基于WIN10的64位系统演示
一、写在前面
上两期,我们讲了多步滚动预测的第两种策略:
对于重复的预测值,取平均处理。例如,(1,2,3)预测出3.9和4.5,(2,3,4)预测出5.2和6.3,那么拼起来的结果就是3.9,(4.5 + 5.2)/2, 6.3。
删除一半的输入数据集。例如,4,5由(1,2,3)预测,6,7由(3,4,5)预测,删掉输入数据(2,3,4)。
没想到吧,还会有第三期。也是我突然记起的,叫做多模型预测。
2、多步滚动预测 vol-3
什么叫多模型预测呢,我举个例子,大家看便知:
首先,我们还是使用3个数值去预测2个数值。不同的是,这2个数值分别是由2个不同参数的模型(这里都是决策树)进行预测的。
第一个模型的构建如下:
| 输入 | 输出 |
| 1,2,3 | 4 |
| 2,3,4 | 6 |
| 3,4,5 | 8 |
| ... | ... |
4由(1,2,3)预测,6由(3,4,5)预测,8由(5,6,7)预测,以此类推。可以理解为,第一个模型专门被训练来预测偶数位的数值。
第二个模型的构建如下:
| 输入 | 输出 |
| 1,2,3 | 5 |
| 2,3,4 | 7 |
| 3,4,5 | 9 |
| ... | ... |
5由(1,2,3)预测,7由(3,4,5)预测,9由(5,6,7)预测,以此类推。可以理解为,第二个模型专门被训练来预测奇数位的数值。
最后,再把两个模型的预测结果按顺序拼接起来即可。也就是:模型一出一个4,模型二接上一个5;模型一接上一个6,模型二补上一个7,以此类推。
我们在总结和扩展:假设使用前n个数值去预测下m个数值。如果m=3时,那么就需要构建3个模型,分别预测3个数值,然后依次把这3个数值按顺序拼接在一起。如果m=4时,那么就需要构建4个模型,分别预测4个数值,然后依次把这4个数值按顺序拼接在一起。同理,如果m=d时,那么就需要构建d个模型,分别预测d个数值,然后依次把这d个数值按顺序拼接在一起。以此类推。
2.1 数据拆分
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error, mean_squared_error
# 数据读取和预处理
data = pd.read_csv('data.csv')
data_y = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
data_y['time'] = pd.to_datetime(data_y['time'], format='%b-%y')
n = 6
for i in range(n, 0, -1):
data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)
data = data.dropna().reset_index(drop=True)
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
X_train = train_data[[f'lag_{i}' for i in range(1, n+1)]]
m = 3
X_train_list = []
y_train_list = []
for i in range(m):
X_temp = X_train
y_temp = data_y['incidence'].iloc[n + i:len(data_y) - m + 1 + i]
X_train_list.append(X_temp)
y_train_list.append(y_temp)
# 截断y_train使其与X_train的长度匹配
for i in range(m):
X_train_list[i] = X_train_list[i].iloc[:-(m-1)]
y_train_list[i] = y_train_list[i].iloc[:len(X_train_list[i])]核心部分在于,对于数据的划分,一个X_train,对应m个(本例子中m = 3)Y_train:
X_train_list = []
y_train_list = []
for i in range(m):
X_temp = X_train
y_temp = data_y['incidence'].iloc[n + i:len(data_y) - m + 1 + i]
X_train_list.append(X_temp)
y_train_list.append(y_temp)
# 截断y_train使其与X_train的长度匹配
for i in range(m):
X_train_list[i] = X_train_list[i].iloc[:-(m-1)]
y_train_list[i] = y_train_list[i].iloc[:len(X_train_list[i])]这段代码主要用于为多个模型准备训练数据。GPT-4逐行解释:
(a)X_train_list = [] 和 y_train_list = []:初始化两个空列表,分别用于存储多个模型的训练数据和标签。
(b)for i in range(m)::开始一个循环,循环m次,其中m是模型的数量。
(c)X_temp = X_train:将X_train赋值给X_temp。这意味着每个模型的特征数据都相同。
(d)y_temp = data_y['incidence'].iloc[n + i:len(data_y) - m + 1 + i]:这是获取标签数据的关键步骤。它使用iloc来获取一个子集,这个子集的起始点根据循环的迭代而变化。起始点是n + i,而终止点是len(data_y) - m + 1 + i。
这意味着:
对于第一个模型(i=0),我们从第n个数据点开始选择标签。
对于第二个模型(i=1),我们从第n+1个数据点开始选择标签。
对于第三个模型(i=2),我们从第n+2个数据点开始选择标签。
...以此类推。
(e)X_train_list.append(X_temp):将X_temp添加到X_train_list。
(f)y_train_list.append(y_temp):将y_temp添加到y_train_list。
到此为止,我们已经为每个模型创建了训练数据和标签。
接下来,为了确保特征数据和标签数据的长度匹配,我们需要进行截断操作。
(g)for i in range(m)::开始另一个循环,再次循环m次。
(h)X_train_list[i] = X_train_list[i].iloc[:-(m-1)]:这行代码将X_train_list中的每个元素(即特征数据)从末尾截断m-1行。例如,如果m=3,则截断最后2行。
(i)y_train_list[i] = y_train_list[i].iloc[:len(X_train_list[i])]:这行代码确保标签数据的长度与特征数据的长度相匹配。
综上所述,我们得到的X_train_list包含三个相同的输入集(A\B\C);同样,y_train_list包含三个输出集(D\E\F),注意D\E\F的数据不一样。A和D用于训练模型一,B和E用于训练模型二,C和F用于训练模型三。
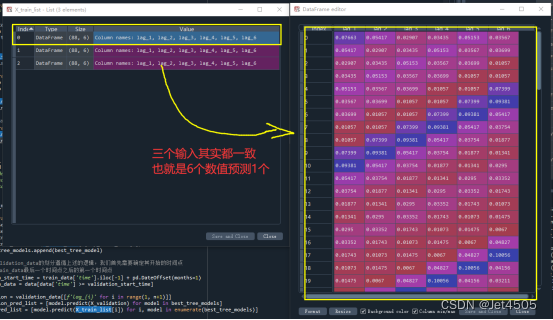

大家看上图自行体会吧!!!
