高斯朴素贝叶斯Gaussian Naive Bayes (GaussianNB).
可通过 partial_fit 对模型参数进行在线更新
一、算法思路
所谓高斯贝叶斯指的便是假定样本每个特征维度的条件概率均服从高斯分布,进而再根据贝叶斯公式来计算得到新样本在某个特征分布下其属于各个类别的后验概率,最后通过极大化后验概率来确定样本的所属类别。
二、官网API
官网API
导包:from sklearn.naive_bayes import GaussianNB
class sklearn.naive_bayes.GaussianNB(*, priors=None, var_smoothing=1e-09)
①类别的先验概率priors
priors,类别的先验概率。如果指定,则不会根据数据调整先验概率
参数形状类似array数组,默认为None
具体官网详情如下:

使用方法
beyond = ["fiber","pilling"]
gaussian = GaussianNB(priors=beyond)
②var_smoothing
所有特征中最大方差的一部分,为保证计算的稳定性而添加到方差中
参数是个浮点数,默认10的-9次方
具体官网详情如下:

使用方法
GaussianNB(var_smoothing=1e-8)
③最终构建模型
GaussianNB(var_smoothing=1e-8)
三、代码实现
①导包
这里需要评估、训练、保存和加载模型,以下是一些必要的包,若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import joblib
%matplotlib inline
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
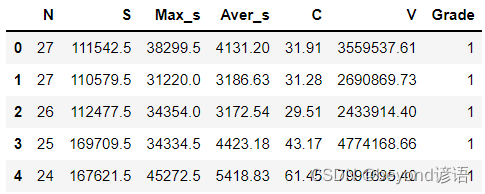
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③划分数据集
前六列是自变量X,最后一列是因变量Y
常用的划分数据集函数官网API:train_test_split
test_size:测试集数据所占比例
train_size:训练集数据所占比例
random_state:随机种子
shuffle:是否将数据进行打乱
因为我这里的数据集共48个,训练集0.75,测试集0.25,即训练集36个,测试集12个
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)
print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
④构建GaussianNB模型
参数可以自己去尝试设置调整
gaussian = GaussianNB(var_smoothing=1e-8)
⑤模型训练
就这么简单,一个fit函数就可以实现模型训练
gaussian.fit(X_train,y_train)
⑥模型评估
把测试集扔进去,得到预测的测试结果
y_pred = gaussian.predict(X_test)
看看预测结果和实际测试集结果是否一致,一致为1否则为0,取个平均值就是准确率
accuracy = np.mean(y_pred==y_test)
print(accuracy)
也可以通过score得分进行评估,计算的结果和思路都是一样的,都是看所有的数据集中模型猜对的概率,只不过这个score函数已经封装好了,当然传入的参数也不一样,需要导入accuracy_score才行,from sklearn.metrics import accuracy_score
score = gaussian.score(X_test,y_test)#得分
print(score)
⑦模型测试
拿到一条数据,使用训练好的模型进行评估
这里是六个自变量,我这里随机整个test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
扔到模型里面得到预测结果,prediction = gaussian.predict(test)
看下预测结果是多少,是否和正确结果相同,print(prediction)
test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
prediction = gaussian.predict(test)
print(prediction) #[2]
⑧保存模型
lsvc是模型名称,需要对应一致
后面的参数是保存模型的路径
joblib.dump(gaussian, './gaussian.model')#保存模型
⑨加载和使用模型
gaussian_yy = joblib.load('./gaussian.model')
test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据
prediction = gaussian_yy.predict(test)#带入数据,预测一下
print(prediction) #[4]
完整代码
模型训练和评估,不包含⑧⑨。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import joblib
%matplotlib inline
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)
print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
gaussian = GaussianNB(var_smoothing=1e-8)
gaussian.fit(X_train,y_train)
y_pred = gaussian.predict(X_test)
accuracy = np.mean(y_pred==y_test)
print(accuracy)
score = gaussian.score(X_test,y_test)#得分
print(score)
test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
prediction = gaussian.predict(test)
print(prediction) #[2]