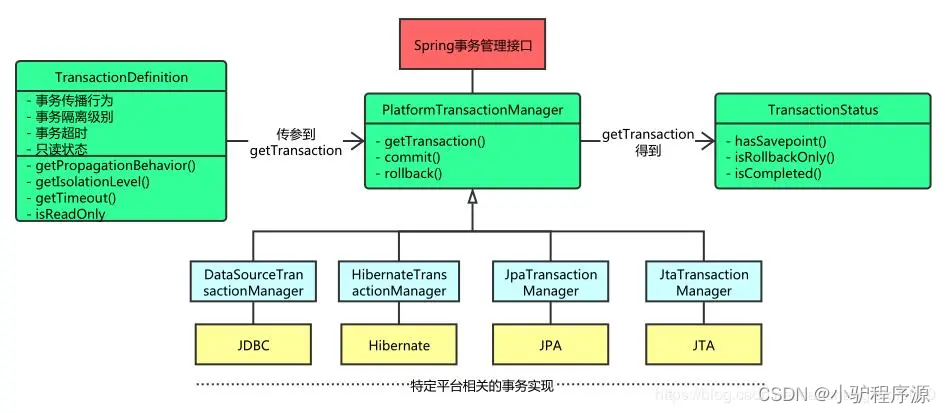
2.1 事务管理器
Spring并不直接管理事务,而是提供了多种事务管理器,他们将事务管理的职责委托给Hibernate或者JTA等持久化机制所提供的相关平台框架的事务来实现。Spring事务管理器的接口是org.springframework.transaction.PlatformTransactionManager,通过这个接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。此接口的内容如下:
package org.springframework.transaction;
import org.springframework.lang.Nullable;
/**
* 这是Spring事务基础架构中的中心接口。
* 应用程序可以直接使用它,但它主要不是指API:
* 一般地,应用程序将通过AOP使用TransactionTemplate或声明性事务划分
* This is the central interface in Spring's transaction infrastructure.
* Applications can use this directly, but it is not primarily meant as API:
* Typically, applications will work with either TransactionTemplate or
* declarative transaction demarcation through AOP.
*
* 对于实现者,建议从提供的
* {@link org.springframework.transaction.support.AbstractPlatformTransactionManager}
* 类,它预先实现定义的传播行为并负责
* 事务同步处理。子类必须实现
* 基础事务的特定状态的模板方法,
* 例如:开始、暂停、恢复、提交。
* <p>For implementors, it is recommended to derive from the provided
* {@link org.springframework.transaction.support.AbstractPlatformTransactionManager}
* class, which pre-implements the defined propagation behavior and takes care
* of transaction synchronization handling. Subclasses have to implement
* template methods for specific states of the underlying transaction,
* for example: begin, suspend, resume, commit.
* 此策略接口的默认实现为 JtaTransactionManager 和 DataSourceTransactionManager
* 它可以作为其他事务策略的实现指南。
* <p>The default implementations of this strategy interface are
* {@link org.springframework.transaction.jta.JtaTransactionManager} and
* {@link org.springframework.jdbc.datasource.DataSourceTransactionManager},
* which can serve as an implementation guide for other transaction strategies.
*
* @author Rod Johnson
* @author Juergen Hoeller
* @since 16.05.2003
* @see org.springframework.transaction.support.TransactionTemplate
* @see org.springframework.transaction.interceptor.TransactionInterceptor
*/
public interface PlatformTransactionManager extends TransactionManager {
/**
* --description:由TransactionDefinition得到TransactionStatus对象
*
* 根据返回当前活动的事务或创建新事务
* 指定的传播行为。
* 请注意,隔离级别或超时等参数将仅应用
* 添加到新事务,因此在参与活动事务时将被忽略。
* 此外,并非所有事务定义设置都受支持
* 每个事务管理器:一个适当的事务管理器实现
* 遇到不支持的设置时,应引发异常。
* 上述规则的一个例外是只读标志,它应该是
* 如果不支持显式只读模式,则忽略。从本质上说
* 只读标志只是潜在优化的提示。
* @param 定义TransactionDefinition实例(默认情况下可以是{@code null})
* 描述传播行为、隔离级别、超时等。
* @return 表示新事务或当前事务的事务状态对象
* @Throws在查找,创建或系统错误的情况下进行TransactionException
* @Throws IllegalTransactionStateException如果给定的交易定义
* 无法执行(例如,如果当前活动的事务是与指定的传播行为冲突)
*
* Return a currently active transaction or create a new one, according to
* the specified propagation behavior.
* <p>Note that parameters like isolation level or timeout will only be applied
* to new transactions, and thus be ignored when participating in active ones.
* <p>Furthermore, not all transaction definition settings will be supported
* by every transaction manager: A proper transaction manager implementation
* should throw an exception when unsupported settings are encountered.
* <p>An exception to the above rule is the read-only flag, which should be
* ignored if no explicit read-only mode is supported. Essentially, the
* read-only flag is just a hint for potential optimization.
* @param definition the TransactionDefinition instance (can be {@code null} for defaults),
* describing propagation behavior, isolation level, timeout etc.
* @return transaction status object representing the new or current transaction
* @throws TransactionException in case of lookup, creation, or system errors
* @throws IllegalTransactionStateException if the given transaction definition
* cannot be executed (for example, if a currently active transaction is in
* conflict with the specified propagation behavior)
* @see TransactionDefinition#getPropagationBehavior
* @see TransactionDefinition#getIsolationLevel
* @see TransactionDefinition#getTimeout
* @see TransactionDefinition#isReadOnly
*/
TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException;
/**
* -- 提交
*
* 提交给定事务的状态
* 如果事务已通过编程方式标记为仅回滚,请执行回滚。
* 如果事务不是新事务,请省略提交,以便正确参与周围的事务。
* 如果上一个事务已暂停以创建新事务,请在提交新事务后恢复上一个事务。
* 请注意,当提交调用完成时,无论是正常还是引发异常,事务都必须完全完成并清理。
* 在这种情况下,不应出现回滚调用。
* 如果此方法引发TransactionException以外的异常,则某些提交前错误会导致提交尝试失败。
* 例如,O/R映射工具可能在提交之前尝试刷新对数据库的更改,结果DataAccessException导致事务失败。
* 在这种情况下,原始异常将传播到此提交方法的调用方。
*
*
* Commit the given transaction, with regard to its status. If the transaction
* has been marked rollback-only programmatically, perform a rollback.
* <p>If the transaction wasn't a new one, omit the commit for proper
* participation in the surrounding transaction. If a previous transaction
* has been suspended to be able to create a new one, resume the previous
* transaction after committing the new one.
* <p>Note that when the commit call completes, no matter if normally or
* throwing an exception, the transaction must be fully completed and
* cleaned up. No rollback call should be expected in such a case.
* <p>If this method throws an exception other than a TransactionException,
* then some before-commit error caused the commit attempt to fail. For
* example, an O/R Mapping tool might have tried to flush changes to the
* database right before commit, with the resulting DataAccessException
* causing the transaction to fail. The original exception will be
* propagated to the caller of this commit method in such a case.
