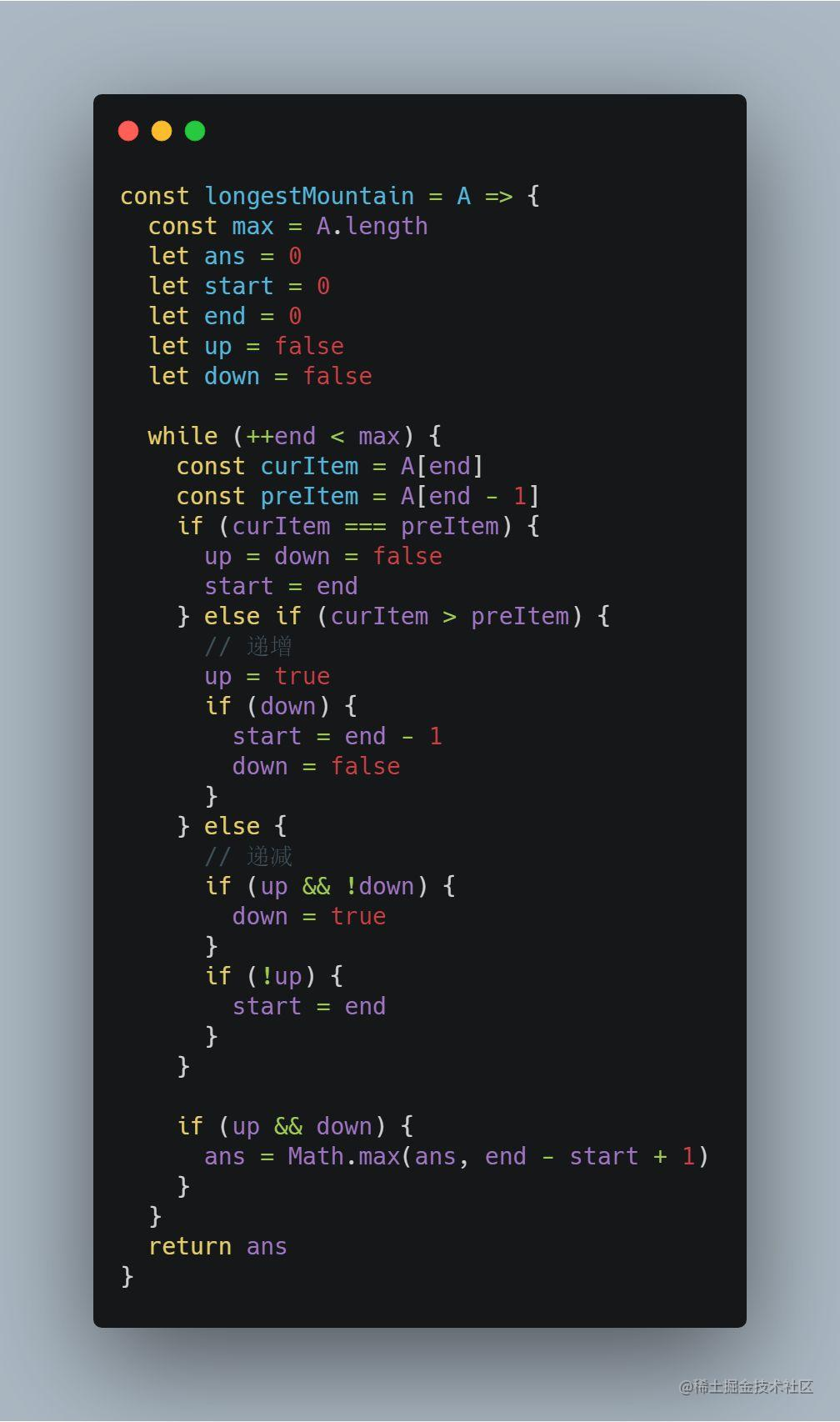
扩散模型原理介绍1
- 一,条件概率公式与高斯分布的KL散度+重参数技巧
- 二,VAE和多层VAE回顾
- 单层VAE的原理公式与置信下界
- 多层VAE的原理公式与置信下界
- 三,Diffusion Model 图示
- 四,扩散过程(Diffusion Process)
- 与VAE的区别:
- 如何设置扩散过程中的 β t \beta_{t} βt
GAN+FLOW+VAE的任务都可以用diffusion model来做
生成模型的5类:
- seq2seq自回归编码
- GAN
- FLOW(数学原理严谨,是个可逆的过程,但需要设计一些巧妙的结构来使得其可解)
- VAE
- Diffusion
一,条件概率公式与高斯分布的KL散度+重参数技巧
-
条件概率的一般形式
P ( A , B , C ) = P ( C ∣ B , A ) P ( B , A ) = P ( C ∣ B , A ) P ( B ∣ A ) P ( A ) P(A,B,C) = P(C|B,A)P(B,A)=P(C|B,A)P(B|A)P(A) P(A,B,C)=P(C∣B,A)P(B,A)=P(C∣B,A)P(B∣A)P(A)
P ( B , C ∣ A ) = P ( B ∣ A ) P ( C ∣ A , B ) P(B,C|A)=P(B|A)P(C|A,B) P(B,C∣A)=P(B∣A)P(C∣A,B)
-
基于马尔科夫假设的条件概率
如果满足马尔科夫链关系 A → B → C A\rightarrow B \rightarrow C A→B→C,则有:
P ( A , B , C ) = P ( C ∣ B , A ) P ( B , A ) = P ( C ∣ B , A ) P ( B ∣ A ) P ( A ) = P ( C ∣ B ) P ( B ∣ A ) P ( A ) P(A,B,C) = P(C|B,A)P(B,A)=P(C|B,A)P(B|A)P(A)=P(C|B)P(B|A)P(A) P(A,B,C)=P(C∣B,A)P(B,A)=P(C∣B,A)P(B∣A)P(A)=P(C∣B)P(B∣A)P(A)
