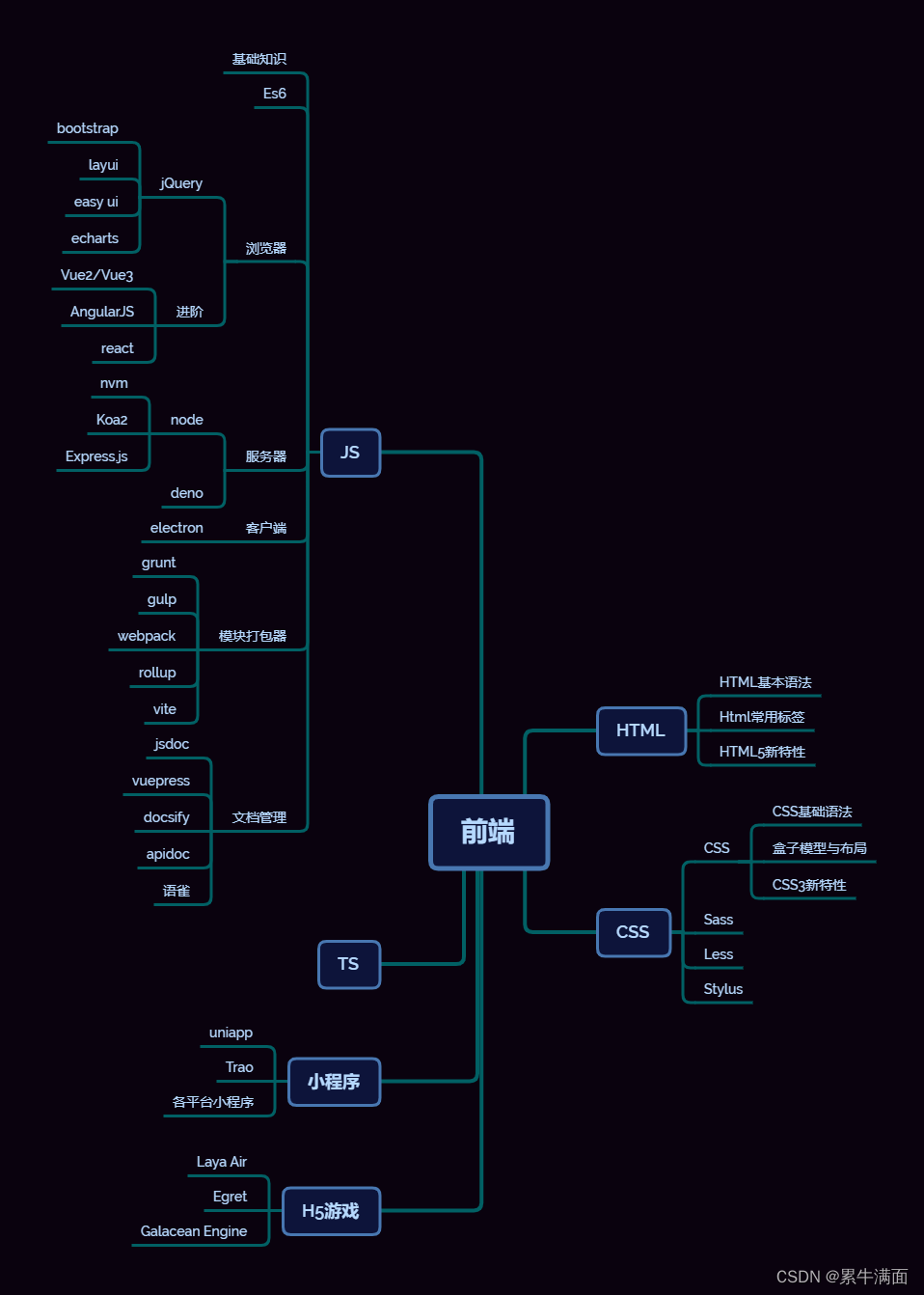
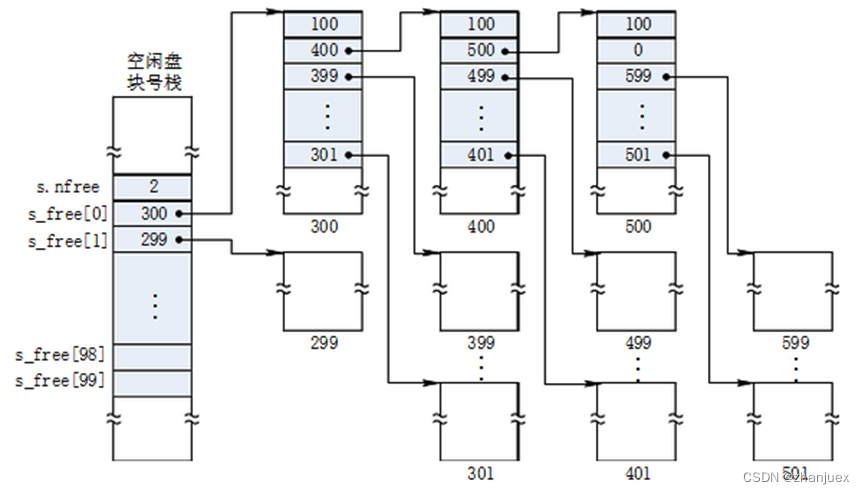
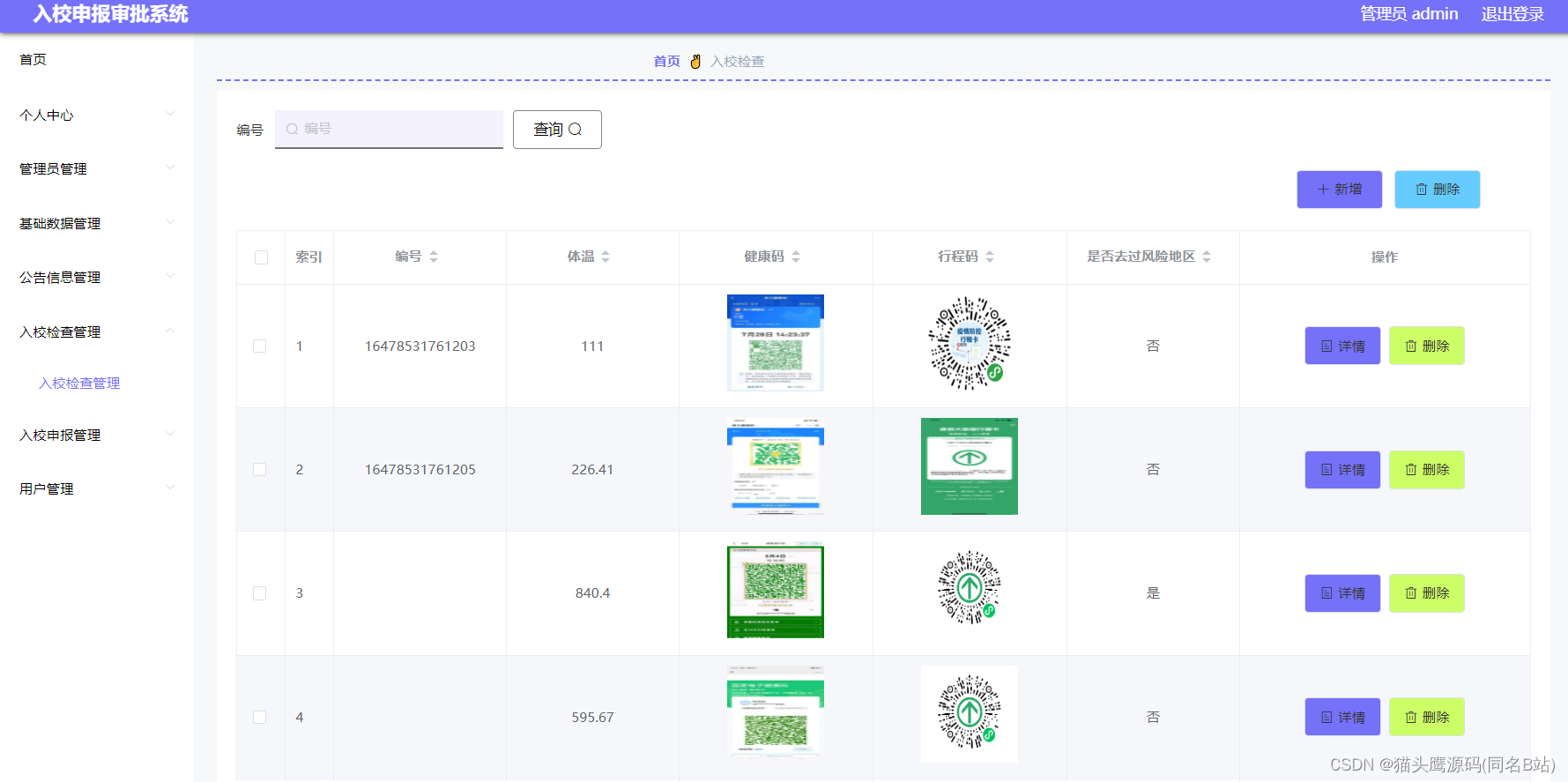
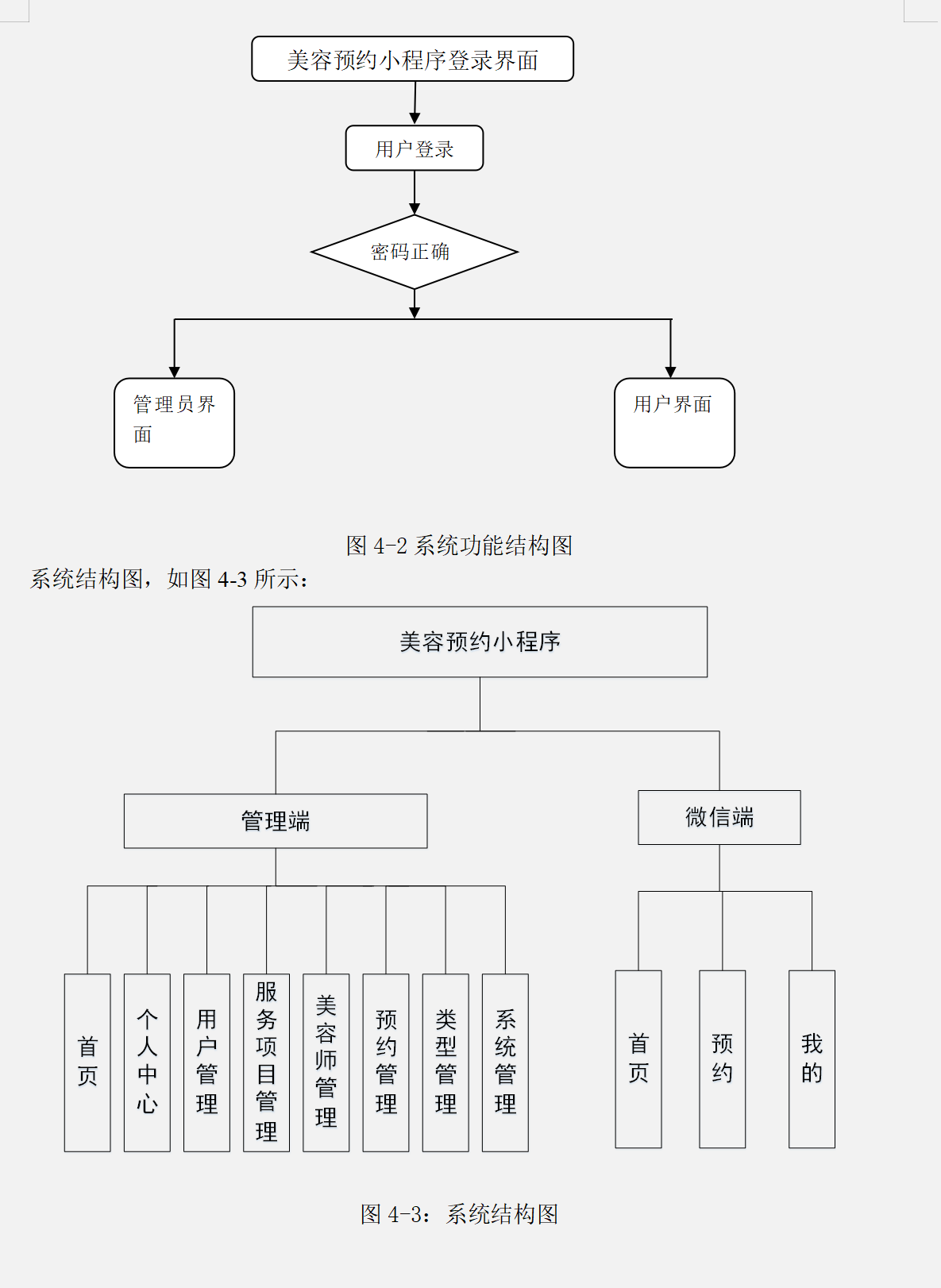
基于 Transformer 架构以及 Attention 机制,一系列预训练语言模型被不断提出。
BERT
2018 年 10 月, Google AI 研究院的 Jacob Devlin 等人提出了 BERT (Bidirectional Encoder Representation from Transformers ) 。具体的研究论文发布在 arXiv 上,标题是《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
BERT 利用掩码机制构造了基于上下文预测中间词的预训练任务, 相较于传统的语言模型建模方法, BERT 能进一步挖掘上下文所带来的丰富语义,这在很大程度上提高了自然语言处理任务的任务性能。
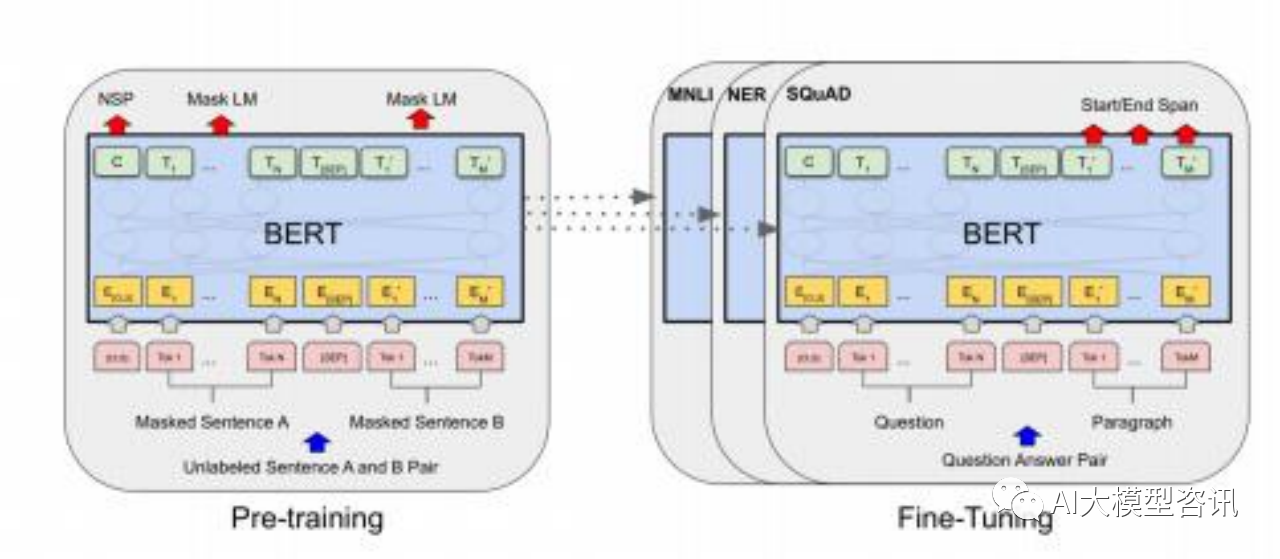
BERT 模型的预训练和优调示例
BERT 所采用的神经结构由多层 Transformer 编码器组成, 这意味着在编码过程中, 每个位置都能获得所有 位置的信息, 而不仅仅是历史位置的信息。BERT 同样由输入层, 编码层和输出层三部分组成。BERT 的训练数 据为 BooksCorpus (8 亿个单词) 和英文版的Wikipedia (25 亿个单词) 并只保留段落文本。BERT 先是采用无标 签数据进行多个预训练步骤, 再使用下游任务的标签数据进行微调。BERT 的输入部分为每一个 token 对应的表 征, 由 WordPiece 构建。每个序列开头都有一个用来分类的 token[CLS], 该token 的最后一层用来聚集整个序列 表征信息。因为多句句子会被包含在一个序列里, 所以不同句子间会被 token[SEP] 分割, 并且每个 token 会被添 加一个 learned embedding 以表明其从属句子。
在预训练时, 模型的最后有两个输出层 MLM 和 NSP,分别对应了两个不同的预训练任务:掩码语言模型 (Masked Language Modeling ,MLM)和下一句预测(Next Sentence Prediction ,NSP )。
-
Masked Language Model (MLM) 因为双向语言模型与从左到右或从右到左的语言模型不同, 其训练时会使 各个单词间接地“看到自己”。因此, 在将训练序列喂给模型前, BERT 以 15%的概率将序列中的 token 替换成 [MASK] token。为了解决因为 [MASK] 不会出现在下游任务的微调阶段而产生预训练阶段和微调阶段之间产生 的不匹配问题, BERT 将被选中替换成 [MASK] 的 token 中, 80%直接替换成 [MASK],10%替换成其他单词, 剩 余 10%则不变。
-
Next Sentence Prediction (NSP) 为了处理一些基于句子之间的关系的问题,BERT 采用next sentence prediction 任务来判断两句句子是否是上下句。在每个训练样例中, BERT 从训练数据库中挑选 A 和 B 两句句子, 50%B 是A 的下句(类别标为 IsNext), 50%则不是(类别标为 NotNext)。之后 BERT 将类别储存在 [CLS] 中并输入样例 去预测。
