相关博客
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、MPT介绍
MPT是由MosaicML团队开源出来了英文预训练大模型,共开源了4个模型:MPT-7B Base、MPT-7B-StoryWriter-65k+、MPT-7B-Instruct、MPT-7B-Chat。
1. 模型结构与预训练
- MPT-7B Base是一个GPT风格的decoder-only Transformer模型,参数量为6.7B,使用了1T tokens进行预训练;
- 使用了440张A100x40G的GPU训练了9.5天;
- 使用ALiBi而不是位置编码,除了可以提供外推长度外,也能提高对loss spike的适应性;
- 优化器使用Lion而不是AdamW,能提供更加稳定的更新幅度且减少优化器缓存占用的一半;
- 通过使用FlashAttention、低精度LayerNorm层和FasterTransformer实现更快的推理;
2. 使用的数据
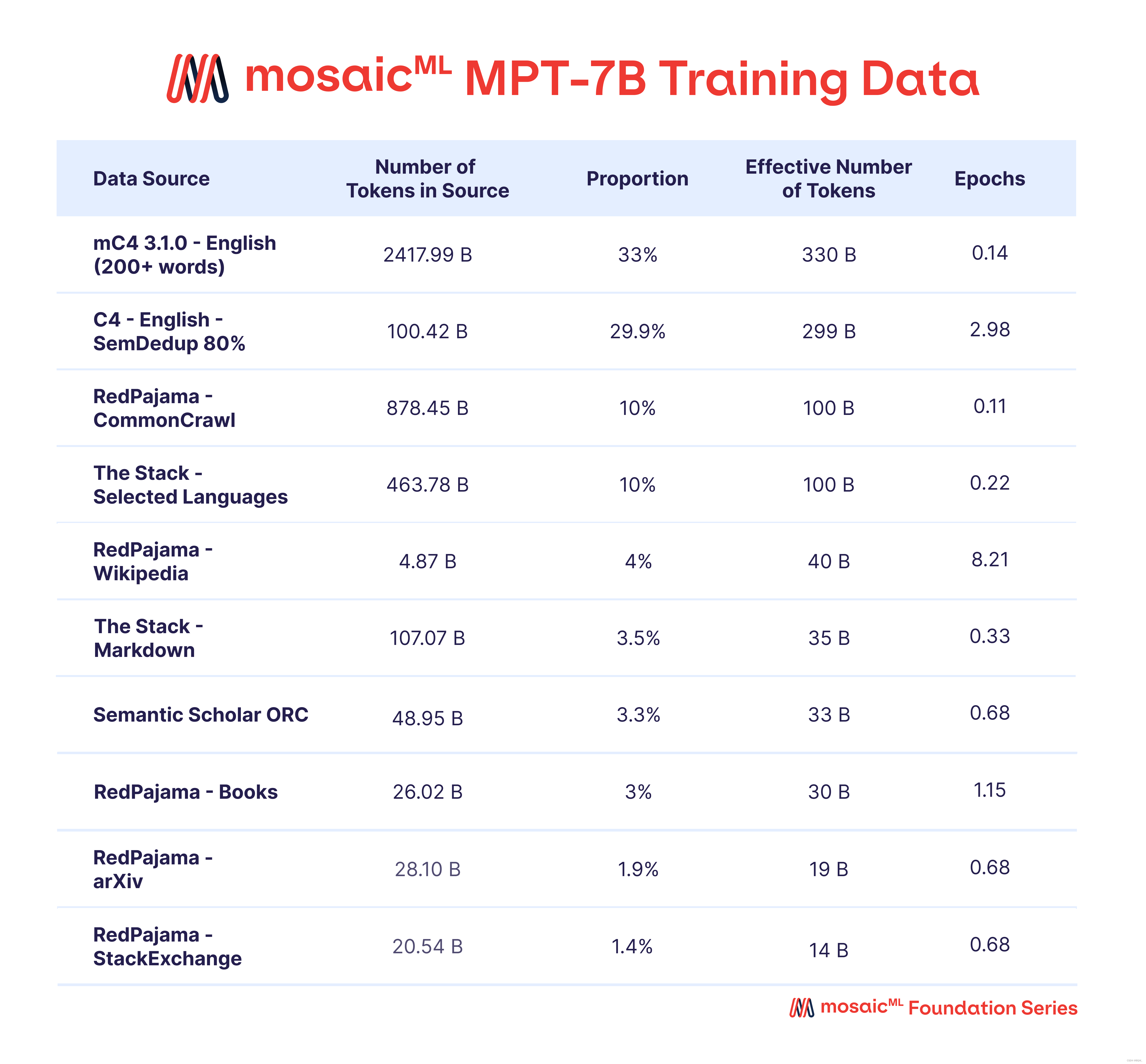
3. 效果
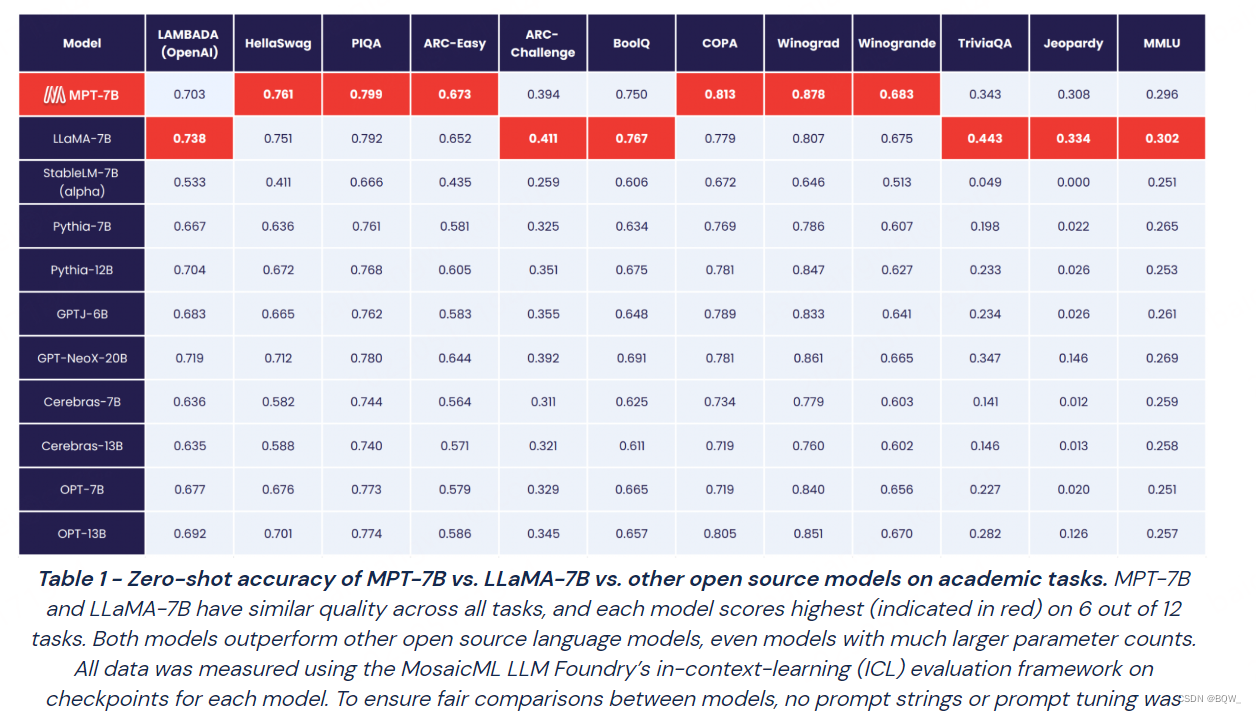
4. 不同版本的模型
MPT-7B Base是预训练语言模型,也是其他模型的基础;
MPT-7B-StoryWriter-65k+则是用长度为65k+的书籍语料微调的模型,得益于ALiBi的外推能力,其能够外推至84k的tokens;
MPT-7B-Instruct是一个经过指令微调的模型;
MPT-7B-Chat是一个对话模型,微调数据包括:ShareGPT-Vicuna、HC3、Alpaca、Helpful and Harmless以及Evol-Instruct;
二、模型结构
1. Layer Norm
虽然MPT在推理时,使用的是低精度LayerNorm。但是代码实现中,也提供了RMSNorm。因此,这里会简单介绍其实现的各类Norm。代码位于https://huggingface.co/mosaicml/mpt-7b/blob/main/norm.py。
1.1 标准Layer Norm
在Transformer中LayerNorm是对**(batch_size, seq_length, hidden_size)**中的hidden_size维度进行normalize。具体来说,给定一个向量
x
\textbf{x}
x,则normalize的过程为:
y
=
x
−
E
(
x
)
Var
(
x
)
+
ϵ
∗
γ
+
β
\textbf{y}=\frac{\textbf{x}-\text{E}(\textbf{x})}{\sqrt{\text{Var}(\textbf{x})+\epsilon}}*\gamma+\beta \\
y=Var(x)+ϵx−E(x)∗γ+β
其中,
E
(
x
)
\text{E}(\textbf{x})
E(x)表示向量
x
\textbf{x}
x的期望,
Var
(
x
)
\text{Var}(\textbf{x})
Var(x)是向量
x
\textbf{x}
x的方差,
ϵ
\epsilon
ϵ是为了防止分母为0的偏置项,
γ
\gamma
γ和
β
\beta
β是两个可学习参数。
def _cast_if_autocast_enabled(tensor):
"""
自动转换tensor的数据类型,用来实现后续的低精度LayerNorm。
"""
if torch.is_autocast_enabled():
if tensor.device.type == 'cuda':
dtype = torch.get_autocast_gpu_dtype()
