论文作者:Lin Geng Foo,Hossein Rahmani,Jun Liu
作者单位:Singapore University of Technology and Design (SUTD); Lancaster University
论文链接:http://arxiv.org/abs/2308.14177v1
内容简介:
人工智能生成内容(AI-generated content,AIGC)方法旨在使用人工智能算法生成文本、图像、视频、3D资源和其他媒体。由于其广泛的应用范围和最近作品所展现的潜力,AIGC的发展近期引起了许多关注。AIGC方法已经针对不同的数据模态进行了开发,如图像、视频、文本、3D形状(体素、点云、网格和神经隐式场等)、3D场景、3D人类化身(身体和头部)、3D运动和音频等,每种模态都具有不同的特点和挑战。此外,在跨模态AIGC方法方面也取得了许多重要进展,即生成方法可以接收一种模态的输入条件,并在另一种模态中生成输出。例如,从不同模态到图像、视频、3D形状、3D场景、3D化身(身体和头部)、3D运动(骨架和化身)以及音频模态等。
在本文中,对不同数据模态下的AIGC方法进行了全面的综述,包括单模态和跨模态方法,突出了每种情况下的各种挑战、代表性作品以及近期的技术方向。文章还在多个基准数据集上呈现了各个模态的比较结果。此外,还讨论了挑战和潜在的未来研究方向。



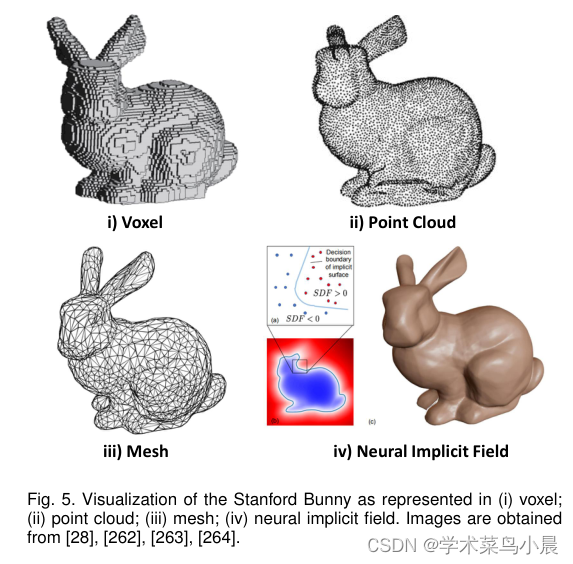
