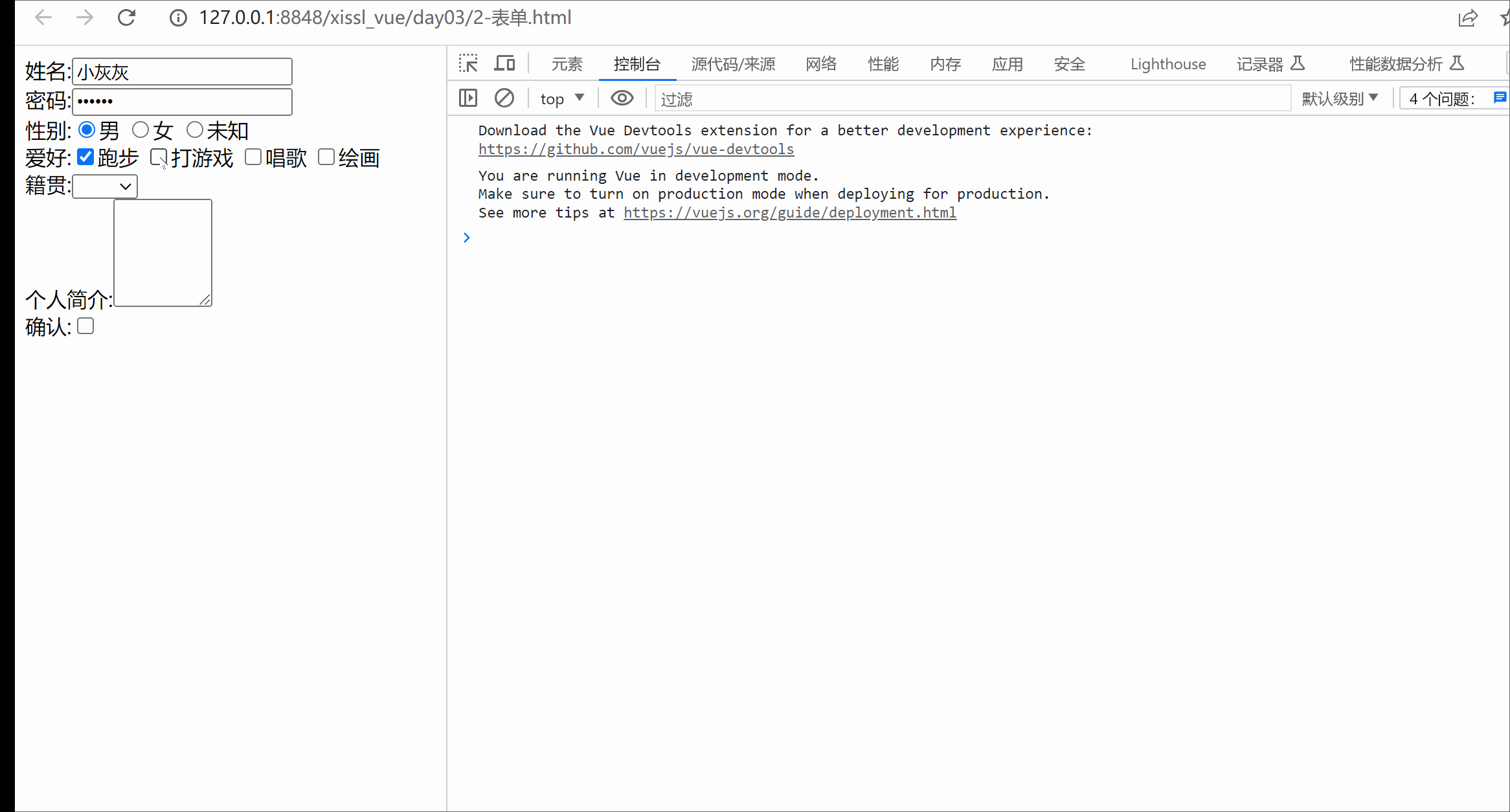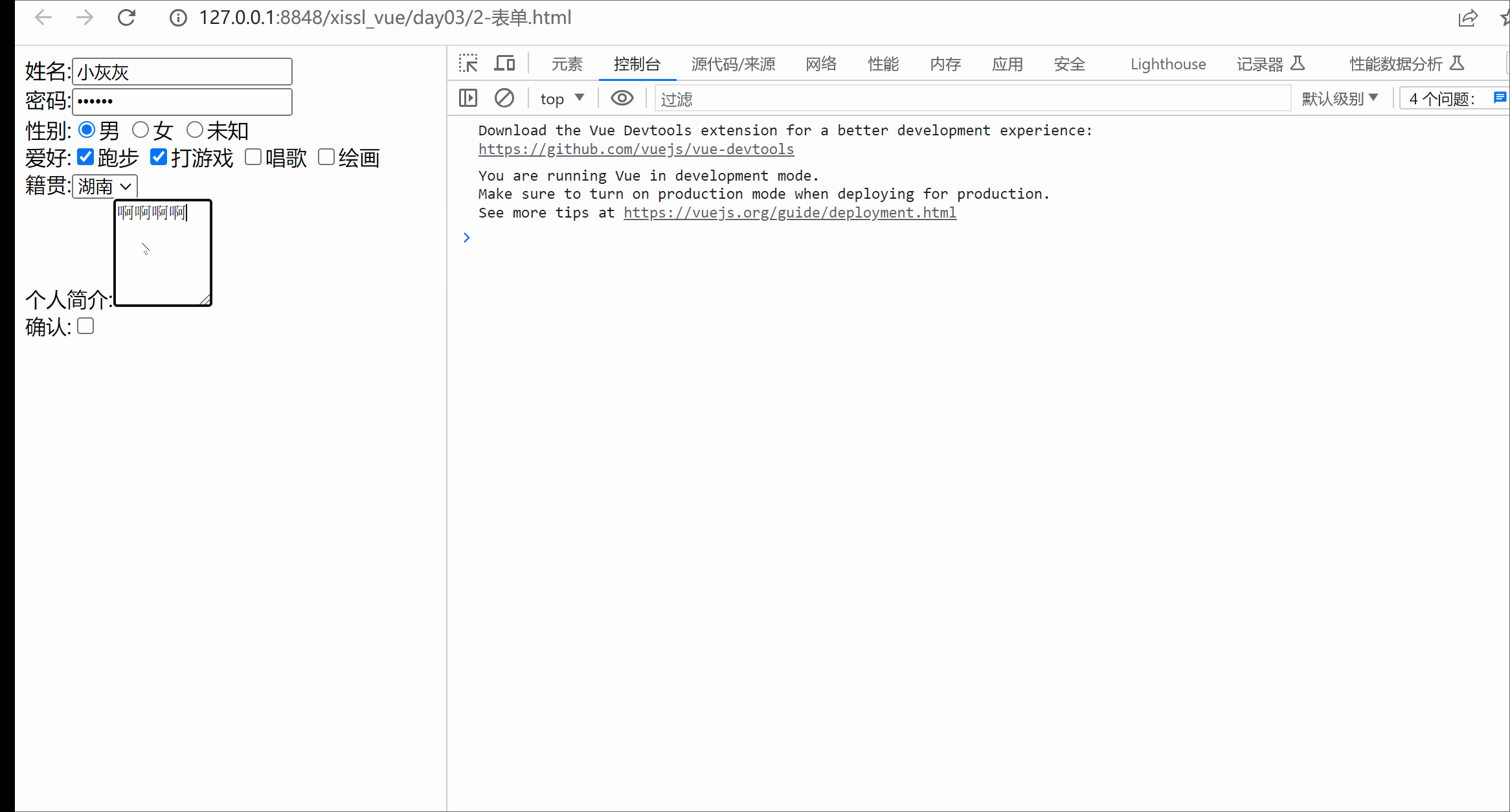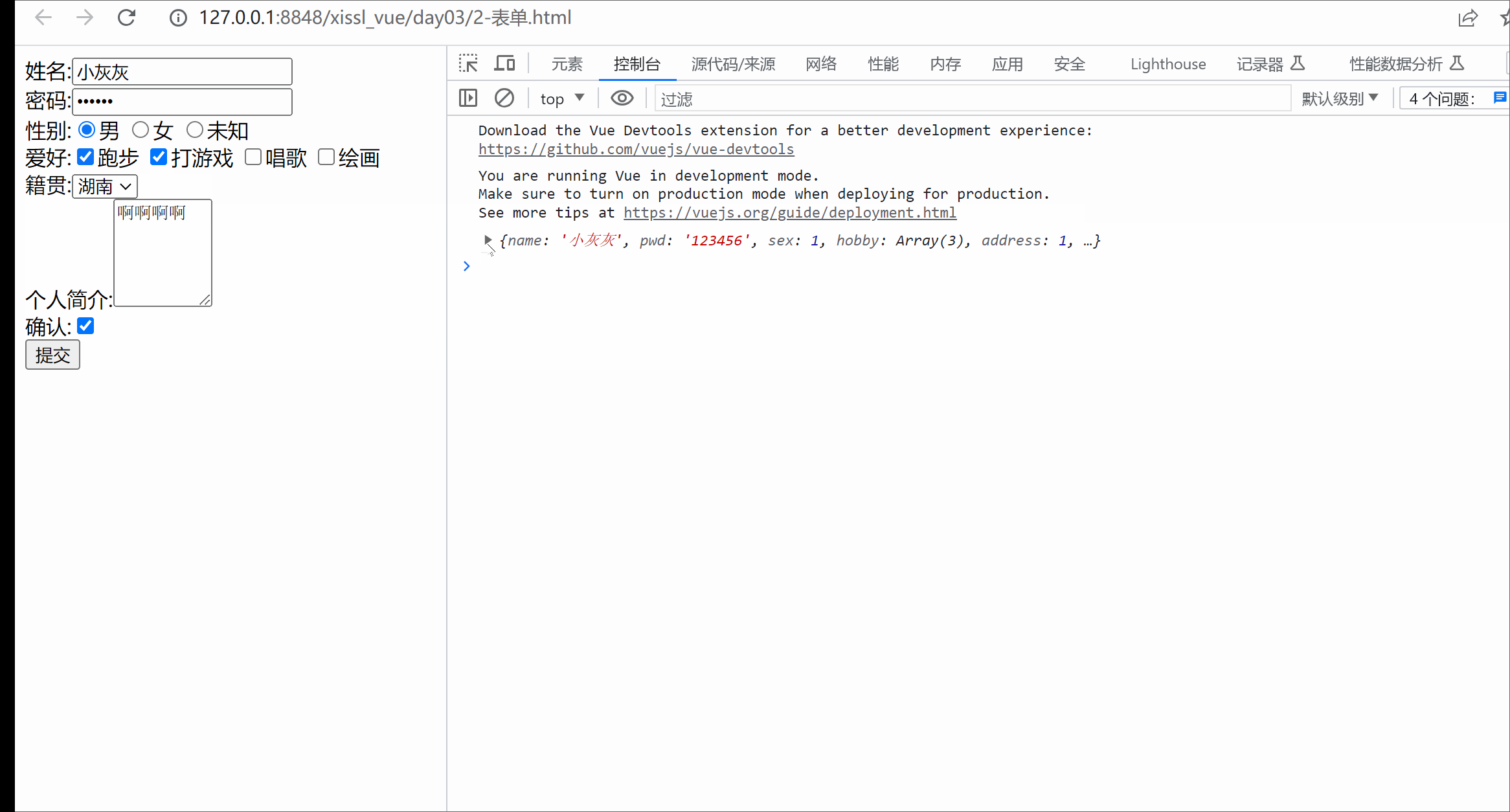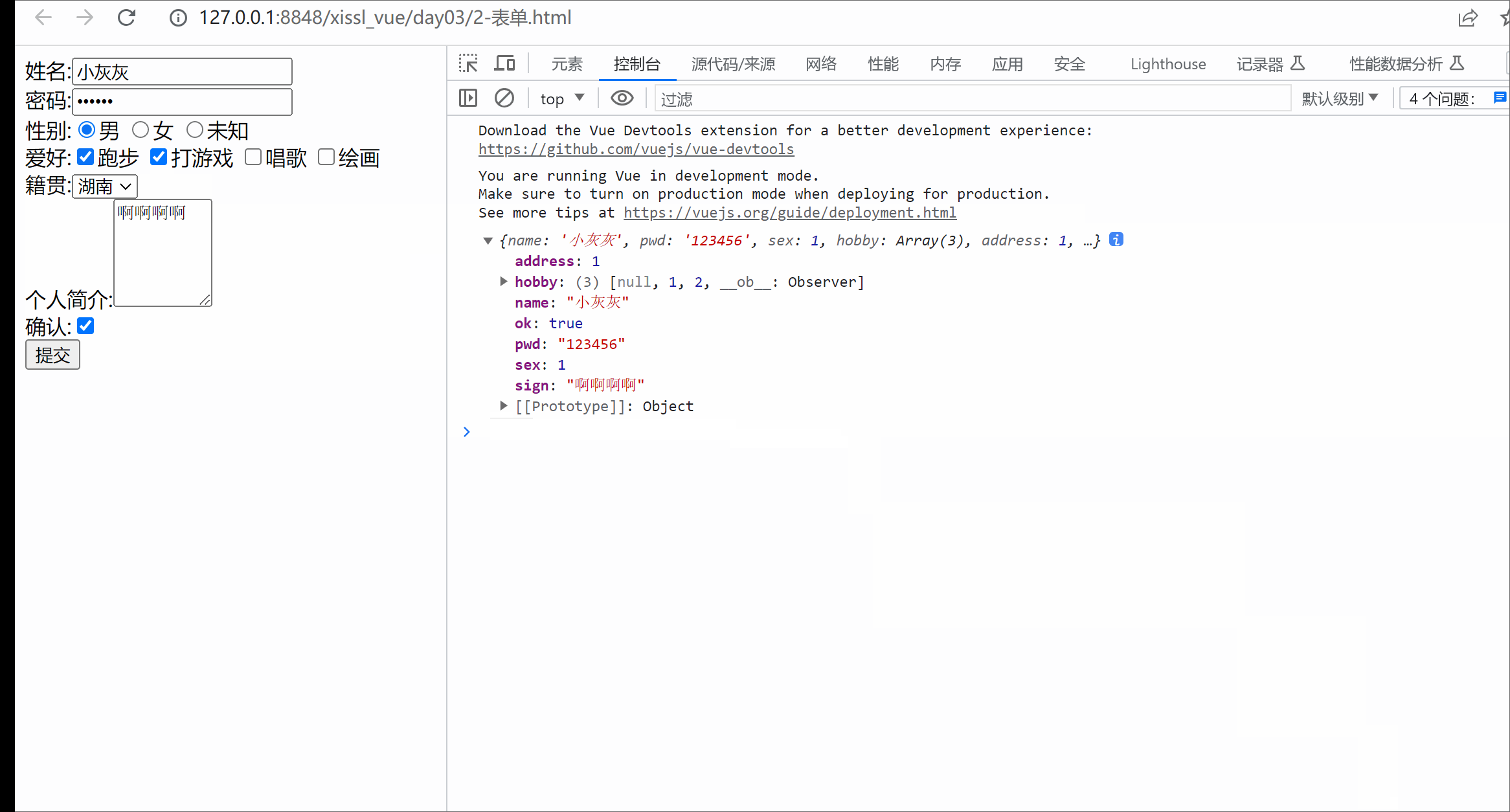
本章概要
- 终端操作
- 数组
- 循环
- 集合
- 组合
- 匹配
- 查找
- 信息
- 数字流信息
终端操作
以下操作将会获取流的最终结果。至此我们无法再继续往后传递流。可以说,终端操作(Terminal Operations)总是我们在流管道中所做的最后一件事。
数组
toArray():将流转换成适当类型的数组。toArray(generator):在特殊情况下,生成自定义类型的数组。
当我们需要得到数组类型的数据以便于后续操作时,上面的方法就很有用。假设我们需要复用流产生的随机数时,就可以这么使用。代码示例:
import java.util.*;
import java.util.stream.*;
public class RandInts {
private static int[] rints = new Random(47).ints(0, 1000).limit(100).toArray();
public static IntStream rands() {
return Arrays.stream(rints);
}
}
上例将100个数值范围在 0 到 1000 之间的随机数流转换成为数组并将其存储在 rints 中。这样一来,每次调用 rands() 的时候可以重复获取相同的整数流。
循环
forEach(Consumer)常见如System.out::println作为 Consumer 函数。forEachOrdered(Consumer): 保证forEach按照原始流顺序操作。
