一、Elasticsearch介绍
1.Elasticsearch产生背景
- 大数据量的检索
- NoSql: not only sql,泛指非关系型的数据库
- Nginx的7层负载均衡和4层负载均衡
2.Elasticsearch是什么
一个基于Lucene的分布式搜索和分析引擎,一个开源的高扩展的分布式全文检索引擎
Elasticsearch使用Java开发:需安装jdk
Apache:
-
公司:开源协议
在它的条款下开源
很多主流的开源软件都捐献给Apache,让它维护
顶级开源项目:Kafka,ES,Echarts -
Apache服务器:Web服务器(Nginx)
是当前流行的企业级搜索引擎:稳定可靠,企业里普遍使用
使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单
Lucene与Elasticsearch关系:
- Lucene是个库,只能Java使用,并且复杂
- Elasticsearch,使用Restful操作
Elasticsearch与solr:
- mysql和oracle的关系
都是分布式的搜索引擎,不是一个软件,核心本质一样 - solr基于Lucene
- es集成度高,solr需要更多插件支持
- Solr是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用
3.核心概念
集群:多太ES服务器的配合使用的集合称为集群。
节点:形成集群的每个服务器称为节点。
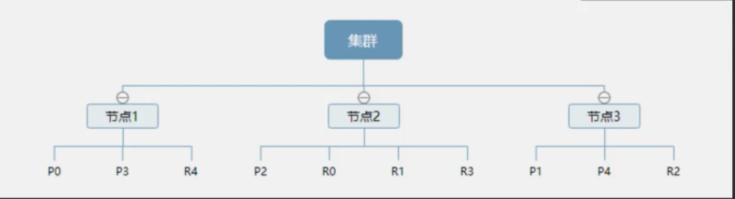
Shard:分片,数据可以分为较小的分片。每个分片放到不同的服务器上。
Replia:副本,为提高查询吞吐量或实现高可用性,副本是一个分片的精确复制,每个分片可以有零个或多个副本。
全文检索:在一篇文档中搜索要的内容,如果想查的数据快,肯定不是基于mysql的那种索引方式—基于倒排索引,实现的全文检索。
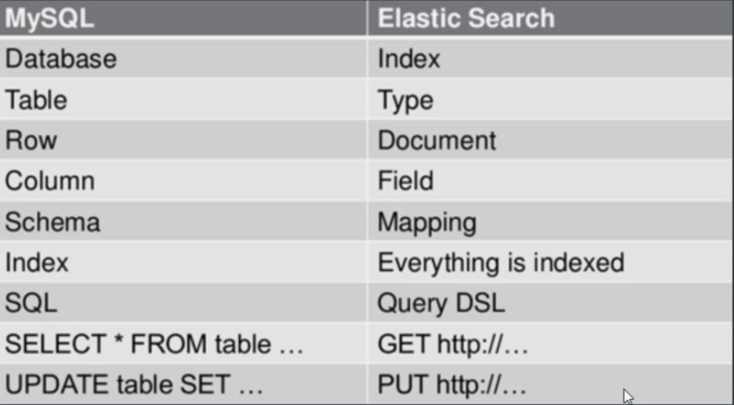
4.ES与关系型数据库Mysql对比
| Mysql | ES |
|---|---|
| 数据库 | 索引 |
| 表 | 类型 |
| 行 | 文档 |
| 建表语句 | 映射 |
5.物理设计
一个集群包含至少一个节点,而一个节点就是一个elasticsearch进程。节点内可以有多个索引。
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
6.ELK是什么
是日志收集和分析系统。
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
7.业务场景
- 搜索功能
- ES来替代传统的NoSQL,它的横向扩展机制太方便了
8.Elasticsearch索引到底能处理多大数据
一个Lucene索引,不能处理多于21亿篇文档,或者多于2740亿的唯一词条
一个分片是一个lucene索引,一个es索引默认5个分片
二、Elasticsearch安装
ES安装:
安装jdk(java开发的)---->官网下载,解压---->启动即可(bin目录下bat文件)
在浏览器输入:http://127.0.0.1:9200/
ES客户端安装:
1.restful接口---->直接使用浏览器就可以访问
2.官方没有提供一个特别好的客户端
- postman
- elasticsearch-head(第三方,node写的:node环境)
# 安装
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
# 启动
npm run start
配置跨域:修改es的配置
http.cors.enabled: true
http.cors.allow-origin: "*"
浏览器输入:http://localhost:9100/
- Kibana(官方提供的)
ES和Kibana版本要严格对应
官网下载,解压即可
修改配置—>连接es的地址:
server.port: 5601
server.host: "127.0.0.1"
server.name: lqz
elasticsearch.hosts: ["http://localhost:9200/"]
bin路径下启动kibana
浏览器访问:http://localhost:5601
三、倒排索引
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而成为倒排索引。
反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
对文章内容进行分词,根据分词建立索引(出现的位置和出现的次数)。
四、索引操作
索引等同于mysql中的数据库
- 在5.x(包含)之前,一个索引下可以建立多个映射(表)
- 6.x后,一个索引下只能建立一个映射(表),之前5.x的查询还能用
- 7.x后,一个索引下完全只支持一个映射
haystack:django的app,实现全文检索
- 底层可以基于 whoosh(python写的,类似于sqlite,文档型的),ES(Java,类似于Mysql,互联网公司用的多),solr(Java,类似于Oracle,传统企业用)
- 年久失修,只支持es 2.x版本
- 咱们做全文检索,基于es,自己通过python操作
配置信息增删改查:
# 增
PUT lqz2
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
# 删
DELETE lqz
# 查
# 获取lqz2索引的配置信息
GET lqz2/_settings
#获取所有索引的配置信息
GET _all/_settings
# 同上
GET _settings
# 获取lqz和lqz2索引的配置信息
GET lqz,lqz2/_settings
# 改(一般不改)
PUT lqz/_settings
{
"number_of_replicas": 1
}
五、映射管理
在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个mapping type。
在5.x中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x中运行。
Mapping types将在Elasticsearch 7.0.0中完全删除。
在创建索引的时候,可以预先定义字段的类型及相关属性,如果没有设置,es会自动设置。
Mapping是我们自己定义的字段数据类型,同时告诉es如何索引数据及是否可以被搜索。
作用:会让索引建立的更加细致和完善
字段及类型:
- 字符串类型:text(会分词),keyword(不会分词)
- 数字类型:long,integer,short,byte double,float
- 日期类型:data
- 布尔类型:boolean
- binary类型:binary
- 复杂类型:object(实体,对象),nested(列表)
- geo类型:geo-point,geo-shape(地理位置)----redis中
- 专业类型:ip,competion(搜索建议)
建立映射:
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{
"type":"text"}