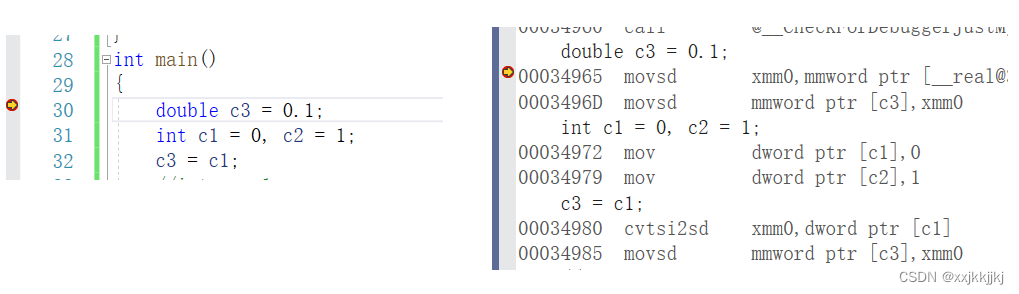
一、Producer发送消息过程
1、普通发送消息过程
一般发送消息都是new一个DefaultMQProducer,所以先找到DefaultMQProducer类
先进行DefaultMQProducerImpl的初始化,所有Producer的启动过程,最终都会调用到DefaultMQProducerImpl#start方法。在start方法中的通过一个mQClientFactory对象,启动生产者的一大堆重要服务。
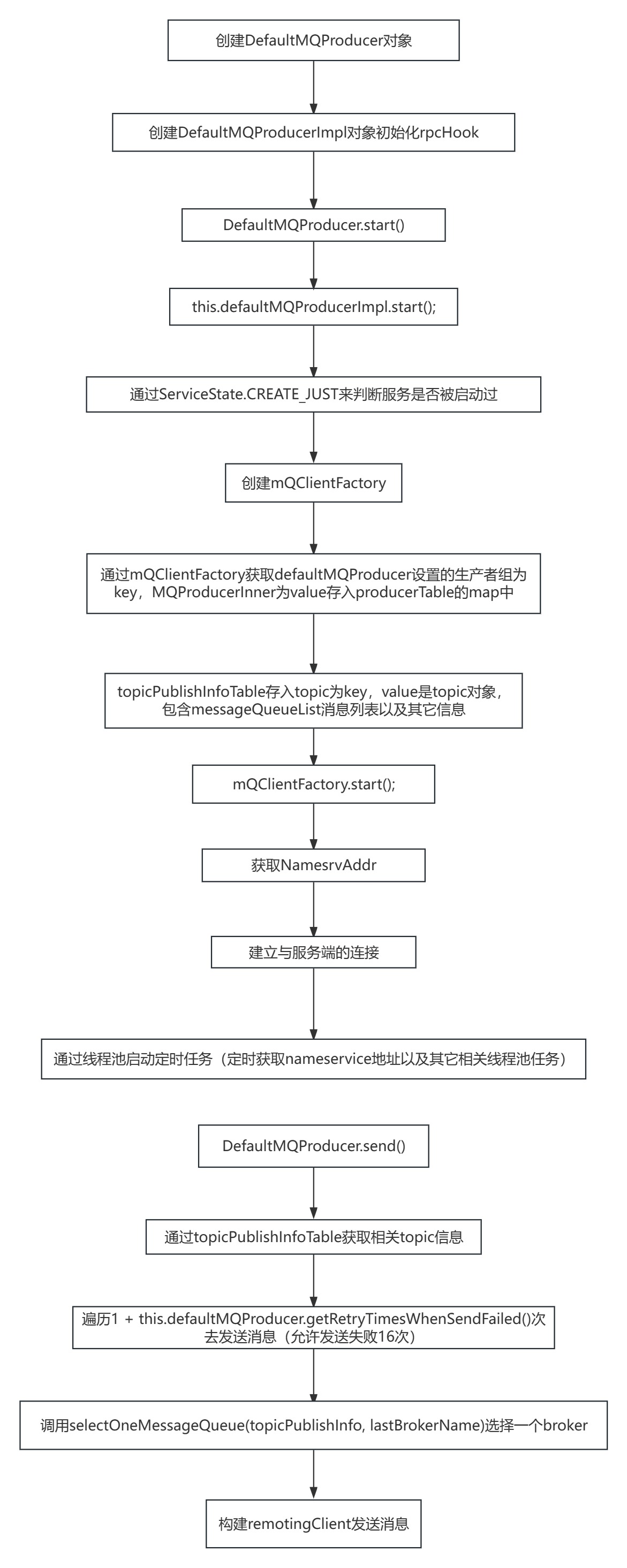
如果Producer启动了之后,NameServer挂了,那么Producer还能继续发送消息
2、事务消息发送过程
TransactionMQProducer。支持事务消息机制。需要在事务消息过程中提供事务状态确认的服务,这就要求事务消息发送者虽然是一个客户端,但是也要完成整个事务消息的确认机制后才能退出
学习任务重后面有时间再追源码了
二、Consumer拉取消息过程
1、关注重点
结合我们之前的示例,回顾下消费者这一块的几个重点问题:
-
消费者也是有两种,推模式消费者和拉模式消费者。优秀的MQ产品都会有一个高级的目标,就是要提升整个消息处理的性能。而要提升性能,服务端的优化手段往往不够直接,最为直接的优化手段就是对消费者进行优化。所以在RocketMQ中,整个消费者的业务逻辑是非常复杂的,甚至某种程度上来说,比服务端更复杂,所以,在这里我们重点关注用得最多的推模式的消费者。
-
消费者组之间有集群模式和广播模式两种消费模式。我们就要了解下这两种集群模式是如何做的逻辑封装。
-
然后我们关注下消费者端的负载均衡的原理。即消费者是如何绑定消费队列的,哪些消费策略到底是如何落地的。
-
最后我们来关注下在推模式的消费者中,MessageListenerConcurrently 和MessageListenerOrderly这两种消息监听器的处理逻辑到底有什么不同,为什么后者能保持消息顺序。
2、源码重点
Consumer的核心启动过程和Producer是一样的, 最终都是通过mQClientFactory对象启动。不过之间添加了一些注册信息。整体的启动过程如下:

3、广播模式与集群模式的Offset处理
在DefaultMQPushConsumerImpl的start方法中,启动了非常多的核心服务。 比如,对于广播模式与集群模式的Offset处理
if (this.defaultMQPushConsumer.getOffsetStore() != null) {
this.offsetStore = this.defaultMQPushConsumer.getOffsetStore();
} else {
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
this.offsetStore = new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
case CLUSTERING:
this.offsetStore = new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
default:
break;
}
this.defaultMQPushConsumer.setOffsetStore(this.offsetStore);
}
this.offsetStore.load();可以看到,广播模式是使用LocalFileOffsetStore,在Consumer本地保存Offset,而集群模式是使用RemoteBrokerOffsetStore,在Broker端远程保存offset。而这两种Offset的存储方式,最终都是通过维护本地的offsetTable缓存来管理Offset。
4、Consumer与MessageQueue建立绑定关系
start方法中还一个比较重要的东西是给rebalanceImpl设定了一个AllocateMessageQueueStrategy,用来给Consumer分配MessageQueue的。
this.rebalanceImpl.setMessageModel(this.defaultMQPushConsumer.getMessageModel());