完成预训练之后, BERT 使用下游任务的标签数据进行微调。任务种类包括:句子对的分类任务, 单 个句子的分类任务,问答任务和命名实体识别任务。
BERT 的出现具有重要意义, 不仅在于其出色的表现, 更启发了的大量的后续工作, 尤其是“预训练 + 参数 微调”的研究范式。根据这一范式,此后出现了更多的预训练语言模型。

BERT 在不同任务下的微调:(左)句子对的分类任务;(右)单个句子的分类任务
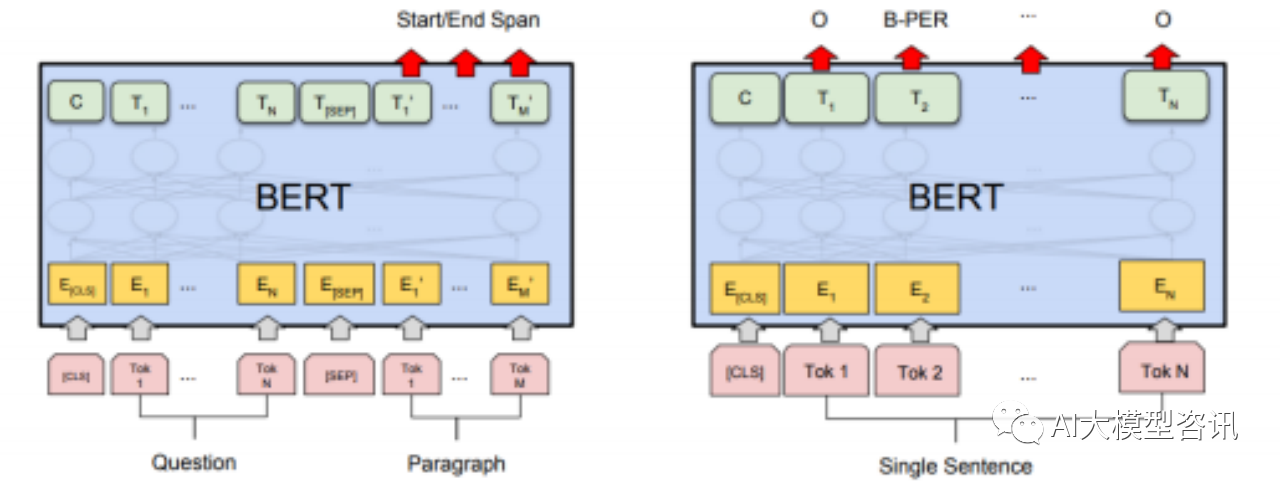
BERT 在不同任务下的微调:(左)问答任务;(右)命名实体识别任务
BERT 在 11 个 NLP 任务中获得了 state-of-the-art 的结果, 包含 GLUE,MultiNLI ,SQuAD v1. 1,和 SQuAD v2.0。后续也有许多建立在 BERT 的基础上进行改善的模型,例如 RoBERTa,DistilBERT和 ALBERT。RoBERTa 使用了更庞大的数据量, 训练了更长的时间, 优化了 Adam 参数, 动态地进行 mask 操作并取消了 NSP任务以获得更好的结果。DistilBERT 使用蒸馏技术来减小模型规模, 该模型比 BERT 小 40%,运行速度快 60%,并保 留 97%BERT 的准确率。ALBERT 则利用两个缩减参数的技术, factorized embedding parameterization 和 cross-layer parameter sharing 减少 BERT 的运行时间和内存容量消耗。
ELECTRA
ELECTRA,全名为Efficiently Learning an Encoder that Classifies Token Replacements Accurately。ELECTRA 的模型结构为生成器(Generator)加上辨别器(Discriminator)。
与 BERT 不同, ELECTRA 的预训练任务是 replaced token detection 目的是判断当前的 token 是否被替换 过。生成器是 BERT 里所使用的 MLM,以被 mask 过的输入序列生成新的文本。辨别器接收生成器生成的文本 后, 分辨每一个 token 是 original 还是 replaced。虽然与生成对抗网络 GAN (Generative Adversarial Network) 结 构类似, 但两者有明显的不同点。如果生成器生成的文本与原来的相同, 辨别器会判断其为“真”而非“假”。生 成器的目的是为了学习语言模型, 而不是为了欺骗辨别器。输入生成器的也是真实文本, 并非噪音。ELECTRA 辨别器的梯度不会传到生成器,而 GAN 辨别器的梯度会传给生成器。

ELECTRA Replaced token detection 图示
ELECTRA 的目标函数为:
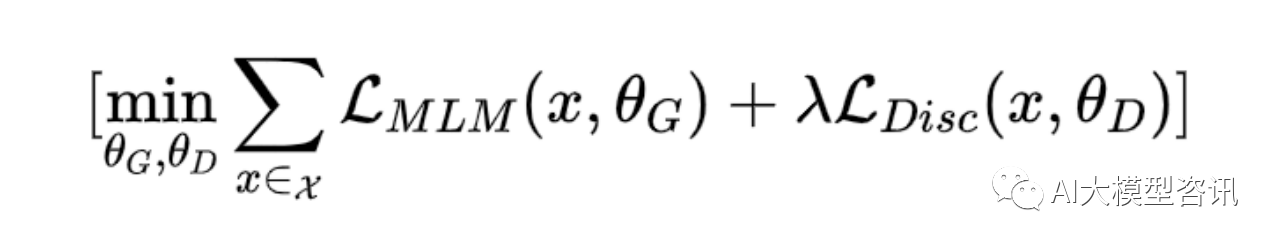
在实验阶段, 作者认为分享生成器和辨别器的权重会提高预训练的效率。如果生成器与辨别器的尺寸相同, 两者可以共享所有参数。然而作者发现使用一个更小的尺寸的生成器更有效率, 并且采用 MLM 训练的生成器 对 embedding 有更好的学习能力,因此只能共享生成器embedding 的权重。
之后作者提议缩小生成器的尺寸以提高训练效率。在保持其他参数不变仅减少 hidden size 的情况下, 作者 发现模型表现在生成器尺寸为辨别器尺寸的 1/4 到 1/2 大小时最为优秀。作者推测如果生成器过于强大的话会影 响辨别器学习的效率(因为绝大部分的 token 都会是 original)。
