深度学习自然语言处理 原创
作者:Winnie
“幻觉”问题即模型生成的内容可能包含虚构的信息。它不仅在大语言模型(LLMs)中存在,也存在于图像、视频和音频等其他一系列基础模型中。
针对这一问题,一篇最近的综述论文对目前所有基础模型的“幻觉”问题进行了第一次全面的调查,详细分类了各类基础模型中的幻觉现象,审视了现有的减轻幻觉问题的策略,并提出了一套用于评估幻觉程度的标准。

Paper: A Survey of Hallucination in “Large” Foundation Models
Link: https://arxiv.org/pdf/2309.05922.pdf
注:本篇解读仅对部分文献进行总结,更多细节请进一步阅读原论文综述。
进NLP群—>加入NLP交流群
前言
基础模型Foundation Models(FMs)是通过自监督学习方法,在大量未标签数据上训练得来的AI模型。这些模型不仅可以在图像分类、自然语言处理和问答等多个领域中提供高精度的表现,还可以处理涉及创作和人际互动的任务,比如制作营销内容或根据简短提示创作复杂艺术品。
虽然基础模型非常强大,但在将其适配到企业应用时也会遇到一系列的挑战,其中一个重要的问题就是“幻觉”现象。“幻觉”现象是指模型生成包含虚假信息或完全捏造的细节。这主要是因为模型根据训练数据中学到的模式来创造看似合理的内容,即便这样的内容与真实情况相去甚远。
这种“幻觉”现象可能是无意中产生的,它可以由多种因素导致,包括训练数据集中存在的偏见、模型不能获取最新的信息,或是其在理解和生成准确回应时的固有限制。为了确保我们可以安全、有效地利用基础模型,特别是在新闻、医疗和法律等需要事实准确的领域,我们必须认真对待和解决“幻觉”问题。目前,研究人员正在努力探索各种方式来减少“幻觉”现象,从而提高模型的可靠性和信任度。
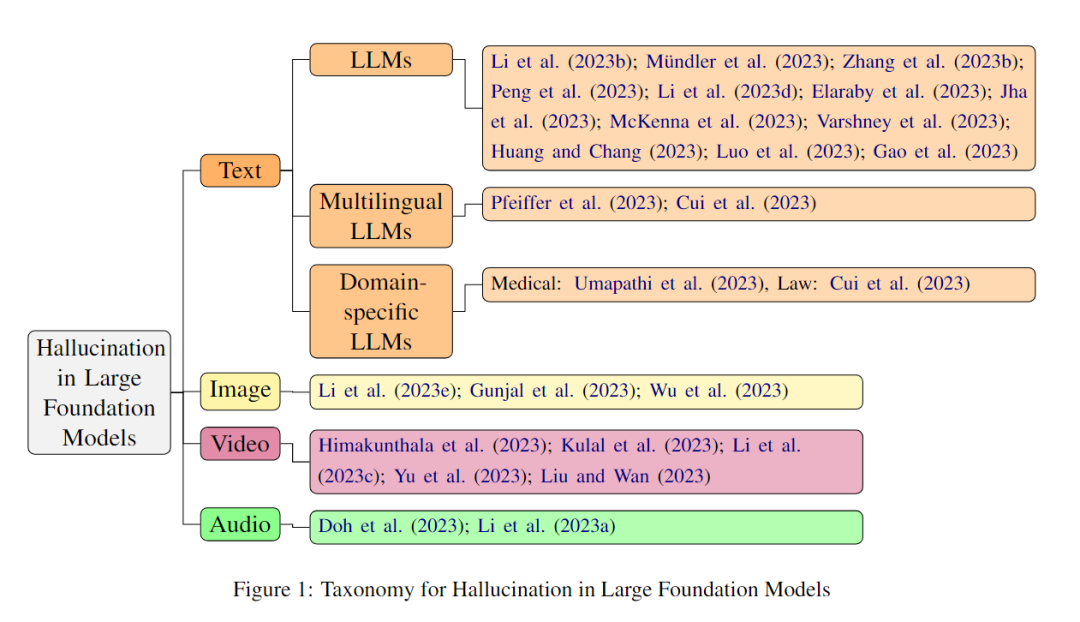
下图展示了本篇综述的一个基本框架,主要从文本、图片、音频和语音等领域来总结目前的研究。其中,文本又可以进一步细分为LLMs,多语言LLMs和特定领域的LLMs(如新闻、医疗等领域)。
LLM的幻觉问题
幻觉检测和修正方法
SELFCHECKGPT [1] 是一个用于监控和纠正LLMs中的“幻觉”现象的工具,它能够识别模型生成的不准确或未验证的信息,无需额外资源或标记数据。这种方法能够在没有外部指南或数据集的情况下提高LLMs的可靠性和可信度。
PURR [2] 则专注于编辑和纠正语言模型中的误导信息,它通过利用去噪语言模型的损坏来识别和修正幻觉,目的是提升模型输出的质量和准确性。
幻觉检测数据集
幻觉问题通常和知识缺口有关。但研究 [3] 提出,有时模型会尝试合理化之前生成的错误信息,从而产生更多的误导内容。为了深入研究这一现象,这项研究创建了三个问答数据集来收集模型产生错误答案和附带虚假断言的实例。
HaluEval [4] 提供了一个综合基准来评估LLMs中的幻觉问题,帮助研究人员和开发人员更好地理解和提高模型的可靠性。
利用外部知识来缓解幻觉问题