//Consumer负载均衡策略
this.rebalanceImpl.setAllocateMessageQueueStrategy(this.defaultMQPushConsumer.getAllocateMessageQueueStrategy());这个AllocateMessageQueueStrategy就是用来给Consumer和MessageQueue之间建立一种对应关系的。也就是说,只要Topic当中的MessageQueue以及同一个ConsumerGroup中的Consumer实例都没有变动,那么某一个Consumer实例只是消费固定的一个或多个MessageQueue上的消息,其他Consumer不会来抢这个Consumer对应的MessageQueue。
关于负载均衡机制,会在后面结合Producer的发送消息策略一起总结。不过这里,你可以想一下为什么要让一个MessageQueue只能由同一个ConsumerGroup中的一个Consumer实例来消费。
其实原因很简单,因为Broker需要按照ConsumerGroup管理每个MessageQueue上的Offset,如果一个MessageQueue上有多个同属一个ConsumerGroup的Consumer实例,他们的处理进度就会不一样。这样的话,Offset就乱套了。
5、顺序消费与并发消费
同样在start方法中,启动了consumerMessageService线程,进行消息拉取。
//Consumer中自行指定的回调函数。
if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {
this.consumeOrderly = true;
this.consumeMessageService =
new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());
} else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) {
this.consumeOrderly = false;
this.consumeMessageService =
new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());
}可以看到, Consumer通过registerMessageListener方法指定的回调函数,都被封装成了ConsumerMessageService的子实现类。
而对于这两个服务实现类的调用,会延续到DefaultMQPushConsumerImpl的pullCallback对象中。也就是Consumer每拉过来一批消息后,就向Broker提交下一个拉取消息的的请求。
这里也可以印证一个点,就是顺序消息,只对异步消费也就是推模式有效。同步消费的拉模式是无法进行顺序消费的。因为这个pullCallback对象,在拉模式的同步消费时,根本就没有往下传。
当然,这并不是说拉模式不能锁定队列进行顺序消费,拉模式在Consumer端应用就可以指定从哪个队列上拿消息。
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
//...
switch (pullResult.getPullStatus()) {
case FOUND:
//...
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispatchToConsume);
//...
break;
//...
}
}
}而这里提交的,实际上是一个ConsumeRequest线程。而提交的这个ConsumeRequest线程,在两个不同的ConsumerService中有不同的实现。
这其中,两者最为核心的区别在于ConsumerMessageOrderlyService是锁定了一个队列,处理完了之后,再消费下一个队列。
public void run() {
// ....
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
synchronized (objLock) {
//....