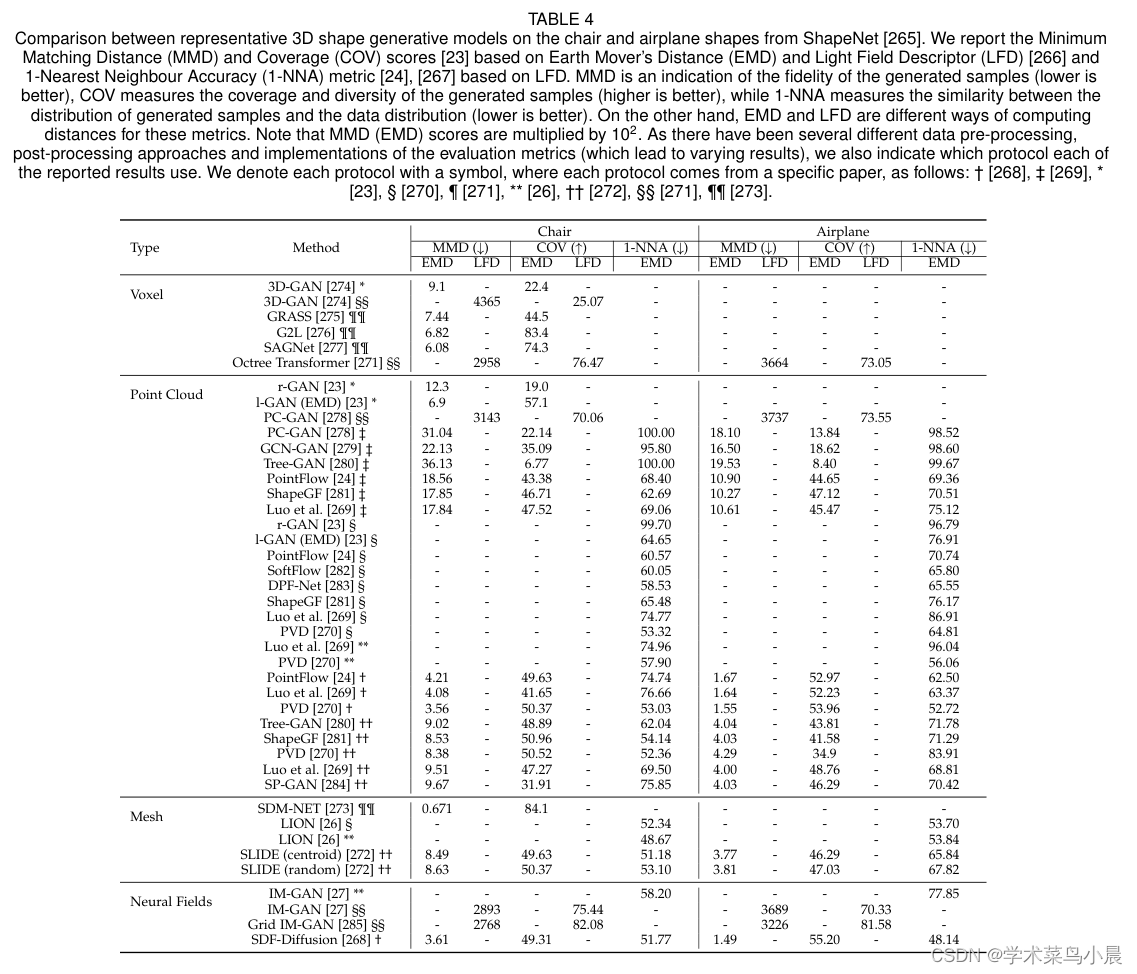
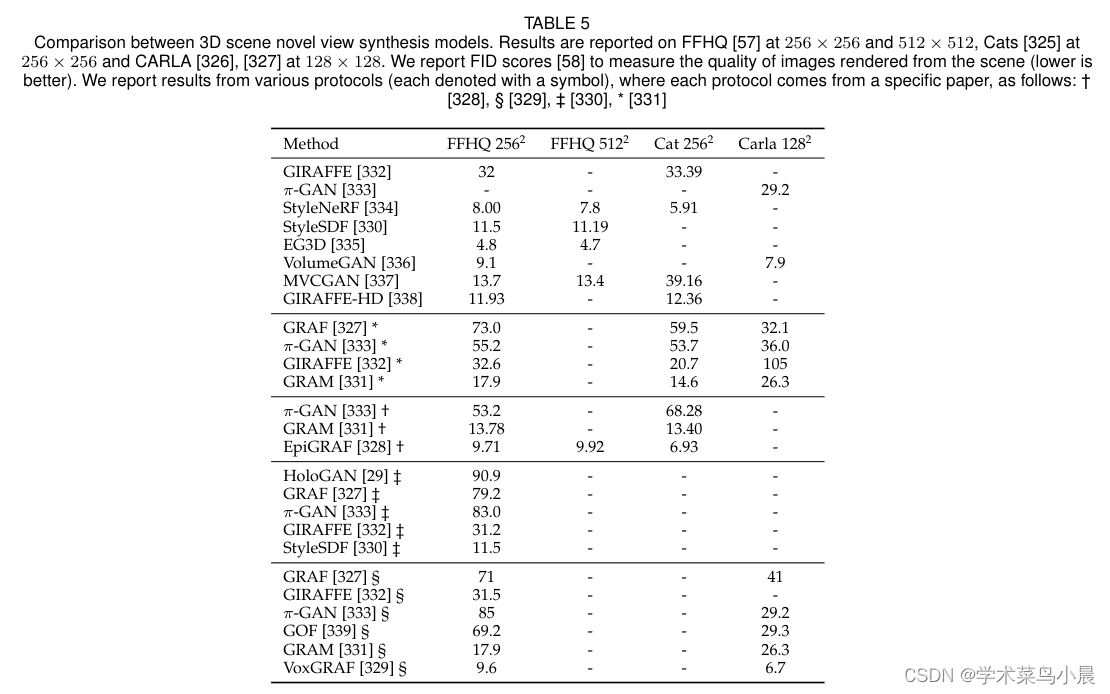
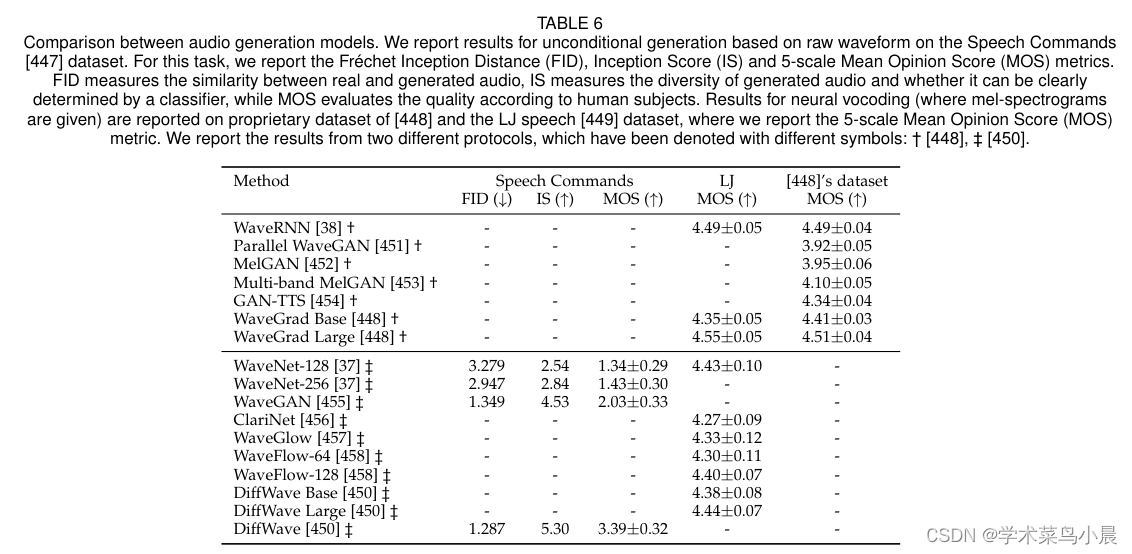
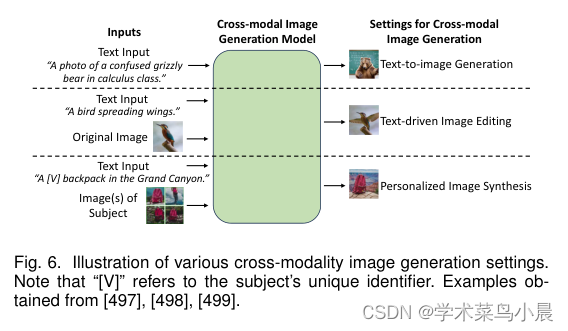
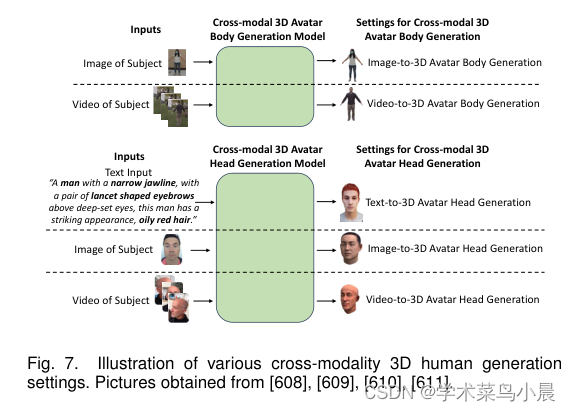


![P3842 [TJOI2007] 线段](https://img-blog.csdnimg.cn/07278fa515b147b791d608e99ac824bb.png)