* @param status object returned by the {@code getTransaction} method
* @throws UnexpectedRollbackException in case of an unexpected rollback
* that the transaction coordinator initiated
* @throws HeuristicCompletionException in case of a transaction failure
* caused by a heuristic decision on the side of the transaction coordinator
* @throws TransactionSystemException in case of commit or system errors
* (typically caused by fundamental resource failures)
* @throws IllegalTransactionStateException if the given transaction
* is already completed (that is, committed or rolled back)
* @see TransactionStatus#setRollbackOnly
*/
void commit(TransactionStatus status) throws TransactionException;
/**
* -- 回滚
*
* 执行给定事务的回滚。
* 如果该事务不是新事务,只需将其设置为回滚,以便正确参与周围的事务。
* 如果上一个事务已暂停以创建新事务,请在回滚新事务后恢复上一个事务。
* 如果commit引发异常,则不要对事务调用rollback。
* 当提交返回时,即使在提交异常的情况下,事务也将已经完成并清理。因此,提交失败后的回滚调用将导致非 法TransactionStateException。
*
* Perform a rollback of the given transaction.
* <p>If the transaction wasn't a new one, just set it rollback-only for proper
* participation in the surrounding transaction. If a previous transaction
* has been suspended to be able to create a new one, resume the previous
* transaction after rolling back the new one.
* <p><b>Do not call rollback on a transaction if commit threw an exception.</b>
* The transaction will already have been completed and cleaned up when commit
* returns, even in case of a commit exception. Consequently, a rollback call
* after commit failure will lead to an IllegalTransactionStateException.
*
* @param status object returned by the {@code getTransaction} method
* @throws TransactionSystemException in case of rollback or system errors
* (typically caused by fundamental resource failures)
* @throws IllegalTransactionStateException if the given transaction
* is already completed (that is, committed or rolled back)
*/
void rollback(TransactionStatus status) throws TransactionException;
}
从这里可知具体的具体的事务管理机制对Spring来说是透明的,它并不关心那些,那些是对应各个平台
需要关心的,所以Spring事务管理的一个优点就是为不同的事务API提供一致的编程模型,如JTA、
JDBC、Hibernate、JPA。下面分别介绍各个平台框架实现事务管理的机制。
2.1.1 JDBC事务
如果应用程序中直接使用JDBC来进行持久化,DataSourceTransactionManager会为你处理事务边界。
为了使用DataSourceTransactionManager,你需要使用如下的XML将其装配到应用程序的上下文定义
中:
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
实际上,DataSourceTransactionManager是通过调用java.sql.Connection来管理事务,而后者是通过DataSource获取到的。通过调用连接的commit()方法来提交事务,同样,事务失败则通过调用rollback()方法进行回滚。
2.1.2 Hibernate事务
如果应用程序的持久化是通过Hibernate实习的,那么你需要使用HibernateTransactionManager。对于Hibernate3,需要在Spring上下文定义中添加如下的声明:
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
sessionFactory属性需要装配一个Hibernate的session工厂,HibernateTransactionManager的实现细节是它将事务管理的职责委托给org.hibernate.Transaction对象,而后者是从Hibernate Session中获取到的。当事务成功完成时,HibernateTransactionManager将会调用Transaction对象的commit()方法,反之,将会调用rollback()方法。
2.1.3 Java持久化API事务(JPA)
Hibernate多年来一直是事实上的Java持久化标准,但是现在Java持久化API作为真正的Java持久化标准进入大家的视野。如果你计划使用JPA的话,那你需要使用Spring的JpaTransactionManager来处理事务。你需要在Spring中这样配置JpaTransactionManager:
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
JpaTransactionManager只需要装配一个JPA实体管理工厂(javax.persistence.EntityManagerFactory接口的任意实现)。JpaTransactionManager将与由工厂所产生的JPA EntityManager合作来构建事务。
2.1.4 Java原生API事务
如果你没有使用以上所述的事务管理,或者是跨越了多个事务管理源(比如两个或者是多个不同的数据源),你就需要使用JtaTransactionManager:
<bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="transactionManagerName" value="java:/TransactionManager" />
</bean>
JtaTransactionManager将事务管理的责任委托给javax.transaction.UserTransaction和javax.transaction.TransactionManager对象,其中事务成功完成通过UserTransaction.commit()方法提交,事务失败通过UserTransaction.rollback()方法回滚。
2.2 基本事务属性的定义
上面讲到的事务管理器接口PlatformTransactionManager通过getTransaction(TransactionDefinition definition)方法来得到事务,这个方法里面的参数是TransactionDefinition类,这个类就定义了一些基本的事务属性。
那么什么是事务属性呢?事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性包含了5个方面,如图所示:

而TransactionDefinition接口内容如下:
public interface TransactionDefinition {
int getPropagationBehavior(); // 返回事务的传播行为
int getIsolationLevel(); // 返回事务的隔离级别,事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
int getTimeout(); // 返回事务必须在多少秒内完成
boolean isReadOnly(); // 事务是否只读,事务管理器能够根据这个返回值进行优化,确保事务是只读的
}
我们可以发现TransactionDefinition正好用来定义事务属性,下面详细介绍一下各个事务属性。
2.2.1 传播行为
事务的第一个方面是传播行为(propagation behavior)。当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。Spring定义了七种传播行为:
| 行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_REQUIRED_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
(1)PROPAGATION_REQUIRED
如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
//事务属性 PROPAGATION_REQUIRED
methodA{
……
methodB();
……
}
//事务属性 PROPAGATION_REQUIRED
methodB{
……
}
使用spring声明式事务,spring使用AOP来支持声明式事务,会根据事务属性,自动在方法调用之前决定是否开启一个事务,并在方法执行之后决定事务提交或回滚事务。
单独调用methodB方法:
main{
metodB();
}
相当于
main{
Connection con=null;
try{
con = getConnection();
con.setAutoCommit(false);
//方法调用
methodB();
//提交事务
con.commit();
} Catch(RuntimeException ex) {
//回滚事务
con.rollback();
} finally {
//释放资源
closeCon();
}
}
Spring保证在methodB方法中所有的调用都获得到一个相同的连接。在调用methodB时,没有一个存在的事务,所以获得一个新的连接,开启了一个新的事务。
单独调用MethodA时,在MethodA内又会调用MethodB.