P ( B , C ∣ A ) = P ( B ∣ A ) P ( C ∣ A , B ) = P ( B ∣ A ) P ( C ∣ B ) P(B,C|A)=P(B|A)P(C|A,B)=P(B|A)P(C|B) P(B,C∣A)=P(B∣A)P(C∣A,B)=P(B∣A)P(C∣B)
-
高斯分布的KL散度公式
对于两个单一变量的高斯分布 p p p 和 q q q 而言,它们的KL散度为:
K L ( p , q ) = l o g σ 2 σ 1 + σ 2 + ( μ 1 − μ 2 ) 2 2 σ 2 2 − 1 2 KL(p,q)=log\frac{\sigma_{2}}{\sigma_{1}}+\frac{\sigma^{2}+(\mu_{1}-\mu_{2})^{2}}{2\sigma_{2}^{2}}-\frac{1}{2} KL(p,q)=logσ1σ2+2σ22σ2+(μ1−μ2)2−21
推导可以看这篇____高斯分布的KL散度公式 -
重参数技巧
如果想从高斯分布 N ( μ , σ 2 ) N(\mu,\sigma^{2}) N(μ,σ2)中采样,可以先从标准分布 N ( 0 , 1 ) N(0,1) N(0,1)采样出 z z z , 再得到 σ ∗ z + μ \sigma*z+\mu σ∗z+μ.这样做的好处是:将随机性转移到了 z z z 这个常量上,而 σ \sigma σ和 μ \mu μ则当做仿射变换网络的一部分。
σ ∗ z \sigma * z σ∗z就把随机性加到了标准差 σ \sigma σ 上, z z z 取0附近的值的概率最大, σ ∗ z + μ \sigma * z+\mu σ∗z+μ 就相当于在 N ( μ , σ ) N(\mu,\sigma) N(μ,σ)中采样了
二,VAE和多层VAE回顾
单层VAE的原理公式与置信下界
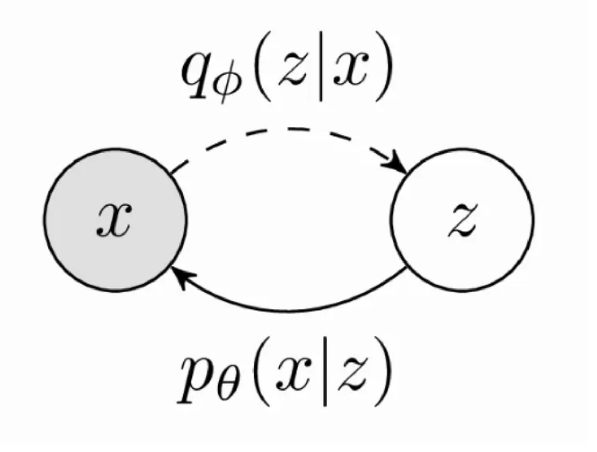
x
−
>
z
x->z
x−>z为后验,训练的过程,train
z
−
>
x
z->x
z−>x为inference过程,(丢掉train的过程)
p
(
x
)
=
∫
z
p
θ
(
x
,
z
)
d
z
=
∫
z
p
θ
(
x
∣
z
)
p
(
z
)
d
z
p(x)=\int_{z}p_{\theta}(x,z)dz=\int_{z}p_{\theta}(x|z)p(z)dz
p(x)=∫zpθ(x,z)dz=∫zpθ(x∣z)p(z)dz
p
(
x
)
=
∫
q
ϕ
(
z
∣
x
)
.