}
}为什么给队列加个锁,就能保证顺序消费呢?结合顺序消息的实现机制理解一下。
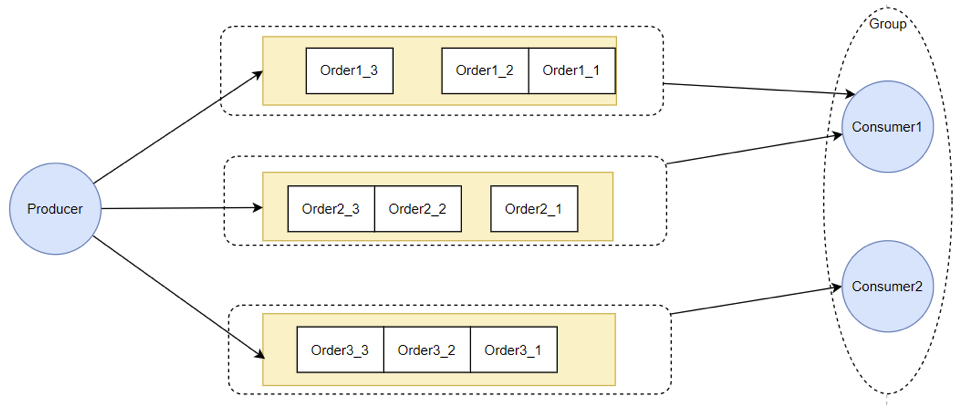
从源码中可以看到,Consumer提交请求时,都是往线程池里异步提交的请求。如果不加队列锁,那么就算Consumer提交针对同一个MessageQueue的拉取消息请求,这些请求都是异步执行,他们的返回顺序是乱的,无法进行控制。给队列加个锁之后,就保证了针对同一个队列的第二个请求,必须等第一个请求处理完了之后,释放了锁,才可以提交。这也是在异步情况下保证顺序的基础思路。
6、实际拉取消息还是通过PullMessageService完成的。
start方法中,相当于对很多消费者的服务进行初始化,包括指定一些服务的实现类,以及启动一些定时的任务线程,比如清理过期的请求缓存等。最后,会随着mQClientFactory组件的启动,启动一个PullMessageService。实际的消息拉取都交由PullMesasgeService进行。
所谓消息推模式,其实还是通过Consumer拉消息实现的。
//org.apache.rocketmq.client.impl.consumer.PullMessageService
private void pullMessage(final PullRequest pullRequest) {
final MQConsumerInner consumer = this.mQClientFactory.selectConsumer(pullRequest.getConsumerGroup());
if (consumer != null) {
DefaultMQPushConsumerImpl impl = (DefaultMQPushConsumerImpl) consumer;
impl.pullMessage(pullRequest);
} else {
log.warn("No matched consumer for the PullRequest {}, drop it", pullRequest);
}
}三、客户端负载均衡管理总结
从之前Producer发送消息的过程以及Conmer拉取消息的过程,我们可以抽象出RocketMQ中一个消息分配的管理模型。这个模型是我们在使用RocketMQ时,很重要的进行性能优化的依据。
1、Producer负载均衡
Producer发送消息时,默认会轮询目标Topic下的所有MessageQueue,并采用递增取模的方式往不同的MessageQueue上发送消息,以达到让消息平均落在不同的queue上的目的。而由于MessageQueue是分布在不同的Broker上的,所以消息也会发送到不同的broker上。
在之前源码中看到过,Producer轮训时,如果发现往某一个Broker上发送消息失败了,那么下一次会尽量避免再往同一个Broker上发送消息。但是,如果你的应用场景允许发送消息长延迟,也可以给Producer设定setSendLatencyFaultEnable(true)。这样对于某些Broker集群的网络不是很好的环境,可以提高消息发送成功的几率。
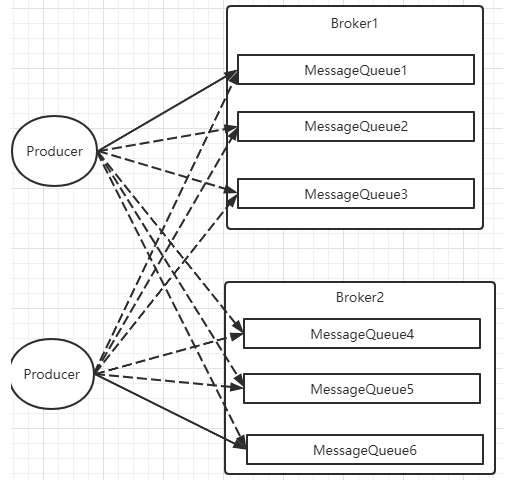
同时生产者在发送消息时,可以指定一个MessageQueueSelector。通过这个对象来将消息发送到自己指定的MessageQueue上。这样可以保证消息局部有序。
2、Consumer负载均衡
Consumer也是以MessageQueue为单位来进行负载均衡。分为集群模式和广播模式。
1、集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
每次分配时,都会将MessageQueue和消费者ID进行排序后,再用不同的分配算法进行分配。内置的分配的算法共有六种,分别对应AllocateMessageQueueStrategy下的六种实现类,可以在consumer中直接set来指定。默认情况下使用的是最简单的平均分配策略。
- AllocateMachineRoomNearby: 将同机房的Consumer和Broker优先分配在一起。
这个策略可以通过一个machineRoomResolver对象来定制Consumer和Broker的机房解析规则。然后还需要引入另外一个分配策略来对同机房的Broker和Consumer进行分配。一般也就用简单的平均分配策略或者轮询分配策略。
感觉这东西挺鸡肋的,直接给个属性指定机房不是挺好的吗。
源码中有测试代码AllocateMachineRoomNearByTest。
在示例中:Broker的机房指定方式: messageQueue.getBrokerName().split("-")[0],而Consumer的机房指定方式:clientID.split("-")[0]
clinetID的构建方式:见ClientConfig.buildMQClientId方法。按他的测试代码应该是要把clientIP指定为IDC1-CID-0这样的形式。
-