执行效果相当于:
main{
Connection con = null;
try{
con = getConnection();
methodA();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
closeCon();
}
}
调用MethodA时,环境中没有事务,所以开启一个新的事务.当在MethodA中调用MethodB时,环境中已经有了一个事务,所以methodB就加入当前事务。
(2)PROPAGATION_SUPPORTS
如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。但是对于事务同步的事务管理器,PROPAGATION_SUPPORTS与不使用事务有少许不同。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_SUPPORTS
methodB(){
……
}
单纯的调用methodB时,methodB方法是非事务的执行的。当调用methdA时,methodB则加入了methodA的事务中,事务地执行。
(3)PROPAGATION_MANDATORY
如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_MANDATORY
methodB(){
……
}
当单独调用methodB时,因为当前没有一个活动的事务,则会抛出异常throw new IllegalTransactionStateException(“Transaction propagation ‘mandatory’ but no existing transaction found”);当调用methodA时,methodB则加入到methodA的事务中,事务地执行。
(4)PROPAGATION_REQUIRES_NEW
总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_REQUIRES_NEW
methodB(){
……
}
调用A方法:
main(){
methodA();
}
相当于
main(){
TransactionManager tm = null;
try{
//获得一个JTA事务管理器
tm = getTransactionManager();
tm.begin();//开启一个新的事务
Transaction ts1 = tm.getTransaction();
doSomeThing();
tm.suspend();//挂起当前事务
try{
tm.begin();//重新开启第二个事务
Transaction ts2 = tm.getTransaction();
methodB();
ts2.commit();//提交第二个事务
} Catch(RunTimeException ex) {
ts2.rollback();//回滚第二个事务
} finally {
//释放资源
}
//methodB执行完后,恢复第一个事务
tm.resume(ts1);
doSomeThingB();
ts1.commit();//提交第一个事务
} catch(RunTimeException ex) {
ts1.rollback();//回滚第一个事务
} finally {
//释放资源
}
}
在这里,我把ts1称为外层事务,ts2称为内层事务。从上面的代码可以看出,ts2与ts1是两个独立的事务,互不相干。Ts2是否成功并不依赖于 ts1。如果methodA方法在调用methodB方法后的doSomeThingB方法失败了,而methodB方法所做的结果依然被提交。而除了 methodB之外的其它代码导致的结果却被回滚了。使用PROPAGATION_REQUIRES_NEW,需要使用 JtaTransactionManager作为事务管理器。
(5)PROPAGATION_NOT_SUPPORTED
总是非事务地执行,并挂起任何存在的事务。使用PROPAGATION_NOT_SUPPORTED,也需要使用JtaTransactionManager作为事务管理器。(代码示例同上,可同理推出)
(6)PROPAGATION_NEVER
总是非事务地执行,如果存在一个活动事务,则抛出异常。
(7)PROPAGATION_NESTED
如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行。这是一个嵌套事务,使用JDBC 3.0驱动时,仅仅支持DataSourceTransactionManager作为事务管理器。需要JDBC 驱动的java.sql.Savepoint类。有一些JTA的事务管理器实现可能也提供了同样的功能。使用PROPAGATION_NESTED,还需要把PlatformTransactionManager的nestedTransactionAllowed属性设为true;而 nestedTransactionAllowed属性值默认为false。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_NESTED
methodB(){
……
}
如果单独调用methodB方法,则按REQUIRED属性执行。如果调用methodA方法,相当于下面的效果:
main(){
Connection con = null;
Savepoint savepoint = null;
try{
con = getConnection();
con.setAutoCommit(false);
doSomeThingA();
savepoint = con2.setSavepoint();
try{
methodB();
} catch(RuntimeException ex) {
con.rollback(savepoint);
} finally {
//释放资源
}
doSomeThingB();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
//释放资源
}
}
当methodB方法调用之前,调用setSavepoint方法,保存当前的状态到savepoint。如果methodB方法调用失败,则恢复到之前保存的状态。但是需要注意的是,这时的事务并没有进行提交,如果后续的代码(doSomeThingB()方法)调用失败,则回滚包括methodB方法的所有操作。
嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:它们非常类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。使用 PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。同时它需要JTA事务管理器的支持。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。DataSourceTransactionManager使用savepoint支持PROPAGATION_NESTED时,需要JDBC 3.0以上驱动及1.4以上的JDK版本支持。其它的JTA TrasactionManager实现可能有不同的支持方式。
PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 “内部” 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行。
另一方面, PROPAGATION_NESTED 开始一个 “嵌套的” 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交。
由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于, PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 嵌套事务也会被 commit, 这个规则同样适用于 roll back.
PROPAGATION_REQUIRED应该是我们首先的事务传播行为。它能够满足我们大多数的事务需求。
2.2.2 隔离级别
事务的第二个维度就是隔离级别(isolation level)。隔离级别定义了一个事务可能受其他并发事务影响的程度。
(1)并发事务引起的问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务。并发虽然是必须的,但可能会导致一下的问题。
- 脏读(Dirty reads)——脏读发生在一个事务读取了另一个事务改写但尚未提交的数据时。如果改写在稍后被回滚了,那么第一个事务获取的数据就是无效的。
- 不可重复读(Nonrepeatable read)——不可重复读发生在一个事务执行相同的查询两次或两次以上,但是每次都得到不同的数据时。这通常是因为另一个并发事务在两次查询期间进行了更新。
- 幻读(Phantom read)——幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录。
不可重复读与幻读的区别
不可重复读的重点是修改:
同样的条件, 你读取过的数据, 再次读取出来发现值不一样了
例如:在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
con1 = getConnection();
select salary from employee empId ="Mary";
在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
con2 = getConnection();
update employee set salary = 2000;
con2.commit();
在事务1中,Mary 再次读取自己的工资时,工资变为了2000
//con1
select salary from employee empId ="Mary";
在一个事务中前后两次读取的结果并不一致,导致了不可重复读。
幻读的重点在于新增或者删除:
同样的条件, 第1次和第2次读出来的记录数不一样
例如:目前工资为1000的员工有10人。事务1,读取所有工资为1000的员工。
con1 = getConnection();
Select * from employee where salary =1000;
共读取10条记录
这时另一个事务向employee表插入了一条员工记录,工资也为1000
con2 = getConnection();
Insert into employee(empId,salary) values("Lili",1000);
con2.commit();
事务1再次读取所有工资为1000的员工
//con1
select * from employee where salary =1000;
共读取到了11条记录,这就产生了幻像读。
从总的结果来看, 似乎不可重复读和幻读都表现为两次读取的结果不一致。但如果你从控制的角度来看, 两者的区别就比较大。
对于前者, 只需要锁住满足条件的记录。
对于后者, 要锁住满足条件及其相近的记录。
(2)隔离级别
| 隔离级别 | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 |
| ISOLATION_READ_COMMITTED | 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 |
| ISOLATION_REPEATABLE_READ | 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生 |
| ISOLATION_SERIALIZABLE | 最高的隔离级别,完全服从ACID的隔离级别,确保阻止脏读、不可重复读以及幻读,也是最慢的事务隔离级别,因为它通常是通过完全锁定事务相关的数据库表来实现的 |
2.2.3 只读
事务的第三个特性是它是否为只读事务。如果事务只对后端的数据库进行该操作,数据库可以利用事务的只读特性来进行一些特定的优化。通过将事务设置为只读,你就可以给数据库一个机会,让它应用它认为合适的优化措施。
2.2.4 事务超时
为了使应用程序很好地运行,事务不能运行太长的时间。因为事务可能涉及对后端数据库的锁定,所以长时间的事务会不必要的占用数据库资源。事务超时就是事务的一个定时器,在特定时间内事务如果没有执行完毕,那么就会自动回滚,而不是一直等待其结束。
2.2.5 回滚规则
事务五边形的最后一个方面是一组规则,这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚(这一行为与EJB的回滚行为是一致的)
但是你可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚。同样,你还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
2.3 事务状态
上面讲到的调用PlatformTransactionManager接口的getTransaction()的方法得到的是TransactionStatus接口的一个实现,这个接口的内容如下:
public interface TransactionStatus{
boolean isNewTransaction(); // 是否是新的事物
boolean hasSavepoint(); // 是否有恢复点
void setRollbackOnly(); // 设置为只回滚
boolean isRollbackOnly(); // 是否为只回滚
boolean isCompleted; // 是否已完成
}
可以发现这个接口描述的是一些处理事务提供简单的控制事务执行和查询事务状态的方法,在回滚或提交的时候需要应用对应的事务状态。
3 编程式事务
3.1 编程式和声明式事务的区别
Spring提供了对编程式事务和声明式事务的支持,编程式事务允许用户在代码中精确定义事务的边界,而声明式事务(基于AOP)有助于用户将操作与事务规则进行解耦。
简单地说,编程式事务侵入到了业务代码里面,但是提供了更加详细的事务管理;而声明式事务由于基于AOP,所以既能起到事务管理的作用,又可以不影响业务代码的具体实现。
3.2 如何实现编程式事务?
