四、融汇贯通阶段
开始梳理⼀些⽐较完整,⽐较复杂的完整业务线。
8
、消息持久化设计
1
、
RocketMQ
的持久化⽂件结构
消息持久化也就是将内存中的消息写⼊到本地磁盘的过程。⽽磁盘
IO
操作通常是⼀个很耗性能,很慢的操作,所以,对消息持久化机制的设计,是⼀个MQ
产品提升性能的关键,甚⾄可以说是最为重要的核⼼也不为过。这部分我们就先来梳理RocketMQ
是如何在本地磁盘中保存消息的。
在进⼊源码之前,我们⾸先需要看⼀下
RocketMQ
在磁盘上存了哪些⽂件。
RocketMQ
消息直接采⽤磁盘⽂件保存消息,默认路径在${user_home}/store
⽬录。这些存储⽬录可以在
broker.conf
中⾃⾏指定。
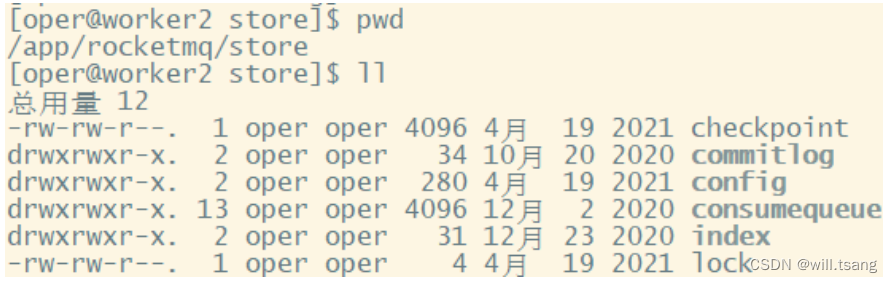
· 存储⽂件主要分为三个部分:
· CommitLog
:存储消息的元数据。所有消息都会顺序存⼊到
CommitLog
⽂件当中。
CommitLog
由多个⽂件组成,每个⽂件固定⼤⼩1G
。以第⼀条消息的偏移量为⽂件名。
· ConsumerQueue
:存储消息在
CommitLog
的索引。⼀个
MessageQueue
⼀个⽂件,记录当前
MessageQueue
被哪些消费者组消费到了哪⼀条
CommitLog
。
· IndexFile
:为了消息查询提供了⼀种通过
key
或时间区间来查询消息的⽅法,这种通过
IndexFile
来查找消息的⽅法不影响发送与消费消息的主流程
另外,还有⼏个辅助的存储⽂件,主要记录⼀些描述消息的元数据:
· checkpoint
:数据存盘检查点。⾥⾯主要记录
commitlog
⽂件、
ConsumeQueue
⽂件以及
IndexFile
⽂件最后⼀次刷盘的时间戳。
· config/*.json
:这些⽂件是将
RocketMQ
的⼀些关键配置信息进⾏存盘保存。例如
Topic
配置、消费者组配置、消费者组消息偏移量Offset
等等⼀些信息。
· abort
:这个⽂件是
RocketMQ
⽤来判断程序是否正常关闭的⼀个标识⽂件。正常情况下,会在启动时创建,⽽关闭服务时删除。但是如果遇到⼀些服务器宕机,或者kill -9
这样⼀些⾮正常关闭服务的情况,这个abort
⽂件就不会删除,因此
RocketMQ
就可以判断上⼀次服务是⾮正常关闭的,后续就会做⼀些数据恢复的操作。
整体的消息存储结构,官⽅做了个图进⾏描述:

简单来说,
Producer
发过来的所有消息,不管是属于那个
Topic
,
Broker
都统⼀存在
CommitLog
⽂件当中,然后分别构建ConsumeQueue
⽂件和
IndexFile
两个索引⽂件,⽤来辅助消费者进⾏消息检索。这种设计最直接的好处是可以较少查找⽬标⽂件的时间,让消息以最快的速度落盘。对⽐Kafka
存⽂件时,需要寻找消息所属的Partition⽂件,再完成写⼊。当
Topic
⽐较多时,这样的
Partition
寻址就会浪费⾮常多的时间。所以
Kafka
不太适合多Topic
的场景。⽽
RocketMQ
的这种快速落盘的⽅式,在多
Topic
的场景下,优势就⽐较明显了。
然后在⽂件形式上:
CommitLog
⽂件的⼤⼩是固定的。⽂件名就是当前
CommitLog
⽂件当中存储的第⼀条消息的
Offset
。
ConsumeQueue
⽂件主要是加速消费者进⾏消息索引。每个⽂件夹对应
RocketMQ
中的⼀个
MessageQueue
,⽂件夹下的⽂件记录了每个MessageQueue
中的消息在
CommitLog
⽂件当中的偏移量。这样,消费者通过ConsumeQueue⽂件,就可以快速找到
CommitLog
⽂件中感兴趣的消息记录。⽽消费者在
ConsumeQueue
⽂件中的消费进度,会保存在config/consumerOffset.json
⽂件当中。
IndexFile⽂件主要是辅助消费者进⾏消息索引。消费者进⾏消息消费时,通过
ConsumeQueue
⽂件就⾜够完成消息检索了,但是如果消费者指定时间戳进⾏消费,或者要按照MeessageId
或者
MessageKey
来检索⽂件,⽐如RocketMQ管理控制台的消息轨迹功能,
ConsumeQueue
⽂件就不够⽤了。
IndexFile
⽂件就是⽤来辅助这类消息检索的。他的⽂件名⽐较特殊,不是以消息偏移量命名,⽽是⽤的时间命名。但是其实,他也是⼀个固定⼤⼩的⽂件。
这是对
RocketMQ
存盘⽂件最基础的了解,但是只有这样的设计,是不⾜以⽀撑
RocketMQ
的三⾼性能的。
RocketMQ
如何保证
ConsumeQueue
、
IndexFile
两个索引⽂件与
CommitLog
中的消息对⻬?如何保证消息断
电不丢失?如何保证⽂件⾼效的写⼊磁盘?等等。如果你想要去抓住
RocketMQ
这些三⾼问题的核⼼设计,那么还
是需要到源码当中去深究。
以下⼏个部分⾮常重要,所以有必要单独拉出章节来详细讲解。
2
、
commitLog
写⼊
消息存储的⼊⼝在:
DefaultMessageStore.asyncPutMessage
⽅法