AllocateMessageQueueAveragely:平均分配。将所有MessageQueue平均分给每一个消费者
-
AllocateMessageQueueAveragelyByCircle: 轮询分配。轮流的给一个消费者分配一个MessageQueue。
-
AllocateMessageQueueByConfig: 不分配,直接指定一个messageQueue列表。类似于广播模式,直接指定所有队列。
-
AllocateMessageQueueByMachineRoom:按逻辑机房的概念进行分配。又是对BrokerName和ConsumerIdc有定制化的配置。
-
AllocateMessageQueueConsistentHash。源码中有测试代码AllocateMessageQueueConsitentHashTest。这个一致性哈希策略只需要指定一个虚拟节点数,是用的一个哈希环的算法,虚拟节点是为了让Hash数据在换上分布更为均匀。
最常用的就是平均分配和轮训分配了。例如平均分配时的分配情况是这样的:
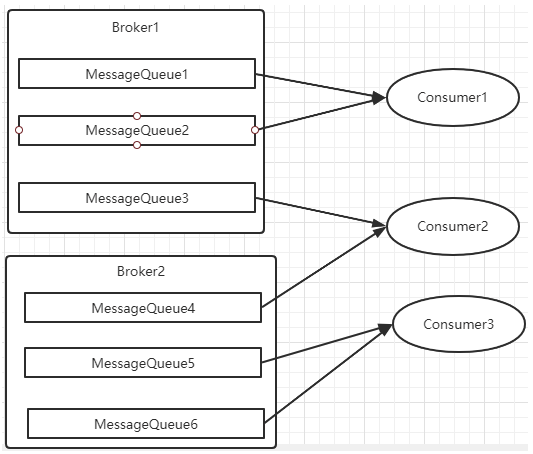
而轮训分配就不计算了,每次把一个队列分给下一个Consumer实例。
2、广播模式
广播模式下,每一条消息都会投递给订阅了Topic的所有消费者实例,所以也就没有消息分配这一说。而在实现上,就是在Consumer分配Queue时,所有Consumer都分到所有的Queue。
广播模式实现的关键是将消费者的消费偏移量不再保存到broker当中,而是保存到客户端当中,由客户端自行维护自己的消费偏移量。
四、消息持久化设计
1、RocketMQ的持久化文件结构
消息持久化也就是将内存中的消息写入到本地磁盘的过程。而磁盘IO操作通常是一个很耗性能,很慢的操作,所以,对消息持久化机制的设计,是一个MQ产品提升性能的关键,甚至可以说是最为重要的核心也不为过。这部分我们就先来梳理RocketMQ是如何在本地磁盘中保存消息的。
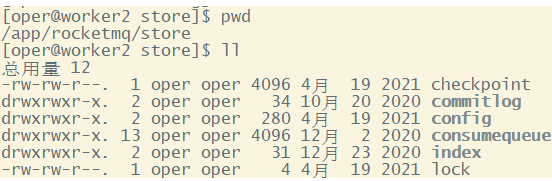
在进入源码之前,我们首先需要看一下RocketMQ在磁盘上存了哪些文件。RocketMQ消息直接采用磁盘文件保存消息,默认路径在${user_home}/store目录。这些存储目录可以在broker.conf中自行指定。
-
存储文件主要分为三个部分:
- CommitLog:存储消息的元数据。所有消息都会顺序存入到CommitLog文件当中。CommitLog由多个文件组成,每个文件固定大小1G。以第一条消息的偏移量为文件名。
- ConsumerQueue:存储消息在CommitLog的索引。一个MessageQueue一个文件,记录当前MessageQueue被哪些消费者组消费到了哪一条CommitLog。
- IndexFile:为了消息查询提供了一种通过key或时间区间来查询消息的方法,这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程
另外,还有几个辅助的存储文件,主要记录一些描述消息的元数据:
- checkpoint:数据存盘检查点。里面主要记录commitlog文件、ConsumeQueue文件以及IndexFile文件最后一次刷盘的时间戳。
- config/*.json:这些文件是将RocketMQ的一些关键配置信息进行存盘保存。例如Topic配置、消费者组配置、消费者组消息偏移量Offset 等等一些信息。
- abort:这个文件是RocketMQ用来判断程序是否正常关闭的一个标识文件。正常情况下,会在启动时创建,而关闭服务时删除。但是如果遇到一些服务器宕机,或者kill -9这样一些非正常关闭服务的情况,这个abort文件就不会删除,因此RocketMQ就可以判断上一次服务是非正常关闭的,后续就会做一些数据恢复的操作。
整体的消息存储结构,官方做了个图进行描述:
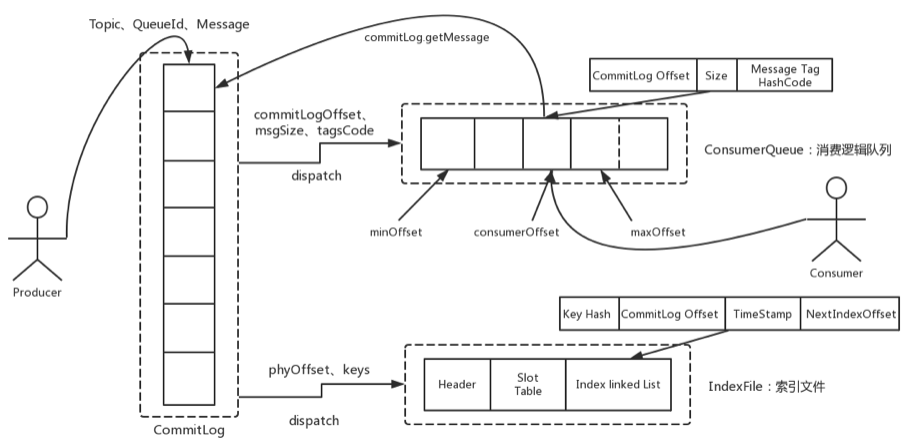
简单来说,Producer发过来的所有消息,不管是属于那个Topic,Broker都统一存在CommitLog文件当中,然后分别构建ConsumeQueue文件和IndexFile两个索引文件,用来辅助消费者进行消息检索。这种设计最直接的好处是可以较少查找目标文件的时间,让消息以最快的速度落盘。对比Kafka存文件时,需要寻找消息所属的Partition文件,再完成写入。当Topic比较多时,这样的Partition寻址就会浪费非常多的时间。所以Kafka不太适合多Topic的场景。而RocketMQ的这种快速落盘的方式,在多Topic的场景下,优势就比较明显了。
然后在文件形式上:
CommitLog文件的大小是固定的。文件名就是当前CommitLog文件当中存储的第一条消息的Offset。
ConsumeQueue文件主要是加速消费者进行消息索引。每个文件夹对应RocketMQ中的一个MessageQueue,文件夹下的文件记录了每个MessageQueue中的消息在CommitLog文件当中的偏移量。这样,消费者通过ConsumeQueue文件,就可以快速找到CommitLog文件中感兴趣的消息记录。而消费者在ConsumeQueue文件中的消费进度,会保存在config/consumerOffset.json文件当中。
