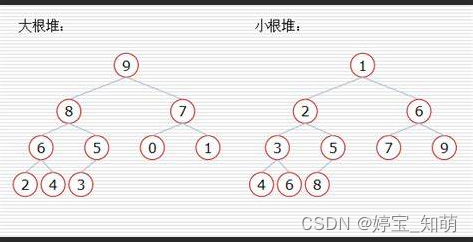
AI视野·今日CS.NLP 自然语言处理论文速览
Wed, 20 Sep 2023
Totally 64 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
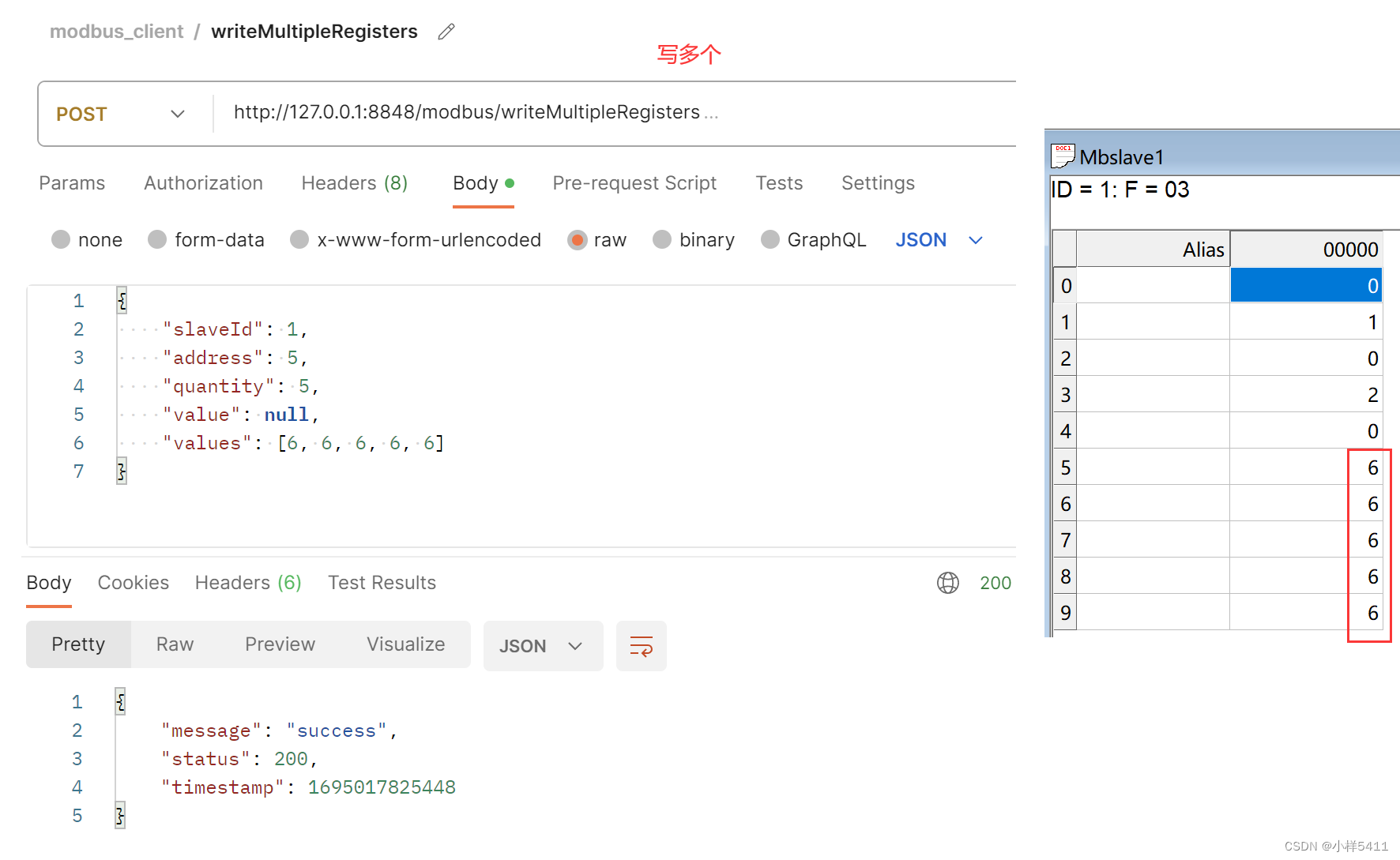
| SlimPajama-DC: Understanding Data Combinations for LLM Training Authors Zhiqiang Shen, Tianhua Tao, Liqun Ma, Willie Neiswanger, Joel Hestness, Natalia Vassilieva, Daria Soboleva, Eric Xing 本文旨在了解各种数据组合的影响,例如网络文本、维基百科、github、有关使用 SlimPajama 训练大型语言模型的书籍。 SlimPajama 是一个经过严格去重的多源数据集,该数据集已从 Together 贡献的广泛的 1.2T 令牌 RedPajama 数据集精炼并进一步去重至 627B 令牌。我们将我们的研究称为 SlimPajama DC,这是一项实证分析,旨在揭示与在大型语言模型训练中使用 SlimPajama 相关的基本特征和最佳实践。在我们对 SlimPajama 进行研究期间,出现了两个关键的观察结果:1 全局重复数据删除与本地重复数据删除。我们分析并讨论不同数据集来源的全局性和单一数据集来源的局部性重复数据删除如何影响训练模型的性能。 2 组合中高质量、高度去重的多源数据集的比例。为了研究这一点,我们构建了 SlimPajama 数据集的六种配置,并使用具有 Alibi 和 SwiGLU 的 1.3B Cerebras GPT 模型来训练各个配置。我们的最佳配置明显优于使用相同数量的训练令牌在 RedPajama 上训练的 1.3B 模型。我们所有的 1.3B 模型均在 Cerebras 16 倍 CS 2 集群上进行训练,bf16 混合精度下总共 80 PFLOP。我们进一步扩展了我们的发现,例如在大批量训练的 7B 模型上进行全局重复数据删除后,增加数据多样性至关重要。 |
| Natural Language Embedded Programs for Hybrid Language Symbolic Reasoning Authors Tianhua Zhang, Jiaxin Ge, Hongyin Luo, Yung Sung Chuang, Mingye Gao, Yuan Gong, Xixin Wu, Yoon Kim, Helen Meng, James Glass 我们如何对自然语言表示进行计算来解决需要符号和数字推理的任务我们提出自然语言嵌入式程序 NLEP 作为解决数学符号推理、自然语言理解和指令跟踪任务的统一框架。我们的方法促使语言模型生成完整的 Python 程序,这些程序定义数据结构上的函数,其中包含结构化知识的自然语言表示。然后,Python 解释器执行生成的代码并打印输出。尽管使用任务一般提示,我们发现这种方法可以在一系列不同任务的强大基线上进行改进,包括数学和符号推理、文本分类、问题回答和指令遵循。 |
| FRASIMED: a Clinical French Annotated Resource Produced through Crosslingual BERT-Based Annotation Projection Authors Jamil Zaghir, Mina Bjelogrlic, Jean Philippe Goldman, Souka na Aananou, Christophe Gaudet Blavignac, Christian Lovis 自然语言处理 NLP 应用程序(例如针对低资源语料库的命名实体识别 NER)无法从大型语言模型 LLM 开发的最新进展中受益,而大型语言模型 LLM 仍然需要更大的注释数据集。本文介绍了一种通过跨语言注释投影生成注释数据集翻译版本的方法。利用与语言无关的 BERT 方法,它是一种有效的解决方案,只需很少的人力,并且仅使用现有的开放数据资源即可增加低资源语料库。在评估半自动数据生成策略的质量和有效性时,通常缺乏定量和定性评估。我们的跨语言注释投影方法的评估显示了所得数据集的有效性和高精度。作为该方法的实际应用,我们介绍了用于医疗实体检测的带有语义信息的法语注释资源 FRASIMED 的创建,这是一个包含 2051 个法语合成临床案例的注释语料库。 |
| Evaluating large language models' ability to understand metaphor and sarcasm using a screening test for Asperger syndrome Authors Hiromu Yakura 隐喻和讽刺是我们高度发展的社交沟通技巧的宝贵成果。然而,众所周知,患有阿斯伯格综合症的儿童在理解讽刺方面有困难,即使他们拥有一定水平的语言智商足以理解隐喻。鉴于此,一项对理解隐喻和讽刺的能力进行评分的筛选测试已被用来区分阿斯伯格综合症和表现出类似外部行为的其他症状,例如注意力缺陷多动障碍。本研究使用标准化测试来检验最近的大型语言模型法学硕士在理解人类细微差别沟通方面的能力。结果表明,虽然他们理解隐喻的能力随着模型参数数量的增加而提高,但讽刺理解的能力却没有提高。 |
| OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch Authors Juntao Li, Zecheng Tang, Yuyang Ding, Pinzheng Wang, Pei Guo, Wangjie You, Dan Qiao, Wenliang Chen, Guohong Fu, Qiaoming Zhu, Guodong Zhou, Min Zhang 拥有数十亿参数的大型语言模型法学硕士在各种自然语言处理任务上表现出了出色的性能。本报告提出了OpenBA,一个开源的15B双语非对称seq2seq模型,为面向中国的开源模型社区贡献LLM变体。我们通过有效且高效的技术增强 OpenBA,并采用三阶段训练策略从头开始训练模型。我们的解决方案还可以仅用 380B 代币实现非常有竞争力的性能,这比 BELEBELE 基准上的 LLaMA 70B、MMLU 基准上的 BLOOM 176B、C Eval 硬基准上的 GLM 130B 更好。本报告提供了预训练类似模型的主要细节,包括预训练数据处理、双语 Flan 数据收集、启发模型架构设计的经验观察、不同阶段的训练目标以及其他增强技术。 |
| MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback Authors Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, Heng Ji 为了解决复杂的任务,大型语言模型法学硕士通常需要与用户进行多轮交互,有时需要外部工具的协助。然而,当前的评估范式通常只关注单轮交换的基准性能,忽略了用户、法学硕士和外部工具之间复杂的交互,导致基准评估与现实世界用例之间存在差异。我们引入 MINT 基准来评估法学硕士通过 1 使用工具和 2 利用自然语言反馈解决多轮交互任务的能力。为了确保可重复性,我们提供了一个评估框架,法学硕士可以通过执行 Python 代码来访问工具,并从使用 GPT 4 模拟的用户那里接收自然语言反馈。我们重新利用了一组不同的已建立数据集和任务,重点关注推理、编码和决策并仔细地将它们整理成一个紧凑的实例子集,以进行有效的评估。我们对 20 个开源和闭源法学硕士的分析提供了有趣的发现。 1 法学硕士通常受益于工具交互和语言反馈,其性能增益是绝对的,使用工具每增加一圈可提高 1 8 分,使用自然语言反馈可提高 2 17 分。 2 更好的单匝性能并不能保证更好的多匝性能。 3 令人惊讶的是,在我们评估的法学硕士中,我们发现监督指令微调 SIFT 和来自人类反馈 RLHF 的强化学习通常会损害多轮能力。 |
| EchoPrompt: Instructing the Model to Rephrase Queries for Improved In-context Learning Authors Rajasekhar Reddy Mekala, Yasaman Razeghi, Sameer Singh 大型语言模型主要依靠上下文学习来执行任务。我们引入了 EchoPrompt,这是一种简单而有效的方法,可以提示模型在回答查询之前重新表述其查询。 EchoPrompt 的灵感来自于自我质疑,这是人类在提供答案之前发出询问的一种认知策略,从而减少误解。实验结果表明,EchoPrompt 在四个因果语言模型系列上通过标准和思维链提示在上下文学习中带来了零样本和少样本的显着改进。这些改进可以在各种数字推理 GSM8K、SVAMP、MultiArith、SingleOp、阅读理解 DROP、SQuAD 以及逻辑推理 Shuffled Objects、日期理解、硬币翻转任务中观察到。平均而言,EchoPrompt 在数值任务中将代码 davinci 002 的零样本 CoT 性能提高了 5 倍,在阅读理解任务中提高了 13 倍。我们通过消融研究调查了 EchoPrompt 的有效性,揭示了原始查询和改写查询对 EchoPrompt 功效的重要性。 |