作者也尝试使用其他学习策略:two-stage 训练和对抗学习。Two-stage 训练是先只训练生成器,然后将生成 器冻结并用生成器的权重初始化判别器, 再单独训练辨别器。对抗学习的方法类似于 GAN,作者将目标函数中 最小化 MLM loss 替换成了最大化判别器在被替换 token 上的 RTD loss,并且使用强化学习 Policy Gradient 的思 想处理新生成器的 loss 无法用梯度上升更新生成器的问题。但是两种方法的表现都没有原训练方式效果出色。
为了达到提高预训练的效率的目的,作者又构建了能在单张 GPU 上训练的小模型 BERT-Small 和ELECTRA- Small 。经过实验对比, BERT-Small 不仅参数量只有 14M,训练效率和表现结果都比 ELMo 和 GPT 等模型要优秀。作者最后又比较了其他的预训练方法以查看 ELECTRA 的改进效果:
-
ELECTRA 15% 辨别器只计算 15%的 token loss,其他与 ELECTRA 相同。
-
Replace MLM 训练 BERT 的 MLM,但用生成器产生的 token 而并非 [MASK] 去替换原有的 token 以解决 预训练阶段和微调阶段间因为 [MASK] token 产生的不同。
-
All-Tokens MLM 使用Replace MLM,但目标变为预测所有的 token。
从实验后的结果上来看, ELECTRA 15%远不如 ELECTRA,计算所有 token 的 loss 确实可以提升效果。因为 Replace MLM 表现比 BERT 稍好, 说明 [MASK] token 确实会对 BERT 的表现产生影响。All-Tokens MLM 的表 现略差于 ELECTRA。因此, 结果表明大部分 ELECTRA 的效果提升可以归功于从所有token 中学习, 另一小部 分可以归功于减缓了预训练和微调之间的不匹配。
GPT
GPT-1
同样是 2018 年, 在 BERT 风靡 NLP 领域的时候, OpenAI 公司同样发布了自己的模型 GPT (Generative Pre- Training ), 发表在论文《Improving Language Understanding by Generative Pre-Training》中, 这是一个典型的 生成式预训练模型。这篇文章的标题叫“使用通用的预训练来提升语言的理解能力”。OpenAI 并没有给自己的语言模型起名字,因此所谓的“GPT”的名字其实是后人给他起的。后来 OpenAI 不断改进模型的时候也采取了这个名字,推出了GPT-2、GPT-3乃至 ChatGPT和最新的 GPT-4。
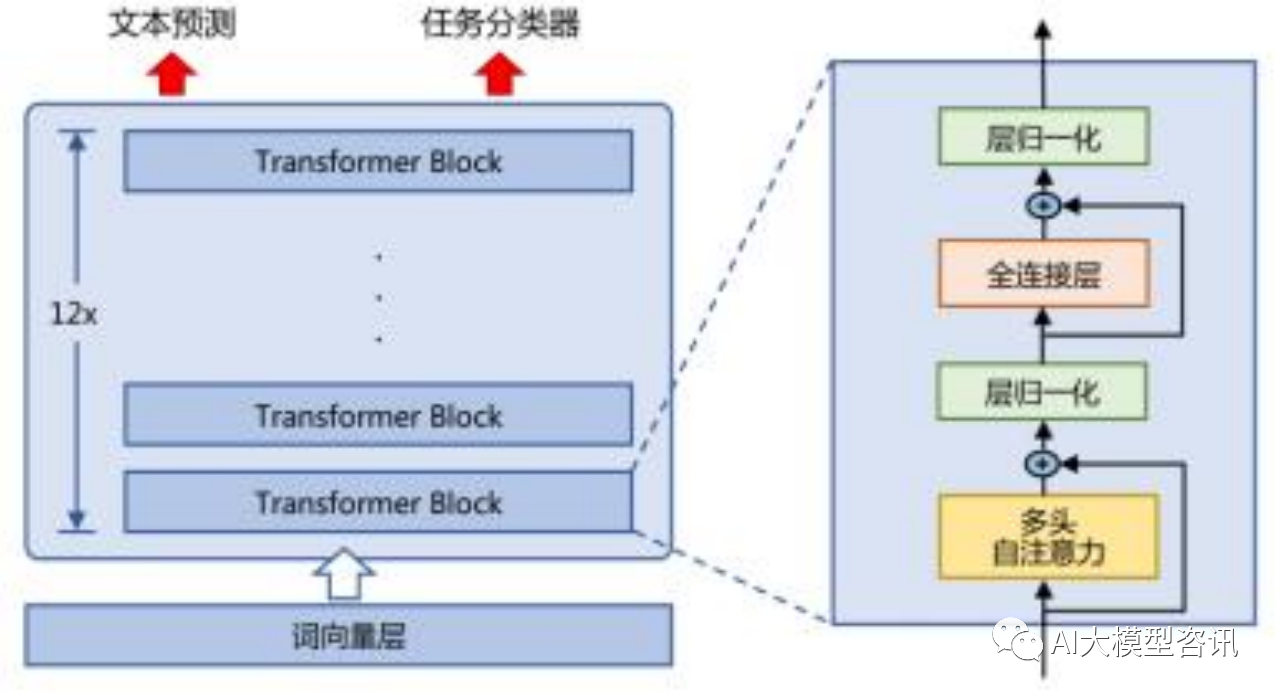
GPT 模型的架构和优调示例
GPT是最初开始使用非监督训练加监督微调的模型之一,也是首个只使用 transformer 里的 decoder 结构的模型。
无监督预训练
GPT 采用生成式预训练方法, 单向意味着模型只能从左到右或从右到左对文本序列建模, 所采用的 Trans- former 结构和解码策略保证了输入文本每个位置只能依赖过去时刻的信息。
在非监督预训练中, 单向语言模型 GPT 是按照阅读顺序输入文本序列 U ,用常规语言模型目标优化 U 的最 大似然估计,使之能根据输入历史序列对当前词能做出准确的预测:

其中 U = {u1 , ..., un } 为文本tokens ,k 为窗口大小, P 为条件概率, 其中 θ 代表模型参数。也可以基于马尔 可夫假设, 只使用部分过去词进行训练。预训练时通常使用随机梯度下降法进行反向传播优化该负似然函数。在 实验中, 模型是多层的 Transformer decoder 结构。模型对输入 U 进行特征嵌入得到 transformer 第一层的输入 h0 , 再经过多层 transformer 特征编码,最后得到目标tokens 的概率分布:

其中 U = (u−k , ..., u − 1 ) 是 token 的上下文向量, n 是层数, We 是词嵌入矩阵, Wp 是位置嵌入矩阵。
有监督下游任务微调
通过无监督语言模型预训练, 使得 GPT 模型具备了一定的通用语义表示能力。在训练好模型并进行微调时, 在有特定下游任务标签的情况下, 输入会经过预训练好的模型以得到最后一层 transformer 的最后一个 token 的特征 hl(m),然后被输入给一个拥有参数 Wy 的线性输出层来预测标签 y:
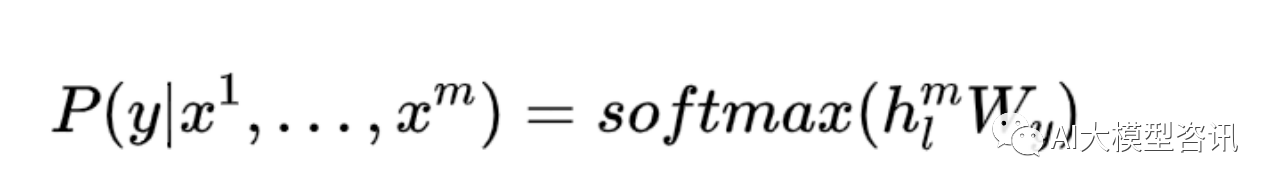
因此微调阶段的目标函数为最大化以下然估计:
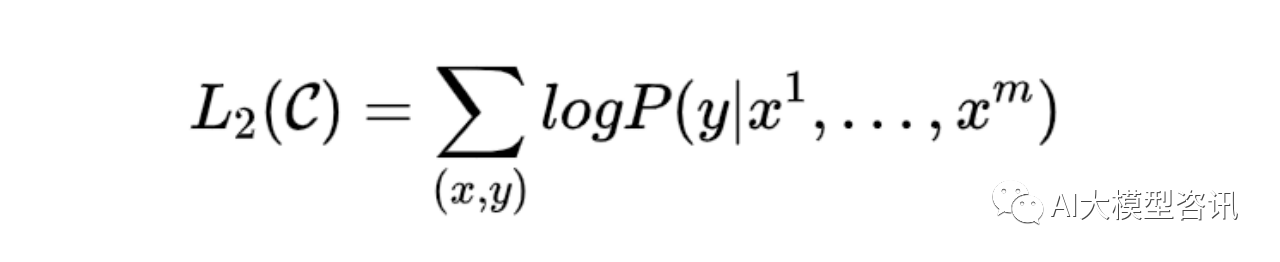
下游任务在微调过程中, 针对任务目标进行优化, 很容易使得模型遗忘预训练阶段所学习到的通用语义知 识表示, 从而损失模型的通用性和泛化能力, 造成灾难性遗忘 (Catastrophic Forgetting) 问题。因此, 通常会采用 混合预训练任务损失和下游微调损失的方法来缓解上述问题。在实际应用中, 通常采用如下公式进行下游任务 微调,最终的目标函数为:
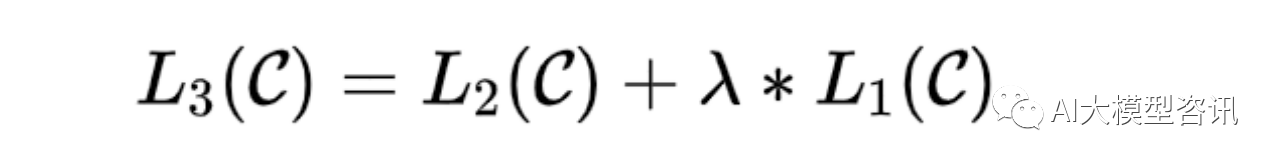
其中 λ 取值为 [0,1] ,用于调节预训练任务损失占比。
对于不同的下游任务, GPT 有不同的微调方式,如下图所示:
-
文本分类直接调整模型。
-
文本蕴含将前提 p 和假设 h 序列连接,并用($) 分隔。
-
文本相似度对于此任务, 两个序列没有内在顺序。为了反应这点, 修改输入序列以同时包含两种可能的句 子排序(中间使用分隔符),每个单独处理以产生两个序列表示 hl(m),并在输入给线性输出层时按元素对齐 相加。
-
问题回答以及常识推理对于这类任务, 会得到一个背景文档 z,一个问题 q,和一系列可能的答案 {ak }。将 文档上下文和问题与每个可能的答案连接起来, 在中间加一个分隔符以获得 [z; q; $; ak ]。每个序列都会被 单独处理并通过 soft
-
max 层归一化,产生可能答案的输出分布。
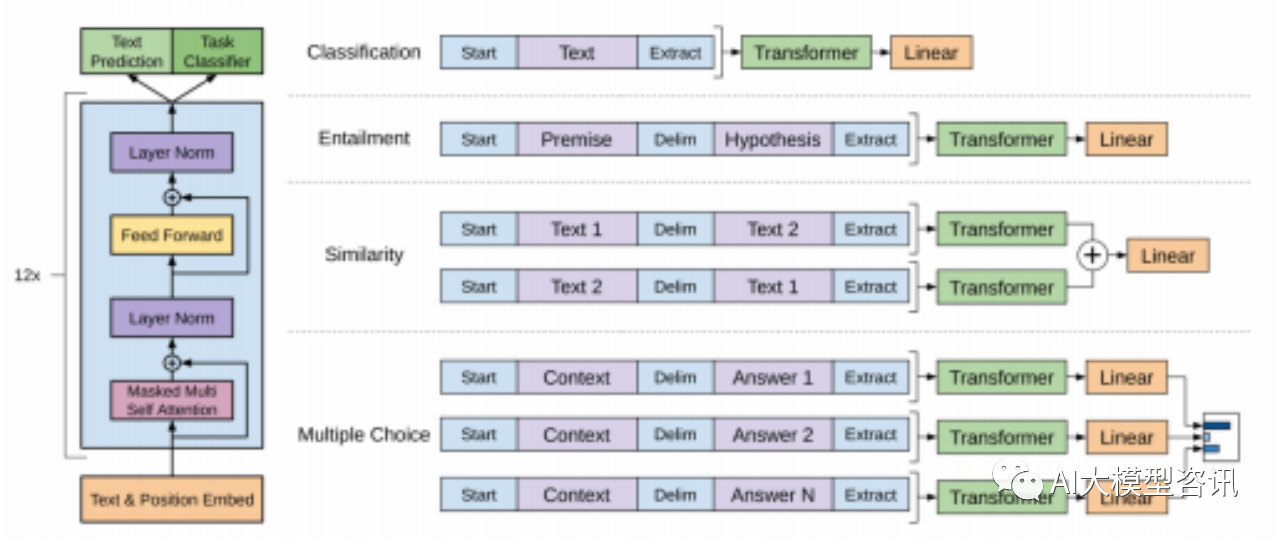
(左)模型结构和训练目标。(右)在不同任务微调时输入的变化
GPT 是最初在 NLP 领域中使用预训练加微调的模型之一, 并且其实验结果证明了模型的表现会随着解码器 的层数增加而增强, 改进了 12 个数据集中 9 个数据集的结果表现。与 BERT 类的语言模型不同, 因为其模型结 构是单向的, GPT 无法利用输入后面的信息,因此比起文本辨别类任务, GPT 更适合文本生成类任务。
GPT-2
2019 年 2 月, OpenAI 随后发布了 GPT-2,它也是基于 Transformer 架构的语言模型, 它不仅继承了初代 GPT 运用大规模无标注文本数据训练模型的能力,并且能通过 FineTune 优化模型表现,并将知识迁移到下游任 务。GPT-2 的目的为使用无监督的预训练模型来完成有监督的任务。该模型采用了 zero shot,即在进行下游任务 时不给予任何特定任务的数据,直接根据指令进行任务。
