在做PHP采集内容时,用过querylist采集组件,但是这个插件采集页面内容时,都必须要写个采集选择器。这样比较麻烦,每个文章页面都必须指定一条采集规则 。就开始着手找一个插件可以能自动识别任意文章url正文内容并采集的,发现有一个插件,是采集内容标签给每个标签拆开后打分来分析出正文内容的,下面给大家展示实现的过程及代码。
先看截图:
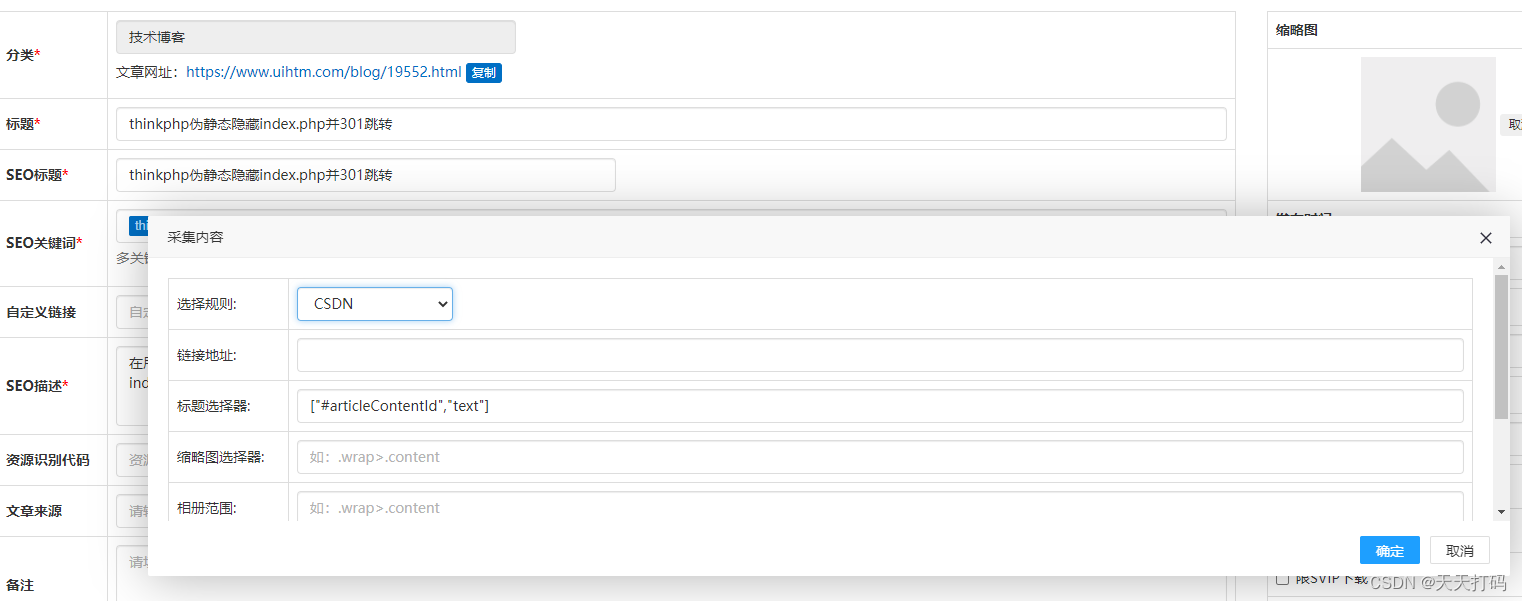
采集代码:
try{
$ql = QueryList::get($url);
}catch(RequestException $e){
//print_r($e->getRequest());
return json(['status'=>false,'msg'=>'Http Error:服务器错误,url不存在']);die;
}
//queryData 方法等同于 query()->getData()->all()
//$query = $ql->rules($rules)->queryData();
$title_rule = json_decode(htmlspecialchars_decode($title_rule),true);
$content_rule = json_decode(htmlspecialchars_decode($content_rule),true);
if($thumb_rule)
$thumb_rule = json_decode(htmlspecialchars_decode($thumb_rule),true);
$photos_range = htmlspecialchars_decode($photos_range);
if(is_array($content_rule)&&is_array($title_rule))
{
$rules = [
'title' => $title_rule,
'seo_title' => ['title','text'],
'keywords' => ['meta[name=keywords]','content'],
'description' => ['meta[name=description]','content'],
