文章目录
- uptime 的命令解释
- uptime
- 平均负载的理解
- man uptime
- 平均负载的合理值
- 系统负载的趋势
- 案例分析
- CPU 密集型程序
- IO 密集型
- 大量进程
学习笔记主要来源:Linux性能优化实战_Linux_性能调优-极客时间
uptime 的命令解释
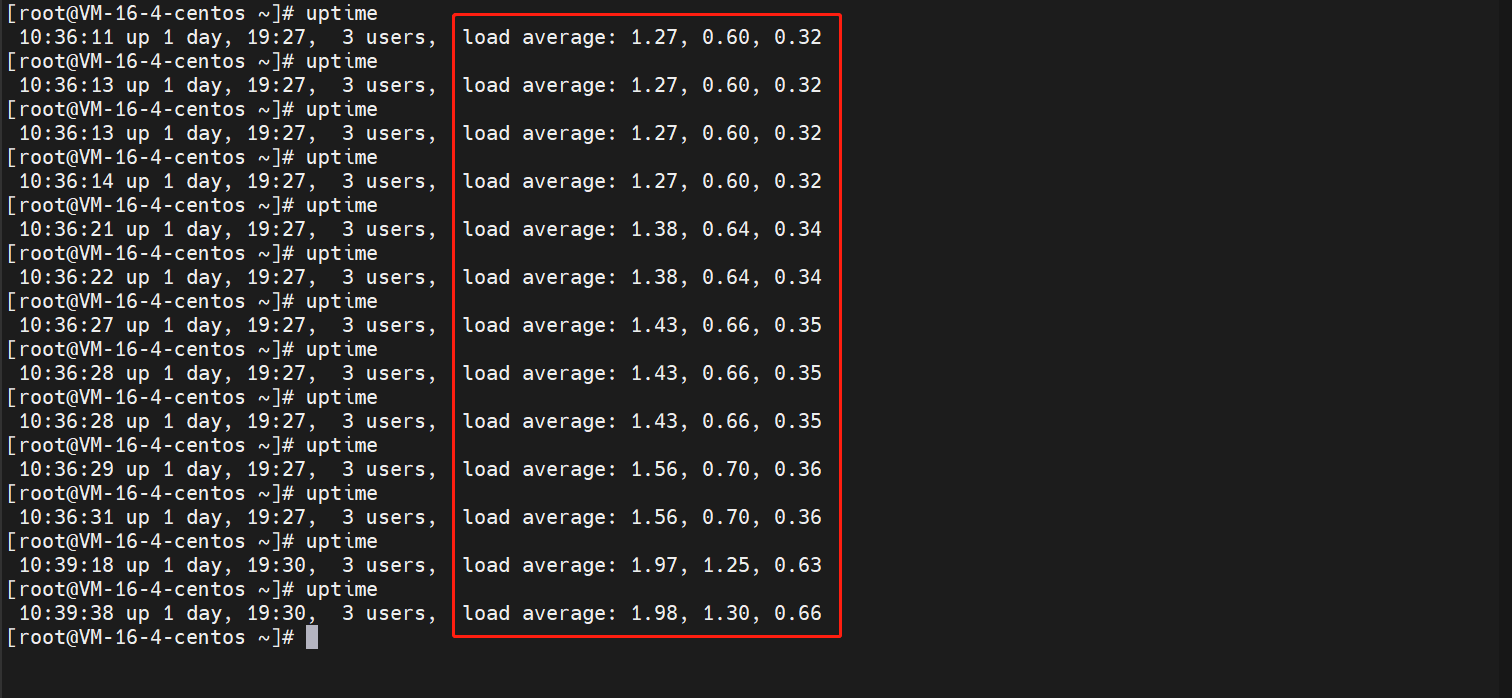
uptime

09:17:52系统当前时间up 1 day, 18:09系统运行了多长时间1 user当前登陆在线的用户数load average: 0.00, 0.01, 0.05过去1分钟、5分钟、15分钟的平均负载
平均负载的理解
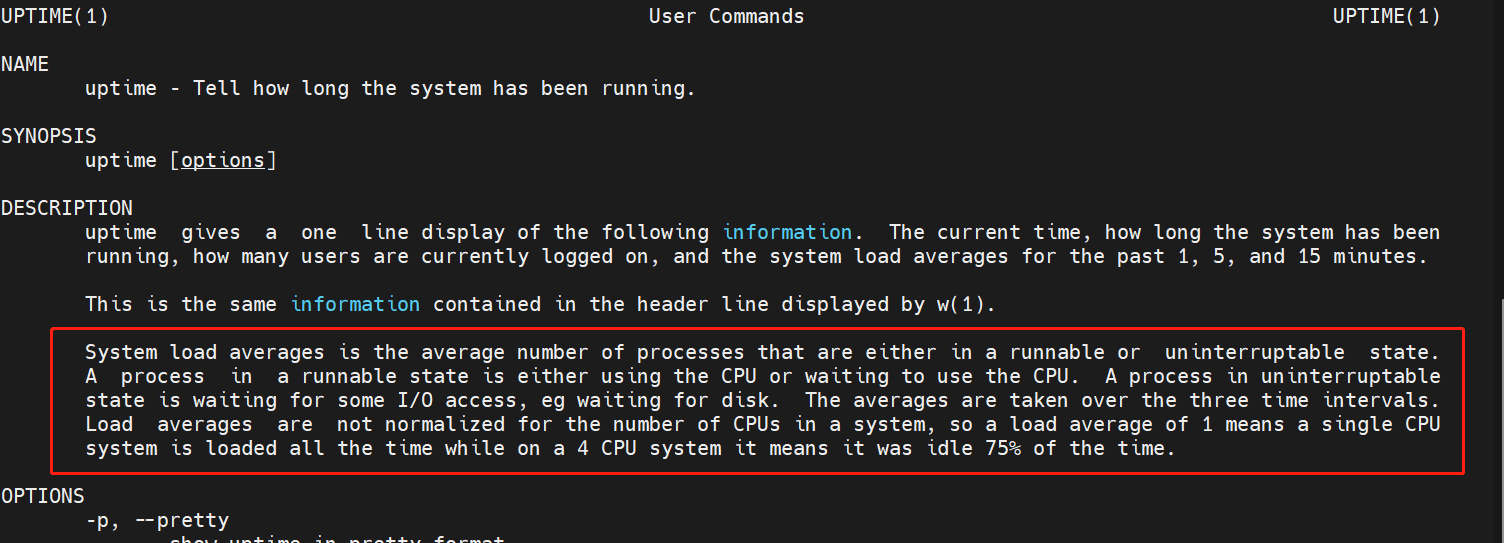
man uptime