除此之外, GPT-2 还更侧重于 0-shot 设定下语言模型的能力。也就是说, 是指模型在下游任务中不进行任何 训练或微调,即模型不再根据下游任务的数据进行参数上的优化,而是根据给定的指令自行理解并完成任务。
虽然 GPT-2 在模型结构上与 GPT 基本相同, 但在几处细节上进行了改进:layer normalization 被移动到了子 块的输入, 并在最后的自注意块后加入一层 layer normalization; 在初始化时, 将 residual layer 的权重按 1/^N
的 比例缩放, N 为 residual layer 的层数;字典大小变为 50,257;滑动窗口大小从 512 变为 1024;以及 batchsize 变 为 512。为了保证模型训练后的效果, GPT-2 使用了从网络上大量爬取的文本组成的数据集 WebText。经过整理后, 该数据集拥有 800 万的文档, 约 40GB。其中维基百科文章都被删除, 因为测试集里大多含有维基百科的内容。从实验结果上来看, GPT-2 在 8 个数据集中的 7 个获得最先进的结果。GPT-2 证明了通过海量的数据和大量的参数训练出的语言模型可以执行 zero shot 并且在部分任务上表现不 错。但其无监督学习能力还有很大的提升空间。
GPT-3
GPT-3则采取了不同的训练策略。首先是测试了 GPT-3 的 in-context learning 能力,之后在下游任务 的评估与预测时使用了三种不同的方法:few-shot learning,one-shot learning,和 zero-shot learning2.20。In-context learning 指的是语言模型元学习中的内循环学习, 它发生在每个序列的前向传递中。该图例的序列并不代表模型 在预训练会看到的数据,而是为了显示有时在单个序列中嵌入了重复的子任务。
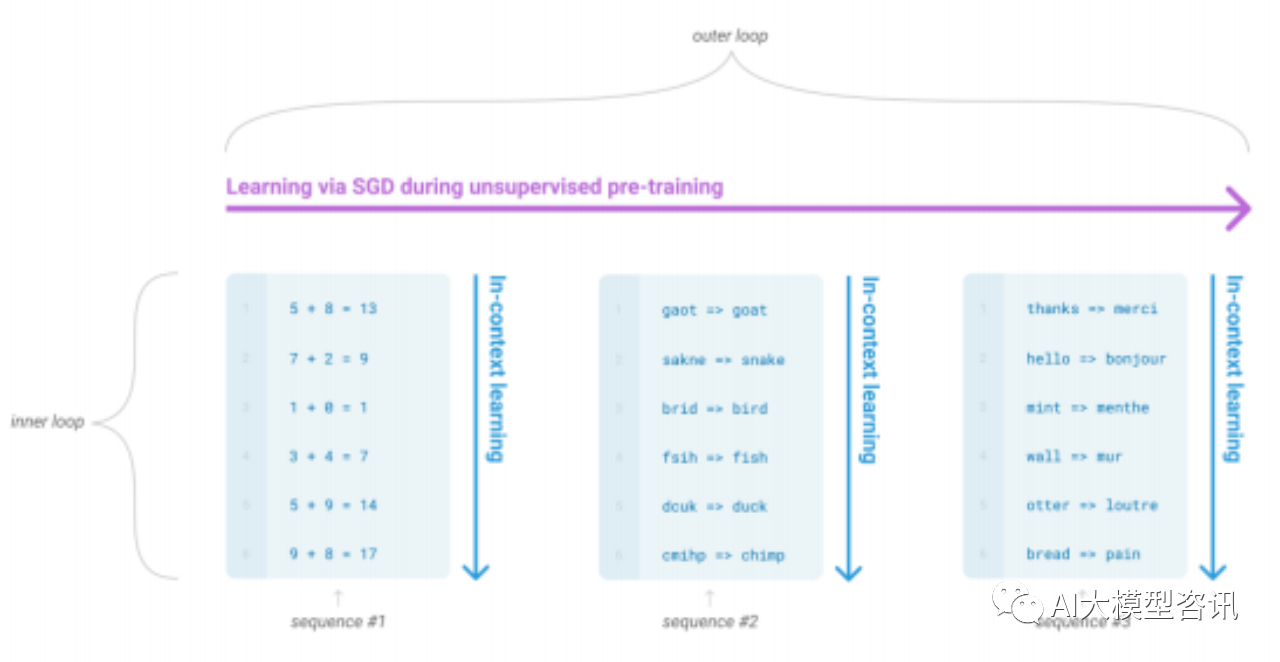
语言模型的语境学习
在 GPT-3 的下游任务中, zero-shot learning 指的是模型仅使用任务描述预测答案, 并不更新梯度。One-shot learning 指的是模型不仅有任务描述, 还能看见一个任务例子, 且梯度不更新。Few-shot learning 指的是模型不 仅有任务描述, 还能看见数个任务例子, 且梯度不更新。与这三种方法不同, 微调时会更新梯度, 且需要的数量 比 in-context learning 所需要的 10 到 100 的数据量要大得多。
GPT-3 的模型结构与 GPT-2 也无太大差异。主要改进为引入了 Sparse Transformer 的 sparse attention 模块。GPT-3 在训练中得到了使用了 8 种不同的规模模型, 其中最大的模型参数大小为 1750 亿。GPT-3 也采集了巨量 的数据集进行训练, 包括了 Common Crawl, WebText2, Books1, Books2 和 Wikipedia,且每个数据集都设置了不 同的比例权重。经实验可以得出, 随着模型参数量的增长, few-shot 的准确率比 one-shot 和 zero-shot 更高且上升 幅度更大。且当模型想要线性提升一个任务的效果时,模型的参数规模和数据量需要指数级的提升。
GPT-3 在各个 NLP 任务上都取得了优异的表现, 使 GPT 系列逐渐开始引起人们的关注, 并且为之后的著名 的 ChatGPT 和 GPT-4 打下了基础。然而 GPT-3 本身也展现出许多需要改进的地方:当生成文本长度过长时, 生 成内容会含有逻辑性以及连贯性等问题;使用 GPT-3 的成本太高;GPT-3 生成的内容可能会带有偏见且容易被 人恶意误导。这些问题都是以后 GPT 系列模型所关注的重点。