elif tensor.device.type == 'cpu':
dtype = torch.get_autocast_cpu_dtype()
else:
raise NotImplementedError()
return tensor.to(dtype=dtype)
return tensor
class LPLayerNorm(torch.nn.LayerNorm):
"""
低精度LayerNorm,也输入和LayerNorm的参数转换为低精度
"""
def __init__(self, normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None):
super().__init__(normalized_shape=normalized_shape, eps=eps, elementwise_affine=elementwise_affine, device=device, dtype=dtype)
def forward(self, x):
module_device = x.device
# 将输入和LayerNorm的参数都转换为低精度
downcast_x = _cast_if_autocast_enabled(x)
downcast_weight = _cast_if_autocast_enabled(self.weight) if self.weight is not None else self.weight
downcast_bias = _cast_if_autocast_enabled(self.bias) if self.bias is not None else self.bias
with torch.autocast(enabled=False, device_type=module_device.type):
return torch.nn.functional.layer_norm(downcast_x, self.normalized_shape, downcast_weight, downcast_bias, self.eps)
1.2 RMS Norm
相比于LayerNorm,RMS Norm主要是去掉了减均值的部分。
y
=
x
RMS
(
x
)
RMS
(
x
)
=
1
n
∑
i
=
1
n
x
i
2
\begin{align} \textbf{y}&=\frac{\textbf{x}}{\text{RMS}(\textbf{x})} \\ \text{RMS}(\textbf{x})&=\sqrt{\frac{1}{n}\sum_{i=1}^n x_i^2} \end{align} \\
yRMS(x)=RMS(x)x=n1i=1∑nxi2
def rms_norm(x, weight=None, eps=1e-05):
"""
RMS的实现
"""
output = x / torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + eps)
if weight is not None:
return output * weight
return output
class RMSNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None):
super().__init__()
self.eps = eps
if weight:
self.weight = torch.nn.Parameter(torch.ones(normalized_shape, dtype=dtype, device=device))