IndexFile文件主要是辅助消费者进行消息索引。消费者进行消息消费时,通过ConsumeQueue文件就足够完成消息检索了,但是如果消费者指定时间戳进行消费,或者要按照MeessageId或者MessageKey来检索文件,比如RocketMQ管理控制台的消息轨迹功能,ConsumeQueue文件就不够用了。IndexFile文件就是用来辅助这类消息检索的。他的文件名比较特殊,不是以消息偏移量命名,而是用的时间命名。但是其实,他也是一个固定大小的文件。
这是对RocketMQ存盘文件最基础的了解,但是只有这样的设计,是不足以支撑RocketMQ的三高性能的。RocketMQ如何保证ConsumeQueue、IndexFile两个索引文件与CommitLog中的消息对齐?如何保证消息断电不丢失?如何保证文件高效的写入磁盘?等等。如果你想要去抓住RocketMQ这些三高问题的核心设计,那么还是需要到源码当中去深究。
2、commitLog写入
消息存储的入口在: DefaultMessageStore.asyncPutMessage方法
怎么找到这个方法的?这个大家可以自行往上溯源。其实还是可以追溯到Broker处理Producer发送消息的请求的SendMessageProcessor中。
CommitLog的asyncPutMessage方法中会给写入线程加锁,保证一次只会允许一个线程写入。写入消息的过程是串行的,一次只会允许一个线程写入。
最终进入CommitLog中的DefaultAppendMessageCallback#doAppend方法,这里就是Broker写入消息的实际入口。这个方法最终会把消息追加到MappedFile映射的一块内存里,并没有直接写入磁盘。而是在随后调用ComitLog#submitFlushRequest方法,提交刷盘申请。刷盘完成之后,内存中的文件才真正写入到磁盘当中。
在提交刷盘申请之后,就会立即调用CommitLog#submitReplicaRequest方法,发起主从同步申请。
3、文件同步刷盘与异步刷盘
入口:CommitLog.submitFlushRequest
这里涉及到了对于同步刷盘与异步刷盘的不同处理机制。这里有很多极致提高性能的设计,对于我们理解和设计高并发应用场景有非常大的借鉴意义。
同步刷盘和异步刷盘是通过不同的FlushCommitLogService的子服务实现的。
//org.apache.rocketmq.store.CommitLog的构造方法
if (FlushDiskType.SYNC_FLUSH == defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
this.flushCommitLogService = new GroupCommitService();
} else {
this.flushCommitLogService = new FlushRealTimeService();
}
this.commitLogService = new CommitRealTimeService();
同步刷盘采用的是GroupCommitService子线程。虽然是叫做同步刷盘,但是从源码中能看到,他实际上并不是来一条消息就刷一次盘。而是这个子线程每10毫秒执行一次doCommit方法,扫描文件的缓存。只要缓存当中有消息,就执行一次Flush操作。
而异步刷盘采用的是FlushRealTimeService子线程。这个子线程最终也是执行Flush操作,只不过他的执行时机会根据配置进行灵活调整。所以可以看到,这里异步刷盘和同步刷盘的最本质区别,实际上是进行Flush操作的频率不同。
我们经常说使用RocketMQ的同步刷盘,可以保证Broker断电时,消息不会丢失。但是可以看到,RocketMQ并不可能真正来一条消息就进行一次刷盘,这样在海量数据下,操作系统是承受不了的。而只要不是来一次消息刷一次盘,那么在Broker直接断电的情况接下,就总是会有内存中的消息没有刷入磁盘的情况,这就会造成消息丢失。所以,对于消息安全性的设计,其实是重在取舍,无法做到绝对。
同步刷盘和异步刷盘最终落地到FileChannel的force方法。这个force方法就会最终调用一次操作系统的fsync系统调用,完成文件写入。关于force操作的详细演示,可以参考后面的零拷贝部分。
//org.apache.rocketmq.store
public int flush(final int flushLeastPages) {
if (this.isAbleToFlush(flushLeastPages)) {
if (this.hold()) {
int value = getReadPosition();
try {
//We only append data to fileChannel or mappedByteBuffer, never both.