| Estimating Contamination via Perplexity: Quantifying Memorisation in Language Model Evaluation Authors Yucheng Li 由于大型语言模型的大量训练语料库经常无意中包含基准样本,模型评估中的数据污染变得越来越普遍。因此,污染分析已成为可靠模型评估的必然组成部分。然而,现有的污染分析方法需要访问整个训练数据,这对于最近的模型来说通常是保密的。这阻碍了社区严格审核这些模型并对其能力进行准确评估。在本文中,我们提出了一种无需访问完整训练集即可量化污染的新方法,该方法通过困惑度来衡量污染程度。 |
| NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages Authors Samuel Cahyawijaya, Holy Lovenia, Fajri Koto, Dea Adhista, Emmanuel Dave, Sarah Oktavianti, Salsabil Maulana Akbar, Jhonson Lee, Nuur Shadieq, Tjeng Wawan Cenggoro, Hanung Wahyuning Linuwih, Bryan Wilie, Galih Pradipta Muridan, Genta Indra Winata, David Moeljadi, Alham Fikri Aji, Ayu Purwarianti, Pascale Fung 自然语言处理 NLP 技术的民主化至关重要,特别是对于代表性不足和资源极少的语言。之前的研究主要集中在通过在线抓取和文档翻译来开发这些语言的标记和未标记语料库。虽然这些方法已被证明是有效且具有成本效益的,但我们发现了所得语料库的局限性,包括缺乏词汇多样性和与当地社区的文化相关性。为了解决这一差距,我们对印度尼西亚当地语言进行了案例研究。我们比较了在线抓取、人工翻译和母语人士撰写段落在构建数据集方面的有效性。我们的研究结果表明,通过母语人士写作段落生成的数据集在词汇多样性和文化内容方面表现出卓越的质量。此外,我们还提供了 datasetname 基准,涵盖印度尼西亚数百万人使用的 12 种代表性不足且资源极少的语言。我们使用现有多语言大语言模型的实证实验结果得出结论,需要将这些模型扩展到更多代表性不足的语言。 |
| CFGPT: Chinese Financial Assistant with Large Language Model Authors Jiangtong Li, Yuxuan Bian, Guoxuan Wang, Yang Lei, Dawei Cheng, Zhijun Ding, Changjun Jiang 大型语言模型法学硕士在金融领域的自然语言处理任务中展现出了巨大的潜力。在这项工作中,我们提出了一个名为 CFGPT 的中国金融生成预训练 Transformer 框架,其中包括用于预训练和监督微调的数据集 CFData、用于熟练管理金融文本的金融 LLM CFLLM 以及旨在导航现实的部署框架 CFAPP世界金融应用。 CFData 包含预训练数据集和监督微调数据集,其中预训练数据集整理了中国金融数据和分析,以及总共 5.84 亿个文档和 141B 个令牌的通用文本的较小子集,以及监督微调数据集专为六种不同的金融任务量身定制,体现了金融分析和决策的各个方面,总共有 150 万条指令对和 1.5B 个代币。 CFLLM 基于 InternLM 7B 来平衡模型能力和大小,在 CFData 上分两个阶段进行训练:持续预训练和监督微调。 CFAPP 以大型语言模型法学硕士为中心,并通过附加模块进行增强,以确保现实世界应用中的多方面功能。 |
| Improving Medical Dialogue Generation with Abstract Meaning Representations Authors Bohao Yang, Chen Tang, Chenghua Lin 医疗对话生成通过促进向患者传播医疗专业知识,在远程医疗中发挥着关键作用。现有的研究侧重于合并文本表示,这限制了它们表示文本语义的能力,例如忽略重要的医学实体。为了增强模型对文本语义和医学知识(包括实体和关系)的理解,我们引入了使用抽象含义表示 AMR 来构建图形表示,以描述语言成分和医学实体在对话中的作用。在本文中,我们提出了一种新颖的框架,使用 AMR 图对患者和医疗保健专业人员之间的对话进行建模,其中神经网络将文本和图形知识与双重注意机制结合在一起。实验结果表明,我们的框架在医学对话生成方面优于强大的基线模型,证明了 AMR 图在增强医学知识和逻辑关系表示方面的有效性。 |
| FRACAS: A FRench Annotated Corpus of Attribution relations in newS Authors Ange Richard, Laura Alonzo Canul, Fran ois Portet 从社会学和自然语言处理的角度来看,引文提取都是一项广泛有用的任务。然而,除了英语之外,用于研究这项任务的数据非常少。在本文中,我们提出了一个包含 1676 篇法语新闻专线文本的手动注释语料库,用于引文提取和来源归属。我们首先描述我们的语料库的组成以及在选择数据时所做的选择。然后我们详细介绍注释指南和注释过程,以及有关最终语料库的一些统计数据以及在直接、间接和混合引用类型之间获得的平衡,这特别具有挑战性。 |
| Unsupervised Deep Cross-Language Entity Alignment Authors Chuanyu Jiang, Yiming Qian, Lijun Chen, Yang Gu, Xia Xie 跨语言实体对齐是从不同语言知识图谱中找到相同语义实体的任务。在本文中,我们提出了一种简单而新颖的跨语言实体对齐无监督方法。我们利用深度学习多语言编码器结合机器翻译器对知识图谱文本进行编码,减少了对标签数据的依赖。与仅强调全局或局部对齐的传统方法不同,我们的方法同时考虑两种对齐策略。我们首先将对齐任务视为二分匹配问题,然后采用重新交换的思想来完成对齐。与仅给出一个最优解的传统二分匹配算法相比,我们的算法生成排名匹配结果,从而启用许多潜在的下游任务。此外,我们的方法可以在二分匹配过程中适应两种不同类型的最小和最大优化,这提供了更大的灵活性。我们的评估显示,在中文、日语和法语到英语对齐任务中,我们在 DBP15K 数据集上分别获得了 0.966、0.990 和 0.996 Hits 1 率。我们在无监督和半监督类别中的表现优于最先进的方法。 |
| Multimodal Modeling For Spoken Language Identification Authors Shikhar Bharadwaj, Min Ma, Shikhar Vashishth, Ankur Bapna, Sriram Ganapathy, Vera Axelrod, Siddharth Dalmia, Wei Han, Yu Zhang, Daan van Esch, Sandy Ritchie, Partha Talukdar, Jason Riesa 口语识别是指自动预测给定话语中口语的任务。传统上,它被建模为基于语音的语言识别任务。现有技术仅限于单一模态,但是在视频数据的情况下,存在大量可能对此任务有益的其他元数据。在这项工作中,我们提出了 MuSeLI,一种多模态口语识别方法,该方法深入研究使用各种元数据源来增强语言识别。我们的研究表明,视频标题、描述和地理位置等元数据为识别多媒体录制的口语提供了大量信息。我们使用 YouTube 视频的两个不同的公共数据集进行实验,并获得了语言识别任务的最新结果。 |