2.2 建模与预测
# 模型训练
tree_model = DecisionTreeRegressor()
param_grid = {
'max_depth': [None, 3, 5, 7, 9],
'min_samples_split': range(2, 11),
'min_samples_leaf': range(1, 11)
}
best_tree_models = []
for i in range(m):
grid_search = GridSearchCV(tree_model, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train_list[i], y_train_list[i])
best_tree_model = DecisionTreeRegressor(**grid_search.best_params_)
best_tree_model.fit(X_train_list[i], y_train_list[i])
best_tree_models.append(best_tree_model)
# 为了使validation_data的划分遵循上述的逻辑,我们首先需要确定其开始的时间点
# 这是在train_data最后一个时间点之后的第一个时间点
validation_start_time = train_data['time'].iloc[-1] + pd.DateOffset(months=1)
validation_data = data[data['time'] >= validation_start_time]
X_validation = validation_data[[f'lag_{i}' for i in range(1, n+1)]]
y_validation_pred_list = [model.predict(X_validation) for model in best_tree_models]
y_train_pred_list = [model.predict(X_train_list[i]) for i, model in enumerate(best_tree_models)]
def concatenate_predictions(pred_list):
concatenated = []
for j in range(len(pred_list[0])):
for i in range(m):
concatenated.append(pred_list[i][j])
return concatenated
y_validation_pred = np.array(concatenate_predictions(y_validation_pred_list))[:len(validation_data['incidence'])]
y_train_pred = np.array(concatenate_predictions(y_train_pred_list))[:len(train_data['incidence']) - m + 1]
mae_validation = mean_absolute_error(validation_data['incidence'], y_validation_pred)
mape_validation = np.mean(np.abs((validation_data['incidence'] - y_validation_pred) / validation_data['incidence']))
mse_validation = mean_squared_error(validation_data['incidence'], y_validation_pred)
rmse_validation = np.sqrt(mse_validation)
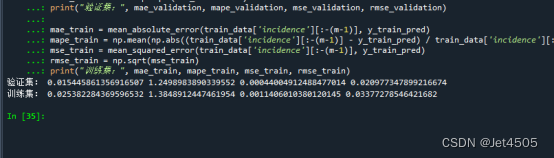
print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)
mae_train = mean_absolute_error(train_data['incidence'][:-(m-1)], y_train_pred)
mape_train = np.mean(np.abs((train_data['incidence'][:-(m-1)] - y_train_pred) / train_data['incidence'][:-(m-1)]))
mse_train = mean_squared_error(train_data['incidence'][:-(m-1)], y_train_pred)
rmse_train = np.sqrt(mse_train)
print("训练集:", mae_train, mape_train, mse_train, rmse_train)核心代码一,建立m个模型:
for i in range(m):
grid_search = GridSearchCV(tree_model, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train_list[i], y_train_list[i])
best_tree_model = DecisionTreeRegressor(**grid_search.best_params_)
best_tree_model.fit(X_train_list[i], y_train_list[i])
best_tree_models.append(best_tree_model)这段代码的目的是为每一个模型(共m个)找到最优的参数,并使用这些参数训练模型,然后保存这些模型。
核心代码二,结果拼接:
def concatenate_predictions(pred_list):
concatenated = []
for j in range(len(pred_list[0])):
for i in range(m):
concatenated.append(pred_list[i][j])
return concatenated
y_validation_pred = np.array(concatenate_predictions(y_validation_pred_list))[:len(validation_data['incidence'])]
y_train_pred = np.array(concatenate_predictions(y_train_pred_list))[:len(train_data['incidence']) - m + 1]详细解释 concatenate_predictions 函数并通过一个简单的例子进行说明。
函数的目的是将多个模型的预测结果按照一定的顺序串联起来。
考虑如下情况:
假设我们有3个模型(即m=3),每个模型都为3个月份进行预测。那么,模型的预测列表 pred_list 可能如下所示:
pred_list = [
[0.1, 0.2, 0.3], # 模型1的预测结果
[0.4, 0.5, 0.6], # 模型2的预测结果
[0.7, 0.8, 0.9] # 模型3的预测结果
]现在,我们想要的串联顺序是:模型1的第1个月预测,模型2的第1个月预测,模型3的第1个月预测,模型1的第2个月预测,模型2的第2个月预测,模型3的第2个月预测,依此类推。
所以,使用 concatenate_predictions 函数处理 pred_list 后的结果应该是:
[0.1, 0.4, 0.7, 0.2, 0.5, 0.8, 0.3, 0.6, 0.9]这就是 concatenate_predictions 函数的作用,大家看懂了吧!
2.3 输出
三、数据
链接:https://pan.baidu.com/s/1EFaWfHoG14h15KCEhn1STg?pwd=q41n
提取码:q41n