if (writeBuffer != null || this.fileChannel.position() != 0) {
this.fileChannel.force(false);
} else {
this.mappedByteBuffer.force();
}
} catch (Throwable e) {
log.error("Error occurred when force data to disk.", e);
}
this.flushedPosition.set(value);
this.release();
} else {
log.warn("in flush, hold failed, flush offset = " + this.flushedPosition.get());
this.flushedPosition.set(getReadPosition());
}
}
return this.getFlushedPosition();
}
而另外一个CommitRealTimeService这个子线程则是用来写入堆外内存的。应用可以通过配置TransientStorePoolEnable参数开启对外内存,如果开启了堆外内存,会在启动时申请一个跟CommitLog文件大小一致的堆外内存,这部分内存就可以确保不会被交换到虚拟内存中。而CommitRealTimeService处理消息的方式则只是调用mappedFileQueue的commit方法。这个方法只是往操作系统的PagedCache里写入消息,并不主动进行刷盘操作。会由操作系统通过Dirty Page机制,在某一个时刻进行统一刷盘。例如我们在正常关闭操作系统时,经常会等待很长时间。这里面大部分的时间其实就是在做PageCache的刷盘。
public boolean commit(final int commitLeastPages) {
boolean result = true;
MappedFile mappedFile = this.findMappedFileByOffset(this.committedWhere, this.committedWhere == 0);
if (mappedFile != null) {
int offset = mappedFile.commit(commitLeastPages);
long where = mappedFile.getFileFromOffset() + offset;
result = where == this.committedWhere;
this.committedWhere = where;
}
return result;
}
然后,在梳理同步刷盘与异步刷盘的具体实现时,可以看到一个小点,RocketMQ是如何让两个刷盘服务间隔执行的?RocketMQ提供了一个自己实现的CountDownLatch2工具类来提供线程阻塞功能,使用CAS驱动CountDownLatch2的countDown操作。每来一个消息就启动一次CAS,成功后,调用一次countDown。而这个CountDonwLatch2在Java.util.concurrent.CountDownLatch的基础上,实现了reset功能,这样可以进行对象重用。如果你对JUC并发编程感兴趣,那么这也是一个不错的学习点。
到这里,我们只是把同步刷盘和异步刷盘的机制梳理清楚了。但是关于force操作跟刷盘有什么关系?如果你对底层IO操作不是很理解,那么很容易产生困惑。没关系,保留你的疑问,下一部分我们会一起梳理。
4、CommigLog主从复制
入口:CommitLog.submitReplicaRequest
主从同步时,也体现到了RocketMQ对于性能的极致追求。最为明显的,RocketMQ整体是基于Netty实现的网络请求,而在主从复制这一块,却放弃了Netty框架,转而使用更轻量级的Java的NIO来构建。
在主要的HAService中,会在启动过程中启动三个守护进程。
//HAService#start
public void start() throws Exception {
this.acceptSocketService.beginAccept();
this.acceptSocketService.start();
this.groupTransferService.start();
this.haClient.start();
}
这其中与Master相关的是acceptSocketService和groupTransferService。其中acceptSocketService主要负责维护Master与Slave之间的TCP连接。groupTransferService主要与主从同步复制有关。而slave相关的则是haClient。
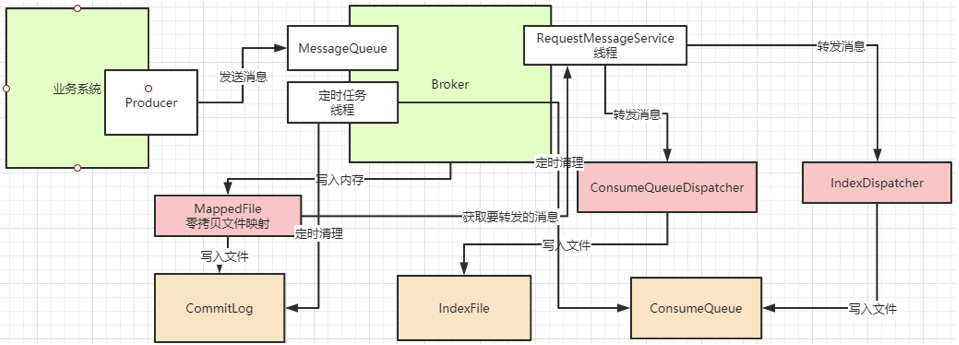
5、分发ConsumeQueue和IndexFile
当CommitLog写入一条消息后,在DefaultMessageStore的start方法中,会启动一个后台线程reputMessageService。源码就定义在DefaultMessageStore中。这个后台线程每隔1毫秒就会去拉取CommitLog中最新更新的一批消息。如果发现CommitLog中有新的消息写入,就会触发一次doDispatch。
//org.apache.rocketmq.store.DefaultMessageStore中的ReputMessageService线程类
public void doDispatch(DispatchRequest req) {
for (CommitLogDispatcher dispatcher : this.dispatcherList) {
dispatcher.dispatch(req);
}
}
dispatchList中包含两个关键的实现类CommitLogDispatcherBuildConsumeQueue和CommitLogDispatcherBuildIndex。源码就定义在DefaultMessageStore中。他们分别用来构建ConsumeQueue索引和IndexFile索引。
具体的构建逻辑比较复杂,在下面章节了解ConsumeQueue文件和IndexFile文件的具体构造后,会比较容易看懂一点。
并且,如果服务异常宕机,会造成CommitLog和ConsumeQueue、IndexFile文件不一致,有消息写入CommitLog后,没有分发到索引文件,这样消息就丢失了。DefaultMappedStore的load方法提供了恢复索引文件的方法,入口在load方法。
6、过期文件删除机制
入口: DefaultMessageStore.addScheduleTask -> DefaultMessageStore.this.cleanFilesPeriodically()
在这个方法中会启动两个线程,cleanCommitLogService用来删除过期的CommitLog文件,cleanConsumeQueueService用来删除过期的ConsumeQueue和IndexFile文件。
在删除CommitLog文件时,Broker会启动后台线程,每60秒,检查CommitLog、ConsumeQueue文件。然后对超过72小时的数据进行删除。也就是说,默认情况下, RocketMQ只会保存3天内的数据。这个时间可以通过fileReservedTime来配置。