CommitLog
的
asyncPutMessage
⽅法中会给写⼊线程加锁,保证⼀次只会允许⼀个线程写⼊。写⼊消息的过程是串⾏的,⼀次只会允许⼀个线程写⼊。
最终进⼊
CommitLog
中的
DefaultAppendMessageCallback#doAppend
⽅法,这⾥就是
Broker
写⼊消息的实际⼊⼝。这个⽅法最终会把消息追加到MappedFile
映射的⼀块内存⾥,并没有直接写⼊磁盘。⽽是在随后调⽤ComitLog#submitFlushRequest⽅法,提交刷盘申请。刷盘完成之后,内存中的⽂件才真正写⼊到磁盘当中。
在提交刷盘申请之后,就会⽴即调⽤
CommitLog#submitReplicaRequest
⽅法,发起主从同步申请。
3
、⽂件同步刷盘与异步刷盘
⼊⼝:
CommitLog.submitFlushRequest
这⾥涉及到了对于同步刷盘与异步刷盘的不同处理机制。这⾥有很多极致提⾼性能的设计,对于我们理解和设计⾼并发应⽤场景有⾮常⼤的借鉴意义。
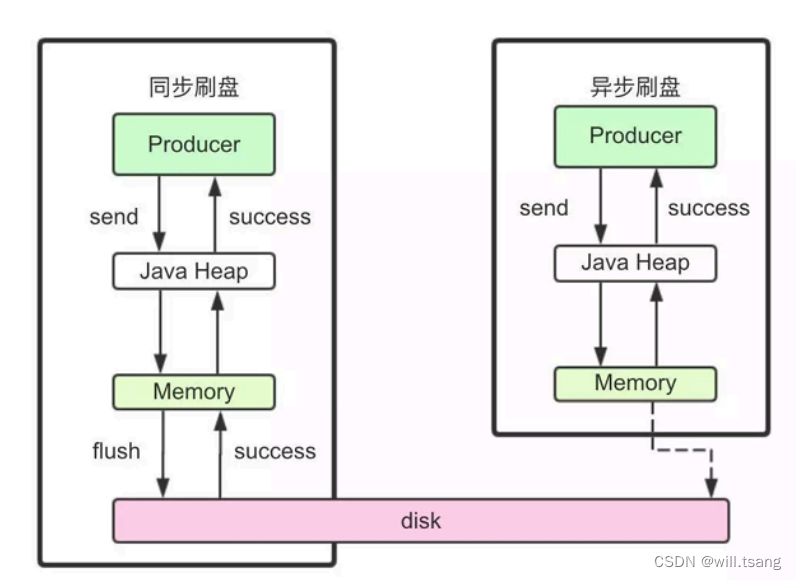
同步刷盘和异步刷盘是通过不同的
FlushCommitLogService
的⼦服务实现的。

同步刷盘采⽤的是
GroupCommitService
⼦线程。虽然是叫做同步刷盘,但是从源码中能看到,他实际上并不是来⼀条消息就刷⼀次盘。⽽是这个⼦线程每10
毫秒执⾏⼀次
doCommit
⽅法,扫描⽂件的缓存。只要缓存当中有消息,就执⾏⼀次Flush
操作。
⽽异步刷盘采⽤的是
FlushRealTimeService
⼦线程。这个⼦线程最终也是执⾏
Flush
操作,只不过他的执⾏时机会根据配置进⾏灵活调整。所以可以看到,这⾥异步刷盘和同步刷盘的最本质区别,实际上是进⾏Flush
操作的频率不同。

同步刷盘和异步刷盘最终落地到
FileChannel
的
force
⽅法。这个
force
⽅法就会最终调⽤⼀次操作系统的
fsync
系统调⽤,完成⽂件写⼊。关于force
操作的详细演示,可以参考后⾯的零拷⻉部分。

⽽另外⼀个
CommitRealTimeService
这个⼦线程则是⽤来写⼊堆外内存的。应⽤可以通过配置
TransientStorePoolEnable
参数开启对外内存,如果开启了堆外内存,会在启动时申请⼀个跟
CommitLog
⽂件⼤⼩⼀致的堆外内存,这部分内存就可以确保不会被交换到虚拟内存中。⽽CommitRealTimeService
处理消息的⽅式则只是调⽤mappedFileQueue
的
commit
⽅法。这个⽅法只是往操作系统的
PagedCache
⾥写⼊消息,并不主动进⾏刷盘操作。会由操作系统通过Dirty Page
机制,在某⼀个时刻进⾏统⼀刷盘。例如我们在正常关闭操作系统时,经常会等待很⻓时间。这⾥⾯⼤部分的时间其实就是在做PageCache
的刷盘。

然后,在梳理同步刷盘与异步刷盘的具体实现时,可以看到⼀个⼩点,
RocketMQ
是如何让两个刷盘服务间隔执⾏的?RocketMQ
提供了⼀个⾃⼰实现的
CountDownLatch2
⼯具类来提供线程阻塞功能,使⽤
CAS
驱动CountDownLatch2的
countDown
操作。每来⼀个消息就启动⼀次
CAS
,成功后,调⽤⼀次
countDown
。⽽
这个
CountDonwLatch2
在
Java.util.concurrent.CountDownLatch
的基础上,实现了
reset
功能,这样可以进⾏对
象重⽤
。如果你对
JUC
并发编程感兴趣,那么这也是⼀个不错的学习点。
到这⾥,我们只是把同步刷盘和异步刷盘的机制梳理清楚了。但是关于
force
操作跟刷盘有什么关系?如果你对底层IO
操作不是很理解,那么很容易产⽣困惑。没关系,保留你的疑问,下⼀部分我们会⼀起梳理。
4
、
CommigLog
主从复制
⼊⼝:
CommitLog.submitReplicaRequest
主从同步时,也体现到了
RocketMQ
对于性能的极致追求。最为明显的,
RocketMQ
整体是基于
Netty
实现的⽹络请求,⽽在主从复制这⼀块,却放弃了Netty
框架,转⽽使⽤更轻量级的
Java
的
NIO
来构建。
在主要的
HAService
中,会在启动过程中启动三个守护进程。