p
θ
(
x
∣
z
)
p
(
z
)
q
ϕ
(
z
∣
x
)
d
z
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
p
θ
(
x
∣
z
)
p
(
z
)
q
ϕ
(
z
∣
x
)
]
p(x)=\int q_{\phi}(z|x).\frac{p_{\theta}(x|z)p(z)}{q_{\phi}(z|x)}dz =\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[\frac{p_{\theta}(x|z)p(z)}{q_{\phi}(z|x)}\right]
p(x)=∫qϕ(z∣x).qϕ(z∣x)pθ(x∣z)p(z)dz=Ez∼qϕ(z∣x)[qϕ(z∣x)pθ(x∣z)p(z)]
l
o
g
p
(
x
)
=
l
o
g
E
z
∼
q
ϕ
(
z
∣
x
)
[
p
θ
(
x
∣
z
)
p
(
z
)
q
ϕ
(
z
∣
x
)
]
≥
J
e
n
s
e
I
n
e
q
u
a
l
i
t
y
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
p
(
z
)
q
ϕ
(
z
∣
x
)
]
log\,p(x)=log\,\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[\frac{p_{\theta}(x|z)p(z)}{q_{\phi}(z|x)}\right]\overset{Jense \,Inequality}{\ge}\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[log\,\frac{p_{\theta}(x|z)p(z)}{q_{\phi}(z|x)}\right]
logp(x)=logEz∼qϕ(z∣x)[qϕ(z∣x)pθ(x∣z)p(z)]≥JenseInequalityEz∼qϕ(z∣x)[logqϕ(z∣x)pθ(x∣z)p(z)]
所以:
l
o
g
p
(
x
)
≥
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
p
(
z
)
q
ϕ
(
z
∣
x
)
]
⏟
E
L
B
O
log\,p(x)\ge\underbrace{\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[log\,\frac{p_{\theta}(x|z)p(z)}{q_{\phi}(z|x)}\right]}_{ELBO}
logp(x)≥ELBO
Ez∼qϕ(z∣x)[logqϕ(z∣x)pθ(x∣z)p(z)]
目的:使得 x x x出现的概率最大,即要最大化 l o g p ( x ) log\,p(x) logp(x),那有Jensen不等式求得了 l o g p ( x ) log\,p(x) logp(x)的下界,现在只需要最大化下界即可。最大化下界了,那 l o g p ( x ) log\,p(x) logp(x)也就最大化了。即至此为止,我们要优化的目标函数已经找到了。
Jensen不等式:
l o g ∑ i λ i y i ≥ ∑ i λ i l o g y i 其中, λ i ≥ 0 , ∑ i λ i = 1 log\underset{i}{\sum}\lambda_{i}y_{i}\ge \underset{i}{\sum}\lambda_{i}log\,y_{i}\quad\quad其中,\lambda_{i}\ge0,\underset{i}{\sum}\lambda_{i}=1 logi∑λiyi≥i∑λilogyi其中,λi≥0,i∑λi=1
下界:
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
p
(
z
)
q
ϕ
(
z
∣
x
)
]
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
−
l
o
g
q
ϕ
(
z
∣
x
)
p
(
z
)
]
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
⏟
由
i
n
f
e
r
e
n
c
e
可以容易得到
]
−
∫
q
ϕ
(
z
∣
x
)
l
o
g
q
ϕ
(
z
∣
x
)
p
(
z
)
⏟
K
L
(
q
ϕ
∣
∣
p
)
\begin{aligned} &\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[log\,\frac{p_{\theta}(x|z)p(z)}{q_{\phi}(z|x)}\right]\\ &=\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[log\,p_{\theta}(x|z)-log\,\frac{q_{\phi}(z|x)}{p(z)}\right]\\ &=\mathbb{E}_{z\sim q_{\phi}(z|x)}\left[\underbrace{log\,p_{\theta}(x|z)}_{由inference可以容易得到}\right]- \underbrace{\int q_{\phi}(z|x) log\,\frac{q_{\phi}(z|x)}{p(z)}}_{KL(q_{\phi}||p)} \end{aligned}
Ez∼qϕ(z∣x)[logqϕ(z∣x)pθ(x∣z)p(z)]=Ez∼qϕ(z∣x)[logpθ(x∣z)−logp(z)qϕ(z∣x)]=Ez∼qϕ(z∣x)
由inference可以容易得到
logpθ(x∣z)
−KL(qϕ∣∣p)
∫qϕ(z∣x)logp(z)qϕ(z∣x)
一般假设
p
,
q
p,q
p,q均为高斯分布,所以整个单层的VAE是可以求解的
多层VAE的原理公式与置信下界
分子分母同乘一个后验分布??????