| OpenMSD: Towards Multilingual Scientific Documents Similarity Measurement Authors Yang Gao, Ji Ma, Ivan Korotkov, Keith Hall, Dana Alon, Don Metzler 我们在这项工作中开发和评估多语言科学文档相似性测量模型。此类模型可用于查找不同语言的相关作品,这可以帮助多语言研究人员更有效地查找和探索论文。我们提出了第一个多语言科学文档数据集,开放获取多语言科学文档 OpenMSD,其中包含 103 种语言的 7400 万篇论文和 7.78 亿个引用对。通过 OpenMSD,我们预训练科学专用语言模型,并探索不同的策略来派生相关论文对以微调模型,包括使用引用、共引和书目耦合对的混合。为了进一步提高非英语论文的模型性能,我们探索使用生成语言模型来用英语摘要丰富非英语论文。这使我们能够利用模型的英语功能为非英语论文创建更好的表示。 |
| NSOAMT -- New Search Only Approach to Machine Translation Authors Jo o Lu s, Diogo Cardoso, Jos Marques, Lu s Campos 翻译自动化机制和工具已经开发了好几年,旨在将不同语言的人们聚集在一起。采用了一种新的仅搜索机器翻译方法来解决其他技术的一些缓慢和不准确的问题。我们的想法是开发一种解决方案,通过索引结合特定语义的增量单词集,可以在其母语记录和翻译语言之间创建对应过程。这一研究原则假设给定类型的出版文献中使用的词汇在语言风格和词汇多样性方面都相对有限,这通过索引过程增强了翻译过程的即时性和严谨性的更大效果。处理大量电子文本文档并将其加载到数据库中,并进行分析和测量,以确认先前的前提。 |
| Enhancing Open-Domain Table Question Answering via Syntax- and Structure-aware Dense Retrieval Authors Nengzheng Jin, Dongfang Li, Junying Chen, Joanna Siebert, Qingcai Chen 开放域表问答旨在通过从大量表中检索和提取信息来提供问题的答案。现有的开放域表QA研究要么直接采用文本检索方法,要么仅在编码层考虑表结构进行表检索,这可能会导致表评分时语法和结构信息丢失。为了解决这个问题,我们提出了一种用于开放域表 QA 任务的语法和结构感知检索方法。它提供问题的语法表示,并使用表的结构标题和值表示,以避免丢失细粒度的语法和结构信息。然后,使用语法到结构聚合器通过模仿人类检索过程来获得问题和候选表之间的匹配分数。 |
| An Evaluation of GPT-4 on the ETHICS Dataset Authors Sergey Rodionov, Zarathustra Amadeus Goertzel, Ben Goertzel 本报告总结了 GPT 4 在 ETHICS 数据集上的性能的简短研究。 ETHICS 数据集由五个子数据集组成,涵盖不同的伦理学领域:正义、道义论、美德伦理学、功利主义和常识伦理学。道德判断的策划是为了与代表共同的人类价值观而不是道德困境的目标高度一致。 |
| Toward Unified Controllable Text Generation via Regular Expression Instruction Authors Xin Zheng, Hongyu Lin, Xianpei Han, Le Sun 可控文本生成是自然语言生成的一个基本方面,针对不同的约束类型提出了多种方法。然而,这些方法通常需要重大的架构或解码修改,这使得它们难以应用于附加约束或解决不同的约束组合。为了解决这个问题,我们的论文引入了正则表达式指令 REI,它利用基于指令的机制来充分利用正则表达式的优势来统一建模不同的约束。具体来说,我们的 REI 通过正则表达式样式指令支持所有流行的细粒度可控生成约束,即词汇、位置和长度,以及它们的复杂组合。我们的方法仅需要在中等规模语言模型或少量镜头上进行微调,在大型语言模型的上下文学习中,并且在应用于各种约束组合时不需要进一步调整。 |
| PICK: Polished & Informed Candidate Scoring for Knowledge-Grounded Dialogue Systems Authors Bryan Wilie, Yan Xu, Willy Chung, Samuel Cahyawijaya, Holy Lovenia, Pascale Fung 建议将对话响应生成建立在外部知识的基础上,以产生信息丰富且引人入胜的响应。然而,由于幻觉和缺乏连贯性等几个问题,当前基于知识的对话 KGD 系统常常无法将生成的响应与人类偏好的品质保持一致。在分析多个语言模型生成后,我们观察到在单个解码过程中存在替代生成的响应。与解码过程优先考虑的最佳响应相比,这些替代响应更加忠实,并且表现出与先前对话轮次相当或更高水平的相关性。为了应对这些挑战并在这些观察的推动下,我们提出了 Polished Informed Candidate Scoring PICK ,这是一种生成重新评分框架,使模型能够生成忠实且相关的响应,而无需额外的标记数据或模型调整。通过全面的自动和人工评估,我们证明了 PICK 在生成更忠实的响应同时保持与对话历史相关性方面的有效性。此外,PICK 在所有解码策略中都使用预言机和检索知识来持续提高系统性能。 |
| PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training Authors Dawei Zhu, Nan Yang, Liang Wang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li 在本文中,我们介绍了 Positional Skip wisE PoSE 训练,用于使大型语言模型 LLM 有效适应极长的上下文窗口。 PoSE 通过在训练期间使用带有操纵位置索引的固定上下文窗口来模拟长输入,从而将训练长度与目标上下文窗口大小解耦。具体来说,我们从长输入序列中选择几个短块,并引入不同的跳跃偏差项来修改每个块的位置索引。这些偏差项以及每个块的长度会针对每个训练示例进行更改,从而使模型能够适应目标上下文窗口内的所有位置,而无需对全长输入进行训练。实验表明,与全长微调相比,PoSE大大减少了内存和时间开销,同时对性能的影响最小。利用这一优势,我们已成功将 LLaMA 模型扩展到 128k 代币。此外,我们凭经验证实 PoSE 与所有基于 RoPE 的 LLM 和各种位置插值策略兼容。值得注意的是,通过将微调长度与目标上下文窗口解耦,PoSE 理论上可以无限扩展上下文窗口,仅受推理内存使用的限制。 |
| Prompt, Condition, and Generate: Classification of Unsupported Claims with In-Context Learning Authors Peter Ebert Christensen, Srishti Yadav, Serge Belongie 我们在日常生活中遇到的未经证实和不可证伪的主张可能会影响我们的世界观。然而,描述、总结以及更普遍地理解这些主张可能具有挑战性。在这项工作中,我们专注于细粒度的辩论主题,并制定一项新任务,从这些主张中提炼出一组可数的叙述。我们提供了一个包含 12 个有争议主题的众包数据集,其中包含来自异构来源的超过 12 万个论点、主张和评论,每个都带有叙述标签。我们进一步研究了如何使用大型语言模型法学硕士来通过上下文学习来综合声明。我们发现,生成的带有支持证据的主张可用于提高叙事分类模型的性能,此外,同一模型可以使用一些训练示例来推断立场和方面。这样的模型在依赖叙述的应用程序中非常有用,例如 |
| KoBigBird-large: Transformation of Transformer for Korean Language Understanding Authors Kisu Yang, Yoonna Jang, Taewoo Lee, Jinwoo Seong, Hyungjin Lee, Hwanseok Jang, Heuiseok Lim 这项工作展示了 KoBigBird Large,一种大尺寸的韩国 BigBird,它实现了最先进的性能,并允许进行长序列处理以实现韩语理解。在没有进一步预训练的情况下,我们仅使用我们提出的锥形绝对位置编码表示 TAPER 来转换架构并扩展位置编码。在实验中,KoBigBird Large 在韩语理解基准上展示了最先进的整体性能,并且在较长序列的文档分类和问答任务上与竞争基准模型相比表现出了最佳性能。 |