为了减轻LLM的幻觉问题,研究人员正在探索如何利用外部知识来提高模型的输出质量和准确性。其中,[5] 提出了一种交互式问题-知识对齐方法,侧重于将生成的文本与相关的事实知识对齐,使用户能够交互式地指导模型的回答,以产生更准确和可靠的信息。类似地,[6] 提出了LLMAUGMENTER方法,结合外部知识来源和自动化反馈机制来提高LLM输出的准确性和可靠性。而 [7] 提出了“知识链”框架来链接LLMs和结构化知识库。
此外,相比于其更大的对应体,小型开源LLMs通常会遇到更严重的幻觉问题。为了解决这个问题,[8] 提出了一系列方法来评估和减轻BLOOM 7B这类弱小型开源LLMs的幻觉问题。
采用prompting来缓解幻觉问题
也有研究致力于通过prompting来减少LLMs生成的不准确或幻觉信息。[9] 在2023年提出了一种由迭代提示指导的方法来去除LLMs的幻觉,提高输出的准确性和可靠性。
多语言LLM的幻觉问题
大型多语言机器翻译系统在直接翻译多种语言方面展示了令人印象深刻的能力。但是,这些模型可能会产生“幻觉翻译”,在部署时会引发信任和安全问题。目前关于幻觉的研究主要集中在小型双语模型和高资源语言上,这留下了一个空白:在多种翻译场景中大规模多语言模型的幻觉理解。
为了解决这个问题,[10] 对传统的神经机器翻译模型的M2M家族和ChatGPT进行了全面的分析,后者可以用于提示翻译。这项调查涵盖了广泛的语言背景,包括100多个翻译方向。
特定领域LLM的幻觉问题
在诸如医学、银行、金融、法律等关键领域中,可靠性和准确性是至关重要的,任何形式的幻觉都可能对结果和操作产生重大和有害的影响。
医学: LLMs中的幻觉问题,特别是在医学领域,生成看似合理但不准确的信息可能是有害的。为了解决这个问题,[11] 引入了一个名为Med-HALT(医学领域幻觉测试)的新基准和数据集。它专门设计用于评估和减轻LLMs中的幻觉。它包括来自不同国家的医学检查的多元化的多国数据集,并包括创新的测试方法。Med-HALT包括两类测试:基于推理和基于记忆的幻觉测试,旨在评估LLMs在医学背景下的问题解决和信息检索能力。
法律: ChatLaw [12]是一个专门用于法律领域的开源LLM。为了确保高质量的数据,作者们创建了一个精心设计的法律领域微调数据集。为了解决法律数据筛选过程中模型幻觉的问题,他们提出了一种将矢量数据库检索与关键字检索相结合的方法。这种方法有效地减少了在法律背景下仅依赖矢量数据库检索来检索参考数据时可能出现的不准确性。
大图像模型中的幻觉问题
对比学习模型利用Siamese结构在自监督学习中展示了令人印象深刻的表现。它们的成功依赖于两个关键条件:存在足够数量的正样本对,并在它们之间存在充足的变化。如果不满足这些条件,这些框架可能缺乏有意义的语义区别并容易过拟合。为了解决这些挑战,[13] 引入了Hallucinator,它可以高效地生成额外的正样本来增强对比。Hallucinator是可微分的,在特征空间中运作,使其适合直接在预训练任务中进行优化,同时带来最小的计算开销。
受LLMs的启发,为复杂的多模态任务加强LVLMs面临一个重大的挑战:对象幻觉,其中LVLMs在描述中生成不一致的对象。[14] 系统地研究了指令调整的大视觉语言模型(LVLMs)中的对象幻觉问题,并发现这是一个常见问题。视觉指令,特别是经常出现或共同出现的对象,影响了这个问题。现有的评估方法也受到输入指令和LVLM生成样式的影响。为了解决这个问题,该研究引入了一种改进的评估方法,称为POPE,为LVLMs中的对象幻觉提供了更稳定和灵活的评估。