else:
self.register_parameter('weight', None)
def forward(self, x):
return rms_norm(x.float(), self.weight, self.eps).to(dtype=x.dtype)
class LPRMSNorm(RMSNorm):
"""
低精度RMS Norm的实现
"""
def __init__(self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None):
super().__init__(normalized_shape=normalized_shape, eps=eps, weight=weight, dtype=dtype, device=device)
def forward(self, x):
downcast_x = _cast_if_autocast_enabled(x)
downcast_weight = _cast_if_autocast_enabled(self.weight) if self.weight is not None else self.weight
with torch.autocast(enabled=False, device_type=x.device.type):
return rms_norm(downcast_x, downcast_weight, self.eps).to(dtype=x.dtype)
NORM_CLASS_REGISTRY = {'layernorm': torch.nn.LayerNorm, 'low_precision_layernorm': LPLayerNorm, 'rmsnorm': RMSNorm, 'low_precision_rmsnorm': LPRMSNorm}
2. 自注意力
虽然MPT中仍然使用多头注意力,但是其同时实现了"多头注意力"和"多Query注意力",并且提供了纯torch、flash_attn和triton_flash_attn的实现。这里会介绍所有这些实现,代码位于https://huggingface.co/mosaicml/mpt-7b/blob/main/attention.py。
2.1 三个版本的Self-Attention实现
自注意力机制的原理如下:
Q
=
W
q
X
K
=
W
k
X
V
=
W
v
X
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\begin{align} Q &= W_q X \\ K &= W_k X \\ V &= W_v X \\ \text{Attention}(Q,K,V) &= \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \end{align} \\
QKVAttention(Q,K,V)=WqX=WkX=WvX=softmax(dkQKT)V
其中,
X
X
X是输入,
W
q
W_q
Wq、
W
k
W_k
Wk和
W
v
W_v
Wv分别是query、key、value的投影矩阵。
纯torch版本
def scaled_multihead_dot_product_attention(
query, # [batch_size, seq_length, (head_num*head_dim)]
key, # 在Multi-Head Attention中形状同query,在Multi-Query Attention中head_num=1