| QASnowball: An Iterative Bootstrapping Framework for High-Quality Question-Answering Data Generation Authors Xu Han, Kunlun Zhu, Shihao Liang, Zhi Zheng, Guoyang Zeng, Zhiyuan Liu, Maosong Sun 近年来,问答 QA 取得了成功,特别是它有可能成为解决各种 NLP 任务的基础范例。然而,获取足够的数据来构建有效且稳定的质量保证系统仍然是一个悬而未决的问题。针对这个问题,我们引入了一种用于 QA 数据增强的迭代引导框架,名为 QASnowball,它可以基于监督示例的种子集迭代生成大规模高质量的 QA 数据。具体来说,QASnowball由三个模块组成:答案提取器,用于提取未标记文档中的核心短语作为候选答案;问题生成器,用于根据文档和候选答案生成问题;QA数据过滤器,用于过滤高质量的QA数据。此外,QASnowball 可以通过重新播种种子集来自我增强,以在不同的迭代中微调自身,从而不断提高生成质量。我们在高资源英语场景和中等资源中文场景进行实验,实验结果表明QASnowball生成的数据可以促进QA模型1在生成的数据上训练模型达到了与使用监督数据相当的结果,2预训练对生成的数据和监督数据进行微调可以获得更好的性能。 |
| Investigating the Catastrophic Forgetting in Multimodal Large Language Models Authors Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, Yi Ma 随着 GPT4 的成功,人们对多模态大语言模型 MLLM 研究的兴趣激增。该研究重点是通过微调预训练的法学硕士和视觉模型来开发通用的法学硕士。然而,灾难性遗忘(一种臭名昭著的现象,即微调模型无法保持与预训练模型相似的性能)仍然是多模态 LLM MLLM 中的固有问题。在本文中,我们引入 EMT 评估多模态来评估 MLLM 中的灾难性遗忘,将每个 MLLM 视为图像分类器。我们首先应用 EMT 来评估几个开源的微调 MLLM,我们发现几乎所有评估的 MLLM 都无法在标准图像分类任务上保持与其视觉编码器相同的性能水平。此外,我们继续对 MLLM LLaVA 进行微调,并利用 EMT 来评估整个微调过程中的性能。有趣的是,我们的结果表明,通过增强文本和视觉特征的对齐,对图像数据集进行早期微调可以提高其他图像数据集的性能。然而,随着微调的进行,MLLM 开始产生幻觉,导致通用性显着损失,即使图像编码器保持冻结状态也是如此。 |
| Rigorously Assessing Natural Language Explanations of Neurons Authors Jing Huang, Atticus Geiger, Karel D Oosterlinck, Zhengxuan Wu, Christopher Potts 自然语言是解释大型语言模型如何处理和存储信息的一种有吸引力的媒介,但评估此类解释的可信度具有挑战性。为了帮助解决这个问题,我们开发了两种自然语言解释的评估模式,这些模式声称单个神经元代表文本输入中的概念。在观察模式中,我们评估神经元 a 在所有且仅涉及由所提出的解释 E 挑选出的概念的输入字符串上激活的声明。在干预模式中,我们将 E 解释为神经元 a 是 E 表示的概念的因果中介。我们将我们的框架应用于 Bills 等人的 GPT 4 生成的 GPT 2 XL 神经元的解释。 2023 年,并表明即使是最有信心的解释也有很高的错误率,并且几乎没有因果效应。 |
| Baichuan 2: Open Large-scale Language Models Authors Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, Fan Yang, Fei Deng, Feng Wang, Feng Liu, Guangwei Ai, Guosheng Dong Haizhou Zhao, Hang Xu, Haoze Sun, Hongda Zhang, Hui Liu, Jiaming Ji, Jian Xie, Juntao Dai, Kun Fang, Lei Su Liang Song, Lifeng Liu, Liyun Ru, Luyao Ma, Mang Wang, Mickel Liu, MingAn Lin, Nuolan Nie, Peidong Guo, Ruiyang Sun, Tao Zhang, Tianpeng Li, Tianyu Li, Wei Cheng, Weipeng Chen, Xiangrong Zeng, Xiaochuan Wang, Xiaoxi Chen, Xin Men, Xin Yu, Xuehai Pan, Yanjun Shen, Yiding Wang, Yiyu Li, Youxin Jiang, Yuchen Gao, Yupeng Zhang, Zenan Zhou, Zhiying Wu 大型语言模型法学硕士仅基于几个自然语言指令示例,就在各种自然语言任务上展示了卓越的性能,减少了对广泛特征工程的需求。然而,大多数强大的法学硕士都是闭源的,或者对英语以外的语言的能力有限。在这份技术报告中,我们介绍了百川 2,这是一系列包含 70 亿和 130 亿参数的大规模多语言语言模型,在 2.6 万亿个令牌上从头开始训练。百川 2 在 MMLU、CMMLU、GSM8K 和 HumanEval 等公共基准测试中匹配或优于其他类似规模的开源模型。此外,百川2在医学、法律等垂直领域也表现出色。 |
| Leveraging Speech PTM, Text LLM, and Emotional TTS for Speech Emotion Recognition Authors Ziyang Ma, Wen Wu, Zhisheng Zheng, Yiwei Guo, Qian Chen, Shiliang Zhang, Xie Chen 在本文中,我们探讨了如何使用最先进的语音预训练模型 PTM、data2vec、文本生成技术 GPT 4 和语音合成技术 Azure TTS 来提升语音情感识别 SER。首先,我们研究了不同语音自监督预训练模型的表示能力,我们发现data2vec在SER任务上具有良好的表示能力。其次,我们采用了强大的大型语言模型 LLM、GPT 4 和情感文本转语音 TTS 模型 Azure TTS,来生成情感一致的文本和语音。我们精心设计了文本提示和数据集构建,以获得高质量的合成情感语音数据。第三,我们研究了不同的数据增强方法来促进合成语音的 SER 任务,包括随机混合、对抗性训练、迁移学习和课程学习。 |
| Mixed-Distil-BERT: Code-mixed Language Modeling for Bangla, English, and Hindi Authors Md Nishat Raihan, Dhiman Goswami, Antara Mahmud 自然语言处理领域最流行的下游任务之一是文本分类。当文本代码混合时,文本分类任务变得更加艰巨。尽管在预训练期间没有接触到此类文本,但不同的 BERT 模型在应对代码混合 NLP 挑战方面已取得了成功。同样,为了提高性能,代码混合 NLP 模型依赖于将合成数据与现实世界数据相结合。了解使用相应代码混合语言进行预训练时 BERT 模型性能如何受到影响至关重要。在本文中,我们介绍了 Tri Distil BERT(一种在孟加拉语、英语和印地语上预训练的多语言模型)和 Mixed Distil BERT(一种对代码混合数据进行微调的模型)。 |
| What is the Best Automated Metric for Text to Motion Generation? Authors Jordan Voas, Yili Wang, Qixing Huang, Raymond Mooney 人们对从自然语言描述生成基于骨骼的人体运动越来越感兴趣。虽然大多数努力都集中在为这项任务开发更好的神经架构,但在确定适当的评估指标方面还没有开展大量工作。人工评估是这项任务的最终准确性衡量标准,自动化指标应与人工质量判断良好相关。由于描述与许多动作兼容,因此确定正确的度量对于评估和设计有效的生成模型至关重要。本文系统地研究了哪些指标最符合人类评估,并提出了更符合人类评估的新指标。我们的研究结果表明,目前用于此任务的指标都没有在样本水平上显示出与人类判断的中等相关性。然而,为了评估平均模型性能,常用的指标(例如 R Precision)和较少使用的坐标误差显示出很强的相关性。此外,不推荐最近开发的几个指标,因为它们与替代指标相比相关性较低。我们还引入了一种基于多模态 BERT 类模型 MoBERT 的新颖指标,它提供了与人类密切相关的样本级别评估,同时保持近乎完美的模型级别相关性。 |