触发过期文件删除时,有两个检查的纬度,一个是,是否到了触发删除的时间,也就是broker.conf里配置的deleteWhen属性。另外还会检查磁盘利用率,达到阈值也会触发过期文件删除。这个阈值默认是72%,可以在broker.conf文件当中定制。但是最大值为95,最小值为10。
然后在删除ConsumeQueue和IndexFile文件时,会去检查CommitLog当前的最小Offset,然后在删除时进行对齐。
需要注意的是,RocketMQ在删除过期CommitLog文件时,并不检查消息是否被消费过。 所以如果有消息长期没有被消费,是有可能直接被删除掉,造成消息丢失的。
RocketMQ整个文件管理的核心入口在DefaultMessageStore的start方法中,整体流程总结如下:
7、文件索引结构
了解了大部分的文件写入机制之后,最后我们来理解一下RocketMQ的索引构建方式。
1、CommitLog文件的大小是固定的,但是其中存储的每个消息单元长度是不固定的,具体格式可以参考org.apache.rocketmq.store.CommitLog中计算消息长度的方法
protected static int calMsgLength(int sysFlag, int bodyLength, int topicLength, int propertiesLength) {
int bornhostLength = (sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 8 : 20;
int storehostAddressLength = (sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 8 : 20;
final int msgLen = 4 //TOTALSIZE
+ 4 //MAGICCODE
+ 4 //BODYCRC
+ 4 //QUEUEID
+ 4 //FLAG
+ 8 //QUEUEOFFSET
+ 8 //PHYSICALOFFSET
+ 4 //SYSFLAG
+ 8 //BORNTIMESTAMP
+ bornhostLength //BORNHOST
+ 8 //STORETIMESTAMP
+ storehostAddressLength //STOREHOSTADDRESS
+ 4 //RECONSUMETIMES
+ 8 //Prepared Transaction Offset
+ 4 + (bodyLength > 0 ? bodyLength : 0) //BODY
+ 1 + topicLength //TOPIC
+ 2 + (propertiesLength > 0 ? propertiesLength : 0) //propertiesLength
+ 0;
return msgLen;
}
正因为消息的记录大小不固定,所以RocketMQ在每次存CommitLog文件时,都会去检查当前CommitLog文件空间是否足够,如果不够的话,就重新创建一个CommitLog文件。文件名为当前消息的偏移量。
2、ConsumeQueue文件主要是加速消费者的消息索引。他的每个文件夹对应RocketMQ中的一个MessageQueue,文件夹下的文件记录了每个MessageQueue中的消息在CommitLog文件当中的偏移量。这样,消费者通过ComsumeQueue文件,就可以快速找到CommitLog文件中感兴趣的消息记录。而消费者在ConsumeQueue文件当中的消费进度,会保存在config/consumerOffset.json文件当中。
文件结构: 每个ConsumeQueue文件固定由30万个固定大小20byte的数据块组成,数据块的内容包括:msgPhyOffset(8byte,消息在文件中的起始位置)+msgSize(4byte,消息在文件中占用的长度)+msgTagCode(8byte,消息的tag的Hash值)。
msgTag是和消息索引放在一起的,所以,消费者根据Tag过滤消息的性能是非常高的。
在ConsumeQueue.java当中有一个常量CQ_STORE_UNIT_SIZE=20,这个常量就表示一个数据块的大小。
例如,在ConsumeQueue.java当中构建一条ConsumeQueue索引的方法 中,就是这样记录一个单元块的数据的。
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
if (offset + size <= this.maxPhysicOffset) {
log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset={}", maxPhysicOffset, offset);
return true;
}
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
//.......
}
3、IndexFile文件主要是辅助消息检索。他的作用主要是用来支持根据key和timestamp检索消息。他的文件名比较特殊,不是以消息偏移量命名,而是用的时间命名。但是其实,他也是一个固定大小的文件。
文件结构: 他的文件结构由 indexHeader(固定40byte)+ slot(固定500W个,每个固定20byte) + index(最多500W*4个,每个固定20byte) 三个部分组成。
然后,了解这些文件结构有什么用呢?下面的延迟消息机制就是一个例子。
五、延迟消息机制
1、关注重点
延迟消息是RocketMQ非常有特色的一个功能,其他MQ产品中,往往需要开发者使用一些特殊方法来变相实现延迟消息功能。而RocketMQ直接在产品中实现了这个功能,开发者只需要设定一个属性就可以快速实现。
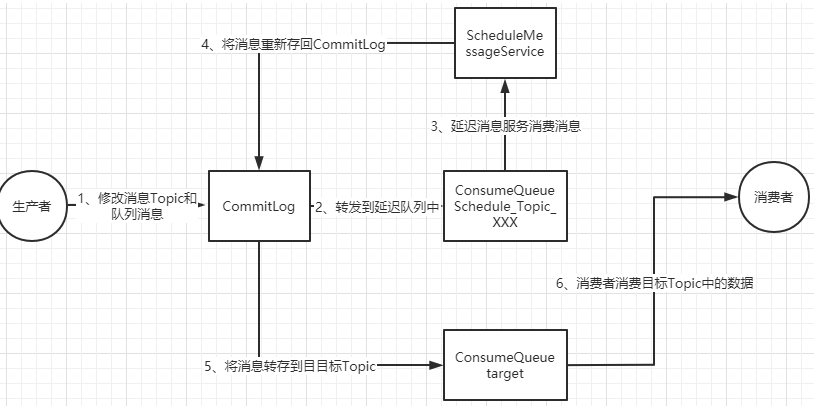
延迟消息的核心使用方法就是在Message中设定一个MessageDelayLevel参数,对应18个延迟级别。然后Broker中会创建一个默认的Schedule_Topic主题,这个主题下有18个队列,对应18个延迟级别。消息发过来之后,会先把消息存入Schedule_Topic主题中对应的队列。然后等延迟时间到了,再转发到目标队列,推送给消费者进行消费。
2、源码重点
延迟消息的处理入口在scheduleMessageService这个组件中。 他会在broker启动时也一起加载。
1、消息写入到系统内置的Topic中
代码见CommitLog.putMessage方法。
在CommitLog写入消息时,会判断消息的延迟级别,然后修改Message的Topic和Queue,将消息转储到系统内部的Topic中,这样消息就对消费者不可见了。而原始的目标信息,会作为消息的属性,保存到消息当中。
if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE
|| tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {
// Delay Delivery
//K1 延迟消息转到系统Topic
if (msg.getDelayTimeLevel() > 0) {
if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
}
topic = TopicValidator.RMQ_SYS_SCHEDULE_TOPIC;
int queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
// Backup real topic, queueId