Zero-shot ,one-shot ,few-shot 和传统微调的对比
BART
BERT 通过选用掩码语言建模任务, 即掩盖住句子中一定比例的单词, 要求模型根据上下文预测被遮掩的单 词。这类模型在预训练中只利用 Encoder,因为在 Encoder 中能看到全部信息, 因此被称为编码预训练语言模型 (Encoder-only Pre-trained Models)。基于编码器的架构得益于双向编码的全局可见性, 在语言理解的相关任务上 性能卓越,但是因为无法进行可变长度的生成,不能应用于生成任务。
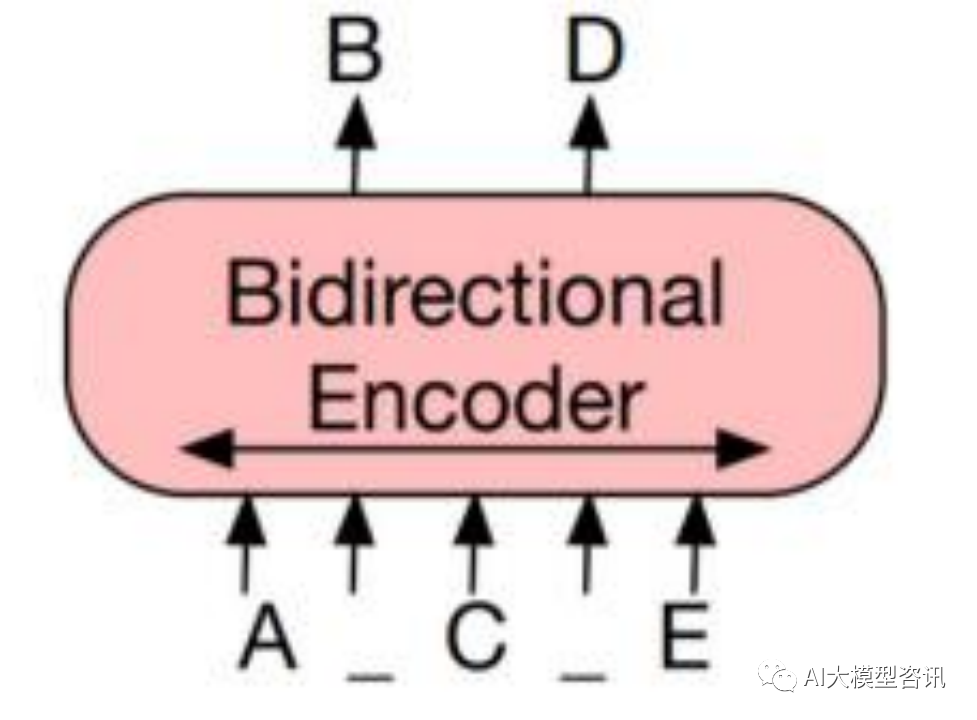
基于双向编码建模的 BERT 模型
GPT 所使用的方式是将 Decoder 中输入与输出之间差出一个位置, 主要目的是使模型能够通过上文预测下 文, 这种方式被称为 Autoregressive (自回归)。此类模型只利用 Decoder,主要用来做序列生成,被称为解码预 训练语言模型(Decoder-only Pre-trained Models)。基于解码器的架构采用单向自回归模式, 可以完成生成任务, 但是信息只能从左到右单向流动,模型只知“上文”而不知“下文”,缺乏双向交互。
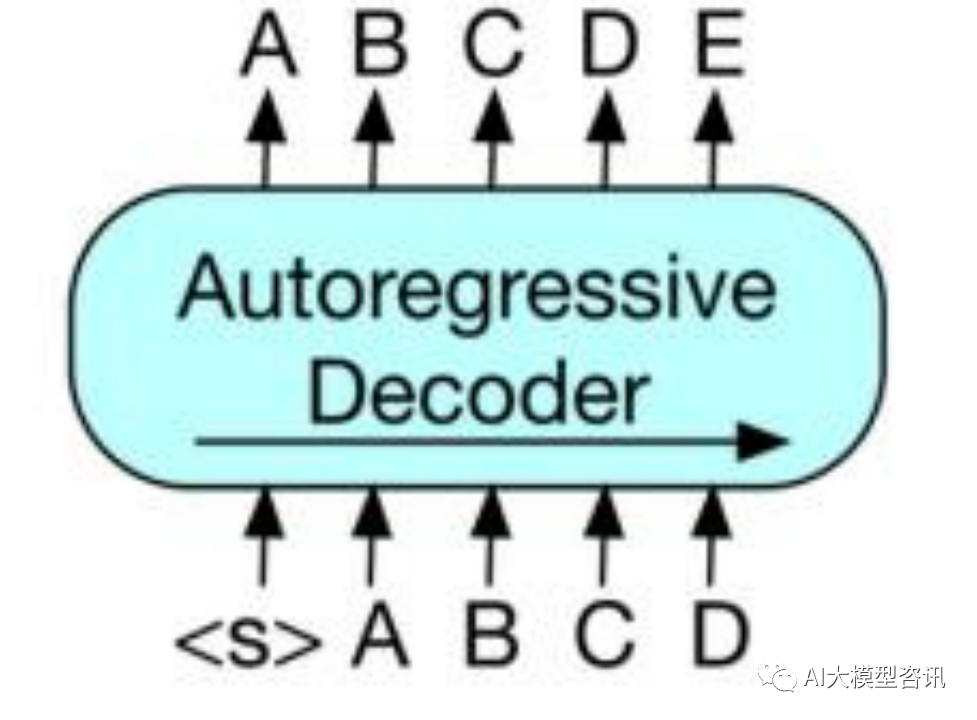
基于自回归方式建模的 GPT 模型
2019 年 10 月, Facebook 提出了 BART,发表在论文《BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension》中, 该模型是一种 Seq2Seq 模型。具体结构为一 个双向的编码器拼接一个单向的自回归解码器, 采用的预训练方式为输入含有各种噪声的文本, 再由模型进行去 噪重构。BART 使用的是标准的 Transformer 模型, 除了其将 ReLU 激活函数变成了 GeLUs 函数, 并从 N(0,0.02) 初始化参数。
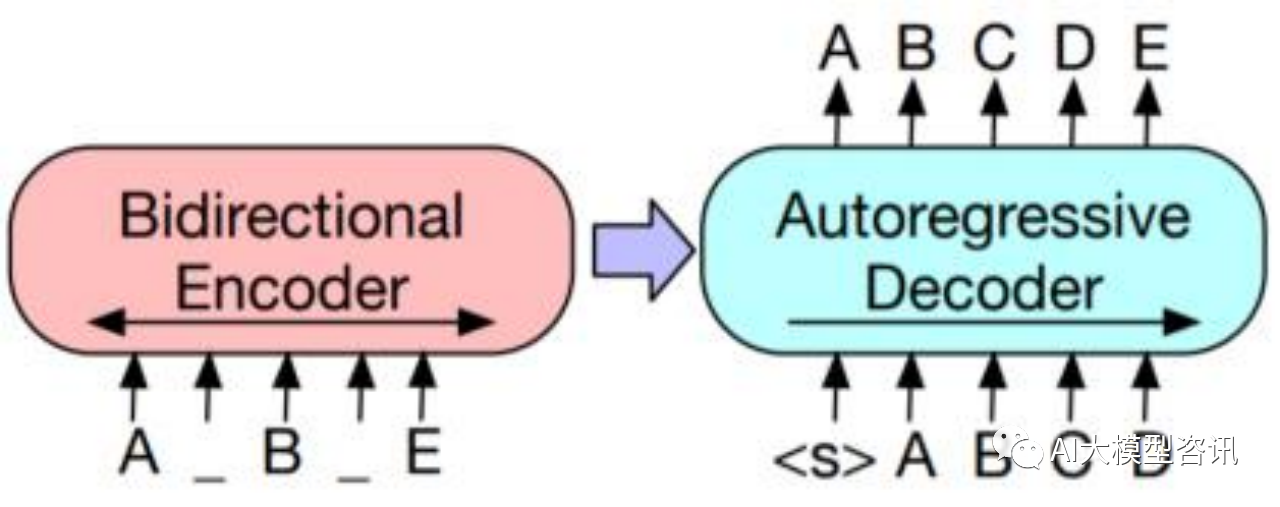
掩码和自回归方式结合建模的 BART 模型。被破坏的文件(左) 被编译进一个双向模型, 然后原文件的 似然(右) 由一个自回归解码器计算得出。在微调阶段, 一份未被损坏的文件被输入给编译器和解码器, 并使用 解码器最后隐藏层的表现。
BART 融合两种结构, 使用编码器提取出输入中有用的表示, 来辅助并约束解码器的生成, 因此这类模型被 称为基于编解码架构的预训练语言模型(Encoder-decoder Pre-trained Models )。
BART 有五种预训练任务来破坏并重建文本:
-
Token Masking 与 BERT 的 MLM 方法相同。
-
Token Deletion 随机从输入文本中删除 token 并判断其位置。
-
Text Infilling 随机挑一段连续文本 (span) ,span 的长度为 λ = 3 的泊松分布, 每个 span 被一个 [MASK] token 替换。目的是为了训练模型预测一个 span 里缺失了多少token。
-
Sentence Permutation 将文本中的句子顺序随机排序。
-
Document Rotation 随机从文本中选取一个 token,将此 token 作为文本的开头。目的是为了训练模型识别出文本开头的能力。