Spring提供两种方式的编程式事务管理,分别是:使用TransactionTemplate和直接使用PlatformTransactionManager。
3.2.1 使用TransactionTemplate采用TransactionTemplate和采用其他Spring模板,如JdbcTempalte和HibernateTemplate是一样的方法。它使用回调方法,把应用程序从处理取得和释放资源中解脱出来。如同其他模板,TransactionTemplate是线程安全的。代码片段:
TransactionTemplate tt = new TransactionTemplate(); // 新建一个TransactionTemplate
Object result = tt.execute(
new TransactionCallback(){
public Object doTransaction(TransactionStatus status){
updateOperation();
return resultOfUpdateOperation();
}
}); // 执行execute方法进行事务管理
使用TransactionCallback()可以返回一个值。如果使用TransactionCallbackWithoutResult则没有返回值。
3.2.2 使用PlatformTransactionManager
示例代码如下:
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); //定义一个某个框架平台的TransactionManager,如JDBC、Hibernate
dataSourceTransactionManager.setDataSource(this.getJdbcTemplate().getDataSource()); // 设置数据源
DefaultTransactionDefinition transDef = new DefaultTransactionDefinition(); // 定义事务属性
transDef.setPropagationBehavior(DefaultTransactionDefinition.PROPAGATION_REQUIRED); // 设置传播行为属性
TransactionStatus status = dataSourceTransactionManager.getTransaction(transDef); // 获得事务状态
try {
// 数据库操作
dataSourceTransactionManager.commit(status);// 提交
} catch (Exception e) {
dataSourceTransactionManager.rollback(status);// 回滚
}
4 声明式事务
4.1 配置方式
根据代理机制的不同,总结了五种Spring事务的配置方式,配置文件如下:
(1)每个Bean都有一个代理
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd">
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation" value="classpath:hibernate.cfg.xml" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration" />
</bean>
<!-- 定义事务管理器(声明式的事务) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<!-- 配置DAO -->
<bean id="userDaoTarget" class="com.bluesky.spring.dao.UserDaoImpl">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="userDao"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<!-- 配置事务管理器 -->
<property name="transactionManager" ref="transactionManager" />
<property name="target" ref="userDaoTarget" />
<property name="proxyInterfaces" value="com.bluesky.spring.dao.GeneratorDao" />
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
</beans>
(2)所有Bean共享一个代理基类
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd">
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation" value="classpath:hibernate.cfg.xml" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration" />
</bean>
<!-- 定义事务管理器(声明式的事务) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="transactionBase"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean"
lazy-init="true" abstract="true">
<!-- 配置事务管理器 -->
<property name="transactionManager" ref="transactionManager" />
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
<!-- 配置DAO -->
<bean id="userDaoTarget" class="com.bluesky.spring.dao.UserDaoImpl">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="userDao" parent="transactionBase" >
<property name="target" ref="userDaoTarget" />
</bean>
</beans>
(3)使用拦截器
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd">
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation" value="classpath:hibernate.cfg.xml" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration" />
</bean>
<!-- 定义事务管理器(声明式的事务) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<bean id="transactionInterceptor"
class="org.springframework.transaction.interceptor.TransactionInterceptor">
<property name="transactionManager" ref="transactionManager" />
<!-- 配置事务属性 -->
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
<bean class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
<property name="beanNames">
<list>
<value>*Dao</value>
</list>
</property>
<property name="interceptorNames">
<list>
<value>transactionInterceptor</value>
</list>
</property>
</bean>
<!-- 配置DAO -->
<bean id="userDao" class="com.bluesky.spring.dao.UserDaoImpl">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
</beans>
(4)使用tx标签配置的拦截器
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="com.bluesky" />
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation" value="classpath:hibernate.cfg.xml" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration" />
</bean>
<!-- 定义事务管理器(声明式的事务) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED" />
</tx:attributes>
</tx:advice>
<aop:config>
<aop:pointcut id="interceptorPointCuts"
expression="execution(* com.bluesky.spring.dao.*.*(..))" />
<aop:advisor advice-ref="txAdvice"
pointcut-ref="interceptorPointCuts" />
</aop:config>
</beans>
(5)全注解
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="com.bluesky" />
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation" value="classpath:hibernate.cfg.xml" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration" />
</bean>
<!-- 定义事务管理器(声明式的事务) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
</beans>
此时在DAO上需加上@Transactional注解,如下:
package com.bluesky.spring.dao;
import java.util.List;
import org.hibernate.SessionFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.orm.hibernate3.support.HibernateDaoSupport;
import org.springframework.stereotype.Component;
import com.bluesky.spring.domain.User;
@Transactional
@Component("userDao")
public class UserDaoImpl extends HibernateDaoSupport implements UserDao {
public List<User> listUsers() {
return this.getSession().createQuery("from User").list();
}
}
4.2 一个声明式事务的实例
首先是数据库表
book(isbn, book_name, price)
account(username, balance)
book_stock(isbn, stock)
然后是XML配置
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<import resource="applicationContext-db.xml" />
<context:component-scan base-package="com.springinaction.transaction"/>
<tx:annotation-driven transaction-manager="txManager"/>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
</beans>
使用的类
BookShopDao
package com.springinaction.transaction;
public interface BookShopDao {
// 根据书号获取书的单价
public int findBookPriceByIsbn(String isbn);
// 更新书的库存,使书号对应的库存-1
public void updateBookStock(String isbn);
// 更新用户的账户余额:account的balance-price
public void updateUserAccount(String username, int price);
}
BookShopDaoImpl
package com.springinaction.transaction;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
@Repository("bookShopDao")
public class BookShopDaoImpl implements BookShopDao {
@Autowired
private JdbcTemplate JdbcTemplate;
@Override
public int findBookPriceByIsbn(String isbn) {
String sql = "SELECT price FROM book WHERE isbn = ?";
return JdbcTemplate.queryForObject(sql, Integer.class, isbn);
}