这其中与
Master
相关的是
acceptSocketService
和
groupTransferService
。其中
acceptSocketService
主要负责维护Master
与
Slave
之间的
TCP
连接。
groupTransferService
主要与主从同步复制有关。⽽
slave
相关的则是haClient。
⾄于其中关于主从的同步复制与异步复制的实现流程,还是⽐较复杂的,有兴趣的同学可以深⼊去研究⼀下。
5
、分发
ConsumeQueue
和
IndexFile
当
CommitLog
写⼊⼀条消息后,在
DefaultMessageStore
的
start
⽅法中,会启动⼀个后台线程
reputMessageService
。源码就定义在
DefaultMessageStore
中。这个后台线程每隔
1
毫秒就会去拉取
CommitLog中最新更新的⼀批消息。如果发现CommitLog
中有新的消息写⼊,就会触发⼀次
doDispatch
。

dispatchList
中包含两个关键的实现类
CommitLogDispatcherBuildConsumeQueue
和
CommitLogDispatcherBuildIndex
。源码就定义在
DefaultMessageStore
中。他们分别⽤来构建
ConsumeQueue索引和IndexFile
索引。

并且,如果服务异常宕机,会造成
CommitLog
和
ConsumeQueue
、
IndexFile
⽂件不⼀致,有消息写⼊CommitLog后,没有分发到索引⽂件,这样消息就丢失了。
DefaultMappedStore
的
load
⽅法提供了恢复索引⽂件的⽅法,⼊⼝在load
⽅法。
6
、过期⽂件删除机制
⼊⼝:
DefaultMessageStore.addScheduleTask ->DefaultMessageStore.this.cleanFilesPeriodically()
在这个⽅法中会启动两个线程,
cleanCommitLogService
⽤来删除过期的
CommitLog
⽂件,
cleanConsumeQueueService
⽤来删除过期的
ConsumeQueue
和
IndexFile
⽂件。
在删除
CommitLog
⽂件时,
Broker
会启动后台线程,每
60
秒,检查
CommitLog
、
ConsumeQueue
⽂件。然后对超过72
⼩时的数据进⾏删除。也就是说,默认情况下,
RocketMQ
只会保存
3
天内的数据。这个时间可以通过fileReservedTime来配置。
触发过期⽂件删除时,有两个检查的纬度,⼀个是,是否到了触发删除的时间,也就是
broker.conf
⾥配置的deleteWhen属性。另外还会检查磁盘利⽤率,达到阈值也会触发过期⽂件删除。这个阈值默认是
72%
,可以在broker.conf⽂件当中定制。但是最⼤值为
95
,最⼩值为
10
。
然后在删除
ConsumeQueue
和
IndexFile
⽂件时,会去检查
CommitLog
当前的最⼩
Offset
,然后在删除时进⾏对⻬。
需要注意的是,
RocketMQ
在删除过期
CommitLog
⽂件时,并不检查消息是否被消费过。
所以如果有消息⻓期没有被消费,是有可能直接被删除掉,造成消息丢失的。
RocketMQ
整个⽂件管理的核⼼⼊⼝在
DefaultMessageStore
的
start
⽅法中,整体流程总结如下:

7
、⽂件索引结构
了解了⼤部分的⽂件写⼊机制之后,最后我们来理解⼀下
RocketMQ
的索引构建⽅式。
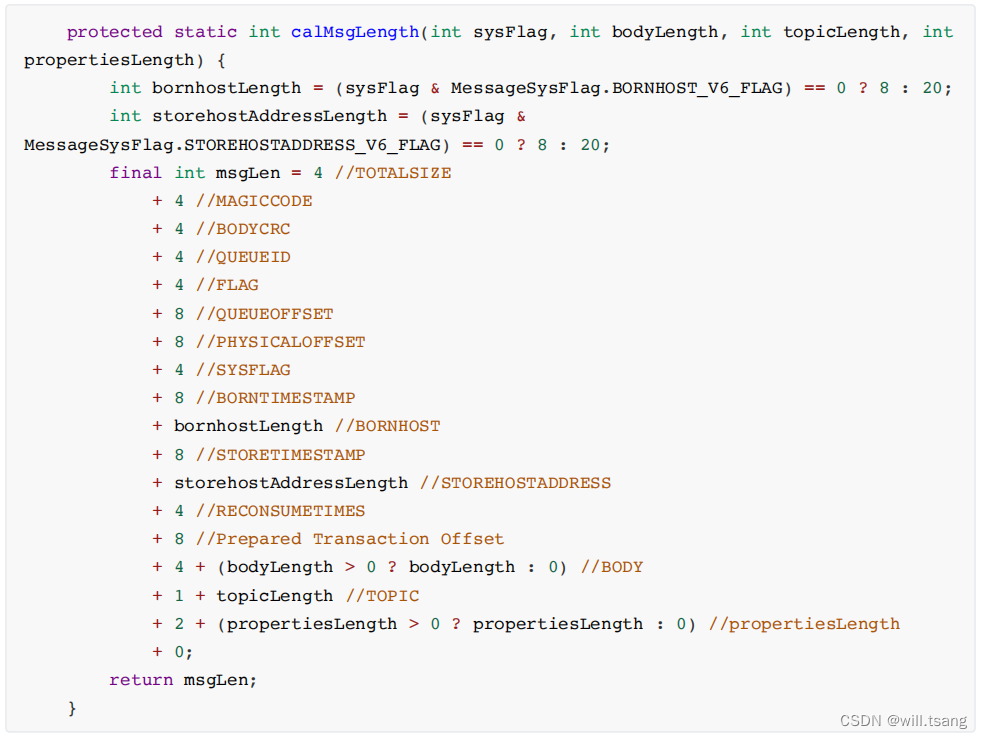
1
、
CommitLog
⽂件的⼤⼩是固定的,但是其中存储的每个消息单元⻓度是不固定的,具体格式可以参考org.apache.rocketmq.store.CommitLog中计算消息⻓度的⽅法
正因为消息的记录⼤⼩不固定,所以
RocketMQ
在每次存
CommitLog
⽂件时,都会去检查当前
CommitLog
⽂件空间是否⾜够,如果不够的话,就重新创建⼀个CommitLog
⽂件。⽂件名为当前消息的偏移量。
2
、
ConsumeQueue
⽂件主要是加速消费者的消息索引。他的每个⽂件夹对应
RocketMQ
中的⼀个
MessageQueue
,⽂件夹下的⽂件记录了每个
MessageQueue
中的消息在
CommitLog
⽂件当中的偏移量。这样,消费者通过ComsumeQueue
⽂件,就可以快速找到
CommitLog
⽂件中感兴趣的消息记录。⽽消费者在ConsumeQueue⽂件当中的消费进度,会保存在
config/consumerOffset.json
⽂件当中。
⽂件结构:
每个
ConsumeQueue
⽂件固定由
30
万个固定⼤⼩
20byte
的数据块组成,数据块的内容包括:msgPhyOffset(8byte,消息在⽂件中的起始位置
)+msgSize(4byte
,消息在⽂件中占⽤的⻓
度
)+msgTagCode(8byte
,消息的
tag
的
Hash
值
)
。
在
ConsumeQueue.java
当中有⼀个常量
CQ_STORE_UNIT_SIZE=20
,这个常量就表示⼀个数据块的⼤⼩。
例如,在
ConsumeQueue.java
当中构建⼀条
ConsumeQueue
索引的⽅法 中,就是这样记录⼀个单元块的数据的。