LVLMs在处理各种多模态任务方面取得了重大进展,包括视觉问题回答(VQA)。然而,为这些模型生成详细和视觉上准确的回答仍然是一个挑战。即使是最先进的LVLMs,如InstructBLIP,也存在高幻觉文本率,包括30%的不存在的对象、不准确的描述和错误的关系。为了解决这个问题,[15] 引入了MHalDetect1,这是一个多模态幻觉检测数据集,专为训练和评估旨在检测和预防幻觉的模型而设计。MHalDetect包含16000个关于VQA示例的精细详细注释,使其成为检测详细图像描述中幻觉的首个全面数据集。
大视频模型中的幻觉问题
幻觉可能发生在模型对视频帧做出错误或富有想象的假设时,导致产生人工或错误的视觉信息,如下图所示。

一个解决方法是通过一种能够生动地将人插入场景的方法来理解场景可供性的挑战。[16] 使用标有区域的场景图像和一个人的图像,该模型无缝地将人集成到场景中,同时考虑场景的特点。该模型能够根据场景环境推断出现实的姿势,相应地调整人的姿势,并确保视觉上令人愉悦的构图。自我监督训练使模型能够在尊重场景环境的同时生成各种可能的姿势。此外,该模型还可以自行生成逼真的人和场景,允许进行交互式编辑。
VideoChat [17] 是一个全面的系统,采用面向聊天的方法来理解视频。VideoChat将基础视频模型与LLMs结合,使用一个可适应的神经界面,展示出在理解空间、时间、事件定位和推断因果关系方面的卓越能力。为了有效地微调这个系统,他们引入了一个专门为基于视频的指导设计的数据集,包括成千上万的与详细描述和对话配对的视频。这个数据集强调了时空推理和因果关系等技能,使其成为训练面向聊天的视频理解系统的有价值的资源。
最近在视频修复方面取得了显著的进步,特别是在光流这样的显式指导可以帮助将缺失的像素传播到各个帧的情况下。然而,当跨帧信息缺失时,就会出现挑战。因此,模型集中解决逆向问题,而不是从其他帧借用像素。[18] 引入了一个双模态兼容的修复框架,称为Deficiency-aware Masked Transformer(DMT)。预训练一个图像修复模型来作为训练视频模型的先验有一个优点,可以改善处理信息不足的情况。
视频字幕的目标是使用自然语言来描述视频事件,但它经常引入事实错误,降低了文本质量。尽管在文本到文本的任务中已经广泛研究了事实一致性,但在基于视觉的文本生成中却受到了较少的关注。[19] 对视频字幕中的事实进行了详细的人类评估,揭示了57.0%的模型生成的句子包含事实错误。现有的评估指标主要基于n-gram匹配,与人类评估不太一致。为了解决这个问题,他们引入了一个基于模型的事实度量称为FactVC,它在评估视频字幕中的事实度方面优于之前的指标。
大型音频模型中的幻觉
自动音乐字幕,即为音乐曲目生成文本描述,有可能增强对庞大音乐数据的组织。现有音乐语言数据集的大小有限,收集过程昂贵。为了解决这种稀缺,[20] 使用了LLMs从广泛的标签数据集生成描述。他们创建了一个名为LP-MusicCaps的数据集,包含约220万个与50万个音频剪辑配对的字幕。他们还使用各种量化自然语言处理指标和人类评估对这个大规模音乐字幕数据集进行了全面评估。他们在这个数据集上训练了一个基于变换器的音乐字幕模型,并在零射击和迁移学习场景中评估了其性能。