同时, BART 也有好几种在不同任务下的微调方式:
-
Sequence Classification Tasks 在序列分类任务中, 同样的输入会被喂给 encoder 和 decoder,并且最后的 decoder token 的最后一个隐藏节点会被输入给一个新的线性多分类器,其作用相当于 BERT 中的 [CLS]。
-
Token Classification Tasks 在 token 分类任务中, 文本会被输入给 encoder 和 decoder,并且 decoder 最后的 隐藏节点作为每个 token 的表达。这表达会被来给 token 分类。
-
Sequence Generation Tasks 在序列生成任务中, 因为 BART 有自回归的 decoder,所以可以直接对生成任 务进行微调。即将文本输入进 encoder 后, decoder 会自回归地生成输出文本。
-
Machine Translation 在机器翻译任务中, BART 将 encoder 的 embedding 层替换成一个新的随机初始化 encoder,该 encoder 可以使用不同的字典。在微调过程中, 先冻结 BART 大部分参数并只更新新的encoder, BART positional embedding,和 BART encoder 第一层的 self-attention 输入映射矩阵。接着只训练几轮所有 模型参数。
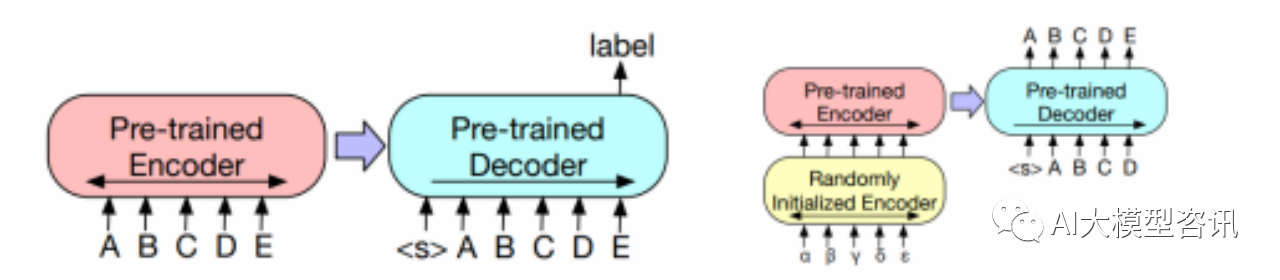
BART 的微调方式:(左)分类任务;(右)机器翻译任务
在实验阶段,作者对比了不同的预训练目标:
-
Language Model: GPT
-
Permuted Language Model: XLNet
-
Masked Language Model: BERT
-
Multitask Masked Language Model: UniLM
-
Masked Seq-to-Seq: MASS
并且涉及了不同的下游任务:SQuAD,MNLI,ELI5,XSum,ConvAI2和 CNN/DM。经过实验,作者得出了以下结论:
预训练方法的表现很大程度上取决于任务种类。
-
Token Masking 很重要。只做了 rotating documents 或 permuting sentences 的预训练模型效果较差, 其他的则 相反。其中,在生成任务中, deletion 的效果比 masking 好。
-
Left-to-right 的预训练提高了模型在生成任务的表现。Masked Language Model 和 Permuted Language Model 在生成任务上表现的比其他模型要差,而它们是仅有的不是left-to-right自回归语言模型。
-
双向的 encoder 对 SQuAD 很重要, 因为以后的文本背景对分类任务来说也很关键, 而 BART 仅用一般的 双向层数就达到了相似的表现。
-
预训练目标并不是唯一重要的因素。比如 Permuted Language Model 表现不如 XLNet 好, 这可能是因为 relative-position embeddings 或者 segment-level recurrence。
-
纯语言模型在 ELI5 上表现最好。说明当输入与输出联系不紧密时, BART 无法发挥很好的作用。
-
除了 ELI5,使用 text-infilling 的 BART 模型在所有任务上都表现优异。
T5