3
、
IndexFile
⽂件主要是辅助消息检索。他的作⽤主要是⽤来⽀持根据
key
和
timestamp
检索消息。他的⽂件名⽐较特殊,不是以消息偏移量命名,⽽是⽤的时间命名。但是其实,他也是⼀个固定⼤⼩的⽂件。
⽂件结构:
他的⽂件结构由
indexHeader(
固定
40byte)+ slot(
固定
500W
个,每个固定
20byte) + index(
最多500W*4个,每个固定
20byte)
三个部分组成。

然后,了解这些⽂件结构有什么⽤呢?下⾯的延迟消息机制就是⼀个例⼦。
9
、延迟消息机制
1
、关注重点
延迟消息是
RocketMQ
⾮常有特⾊的⼀个功能,其他
MQ
产品中,往往需要开发者使⽤⼀些特殊⽅法来变相实现延迟消息功能。⽽RocketMQ
直接在产品中实现了这个功能,开发者只需要设定⼀个属性就可以快速实现。
延迟消息的核⼼使⽤⽅法就是在
Message
中设定⼀个
MessageDelayLevel
参数,对应
18
个延迟级别。然后Broker中会创建⼀个默认的
Schedule_Topic
主题,这个主题下有
18
个队列,对应
18
个延迟级别。消息发过来之后,会先把消息存⼊Schedule_Topic
主题中对应的队列。然后等延迟时间到了,再转发到⽬标队列,推送给消费者进⾏消费。
2
、源码重点
延迟消息的处理⼊⼝在
scheduleMessageService
这个组件中。 他会在
broker
启动时也⼀起加载。
1
、消息写⼊到系统内置的
Topic
中
代码⻅
CommitLog.putMessage
⽅法。
在
CommitLog
写⼊消息时,会判断消息的延迟级别,然后修改
Message
的
Topic
和
Queue
,将消息转储到系统内部的Topic
中,这样消息就对消费者不可⻅了。⽽原始的⽬标信息,会作为消息的属性,保存到消息当中。

⼗⼋个队列对应了⼗⼋个延迟级别,这也说明了为什么这种机制下不⽀持⾃定义时间戳。
2
、消息转储到⽬标
Topic
接下来就是需要过⼀点时间,再将消息转回到
Producer
提交的
Topic
和
Queue
中,这样就可以正常往消费者推送了。
这个转储的核⼼服务是
scheduleMessageService
,他也是
Broker
启动过程中的⼀个功能组件。随
DefaultMessageStore
组件⼀起构建。这个服务只在
master
节点上启动,⽽在
slave
节点上会主动关闭这个服务。

由于
RocketMQ
的主从节点⽀持切换,所以就需要考虑这个服务的幂等性。在节点切换为
slave
时就要关闭服务,切换为master
时就要启动服务。并且,即便节点多次切换为
master
,服务也只启动⼀次。所以在ScheduleMessageService的
start
⽅法中,就通过⼀个
CAS
操作来保证服务的启动状态。

这个
CAS
操作还保证了在后⾯,同⼀时间只有⼀个
DeliverDelayedMessageTimerTask
执⾏。这种⽅式,给整个延迟消息服务提供了⼀个基础保证。
ScheduleMessageService
会每隔
1
秒钟执⾏⼀个
executeOnTimeup
任务,将消息从延迟队列中写⼊正常
Topic中。 代码⻅ScheduleMessageService
中的
DeliverDelayedMessageTimerTask.executeOnTimeup
⽅法。
在
executeOnTimeup
⽅法中,就会去扫描
SCHEDULE_TOPIC_XXXX
这个
Topic
下的所有
messageQueue
,然后扫描这些MessageQueue
对应的
ConsumeQueue
⽂件,找到没有处理过的消息,计算他们的延迟时间。如果延迟时间没有到,就等下⼀秒再重新扫描。如果延迟时间到了,就进⾏消息转储。将消息转回到原来的⽬标Topic
下。
整个延迟消息的实现⽅式是这样的:

⽽
ScheduleMessageService
中扫描延迟消息的主要逻辑是这样的:


你看。这段代码,如果你不懂
ConsumeQueue
⽂件的结构,⼤概率是看不懂他是在⼲什么的。但是如果清楚了ConsumeQueue⽂件的结构,就可以很清晰的感受到
RocketMQ
其实就是在
Broker
端,像⼀个普通消费者⼀样去进⾏消费,然后扩展出了延迟消息的整个扩展功能。⽽这,其实也是很多互联⽹⼤⼚对RocketMQ
进⾏⾃定义功能扩展的很好的参考。
当然,如果你有⼼深⼊分析下去的话,可以针对扫描的效率做更多的梳理以及总结。因为只要是延迟类任务,都需要不断进⾏扫描。但是如何提升扫描的效率其实是⼀个⾮常核⼼的问题。各种框架都有不同的设计思路,⽽RocketMQ其实就是给出了⼀个很⾼效的参考。
例如下⾯的⻓轮询机制,就是在普通消息流转过程中加⼊⼀些⼩逻辑,扩展出来的⼀种很好的优化机制。在花联⽹⼤⼚中,会有很多类似这样的⾃定义优化机制。⽐如对于延迟消息,只⽀持⼗⼋个固定的延迟级别,但是在很多互联⽹⼤⼚,其实早在官⽅提出5.0
版本之前,就已经定制形成了⽀持任意延迟时间的扩展功能。
10
、⻓轮询机制
1
、功能回顾
RocketMQ
对消息消费者提供了
Push
推模式和
Pull
拉模式两种消费模式。但是这两种消费模式的本质其实都是Pull拉模式,
Push
模式可以认为是⼀种定时的
Pull
机制。但是这时有⼀个问题,当使⽤
Push
模式时,如果RocketMQ中没有对应的数据,那难道⼀直进⾏空轮询吗?如果是这样的话,那显然会极⼤的浪费⽹络带宽以及服务器的性能,并且,当有新的消息进来时,RocketMQ
也没有办法尽快通知客户端,⽽只能等客户端下⼀次来拉取消息了。针对这个问题,RocketMQ
实现了⼀种⻓轮询机制
long polling
。
⻓轮询机制简单来说,就是当
Broker
接收到
Consumer
的
Pull
请求时,判断如果没有对应的消息,不⽤直接给Consumer响应
(
给响应也是个空的,没意义
)
,⽽是就将这个
Pull
请求给缓存起来。当
Producer
发送消息过来时,增加⼀个步骤去检查是否有对应的已缓存的Pull
请求,如果有,就及时将请求从缓存中拉取出来,并将消息通知给Consumer。
2
、源码重点
Consumer
请求缓存,代码⼊⼝
PullMessageProcessor#processRequest
⽅法
PullRequestHoldService
服务会随着
BrokerController
⼀起启动。
⽣产者线:从
DefaultMessageStore.doReput
进⼊
整个流程以及源码重点如下图所示:

五、关于零拷⻉与顺序写
1
、刷盘机制保证消息不丢失
在操作系统层⾯,当应⽤程序写⼊⼀个⽂件时,⽂件内容并不会直接写⼊到硬件当中,⽽是会先写⼊到操作系统中的⼀个缓存PageCache
中。
PageCache
缓存以
4K
⼤⼩为单位,缓存⽂件的具体内容。这些写⼊到
PageCache中的⽂件,在应⽤程序看来,是已经完全落盘保存好了的,可以正常修改、复制等等。但是,本质上,PageCache依然是内存状态,所以⼀断电就会丢失。因此,需要将内存状态的数据写⼊到磁盘当中,这样数据才能真正完成持久化,断电也不会丢失。这个过程就称为刷盘。

PageCache
是源源不断产⽣的,⽽
Linux
操作系统显然不可能时时刻刻往硬盘写⽂件。所以,操作系统只会在某些特定的时刻将PageCache
写⼊到磁盘。例如当我们正常关机时,就会完成
PageCache
刷盘。另外,在
Linux
中,对于有数据修改的PageCache
,会标记为
Dirty(
脏⻚
)
状态。当
Dirty Page
的⽐例达到⼀定的阈值时,就会触发⼀次刷盘操作。例如在Linux
操作系统中,可以通过
/proc/meminfo
⽂件查看到
Page Cache
的状态。