System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk. The averages are taken over the three time intervals. Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time
平均负载并不是单位时间内的CPU使用率- 平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,意思就是平均活跃进程数
- 处于可运行状态的进程肯定是正在使用CPU或等待使用CPU的
- 不可中断状态是等待一些 I/O 访问,比如进程需要向磁盘读写数据,为了保证数据的一致性,在得到磁盘的确切的回复前,它是不能被其他进程或者中断打断的,这也是系统对进程和硬件设备的一种保护机制
- 在1个CPU的系统上,如果平均负载为1,那就说明这1个CPU刚好被完全占用
- 在2个CPU的系统上,如果平均负载为1,那就说明这2个CPU中有1个CPU处于空闲时间
平均负载的合理值
- 平均负载最理想的情况就是等于 CPU 的核心数
# 查看服务器的CPU核心数
lscpu | awk '/^CPU\(s\)/ {print $2}'
- 如果平均负载比CPU核心数还要大的时候,就说明系统处于超负荷的状态了
- 对于大多数情况,我们一般要看整个监控阶段的趋势图,结合历史数据,来判断业务系统是否正常,如果没有历史数据,我们对当前能看到的数据而言,如果负载值高于 CPU 数量的70%,就得具体分析一下,可能就会引起进程响应变慢、业务系统访问变慢等异常情况
系统负载的趋势