@Override
public void updateBookStock(String isbn) {
//检查书的库存是否足够,若不够,则抛出异常
String sql2 = "SELECT stock FROM book_stock WHERE isbn = ?";
int stock = JdbcTemplate.queryForObject(sql2, Integer.class, isbn);
if (stock == 0) {
throw new BookStockException("库存不足!");
}
String sql = "UPDATE book_stock SET stock = stock - 1 WHERE isbn = ?";
JdbcTemplate.update(sql, isbn);
}
@Override
public void updateUserAccount(String username, int price) {
//检查余额是否不足,若不足,则抛出异常
String sql2 = "SELECT balance FROM account WHERE username = ?";
int balance = JdbcTemplate.queryForObject(sql2, Integer.class, username);
if (balance < price) {
throw new UserAccountException("余额不足!");
}
String sql = "UPDATE account SET balance = balance - ? WHERE username = ?";
JdbcTemplate.update(sql, price, username);
}
}
BookShopService
package com.springinaction.transaction;
public interface BookShopService {
public void purchase(String username, String isbn);
}
BookShopServiceImpl
package com.springinaction.transaction;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Isolation;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@Service("bookShopService")
public class BookShopServiceImpl implements BookShopService {
@Autowired
private BookShopDao bookShopDao;
/**
* 1.添加事务注解
* 使用propagation 指定事务的传播行为,即当前的事务方法被另外一个事务方法调用时如何使用事务。
* 默认取值为REQUIRED,即使用调用方法的事务
* REQUIRES_NEW:使用自己的事务,调用的事务方法的事务被挂起。
*
* 2.使用isolation 指定事务的隔离级别,最常用的取值为READ_COMMITTED
* 3.默认情况下 Spring 的声明式事务对所有的运行时异常进行回滚,也可以通过对应的属性进行设置。通常情况下,默认值即可。
* 4.使用readOnly 指定事务是否为只读。 表示这个事务只读取数据但不更新数据,这样可以帮助数据库引擎优化事务。若真的是一个只读取数据库值得方法,应设置readOnly=true
* 5.使用timeOut 指定强制回滚之前事务可以占用的时间。
*/
@Transactional(propagation=Propagation.REQUIRES_NEW,
isolation=Isolation.READ_COMMITTED,
noRollbackFor={UserAccountException.class},
readOnly=true, timeout=3)
@Override
public void purchase(String username, String isbn) {
//1.获取书的单价
int price = bookShopDao.findBookPriceByIsbn(isbn);
//2.更新书的库存
bookShopDao.updateBookStock(isbn);
//3.更新用户余额
bookShopDao.updateUserAccount(username, price);
}
}
Cashier
package com.springinaction.transaction;
import java.util.List;
public interface Cashier {
public void checkout(String username, List<String>isbns);
}
CashierImpl:CashierImpl.checkout和bookShopService.purchase联合测试了事务的传播行为
package com.springinaction.transaction;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service("cashier")
public class CashierImpl implements Cashier {
@Autowired
private BookShopService bookShopService;
@Transactional
@Override
public void checkout(String username, List<String> isbns) {
for(String isbn : isbns) {
bookShopService.purchase(username, isbn);
}
}
}
BookStockException
package com.springinaction.transaction;
public class BookStockException extends RuntimeException {
private static final long serialVersionUID = 1L;
public BookStockException() {
super();
// TODO Auto-generated constructor stub
}
public BookStockException(String arg0, Throwable arg1, boolean arg2,
boolean arg3) {
super(arg0, arg1, arg2, arg3);
// TODO Auto-generated constructor stub
}
public BookStockException(String arg0, Throwable arg1) {
super(arg0, arg1);
// TODO Auto-generated constructor stub
}
public BookStockException(String arg0) {
super(arg0);
// TODO Auto-generated constructor stub
}
public BookStockException(Throwable arg0) {
super(arg0);
// TODO Auto-generated constructor stub
}
}
UserAccountException
package com.springinaction.transaction;
public class UserAccountException extends RuntimeException {
private static final long serialVersionUID = 1L;
public UserAccountException() {
super();
// TODO Auto-generated constructor stub
}
public UserAccountException(String arg0, Throwable arg1, boolean arg2,
boolean arg3) {
super(arg0, arg1, arg2, arg3);
// TODO Auto-generated constructor stub
}
public UserAccountException(String arg0, Throwable arg1) {
super(arg0, arg1);
// TODO Auto-generated constructor stub
}
public UserAccountException(String arg0) {
super(arg0);
// TODO Auto-generated constructor stub
}
public UserAccountException(Throwable arg0) {
super(arg0);
// TODO Auto-generated constructor stub
}
}
测试类
复制代码
package com.springinaction.transaction;
import java.util.Arrays;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class SpringTransitionTest {
private ApplicationContext ctx = null;
private BookShopDao bookShopDao = null;
private BookShopService bookShopService = null;
private Cashier cashier = null;
{
ctx = new ClassPathXmlApplicationContext("config/transaction.xml");
bookShopDao = ctx.getBean(BookShopDao.class);
bookShopService = ctx.getBean(BookShopService.class);
cashier = ctx.getBean(Cashier.class);
}
@Test
public void testBookShopDaoFindPriceByIsbn() {
System.out.println(bookShopDao.findBookPriceByIsbn("1001"));
}
@Test
public void testBookShopDaoUpdateBookStock(){
bookShopDao.updateBookStock("1001");
}
@Test
public void testBookShopDaoUpdateUserAccount(){
bookShopDao.updateUserAccount("AA", 100);
}
@Test
public void testBookShopService(){
bookShopService.purchase("AA", "1001");
}
@Test
public void testTransactionPropagation(){
cashier.checkout("AA", Arrays.asList("1001", "1002"));
}
}
Spring事务管理及几种简单的实现
事务是逻辑上的一组操作,这组操作要么全部成功,要么全部失败,最为典型的就是银行转账的案例:
A要向B转账,现在A,B各自账户中有1000元,A要给B转200元,那么这个转账就必须保证是一个事务,防止中途因为各种原因导致A账户资金减少而B账户资金未添加,或者B账户资金添加而A账户资金未减少,这样不是用户有损失就是银行有损失,为了保证转账前后的一致性就必须保证转账操作是一个事务。
事务具有的ACID特性
首先,这篇文章先提及一些Spring中事务有关的API,然后分别实现编程式事务管理和声明式事务管理,其中声明式事务管理分别使用基于TransactionProxyFactoryBean的方式、基于AspectJ的XML方式、基于注解方式进行实现。
首先,我们简单看一下Spring事务管理需要提及的接口,Spring事务管理高层抽象主要包括3个接口
PlatformTransactionManager :事务管理器(用来管理事务,包含事务的提交,回滚)
TransactionDefinition :事务定义信息(隔离,传播,超时,只读)
TransactionStatus :事务具体运行状态
Spring根据事务定义信息(TransactionDefinition)由平台事务管理器(PlatformTransactionManager)真正进行事务的管理,在进行事务管理的过程中,事务会产生运行状态,状态保存在TransactionStatus中
PlatformTransactionManager:
Spring为不同的持久化框架提供了不同的PlatformTransactionManager如:
在使用Spring JDBC或iBatis进行持久化数据时,采用DataSourceTransactionManager
在使用Hibernate进行持久化数据时使用HibernateTransactionManager
TransactionDefinition:
TransactionDefinition接口中定义了一组常量,包括事务的隔离级别,事务的传播行为,超时信息,其中还定义了一些方法,可获得事务的隔离级别,超时信息,是否只读。
传播行为主要解决业务层方法之间的相互调用产生的事务应该如何传递的问题。
TransactionDefinition中定义的属性常量如下:
| Field(属性) | Description(描述) |
|---|---|
| ISOLATION_DEFAULT | 使用底层数据存储的默认隔离级别 |
| ISOLATION_READ_COMMITTED | 表示防止脏读;可能会发生不可重复的读取和幻像读取 |
| ISOLATION_READ_UNCOMMITTED | 表示可能会发生脏读,不可重复的读取和幻像读取 |
| ISOLATION_REPEATABLE_READ | 表示禁止脏读和不可重复读;可以发生幻影读取 |