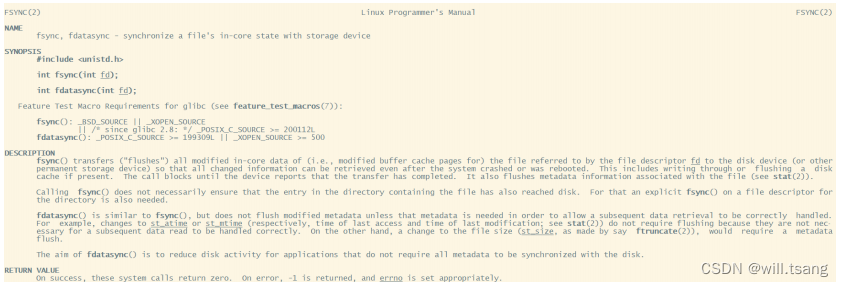
但是,只要操作系统的刷盘操作不是时时刻刻执⾏的,那么对于⽤户态的应⽤程序来说,那就避免不了⾮正常宕机时的数据丢失问题。因此,操作系统也提供了⼀个系统调⽤,应⽤程序可以⾃⾏调⽤这个系统调⽤,完成PageCache的强制刷盘。在
Linux
中是
fsync
,同样我们可以⽤
man 2 fsync
指令查看。
RocketMQ
对于何时进⾏刷盘,也设计了两种刷盘机制,同步刷盘和异步刷盘。只需要在
broker.conf
中进⾏配置就⾏。
RocketMQ
到底是怎么实现同步刷盘和异步刷盘的,还记得吗?
2
、零拷⻉加速⽂件读写
零拷⻉
(zero-copy)
是操作系统层⾯提供的⼀种加速⽂件读写的操作机制,⾮常多的开源软件都在⼤量使⽤零拷⻉,来提升IO
操作的性能。对于
Java
应⽤层,对应着
mmap
和
sendFile
两种⽅式。接下来,咱们深⼊操作系统来详细理解⼀下零拷⻉。
1
:理解
CPU
拷⻉和
DMA
拷⻉
我们知道,操作系统对于内存空间,是分为⽤户态和内核态的。⽤户态的应⽤程序⽆法直接操作硬件,需要通过内核空间进⾏操作转换,才能真正操作硬件。这其实是为了保护操作系统的安全。正因为如此,应⽤程序需要与⽹卡、磁盘等硬件进⾏数据交互时,就需要在⽤户态和内核态之间来回的复制数据。⽽这些操作,原本都是需要由CPU来进⾏任务的分配、调度等管理步骤的,早先这些
IO
接⼝都是由
CPU
独⽴负责,所以当发⽣⼤规模的数据读写操作时,CPU
的占⽤率会⾮常⾼。
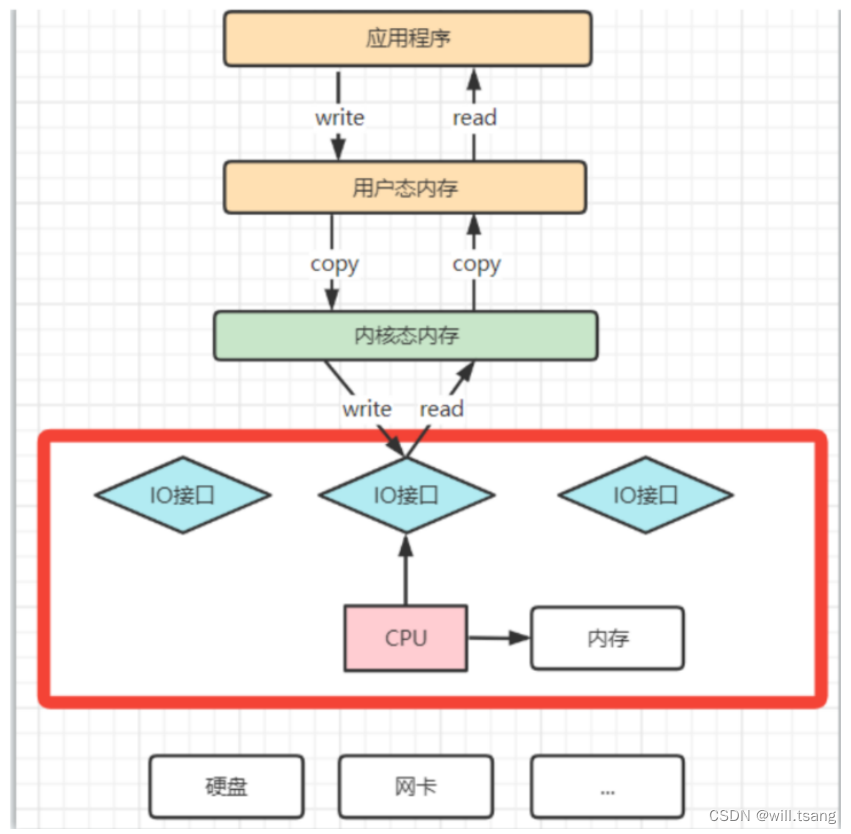
之后,操作系统为了避免
CPU
完全被各种
IO
调⽤给占⽤,引⼊了
DMA(
直接存储器存储
)
。由
DMA
来负责这些频繁的IO操作。
DMA
是⼀套独⽴的指令集,不会占⽤
CPU
的计算资源。这样,
CPU
就不需要参与具体的数据复制的⼯作,只需要管理DMA
的权限即可。