第一种形式:无序操作,仅在引入并行流时才有意义。这里简单介绍下 parallel():可实现多处理器并行操作。实现原理为将流分割为多个(通常数目为 CPU 核心数)并在不同处理器上分别执行操作。因为我们采用的是内部迭代,而不是外部迭代,所以这是可能实现的。
parallel() 看似简单,实则棘手。
下例引入 parallel() 来帮助理解 forEachOrdered(Consumer) 的作用和使用场景。代码示例:
import static base.RandInts.rands;
public class ForEach {
static final int SZ = 14;
public static void main(String[] args) {
rands().limit(SZ)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
rands().limit(SZ)
.parallel()
.forEach(n -> System.out.format("%d ", n));
System.out.println();
rands().limit(SZ)
.parallel()
.forEachOrdered(n -> System.out.format("%d ", n));
}
}
输出结果:
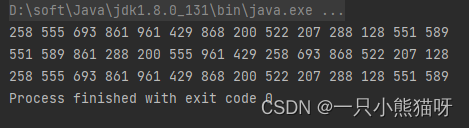
为了方便测试不同大小的流,我们抽离出了 SZ 变量。然而即使 SZ 值为14也产生了有趣的结果。在第一个流中,未使用 parallel() ,因此以元素从 rands()出来的顺序输出结果。在第二个流中,引入parallel() ,即便流很小,输出的结果的顺序也和前面不一样。这是由于多处理器并行操作的原因,如果你将程序多运行几次,你会发现输出都不相同,这是多处理器并行操作的不确定性造成的结果。
在最后一个流中,同时使用了 parallel() 和 forEachOrdered() 来强制保持原始流顺序。因此,对非并行流使用 forEachOrdered() 是没有任何影响的。