value, # 在Multi-Head Attention中形状同query,在Multi-Query Attention中head_num=1
n_heads, # 注意力头的数量
softmax_scale=None, # 注意力分数的缩放因子
attn_bias=None, # 注意力分数的额外偏置项
key_padding_mask=None,
is_causal=False, # 是否为causal,决定了注意力mask的类型
dropout_p=0.0,
multiquery=False, # 是否是Mulit-Query Attention
training=False,
needs_weights=False):
# 通过rearrange函数重塑query、key、value的形状
# 这里的重塑过程同时包括了拆分多头以及调整维度的顺序
q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads)
# 在Mulit-Query Attention中, h=1,也就是多个头共享同一份key和value
k = rearrange(key, 'b s (h d) -> b h d s', h=1 if multiquery else n_heads)
v = rearrange(value, 'b s (h d) -> b h s d', h=1 if multiquery else n_heads)
min_val = torch.finfo(q.dtype).min
# b: batch_size, s_q: seq_length, d: head_dim
(b, _, s_q, d) = q.shape
s_k = k.size(-1)
# 若没有指定softmax的缩放因子,则是默认的因子
if softmax_scale is None:
softmax_scale = 1 / math.sqrt(d)
# 得到未经过softmax规范化的注意力权重
attn_weight = q.matmul(k) * softmax_scale
# 将注意力偏置项添加到注意力分数attn_weight上
if attn_bias is not None:
if attn_bias.size(-1) != 1 and attn_bias.size(-1) != s_k or (attn_bias.size(-2) != 1 and attn_bias.size(-2) != s_q):
raise RuntimeError(f'attn_bias (shape: {attn_bias.shape}) is expected to broadcast to shape: {attn_weight.shape}.')
attn_weight = attn_weight + attn_bias
# 应用key padding mask
if key_padding_mask is not None:
if attn_bias is not None:
warnings.warn('Propogating key_padding_mask to the attention module ' + 'and applying it within the attention module can cause ' + 'unneccessary computation/memory usage. Consider integrating ' + 'into attn_bias once and passing that to each attention ' + 'module instead.')