p
(
x
)
=
∫
z
1
∫
z
2
p
θ
(
x
,
z
1
,
z
2
)
d
z
1
,
d
z
2
p(x)=\int_{z_{1}}\int_{z_{2}}p_{\theta}(x,z_{1},z_{2})dz_{1},dz_{2}
p(x)=∫z1∫z2pθ(x,z1,z2)dz1,dz2
p
(
x
)
=
∬
q
ϕ
(
z
1
,
z
2
∣
x
)
p
θ
(
x
,
z
1
,
z
2
)
q
ϕ
(
z
1
,
z
2
∣
x
)
d
z
1
,
d
z
2
=
E
z
1
,
z
2
∼
q
ϕ
(
z
1
,
z
2
∣
x
)
[
p
θ
(
x
,
z
1
,
z
2
)
q
ϕ
(
z
1
,
z
2
∣
x
)
]
p(x)=\iint q_{\phi}\left(z_{1}, z_{2} \mid x\right) \frac{p_{\theta}\left(x, z_{1}, z_{2}\right)}{q_{\phi}\left(z_{1}, z_{2} \mid x\right)}dz_{1},dz_{2}=\mathbb{E}_{z_{1}, z_{2} \sim q_{\phi}\left(z_{1}, z_{2} \mid x\right)}\left[\frac{p_{\theta}\left(x, z_{1}, z_{2}\right)}{q_{\phi}\left(z_{1}, z_{2} \mid x\right)}\right]
p(x)=∬qϕ(z1,z2∣x)qϕ(z1,z2∣x)pθ(x,z1,z2)dz1,dz2=Ez1,z2∼qϕ(z1,z2∣x)[qϕ(z1,z2∣x)pθ(x,z1,z2)]
log
p
(
x
)
≥
E
z
1
,
z
2
∼
q
ϕ
(
z
1
,
z
2
∣
x
)
[
log
p
θ
(
x
,
z
1
,
z
2
)
q
ϕ
(
z
1
,
z
2
∣
x
)
]
⏟
E
L
B
O
\log p(x) \geq \underbrace{\mathbb{E}_{z_{1}, z_{2} \sim q_{\phi}\left(z_{1}, z_{2} \mid x\right)}\left[\log \frac{p_{\theta}\left(x, z_{1}, z_{2}\right)}{q_{\phi}\left(z_{1}, z_{2} \mid x\right)}\right]}_{ELBO}
logp(x)≥ELBO
Ez1,z2∼qϕ(z1,z2∣x)[logqϕ(z1,z2∣x)pθ(x,z1,z2)]
q
(
z
1
,
z
2
∣
x
)
=
q
(
z
1
∣
x
)
q
(
z
2
∣
z
1
,
x
)
=
马尔科夫性质
q
(
z
1
∣
x
)
q
(
z
2
∣
z
1
)
q(z_{1},z_{2}|x)=q(z_{1}|x)q(z_{2}|z_{1},x)\xlongequal[]{马尔科夫性质}q(z_{1}|x)q(z_{2}|z_{1})
q(z1,z2∣x)=q(z1∣x)q(z2∣z1,x)马尔科夫性质q(z1∣x)q(z2∣z1)
同理:
p
(
x
,
z
1
,
z
2
)
=
p
(
x
∣
z
1
)
p
(
z
1
∣
z
2
)
p
(
z
2
)
p(x,z_{1},z_{2})=p(x|z_{1})p(z_{1}|z_2)p(z_2)
p(x,z1,z2)=p(x∣z1)p(z1∣z2)p(z2)
所以多层VAE的目标函数为: L ( θ , ϕ ) \mathcal{L}(\theta, \phi) L(θ,ϕ)