uptime 命令所展示的平均负载分别为过去的1分钟、5分钟、15分钟的负载值,从这几个趋势值就可以的出来
- 三个值基本相同,相差不大,就说明系统负载很稳定
- 如果1分钟的值远远小于15分钟,说明负载在减少,过去15分钟的负载更大一点
- 如果1分钟的值远远大于15分钟,说明负载在增加,过去1分钟的负载更大一点
- 值接近或者超过了 CPU 个数,说明系统已经超负载运行了,就得优化处理了
案例分析
服务器准备:stress(压力测试工具)、sysstat包(包含了Linux性能工具)
CPU 密集型程序
- 使用命令模拟2个CPU使用率100%的场景
stress --cpu 2 --timeout 600
- 查看使用情况

- 查看一个负载的趋势图:因为我是4核,2个CPU跑满的程序下,负载值就会趋近于2左右
IO 密集型
- 模拟 IO 压力
stress -i 2 --timeout 600
- 查看一下负载值的历史趋势(因为我是接着上面操作的,所以5分钟核15分钟的值会有影响,我们只看1分钟的)
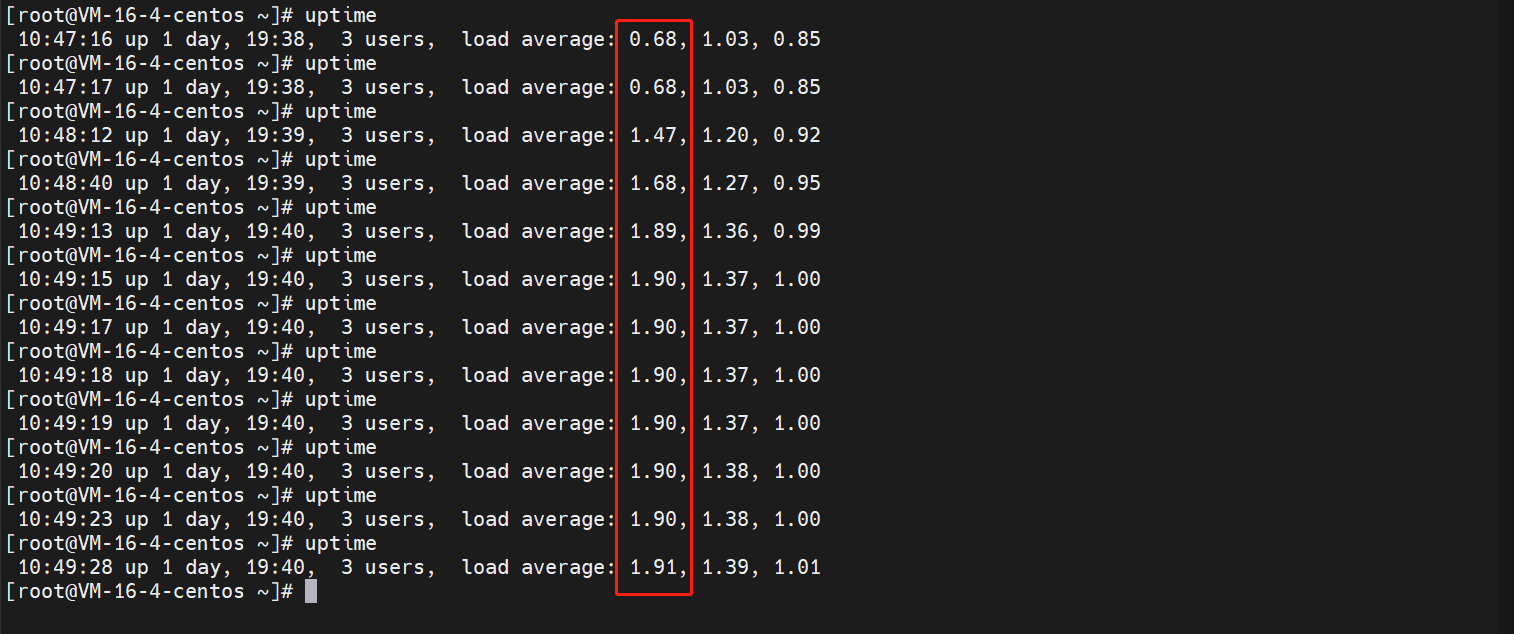
- 使用
mpstat -P ALL 1查看每个 CPU 繁忙情况

- 使用
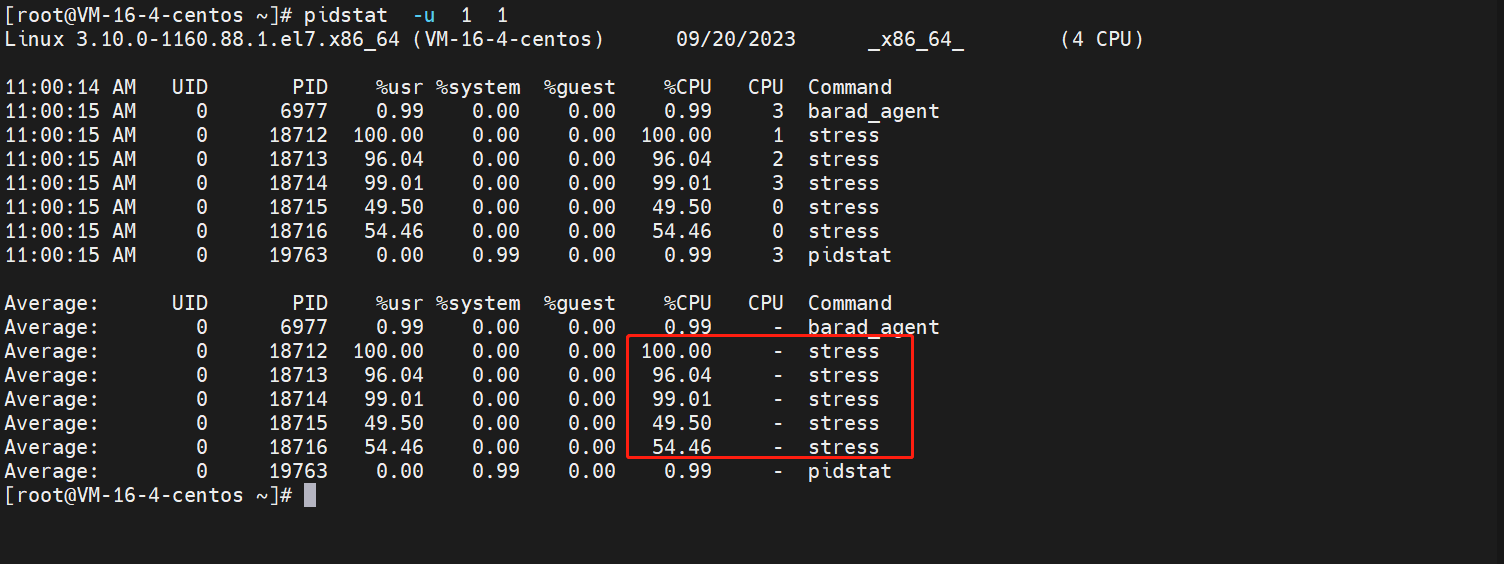
pidstat -u 1 5找出进程
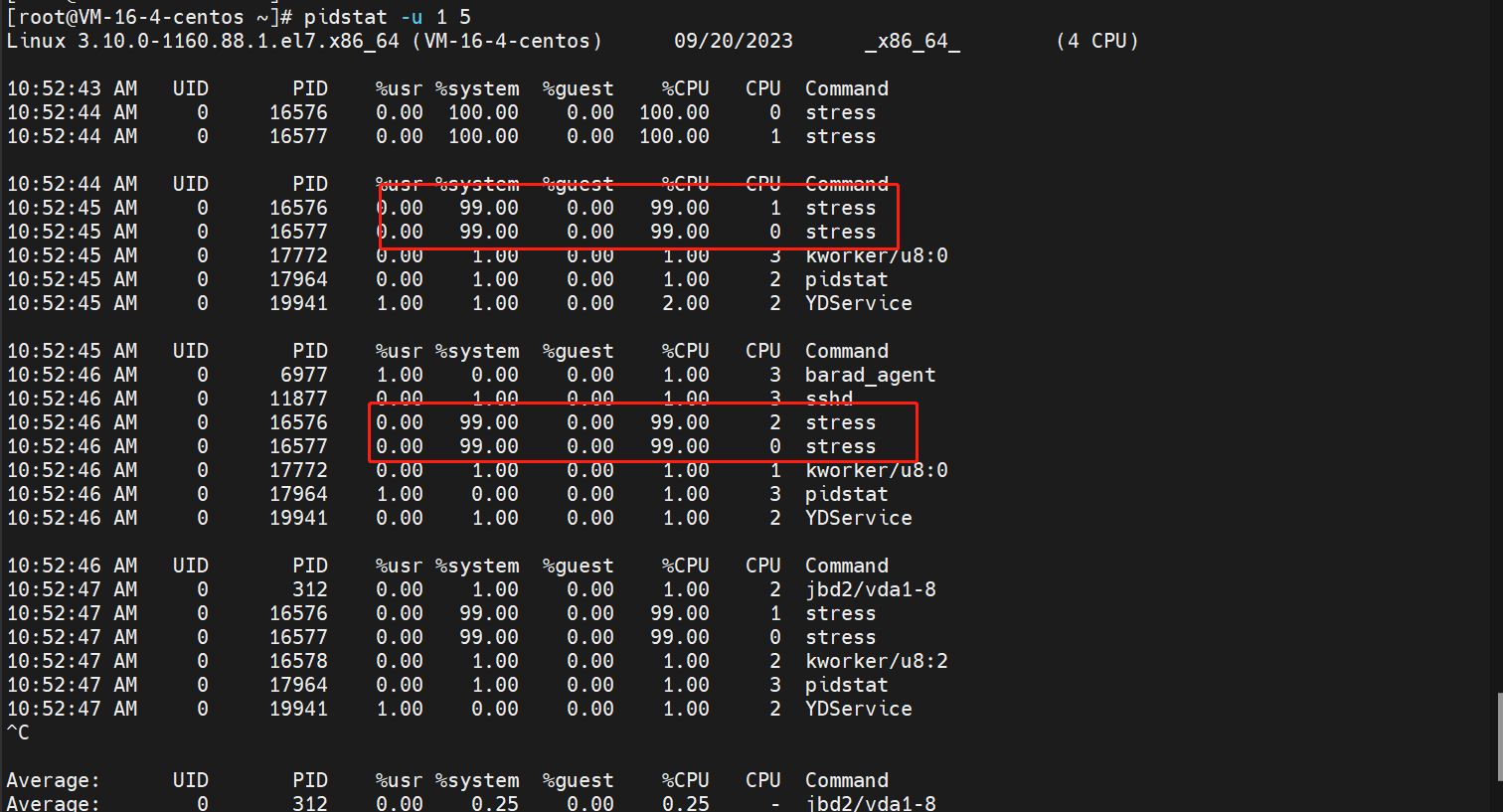
大量进程
- 模拟大量进程(超过了CPU核心数)
stress -c 5 --timeout 600
- 负载的历史趋势:可以明显看到飙升

- 执行
pidstat -u 1 1看下输出情况:5个进程在抢夺4个CPU,超出了CPU的计算能力,负载过载了