| PolicyGPT: Automated Analysis of Privacy Policies with Large Language Models Authors Chenhao Tang, Zhengliang Liu, Chong Ma, Zihao Wu, Yiwei Li, Wei Liu, Dajiang Zhu, Quanzheng Li, Xiang Li, Tianming Liu, Lei Fan 隐私政策是在线服务提供商告知用户其数据收集和使用程序的主要渠道。然而,为了全面、降低法律风险,这些政策文件往往相当冗长。在实际使用中,用户倾向于直接点击“同意”按钮,而不是仔细阅读。这种做法使用户面临隐私泄露和法律问题的风险。最近,ChatGPT 和 GPT 4 等大型语言模型 LLM 的出现为文本分析开辟了新的可能性,特别是对于隐私政策等冗长的文档。在本研究中,我们研究了基于法学硕士的隐私政策文本分析框架PolicyGPT。该框架使用两个数据集进行了测试。第一个数据集包含 115 个网站的隐私政策,这些政策由法律专家精心注释,将每个部分分为 10 个类别之一。第二个数据集包含来自 304 个流行移动应用程序的隐私政策,每个句子都经过手动注释并分类为另外 10 个类别之一。在零样本学习条件下,PolicyGPT 表现出了强大的性能。 |
| Stabilizing RLHF through Advantage Model and Selective Rehearsal Authors Baolin Peng, Linfeng Song, Ye Tian, Lifeng Jin, Haitao Mi, Dong Yu 大型语言模型 法学硕士彻底改变了自然语言处理,但使用 RLHF 将这些模型与人类价值观和偏好保持一致仍然是一项重大挑战。这一挑战的特点是各种不稳定性,例如奖励黑客和灾难性遗忘。在本技术报告中,我们提出了两项创新来稳定 RLHF 训练 1 优势模型,该模型直接对优势分数(即与预期奖励相比的额外奖励)进行建模,并调节任务之间的分数分布以防止奖励黑客攻击。 2 选择性演练,通过战略性地选择 PPO 培训和知识演练的数据来减轻灾难性遗忘。 |
| Positive and Risky Message Assessment for Music Products Authors Yigeng Zhang, Mahsa Shafaei, Fabio Gonzalez, Thamar Solorio 在这项工作中,我们提出了一个新的研究问题,评估音乐产品中的积极和危险信息。我们首先建立多角度多层次音乐内容评估的基准,然后提出一种具有序数执行的有效多任务预测模型来解决这个问题。 |
| Few-Shot Adaptation for Parsing Contextual Utterances with LLMs Authors Kevin Lin, Patrick Xia, Hao Fang 我们评估基于大型语言模型 LLM 的语义解析器处理上下文话语的能力。在现实世界中,由于注释成本,通常仅存在有限数量的带注释的上下文话语,导致与非上下文话语相比不平衡。因此,解析器必须通过一些训练示例来适应上下文话语。我们研究了会话语义解析中的四种主要范式,即用话语历史解析、用参考程序解析、解析然后解析和重写然后解析。为了促进这种跨范式比较,我们构建了 SMCalFlow EventQueries,它是来自 SMCalFlow 的上下文示例的子集,并带有附加注释。 |
| Understanding Catastrophic Forgetting in Language Models via Implicit Inference Authors Suhas Kotha, Jacob Mitchell Springer, Aditi Raghunathan 通过指令调整或根据人类反馈进行强化学习等方法进行微调是训练语言模型以稳健地执行感兴趣的任务的关键步骤。然而,我们对微调的影响缺乏系统的了解,特别是对于窄微调分布之外的任务。在一个简化的场景中,我们证明了在微调数据分布中提高任务性能是以抑制其他任务上的模型功能为代价的。对于最接近微调分布的任务,这种降级尤其明显。我们假设语言模型隐式推断提示对应的任务,并且微调过程主要将该任务推断偏向微调分布中的任务。为了检验这个假设,我们提出了共轭提示,看看我们是否可以恢复预训练的能力。共轭提示人为地使任务看起来离微调分布更远,同时需要相同的功能。我们发现结合提示系统地恢复了我们合成设置的一些预训练能力。然后,我们观察到微调分布通常严重偏向英语,从而将共轭提示应用于现实世界的法学硕士。我们发现,简单地将提示翻译成不同的语言就可以使微调模型像预训练的模型一样做出响应。 |
| Hierarchy Builder: Organizing Textual Spans into a Hierarchy to Facilitate Navigation Authors Itay Yair, Hillel Taub Tabib, Yoav Goldberg 信息提取系统通常会生成有关特定主题的数百到数千个字符串。我们提出了一种方法,可以在探索性设置中促进更好地使用这些字符串,在该设置中,用户希望获得可用内容的广泛概述,并有机会更深入地了解某些方面。该系统的工作原理是将相似的项目分组在一起,并将剩余的项目排列成分层可导航的 DAG 结构。 |
| SYNDICOM: Improving Conversational Commonsense with Error-Injection and Natural Language Feedback Authors Christopher Richardson, Anirudh Sundar, Larry Heck 常识推理是人类交流的一个重要方面。尽管大型语言模型驱动的对话式人工智能最近取得了进展,但常识推理仍然是一项具有挑战性的任务。在这项工作中,我们介绍了 SYNDICOM 一种提高对话响应生成常识的方法。 SYNDICOM 由两个组件组成。第一个组件是由常识对话组成的数据集,这些常识对话是根据知识图创建并合成为自然语言的。该数据集包括对对话上下文的有效和无效响应,以及无效响应的自然语言反馈 NLF。第二个贡献是训练一个模型来预测无效响应的自然语言反馈 NLF 的两步过程,然后训练一个以预测的 NLF、无效响应和对话为条件的响应生成模型。 SYNDICOM 具有可扩展性,不需要强化学习。使用广泛的指标评估三项任务的实证结果。 SYNDICOM 在 ROUGE1 上比 ChatGPT 实现了 53 的相对改进,人类评估者当时更喜欢 SYNDICOM 而不是 ChatGPT 57。 |
| A novel approach to measuring patent claim scope based on probabilities obtained from (large) language models Authors S bastien Ragot 这项工作建议将专利权利要求的范围衡量为该权利要求中包含的自身信息的倒数。这种方法以信息论为基础,基于这样的假设:罕见的概念比常见的概念更具信息性,因为它更令人惊讶。自我信息是根据该主张发生的概率来计算的,其中该概率是根据语言模型计算的。考虑了五种语言模型,从最简单的每个单词或字符从均匀分布中提取的模型到使用平均单词或字符频率的中间模型,再到大型语言模型 GPT2 。有趣的是,最简单的语言模型将范围度量减少到单词或字符数的倒数,这是以前的作品中已经使用的度量。申请涉及针对不同发明的九个系列的专利权利要求,其中每个系列的权利要求的范围逐渐缩小。然后根据几个临时测试评估语言模型的性能。模型越复杂,结果就越好。 |
| Modeling interdisciplinary interactions among Physics, Mathematics & Computer Science Authors Rima Hazra, Mayank Singh, Pawan Goyal, Bibhas Adhikari, Animesh Mukherjee 近年来,跨学科性变得非常重要,并已成为进行前沿研究的关键方式之一。在本文中,我们尝试对物理 PHY、数学 MA 和计算机科学 CS 三个不同领域的引用流进行建模。例如,这些领域之间是否存在相互引用的特定模式。我们在包含来自这三个领域的超过 120 万篇文章的数据集上进行了实验。我们通过时间桶签名来量化这三个字段之间的引用交互。我们提出了基于最近提出的中继链接框架变体的数值模型,以解释三个学科的引用动态。 |
| Semantic Text Compression for Classification Authors Emrecan Kutay, Aylin Yener 我们研究文本的语义压缩,其中文本中包含的含义被传送到源解码器,例如用于分类。采用这种无需精确重建即可恢复含义的方法的主要动机是在存储和将信息传送到另一个节点方面潜在的资源节省。为此,我们提出了文本的语义量化和压缩方法,其中我们利用句子嵌入和语义失真度量来保留含义。我们的结果表明,与语义无关的基线相比,所提出的语义方法可以节省大量数量级的消息表示所需的位数,但代价是非常适度的准确性损失。我们比较了所提出方法的结果,并观察到语义量化所带来的资源节省可以通过语义聚类进一步放大。 |