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
//修改消息的Topic和Queue,转储到系统的Topic中。
msg.setTopic(topic);
msg.setQueueId(queueId);
}
}
十八个队列对应了十八个延迟级别,这也说明了为什么这种机制下不支持自定义时间戳。
2、消息转储到目标Topic
接下来就是需要过一点时间,再将消息转回到Producer提交的Topic和Queue中,这样就可以正常往消费者推送了。
这个转储的核心服务是scheduleMessageService,他也是Broker启动过程中的一个功能组件。随DefaultMessageStore组件一起构建。这个服务只在master节点上启动,而在slave节点上会主动关闭这个服务。
//org.apache.rocketmq.store.DefaultMessageStore
@Override
public void handleScheduleMessageService(final BrokerRole brokerRole) {
if (this.scheduleMessageService != null) {
if (brokerRole == BrokerRole.SLAVE) {
this.scheduleMessageService.shutdown();
} else {
this.scheduleMessageService.start();
}
}
}
由于RocketMQ的主从节点支持切换,所以就需要考虑这个服务的幂等性。在节点切换为slave时就要关闭服务,切换为master时就要启动服务。并且,即便节点多次切换为master,服务也只启动一次。所以在ScheduleMessageService的start方法中,就通过一个CAS操作来保证服务的启动状态。
if (started.compareAndSet(false, true)) {
这个CAS操作还保证了在后面,同一时间只有一个DeliverDelayedMessageTimerTask执行。这种方式,给整个延迟消息服务提供了一个基础保证。
ScheduleMessageService会每隔1秒钟执行一个executeOnTimeup任务,将消息从延迟队列中写入正常Topic中。 代码见ScheduleMessageService中的DeliverDelayedMessageTimerTask.executeOnTimeup方法。
在executeOnTimeup方法中,就会去扫描SCHEDULE_TOPIC_XXXX这个Topic下的所有messageQueue,然后扫描这些MessageQueue对应的ConsumeQueue文件,找到没有处理过的消息,计算他们的延迟时间。如果延迟时间没有到,就等下一秒再重新扫描。如果延迟时间到了,就进行消息转储。将消息转回到原来的目标Topic下。
整个延迟消息的实现方式是这样的:
而ScheduleMessageService中扫描延迟消息的主要逻辑是这样的:
//ScheduleMessageService.DeliverDelayedMessageTimerTask#executeOnTimeup
public void executeOnTimeup() {
//找到延迟队列对应的ConsumeQueue文件
ConsumeQueue cq = ScheduleMessageService.this.defaultMessageStore.findConsumeQueue(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC,
delayLevel2QueueId(delayLevel));
//...
//通过计算,找到这一次扫描需要处理的的ConsumeQueue文件
SelectMappedBufferResult bufferCQ = cq.getIndexBuffer(this.offset);
//...
try {
//...
//循环过滤ConsumeQueue文件当中的每一条消息索引
for (; i < bufferCQ.getSize() && isStarted(); i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
//解析每一条ConsumeQueue记录
long offsetPy = bufferCQ.getByteBuffer().getLong();
int sizePy = bufferCQ.getByteBuffer().getInt();
long tagsCode = bufferCQ.getByteBuffer().getLong();
//...
//计算延迟时间
long now = System.currentTimeMillis();
long deliverTimestamp = this.correctDeliverTimestamp(now, tagsCode);
nextOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
//延迟时间没到就等下一次扫描。
long countdown = deliverTimestamp - now;
if (countdown > 0) {
this.scheduleNextTimerTask(nextOffset, DELAY_FOR_A_WHILE);
return;
}
//...
//时间到了就进行转储。
boolean deliverSuc;
if (ScheduleMessageService.this.enableAsyncDeliver) {
deliverSuc = this.asyncDeliver(msgInner, msgExt.getMsgId(), nextOffset, offsetPy, sizePy);
} else {
deliverSuc = this.syncDeliver(msgInner, msgExt.getMsgId(), nextOffset, offsetPy, sizePy);
}
//...
}
//计算下一次扫描时的Offset起点。
nextOffset = this.offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
} catch (Exception e) {
log.error("ScheduleMessageService, messageTimeup execute error, offset = {}", nextOffset, e);
} finally {
bufferCQ.release();
}
//部署下一次扫描任务
this.scheduleNextTimerTask(nextOffset, DELAY_FOR_A_WHILE);
}
你看。这段代码,如果你不懂ConsumeQueue文件的结构,大概率是看不懂他是在干什么的。但是如果清楚了ConsumeQueue文件的结构,就可以很清晰的感受到RocketMQ其实就是在Broker端,像一个普通消费者一样去进行消费,然后扩展出了延迟消息的整个扩展功能。而这,其实也是很多互联网大厂对RocketMQ进行自定义功能扩展的很好的参考。
当然,如果你有心深入分析下去的话,可以针对扫描的效率做更多的梳理以及总结。因为只要是延迟类任务,都需要不断进行扫描。但是如何提升扫描的效率其实是一个非常核心的问题。各种框架都有不同的设计思路,而RocketMQ其实就是给出了一个很高效的参考。