理想情况下,视频应该增强音频,[21]使用了一个先进的语言模型进行数据扩充,而不需要人工标注。此外,他们利用音频编码模型有效地适应了一个预训练的文本到图像生成模型,用于文本到音频生成。
幻觉并非总是有害
从一个不同的角度来看,[22]讨论了幻觉模型如何可以提供创意,提供可能不完全基于事实但仍然提供有价值线索来探索的输出。创意地利用幻觉可以带来不容易被大多数人想到的结果或新奇的创意组合。“幻觉”变得有害是当生成的陈述事实上不准确或违反普遍的人类、社会或特定文化规范时。这在一个人依赖LLM来提供专家知识的情况下尤其关键。然而,在需要创意或艺术的背景下,产生不可预见结果的能力可能相当有利。对查询的意外响应可以惊喜人类并激发发现新奇想法联系的可能性。
结论与未来方向
这篇综述对现有关于基础模型内部的幻觉问题进行了简单的分类和分析,研究涵盖了幻觉检测,缓解,数据集,以及评估标准。以下是一些可能的未来研究方向。
对幻觉的自动评估
幻觉指的是AI模型生成的不正确或捏造的信息。在像文本生成这样的应用中,这可能是一个重大的问题,因为目标是提供准确和可靠的信息。以下是对错觉自动评估的潜在未来方向:
评估指标的开发: 研究者可以努力创建能够检测生成内容中的幻觉的专门的评估指标。这些指标可能会考虑事实的准确性、连贯性和一致性。可以训练高级机器学习模型根据这些指标评估生成的文本。
人工智能合作: 将人类判断与自动评估系统结合是一个有前景的方向。众包平台可以用来收集人类对AI生成内容的评估,然后用于训练自动评估的模型。这种混合方法可以帮助捕捉对自动系统来说具有挑战性的细微差别。
对抗性测试: 研究者可以开发对抗性测试方法,其中AI系统被暴露于专门设计的输入,以触发幻觉。这有助于识别AI模型的弱点并提高其抵抗错觉的鲁棒性。
微调策略: 特别为减少幻觉而微调预训练的语言模型是另一个潜在的方向。模型可以在强调事实检查和准确性的数据集上进行微调,以鼓励生成更可靠的内容。
改进检测和缓解幻觉的策略
检测和缓解AI生成文本中的偏见、错误信息和低质量内容对于负责任的AI开发至关重要。策划的知识来源在实现这一目标中可以起到重要作用。以下是一些未来的方向:
知识图谱集成: 将知识图谱和策划的知识库集成到AI模型中可以增强它们对事实信息和概念之间关系的理解。这既可以帮助生成内容,也可以帮助事实检查。
事实检查和验证模型: 开发专门的模型,专注于事实检查和内容验证。这些模型可以使用策划的知识来源来交叉引用生成的内容,识别不准确或不一致之处。
偏见检测和缓解: 策划的知识来源可以用来训练AI模型识别和减少生成内容中的偏见。AI系统可以被编程来检查内容是否存在潜在的偏见,并提议更加平衡的替代方案。
主动学习: 通过主动学习不断更新和完善策划的知识来源。AI系统可以被设计为寻求人类对模糊或新信息的输入和验证,从而提高策划知识的质量。
道德指导和监管: 未来的方向还可能包括为AI开发中使用外部知识来源制定道德指南和监管框架。这可以确保负责任和透明地使用策划知识来缓解潜在风险。
进NLP群—>加入NLP交流群
参考文献
[1]MANAKUL P, LIUSIE A, GALES MarkJ F. SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models[J]. 2023.