| Language as the Medium: Multimodal Video Classification through text only Authors Laura Hanu, Anita L. Ver , James Thewlis 尽管多模态机器学习模型出现了令人兴奋的新浪潮,但当前的方法仍然难以解释视频中存在的不同模态之间复杂的上下文关系。超越强调简单活动或对象的现有方法,我们提出了一种新的模型不可知方法,用于生成捕获多模态视频信息的详细文本描述。我们的方法利用大型语言模型(例如 GPT 3.5 或 Llama2)学到的广泛知识来推理从 BLIP 2、Whisper 和 ImageBind 获得的视觉和听觉模态的文本描述。无需对视频文本模型或数据集进行额外的微调,我们证明可用的法学硕士能够使用这些多模态文本描述作为视觉或听觉的代理,并在上下文中对视频进行零样本多模态分类。我们对流行的动作识别基准(例如 UCF 101 或 Kinetics)的评估表明,这些上下文丰富的描述可以成功地用于视频理解任务。 |
| Interactive Distillation of Large Single-Topic Corpora of Scientific Papers Authors Nicholas Solovyev, Ryan Barron, Manish Bhattarai, Maksim E. Eren, Kim O. Rasmussen, Boian S. Alexandrov 高度具体的科学文献数据集对于研究和教育都很重要。然而,大规模构建这样的数据集很困难。一种常见的方法是通过在已建立的语料库上应用主题建模并选择特定主题来简化构建这些数据集。一种更强大但耗时的方法是建设性地构建数据集,其中主题专家 SME 精心挑选文档。此方法无法扩展,并且随着数据集的增长容易出错。在这里,我们展示了一种基于机器学习的新工具,用于建设性地生成科学文献的目标数据集。给定一个小的初始核心论文语料库,我们构建一个文档引用网络。在引文网络的每一步,我们都会生成文本嵌入并通过降维来可视化嵌入。如果论文与核心相似,或者通过人工循环选择进行了修剪,则它们会保留在数据集中。通过使用 SeNMFk 进行子主题建模,可以获得对论文的更多见解。 |
| MelodyGLM: Multi-task Pre-training for Symbolic Melody Generation Authors Xinda Wu, Zhijie Huang, Kejun Zhang, Jiaxing Yu, Xu Tan, Tieyao Zhang, Zihao Wang, Lingyun Sun 预训练的语言模型在各种音乐理解和生成任务中取得了令人印象深刻的结果。然而,由于文本和音乐之间的领域知识差异,现有的符号旋律生成预训练方法难以捕获音符序列中的多尺度、多维结构信息。此外,缺乏可用的大规模符号旋律数据集限制了预训练的改进。在本文中,我们提出了 MelodyGLM,一种用于生成具有长期结构的旋律的多任务预训练框架。我们设计了旋律 n gram 和长跨度采样策略来创建局部和全局空白填充任务,以对旋律中的局部和全局结构进行建模。具体来说,我们将音高 n 克、节奏 n 克及其组合 n 克纳入旋律 n 克空白填充任务中,以对旋律中的多维结构进行建模。为此,我们构建了一个大规模的符号旋律数据集MelodyNet,包含超过40万个旋律片段。 MelodyNet 用于大规模预训练和特定领域的 n gram 词典构建。主观和客观评估都表明 MelodyGLM 超越了标准和之前的预训练方法。特别是,主观评估表明,在旋律延续任务上,MelodyGLM 在一致性、节奏性、结构和整体质量方面分别实现了 0.82、0.87、0.78 和 0.94 的平均改进。 |
| Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models Authors Hsuan Su, Ting Yao Hu, Hema Swetha Koppula, Raviteja Vemulapalli, Jen Hao Rick Chang, Karren Yang, Gautam Varma Mantena, Oncel Tuzel 虽然自动语音识别 ASR 系统广泛应用于许多现实世界的应用中,但它们通常不能很好地推广到新领域,需要根据这些领域的数据进行微调。然而,在许多情况下,目标域数据通常不容易获得。在本文中,我们提出了一种新策略,使 ASR 模型适应新的目标领域,而无需这些领域的任何文本或语音。为了实现这一目标,我们提出了一种新颖的数据合成管道,它使用大型语言模型 LLM 来生成目标域文本语料库,并使用最先进的可控语音合成模型来生成相应的语音。我们提出了一种简单而有效的上下文指令微调策略,以提高法学硕士为新领域生成文本语料库的有效性。 |
| Language Modeling Is Compression Authors Gr goire Del tang, Anian Ruoss, Paul Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, Marcus Hutter, Joel Veness 人们早已确定预测模型可以转化为无损压缩器,反之亦然。顺便说一句,近年来,机器学习社区一直专注于训练越来越大、越来越强大的自监督语言模型。由于这些大型语言模型表现出令人印象深刻的预测能力,因此它们非常适合成为强大的压缩器。在这项工作中,我们主张通过压缩的视角来看待预测问题,并评估大型基础模型的压缩能力。我们证明大型语言模型是强大的通用预测器,并且压缩观点为缩放法则、标记化和上下文学习提供了新颖的见解。例如,Chinchilla 70B 虽然主要在文本上进行训练,但将 ImageNet 补丁压缩到原始大小的 43.4,将 LibriSpeech 样本压缩到原始大小的 16.4,分别击败了 PNG 58.5 或 FLAC 30.3 等领域特定压缩器。 |
| Large language models can accurately predict searcher preferences Authors Paul Thomas, Seth Spielman, Nick Craswell, Bhaskar Mitra 相关性标签表明搜索结果对搜索者是否有价值,是评估和优化搜索系统的关键。捕获用户真实偏好的最佳方法是询问他们对哪些结果有用的仔细反馈,但这种方法无法扩展以产生大量标签。大规模获取相关性标签通常由第三方贴标者完成,他们代表用户进行判断,但如果贴标者不了解用户需求,则存在低质量数据的风险。为了提高质量,一种标准方法是通过访谈、用户研究和直接反馈来研究真实用户,找到标签与用户系统性不一致的领域,然后通过判断指南、培训和监控来教育标签者了解用户需求。本文介绍了一种提高标签质量的替代方法。 |
| A Neighbourhood-Aware Differential Privacy Mechanism for Static Word Embeddings Authors Danushka Bollegala, Shuichi Otake, Tomoya Machide, Ken ichi Kawarabayashi 我们提出了一种邻域感知差分隐私 NADP 机制,考虑预训练静态词嵌入空间中单词的邻域,以确定保证指定隐私级别所需的最小噪声量。我们首先使用单词的嵌入构建单词的最近邻图,并将其分解为一组连接的组件,即邻域。然后,我们分别对每个邻域中的单词应用不同级别的高斯噪声,具体取决于该邻域中的单词集。 |
| Model Leeching: An Extraction Attack Targeting LLMs Authors Lewis Birch, William Hackett, Stefan Trawicki, Neeraj Suri, Peter Garraghan Model Leeching 是一种针对大型语言模型 LLM 的新型提取攻击,能够将目标 LLM 中的任务特定知识提取到简化的参数模型中。我们通过从 ChatGPT 3.5 Turbo 中提取任务能力来证明攻击的有效性,实现了 73 的精确匹配 EM 相似度,以及 SQuAD EM 和 F1 准确度分数分别为 75 和 87,而 API 成本仅为 50。 |
| Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition Authors Yosuke Higuchi, Tetsuji Ogawa, Tetsunori Kobayashi 我们提出了一种指令调整大语言模型 LLM 和端到端自动语音识别 ASR 的新颖集成。当提供精确的指令或提示来指导文本生成过程实现所需任务时,现代法学硕士可以在零样本学习中执行广泛的语言任务。我们探索使用法学硕士的这种零样本能力来提取有助于提高 ASR 性能的语言信息。具体来说,我们指导法学硕士纠正 ASR 假设中的语法错误,并利用嵌入的语言知识进行端到端 ASR。所提出的模型建立在混合连接主义时间分类 CTC 和注意力架构的基础上,其中指令调整的 LLM(即 Llama2)被用作解码器的前端。经过修正的 ASR 假设是通过 CTC 解码从编码器获得的,然后与指令一起输入到 LLM 中。解码器随后将 LLM 嵌入作为输入来执行序列生成,并结合来自编码器输出的声学信息。 |
| Improving Speaker Diarization using Semantic Information: Joint Pairwise Constraints Propagation Authors Luyao Cheng, Siqi Zheng, Qinglin Zhang, Hui Wang, Yafeng Chen, Qian Chen, Shiliang Zhang 说话人分类在语音处理研究界引起了相当大的关注。主流的说话人分类主要依赖于从声学信号中提取的说话人语音特征,并且常常忽视语义信息的潜力。考虑到语音信号可以有效地传达语音内容,我们有兴趣利用语言模型充分利用这些语义线索。在这项工作中,我们提出了一种新方法,可以在基于聚类的说话人分类系统中有效利用语义信息。首先,我们引入口语理解模块来提取与说话人相关的语义信息,并利用这些信息来构造成对约束。其次,我们提出了一种新颖的框架,将这些约束集成到说话人二值化管道中,从而提高整个系统的性能。 |
| Exploring Self-Reinforcement for Improving Learnersourced Multiple-Choice Question Explanations with Large Language Models Authors Qiming Bao, Juho Leinonen, Alex Yuxuan Peng, Wanjun Zhong, Tim Pistotti, Alice Huang, Paul Denny, Michael Witbrock, Jiamou Liu 学习者采购涉及学生生成并与同龄人共享学习资源。当学习者处理多项选择题时,为生成的问题创建解释是至关重要的一步,因为它有助于更深入地理解相关概念。然而,由于学科理解有限,并且倾向于仅仅重述问题主干、干扰因素和正确答案,学生通常很难做出有效的解释。为了帮助完成这项任务,在这项工作中,我们提出了一个自我强化的大型语言模型框架,其目标是自动生成和评估解释。该框架由三个模块组成,生成学生一致的解释,评估这些解释以确保其质量并迭代增强解释。如果解释的评估分数低于定义的阈值,框架会迭代地细化并重新评估该解释。重要的是,我们的框架模仿了学生在相关年级撰写解释的方式。为了进行评估,我们请了一位人类主题专家将学生生成的解释与开源大型语言模型 Vicuna 13B(使用我们的方法微调的 Vicuna 13B 版本)和 GPT 4 创建的解释进行比较。观察到,与其他大型语言模型相比,GPT 4 在生成解释方面表现出更高水平的创造力。我们还发现,人类专家对 GPT 4 生成的解释的排名高于其他模型创建的解释和原始学生创建的解释。 |
| Reformulating Sequential Recommendation: Learning Dynamic User Interest with Content-enriched Language Modeling Authors Junzhe Jiang, Shang Qu, Mingyue Cheng, Qi Liu 推荐系统对于在线应用程序至关重要,顺序推荐由于其捕捉动态用户兴趣的表达能力而受到广泛欢迎。然而,以前的顺序建模方法在捕获上下文信息方面仍然存在局限性。这个问题的主要原因是语言模型通常缺乏对特定领域知识和项目相关文本内容的理解。为了解决这个问题,我们采用了一种新的顺序推荐范式并提出了 LANCER,它利用预先训练的语言模型的语义理解能力来生成个性化推荐。我们的方法弥合了语言模型和推荐系统之间的差距,从而产生更加人性化的推荐。我们通过对几个基准数据集的实验证明了我们方法的有效性,显示了有希望的结果,并为我们的模型对顺序推荐任务的影响提供了有价值的见解。 |
| Writer-Defined AI Personas for On-Demand Feedback Generation Authors Karim Benharrak, Tim Zindulka, Florian Lehmann, Hendrik Heuer, Daniel Buschek 引人入胜的写作是为读者量身定制的。这是具有挑战性的,因为作家可能很难理解读者、及时获得反馈或接触目标群体。我们提出了一个概念,可以根据作者定义的任何目标受众的人工智能角色生成按需反馈。我们在两项用户研究中使用 GPT 3.5 探索了这个概念,N 5 和 N 11 作者很欣赏这个概念,并战略性地使用角色来获得不同的观点。这些反馈被认为是对文本和角色的有益和启发性的修改,尽管它通常是冗长和不具体的。我们讨论了按需反馈的影响、当代人工智能系统的有限代表性,以及定义人工智能角色的进一步想法。 |
| Explaining Agent Behavior with Large Language Models Authors Xijia Zhang, Yue Guo, Simon Stepputtis, Katia Sycara, Joseph Campbell 机器人等智能代理越来越多地部署在现实世界的安全关键环境中。至关重要的是,这些智能体能够向人类同行解释其决策背后的推理,然而,它们的行为通常是由不可解释的模型(例如深度神经网络)产生的。我们提出了一种仅基于对状态和动作的观察来生成代理行为的自然语言解释的方法,与底层模型表示无关。我们展示了如何学习代理行为的紧凑表示并用于以最小的幻觉产生合理的解释,同时为用户提供与预先训练的大型语言模型的交互。 |
| Using fine-tuning and min lookahead beam search to improve Whisper Authors Andrea Do, Oscar Brown, Zhengjie Wang, Nikhil Mathew, Zixin Liu, Jawwad Ahmed, Cheng Yu Whisper 在低资源语言中的性能还远未达到完美。除了缺乏低资源语言的训练数据之外,我们还发现 Whisper 中使用的波束搜索算法存在一些局限性。为了解决这些问题,我们对附加数据进行微调 Whisper 并提出改进的解码算法。对于越南语,使用 LoRA 进行微调 Whisper Tiny 使 WER 比零样本 Whisper Tiny 设置提高了 38.49,与全参数微调相比进一步降低了 1.45。此外,通过使用 Filter Ends 和 Min Lookahead 解码算法,与标准波束搜索相比,多种语言的 WER 平均降低了 2.26。这些结果可推广到更大的 Whisper 模型尺寸。 |
| LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI's ChatGPT Plugins Authors Umar Iqbal, Tadayoshi Kohno, Franziska Roesner ChatGPT 等大型语言模型 LLM 平台最近开始提供插件生态系统来与互联网上的第三方服务进行交互。虽然这些插件扩展了 LLM 平台的功能,但它们是由任意第三方开发的,因此不能被隐式信任。插件还使用自然语言与 LLM 平台和用户进行交互,这可能会有不精确的解释。在本文中,我们提出了一个框架,为LLM平台设计者分析和提高当前和未来插件集成LLM平台的安全性、隐私性和安全性奠定了基础。我们的框架是攻击分类法的制定,该分类法是通过迭代探索LLM平台利益相关者如何利用他们的能力和责任来相互发起攻击而开发的。作为迭代过程的一部分,我们在 OpenAI 插件生态系统的背景下应用我们的框架。我们发现的插件具体展示了我们在攻击分类中概述的问题类型的可能性。 |
| Unified Coarse-to-Fine Alignment for Video-Text Retrieval Authors Ziyang Wang, Yi Lin Sung, Feng Cheng, Gedas Bertasius, Mohit Bansal 视频文本检索的规范方法利用视觉和文本信息之间的粗粒度或细粒度对齐。然而,根据文本查询检索正确的视频通常具有挑战性,因为它需要能够推理高级场景和低级对象视觉线索以及它们与文本查询的关系。为此,我们提出了一个统一的粗细对齐模型,称为 UCoFiA。具体来说,我们的模型捕获不同粒度级别的跨模态相似性信息。为了减轻不相关视觉线索的影响,我们还应用交互式相似性聚合模块 ISA 来考虑不同视觉特征的重要性,同时聚合跨模式相似性以获得每个粒度的相似性得分。最后,我们应用 Sinkhorn Knopp 算法在求和之前对每个级别的相似性进行归一化,从而缓解不同级别的表示过度和不足的问题。通过共同考虑不同粒度的跨模态相似性,UCoFiA 允许多粒度对齐的有效统一。根据经验,UCoFiA 在多个视频文本检索基准上优于先前最先进的基于 CLIP 的方法,在 MSR VTT、Activity Net 和 DiDeMo 上的文本到视频检索 R 1 方面分别实现了 2.4、1.4 和 1.3 的改进。 |