attn_weight = attn_weight.masked_fill(~key_padding_mask.view((b, 1, 1, s_k)), min_val)
# 是否使用causal mask(关于causal mask可以见文章https://zhuanlan.zhihu.com/p/625911234)
if is_causal:
s = max(s_q, s_k)
# 全1矩阵
causal_mask = attn_weight.new_ones(s, s, dtype=torch.float16)
causal_mask = causal_mask.tril()
causal_mask = causal_mask.to(torch.bool)
causal_mask = ~causal_mask
causal_mask = causal_mask[-s_q:, -s_k:]
attn_weight = attn_weight.masked_fill(causal_mask.view(1, 1, s_q, s_k), min_val)
# softmax
attn_weight = torch.softmax(attn_weight, dim=-1)
# dropout
if dropout_p:
attn_weight = torch.nn.functional.dropout(attn_weight, p=dropout_p, training=training, inplace=True)
out = attn_weight.matmul(v)
out = rearrange(out, 'b h s d -> b s (h d)')
if needs_weights:
return (out, attn_weight)
return (out, None)
FlashAttention
在标准的自注意力计算中,有一些中间计算结果
S
S
S和
P
P
P:
S
=
Q
K
⊤
P
=
Softmax
(
S
)
S=QK^\top \\ P=\text{Softmax}(S) \\
S=QK⊤P=Softmax(S)
这些中间结果需要通过高带宽内存(HBM)进行存取,FlashAttention主要是通过减少对HBM的访问次数来优化速度。这里不展开介绍该技术的实现,其通过调用包flash_attn即可实现,在MPT的代码中对其进行了简单的封装flash_attn_fn。
TritonFlashAttention
使用Triton实现的FlashAttention,也可以通过调用flash_attn来实现,在MPT代码中封装为triton_flash_attn_fn。
2.2 多头注意力
多头注意力就是将多个自注意力的结果合并,如下:
head
i
=
Attention
(
Q
i
,
K
i
,
V
i
,
A
i
)
MultiHead
(
Q
,
K
,
V
,
A
)
=
Concat
(
head
1
,
…
,
head
h
)
W
o
\begin{align} \text{head}_i&=\text{Attention}(Q_i,K_i,V_i,A_i) \\ \text{MultiHead}(Q,K,V,A)&=\text{Concat}(\text{head}_1,\dots,\text{head}_h)W_o \end{align} \\
headiMultiHead(Q,K,V,A)=Attention(Qi,Ki,Vi,Ai)=Concat(head1,…,headh)Wo
class MultiheadAttention(nn.Module):
def __init__(self, d_model: int, n_heads: int, attn_impl: str='triton', clip_qkv: Optional[float]=None, qk_ln: bool=False, softmax_scale: Optional[float]=None, attn_pdrop: float=0.0, low_precision_layernorm: bool=False, device: Optional[str]=None):
super().__init__()
self.attn_impl = attn_impl #注意力的实现方式
self.clip_qkv = clip_qkv # query、key、value是否进行clip
self.qk_ln = qk_ln # 是否对query和key进行LayerNorm
self.d_model = d_model
self.n_heads = n_heads # 注意力头的数量
self.softmax_scale = softmax_scale # softmax缩放因子
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)
self.attn_dropout_p = attn_pdrop
# 投影层
self.Wqkv = nn.Linear(self.d_model, 3 * self.d_model, device=device)
fuse_splits = (d_model, 2 * d_model)
self.Wqkv._fused = (0, fuse_splits)
if self.qk_ln:
# 初始化query和key的LayerNorm
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(self.d_model, device=device)
self.k_ln = layernorm_class(self.d_model, device=device)
if self.attn_impl == 'flash':
self.attn_fn = flash_attn_fn
elif self.attn_impl == 'triton':
self.attn_fn = triton_flash_attn_fn
elif self.attn_impl == 'torch':
self.attn_fn = scaled_multihead_dot_product_attention
else:
raise ValueError(f'attn_impl={attn_impl!r} is an invalid setting.')