集合
collect(Collector):使用 Collector 收集流元素到结果集合中。collect(Supplier, BiConsumer, BiConsumer):同上,第一个参数 Supplier 创建了一个新的结果集合,第二个参数 BiConsumer 将下一个元素收集到结果集合中,第三个参数 BiConsumer 用于将两个结果集合合并起来。
在这里我们只是简单介绍了几个 Collectors 的运用示例。实际上,它还有一些非常复杂的操作实现,可通过查看 java.util.stream.Collectors 的 API 文档了解。例如,我们可以将元素收集到任意一种特定的集合中。
假设我们现在为了保证元素有序,将元素存储在 TreeSet 中。Collectors 里面没有特定的 toTreeSet(),但是我们可以通过将集合的构造函数引用传递给 Collectors.toCollection(),从而构建任何类型的集合。下面我们来将一个文件中的单词收集到 TreeSet 集合中。代码示例:
import java.util.*;
import java.nio.file.*;
import java.util.stream.*;
public class TreeSetOfWords {
public static void
main(String[] args) throws Exception {
Set<String> words2 =
Files.lines(Paths.get("D:\\onJava\\myTest\\base\\TreeSetOfWords.java"))
.flatMap(s -> Arrays.stream(s.split("\\W+")))
.filter(s -> !s.matches("\\d+")) // No numbers
.map(String::trim)
.filter(s -> s.length() > 2)