| ISOLATION_SERIALIZABLE | 表示可以防止脏读,不可重复的读取和幻像读取 |
| PROPAGATION_MANDATORY | 支持当前交易;如果不存在当前事务,则抛出异常 |
| PROPAGATION_NESTED | 如果当前事务存在,则在嵌套事务中执行,其行为类似于PROPAGATION_REQUIRED |
| PROPAGATION_NEVER | 不支持当前交易;如果当前事务存在,则抛出异常 |
| PROPAGATION_NOT_SUPPORTED | 不支持当前交易;而是总是非事务地执行 |
| PROPAGATION_REQUIRED | 支持当前交易;如果不存在,创建一个新的 |
| PROPAGATION_REQUIRES_NEW | 创建一个新的事务,挂起当前事务(如果存在) |
| PROPAGATION_SUPPORTS | 支持当前交易;如果不存在,则执行非事务性的 |
| TIMEOUT_DEFAULT | 使用底层事务系统的默认超时,如果不支持超时,则为none |
TransationStatus:
在该接口中提供了一些方法:
| Method | Description |
|---|---|
| flush() | 将基础会话刷新到数据存储(如果适用):例如,所有受影响的Hibernate / JPA会话 |
| hasSavepoint() | 返回此事务是否内部携带保存点,也就是基于保存点创建为嵌套事务 |
| isCompleted() | 返回此事务是否完成,即是否已经提交或回滚 |
| isNewTransaction() | 返回当前交易是否是新的(否则首先参与现有交易,或者潜在地不会在实际交易中运行) |
| isRollbackOnly() | 返回事务是否已被标记为仅回滚(由应用程序或由事务基础结构) |
| setRollbackOnly() | 设置事务回滚 |
了解了上述接口,接下来我们通过转账案例来实现Spring的事务管理:
数据库中account表如下:
| id | name | money |
|---|---|---|
| 1 | aaa | 1000 |
| 2 | bbb | 1000 |
| 3 | ccc | 1000 |
| … | … | … |
1.编程式事务管理实现:
AccountDao.java:
package com.spring.demo1;
public interface AccountDao {
public void outMoney(String out, Double money);
public void inMoney(String in, Double money);
}
AccountDaoImp.java
package com.spring.demo1;
import org.springframework.jdbc.core.support.JdbcDaoSupport;
public class AccountDaoImp extends JdbcDaoSupport implements AccountDao {
public void outMoney(String out, Double money) {
String sql = "update account set money = money - ? where name = ?";
this.getJdbcTemplate().update(sql, money, out);
}
public void inMoney(String in, Double money) {
String sql = "update account set money = money + ? where name = ?";
this.getJdbcTemplate().update(sql, money, in);
}
}
AccountService.java
package com.spring.demo1;
public interface AccountService {
public void transfer(String out, String in, Double money);
}
AccountServiceImp.java
package com.spring.demo1;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallbackWithoutResult;
import org.springframework.transaction.support.TransactionTemplate;
public class AccountServiceImp implements AccountService{
private AccountDao accountDao;
// 注入事务管理的模板
private TransactionTemplate transactionTemplate;
public void setTransactionTemplate(TransactionTemplate transactionTemplate) {
this.transactionTemplate = transactionTemplate;
}
public void setAccountDao(AccountDao accountDao) {
this.accountDao = accountDao;
}
public void transfer(final String out, final String in, final Double money) {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
accountDao.outMoney(out, money);
//此处除0模拟转账发生异常
int i = 1 / 0;
accountDao.inMoney(in, money);
}
});
}
}
package com.spring.demo1;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallbackWithoutResult;
import org.springframework.transaction.support.TransactionTemplate;
public class AccountServiceImp implements AccountService{
private AccountDao accountDao;
// 注入事务管理的模板
private TransactionTemplate transactionTemplate;
public void setTransactionTemplate(TransactionTemplate transactionTemplate) {
this.transactionTemplate = transactionTemplate;
}
public void setAccountDao(AccountDao accountDao) {
this.accountDao = accountDao;
}
public void transfer(final String out, final String in, final Double money) {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
accountDao.outMoney(out, money);
int i = 1 / 0;
accountDao.inMoney(in, money);
}
});
}
}
创建Spring配置文件applicationContext.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:jdbc.properties"/>
<!--配置c3p0连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.Driver}"/>
<property name="jdbcUrl" value="${jdbc.URL}"/>
<property name="user" value="${jdbc.USERNAME}"/>
<property name="password" value="${jdbc.PASSWD}"/>
</bean>
<!--配置业务层类-->
<bean id="accountService" class="com.spring.demo1.AccountServiceImp">
<property name="accountDao" ref="accountDao"/>
<property name="transactionTemplate" ref="transactionTemplate"/>
</bean>
<!--配置Dao的类-->
<bean id="accountDao" class="com.spring.demo1.AccountDaoImp">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置事务管理模板,Spring为了简化事务管理的代码而提供的类-->
<bean id="transactionTemplate" class="org.springframework.transaction.support.TransactionTemplate">
<property name="transactionManager" ref="transactionManager"/>
</bean>
</beans>
编写测试类如下:
SpringDemoTest1.java
import com.spring.demo1.AccountService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.context.annotation.Configuration;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import javax.annotation.Resource;
/**
* Spring编程式事务管理
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext.xml")
public class SpringDemoTest1 {
@Resource(name = "accountService")
private AccountService accountService;
@Test
public void demo1(){
accountService.transfer("aaa", "bbb", 200d);
}
}
2.基于TransactionProxyFactoryBean的声明式事务管理
Dao与Service代码与1中相同,applicationContext2.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:jdbc.properties"/>
<!--配置c3p0连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.Driver}"/>
<property name="jdbcUrl" value="${jdbc.URL}"/>
<property name="user" value="${jdbc.USERNAME}"/>
<property name="password" value="${jdbc.PASSWD}"/>
</bean>
<!--配置业务层类-->
<bean id="accountService" class="com.spring.demo2.AccountServiceImp">
<property name="accountDao" ref="accountDao"/>
</bean>
<!--配置Dao的类-->
<bean id="accountDao" class="com.spring.demo2.AccountDaoImp">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置业务层代理-->
<bean id="accountServiceProxy" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<!--配置目标对象-->
<property name="target" ref="accountService"/>
<!--注入事务管理器-->
<property name="transactionManager" ref="transactionManager"/>
<!--注入事务的属性-->
<property name="transactionAttributes">
<props>
<!--
prop格式
* PROPAGATION :事务的传播行为
* ISOLATION :事务的隔离级别
* readOnly :只读(不可以进行修改,插入,删除的操作)
* -Exception :发生哪些异常回滚事务
* +Exception :发生哪些异常不回滚事务
-->
<prop key="transfer">PROPAGATION_REQUIRED</prop>
<!--<prop key="transfer">PROPAGATION_REQUIRED,readOnly</prop>-->
<!--<prop key="transfer">PROPAGATION_REQUIRED, +java.lang.ArithmeticException</prop>-->
</props>
</property>
</bean>
</beans>
此时注入时需要选择代理类,因为在代理类中进行增强操作,测试代码如下:
SpringDemoTest2.java
import com.spring.demo2.AccountService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import javax.annotation.Resource;
/**
* Spring声明式事务管理:基于TransactionProxyFactoryBean的方式