# 输出投影层
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True
def forward(self, x, past_key_value=None, attn_bias=None, attention_mask=None, is_causal=True, needs_weights=False):
# 投影获得query、key、value
qkv = self.Wqkv(x)
# 对query、key和value进行clip(MPT并没有使用该选项)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
# 将query、key和value中qkv中拆分出来
(query, key, value) = qkv.chunk(3, dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
# 对query和key进行LayerNorm(MPT并没有使用该选项)
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
# 推理时,会将前面token的key和value传递过来,这里进行合并
if past_key_value is not None:
if len(past_key_value) != 0:
key = torch.cat([past_key_value[0], key], dim=1)
value = torch.cat([past_key_value[1], value], dim=1)
past_key_value = (key, value)
if attn_bias is not None:
attn_bias = attn_bias[:, :, -query.size(1):, -key.size(1):]
# 执行自注意力
(context, attn_weights) = self.attn_fn(query, key, value, self.n_heads, softmax_scale=self.softmax_scale, attn_bias=attn_bias, key_padding_mask=key_padding_mask, is_causal=is_causal, dropout_p=self.attn_dropout_p, training=self.training, needs_weights=needs_weights)
return (self.out_proj(context), attn_weights, past_key_value)
2.3 多Query注意力
在多头注意力中,每个头都有自己独立的query、key和value。多Query注意力中,各个头之间共享key和value。所以,多Query注意力的参数量要比多头注意力少。多Query注意力和多头注意力的实现非常类似,仅有少量的不同,这里仅展示代码中不同的部分:
class MultiQueryAttention(nn.Module):
def __init__(self, d_model: int, n_heads: int, attn_impl: str='triton', clip_qkv: Optional[float]=None, qk_ln: bool=False, softmax_scale: Optional[float]=None, attn_pdrop: float=0.0, low_precision_layernorm: bool=False, device: Optional[str]=None):
super().__init__()
...
# 计算每个头的维度
self.head_dim = d_model // n_heads
...
# 投影层与多头注意力具有明显区别,多头注意力的输出维度为3*d_model,而这里是d_model + 2*head_dim
self.Wqkv = nn.Linear(d_model, d_model + 2 * self.head_dim, device=device)
...
3. 位置偏差ALiBi
MPT使用ALiBi的方式向模型注入位置信息。ALiBi注入位置信息的方式是在注意力分数矩阵添加一个偏差(bias)来实现的。具体来说,给定一个长度为L的输入序列, 那么每个注意力头的第i个query q i ∈ R 1 × d ( 1 ≤ i ≤ L ) \textbf{q}_i\in\mathbb{R}^{1\times d}(1\leq i\leq L) qi∈R1×d(1≤i≤L)针对前i个key K ∈ R i × d \textbf{K}\in\mathbb{R}^{i\times d} K∈Ri×d的注意力分数为
softmax
(
q
i
K
⊤
)
\text{softmax}(\textbf{q}_i\textbf{K}^\top) \\
softmax(qiK⊤)
在使用ALiBi时,不需要向网络添加位置嵌入。仅需要在query-key点积中添加静态偏差即可。
softmax
(
q
i
K
⊤
+
m
⋅
[
−
(
i
−
1
)
,
…
,
−
2
,
−
1
,
0
]
)
\text{softmax}(\textbf{q}_i\textbf{K}^\top+m\cdot[-(i-1),\dots,-2,-1,0]) \\
softmax(qiK⊤+m⋅[−(i−1),…,−2,−1,0])
其中m是与注意力头相关的斜率(slope),也就是超参;
[
−
(
i
−
1
)
,
…
,
−
2
,
−
1
,
0
]
[-(i-1),\dots,-2,-1,0]
[−(i−1),…,−2,−1,0]其实就是
q
i
\textbf{q}_i
qi与各个key的相对距离。