L ( θ , ϕ ) = E q ( z 1 , z 2 ∣ x ) [ log p ( x ∣ z 1 ) − log q ( z 1 ∣ x ) + log p ( z 1 ∣ z 2 ) − log q ( z 2 ∣ z 1 ) + log p ( z 2 ) ] \mathcal{L}(\theta, \phi)=\mathbb{E}_{q\left(z_{1}, z_{2} \mid x\right)}\left[\log p\left(x \mid z_{1}\right)-\log q\left(z_{1} \mid x\right)+\log p\left(z_{1} \mid z_{2}\right)-\log q\left(z_{2} \mid z_{1}\right)+\log p\left(z_{2}\right)\right] L(θ,ϕ)=Eq(z1,z2∣x)[logp(x∣z1)−logq(z1∣x)+logp(z1∣z2)−logq(z2∣z1)+logp(z2)]
三,Diffusion Model 图示
Diffusion 的目标函数和多层VAE的目标函数很像。
从右往左:正向过程,q:条件概率分布(不含参数),扩散过程,熵增过程,加噪过程,逐渐变为–>高斯分布
从左往右:反向过程/重建过程/生成过程:逆扩散过程, p θ p_{\theta} pθ:条件概率分布(含参数),从噪声分布中推出目标分布,从目标分布中采样新样本,这样就可以生成新的图片。 在推理的时候只用到逆扩散过程 \color{red}在推理的时候只用到逆扩散过程 在推理的时候只用到逆扩散过程
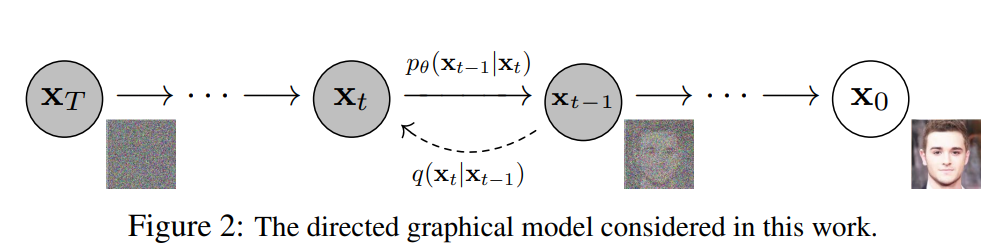
目的
:
搞懂逆扩散过程是咋弄的,这样就可以由噪声来生成新图片了
{\color{red}目的:}{\color{blue}搞懂逆扩散过程是咋弄的,这样就可以由噪声来生成新图片了}
目的:搞懂逆扩散过程是咋弄的,这样就可以由噪声来生成新图片了
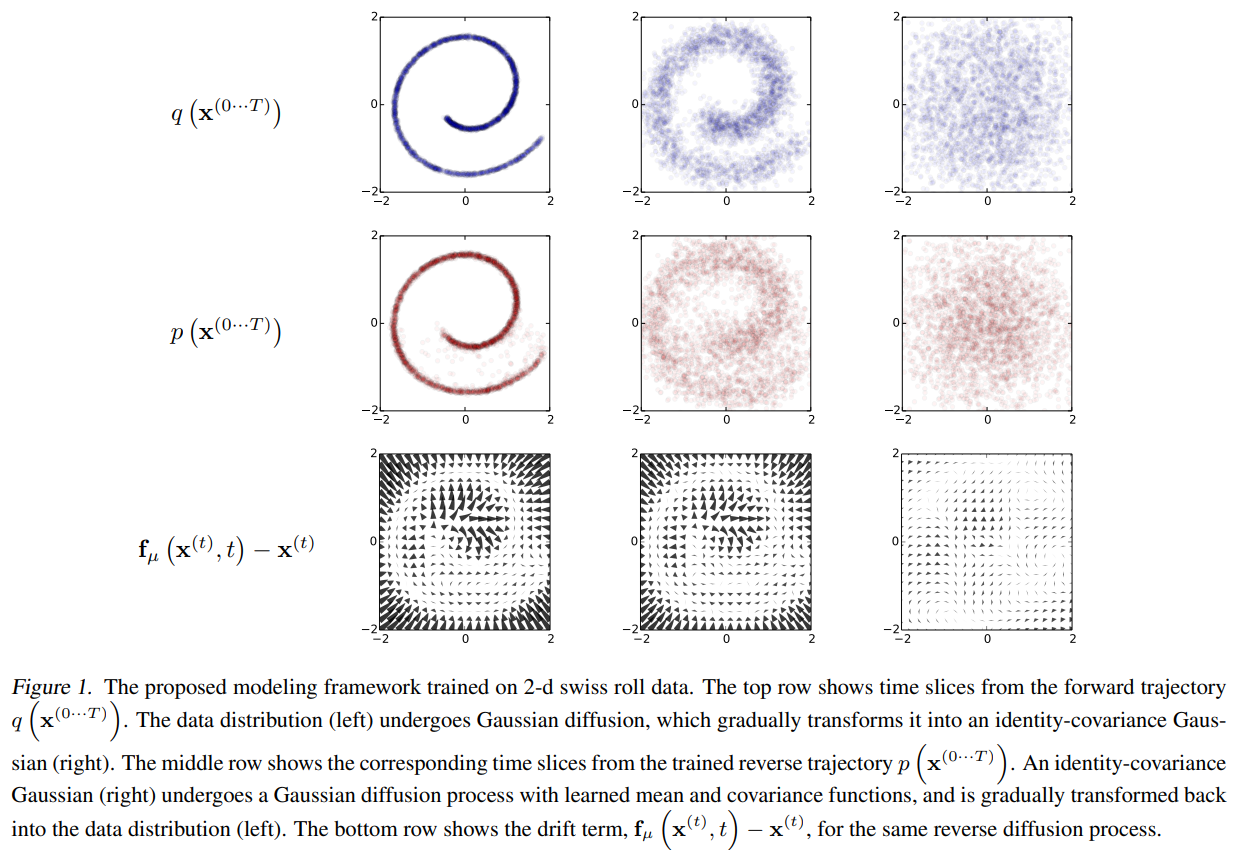
Figure1.瑞士卷图解:
第一行为从左到右:
q
(
x
(
0
⋯
T
)
)
q(\mathrm{x}^{(0\cdots T)})
q(x(0⋯T)): pic–> noise加噪过程
第二行为从右到左:
p
(
x
(
0
⋯
T
)
)
p(\mathrm{x}^{(0\cdots T)})
p(x(0⋯T)): noise->pic去噪过程
第三行为漂移量:
q
和
p
之间的差
q和p之间的差
q和p之间的差
四,扩散过程(Diffusion Process)
- 给定初始数据分布 x 0 ∼ q ( x ) x_{0}\sim q(x) x0∼q(x), 可以不断地向分布中添加高斯噪声,此噪声的标准差是以固定值 β t \beta_{t} βt 而确定的,均值是以固定值 β t \beta_{t} βt 和当前 t t t 时刻的数据 x t x_{t} xt 决定的。这个过程是一个马尔科夫链过程。
x 0 ∼ q ( x ) x_{0}\sim q(x) x0∼q(x)即训练集服从 q ( x ) q(x) q(x)分布,即扩散过程, β t \beta_{t} βt是已知的,确定的(像learning rate),,它不是通过网络预测的。扩散过程不含参数。
- 随着 t t t 的不断增大,最终数据分布 x T x_{T} xT 变成了一个各项独立的高斯分布。

3. 任意时刻的
q
(
x
t
)
q(x_{t})
q(xt)推导也可以完全基于
x
0
x_{0}
x0和
β
\beta