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext2.xml")
public class SpringDemoTest2 {
/**
*此时需要注入代理类:因为代理类进行增强操作
*/
// @Resource(name = "accountService")
@Resource(name = "accountServiceProxy")
private AccountService accountService;
@Test
public void demo1(){
accountService.transfer("aaa", "bbb", 200d);
}
}
3.基于AspectJ的XML声明式事务管理
在这种方式下Dao和Service的代码也没有改变,applicationContext3.xml如下:
applicationContext3.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.1.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.1.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.1.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task-3.1.xsd">
<context:property-placeholder location="classpath:jdbc.properties"/>
<!--配置c3p0连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.Driver}"/>
<property name="jdbcUrl" value="${jdbc.URL}"/>
<property name="user" value="${jdbc.USERNAME}"/>
<property name="password" value="${jdbc.PASSWD}"/>
</bean>
<!--配置业务层类-->
<bean id="accountService" class="com.spring.demo3.AccountServiceImp">
<property name="accountDao" ref="accountDao"/>
</bean>
<!--配置Dao的类-->
<bean id="accountDao" class="com.spring.demo3.AccountDaoImp">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置事务的通知:(事务的增强)-->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!--
propagation :事务传播行为
isolation :事务的隔离级别
read-only :只读
rollback-for :发生哪些异常回滚
no-rollback-for :发生哪些异常不回滚
timeout :过期信息
-->
<tx:method name="transfer" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!--配置切面-->
<aop:config>
<!--配置切入点-->
<aop:pointcut id="pointcut1" expression="execution(* com.spring.demo3.AccountService+.*(..))"/>
<!--配置切面-->
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut1"/>
</aop:config>
</beans>
测试类与1中相同,增强是动态织入的,所以此时注入的还是accountService。
4.基于注解的声明式事务管理
基于注解的方式需要在业务层上添加一个@Transactional的注解。
如下:
AccountServiceImp.java
package com.spring.demo4;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
/**
* propagation :事务的传播行为
* isolation :事务的隔离级别
* readOnly :只读
* rollbackFor :发生哪些异常回滚
*/
@Transactional(propagation = Propagation.REQUIRED)
public class AccountServiceImp implements AccountService {
private AccountDao accountDao;
public void setAccountDao(AccountDao accountDao) {
this.accountDao = accountDao;
}
public void transfer(String out, String in, Double money) {
accountDao.outMoney(out, money);
int i = 1 / 0;
accountDao.inMoney(in, money);
}
}
此时需要在Spring配置文件中开启注解事务,打开事务驱动
applicationContext4.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.1.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.1.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.1.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task-3.1.xsd">
<context:property-placeholder location="classpath:jdbc.properties"/>
<!--配置c3p0连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.Driver}"/>
<property name="jdbcUrl" value="${jdbc.URL}"/>
<property name="user" value="${jdbc.USERNAME}"/>
<property name="password" value="${jdbc.PASSWD}"/>
</bean>
<!--配置业务层类-->
<bean id="accountService" class="com.spring.demo4.AccountServiceImp">
<property name="accountDao" ref="accountDao"/>
</bean>
<!--配置Dao的类-->
<bean id="accountDao" class="com.spring.demo4.AccountDaoImp">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--配置事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!--开启注解事务 打开事务驱动-->
<tx:annotation-driven transaction-manager="transactionManager"/>
</beans>
测试类与1中相同
JDBC如何实现事务
在jdbc中处理事务,都是通过Connection完成的!
同一事务中所有的操作,都在使用同一个Connection对象!
JDBC中的事务
Connection的三个方法与事务相关:
- setAutoCommit(boolean):设置是否为自动提交事务,如果true(默认值就是true)表示自动提交,也就是每条执行的SQL语句都是一个单独的事务,如果设置false,那么就相当于开启了事务了;
con.setAutoCommit(false)表示开启事务!!! - commit():提交结束事务;
con.commit();表示提交事务 - rollback():回滚结束事务。
con.rollback();表示回滚事务
jdbc处理事务的代码格式:
try {
con.setAutoCommit(false);//开启事务…
….
…
con.commit();//try的最后提交事务
} catch() {
con.rollback();//回滚事务
}
嵌套事务实现
spring 事务嵌套:
外层事务TraB,内层事务TraA、TraC
场景1:
TraA、TraC @Transactional(默认REQUIRED)
TraB:
traA.update(order1); (traA.update throw new RuntimeException();)
traC.update(order2);
结果:内外层事务全部回滚;
场景2:
TraA、TraC @Transactional(默认REQUIRED)
TraB:
traA.update(order1); (traA.update throw new RuntimeException();try catch traC.update)
traC.update(order2);
结果:内外层事务全部不回滚,traA中try catch后的事务提交;
场景3:
TraA、TraC @Transactional(默认REQUIRED)
TraB: try{(traA.update throw new RuntimeException();
在外层TraB try catch TraA)
traA.update(order1);
}catch(){}
traC.update(order2);
结果:内外层事务全部回滚,内层的异常抛出到外层捕获也会回滚;
场景4:
TraA @Transactional(propagation=Propagation.REQUIRES_NEW)、TraC @Transactional(默认REQUIRED)
TraB:
traA.update(order1); (traA.update throw new RuntimeException();)
traC.update(order2);
结果:内层事务回滚,外层事务继续提交;
场景5:
TraA @Transactional(propagation=Propagation.REQUIRES_NEW)、TraC @Transactional(默认REQUIRED)
TraB:
traA.update(order1); (traA.update throw new RuntimeException();try catch traC.update)
traC.update(order2);
结果:内外层事务全部不回滚,traA中try catch后的事务提交,达到与场景2的同样效果;
场景6:
TraA @Transactional(propagation=Propagation.REQUIRES_NEW)、TraC @Transactional(默认REQUIRED)
TraB:
try{ (traA.update throw new RuntimeException();在外层TraB try catch TraA)
traA.update(order1);
} catch
traC.update(order2);
结果:内层事务回滚,外层事务不回滚;
Spring事务管理–(二)嵌套事物详解
一、前言
最近开发程序的时候,出现数据库自增id跳数字情况,无奈之下dba遍查操作日志,没有delete记录。才开始慢慢来查询事物问题。多久以来欠下的账,今天该还给spring事物。 希望大家有所收获。
二、spring嵌套事物
1、展示项目代码–简单测springboot项目
整体项目就这么简单,为了方便。这里就只有biz层与service层,主要作为两层嵌套,大家只要看看大概就ok。后面会给出git项目地址,下载下来看一看就明白,力求最简单。
下面我们分情况介绍异常。
Controller 调用层(没有使用它作为外层,因为controller作为外层要在servlet-mvc.xml 配置就ok。但是我觉得比较麻烦,一般也不推荐)
package com.ycy.app;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.context.annotation.ImportResource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class})
@ImportResource({"classpath:/applicationContext.xml"})
public class Application {
@Autowired
private TestBiz testBiz;
@RequestMapping("/")
String home() throws Exception {
System.out.println("controller 正常执行");
testBiz.insetTes();
return " 正常返回Hello World!";
}
public static void main(String[] args) throws Exception {
SpringApplication.run(Application.class, args);
}
}
Biz层(外层).
package com.ycy.app;
import com.ycy.service.TestService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Component
public class TestBiz {
@Autowired
private TestService testService;
@Transactional
public void insetTes() {
for (int j = 0; j < 8; j++) {
testService.testInsert(j, j + "姓名");
}
System.out.println("biz层 正常执行");
}
}
Service层 (内层).