对于8个注意力头,m是等比序列: 1 2 1 , 1 2 2 , … , 1 2 8 \frac{1}{2^1},\frac{1}{2^2},\dots,\frac{1}{2^8} 211,221,…,281。对于16个注意力头的模型,m则是等比序列: 1 2 0.5 , 1 2 1 , 1 2 1.5 , … , 1 2 8 \frac{1}{2^{0.5}},\frac{1}{2^1},\frac{1}{2^{1.5}},\dots,\frac{1}{2^8} 20.51,211,21.51,…,281。
def gen_slopes(n_heads, alibi_bias_max=8, device=None):
"""
计算斜率
"""
# _n_heads是与n_heads接近的2的次数,例如:n_heads为5/6/7时,_n_heads为8
_n_heads = 2 ** math.ceil(math.log2(n_heads))
m = torch.arange(1, _n_heads + 1, dtype=torch.float32, device=device)
# m是alibi_bias_max/_n_heads到alibi_bias_max的等差数列
m = m.mul(alibi_bias_max / _n_heads)
# 计算斜率
slopes = 1.0 / torch.pow(2, m)
if _n_heads != n_heads:
slopes = torch.concat([slopes[1::2], slopes[::2]])[:n_heads]
return slopes.view(1, n_heads, 1, 1)
def build_alibi_bias(n_heads, seq_len, full=False, alibi_bias_max=8, device=None, dtype=None):
"""
构建alibi注意力偏差
"""
alibi_bias = torch.arange(1 - seq_len, 1, dtype=torch.int32, device=device).view(1, 1, 1, seq_len)
if full:
alibi_bias = alibi_bias - torch.arange(1 - seq_len, 1, dtype=torch.int32, device=device).view(1, 1, seq_len, 1)
alibi_bias = alibi_bias.abs().mul(-1)
slopes = gen_slopes(n_heads, alibi_bias_max, device=device)
alibi_bias = alibi_bias * slopes
return alibi_bias.to(dtype=dtype)
def build_attn_bias(attn_impl, attn_bias, n_heads, seq_len, causal=False, alibi=False, alibi_bias_max=8):
"""
该函数只是对`build_alibi_bias`进行了封装,由于flash版本的注意力不支持attn_bias所以返回none
"""
if attn_impl == 'flash':
return None
elif attn_impl in ['torch', 'triton']:
if alibi:
(device, dtype) = (attn_bias.device, attn_bias.dtype)
attn_bias = attn_bias.add(build_alibi_bias(n_heads, seq_len, full=not causal, alibi_bias_max=alibi_bias_max, device=device, dtype=dtype))
return attn_bias
else:
raise ValueError(f'attn_impl={attn_impl!r} is an invalid setting.')
4. MLP层
MLP ( X ) = GELU ( X W 1 ) W 2 \text{MLP}(X) = \text{GELU}(XW_1)W_2 \\ MLP(X)=GELU(XW1)W2
class MPTMLP(nn.Module):
def __init__(self, d_model: int, expansion_ratio: int, device: Optional[str]=None):
super().__init__()
self.up_proj = nn.Linear(d_model, expansion_ratio * d_model, device=device)
self.act = nn.GELU(approximate='none')
self.down_proj = nn.Linear(expansion_ratio * d_model, d_model, device=device)
self.down_proj._is_residual = True
def forward(self, x):
return self.down_proj(self.act(self.up_proj(x)))
5. MPTBlock层
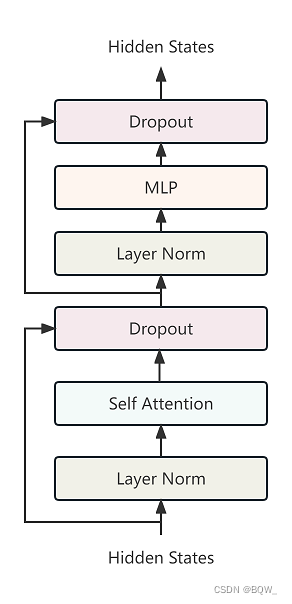
class MPTBlock(nn.Module):
def __init__(self, d_model: int, n_heads: int, expansion_ratio: int, attn_config: Dict={'attn_type': 'multihead_attention', 'attn_pdrop': 0.0, 'attn_impl': 'triton', 'qk_ln': False, 'clip_qkv': None, 'softmax_scale': None, 'prefix_lm': False, 'attn_uses_sequence_id': False, 'alibi': False, 'alibi_bias_max': 8}, resid_pdrop: float=0.0, norm_type: str='low_precision_layernorm', device: Optional[str]=None, **kwargs):