β来计算出来,而不需要做迭代。
注意:两个正态分布 X ∼ N ( μ 1 , σ 1 2 ) X\sim N(\mu_{1},\sigma_{1}^{2}) X∼N(μ1,σ12)和 Y ∼ N ( μ 2 , σ 2 2 ) Y\sim N(\mu_{2},\sigma_{2}^{2}) Y∼N(μ2,σ22)的叠加后的分布 a X + b Y aX+bY aX+bY的均值为 a μ 1 + b μ 2 a\mu_{1}+b\mu_{2} aμ1+bμ2, 方差为 a 2 σ 1 2 + b 2 σ 2 2 a^{2}\sigma_{1}^{2}+b^{2}\sigma_{2}^{2} a2σ12+b2σ22。所以 α t − α t α t − 1 z t − 2 + 1 − α t z t − 1 \sqrt{\alpha_{t}-\alpha_{t}\alpha_{t-1}}z_{t-2}+\sqrt{1-\alpha_{t}}z_{t-1} αt−αtαt−1zt−2+1−αtzt−1可以重参数化成只含一个随机变量 z z z 构成的 1 − α t α t − 1 z \sqrt{1-\alpha_{t}\alpha_{t-1}}z 1−αtαt−1z的形式。
A nice property of the above process is that we can sample
x
t
\mathrm{x_{t}}
xt at any arbitrary time step
t
t
t in a closed form using
r
e
p
a
r
a
m
e
t
e
r
i
z
a
t
i
o
n
t
r
i
c
k
\color{orange}\mathrm{reparameterization\,trick}
reparameterizationtrick. Let
α
t
=
1
−
β
t
\alpha_{t}=1-\beta_{t}
αt=1−βt and
α
ˉ
t
=
∏
i
=
1
t
α
i
\bar\alpha_{t}=\prod\limits_{i=1}^{t}\alpha_{i}
αˉt=i=1∏tαi

q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) , β t q(x_{t}|x_{t-1})=\mathcal{N}(x_{t};\sqrt{1-\beta_{t}}x_{t-1},\beta_{t}I), \beta_{t} q(xt∣xt−1)=N(xt;1−βtxt−1,βtI),βt是方差,标准差是 β t \sqrt{\beta_{t}} βt
如何生成 x t 呢?利用重参数技巧 \color{blue}如何生成x_{t}呢?利用重参数技巧 如何生成xt呢?利用重参数技巧
先从正态分布中生成一个 z t − 1 z_{t-1} zt−1, 然后把 β t . z t − 1 + 1 − β t x t − 1 \sqrt{\beta_{t}}.z_{t-1}+\sqrt{1-\beta_{t}}x_{t-1} βt.zt−1+1−βtxt−1 作为 x t x_{t} xt 的一个采样值,不断迭代得到 x T x_{T} xT, 其中 β t \beta_{t} βt是随着 t t t不断增加的。
−
−
−
−
−
−
−
−
x
t
的推导过程
−
−
−
−
−
−
−
−
−
−
−
--------{\color{blue}x_{t}的推导过程}-----------
−−−−−−−−xt的推导过程−−−−−−−−−−−
x
t
=
1
−
β
t
x
t
−
1
+
β
t
.