.limit(100)
.collect(Collectors.toCollection(TreeSet::new));
System.out.println(words2);
}
}
输出结果:

Files.lines() 打开 Path 并将其转换成为由行组成的流。下一行代码以一个或多个非单词字符(\\W+)为分界,对每一行进行分割,结果是产生一个数组,然后使用 Arrays.stream() 将数组转化成为流,最后flatMap()将各行形成的多个单词流,扁平映射为一个单词流。使用 matches(\\d+) 查找并移除全部是数字的字符串(注意,words2 是通过的)。然后用 String.trim() 去除单词两边的空白,filter() 过滤所有长度小于3的单词,并只获取前100个单词,最后将其保存到 TreeSet 中。
我们也可以在流中生成 Map。代码示例:
import java.util.*;
import java.util.stream.*;
class Pair {
public final Character c;
public final Integer i;
Pair(Character c, Integer i) {
this.c = c;
this.i = i;
}
public Character getC() {
return c;
}
public Integer getI() {
return i;
}
@Override
public String toString() {
return "Pair(" + c + ", " + i + ")";
}
}
class RandomPair {
Random rand = new Random(47);
// An infinite iterator of random capital letters:
Iterator<Character> capChars = rand.ints(65, 91)
.mapToObj(i -> (char) i)
.iterator();
public Stream<Pair> stream() {
return rand.ints(100, 1000).distinct()
.mapToObj(i -> new Pair(capChars.next(), i));
}
}
public class MapCollector {
public static void main(String[] args) {
Map<Integer, Character> map =
new RandomPair().stream()
.limit(8)
.collect(
Collectors.toMap(Pair::getI, Pair::getC));
System.out.println(map);
}
}
输出结果:
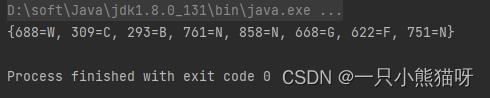
Pair 只是一个基础的数据对象。RandomPair 创建了随机生成的 Pair 对象流。在 Java 中,我们不能直接以某种方式组合两个流。所以我创建了一个整数流,并且使用 mapToObj() 将整数流转化成为 Pair 流。 capChars的随机大写字母迭代器创建了流,然后next()让我们可以在stream()中使用这个流。就我所知,这是将多个流组合成新的对象流的唯一方法。
在这里,我们只使用最简单形式的 Collectors.toMap(),这个方法只需要两个从流中获取键和值的函数。还有其他重载形式,其中一种当是键发生冲突时,使用一个函数来处理冲突。
大多数情况下,java.util.stream.Collectors 中预设的 Collector 就能满足我们的要求。除此之外,你还可以使用第二种形式的 collect()。 我把它留作更高级的练习,下例给出基本用法:
SpecialCollector.java
import java.util.*;
import java.util.stream.*;
public class SpecialCollector {
public static void main(String[] args) throws Exception {
ArrayList<String> words =
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat")
.collect(ArrayList::new,
ArrayList::add,
ArrayList::addAll);
words.stream()
.filter(s -> s.equals("cheese"))
.forEach(System.out::println);
}
}
FileToWords.java
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.regex.Pattern;
import java.util.stream.Stream;
public class FileToWords {
public static Stream<String> stream(String filePath)
throws Exception {
return Files.lines(Paths.get(filePath))
.skip(1) // First (comment) line
.flatMap(line ->
Pattern.compile("\\W+").splitAsStream(line));
}
}
Cheese.dat
// streams/Cheese.dat
Not much of a cheese shop really, is it?
Finest in the district, sir.
And what leads you to that conclusion?
Well, it's so clean.
It's certainly uncontaminated by cheese.