[2]Anthony Chen, Panupong Pasupat, Sameer Singh, Hongrae Lee, and Kelvin Guu. 2023. Purr: Efficiently editing language model hallucinations by denoising language model corruptions.
[3]ZHANG M, PRESS O, MERRILL W, et al. How Language Model Hallucinations Can Snowball[J]. 2023.
[4]LI J, CHENG X, ZHAO W, et al. HELMA: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models[J].
[5]ZHANG S, PAN L, ZHAO J, et al. Mitigating Language Model Hallucination with Interactive Question-Knowledge Alignment[J].
[6]PENG B, GALLEY M, HE P, et al. Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback *[J].
[7]Xingxuan Li, Ruochen Zhao, Yew Ken Chia, Bosheng Ding, Lidong Bing, Shafiq Joty, and Soujanya Poria. 2023d. Chain of knowledge: A framework for grounding large language models with structured knowledge bases. arXiv preprint arXiv:2305.13269.
[8]Mohamed Elaraby, Mengyin Lu, Jacob Dunn, Xueying Zhang, Yu Wang, and Shizhu Liu. 2023. Halo: Estimation and reduction of hallucinations in opensource weak large language models. arXiv preprint arXiv:2308.11764.
[9]JHA S, KUMAR S, LINCOLN P, et al. Dehallucinating Large Language Models Using Formal Methods Guided Iterative Prompting[J].
[10]Jonas Pfeiffer, Francesco Piccinno, Massimo Nicosia, Xinyi Wang, Machel Reid, and Sebastian Ruder. 2023. mmt5: Modular multilingual pre-training solves source language hallucinations.
[11]Logesh Kumar Umapathi, Ankit Pal, and Malaikannan Sankarasubbu. 2023. Med-halt: Medical domain hallucination test for large language models. arXiv preprint arXiv:2307.15343.
[12]Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. 2023. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv:2306.16092.
[13]Jing Wu, Jennifer Hobbs, and Naira Hovakimyan. 2023. Hallucination improves the performance of unsupervised visual representation learning. arXiv preprint arXiv:2307.12168.
[14]LI Y, DU Y, ZHOU K, et al. Evaluating Object Hallucination in Large Vision-Language Models[J].
[15]Detecting and Preventing Hallucinations in Large Vision Language Models[J]. 2023.
[16]KULAL S, BROOKS T, AIKEN A, et al. Putting People in Their Place: Affordance-Aware Human Insertion into Scenes[J].
[17] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2023c. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355.
[18] Yongsheng Yu, Heng Fan, and Libo Zhang. 2023. Deficiency-aware masked transformer for video inpainting. arXiv preprint arXiv:2307.08629.
[19]Hui Liu and Xiaojun Wan. 2023. Models see hallucinations: Evaluating the factuality in video captioning.arXiv preprint arXiv:2303.02961.
[20]SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. 2023. Lp-musiccaps: Llm-based pseudo music captioning. arXiv preprint arXiv:2307.16372.
[21]Juncheng B Li, Jackson Sam Michaels, Laura Yao, Lijun Yu, Zach Wood-Doughty, and Florian Metze. 2023a. Audio-journey: Efficient visual+ llm-aided audio encodec diffusion. In Workshop on Efficient Systems for Foundation Models@ ICML2023.
[22]Kyle Wiggers. 2023. Are ai models doomed to always hallucinate?*
![linux、windows的pip一键永久换源[清华源、中科大、豆瓣、阿里云]](https://img-blog.csdnimg.cn/dc521cdc2bb245dcb71e670bff0b206f.png)