z
t
−
1
①
x_{t}=\sqrt{1-\beta_{t}}x_{t-1}+\sqrt{\beta_{t}}.z_{t-1}\quad\quad\quad\quad\,\,\,\,①
xt=1−βtxt−1+βt.zt−1①
x
t
−
1
=
1
−
β
t
−
1
x
t
−
2
+
β
t
−
1
.
z
t
−
2
②
x_{t-1}=\sqrt{1-\beta_{t-1}}x_{t-2}+\sqrt{\beta_{t-1}}.z_{t-2}\quad\quad②
xt−1=1−βt−1xt−2+βt−1.zt−2②
令
α
t
=
1
−
β
t
,
α
ˉ
t
=
∏
i
=
1
t
α
i
\alpha_{t}=1-\beta_{t}, \bar\alpha_{t}=\prod\limits_{i=1}^{t}\alpha_{i}
αt=1−βt,αˉt=i=1∏tαi,并将②带入①中得:
疑惑:那
β
t
应该代表是是方差吧,即
σ
2
\color{red}疑惑:那\beta_{t}应该代表是是方差吧,即\sigma^{2}
疑惑:那βt应该代表是是方差吧,即σ2
x
t
=
1
−
β
t
x
t
−
1
+
β
t
.
z
t
−
1
=
α
t
x
t
−
1
+
1
−
α
t
.
z
t
−
1
=
α
t
α
t
−
1
x
t
−
2
+
α
t
(
1
−
α
t
−
1
)
z
t
−
2
+
1
−
α
t
.
z
t
−
1
⏟
重参数技巧
=
α
t
α
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
z
ˉ
t
−
2
=
⋯
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
\begin{aligned} x_{t}&=\sqrt{1-\beta_{t}}x_{t-1}+\sqrt{\beta_{t}}.z_{t-1}\\&=\sqrt{\alpha_{t}}x_{t-1}+\sqrt{1-\alpha_{t}}.z_{t-1}\\ &=\sqrt{\alpha_{t}\alpha_{t-1}}x_{t-2}+\underbrace{\sqrt{\alpha_{t}(1-\alpha_{t-1})}z_{t-2}+\sqrt{1-\alpha_{t}}.z_{t-1}}_{重参数技巧}\\ &=\sqrt{\alpha_{t}\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t}\alpha_{t-1}}\bar z_{t-2}\\ &=\cdots\\ &=\sqrt{\bar\alpha_{t}}x_{0}+\sqrt{1-\bar\alpha_{t}}z \end{aligned}
xt=1−βtxt−1+βt.zt−1=αtxt−1+1−αt.zt−1=αtαt−1xt−2+重参数技巧
αt(1−αt−1)zt−2+1−αt.zt−1=αtαt−1xt−2+1−αtαt−1zˉt−2=⋯=αˉtx0+1−αˉtz
q ( x t ∣ x 0 ) = N ( x ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_{t}|x_{0})=\mathcal{N}(x;\sqrt{\bar\alpha_{t}}x_{0},(1-\bar\alpha_{t})I) q(xt∣x0)=N(x;αˉtx0,(1−αˉt)I),其中,方差为 ( 1 − α ˉ t ) I (1-\bar\alpha_{t})I (1−αˉt)I, 即 σ 2 \sigma^{2} σ2
因为所有的
z
z
z 都是从正态分布
N
(
0
,
1
)
N(0,1)
N(0,1)中采样出来的,再由3中的两个正太分布的叠加提示得:
L
e
t
z
ˉ
t
−
2
=
[
α
t
(
1
−
α
t
−
1
)
z
t
−
2
+
1
−
α
t
.