'content' => $content_rule,
'thumb' => $thumb_rule
];
if(empty($thumb_rule))
unset($rules['thumb']);
}
else
{
$rules = [
'title' => ['h1','text'],
'seo_title' => ['title','text'],
'keywords' => ['meta[name=keywords]','content'],
'description' => ['meta[name=description]','content'],
'content' => [$content_rule,'html','-a -ul -li -.group-post-list'],
'thumb' => [$thumb_rule,'src']
];
}
$query = $ql->rules($rules)->queryData();
这些写对于每个页面都要定好规则,比较麻烦有没有一种组件可以任意网址自动识别采集正文内容的,
先看效果
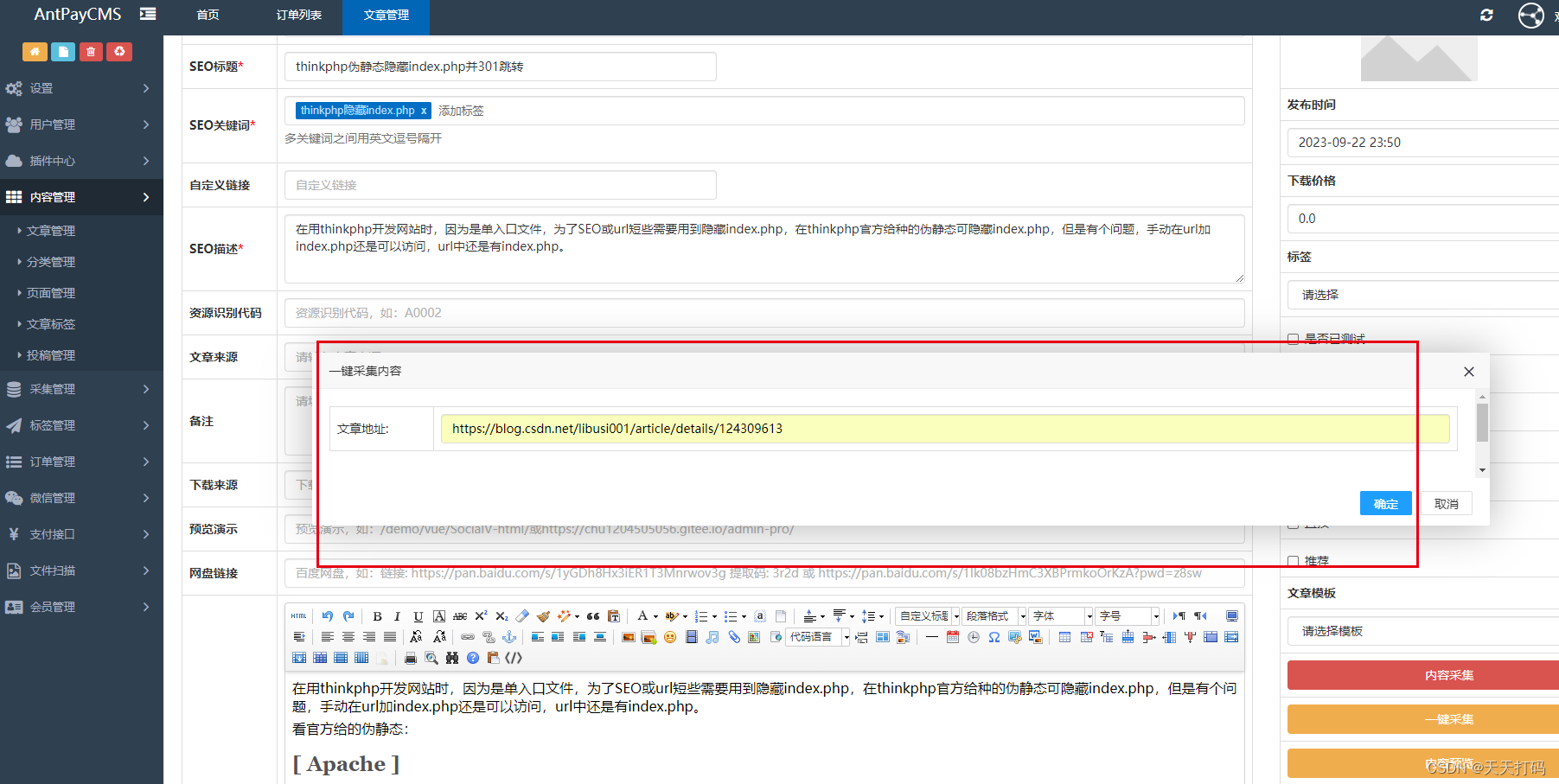
只需要输入一个文章的网站,自动识别正文内容并采集
主要用的一个插件readability,git地址: https://github.com/andreskrey/readability.php
代码:
$html = file_get_contents($url);
$readability = new Readability(new Configuration());
$readability->parse($html);
$data['title'] = $readability->getTitle();
$data['seo_title'] = $readability->getTitle();

![CTF 全讲解:[SWPUCTF 2021 新生赛]jicao](https://img-blog.csdnimg.cn/641481c6333043d3930ddac3b19a5573.png)