DMA
拷⻉极⼤的释放了
CPU
的性能,因此他的拷⻉速度会⽐
CPU
拷⻉要快很多。但是,其实
DMA
拷⻉本身,也在不断优化。
引⼊
DMA
拷⻉之后,在读写请求的过程中,
CPU
不再需要参与具体的⼯作,
DMA
可以独⽴完成数据在系统内部的复制。但是,数据复制过程中,依然需要借助数据总进线。当系统内的IO
操作过多时,还是会占⽤过多的数据总线,造成总线冲突,最终还是会影响数据读写性能。
为了避免
DMA
总线冲突对性能的影响,后来⼜引⼊了
Channel
通道的⽅式。
Channel
,是⼀个完全独⽴的处理器,专⻔负责IO
操作。既然是处理器,
Channel
就有⾃⼰的
IO
指令,与
CPU
⽆关,他也更适合⼤型的
IO
操作,性能更⾼。
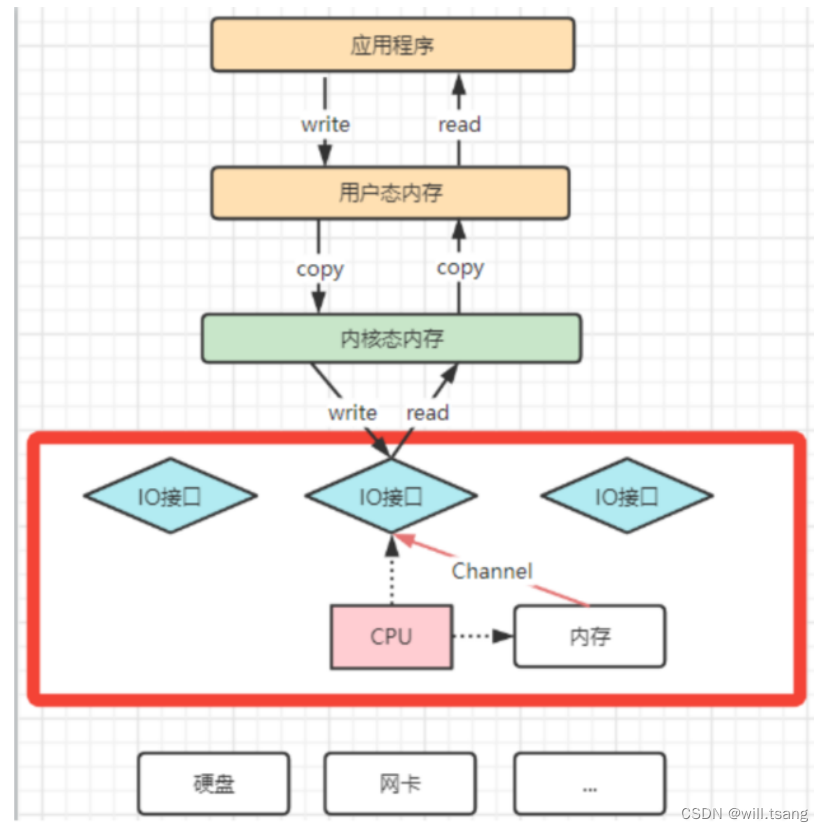
这也解释了,为什么
Java
应⽤层与零拷⻉相关的操作都是通过
Channel
的⼦类实现的。这其实是借鉴了操作系统中的概念。
⽽所谓的零拷⻉技术,其实并不是不拷⻉,⽽是要尽量减少
CPU
拷⻉。
2
:再来理解下
mmap
⽂件映射机制是怎么回事。
mmap
机制的具体实现参⻅配套示例代码。主要是通过
java.nio.channels.FileChannel
的
map
⽅法完成映射。
以⼀次⽂件的读写操作为例,应⽤程序对磁盘⽂件的读与写,都需要经过内核态与⽤户态之间的状态切换,每次状态切换的过程中,就需要有⼤量的数据复制。
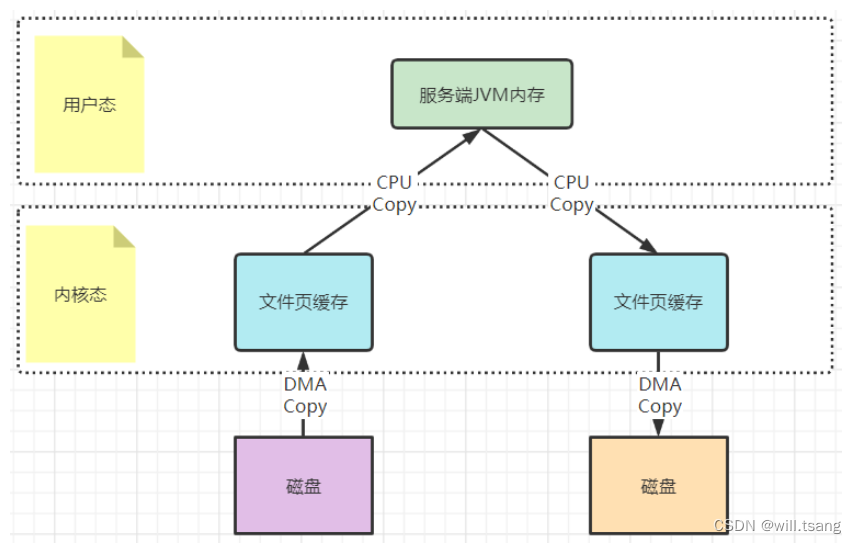
在这个过程中,总共需要进⾏四次数据拷⻉。⽽磁盘与内核态之间的数据拷⻉,在操作系统层⾯已经由
CPU
拷⻉优化成了DMA
拷⻉。⽽内核态与⽤户态之间的拷⻉依然是
CPU
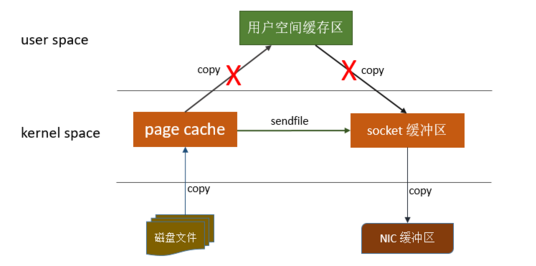
拷⻉。所以,在这个场景下,零拷⻉技术优化的重点,就是内核态与⽤户态之间的这两次拷⻉。
⽽
mmap
⽂件映射的⽅式,就是在⽤户态不再保存⽂件的内容,⽽只保存⽂件的映射,包括⽂件的内存起始地址,⽂件⼤⼩等。真实的数据,也不需要在⽤户态留存,可以直接通过操作映射,在内核态完成数据复制。
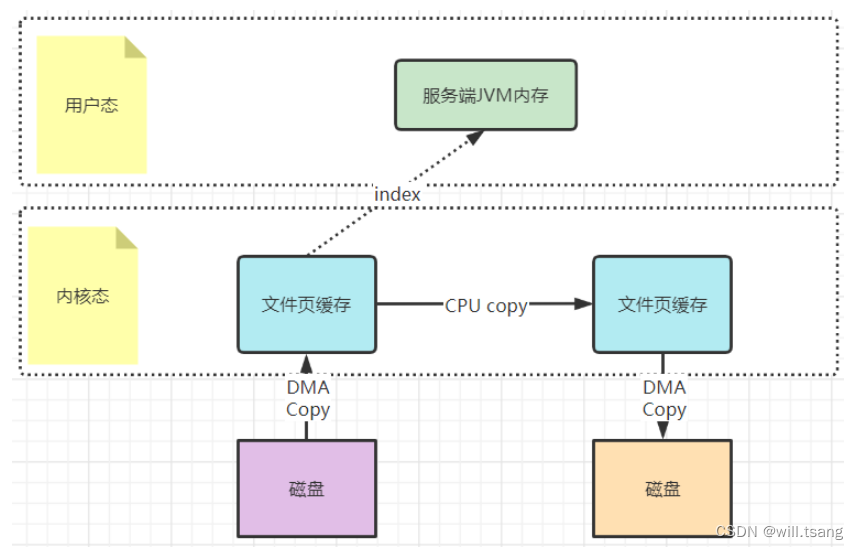
这个拷⻉过程都是在操作系统的系统调⽤层⾯完成的,在
Java
应⽤层,其实是⽆法直接观测到的,但是我们可以去JDK
源码当中进⾏间接验证。在
JDK
的
NIO
包中,
java.nio.HeapByteBuffer
映射的就是
JVM
的⼀块堆内内存,在HeapByteBuffer中,会由⼀个
byte
数组来缓存数据内容,所有的读写操作也是先操作这个
byte
数组。这其实就是没有使⽤零拷⻉的普通⽂件读写机制。