T5,全名为 Text-to-Text Transfer Transformer。该模型目的是让所有文本处理问题转变成“text-to-text”的 问题,即使用同样的模型去解决所有的 NLP 问题。
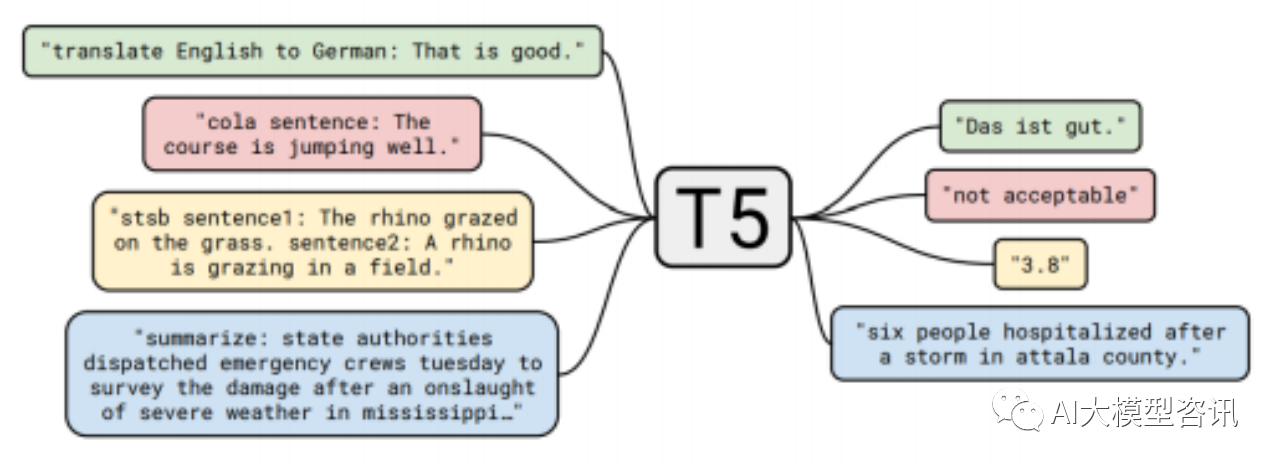
Text-to-Text 的结构
在比较了多个不同模型结构后, 包括标准的 encoder-decoder 结构, 单独的 decode 部分, 以及 prefix 语言模型, T5 的模型结构被决定是在原来的 transformer 的 encoder-decoder 结构上进行了些许修改, 包括:移除了bias 以简化 layer normalization,在 layer normalization 后, 一个 residual skip connection 将每个次要部分的输入和输出 连接在一起,并使用了一个不同的 position embedding。
T5 从 Common Crawl 上清理了大小约为 750GB 的纯英文文本数据, 称为 C4 (Colossal Clean Crawled Corpus)。清理数据的方式含有:
-
只保留结尾有正常符号的语句,例如句号。
-
舍弃少于 5 个句子的页面并只保留至少含有 3 个单词的句子。
-
移除了任何含有“List of Dirty, Naughty, Obscene or Otherwise Bad Words”里的词汇的页面。
-
移除含有 Javascript 单词的句子。
-
移除含有“lorem ipsum”的页面。
-
移除含有大括号的页面。当连续三句话出现重复时,只保留一句。
在经过多次多种方法的表现对比后,T5 的非监督目标为 BERT 式的预训练方式, 替换 span 式的破坏策 略(类似 BART 的 Text Infilling),15%的破坏比,以及 span 平均长度为 3。

非监督目标探索过程的流程图
为了突出预训练时使用的数据集对模型训练的重要性,作者也对比了 C4 和其他数据集,包括:
-
Unfiltered C4: 没有过滤过的 C4。
-
RealNews-like: C4 中关于新闻的部分。
-
WebText-like: Reddit 评分至少为 3 的数据。
-
Wikipedia:维基百科
-
Wikipedia + Toronto Books Corpus: Toronto Books Corpus 的数据主要来源为电子书
经过实验对比, C4 的表现结果比 Unfiltersed C4 强, 说明过滤数据的重要性。以及 Wikipedia + TBC 或 RealNews 在部分任务中表现比 C4 好, 说明预训练数据中包含一定的领域数据对该类下游任务的表现提升有效果。
另外, 当使用更少量的数据进行更多次重复以达到相同的预训练量时, 模型的表现结果也会下降, 这可能是因 为当数据量少时模型可能会记住数据导致 training loss 下降地更迅速但测试结果变差。此外, 作者测试了 T5 在 不同训练方法的混合下的表现效果。结果表明, 除了监督多任务预训练的效果较差外, 其余训练方式的效果与 原有方法的效果差不多。在给予了 4 倍算力的情况下, 作者对比了增大模型, 增大数据, 以及其他方式下增强模 型后的表现。结果表明, 无论增大模型尺寸还是增加训练时间都能提高表现, 且增大模型尺寸和增加训练时间 对提高表现的作用可以互补。最后, 从不同规模 T5 的最终表现结果数据可以看出, 不仅 T5- 11B 在许多任务上 表现都是最佳,而且模型效果明显可以随着参数量的增长进一步提升。
ps:欢迎扫码关注公众号^-^.