输出结果:
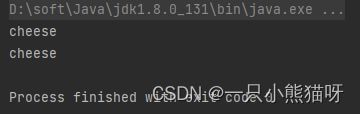
在这里, ArrayList 的方法已经做了你所需要的操作,但更有可能的是,如果你必须使用这种形式的 collect(),就要自己创建特定的定义。
组合
reduce(BinaryOperator):使用 BinaryOperator 来组合所有流中的元素。因为流可能为空,其返回值为 Optional。reduce(identity, BinaryOperator):功能同上,但是使用 identity 作为其组合的初始值。因此如果流为空,identity 就是结果。reduce(identity, BiFunction, BinaryOperator):更复杂的使用形式(暂不介绍),这里把它包含在内,因为它可以提高效率。通常,我们可以显式地组合map()和reduce()来更简单的表达它。
下面来看下 reduce 的代码示例:
import java.util.*;
import java.util.stream.*;
class Frobnitz {
int size;
Frobnitz(int sz) {
size = sz;
}
@Override
public String toString() {
return "Frobnitz(" + size + ")";
}
// Generator:
static Random rand = new Random(47);
static final int BOUND = 100;
static Frobnitz supply() {
return new Frobnitz(rand.nextInt(BOUND));
}
}
public class Reduce {
public static void main(String[] args) {
Stream.generate(Frobnitz::supply)
.limit(10)
.peek(System.out::println)
.reduce((fr0, fr1) -> fr0.size < 50 ? fr0 : fr1)
.ifPresent(System.out::println);
}
}
输出结果:
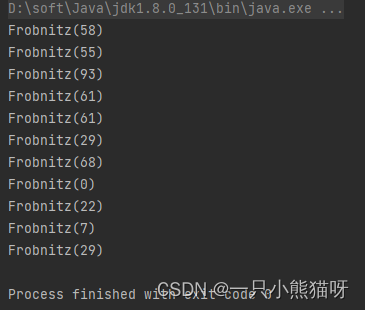
Frobnitz 包含一个可生成自身的生成器 supply() ;因为 supply() 方法作为一个 Supplier<Frobnitz> 是签名兼容的,我们可以把 supply() 作为一个方法引用传递给 Stream.generate() (这种签名兼容性被称作结构一致性)。我们使用了没有“初始值”作为第一个参数的 reduce()方法,所以产生的结果是 Optional 类型。Optional.ifPresent() 方法只有在结果非空的时候才会调用 Consumer<Frobnitz> (println 方法可以被调用是因为 Frobnitz 可以通过 toString() 方法转换成 String)。
Lambda 表达式中的第一个参数 fr0 是 reduce() 中上一次调用的结果。而第二个参数 fr1 是从流传递过来的值。
reduce() 中的 Lambda 表达式使用了三元表达式来获取结果,当 fr0 的 size 值小于 50 的时候,将 fr0 作为结果,否则将序列中的下一个元素即 fr1作为结果。当取得第一个 size 值小于 50 的 Frobnitz,只要得到这个结果就会忽略流中其他元素。这是个非常奇怪的限制, 但也确实让我们对 reduce() 有了更多的了解。
匹配
allMatch(Predicate):如果流的每个元素提供给 Predicate 都返回 true ,结果返回为 true。在第一个 false 时,则停止执行计算。anyMatch(Predicate):如果流的任意一个元素提供给 Predicate 返回 true ,结果返回为 true。在第一个 true 是停止执行计算。noneMatch(Predicate):如果流的每个元素提供给 Predicate 都返回 false 时,结果返回为 true。在第一个 true 时停止执行计算。
我们已经在 Prime.java 中看到了 noneMatch() 的示例;allMatch() 和 anyMatch() 的用法基本上是等同的。下面我们来探究一下短路行为。为了消除冗余代码,我们创建了 show()。首先我们必须知道如何统一地描述这三个匹配器的操作,然后再将其转换为 Matcher 接口。代码示例:
import java.util.stream.*;
import java.util.function.*;
interface Matcher extends BiPredicate<Stream<Integer>, Predicate<Integer>> {
}
public class Matching {
static void show(Matcher match, int val) {
System.out.println(
match.test(
IntStream.rangeClosed(1, 9)
.boxed()
.peek(n -> System.out.format("%d ", n)),
n -> n < val));
}
public static void main(String[] args) {
show(Stream::allMatch, 10);
show(Stream::allMatch, 4);
show(Stream::anyMatch, 2);
show(Stream::anyMatch, 0);
show(Stream::noneMatch, 5);
show(Stream::noneMatch, 0);
}
}
输出结果:
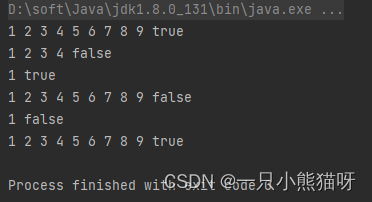
BiPredicate 是一个二元谓词,它接受两个参数并返回 true 或者 false。第一个参数是我们要测试的流,第二个参数是一个谓词 Predicate。Matcher 可以匹配所有的 Stream::Match 方法,所以可以将每一个Stream::*Match方法引用传递到 show() 中。对match.test() 的调用会被转换成 对方法引用Stream::Match 的调用。