⽽
NIO
把包中的另⼀个实现类
java.nio.DirectByteBuffer
则映射的是⼀块堆外内存。在
DirectByteBuffer
中,并没有⼀个数据结构来保存数据内容,只保存了⼀个内存地址。所有对数据的读写操作,都通过unsafe
魔法类直接交由内核完成,这其实就是mmap
的读写机制。
mmap
⽂件映射机制,其实并不神秘,我们启动任何⼀个
Java
程序时,其实都⼤量⽤到了
mmap
⽂件映射。例如,我们可以在Linux
机器上,运⾏⼀下下⾯这个最简单不过的应⽤程序:

通过
Java
指令运⾏起来后,可以⽤
jps
查看到运⾏的进程
ID
。然后,就可以使⽤
lsof -p {PID}
的⽅式查看⽂件的映射情况。

这⾥⾯看到的
mem
类型的
FD
其实就是⽂件映射。

最后,这种
mmap
的映射机制由于还是需要⽤户态保存⽂件的映射信息,数据复制的过程也需要⽤户态的参与,这其中的变数还是⾮常多的。所以,mmap
机制适合操作⼩⽂件
,如果⽂件太⼤,映射信息也会过⼤,容易造成很多问题。通常mmap
机制建议的映射⽂件⼤⼩不要超过
2G
。⽽
RocketMQ
做⼤的
CommitLog
⽂件保持在
1G
固定⼤⼩,也是为了⽅便⽂件映射。
3
:梳理下
sendFile
机制是怎么运⾏的。
sendFile
机制的具体实现参⻅配套示例代码。主要是通过
java.nio.channels.FileChannel
的
transferTo
⽅法完成。

还记得
Kafka
当中是如何使⽤零拷⻉的吗?你应该看到过这样的例⼦,就是
Kafka
将⽂件从磁盘复制到⽹卡时,就⼤量的使⽤了零拷⻉。百度去搜索⼀下零拷⻉,铺天盖地的也都是拿这个场景在举例。

早期的
sendfile
实现机制其实还是依靠
CPU
进⾏⻚缓存与
socket
缓存区之间的数据拷⻉。但是,在后期的不断改进过程中,sendfile
优化了实现机制,在拷⻉过程中,并不直接拷⻉⽂件的内容,⽽是只拷⻉⼀个带有⽂件位置和⻓度等信息的⽂件描述符FD
,这样就⼤⼤减少了需要传递的数据。⽽真实的数据内容,会交由
DMA
控制器,从⻚缓存中打包异步发送到socket
中。

为什么⼤家都喜欢⽤这个场景来举例呢?其实我们去看下
Linux
操作系统的
man
帮助⼿册就能看到⼀部分答案。使⽤指令man 2 sendfile
就能看到
Linux
操作系统对于
sendfile
这个系统调⽤的⼿册。
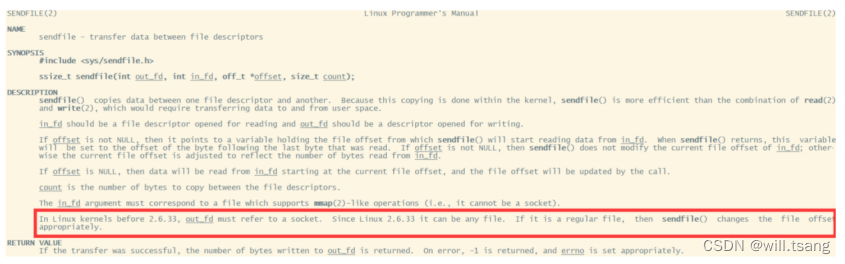
2.6.33
版本以前的
Linux
内核中,
out_fd
只能是⼀个
socket
,所以⽹上铺天盖地的⽼资料都是拿⽹卡来举例。但是现在版本已经没有了这个限制。
最后,
sendfile
机制在内核态直接完成了数据的复制,不需要⽤户态的参与,所以这种机制的传输效率是⾮常稳定的。sendfile
机制⾮常适合⼤数据的复制转移。
3
、顺序写加速⽂件写⼊磁盘
通常应⽤程序往磁盘写⽂件时,由于磁盘空间不是连续的,会有很多碎⽚。所以我们去写⼀个⽂件时,也就⽆法把⼀个⽂件写在⼀块连续的磁盘空间中,⽽需要在磁盘多个扇区之间进⾏⼤量的随机写。这个过程中有⼤量的寻址操作,会严重影响写数据的性能。⽽顺序写机制是在磁盘中提前申请⼀块连续的磁盘空间,每次写数据时,就可以避免这些寻址操作,直接在之前写⼊的地址后⾯接着写就⾏。
Kafka
官⽅详细分析过顺序写的性能提升问题。
Kafka
官⽅曾说明,顺序写的性能基本能够达到内存级别。⽽如果配备固态硬盘,顺序写的性能甚⾄有可能超过写内存。⽽RocketMQ
很⼤程度上借鉴了
Kafka
的这种思想。
例如可以看下
org.apache.rocketmq.store.CommitLog#DefaultAppendMessageCallback
中的
doAppend
⽅法。在这个⽅法中,会以追加的⽅式将消息先写⼊到⼀个堆外内存byteBuffer
中,然后再通过
fileChannel
写⼊到磁盘。