z
t
−
1
]
,
t
h
e
n
z
ˉ
t
−
2
∼
N
(
0
,
1
−
α
t
α
t
−
1
)
Let\,\bar z_{t-2}=\left[\sqrt{\alpha_{t}(1-\alpha_{t-1})}z_{t-2}+\sqrt{1-\alpha_{t}}.z_{t-1}\right],then\, \, \bar z_{t-2}\sim\mathcal{N}(0,1-\alpha_{t}\alpha_{t-1})
Letzˉt−2=[αt(1−αt−1)zt−2+1−αt.zt−1],thenzˉt−2∼N(0,1−αtαt−1)
即
z
t
−
1
∼
N
(
0
,
1
)
,
z
t
−
2
∼
N
(
0
,
1
)
z_{t-1}\sim\mathcal{N}(0,1),z_{t-2}\sim\mathcal{N}(0,1)
zt−1∼N(0,1),zt−2∼N(0,1),所以aX+bY的均值为:0,方差为:
1
−
α
t
α
t
−
1
1-\alpha_{t}\alpha_{t-1}
1−αtαt−1,即
z
ˉ
t
−
2
\bar z_{t-2}
zˉt−2 也是从高斯分布中采样得到的
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
-------------------
−−−−−−−−−−−−−−−−−−−
总结:
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
t
③
x_{t}=\sqrt{\bar\alpha_{t}}x_{0}+\sqrt{1-\bar\alpha_{t}}z_{t}\quad\quad③
xt=αˉtx0+1−αˉtzt③,那当T为多少时,
x
T
x_{T}
xT才能真变为各向独立的高斯分布呢?
即 α ˉ t → 1 , 1 − α ˉ t → 0 \bar\alpha_{t}\rightarrow1,\quad\quad1-\bar\alpha_{t}\rightarrow0 αˉt→1,1−αˉt→0时, q ( x t ∣ x 0 ) = N ( x ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_{t}|x_{0})=\mathcal{N}(x;\sqrt{\bar\alpha_{t}}x_{0},(1-\bar\alpha_{t})I) q(xt∣x0)=N(x;αˉtx0,(1−αˉt)I)变为标准的高斯分布 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1), 由上式可以求出当 t = t= t=何值时, q ( x t ∣ x 0 ) q(x_{t}|x_{0}) q(xt∣x0)约等于标准的高斯分布。
为什么要让最后的
q
(
x
t
∣
x
0
)
约等于标准的高斯分布?
\color{red}为什么要让最后的q(x_{t}|x_{0})约等于标准的高斯分布?
为什么要让最后的q(xt∣x0)约等于标准的高斯分布?
因为让扩散过程扩散到最后,即不断加噪,然后最后变成标准高斯分布,这样逆扩散过程就可以由任意的一个标准高斯分布的初始状态通过逆扩散过程最后生成新的样本
Diffusion 过程完全不含参数
由式③得:只要给定初始分布
x
0
x_{0}
x0, 则任何时刻的采样值均可以算出,方法有两种:1.迭代;2.直接算(需要预先计算出
α
t
\alpha_{t}
αt)
与VAE的区别:
VAE:
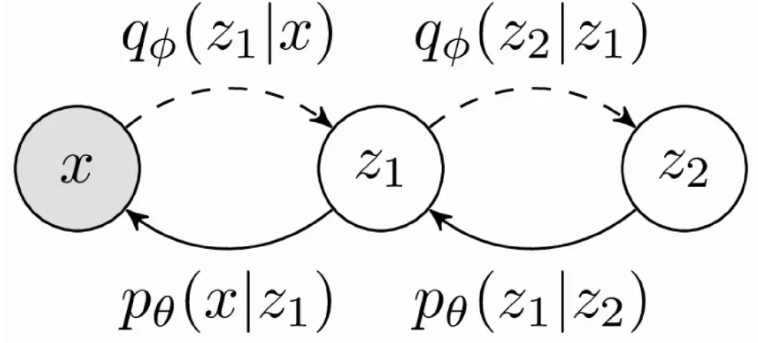
- x → z x\rightarrow z x→z并不是无参过程,而是通过后验网络给预测出来的
- z z z和 x x x不一定完全无关,但diffusion model中最后的 x T x_{T} xT 是一个标准的高斯分布,基本和 x 0 x_{0} x0完全无关
- 在VAE中的 x x x和 z z z的维度可以不一样,但diffusion model中的 x 1 , x 2 , ⋯ x T x_{1},x_{2},\cdots x_{T} x1,x2,⋯xT的维度始终保持不变。
如何设置扩散过程中的 β t \beta_{t} βt
当分布越来越接近于噪声分布时,可让 β t \beta_{t} βt增大,越来越大。同理,在 x T → x 0 x_{T}\rightarrow x_{0} xT→x0逆扩散过程中, 最开始的几步可能还是噪声的模样,到最后面的几步就很快显示出图片的模样了。