package com.ycy.service.impl;
import com.ycy.center.dao.entity.YcyTable;
import com.ycy.center.dao.mapper.YcyTableMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class TestServiceImpl implements com.ycy.service.TestService {
@Autowired
private YcyTableMapper ycyTableMapper;
@Transactional
public void testInsert(int num,String name) {
YcyTable ycyTable=new YcyTable();
ycyTable.setName(name);
ycyTable.setNum(num);
ycyTableMapper.insert(ycyTable);
System.out.println(num+"service正常执行");
}
}
2、外部起事物,内部起事物,内外都无Try Catch
外部异常:
代码展示,修改外层Biz层代码如下
@Component
public class TestBiz {
@Autowired
private TestService testService;
@Transactional
public void insetTes() {
for (int j = 0; j < 8; j++) {
testService.testInsert(j, j + "姓名");
if (j == 3) {
int i = 1 / 0;// 此处会产生异常
}
}
System.out.println("biz层 正常执行");
}
}
打印执行结果:0-3service正常执行
数据库结果:全部数据回滚
内部异常总结: 内外都无try Catch的时候,内部异常,全部回滚
内部异常:
代码展示,修改service层代码
package com.ycy.service.impl;
import com.ycy.center.dao.entity.YcyTable;
import com.ycy.center.dao.mapper.YcyTableMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class TestServiceImpl implements com.ycy.service.TestService {
@Autowired
private YcyTableMapper ycyTableMapper;
@Transactional
public void testInsert(int num, String name) {
YcyTable ycyTable = new YcyTable();
ycyTable.setName(name);
ycyTable.setNum(num);
ycyTableMapper.insert(ycyTable);
if (num == 3) {
int i = 1 / 0;// 此处会产生异常
}
System.out.println(num + "service正常执行");
}
}
3、外部起事物,内部起事物,外部有Try Catch
外部异常:
代码展示,修改biz层代码
@Component
public class TestBiz {
@Autowired
private TestService testService;
@Transactional
public void insetTes() {
try {
for (int j = 0; j < 8; j++) {
testService.testInsert(j, j + "姓名");
if (j == 3) {
int i = 1 / 0;// 此处会产生异常
}
}
} catch (Exception ex) {
System.out.println("异常日志处理");
}
System.out.println("biz层 正常执行");
}
}
打印结果:0-3执行正常
数据库结果:4条数据
外部异常总结:外部有try Catch时候,外部异常,不能回滚(事物错误)
内部异常:
代码展示,修改service层代码:
@Service
public class TestServiceImpl implements com.ycy.service.TestService {
@Autowired
private YcyTableMapper ycyTableMapper;
@Transactional
public void testInsert(int num, String name) {
YcyTable ycyTable = new YcyTable();
ycyTable.setName(name);
ycyTable.setNum(num);
ycyTableMapper.insert(ycyTable);
if (num == 3) {
int i = 1 / 0;// 此处会产生异常
}
System.out.println(num + "service正常执行");
}
}
打印结果:0-2打印正常
数据库结果:无数据,全部数据回滚
内部异常总结:外部有try Catch时候,内部异常,全部回滚
4、外部起事物,内部起事物,内部有Try Catch
外部异常:
代码展示,修改biz层:
@Component
public class TestBiz {
@Autowired
private TestService testService;
@Transactional
public void insetTes() {
for (int j = 0; j < 8; j++) {
testService.testInsert(j, j + "姓名");
if (j == 3) {
int i = 1 / 0;// 此处会产生异常
}
}
System.out.println("biz层 正常执行");
}
}
打印结果:0-3service打印正常 数据库结果:无数据,全部数据回滚
外部异常总结: 内部有try Catch,外部异常,全部回滚
内部异常:
修改service层代码:
@Service
public class TestServiceImpl implements com.ycy.service.TestService {
@Autowired
private YcyTableMapper ycyTableMapper;
@Transactional
public void testInsert(int num, String name) {
try {
YcyTable ycyTable = new YcyTable();
ycyTable.setName(name);
ycyTable.setNum(num);
ycyTableMapper.insert(ycyTable);
if (num == 3) {
int i = 1 / 0;// 此处会产生异常
}
} catch (Exception ex) {
System.out.println(num + "service异常日志");
}
System.out.println(num + "service正常执行");
}
}
打印结果:0-0service打印正常
数据库结果:没有回滚
内部异常总结: 内部有try Catch,内部异常,全部不回滚(事物失败);
5、外部起事物,内部起事物,内外有Try Catch
外部异常:
代码展示,修改biz层:
@Component
public class TestBiz {
@Autowired
private TestService testService;
@Transactional
public void insetTes() {
try {
for (int j = 0; j < 8; j++) {
testService.testInsert(j, j + "姓名");
if (j == 3) {
int i = 1 / 0;// 此处会产生异常
}
}
} catch (Exception ex) {
System.out.println("biz层异常日志处理");
}
System.out.println("biz层 正常执行");
}
}
打印结果:0-3service打印正常
数据库结果:插入三条数据,没有回滚
外部异常总结: 内外都有try Catch,外部异常,事物执行一半(事物失败)
内部异常:
代码展示,修改service 层代码
@Service
public class TestServiceImpl implements com.ycy.service.TestService {
@Autowired
private YcyTableMapper ycyTableMapper;
@Transactional
public void testInsert(int num, String name) {
try {
YcyTable ycyTable = new YcyTable();
ycyTable.setName(name);
ycyTable.setNum(num);
ycyTableMapper.insert(ycyTable);
if (num == 3) {
int i = 1 / 0;// 此处会产生异常
}
} catch (Exception ex) {
System.out.println(num + "service异常日志处理");
}
System.out.println(num + "service正常执行");
}
}
打印结果:0-7service打印正常,3异常日子好
数据库结果:插入全部,没有回滚
内部事物总结: 内外都有try Catch,内部异常,事物全部不会滚(事物失败)
三、嵌套事物总结
事物成功总结
- 内外都无try Catch的时候,外部异常,全部回滚。
- 内外都无try Catch的时候,内部异常,全部回滚。
- 外部有try Catch时候,内部异常,全部回滚
- 内部有try Catch,外部异常,全部回滚
- 友情提示:外层方法中调取其他接口,或者另外开启线程的操作,一定放到最后!!!(因为调取接口不能回滚,一定要最后来处理)
总结:由于上面的异常被捕获导致,很多事务回滚失败。如果一定要将捕获,请捕获后又抛出
RuntimeException(默认为异常捕获RuntimeException) 。
四、正确的嵌套事物实例
controller层
package com.ycy.app;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.context.annotation.ImportResource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class})
@ImportResource({"classpath:/applicationContext.xml"})
public class Application {
@Autowired
private TestBiz testBiz;
@RequestMapping("/")
String home() {
System.out.println("controller 正常执行");
try {
testBiz.insetTes();
} catch (Exception e) {
System.out.println("controller 异常日志执行");
}
return " 正常返回Hello World!";
}
public static void main(String[] args) throws Exception {
SpringApplication.run(Application.class, args);
}
}
外层biz层:
package com.ycy.app;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import com.ycy.service.TestService;
@Component
public class TestBiz {
@Autowired
private TestService testService;
@Transactional
public void insetTes() throws Exception {
try {
for (int j = 0; j < 8; j++) {
testService.testInsert(j, j + "姓名");
if (j == 3) {
int i = 1 / 0;// 此处会产生异常
}
}
} catch (Exception ex) {
System.out.println("biz层异常日志处理");
throw new RuntimeException(ex);
}
System.out.println("biz层 正常执行");
}
}
内层service层
package com.ycy.service.impl;
import com.ycy.center.dao.entity.YcyTable;
import com.ycy.center.dao.mapper.YcyTableMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class TestServiceImpl implements com.ycy.service.TestService {
@Autowired
private YcyTableMapper ycyTableMapper;
@Transactional
public void testInsert(int num, String name) throws Exception {
try {
YcyTable ycyTable = new YcyTable();
ycyTable.setName(name);
ycyTable.setNum(num);
ycyTableMapper.insert(ycyTable);
if (num== 3) {
int i = 1 / 0;// 此处会产生异常
}
} catch (Exception ex) {
System.out.println(num + "service异常日志处理");
throw new RuntimeException(ex);
}
System.out.println(num + "service正常执行");
}
}