del kwargs
super().__init__()
# LayerNorm的类别
norm_class = NORM_CLASS_REGISTRY[norm_type.lower()]
# 注意力的类别
attn_class = ATTN_CLASS_REGISTRY[attn_config['attn_type']]
# LayerNorm
self.norm_1 = norm_class(d_model, device=device)
# 注意力
self.attn = attn_class(attn_impl=attn_config['attn_impl'], clip_qkv=attn_config['clip_qkv'], qk_ln=attn_config['qk_ln'], softmax_scale=attn_config['softmax_scale'], attn_pdrop=attn_config['attn_pdrop'], d_model=d_model, n_heads=n_heads, device=device)
# LayerNorm
self.norm_2 = norm_class(d_model, device=device)
# MLP层
self.ffn = MPTMLP(d_model=d_model, expansion_ratio=expansion_ratio, device=device)
self.resid_attn_dropout = nn.Dropout(resid_pdrop)
self.resid_ffn_dropout = nn.Dropout(resid_pdrop)
def forward(self, x: torch.Tensor, past_key_value: Optional[Tuple[torch.Tensor]]=None, attn_bias: Optional[torch.Tensor]=None, attention_mask: Optional[torch.ByteTensor]=None, is_causal: bool=True) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor]]]:
a = self.norm_1(x)
(b, _, past_key_value) = self.attn(a, past_key_value=past_key_value, attn_bias=attn_bias, attention_mask=attention_mask, is_causal=is_causal)
x = x + self.resid_attn_dropout(b)
m = self.norm_2(x)
n = self.ffn(m)
x = x + self.resid_ffn_dropout(n)
return (x, past_key_value)
6. MPTModel
MPTModel的代码比较多,这里就不贴完整代码了,介绍一下主要的结构和值得关注的点。
Shrink Embedding Gradient
Shrink Embedding Gradient技术来自于GLM-130B,用于稳定预训练,防止出现loss峰值。MPT在代码中也支持该技术,但并没有使用
# 当self.embedding_fraction小于1时,执行该段代码
# x接收到的梯度缩减为self.embedding_fraction
x_shrunk = x * self.embedding_fraction + x.detach() * (1 - self.embedding_fraction)
assert isinstance(self.emb_drop, nn.Module)
# embedding dropout
x = self.emb_drop(x_shrunk)
模型结构相关的代码
# embedding
tok_emb = self.wte(input_ids)
x = tok_emb
# embedding dropout
x = self.emb_drop(x)
# 计算alibi的注意力偏差
(attn_bias, attention_mask) = self._attn_bias(device=x.device, dtype=x.dtype, attention_mask=attention_mask, prefix_mask=prefix_mask, sequence_id=sequence_i)
# 多个block的前向传播
for (b_idx, block) in enumerate(self.blocks):
past_key_value = past_key_values[b_idx] if past_key_values is not None else None
(x, past_key_value) = block(x, past_key_value=past_key_value, attn_bias=attn_bias, attention_mask=attention_mask, is_causal=self.is_causal)
if past_key_values is not None:
past_key_values[b_idx] = past_key_value
# 最后的输出进行LayerNorm
x = self.norm_f(x)
参考资料
https://www.mosaicml.com/blog/mpt-7b#training-stability
https://huggingface.co/mosaicml/mpt-7b/tree/main



![linux、windows的pip一键永久换源[清华源、中科大、豆瓣、阿里云]](https://img-blog.csdnimg.cn/dc521cdc2bb245dcb71e670bff0b206f.png)