| HTEC: Human Transcription Error Correction Authors Hanbo Sun, Jian Gao, Xiaomin Wu, Anjie Fang, Cheng Cao, Zheng Du 高质量的人工转录对于训练和改进自动语音识别 ASR 模型至关重要。引用 libricrowd 的最新研究发现,通过使用转录来训练 ASR 模型,每恶化 1 个转录单词错误率 WER 就会增加大约 2 个 ASR WER。即使对于训练有素的注释者来说,转录错误也是不可避免的。然而,很少有研究探索人类转录校正。针对其他问题的纠错方法,例如 ASR 纠错和语法纠错,不足以解决该问题。因此,我们提出 HTEC 用于人类转录错误校正。 HTEC 由两个阶段组成:Trans Checker(一种预测和屏蔽错误单词的错误检测模型)和 Trans Filler(一种填充屏蔽位置的序列到序列生成模型)。我们提出了一个完整的更正操作列表,包括四个处理删除错误的新颖操作。我们进一步提出了一种嵌入的变体,它将音素信息合并到变压器的输入中。 HTEC 大幅优于其他方法,WER 超过人类注释者 2.2 至 4.5。 |
| Automatic Personalized Impression Generation for PET Reports Using Large Language Models Authors Xin Tie, Muheon Shin, Ali Pirasteh, Nevein Ibrahim, Zachary Huemann, Sharon M. Castellino, Kara M. Kelly, John Garrett, Junjie Hu, Steve Y. Cho, Tyler J. Bradshaw 目的 确定经过微调的大型语言模型法学硕士是否可以为全身 PET 报告生成准确、个性化的印象。材料和方法 使用教师强制算法在 PET 报告语料库上训练 12 个语言模型,以报告结果作为输入,以临床印象作为参考。额外的输入标记对阅读医生的身份进行编码,允许模型学习医生特定的报告风格。我们的语料库包含 2010 年至 2022 年间从我们机构收集的 37,370 份回顾性 PET 报告。为了确定最佳的法学硕士,我们以两名核医学 NM 医生的质量评分为基准,对 30 个评估指标进行了基准测试,并选择最一致的指标进行专家评估模型。在数据子集中,模型生成的印象和原始临床印象由三名 NM 医生根据 6 个质量维度和总体效用评分 5 分制进行评估。每位医生审查了 12 份自己的报告和 12 份其他医生的报告。使用 Bootstrap 重采样进行统计分析。结果 在所有评估指标中,领域适应的 BARTScore 和 PEGASUSScore 显示与医生偏好的 Spearman s rho 相关性最高,分别为 0.568 和 0.563。根据这些指标,经过微调的 PEGASUS 模型被选为顶级法学硕士。当医生以自己的风格审查 PEGASUS 生成的印象时,89 个被认为是临床可接受的,平均效用得分为 4.08 5。医生将这些个性化印象的总体效用与其他医生指定的印象相比较 4.03,P 0.41 。 |
| Multimodal Foundation Models: From Specialists to General-Purpose Assistants Authors Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, Jianfeng Gao 本文对展示视觉和视觉语言功能的多模态基础模型的分类和演变进行了全面调查,重点关注从专业模型到通用助手的转变。研究领域包括五个核心主题,分为两类。 i 我们首先对已建立的研究领域进行了调查,针对特定目的进行了预训练的多模态基础模型,包括学习用于视觉理解的视觉主干和文本到图像生成的两个主题方法。 ii 然后,我们介绍了探索性、开放研究领域多模态基础模型的最新进展,旨在发挥通用助理的作用,包括受大语言模型法学硕士启发的三个主题统一视觉模型、多模态法学硕士的端到端训练和链接与法学硕士的多模式工具。 |
| Detecting covariate drift in text data using document embeddings and dimensionality reduction Authors Vinayak Sodar, Ankit Sekseria 检测文本数据中的协变量漂移对于维持文本分析模型的可靠性和性能至关重要。在这项研究中,我们研究了不同文档嵌入、降维技术和漂移检测方法在识别文本数据中协变量漂移方面的有效性。我们探索了三种流行的文档嵌入术语频率逆文档频率 TF IDF,使用潜在语义分析 LSA 进行降维和 Doc2Vec,以及 BERT 嵌入,使用或不使用主成分分析 PCA 进行降维。为了量化训练和测试数据分布之间的差异,我们采用 Kolmogorov Smirnov KS 统计量和最大平均差异 MMD 测试作为漂移检测方法。实验结果表明,嵌入、降维技术和漂移检测方法的某些组合在检测协变量漂移方面优于其他方法。 |
| Improving Speech Recognition for African American English With Audio Classification Authors Shefali Garg, Zhouyuan Huo, Khe Chai Sim, Suzan Schwartz, Mason Chua, Al na Aks nova, Tsendsuren Munkhdalai, Levi King, Darryl Wright, Zion Mengesha, Dongseong Hwang, Tara Sainath, Fran oise Beaufays, Pedro Moreno Mengibar 自动语音识别 ASR 系统已被证明在它们打算或期望识别的语言品种之间存在巨大的质量差异。缓解这种情况的一种方法是使用更具代表性的数据集来训练或微调模型。但这种方法可能会受到用于训练和评估的领域数据有限的阻碍。我们提出了一种新方法,使用少量的域外长格式非裔美国英语 AAE 数据来提高美国英语短格式语音识别器的鲁棒性。我们使用 CORAAL、YouTube 和 Mozilla Common Voice 来训练音频分类器,以大致输出话语是 AAE 还是其他类型(包括主流美式英语 MAE)。通过将分类器输出与粗略地理信息相结合,我们可以从大量未转录的简短查询语料库中选择话语子集,以进行大规模的半监督学习。 |
| OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax? Authors Andrew Blair Stanek, Nils Holzenberger, Benjamin Van Durme |
| Code Representation Pre-training with Complements from Program Executions Authors Jiabo Huang, Jianyu Zhao, Yuyang Rong, Yiwen Guo, Yifeng He, Hao Chen 用于自然语言处理的大型语言模型法学硕士已被移植到编程语言模型中,以提高代码智能。尽管它可以以文本格式表示,但代码在语法上更加严格,以便正确编译或解释以在给定任何输入的情况下执行一组所需的行为。在这种情况下,现有的工作受益于语法表示,以抽象语法树、控制流图等形式更明确地从代码中学习。然而,具有相同目的的程序可以通过多种方式实现,显示不同的语法表示,而这些具有相似实现的可以有不同的行为。尽管在执行过程中进行了简单的演示,但直接从代码中学习此类有关功能的语义具有挑战性,尤其是以无监督的方式。因此,在本文中,我们提出 FuzzPretrain 来探索测试用例揭示的程序的动态信息,并将其作为补充嵌入到代码的特征表示中。测试用例是在定制模糊器的帮助下获得的,并且仅在预训练期间需要。与仅使用源代码或 AST 训练的对应模型相比,FuzzPretrain 在代码搜索方面产生了超过 6 9 mAP 改进。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com