show() 接受一个Matcher和一个 val 参数,val 在判断测试 n < val中指定了最大值。show() 方法生成了整数1-9组成的一个流。peek()用来展示在测试短路之前测试进行到了哪一步。从输出中可以看到每次都发生了短路。
查找
findFirst():返回第一个流元素的 Optional,如果流为空返回 Optional.empty。findAny(:返回含有任意流元素的 Optional,如果流为空返回 Optional.empty。
代码示例:
import static base.RandInts.rands;
public class SelectElement {
public static void main(String[] args) {
System.out.println(rands().findFirst().getAsInt());
System.out.println(
rands().parallel().findFirst().getAsInt());
System.out.println(rands().findAny().getAsInt());
System.out.println(
rands().parallel().findAny().getAsInt());
}
}
输出结果:
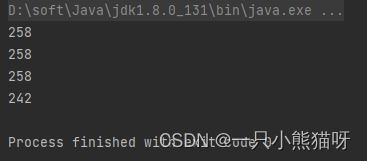
无论流是否为并行化,findFirst() 总是会选择流中的第一个元素。对于非并行流,findAny()会选择流中的第一个元素(即使从定义上来看是选择任意元素)。在这个例子中,用 parallel() 将流并行化,以展示 findAny() 不选择流的第一个元素的可能性。
如果必须选择流中最后一个元素,那就使用 reduce()。代码示例:
import java.util.*;
import java.util.stream.*;
public class LastElement {
public static void main(String[] args) {
OptionalInt last = IntStream.range(10, 20)
.reduce((n1, n2) -> n2);
System.out.println(last.orElse(-1));
// Non-numeric object:
Optional<String> lastobj =
Stream.of("one", "two", "three")
.reduce((n1, n2) -> n2);
System.out.println(
lastobj.orElse("Nothing there!"));
}
}
输出结果:
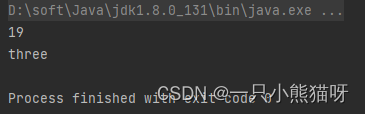
reduce() 的参数只是用最后一个元素替换了最后两个元素,最终只生成最后一个元素。如果为数字流,你必须使用相近的数字 Optional 类型( numeric optional type),否则使用 Optional 类型,就像上例中的 Optional<String>。
信息
count():流中的元素个数。max(Comparator):根据所传入的 Comparator 所决定的“最大”元素。min(Comparator):根据所传入的 Comparator 所决定的“最小”元素。
String 类型有预设的 Comparator 实现。代码示例:
public class Informational {
public static void
main(String[] args) throws Exception {
System.out.println(
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat").count());
System.out.println(
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat")
.min(String.CASE_INSENSITIVE_ORDER)
.orElse("NONE"));
System.out.println(
FileToWords.stream("D:\\onJava\\myTest\\base\\Cheese.dat")
.max(String.CASE_INSENSITIVE_ORDER)
.orElse("NONE"));
}
}
输出结果:
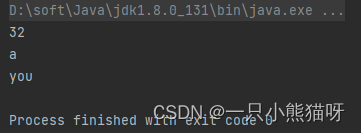
min() 和 max() 的返回类型为 Optional,这需要我们使用 orElse()来解包。
数字流信息
average():求取流元素平均值。max()和min():数值流操作无需 Comparator。sum():对所有流元素进行求和。summaryStatistics():生成可能有用的数据。目前并不太清楚这个方法存在的必要性,因为我们其实可以用更直接的方法获得需要的数据。
import static base.RandInts.rands;
public class NumericStreamInfo {
public static void main(String[] args) {
System.out.println(rands().average().getAsDouble());
System.out.println(rands().max().getAsInt());
System.out.println(rands().min().getAsInt());
System.out.println(rands().sum());
System.out.println(rands().summaryStatistics());
}
}
输出结果:
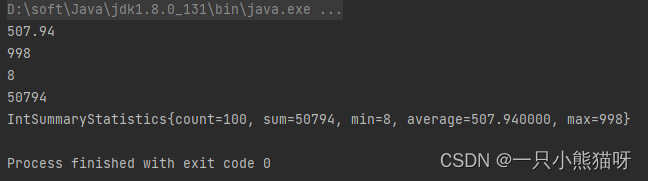
上例操作对于 LongStream 和 DoubleStream 同样适用。